Working with Transformers#
Rotary Position Embedding#
Added in version 10.15.1: Built-in support for RoPE (Rotary Position Embedding) with the new IRotaryEmbeddingLayer.
TensorRT includes built-in support for RoPE (Rotary Position Embedding) for transformers to make it easier to express RoPE and convert ONNX models with the IRotaryEmbeddingLayer (C++, Python) API to TensorRT.
The IRotaryEmbeddingLayer has three inputs, one optional input, and two attributes:
Inputs
(index 0) input: The input activation tensor with shape[B, N, S, H](index 1) cosCache: The cosine values for calculating the rotary embedding(index 2) sinCache: The sine values for calculating the rotary embedding
cosCache and sinCache should have the shape [B, S, H / 2].
Optional input
(index 3) positionIds: Position IDs for indexing intocosCacheandsinCache
positionIds should have shape [B, S]. When positionIds is provided, cosCache and sinCache should correspondingly have shape [maxPositionId + 1, H / 2].
Attributes
interleaved: A boolean that specifies whether the input tensor is ininterleavedformat, that is, whether the 2d vectors rotated are taken from adjacent 2 elements in the hidden dimension.rotaryEmbeddingDim: An integer specifying the hidden dimension that participates in RoPE. A special value of 0 means the full hidden dimension participates in RoPE. If it is not0, then the last dimension ofcosCacheandsinCacheshould correspondingly berotaryEmbeddingDim / 2instead ofH / 2.
The IRotaryEmbeddingLayer has one output, which is the output activation tensor. It has the same shape and format as (index 0) input: the input activation tensor with shape.
The IRotaryEmbeddingLayer is supported by all SM versions.
KV Cache#
Added in version 10.15.1: Added KVCacheUpdate API to efficiently reuse KV cache and save GPU computation.
TensorRT supports using KV cache when doing LLM inference with transformers using the IKVCacheUpdateLayer (C++, Python).
The IKVCacheUpdateLayer has three inputs, one output, and two attributes.
Inputs
(index 0) cache: The K/V cache tensor with shape[B, N, S_max, H]. Allocate this tensor and provide it as an input to the TensorRT network.(index 1) update: The newly calculated K or V tensor with dimension:[B, N, S_new, H].(index 2) writeIndices: A tensor of size[B]represents where to start to write K/V updates for each sequence.
Output
The K/V cache tensor has a shape [B, N, S_max, H].
Attributes
cacheMode: An enum that specifies the K/V cache update strategy. Currently, onlykLINEARmode is supported, which performs sequential updates to the cache based on the provided write indices.
Note
IKVCacheUpdateLayer does not own or allocate the cache memory. Memory management is handled by higher-level frameworks (such as TensorRT Edge-LLM or your application).
Memory Requirements: The cache input tensor and cache output tensor must share the same device memory to enable in-place updates. Use the context->setTensorAddress() API to explicitly set both tensors to the same memory address. If different addresses are assigned to these tensors, TensorRT will report an API error.
TensorRT also includes a public engine API getAliasedInputTensor(char const* outputTensorName) (C++, Python)).
IKVCacheUpdateLayer has the same hardware support matrix as IAttention.
MoE (Mixture of Experts)#
TensorRT includes built-in support for MoE (Mixture of Experts) in transformer models using the IMoELayer (C++, Python) API.
The IMoELayer is currently only supported on SM110.
Inputs
(index 0) hiddenStates: Activation tensor with shape[B, S, H](index 1) selectedExpertsForTokens: Indexes of chosen experts per token, with shape[B, S, topK](index 2) scoresForSelectedExperts: Scores per chosen expert for the weighted output, with shape[B, S, topK]
The following inputs are set using setGatedWeights. Each tensor corresponds to a layer in the expert’s GLU (gated linear unit), where I is the internal hidden size within each expert.
