TensorFlow-2.x-Quantization-Toolkit
Installation
Docker
Latest TensorFlow 2.x docker image from NGC is recommended.
Clone the tensorflow-quantization repository, pull the docker image, and launch the container.
$ cd ~/ $ git clone https://github.com/NVIDIA/TensorRT.git $ docker pull nvcr.io/nvidia/tensorflow:22.03-tf2-py3 $ docker run -it --runtime=nvidia --gpus all --net host -v ~/TensorRT/tools/tensorflow-quantization:/home/tensorflow-quantization nvcr.io/nvidia/tensorflow:22.03-tf2-py3 /bin/bash
After the last command, you will be placed in the /workspace directory inside the running docker container, whereas the tensorflow-quantization repository is mounted in the /home directory.
$ cd /home/tensorflow-quantization $ ./install.sh $ cd tests $ python3 -m pytest quantize_test.py -rP
If all tests pass, installation is successful.
Local
$ cd ~/
$ git clone https://github.com/NVIDIA/TensorRT.git
$ cd TensorRT/tools/tensorflow-quantization
$ ./install.sh
$ cd tests
$ python3 -m pytest quantize_test.py -rP
If all tests pass, installation is successful.
Attention
This toolkit supports only Quantization Aware Training (QAT) as a quantization method.
Subclassed models are not supported in the current version of this toolkit. Original Keras layers are wrapped into quantized layers using TensorFlow's clone_model method, which doesn't support subclassed models.
Basics
Quantization Function
quantize_model is the only function the user needs to quantize any Keras model. It has the following signature:
(function) quantize_model:
(
model: tf.keras.Model,
quantization_mode: str = "full",
quantization_spec: QuantizationSpec = None,
custom_qdq_cases : List['CustomQDQInsertionCase'] = None
) -> tf.keras.Model
Note
Refer to the Python API for more details.
Example
import tensorflow as tf
from tensorflow_quantization import quantize_model, utils
assets = utils.CreateAssetsFolders("toolkit_basics")
assets.add_folder("example")
# 1. Create a simple model (baseline)
input_img = tf.keras.layers.Input(shape=(28, 28, 1))
x = tf.keras.layers.Conv2D(filters=2, kernel_size=(3, 3))(input_img)
x = tf.keras.layers.ReLU()(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(10)(x)
model = tf.keras.Model(input_img, x)
# 2. Train model
model.fit(train_images, train_labels, batch_size=32, epochs=2, validation_split=0.1)
# 3. Save model and then convert it to ONNX
tf.keras.models.save_model(model, assets.example.fp32_saved_model)
utils.convert_saved_model_to_onnx(assets.example.fp32_saved_model, assets.example.fp32_onnx_model)
# 4. Quantize the model
q_model = quantize_model(model)
# 5. Train quantized model again for a few epochs to recover accuracy (fine-tuning).
q_model.fit(train_images, train_labels, batch_size=32, epochs=2, validation_split=0.1)
# 6. Save the quantized model with QDQ nodes inserted and then convert it to ONNX
tf.keras.models.save_model(q_model, assets.example.int8_saved_model)
utils.convert_saved_model_to_onnx(assets.example.int8_saved_model, assets.example.int8_onnx_model)
Note
The quantized model q_model behaves similar to the original Keras model, meaning that the compile() and fit() functions can also be used to easily fine-tune the model.
Refer to Getting Started: End to End for more details.
Saved ONNX files can be visualized with Netron. Figure 1, below, shows a snapshot of the original FP32 baseline model.
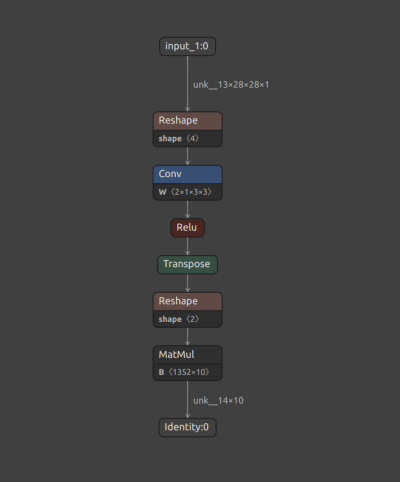
Figure 1. Original FP32 model.
The quantization process inserts Q/DQ
nodes at the inputs and weights (if layer is weighted) of all supported layers, according to the TensorRT™ quantization
policy.
The presence of a Quantize node (QuantizeLinear ONNX op), followed by a Dequantize node (DequantizeLinear ONNX op),
for each supported layer, can be verified in the Netron visualization in Figure 2 below.
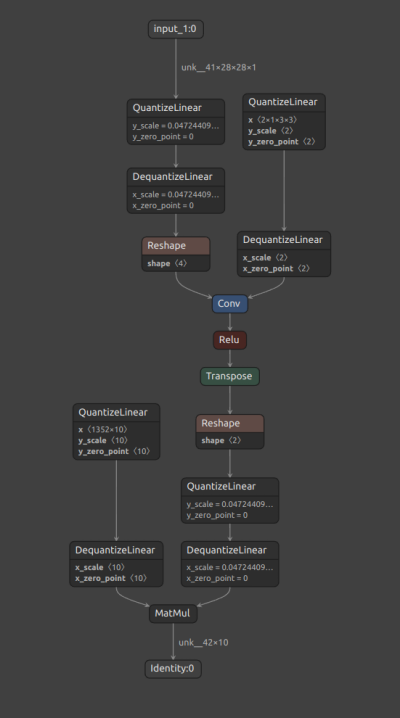
Figure 2. Quantized INT8 model.
TensorRT™ converts ONNX models with Q/DQ nodes into an INT8 engine, which can take advantage of Tensor Cores and other hardware accelerations in the latest NVIDIA® GPUs.
Quantization Modes
There are a few scenarios where one might need to customize the default quantization scheme.
We broadly categorize quantization (i.e. the process of adding Q/DQ nodes) into Full and Partial modes, depending on the set of layers that are quantized.
Additionally, Full quantization can be Default or Custom, while Partial quantization is always Custom.
- Full Default Quantization
All supported layers of a given model are quantized as per default toolkit behavior.
- Full Custom Quantization
Toolkit behavior can be programmed to quantize specific layers differentely by passing an object of
QuantizationSpecclass and/orCustomQDQInsertionCaseclass. The remaining supported layers are quantized as per default behavior.
- Partial Quantization
Only layers passed using
QuantizationSpecand/orCustomQDQInsertionCaseclass object are quantized.
Note
Refer to the Tutorials for examples on each mode.
Terminologies
Layer Name
Name of the Keras layer either assigned by the user or Keras. These are unique by default.
import tensorflow as tf
l = tf.keras.layers.Dense(units=100, name='my_dense')
Here ‘my_dense’ is a layer name assigned by the user.
Tip
For a given layer l, the layer name can be found using l.name.
Layer Class
Name of the Keras layer class.
import tensorflow as tf
l = tf.keras.layers.Dense(units=100, name='my_dense')
Here ‘Dense’ is the layer class.
Tip
For a given layer l, the layer class can be found using l.__class__.__name__ or l.__class__.__module__.
NVIDIA® vs TensorFlow Toolkit
TFMOT is TensorFlow’s official quantization toolkit. The quantization recipe used by TFMOT is different to NVIDIA®’s in terms of Q/DQ nodes placement, and it is optimized for TFLite inference. The NVIDIA® quantization recipe, on the other hand, is optimized for TensorRT™, which leads to optimal model acceleration on NVIDIA® GPUs and hardware accelerators.
Other differences:
Feature |
TensorFlow Model Optimization Toolkit (TFMOT) |
NVIDIA® Toolkit |
|---|---|---|
QDQ node placements |
Outputs and Weights |
Inputs and Weights |
Quantization support |
Whole model (full) and of some layers (partial by layer class) |
Extends TF quantization support: partial quantization by layer name and pattern-base quantization by extending |
Quantization scheme |
|
|
Additional Resources
About this toolkit
GTC 2022 Tech Talk (NVIDIA)
Blogs
Achieving FP32 Accuracy for INT8 Inference Using Quantization Aware Training with NVIDIA TensorRT (NVIDIA)
Speeding Up Deep Learning Inference Using TensorFlow, ONNX, and NVIDIA TensorRT (NVIDIA)
Videos
Generate per-tensor dynamic range
Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
Quantizing Deep Convolutional Networks for Efficient Inference: A Whitepaper
8-bit Inference with TensorRT (NVIDIA)
Documentation (NVIDIA)
Getting Started: End to End
NVIDIA® TensorFlow 2.x Quantization toolkit provides a simple API to quantize a given Keras model. At a higher level, Quantization Aware Training (QAT) is a three-step workflow as shown below:
Initially, the network is trained on the target dataset until fully converged. The Quantization step consists of inserting Q/DQ nodes in the pre-trained network to simulate quantization during training. Note that simply adding Q/DQ nodes will result in reduced accuracy since the quantization parameters are not yet updated for the given model. The network is then re-trained for a few epochs to recover accuracy in a step called “fine-tuning”.
Goal
Train a simple network on the Fashion MNIST dataset and save it as the baseline model.
Quantize the pre-trained baseline network.
Fine-tune the quantized network to recover accuracy and save it as the QAT model.
1. Train
Import required libraries and create a simple network with convolution and dense layers.
import tensorflow as tf
from tensorflow_quantization import quantize_model
from tensorflow_quantization import utils
assets = utils.CreateAssetsFolders("GettingStarted")
assets.add_folder("example")
def simple_net():
"""
Return a simple neural network.
"""
input_img = tf.keras.layers.Input(shape=(28, 28), name="nn_input")
x = tf.keras.layers.Reshape(target_shape=(28, 28, 1), name="reshape_0")(input_img)
x = tf.keras.layers.Conv2D(filters=126, kernel_size=(3, 3), name="conv_0")(x)
x = tf.keras.layers.ReLU(name="relu_0")(x)
x = tf.keras.layers.Conv2D(filters=64, kernel_size=(3, 3), name="conv_1")(x)
x = tf.keras.layers.ReLU(name="relu_1")(x)
x = tf.keras.layers.Conv2D(filters=32, kernel_size=(3, 3), name="conv_2")(x)
x = tf.keras.layers.ReLU(name="relu_2")(x)
x = tf.keras.layers.Conv2D(filters=16, kernel_size=(3, 3), name="conv_3")(x)
x = tf.keras.layers.ReLU(name="relu_3")(x)
x = tf.keras.layers.Conv2D(filters=8, kernel_size=(3, 3), name="conv_4")(x)
x = tf.keras.layers.ReLU(name="relu_4")(x)
x = tf.keras.layers.MaxPooling2D(pool_size=(2, 2), name="max_pool_0")(x)
x = tf.keras.layers.Flatten(name="flatten_0")(x)
x = tf.keras.layers.Dense(100, name="dense_0")(x)
x = tf.keras.layers.ReLU(name="relu_5")(x)
x = tf.keras.layers.Dense(10, name="dense_1")(x)
return tf.keras.Model(input_img, x, name="original")
# create model
model = simple_net()
model.summary()
Model: "original"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
nn_input (InputLayer) [(None, 28, 28)] 0
reshape_0 (Reshape) (None, 28, 28, 1) 0
conv_0 (Conv2D) (None, 26, 26, 126) 1260
relu_0 (ReLU) (None, 26, 26, 126) 0
conv_1 (Conv2D) (None, 24, 24, 64) 72640
relu_1 (ReLU) (None, 24, 24, 64) 0
conv_2 (Conv2D) (None, 22, 22, 32) 18464
relu_2 (ReLU) (None, 22, 22, 32) 0
conv_3 (Conv2D) (None, 20, 20, 16) 4624
relu_3 (ReLU) (None, 20, 20, 16) 0
conv_4 (Conv2D) (None, 18, 18, 8) 1160
relu_4 (ReLU) (None, 18, 18, 8) 0
max_pool_0 (MaxPooling2D) (None, 9, 9, 8) 0
flatten_0 (Flatten) (None, 648) 0
dense_0 (Dense) (None, 100) 64900
relu_5 (ReLU) (None, 100) 0
dense_1 (Dense) (None, 10) 1010
=================================================================
Total params: 164,058
Trainable params: 164,058
Non-trainable params: 0
_________________________________________________________________
Load Fashion MNIST data and split train and test sets.
# Load Fashion MNIST dataset
mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# Normalize the input image so that each pixel value is between 0 to 1.
train_images = train_images / 255.0
test_images = test_images / 255.0
Compile the model and train for five epochs.
# Train original classification model
model.compile(
optimizer="adam",
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"],
)
model.fit(
train_images, train_labels, batch_size=128, epochs=5, validation_split=0.1
)
# get baseline model accuracy
_, baseline_model_accuracy = model.evaluate(
test_images, test_labels, verbose=0
)
print("Baseline test accuracy:", baseline_model_accuracy)
Epoch 1/5
422/422 [==============================] - 4s 8ms/step - loss: 0.5639 - accuracy: 0.7920 - val_loss: 0.4174 - val_accuracy: 0.8437
Epoch 2/5
422/422 [==============================] - 3s 8ms/step - loss: 0.3619 - accuracy: 0.8696 - val_loss: 0.4134 - val_accuracy: 0.8433
Epoch 3/5
422/422 [==============================] - 3s 8ms/step - loss: 0.3165 - accuracy: 0.8855 - val_loss: 0.3137 - val_accuracy: 0.8812
Epoch 4/5
422/422 [==============================] - 3s 8ms/step - loss: 0.2787 - accuracy: 0.8964 - val_loss: 0.2943 - val_accuracy: 0.8890
Epoch 5/5
422/422 [==============================] - 3s 8ms/step - loss: 0.2552 - accuracy: 0.9067 - val_loss: 0.2857 - val_accuracy: 0.8952
Baseline test accuracy: 0.888700008392334
# save TF FP32 original model
tf.keras.models.save_model(model, assets.example.fp32_saved_model)
# Convert FP32 model to ONNX
utils.convert_saved_model_to_onnx(saved_model_dir = assets.example.fp32_saved_model, onnx_model_path = assets.example.fp32_onnx_model)
INFO:tensorflow:Assets written to: GettingStarted/example/fp32/saved_model/assets
INFO:tensorflow:Assets written to: GettingStarted/example/fp32/saved_model/assets
ONNX conversion Done!
2. Quantize
Full model quantization is the most basic quantization mode someone can follow. In this mode, Q/DQ nodes are inserted in all supported keras layers, with a single function call:
# Quantize model
quantized_model = quantize_model(model)
Keras model summary shows all supported layers wrapped into QDQ wrapper class.
quantized_model.summary()
Model: "original"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
nn_input (InputLayer) [(None, 28, 28)] 0
reshape_0 (Reshape) (None, 28, 28, 1) 0
quant_conv_0 (Conv2DQuantiz (None, 26, 26, 126) 1515
eWrapper)
relu_0 (ReLU) (None, 26, 26, 126) 0
quant_conv_1 (Conv2DQuantiz (None, 24, 24, 64) 72771
eWrapper)
relu_1 (ReLU) (None, 24, 24, 64) 0
quant_conv_2 (Conv2DQuantiz (None, 22, 22, 32) 18531
eWrapper)
relu_2 (ReLU) (None, 22, 22, 32) 0
quant_conv_3 (Conv2DQuantiz (None, 20, 20, 16) 4659
eWrapper)
relu_3 (ReLU) (None, 20, 20, 16) 0
quant_conv_4 (Conv2DQuantiz (None, 18, 18, 8) 1179
eWrapper)
relu_4 (ReLU) (None, 18, 18, 8) 0
max_pool_0 (MaxPooling2D) (None, 9, 9, 8) 0
flatten_0 (Flatten) (None, 648) 0
quant_dense_0 (DenseQuantiz (None, 100) 65103
eWrapper)
relu_5 (ReLU) (None, 100) 0
quant_dense_1 (DenseQuantiz (None, 10) 1033
eWrapper)
=================================================================
Total params: 164,791
Trainable params: 164,058
Non-trainable params: 733
_________________________________________________________________
Let’s check the quantized model’s accuracy immediately after Q/DQ nodes are inserted.
# Compile quantized model
quantized_model.compile(
optimizer=tf.keras.optimizers.Adam(0.0001),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"],
)
# Get accuracy immediately after QDQ nodes are inserted.
_, q_aware_model_accuracy = quantized_model.evaluate(test_images, test_labels, verbose=0)
print("Quantization test accuracy immediately after QDQ insertion:", q_aware_model_accuracy)
Quantization test accuracy immediately after QDQ insertion: 0.883899986743927
The model’s accuracy decreases a bit as soon as Q/DQ nodes are inserted, requiring fine-tuning to recover it.
Note
Since this is a very small model, accuracy drop is small. For standard models like ResNets, accuracy drop immediately after QDQ insertion can be significant.
3. Fine-tune
Since the quantized model behaves similar to the original keras model, the same training recipe can be used for fine-tuning as well.
We fine-tune the model for two epochs and evaluate the model on the test dataset.
# fine tune quantized model for 2 epochs.
quantized_model.fit(
train_images, train_labels, batch_size=32, epochs=2, validation_split=0.1
)
# Get quantized accuracy
_, q_aware_model_accuracy_finetuned = quantized_model.evaluate(test_images, test_labels, verbose=0)
print("Quantization test accuracy after fine-tuning:", q_aware_model_accuracy_finetuned)
print("Baseline test accuracy (for reference):", baseline_model_accuracy)
Epoch 1/2
1688/1688 [==============================] - 26s 15ms/step - loss: 0.1793 - accuracy: 0.9340 - val_loss: 0.2468 - val_accuracy: 0.9112
Epoch 2/2
1688/1688 [==============================] - 25s 15ms/step - loss: 0.1725 - accuracy: 0.9373 - val_loss: 0.2484 - val_accuracy: 0.9070
Quantization test accuracy after fine-tuning: 0.9075999855995178
Baseline test accuracy (for reference): 0.888700008392334
Note
If the network is not fully converged, the fine-tuned model’s accuracy can surpass the original model’s accuracy.
# save TF INT8 original model
tf.keras.models.save_model(quantized_model, assets.example.int8_saved_model)
# Convert INT8 model to ONNX
utils.convert_saved_model_to_onnx(saved_model_dir = assets.example.int8_saved_model, onnx_model_path = assets.example.int8_onnx_model)
tf.keras.backend.clear_session()
WARNING:absl:Found untraced functions such as conv_0_layer_call_fn, conv_0_layer_call_and_return_conditional_losses, conv_1_layer_call_fn, conv_1_layer_call_and_return_conditional_losses, conv_2_layer_call_fn while saving (showing 5 of 14). These functions will not be directly callable after loading.
INFO:tensorflow:Assets written to: GettingStarted/example/int8/saved_model/assets
INFO:tensorflow:Assets written to: GettingStarted/example/int8/saved_model/assets
ONNX conversion Done!
In this example, accuracy loss due to quantization is recovered in just two epochs.
This NVIDIA® Quantization Toolkit provides an easy interface to create quantized networks, and thus take advantage of INT8 inference on NVIDIA® GPUs using TensorRT™.
Full Network Quantization
In this tutorial, we will take a sample network with ResNet-like network and perform full network quantization.
Goal
Take a resnet-like model and train on cifar10 dataset.
Perform full model quantization.
Fine-tune to recover model accuracy.
Save both original and quantized model while performing ONNX conversion.
#
# SPDX-FileCopyrightText: Copyright (c) 1993-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
# SPDX-License-Identifier: Apache-2.0
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
import tensorflow as tf
from tensorflow_quantization import quantize_model
import tiny_resnet
from tensorflow_quantization import utils
import os
tf.keras.backend.clear_session()
# Create folders to save TF and ONNX models
assets = utils.CreateAssetsFolders(os.path.join(os.getcwd(), "tutorials"))
assets.add_folder("simple_network_quantize_full")
# Load CIFAR10 dataset
cifar10 = tf.keras.datasets.cifar10
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
# Normalize the input image so that each pixel value is between 0 and 1.
train_images = train_images / 255.0
test_images = test_images / 255.0
nn_model_original = tiny_resnet.model()
tf.keras.utils.plot_model(nn_model_original, to_file = assets.simple_network_quantize_full.fp32 + "/model.png")
You must install pydot (`pip install pydot`) and install graphviz (see instructions at https://graphviz.gitlab.io/download/) for plot_model/model_to_dot to work.