fcGateWeights: GLU gate weights, with shape[numExperts, H, I]fcUpWeights: GLU up-projection weights, with shape[numExperts, H, I]fcDownWeights: GLU down-projection weights, with shape[numExperts, I, H]
The following optional inputs are set using setGatedBiases:
fcGateBias: GLU gate biases, with shape[numExperts, I]fcUpBias: GLU up-projection biases, with shape[numExperts, I]fcDownBias: GLU down-projection biases, with shape[numExperts, H]
The following input is set using setQuantizationStatic:
fcDownActivationScale: Quantization scales for thefcDownactivation input (mul output), with shape[]or[numExperts]
Attributes
activationType: Activation type in the expert GLU. Supported values:NoneandSiLU. Set viasetGatedWeights.quantizationToType: Type to quantize the mul output (fcDowninput) to. Currently only FP8 is supported. Set viasetQuantizationStatic.
Note
The following attributes and inputs are not yet supported:
quantizationBlockShape,dynQOutputScaleType,fcDownActivationDblQScale(set viasetQuantizationDynamicDblQ), and the SwiGLU parameters (swigluParamLimit,swigluParamAlpha,swigluParamBeta).Performance may be limited when the sequence length (
S) exceeds 16.
Output
The IMoELayer produces one output with the same shape as hiddenStates ([B, S, H]), representing the weighted sum of the top-K expert outputs.
Supported Configuration
Parameter |
Requirement |
|---|---|
Hardware |
SM110 |
Weights |
NVFP4 double quantized. Weights pass through a DQ layer (with scales from a second DQ), then optionally a |
|
FP8 static quantization via a DQ layer before the MoE layer. |
Internal mul output ( |
FP8 static quantization. Set via |
SwiGLU parameters |
Not supported |
Multi-Head Attention Fusion#
TensorRT supports two different methods to trigger Multi-Head Attention (MHA) fusion:
Adding an attention operator to the network using
IAttentionAPI.Constructing an attention graph using primitive
INetworklayers likeIMatrixMultiplyLayerandISoftMaxLayer.
MHA computes softmax(Q * Kᵀ ⊗ mask) * V, where:
Qis query embeddingKis key embeddingVis value embeddingsmaskcan be:A boolean mask indicating that the corresponding position is allowed to attend by Softmax.
An add mask offsetting
Q * Kᵀ
Note
TensorRT requires Q or K to be multiplied with \(attention scale\) or both Q and K to be multiplied with \(\sqrt{attention scale}\) before going into IAttention or the first Batched Matrix Multiply (BMM) IMatrixMultiplyLayer for numeric stability and performance reasons.
The shape of Q is [B, N_q, S_q, H], and the shapes of K and V are [B, N_kv, S_kv, H], where:
Bis batch sizeN_qandN_kvare the numbers of attention heads of the query and key/value, respectivelyS_qandS_kvare the sequence lengths of the query and key/value, respectively.His the head/hidden size
Group-Query Attention (GQA) and Multi-Query Attention (MQA) fusion are also supported when N_kv == 1 and N_q % N_kv == 0 respectively.
We highly recommend tailoring your model to the said restrictions in the following tables, so that MHA fusion happens. It is important because MHA fusion optimizes large sequence length cases by significantly reducing memory footprint from O(S^2) to O(S), where S is the sequence length. On top of that, it shares the common performance benefits of operator fusion, that is, reduced memory traffic, better hardware utilization, less kernel launch, and synchronization overhead.