# Train original classification model
nn_model_original.compile(
optimizer=tiny_resnet.optimizer(lr=1e-4),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"],
)
nn_model_original.fit(
train_images, train_labels, batch_size=32, epochs=10, validation_split=0.1
)
# Get baseline model accuracy
_, baseline_model_accuracy = nn_model_original.evaluate(
test_images, test_labels, verbose=0
)
baseline_model_accuracy = round(100 * baseline_model_accuracy, 2)
print("Baseline FP32 model test accuracy: {}".format(baseline_model_accuracy))
Epoch 1/10
1407/1407 [==============================] - 16s 9ms/step - loss: 1.7653 - accuracy: 0.3622 - val_loss: 1.5516 - val_accuracy: 0.4552
Epoch 2/10
1407/1407 [==============================] - 13s 9ms/step - loss: 1.4578 - accuracy: 0.4783 - val_loss: 1.3877 - val_accuracy: 0.5042
Epoch 3/10
1407/1407 [==============================] - 13s 9ms/step - loss: 1.3499 - accuracy: 0.5193 - val_loss: 1.3066 - val_accuracy: 0.5342
Epoch 4/10
1407/1407 [==============================] - 13s 9ms/step - loss: 1.2736 - accuracy: 0.5486 - val_loss: 1.2636 - val_accuracy: 0.5550
Epoch 5/10
1407/1407 [==============================] - 13s 9ms/step - loss: 1.2101 - accuracy: 0.5732 - val_loss: 1.2121 - val_accuracy: 0.5670
Epoch 6/10
1407/1407 [==============================] - 12s 9ms/step - loss: 1.1559 - accuracy: 0.5946 - val_loss: 1.1753 - val_accuracy: 0.5844
Epoch 7/10
1407/1407 [==============================] - 13s 9ms/step - loss: 1.1079 - accuracy: 0.6101 - val_loss: 1.1143 - val_accuracy: 0.6076
Epoch 8/10
1407/1407 [==============================] - 13s 9ms/step - loss: 1.0660 - accuracy: 0.6272 - val_loss: 1.0965 - val_accuracy: 0.6158
Epoch 9/10
1407/1407 [==============================] - 13s 9ms/step - loss: 1.0271 - accuracy: 0.6392 - val_loss: 1.1100 - val_accuracy: 0.6122
Epoch 10/10
1407/1407 [==============================] - 13s 9ms/step - loss: 0.9936 - accuracy: 0.6514 - val_loss: 1.0646 - val_accuracy: 0.6304
Baseline FP32 model test accuracy: 61.65
# Save TF FP32 original model
tf.keras.models.save_model(nn_model_original, assets.simple_network_quantize_full.fp32_saved_model)
# Convert FP32 model to ONNX
utils.convert_saved_model_to_onnx(saved_model_dir = assets.simple_network_quantize_full.fp32_saved_model, onnx_model_path = assets.simple_network_quantize_full.fp32_onnx_model)
# Quantize model
q_nn_model = quantize_model(model=nn_model_original)
q_nn_model.compile(
optimizer=tiny_resnet.optimizer(lr=1e-4),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"],
)
INFO:tensorflow:Assets written to: /home/nvidia/PycharmProjects/tensorrt_qat/docs/source/notebooks/tutorials/simple_network_quantize_full/fp32/saved_model/assets
WARNING:tensorflow:From /home/nvidia/PycharmProjects/tensorrt_qat/venv38_tf2.8_newPR/lib/python3.8/site-packages/tf2onnx/tf_loader.py:711: extract_sub_graph (from tensorflow.python.framework.graph_util_impl) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.compat.v1.graph_util.extract_sub_graph`
ONNX conversion Done!
_, q_model_accuracy = q_nn_model.evaluate(test_images, test_labels, verbose=0)
q_model_accuracy = round(100 * q_model_accuracy, 2)
print(
"Test accuracy immediately after quantization: {}, diff: {}".format(
q_model_accuracy, (baseline_model_accuracy - q_model_accuracy)
)
)
Test accuracy immediately after quantization:50.45, diff:11.199999999999996
tf.keras.utils.plot_model(q_nn_model, to_file = assets.simple_network_quantize_full.int8 + "/model.png")
You must install pydot (`pip install pydot`) and install graphviz (see instructions at https://graphviz.gitlab.io/download/) for plot_model/model_to_dot to work.
# Fine-tune quantized model
fine_tune_epochs = 2
q_nn_model.fit(
train_images,
train_labels,
batch_size=32,
epochs=fine_tune_epochs,
validation_split=0.1,
)
_, q_model_accuracy = q_nn_model.evaluate(test_images, test_labels, verbose=0)
q_model_accuracy = round(100 * q_model_accuracy, 2)
print(
"Accuracy after fine-tuning for {} epochs: {}".format(
fine_tune_epochs, q_model_accuracy
)
)
print("Baseline accuracy (for reference): {}".format(baseline_model_accuracy))
Epoch 1/2
1407/1407 [==============================] - 27s 19ms/step - loss: 0.9625 - accuracy: 0.6630 - val_loss: 1.0430 - val_accuracy: 0.6420
Epoch 2/2
1407/1407 [==============================] - 25s 18ms/step - loss: 0.9315 - accuracy: 0.6758 - val_loss: 1.0717 - val_accuracy: 0.6336
Accuracy after fine-tuning for 2 epochs: 62.27
Baseline accuracy (for reference): 61.65
# Save TF INT8 original model
tf.keras.models.save_model(q_nn_model, assets.simple_network_quantize_full.int8_saved_model)
# Convert INT8 model to ONNX
utils.convert_saved_model_to_onnx(saved_model_dir = assets.simple_network_quantize_full.int8_saved_model, onnx_model_path = assets.simple_network_quantize_full.int8_onnx_model)
tf.keras.backend.clear_session()
WARNING:absl:Found untraced functions such as conv2d_layer_call_fn, conv2d_layer_call_and_return_conditional_losses, conv2d_1_layer_call_fn, conv2d_1_layer_call_and_return_conditional_losses, conv2d_2_layer_call_fn while saving (showing 5 of 18). These functions will not be directly callable after loading.
INFO:tensorflow:Assets written to: /home/nvidia/PycharmProjects/tensorrt_qat/docs/source/notebooks/tutorials/simple_network_quantize_full/int8/saved_model/assets
INFO:tensorflow:Assets written to: /home/nvidia/PycharmProjects/tensorrt_qat/docs/source/notebooks/tutorials/simple_network_quantize_full/int8/saved_model/assets
ONNX conversion Done!
Note
ONNX files can be visualized with Netron.
Partial Network Quantization
This example shows how the NVIDIA TensorFlow 2.x Quantization Toolkit can be used to quantize only a few layers in a TensorFlow 2.x model.
Goal
Take a resnet-like model and train on cifar10 dataset.
Quantize only layers named 'conv2d_2' and 'dense' in the model.
Fine-tune to recover model accuracy.
Save both original and quantized model while performing ONNX conversion.
Background
Few/specific layers to quantize are passed to quantize_model function as an object of QuantizationSpec class.
quantization mode is set to partial in quantize_model function.
Adding layers with single input to QuantizationSpec is rather simple. However, for multi-input layers, flexibility to quantize specific inputs is also provided.
For example, user wants to quantize layers with name conv2d_2 and add.
Default behavior of Add layer class is NOT to quantize any input. None of inputs to the Add class layer is quantized when following code snippet is used.
q_spec = QuantizationSpec()
layer_name = ['conv2d_2']
q_spec.add(name=layer_name, quantization_index=layer_quantization_index)
q_model = quantize_model(model, quantization_spec=q_spec)
However, when layer of Add class is passed via QuantizationSpec object, all inputs are quantized.
q_spec = QuantizationSpec()
layer_name = ['conv2d_2', 'add']
q_spec.add(name=layer_name, quantization_index=layer_quantization_index)
q_model = quantize_model(model, quantization_spec=q_spec)
Code to quantize input at specific index (in this case, 1) for layer add could look as follows.
q_spec = QuantizationSpec()
layer_name = ['conv2d_2', 'add']
layer_quantization_index = [None, [1]]
q_spec.add(name=layer_name, quantization_index=layer_quantization_index)
q_model = quantize_model(model, quantization_spec=q_spec)
Layer name can be found from the putput of model.summary() function for Functional and Sequetial models.
For subclassed model, use KerasModelTravller class from tensorflow_quantization.utils.
Refer Python API documentation for more details.
#
# SPDX-FileCopyrightText: Copyright (c) 1993-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
# SPDX-License-Identifier: Apache-2.0
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
import tensorflow as tf
from tensorflow_quantization import quantize_model, QuantizationSpec
from tensorflow_quantization.custom_qdq_cases import ResNetV1QDQCase
import tiny_resnet
import os
from tensorflow_quantization import utils
tf.keras.backend.clear_session()
# Create folders to save TF and ONNX models
assets = utils.CreateAssetsFolders(os.path.join(os.getcwd(), "tutorials"))
assets.add_folder("simple_network_quantize_partial")
# Load CIFAR10 dataset
cifar10 = tf.keras.datasets.cifar10
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
# Normalize the input image so that each pixel value is between 0 and 1.
train_images = train_images / 255.0
test_images = test_images / 255.0
nn_model_original = tiny_resnet.model()
tf.keras.utils.plot_model(nn_model_original, to_file = assets.simple_network_quantize_partial.fp32 + "/model.png")
# Train original classification model
nn_model_original.compile(
optimizer=tiny_resnet.optimizer(lr=1e-4),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"],
)
nn_model_original.fit(
train_images, train_labels, batch_size=32, epochs=10, validation_split=0.1
)
# Get baseline model accuracy
_, baseline_model_accuracy = nn_model_original.evaluate(
test_images, test_labels, verbose=0
)
baseline_model_accuracy = round(100 * baseline_model_accuracy, 2)
print("Baseline FP32 model test accuracy:", baseline_model_accuracy)
Epoch 1/10
1407/1407 [==============================] - 18s 10ms/step - loss: 1.7617 - accuracy: 0.3615 - val_loss: 1.5624 - val_accuracy: 0.4300
Epoch 2/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.4876 - accuracy: 0.4645 - val_loss: 1.4242 - val_accuracy: 0.4762
Epoch 3/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.3737 - accuracy: 0.5092 - val_loss: 1.3406 - val_accuracy: 0.5202
Epoch 4/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.2952 - accuracy: 0.5396 - val_loss: 1.2768 - val_accuracy: 0.5398
Epoch 5/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.2370 - accuracy: 0.5649 - val_loss: 1.2466 - val_accuracy: 0.5560
Epoch 6/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.1857 - accuracy: 0.5812 - val_loss: 1.2052 - val_accuracy: 0.5718
Epoch 7/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.1442 - accuracy: 0.5972 - val_loss: 1.1836 - val_accuracy: 0.5786
Epoch 8/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.1079 - accuracy: 0.6091 - val_loss: 1.1356 - val_accuracy: 0.5978
Epoch 9/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.0702 - accuracy: 0.6220 - val_loss: 1.1244 - val_accuracy: 0.5940
Epoch 10/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.0354 - accuracy: 0.6368 - val_loss: 1.1019 - val_accuracy: 0.6108
Baseline FP32 model test accuracy: 61.46
# save TF FP32 original model
tf.keras.models.save_model(nn_model_original, assets.simple_network_quantize_partial.fp32_saved_model)
# Convert FP32 model to ONNX
utils.convert_saved_model_to_onnx(saved_model_dir = assets.simple_network_quantize_partial.fp32_saved_model, onnx_model_path = assets.simple_network_quantize_partial.fp32_onnx_model)
INFO:tensorflow:Assets written to: /home/sagar/nvidia/2021/Customers/Waymo/QAT/tensorrt_qat/docs/source/notebooks/tutorials/simple_network_quantize_partial/fp32/saved_model/assets
WARNING:tensorflow:From /home/sagar/miniconda3/lib/python3.8/site-packages/tf2onnx/tf_loader.py:711: extract_sub_graph (from tensorflow.python.framework.graph_util_impl) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.compat.v1.graph_util.extract_sub_graph`
ONNX conversion Done!
# Quantize model
# 1.1 Create a dictionary to quantize only two layers named 'conv2d_2' and 'dense'
qspec = QuantizationSpec()
layer_name = ['conv2d_2', 'dense']
qspec.add(name=layer_name)
# 1.2 Call quantize model function
q_nn_model = quantize_model(
model=nn_model_original, quantization_mode="partial", quantization_spec=qspec)
q_nn_model.compile(
optimizer=tiny_resnet.optimizer(lr=1e-4),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"],
)
[I] Layer `conv2d` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `re_lu` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `conv2d_1` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `re_lu_1` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `re_lu_2` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `conv2d_3` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `re_lu_3` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `conv2d_4` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `re_lu_4` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `conv2d_5` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `conv2d_6` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `re_lu_5` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `flatten` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `re_lu_6` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
[I] Layer `dense_1` is not quantized. Partial quantization is enabled and layer name is not in user provided QuantizationSpec class object
tf.keras.utils.plot_model(q_nn_model, to_file = assets.simple_network_quantize_partial.int8 + "/model.png")
_, q_model_accuracy = q_nn_model.evaluate(test_images, test_labels, verbose=0)
q_model_accuracy = round(100 * q_model_accuracy, 2)
print(
"Test accuracy immediately after quantization:{}, diff:{}".format(
q_model_accuracy, (baseline_model_accuracy - q_model_accuracy)
)
)
Test accuracy immediately after quantization:58.96, diff:2.5
# Fine-tune quantized model
fine_tune_epochs = 2
q_nn_model.fit(
train_images,
train_labels,
batch_size=32,
epochs=fine_tune_epochs,
validation_split=0.1,
)
_, q_model_accuracy = q_nn_model.evaluate(test_images, test_labels, verbose=0)
q_model_accuracy = round(100 * q_model_accuracy, 2)
print(
"Accuracy after fine tuning for {} epochs :{}".format(
fine_tune_epochs, q_model_accuracy
)
)
Epoch 1/2
1407/1407 [==============================] - 20s 14ms/step - loss: 1.0074 - accuracy: 0.6480 - val_loss: 1.0854 - val_accuracy: 0.6194
Epoch 2/2
1407/1407 [==============================] - 19s 14ms/step - loss: 0.9799 - accuracy: 0.6583 - val_loss: 1.0782 - val_accuracy: 0.6242
Accuracy after fine tuning for 2 epochs :62.0
# Save TF INT8 original model
tf.keras.models.save_model(q_nn_model, assets.simple_network_quantize_partial.int8_saved_model)
# Convert INT8 model to ONNX
utils.convert_saved_model_to_onnx(saved_model_dir = assets.simple_network_quantize_partial.int8_saved_model, onnx_model_path = assets.simple_network_quantize_partial.int8_onnx_model)
tf.keras.backend.clear_session()
WARNING:absl:Found untraced functions such as conv2d_2_layer_call_fn, conv2d_2_layer_call_and_return_conditional_losses, dense_layer_call_fn, dense_layer_call_and_return_conditional_losses while saving (showing 4 of 4). These functions will not be directly callable after loading.
INFO:tensorflow:Assets written to: /home/sagar/nvidia/2021/Customers/Waymo/QAT/tensorrt_qat/docs/source/notebooks/tutorials/simple_network_quantize_partial/int8/saved_model/assets
INFO:tensorflow:Assets written to: /home/sagar/nvidia/2021/Customers/Waymo/QAT/tensorrt_qat/docs/source/notebooks/tutorials/simple_network_quantize_partial/int8/saved_model/assets
ONNX conversion Done!
Note
ONNX files can be visualized with Netron.
Partial Network Quantization: Specific Layer Class
Goal
Take a resnet-like model and train on cifar10 dataset.
Quantize only 'Dense' layer class.
Fine-tune to recover model accuracy.
Save both original and quantized model while performing ONNX conversion.
Background
Specific layer classes to quantize are passed to quantize_model() via a QuantizationSpec object. For layer l, the class name can be found using l.__class__.__name__. </br>
Refer to the Python API documentation for more details.
#
# SPDX-FileCopyrightText: Copyright (c) 1993-2024 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
# SPDX-License-Identifier: Apache-2.0
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
import tensorflow as tf
from tensorflow_quantization import quantize_model, QuantizationSpec
import tiny_resnet
from tensorflow_quantization import utils
import os
tf.keras.backend.clear_session()
# Create folders to save TF and ONNX models
assets = utils.CreateAssetsFolders(os.path.join(os.getcwd(), "tutorials"))
assets.add_folder("simple_network_quantize_specific_class")
# Load CIFAR10 dataset
cifar10 = tf.keras.datasets.cifar10
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
# Normalize the input image so that each pixel value is between 0 and 1.
train_images = train_images / 255.0
test_images = test_images / 255.0
nn_model_original = tiny_resnet.model()
tf.keras.utils.plot_model(nn_model_original, to_file = assets.simple_network_quantize_specific_class.fp32 + "/model.png")
# Train original classification model
nn_model_original.compile(
optimizer=tiny_resnet.optimizer(lr=1e-4),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"],
)
_ = nn_model_original.fit(
train_images, train_labels, batch_size=32, epochs=10, validation_split=0.1
)
Epoch 1/10
1407/1407 [==============================] - 17s 10ms/step - loss: 1.7871 - accuracy: 0.3526 - val_loss: 1.5601 - val_accuracy: 0.4448
Epoch 2/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.4970 - accuracy: 0.4641 - val_loss: 1.4441 - val_accuracy: 0.4812
Epoch 3/10
1407/1407 [==============================] - 13s 9ms/step - loss: 1.3885 - accuracy: 0.5040 - val_loss: 1.3627 - val_accuracy: 0.5178
Epoch 4/10
1407/1407 [==============================] - 13s 10ms/step - loss: 1.3101 - accuracy: 0.5347 - val_loss: 1.3018 - val_accuracy: 0.5332
Epoch 5/10
1407/1407 [==============================] - 13s 9ms/step - loss: 1.2473 - accuracy: 0.5591 - val_loss: 1.2233 - val_accuracy: 0.5650
Epoch 6/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.1926 - accuracy: 0.5796 - val_loss: 1.2065 - val_accuracy: 0.5818
Epoch 7/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.1475 - accuracy: 0.5972 - val_loss: 1.1449 - val_accuracy: 0.5966
Epoch 8/10
1407/1407 [==============================] - 13s 10ms/step - loss: 1.1041 - accuracy: 0.6126 - val_loss: 1.1292 - val_accuracy: 0.6048
Epoch 9/10
1407/1407 [==============================] - 14s 10ms/step - loss: 1.0636 - accuracy: 0.6275 - val_loss: 1.1122 - val_accuracy: 0.6112
Epoch 10/10
1407/1407 [==============================] - 13s 10ms/step - loss: 1.0268 - accuracy: 0.6406 - val_loss: 1.0829 - val_accuracy: 0.6244
# Get baseline model accuracy
_, baseline_model_accuracy = nn_model_original.evaluate(
test_images, test_labels, verbose=0
)
baseline_model_accuracy = round(100 * baseline_model_accuracy, 2)
print("Baseline FP32 model test accuracy:", baseline_model_accuracy)
Baseline FP32 model test accuracy: 61.51
# Save TF FP32 original model
tf.keras.models.save_model(nn_model_original, assets.simple_network_quantize_specific_class.fp32_saved_model)
# Convert FP32 model to ONNX
utils.convert_saved_model_to_onnx(saved_model_dir = assets.simple_network_quantize_specific_class.fp32_saved_model, onnx_model_path = assets.simple_network_quantize_specific_class.fp32_onnx_model)
INFO:tensorflow:Assets written to: /home/sagar/nvidia/2021/Customers/Waymo/QAT/tensorrt_qat/docs/source/notebooks/tutorial_onnx_models/simple_network_quantize_specific_class/fp32/saved_model/assets
WARNING:tensorflow:From /home/sagar/miniconda3/lib/python3.8/site-packages/tf2onnx/tf_loader.py:711: extract_sub_graph (from tensorflow.python.framework.graph_util_impl) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.compat.v1.graph_util.extract_sub_graph`
ONNX conversion Done!