Feature |
FP16 |
BF16 |
FP8 |
|---|---|---|---|
SM Version ( |
|
|
|
Head Size ( |
|
|
|
Sequence Length ( |
No restriction |
No restriction |
No restriction |
Quantization |
Not required |
Not required |
Specify Q/DQ layers in the MHA pattern for FP8. |
Accumulation Precision ( |
FP32 |
FP32 |
FP32 |
Accumulation Precision ( |
FP32 |
FP32 |
FP32 |
Supported Mask Type |
1d or 2d vector or scalar |
1d or 2d vector or scalar |
1d or 2d vector or scalar |
Pointwise op |
Activation, Constant, Elementwise (including SiLU), Scale, and Unary |
Activation, Constant, Elementwise (including SiLU), Scale, and Unary |
Activation, Constant, Elementwise (including SiLU), Scale, and Unary |
Feature |
FP16 |
BF16 |
INT8 |
FP8 |
|---|---|---|---|---|
SM Version ( |
|
|
|
|
Head Size ( |
|
|
|
|
Sequence Length ( |
No restriction |
No restriction |
|
|
Quantization |
Not required |
Not required |
Specify Q/DQ layers in the MHA pattern for FP8 and INT8. |
Specify Q/DQ layers in the MHA pattern for FP8 and INT8. |
Accumulation Precision ( |
|
FP32 |
INT32 |
FP32 |
Accumulation Precision ( |
|
FP32 |
INT32 |
FP32 |
Supported Mask Type |
Any masking (such as Select operator in TensorRT) |
Any masking (such as Select operator in TensorRT) |
Any masking (such as Select operator in TensorRT) |
Any masking (such as Select operator in TensorRT) |
Pointwise op |
Activation, Constant, Elementwise (including SiLU), Pointwise (single input), Scale, and Unary |
Activation, Constant, Elementwise (including SiLU), Pointwise (single input), Scale, and Unary |
Activation, Constant, Elementwise (including SiLU), Pointwise (single input), Scale, and Unary |
Activation, Constant, Elementwise (including SiLU), Pointwise (single input), Scale, and Unary |
Note
FP8 MHA is expected to outperform FP16 MHA when the head size (H) ≥ 128 or the sequence length S_{q,kv} ≥ 128.
Note
Numerical issues in multi-head attention implementations
Attention implementations that use online softmax (for example, Flash Attention) can produce NaN outputs with certain attention masks. In TensorRT 10.16, two mitigations are applied for all platforms prior to Blackwell datacenter (SM100, SM110):
The attention kernel guards against NaN values at critical computation points.
Multiply+Add to fused-multiply-add optimization is disabled where unsafe, consistent with other frameworks.
These mitigations may reduce performance by 2–3%, or up to 5–10% in worst cases.
Method 1 (Recommended): Use IAttention API
IAttention offers a direct API to incorporate an attention to the network and trigger the MHA fusion in TensorRT. Refer to the IAttention Operator Documentation for more details.
IAttention by default assumes the attention should always use a fused kernel. If the added attention does not comply with the restrictions listed in the tables above, and thus a fused kernel cannot be utilized, the engine build will raise an error. If users want to allow IAttention to fallback to use non-fused kernels, users can set the IAttention to be decomposable by calling the method IAttention::setDecomposable.
To quantize an IAttention, Q/DQ pairs following Explicit Quantization rules must be used for all query, key and value inputs with another normalization quantize scale and a normalization quantize-to data type supplied to IAttention using IAttention::setNormalizationQuantizeScale and IAttention::setNormalizationQuantizeToType respectively. The normalization quantize scale and the normalization quantize-to data type have to match the data types of the Q/DQ pairs. The output of the IAttention can be quantized with an optional quantizer.
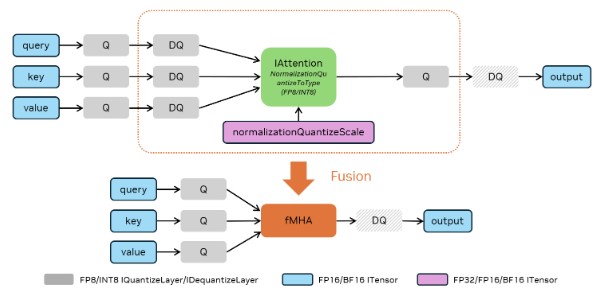
To apply masks with IAttention, use IAttention::setCausal for causal masks or IAttention::setMask for arbitrary masks (boolean or float).
Added in version 10.15.1: Support for Sage Attention with Dynamic Quantization. Dynamic Quantization now supports up to 2D blocks for per-token quantization.
To add a Sage Attention and trigger the fusion, follow the paradigm in the above figure and use IDynamicQuantizeLayer in place of IQuantizeLayer after query, key, value.
Method 2: Construct an Attention Graph with Primitive ``INetwork`` Layers
The following figures demonstrate how FP16, BF16, FP8, and INT8 attentions can be constructed to trigger MHA fusion. Batched MatMul uses IMatrixMultiplyLayer, Softmax uses ISoftMaxLayer and Q/DQ uses IQuantizeLayer and IDequantizeLayer.
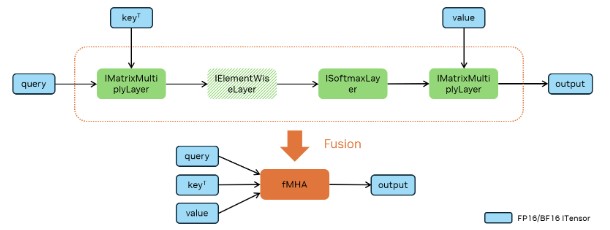
TensorRT chooses the accumulation precision by default based on the input types and performance considerations. However, you can also control accumulation precision (refer to Control of Computational Precision).
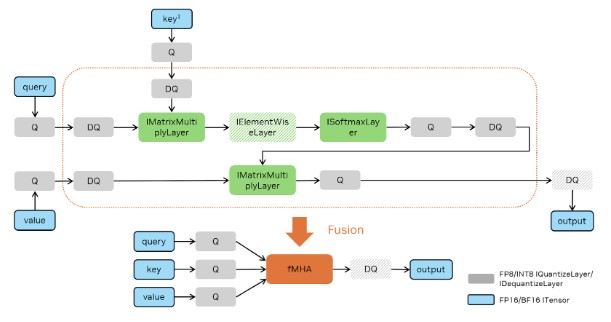
The MHA fusion captures common pointwise operators in series in MHA as mentioned in the pointwise operation list. It also covers Q/DQ fusion following MHA for certain quantization and architecture (such as FP16/BF16 to FP8/INT8 on NVIDIA Ampere GPU architecture).
For method 2, TensorRT can decide not to fuse an MHA graph into a single kernel based on performance evaluations or other constraints.
Example Workflow: FP8 MHA Fusion#
Assume you have an ONNX model, vit_base_patch8_224_Opset17.onnx, and calibration data, calib.npy, on your local machine.
Install the TensorRT model optimizer.
pip3 install --no-cache-dir --extra-index-url https://pypi.nvidia.com nvidia-modelop
Quantize a model with TensorRT model optimizer. For more information, refer to these detailed instructions.
python3 -m modelopt.onnx.quantization \ --onnx_path=vit_base_patch8_224_Opset17.onnx \ --quantize_mode=<fp8|int8> \ --calibration_data=calib.npy \ --calibration_method=<max|entropy> \ --output_path=vit_base_patch8_224_Opset17.quant.onnx
For example, to quantize the model using FP8 and entropy and store as vit_base_patch8_224_Opset17.quant.onnx, use:
python3 -m modelopt.onnx.quantization \ --onnx_path=vit_base_patch8_224_Opset17.onnx \ --quantize_mode=fp8 \ --calibration_data=calib.npy \ --calibration_method=entropy \ --output_path=vit_base_patch8_224_Opset17.quant.onnx
Compile the quantized model with TensorRT.
trtexec --onnx=vit_base_patch8_224_Opset17.quant.onnx \ --saveEngine=vit_base_patch8_224_Opset17.engine \ --stronglyTyped --skipInference --profilingVerbosity=detailed
Run the quantized model with TensorRT.
trtexec --loadEngine=vit_base_patch8_224_Opset17.engine \ --useCudaGraph --noDataTransfers --useSpinWait
Add the following options if you want to check if MHA is fused. MHA should be fused if you find the
mhaop in theoutput.logfile.trtexec --loadEngine=vit_base_patch8_224_Opset17.engine \ --profilingVerbosity=detailed --dumpLayerInfo --skipInference &> output.log
Tip
There are two ways to set the accumulation data type to FP32:
Manually set computational precision. For more information, refer to these detailed instructions.
Convert your ONNX model using TensorRT Model Optimizer, which adds the Cast ops automatically.
If the MHA has a head size (
H) that is not a multiple of 16, for better performance do not add Q/DQ ops in the MHA to fall back to the FP16/BF16 MHA.Compare MHA fusion performance of INT8 with FP8.