# Quantize model
# 1.1 Create a list with keras layer classes to quantize
qspec = QuantizationSpec()
qspec.add(name="Dense", is_keras_class=True)
# 1.2 Call quantize model function
q_nn_model = quantize_model(model=nn_model_original, quantization_mode='partial', quantization_spec=qspec)
q_nn_model.compile(
optimizer=tiny_resnet.optimizer(lr=1e-4),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=["accuracy"],
)
[I] Layer class `Conv2D` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `ReLU` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `Conv2D` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `ReLU` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `Conv2D` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `ReLU` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `Conv2D` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `Add` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `ReLU` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `Conv2D` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `ReLU` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `Conv2D` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `Conv2D` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `Add` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `ReLU` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `MaxPooling2D` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `Flatten` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
[I] Layer class `ReLU` is not quantized. Partial quantization is enabled and layer class is not in user provided QuantizationSpec class object
_, q_model_accuracy = q_nn_model.evaluate(test_images, test_labels, verbose=0)
q_model_accuracy = round(100 * q_model_accuracy, 2)
print(
"Test accuracy immediately after quantization:{}, diff:{}".format(
q_model_accuracy, (baseline_model_accuracy - q_model_accuracy)
)
)
Test accuracy immediately after quantization:60.28, diff:1.2299999999999969
tf.keras.utils.plot_model(q_nn_model, to_file = assets.simple_network_quantize_specific_class.int8 + "/model.png")
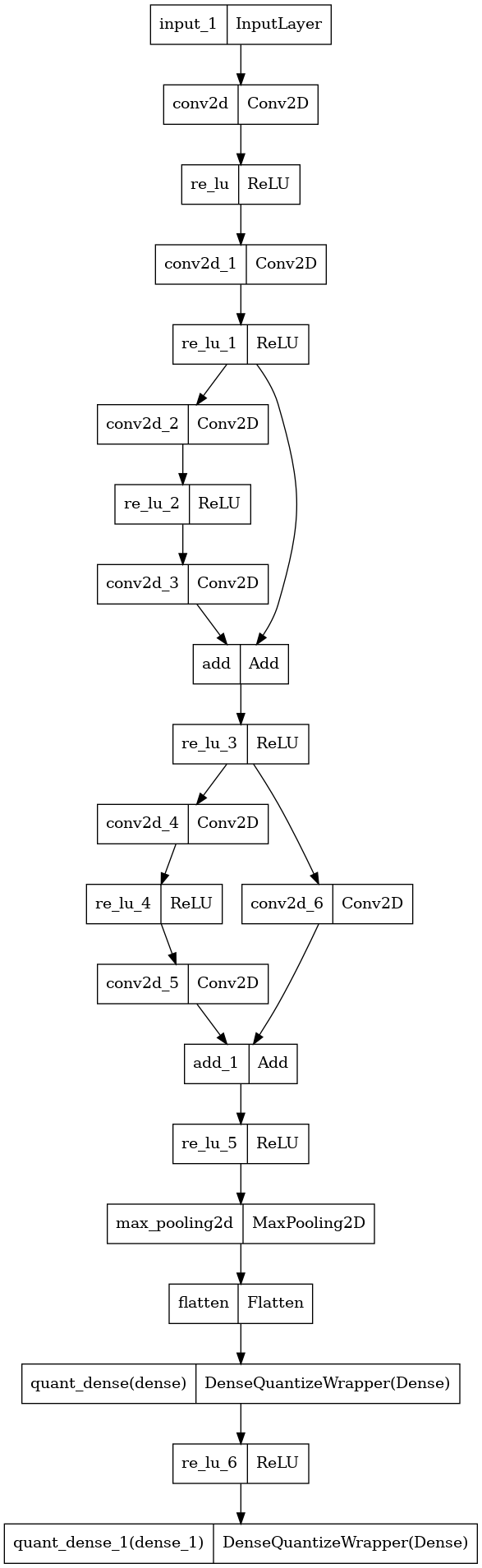
# Fine-tune quantized model
fine_tune_epochs = 2
q_nn_model.fit(
train_images,
train_labels,
batch_size=32,
epochs=fine_tune_epochs,
validation_split=0.1,
)
_, q_model_accuracy = q_nn_model.evaluate(test_images, test_labels, verbose=0)
q_model_accuracy = round(100 * q_model_accuracy, 2)
print(
"Accuracy after fine tuning for {} epochs :{}".format(
fine_tune_epochs, q_model_accuracy
)
)
Epoch 1/2
1407/1407 [==============================] - 18s 13ms/step - loss: 0.9981 - accuracy: 0.6521 - val_loss: 1.0761 - val_accuracy: 0.6324
Epoch 2/2
1407/1407 [==============================] - 18s 13ms/step - loss: 0.9655 - accuracy: 0.6631 - val_loss: 1.0572 - val_accuracy: 0.6302
Accuracy after fine tuning for 2 epochs :61.82
# Save TF INT8 original model
tf.keras.models.save_model(q_nn_model, assets.simple_network_quantize_specific_class.int8_saved_model)
# Convert INT8 model to ONNX
utils.convert_saved_model_to_onnx(saved_model_dir = assets.simple_network_quantize_specific_class.int8_saved_model, onnx_model_path = assets.simple_network_quantize_specific_class.int8_onnx_model)
tf.keras.backend.clear_session()
WARNING:absl:Found untraced functions such as dense_layer_call_fn, dense_layer_call_and_return_conditional_losses, dense_1_layer_call_fn, dense_1_layer_call_and_return_conditional_losses while saving (showing 4 of 4). These functions will not be directly callable after loading.
INFO:tensorflow:Assets written to: /home/sagar/nvidia/2021/Customers/Waymo/QAT/tensorrt_qat/docs/source/notebooks/tutorial_onnx_models/simple_network_quantize_specific_class/int8/saved_model/assets
INFO:tensorflow:Assets written to: /home/sagar/nvidia/2021/Customers/Waymo/QAT/tensorrt_qat/docs/source/notebooks/tutorial_onnx_models/simple_network_quantize_specific_class/int8/saved_model/assets
ONNX conversion Done!
Note
ONNX files can be visualized with Netron.
ResNet50 V1
This assumes that our toolkits and its base requirements have been met, including access to the ImageNet dataset. Please refer to “Requirements” in the examples folder.
1. Initial settings
import os
import tensorflow as tf
from tensorflow_quantization.quantize import quantize_model
from tensorflow_quantization.custom_qdq_cases import ResNetV1QDQCase
from tensorflow_quantization.utils import convert_saved_model_to_onnx
HYPERPARAMS = {
"tfrecord_data_dir": "/media/Data/ImageNet/train-val-tfrecord",
"batch_size": 64,
"epochs": 2,
"steps_per_epoch": 500,
"train_data_size": None,
"val_data_size": None,
"save_root_dir": "./weights/resnet_50v1_jupyter"
}
Load data
from examples.data.data_loader import load_data
train_batches, val_batches = load_data(HYPERPARAMS, model_name="resnet_v1")
2. Baseline model
Instantiate
model = tf.keras.applications.ResNet50(
include_top=True,
weights="imagenet",
classes=1000,
classifier_activation="softmax",
)
Evaluate
def compile_model(model, lr=0.001):
model.compile(
optimizer=tf.keras.optimizers.SGD(learning_rate=lr),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=["accuracy"],
)
compile_model(model)
_, baseline_model_accuracy = model.evaluate(val_batches)
print("Baseline val accuracy: {:.3f}%".format(baseline_model_accuracy*100))
781/781 [==============================] - 41s 51ms/step - loss: 1.0481 - accuracy: 0.7504
Baseline val accuracy: 75.044%
Save and convert to ONNX
model_save_path = os.path.join(HYPERPARAMS["save_root_dir"], "saved_model_baseline")
model.save(model_save_path)
convert_saved_model_to_onnx(saved_model_dir=model_save_path,
onnx_model_path=model_save_path + ".onnx")
INFO:tensorflow:Assets written to: ./weights/resnet_50v1_jupyter/saved_model_baseline/assets
ONNX conversion Done!
3. Quantization-Aware Training model
Quantize
q_model = quantize_model(model, custom_qdq_cases=[ResNetV1QDQCase()])
Fine-tune
compile_model(q_model)
q_model.fit(
train_batches,
validation_data=val_batches,
batch_size=HYPERPARAMS["batch_size"],
steps_per_epoch=HYPERPARAMS["steps_per_epoch"],
epochs=HYPERPARAMS["epochs"]
)
Epoch 1/2
500/500 [==============================] - 425s 838ms/step - loss: 0.4075 - accuracy: 0.8898 - val_loss: 1.0451 - val_accuracy: 0.7497
Epoch 2/2
500/500 [==============================] - 420s 840ms/step - loss: 0.3960 - accuracy: 0.8918 - val_loss: 1.0392 - val_accuracy: 0.7511
<keras.callbacks.History at 0x7f9cec1e60d0>
Evaluate
_, qat_model_accuracy = q_model.evaluate(val_batches)
print("QAT val accuracy: {:.3f}%".format(qat_model_accuracy*100))
781/781 [==============================] - 179s 229ms/step - loss: 1.0392 - accuracy: 0.7511
QAT val accuracy: 75.114%
Save and convert to ONNX
q_model_save_path = os.path.join(HYPERPARAMS["save_root_dir"], "saved_model_qat")
q_model.save(q_model_save_path)
convert_saved_model_to_onnx(saved_model_dir=q_model_save_path,
onnx_model_path=q_model_save_path + ".onnx")
WARNING:absl:Found untraced functions such as conv1_conv_layer_call_fn, conv1_conv_layer_call_and_return_conditional_losses, conv2_block1_1_conv_layer_call_fn, conv2_block1_1_conv_layer_call_and_return_conditional_losses, conv2_block1_2_conv_layer_call_fn while saving (showing 5 of 140). These functions will not be directly callable after loading.