Example: Exploiting Sparsity in Attention Masks#
In limited cases, TensorRT can exploit block sparsity in attention masks to reduce the runtime of the attention computation. For example, an attention with a causal mask requires half the computation of a regular attention (since it only considers query tokens with index position in the sequence at or after a corresponding key token’s index,for example, q >= kv), therefore, TensorRT can achieve up to 2x speedup on the attention computation.
In ONNX, such as here is how you would express a causal mask for primitive op constructed attention.
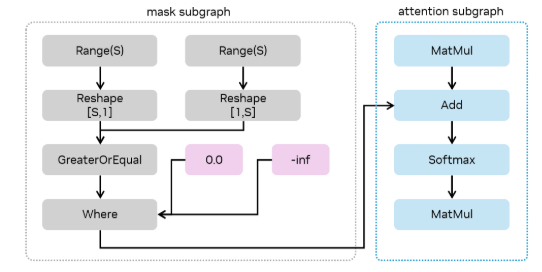
While TensorRT’s overall approach to recognizing sparsity in masks is flexible, there are a few characteristics of this expression that must be present for TensorRT to consider such an optimization.
The mask is expressed using indices along the sequence length (that is, through the
Rangeop). A causal mask is written asq >= kv, therefore, we get the index, the sequence length, the query, key dimensions through theRangeops, and reshape them so they can be compared.The mask subgraph (that is, the subgraph of operations feeding into the
Add, starting with theWhere) must be expressed solely using pointwise operations, position expressions (such asTrilu,Range), orExpandoperations (or equivalentReshape,Tileoperations).Along the chain of operations from the
MatMulto theSoftmax, there must be exactly one operation doing masking, in this case theAdd. That operation with input dependent on the MatMulvInand outputvOutmust obey the property that at a point (q,kv) in the attention computation:If the mask is valid at that point,
vOut = vIn.If the mask is invalid at that point,
vOut = -inf.
The masking operation must be a
Where,Add, orSubtractoperation.
Example of Using Transformer-Oriented APIs#
Examples of how IKVCacheUpdateLayer can be used together with IAttention and IRotaryEmbeddingLayer:
1ITensor* qInput = network->addInput("q", DataType::kHALF,
2 Dims4{-1, numQHeads, -1, headSize});
3ITensor* kInput = network->addInput("k", DataType::kHALF,
4 Dims4{-1, numKvHeads, -1, headSize});
5ITensor* vInput = network->addInput("v", DataType::kHALF,
6 Dims4{-1, numKvHeads, -1, headSize});
7
8ITensor* kCacheInput = network->addInput("kCache", DataType::kHALF,
9 Dims4{-1, numKvHeads, kvCacheCapacity, headSize});
10ITensor* vCacheInput = network->addInput("vCache", DataType::kHALF,
11 Dims4{-1, numKvHeads, kvCacheCapacity, headSize});
12ITensor* ropeCosCache = network->addInput("ropeCosCache", DataType::kHALF,
13 Dims2{maxPositionEmbeddings, headSize / 2});
14ITensor* ropeSinCache = network->addInput("ropeSinCache", DataType::kHALF,
15 Dims2{maxPositionEmbeddings, headSize / 2});
16ITensor* positionIds = network->addInput("positionIds", DataType::kINT32,
17 Dims2{-1, -1});
18ITensor* kCacheIndices = network->addInput("kCacheIndices", DataType::kINT32,
19 Dims{1, {-1}});
20// Used to slice the present KV from the cache
21ITensor* presentLengthInput = network->addInput("presentLength", DataType::kINT32,
22 Dims{1, {-1}});
23
24// Apply RoPE to Q and K
25IRotaryEmbeddingLayer* ropeQ = network->addRotaryEmbedding(*qInput, *ropeCosCache, *ropeSinCache,
26 false, 0); // interleaved=false, rotaryEmbeddingDim=0 (use all)
27ropeQ->setInput(3, *positionIds);
28IRotaryEmbeddingLayer* ropeK = network->addRotaryEmbedding(*kInput, *ropeCosCache, *ropeSinCache,
29 false, 0);
30ropeK->setInput(3, *positionIds);