INFO:tensorflow:Assets written to: ./weights/resnet_50v1_jupyter/saved_model_qat/assets
INFO:tensorflow:Assets written to: ./weights/resnet_50v1_jupyter/saved_model_qat/assets
ONNX conversion Done!
4. QAT vs Baseline comparison
print("Baseline vs QAT: {:.3f}% vs {:.3f}%".format(baseline_model_accuracy*100, qat_model_accuracy*100))
acc_diff = (qat_model_accuracy - baseline_model_accuracy)*100
acc_diff_sign = "" if acc_diff == 0 else ("-" if acc_diff < 0 else "+")
print("Accuracy difference of {}{:.3f}%".format(acc_diff_sign, abs(acc_diff)))
Baseline vs QAT: 75.044% vs 75.114%
Accuracy difference of +0.070%
Note
For full workflow, including TensorRT™ deployment, please refer to examples/resnet.
Model Zoo Results
Results obtained on NVIDIA’s A100 GPU and TensorRT 8.4.
ResNet
ResNet50-v1
Model |
Accuracy (%) |
Latency (ms, bs=1) |
|---|---|---|
Baseline (TensorFlow) |
75.05 |
7.95 |
PTQ (TensorRT) |
74.96 |
0.46 |
QAT (TensorRT) |
75.12 |
0.45 |
ResNet50-v2
Model |
Accuracy (%) |
Latency (ms, bs=1) |
|---|---|---|
Baseline (TensorFlow) |
75.36 |
6.16 |
PTQ (TensorRT) |
75.48 |
0.57 |
QAT (TensorRT) |
75.65 |
0.57 |
ResNet101-v1
Model |
Accuracy (%) |
Latency (ms, bs=1) |
|---|---|---|
Baseline (TensorFlow) |
76.47 |
15.92 |
PTQ (TensorRT) |
76.32 |
0.84 |
QAT (TensorRT) |
76.26 |
0.84 |
ResNet101-v2
Model |
Accuracy (%) |
Latency (ms, bs=1) |
|---|---|---|
Baseline (TensorFlow) |
76.89 |
14.13 |
PTQ (TensorRT) |
76.94 |
1.05 |
QAT (TensorRT) |
77.15 |
1.05 |
QAT fine-tuning hyper-parameters: bs=32 (bs=64 was OOM).
MobileNet
MobileNet-v1
Model |
Accuracy (%) |
Latency (ms, bs=1) |
|---|---|---|
Baseline (TensorFlow) |
70.60 |
1.99 |
PTQ (TensorRT) |
69.31 |
0.16 |
QAT (TensorRT) |
70.43 |
0.16 |
MobileNet-v2
Model |
Accuracy (%) |
Latency (ms, bs=1) |
|---|---|---|
Baseline (TensorFlow) |
71.77 |
3.71 |
PTQ (TensorRT) |
70.87 |
0.30 |
QAT (TensorRT) |
71.62 |
0.30 |
EfficientNet
EfficientNet-B0
Model |
Accuracy (%) |
Latency (ms, bs=1) |
|---|---|---|
Baseline (TensorFlow) |
76.97 |
6.77 |
PTQ (TensorRT) |
71.71 |
0.67 |
QAT (TensorRT) |
75.82 |
0.68 |
QAT fine-tuning hyper-parameters: bs=64, ep=10, lr=0.001, steps_per_epoch=None.
EfficientNet-B3
Model |
Accuracy (%) |
Latency (ms, bs=1) |
|---|---|---|
Baseline (TensorFlow) |
81.36 |
10.33 |
PTQ (TensorRT) |
78.88 |
1.24 |
QAT (TensorRT) |
79.48 |
1.23 |
QAT fine-tuning hyper-parameters: bs=32, ep20, lr=0.0001, steps_per_epoch=None.
Inception
Inception-v3
Model |
Accuracy (%) |
Latency (ms, bs=1) |
|---|---|---|
Baseline (TensorFlow) |
77.86 |
9.01 |
PTQ (TensorRT) |
77.73 |
0.82 |
QAT (TensorRT) |
78.08 |
0.82 |
Note
The results here were obtained with NVIDIA's A100 GPU and TensorRT 8.4.
Accuracy metric: Top-1 validation accuracy with the full ImageNet dataset.
Hyper-parameters
QAT fine-tuning: bs=64, ep=10, lr=0.001 (unless otherwise stated).
PTQ calibration: bs=64.
Add New Layer Support
This toolkit uses a TensorFlow Keras wrapper layer to insert QDQ nodes before quantizable layers.
Supported Layers
The following matrix shows the layers supported by this toolkit and their default behavior:
Layer |
Quantize Input |
Quantize Weight |
Quantization Indices |
|---|---|---|---|
tf.keras.layers.Conv2D |
True |
True |
- |
tf.keras.layers.Dense |
True |
True |
- |
tf.keras.layers.DepthwiseConv2D |
True |
True |
- |
tf.keras.layers.AveragePooling2D |
True |
- |
- |
tf.keras.layers.GlobalAveragePooling2D |
True |
- |
- |
tf.keras.layers.MaxPooling2D |
False* |
- |
- |
tf.keras.layers.BatchNormalization |
False* |
- |
- |
tf.keras.layers.Concatenate |
False* |
- |
None* |
tf.keras.layers.Add |
False* |
- |
None* |
tf.keras.layers.Multiply |
False* |
- |
None* |
Note
*Inputs are not quantized by default. However, quantization is possible by passing those layers as QuantizationSpec to quantize_model(). Alternatively, fine-grained control over the layer’s behavior can also be achieved by implementing a Custom QDQ Insertion Case.
Note that the set of layers to be quantized can be network dependent. For example, MaxPool layers need not be quantized in ResNet-v1, but ResNet-v2 requires them to be quantized due to their location in residual connections. This toolkit, thus, offers flexibility to quantize any layer as needed.
How are wrappers developed?
BaseQuantizeWrapper is a core quantization class which is inherited from tf.keras.layers.Wrapper keras wrapper class as shown in Figure 1 below.
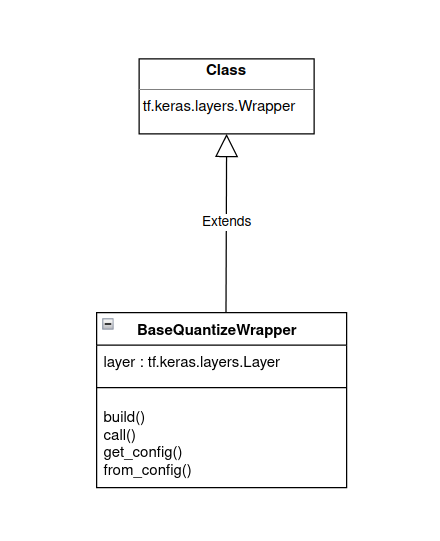
Figure 1. BaseQuantizeWrapper inheritance.
All quantization wrappers are derived from BaseQuantizeWrapper class. Each wrapper takes layer(tf.keras.layers.Layer) as an argument which is handled by the toolkit internally. To simplify the development process, layers are classified as weighted, non-weighted, or other type.
Weighted Layers
Weighted layers are inherited from WeightedBaseQuantizeWrapper class which itself is inherited from BaseQuantizeWrapper, as shown in Figure 2 below. layer argument to WeightedBaseQuantizeWrapper class is handled by the library, however, kernel_type argument must be selected while developing wrapper. kernel_type for weighted layer gives access to layer weights.
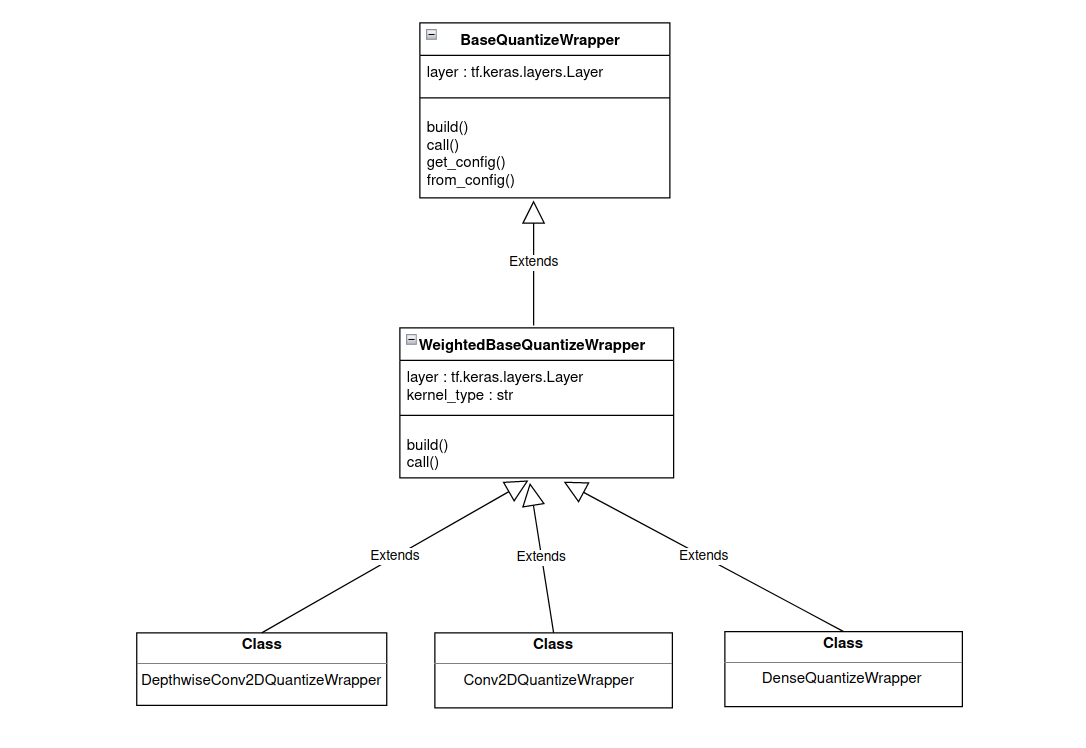
Figure 2. Inheritance flow for weighted layers.