31
32ITensor* ropeQTensor = ropeQ->getOutput(0);
33ITensor* ropeKTensor = ropeK->getOutput(0);
34
35// Update KV cache
36KVCacheMode kvCacheMode = KVCacheMode::kLINEAR;
37IKVCacheUpdateLayer* kCacheLayer = network->addKVCacheUpdate(*kCacheInput, *ropeKTensor,
38 *kCacheIndices, kvCacheMode);
39IKVCacheUpdateLayer* vCacheLayer = network->addKVCacheUpdate(*vCacheInput, *vInput,
40 *kCacheIndices, kvCacheMode);
41
42ITensor* kCacheOutput = kCacheLayer->getOutput(0);
43ITensor* vCacheOutput = vCacheLayer->getOutput(0);
44
45// Mark cache outputs
46kCacheOutput->setName("kCacheOutput");
47network->markOutput(*kCacheOutput);
48vCacheOutput->setName("vCacheOutput");
49network->markOutput(*vCacheOutput);
50
51// Create slice layers to extract present KV from cache
52ITensor* kPresent = /* ... */;
53ITensor* vPresent = /* ... */;
54
55// Apply Q/K scale using elementwise multiplication
56// Scale Q by sqrt(head size) to get the same effect as scaling QK^T by scale
57float qkScale = 1.0f / std::sqrt(static_cast<float>(headSize));
58half_float::half scaleData{qkScale};
59IConstantLayer* scaleConst = network->addConstant(Dims4{1, 1, 1, 1}, Weights{DataType::kHALF, &scaleData, 1});
60
61IElementWiseLayer* scaledQ = network->addElementWise(*ropeQTensor, *scaleConst->getOutput(0),
62 ElementWiseOperation::kPROD);
63ITensor* scaledQTensor = scaledQ->getOutput(0);
64
65// Add attention layer
66IAttention* attention = network->addAttention(*scaledQTensor, *kPresent, *vPresent,
67 AttentionNormalizationOp::kSOFTMAX, false);
68attention->setDecomposable(true);
69
70ITensor* attentionOutput = attention->getOutput(0);
71attentionOutput->setName("attentionOutput");
72network->markOutput(*attentionOutput);
1q_input = network.add_input("q", trt.float16,
2 (-1, num_q_heads, -1, head_size))
3k_input = network.add_input("k", trt.float16,
4 (-1, num_kv_heads, -1, head_size))
5v_input = network.add_input("v", trt.float16,
6 (-1, num_kv_heads, -1, head_size))
7
8k_cache_input = network.add_input("k_cache", trt.float16,
9 (-1, num_kv_heads, kv_cache_capacity, head_size))
10v_cache_input = network.add_input("v_cache", trt.float16,
11 (-1, num_kv_heads, kv_cache_capacity, head_size))
12
13rope_cos_cache = network.add_input("rope_cos_cache", trt.float16,
14 (max_position_embeddings, head_size // 2))
15rope_sin_cache = network.add_input("rope_sin_cache", trt.float16,
16 (max_position_embeddings, head_size // 2))
17
18position_ids = network.add_input("position_ids", trt.int32, (-1, -1))
19k_cache_indices = network.add_input("k_cache_indices", trt.int32,(-1, ))
20
21# Used to slice the present KV from the cache
22present_length_input = network.add_input("present_length", trt.int32, (-1, ))
23
24# Apply RoPE to Q and K
25rope_q = network.add_rotary_embedding(
26 q_input, rope_cos_cache, rope_sin_cache, False,
27 0) # interleaved=False, rotary_ndims=0 (use all)
28rope_q.set_input(3, position_ids)
29
30rope_k = network.add_rotary_embedding(
31 k_input, rope_cos_cache, rope_sin_cache, False, 0)
32rope_k.set_input(3, position_ids)
33
34rope_q_tensor = rope_q.get_output(0)
35rope_k_tensor = rope_k.get_output(0)
36
37# Update KV cache
38kv_cache_mode = trt.KVCacheMode.LINEAR
39k_cache_layer = network.add_kv_cache_update(k_cache_input,
40 rope_k_tensor,
41 k_cache_indices,
42 kv_cache_mode)
43v_cache_layer = network.add_kv_cache_update(v_cache_input,
44 v_input,
45 k_cache_indices,
46 kv_cache_mode)
47
48k_cache_output = k_cache_layer.get_output(0)
49v_cache_output = v_cache_layer.get_output(0)
50
51# Mark cache outputs
52k_cache_output.name = "k_cache_output"
53network.mark_output(k_cache_output)
54v_cache_output.name = "v_cache_output"
55network.mark_output(v_cache_output)
56
57# Create slice layers to extract present KV from cache
58k_present = …
59v_present = …
60
61# Apply Q/K scale using elementwise multiplication
62# Scale Q by sqrt(head size) to get the same effect as scaling QK^T by scale
63qk_scale = 1.0 / (head_size**0.5)
64scale_const = network.add_constant((1, 1, 1, 1),
65 np.array([qk_scale],
66 dtype=np.float16))
67scaled_q = network.add_elementwise(rope_q_tensor,
68 scale_const.get_output(0),
69 trt.ElementWiseOperation.PROD)
70scaled_q_tensor = scaled_q.get_output(0)
71
72# Add attention layer
73attention = network.add_attention(scaled_q_tensor, k_present,
74 v_present,trt.AttentionNormalizationOp.SOFTMAX, False)
75attention.decomposable = True
76attention_output = attention.get_output(0)
77attention_output.name = "attention_output"
78network.mark_output(attention_output)
Multi-Device Attention (Preview Feature)#
TensorRT supports multi-device attention through context parallelism, splitting the key-value sequence across multiple GPUs. Each GPU processes a portion of the sequence, and NCCL handles inter-device communication.
Supported data types: BF16 and FP16
Platform support: Blackwell (SM 100) and later
For more information, refer to the GPU Architecture and Precision Support section.
Note
Multi-device attention is a preview feature. Enable PreviewFeature::kMULTIDEVICE_RUNTIME_10_16 in the builder config. There is no ONNX compliant operator for multi-device attention. However, standard ONNX files generated by a sharding tool are supported when the Attention op includes an nbRanks field. You can also use the C++ or Python API directly.
The IAttention layer runs in multi-device mode when nbRanks > 1. Use IAttention::setNbRanks (C++) or IAttention.num_ranks (Python) to set the number of devices. Once set to a value greater than 1, this value cannot be changed.
Build-time configuration
Add the attention layer with the
IAttentionAPI.Call
IAttention::setNbRanks(nbRanks)(C++) or setattention.num_ranks = nbRanks(Python).Enable
PreviewFeature::kMULTIDEVICE_RUNTIME_10_16in the builder config.
Runtime requirements
Initialize an NCCL communicator with
ncclCommInitRankorncclCommInitAll.Call
IExecutionContext::setCommunicator(ncclComm_t)before inference.All participating ranks must execute the same network with synchronized execution calls.
1// Enable multi-device preview feature
2config->setPreviewFeature(PreviewFeature::kMULTIDEVICE_RUNTIME_10_16, true);
3
4// Add attention layer and set number of ranks
5auto attention = network->addAttention(query, key, value, AttentionNormalizationOp::kSOFTMAX, false);
6attention->setNbRanks(numGpus);
7
8// At runtime, on each rank, set communicator and run inference
9context->setCommunicator(ncclComm);
10context->enqueueV3(stream);
1# Enable multi-device preview feature
2config.set_preview_feature(trt.PreviewFeature.MULTIDEVICE_RUNTIME_10_16, True)
3
4# Add attention layer and set number of ranks
5attention = network.add_attention(query, key, value, trt.AttentionNormalizationOp.SOFTMAX, False)
6attention.num_ranks = num_gpus
7
8# At runtime, on each rank, set communicator and run inference
9context.set_communicator(nccl_comm)
10context.execute_async_v3(stream)