Non-weighted Layers
Weighted layers are inherited from WeightedBaseQuantizeWrapper class which itself is inherited from BaseQuantizeWrapper as shown in Figure 3 below. layer argument to WeightedBaseQuantizeWrapper class is handled by the library.
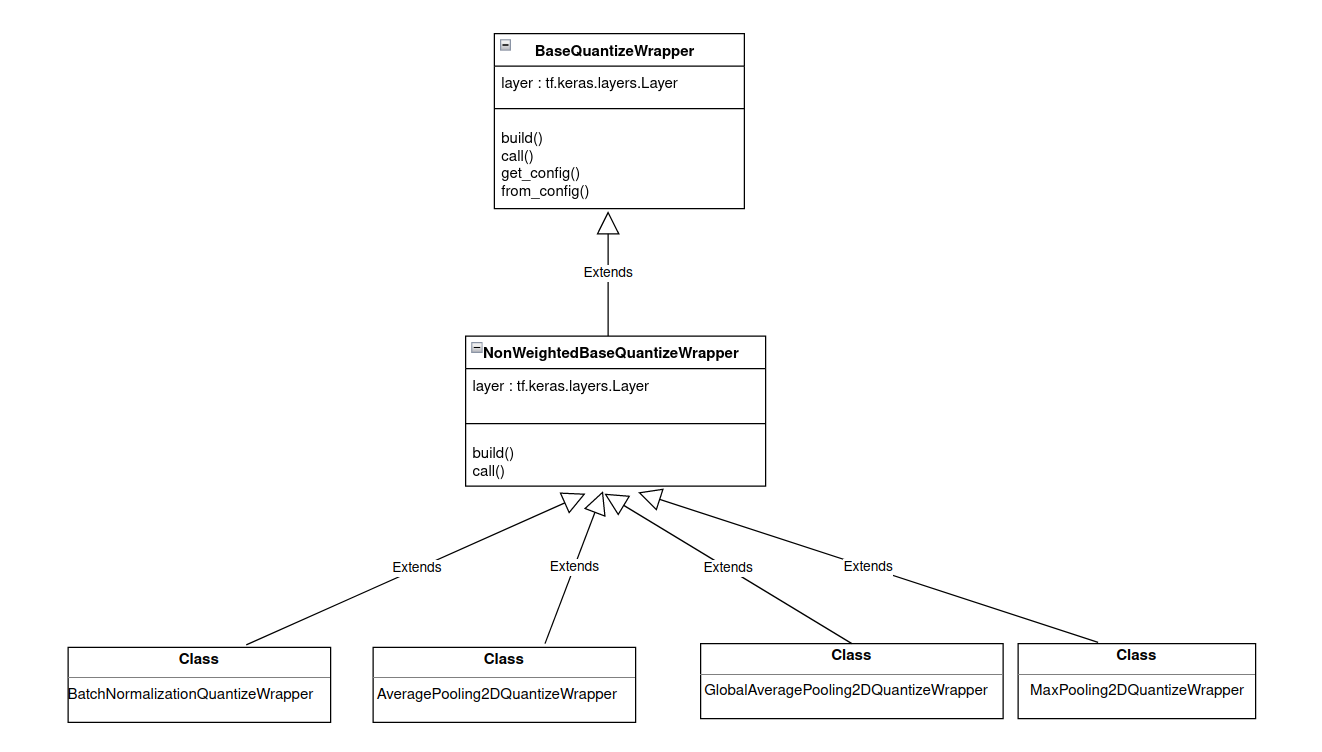
Figure 3. Inheritance flow for non-weighted layers.
Other Layers
Other layers are inherited from BaseQuantizeWrapper directly, as shown in Figure 4 below.
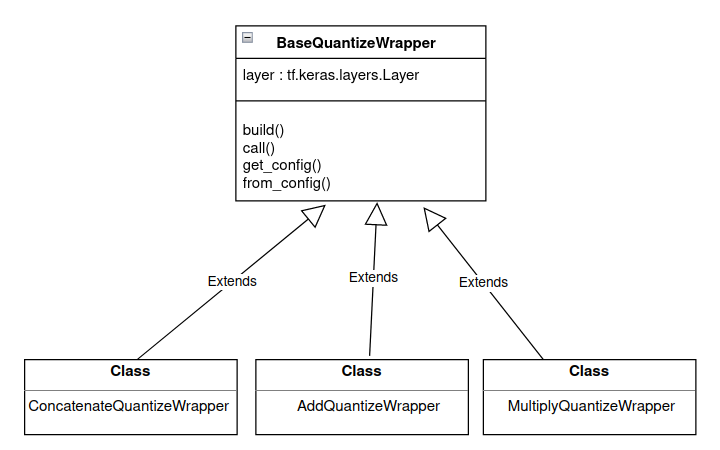
Figure 4. Inheritance flow for other layers.
How to add a new wrapper?
Study current wrappers from
tensorflow_quantization/quantize_wrappers.pyscript.Create a new class by inheriting one of
BaseQuantizeWrapper,WeightedBaseQuantizeWrapperorNonWeightedBaseQuantizeWrapperclasses based on new layer type.Update
buildandcallmethods based upon layer behavior.
Attention
New class will automatically get registered only if toolkit naming conventions are followed. For a keras layer l, class name must be <l.__class__.__name__>QuantizeWrapper.
Example
Let’s see how support for a new Keras layer GlobalMaxPool2D can be added.
This is a non-weighted layer thus we will inherit NonWeightedBaseQuantizeWrapper.
Following toolkit naming conventions, this new wrapper should be named GlobalMaxPool2DQuantizeWrapper.
from tensorflow_quantization import NonWeightedBaseQuantizeWrapper
class GlobalMaxPool2DQuantizeWrapper(NonWeightedBaseQuantizeWrapper):
def __init__(self, layer, **kwargs):
"""
Creates a wrapper to emulate quantization for the GlobalMaxPool2D keras layer.
Args:
layer: The keras layer to be quantized.
**kwargs: Additional keyword arguments to be passed to the keras layer.
"""
super().__init__(layer, **kwargs)
def build(self, input_shape):
super().build(input_shape)
def call(self, inputs, training=None):
return super().call(inputs, training=training)
This new wrapper class is the same as the existing GlobalAveragePooling2D, AveragePooling2D, and MaxPool2D wrapper classes found in tensorflow_quantization/quantize_wrappers.py.
Attention
New Class registration is based on tracking child classes of BaseQuantizeWrapper parent class. Thus, new class won't get registered unless explicitly called (this is current restriction).
To make sure new wrapper class is registered,
If new wrapper class is defined in a separate module, import it in the module where
quantize_modelfunction is called.If new wrapper class if defined in the same module as
quantize_modelfunction, create object of this new class. You don't have to pass that object anywhere.
Add Custom QDQ Insertion Case
This toolkit’s default quantization behavior for each supported layer is displayed in the Add New Layer Support section.
For the most part, it quantizes (adds Q/DQ nodes to) all inputs and weights (if the layer is weighted) of supported layers. However, the default behavior might not always lead to optimal INT8 fusions in TensorRT™. For example, Q/DQ nodes need to be added to residual connections in ResNet models. We provide a more in-depth explanation about this case in the “Custom Q/DQ Insertion Case Quantization” section later in this page.
To tackle those scenarios, we added the Custom Q/DQ Insertion Case library feature, which allows users to programmatically decide how a specific layer should be quantized differently in specific situations. Note that providing an object of QuantizationSpec class is a hard coded way of achieving the same goal.
Let’s discuss the library-provided ResNetV1QDQCase to understand how passing custom Q/DQ insertion case objects affect Q/DQ insertion for the Add layer.
Why is this needed?
The main goal of the Custom Q/DQ Insertion feature is to twick the framework’s behavior to meet network-specific quantization requirements. Let’s check this through an example.
Goal: Perform custom quantization on a ResNet-like model. More specifically, we aim to quantize a model’s residual connections.
We show three quantization scenarios: 1) default, 2) custom with QuantizationSpec (suboptimal), and 3) custom with Custom Q/DQ Insertion Case (optimal).
Default Quantization
Note
Refer to Full Default Quantization mode.
The default quantization of the model is done with the following code snippet:
# Quantize model
q_nn_model = quantize_model(model=nn_model_original)
Figure 1, below, shows the baseline ResNet residual block and its corresponding quantized block with the default quantization scheme.
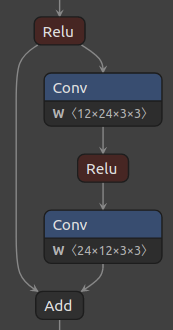
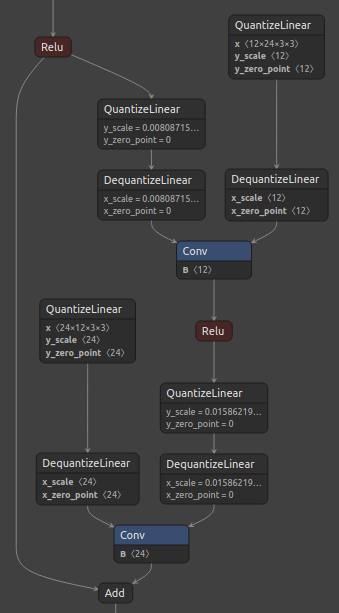
Figure 1. ResNet residual block (left), and default quantized block (right).
Notice that the default quantization behavior is to not add Q/DQ nodes before Add layers. Since AddQuantizeWrapper
is already implemented in the toolkit, and just disabled by default, the simplest way to quantize that layer would be
to enable quantization of layers of class type Add.
Custom Quantization with ‘QuantizationSpec’ (suboptimal)
Note
Refer to Full Custom Quantization mode.
The following code snippet enables quantization of all layers of class type Add:
# 1. Enable `Add` layer quantization
qspec = QuantizationSpec()
qspec.add(name='Add', is_keras_class=True)
# 2. Quantize model
q_nn_model = quantize_model(
model=nn_model_original, quantization_spec=qspec
)
Figure 2, below, shows the standard ResNet residual block and its corresponding quantized block with the suggested custom quantization.
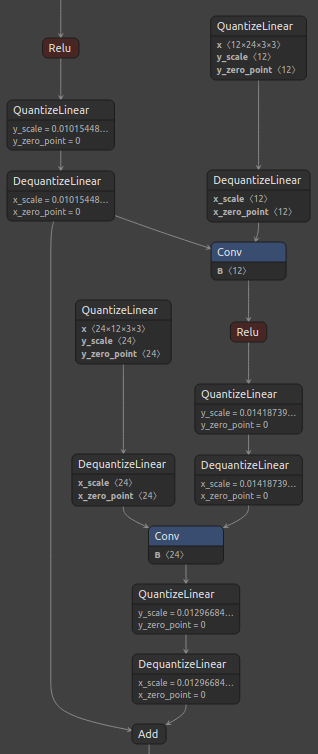
Figure 2. ResNet residual block (left), and Q/DQ node insertion for Add layer passed via QuantizationSpec (right).
Notice that all inputs of the Add layer were quantized. However, that still does not enable optimal layer fusions in TensorRT™, where a Convolution layer followed by an ElementWise layer (such as Add) can be fused into a single Convolution kernel.
The recommendation, in this case, is to add Q/DQ nodes in the residual connection only (not between Add and Conv).
Custom Quantization with ‘Custom Q/DQ Insertion Case’ (optimal)
Note
Refer to Full Custom Quantization mode.
The library-provided ResNetV1QDQCase class solves this issue by programming Add layer class to skip Q/DQ in one path if that path connects to Conv.
This time, we pass an object of ResNetV1QDQCase class to the quantize_model function:
# 1. Indicate one or more custom QDQ cases
custom_qdq_case = ResNetV1QDQCase()
# 3. Quantize model
q_nn_model = quantize_model(
model=nn_model_original, custom_qdq_cases=[custom_qdq_case]
)
Figure 3, below, shows the standard ResNet residual block and its corresponding quantized block with the suggested custom quantization.
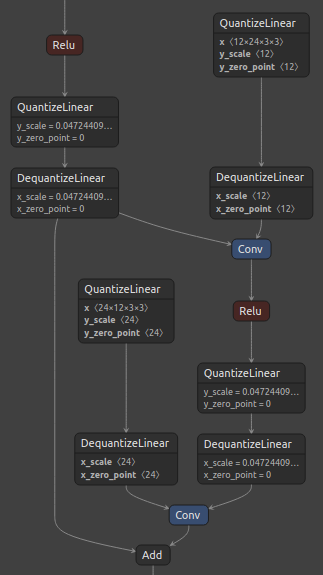
Figure 3. ResNet residual block (left), and Q/DQ node insertion for Add layer passed via ResNetV1QDQCase (right).
Notice that Q/DQ nodes are not added to the path coming from Conv layer. Additionally, since both outputs of the first Relu layer were quantized, it was possible to perform a horizontal fusion with them, resulting in only one pair of Q/DQ nodes at that location.
This quantization approach leads to an optimal graph for TensorRT INT8 fusions.
Library provided custom Q/DQ insertion cases
We provide custom Q/DQ insertion cases for the models available in the model zoo. The library-provided custom Q/DQ insertion case classes can be imported from tensorflow_quantization.custom_qdq_cases module and passed to the quantize_model function.
Note
Refer to tensorflow_quantization.custom_qdq_cases module for more details.
How to add a new custom Q/DQ insertion case?
Create a new class by inheriting
tensorflow_quantization.CustomQDQInsertionCaseclass.Override two methods:
case(compulsory)
This method has fixed signature as shown below. Library automatically calls
casemethod of all members ofcustom_qdq_casesparameter insidequantize_modelfunction. Logic for changing the default layer behavior should be encoded in this function and an object ofQuantizationSpecclass must be returned.(function)CustomQDQInsertionCase.case( self, keras_model : 'tf.keras.Model', qspec : 'QuantizationSpec' ) -> 'QuantizationSpec'
info(optional)
This is just a helper method explaining the logic inside
casemethod.Add object of this new class to a list and pass it to the
custom_qdq_casesparameter of thequantize_modelfunction.
Attention
If CustomQDQInsertionCase is written, QuantizationSpec object MUST be returned.
Example,
class MaxPoolQDQCase(CustomQDQInsertionCase):
def __init__(self) -> None:
super().__init__()
def info(self) -> str:
return "Enables quantization of MaxPool layers."
def case(
self, keras_model: tf.keras.Model, qspec: QuantizationSpec
) -> QuantizationSpec:
mp_qspec = QuantizationSpec()
for layer in keras_model.layers:
if isinstance(layer, tf.keras.layers.MaxPooling2D):
if check_is_quantizable_by_layer_name(qspec, layer.name):
mp_qspec.add(
name=layer.name,
quantize_input=True,
quantize_weight=False
)
return mp_qspec
As shown in the above MaxPool custom Q/DQ case class, the case method needs to be overridden. The optional info method returns a short description string.
The logic written in the case method might or might not use the user-provided QuantizationSpec object, but it MUST return a new QuantizationSpec which holds information on the updated layer behavior. In the MaxPoolQDQCase case above, the custom Q/DQ insertion logic is dependent of the user-provided QuantizationSpec object (check_is_quantizable_by_layer_name checks if the layer name is in the user-provided object and gives priority to that specification).
tensorflow_quantization
- tensorflow_quantization.G_NUM_BITS
8 bit quantization is used by default. However, it can be changed by using
G_NUM_BITSglobal variable. The following code snippet performs 4 bit quantization.import tensorflow_quantization # get pretrained model ..... # perform 4 bit quantization tensorflow_quantization.G_NUM_BITS = 4 q_model = quantize_model(nn_model_original) # fine-tune model .....
Check
test_end_to_end_workflow_4bit()test case fromquantize_test.pytest module.- tensorflow_quantization.G_NARROW_RANGE
If True, the absolute value of quantized minimum is the same as the quantized maximum value. For example, minimum of -127 is used for 8 bit quantization instead of -128. TensorRT ™ only supports G_NARROW_RANGE=True.
- tensorflow_quantization.G_SYMMETRIC
If True, 0.0 is always in the center of real min, max i.e. zero point is always 0. TensorRT ™ only supports G_SYMMETRIC=True.
Attention
When used, set global variables immediately before the quantize_model function call.
tensorflow_quantization.quantize_model
Note
Currently only Functional and Sequential models are supported.
Examples
import tensorflow as tf
from tensorflow_quantization.quantize import quantize_model
# Simple full model quantization.
# 1. Create a simple network
input_img = tf.keras.layers.Input(shape=(28, 28))
r = tf.keras.layers.Reshape(target_shape=(28, 28, 1))(input_img)
x = tf.keras.layers.Conv2D(filters=2, kernel_size=(3, 3))(r)
x = tf.keras.layers.ReLU()(x)
x = tf.keras.layers.Conv2D(filters=2, kernel_size=(3, 3))(x)
x = tf.keras.layers.ReLU()(x)
x = tf.keras.layers.Flatten()(x)
model = tf.keras.Model(input_img, x)
print(model.summary())
# 2. Quantize the network
q_model = quantize_model(model)
print(q_model.summary())
tensorflow_quantization.QuantizationSpec
Examples
Let's write a simple network to use in all examples.
import tensorflow as tf
# Import necessary methods from the Quantization Toolkit
from tensorflow_quantization.quantize import quantize_model, QuantizationSpec
# 1. Create a small network
input_img = tf.keras.layers.Input(shape=(28, 28))
x = tf.keras.layers.Reshape(target_shape=(28, 28, 1))(input_img)
x = tf.keras.layers.Conv2D(filters=126, kernel_size=(3, 3))(x)
x = tf.keras.layers.ReLU()(x)
x = tf.keras.layers.Conv2D(filters=64, kernel_size=(3, 3))(x)
x = tf.keras.layers.ReLU()(x)
x = tf.keras.layers.Conv2D(filters=32, kernel_size=(3, 3))(x)
x = tf.keras.layers.ReLU()(x)
x = tf.keras.layers.Conv2D(filters=16, kernel_size=(3, 3))(x)
x = tf.keras.layers.ReLU()(x)
x = tf.keras.layers.Conv2D(filters=8, kernel_size=(3, 3))(x)
x = tf.keras.layers.ReLU()(x)
x = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(100)(x)
x = tf.keras.layers.ReLU()(x)
x = tf.keras.layers.Dense(10)(x)
model = tf.keras.Model(input_img, x)
Select layers based on layer names
Goal: Quantize the 2nd Conv2D, 4th Conv2D and 1st Dense layer in the following network.
# 1. Find out layer names print(model.summary()) # 2. Create quantization spec and add layer names q_spec = QuantizationSpec() layer_name = ['conv2d_1', 'conv2d_3', 'dense'] """ # Alternatively, each layer configuration can be added one at a time: q_spec.add('conv2d_1') q_spec.add('conv2d_3') q_spec.add('dense') """ q_spec.add(name=layer_name) # 3. Quantize model q_model = quantize_model(model, quantization_mode='partial', quantization_spec=q_spec) print(q_model.summary()) tf.keras.backend.clear_session()
Select layers based on layer class
Goal: Quantize all Conv2D layers.
# 1. Create QuantizationSpec object and add layer class q_spec = QuantizationSpec() q_spec.add(name='Conv2D', is_keras_class=True) # 2. Quantize model q_model = quantize_model(model, quantization_mode='partial', quantization_spec=q_spec) q_model.summary() tf.keras.backend.clear_session()
Select layers based both layer name and layer class
Goal: Quantize all Dense layers and the 3rd Conv2D layer.
# 1. Create QuantizationSpec object and add layer information q_spec = QuantizationSpec() layer_name = ['Dense', 'conv2d_2'] layer_is_keras_class = [True, False] """ # Alternatively, each layer configuration can be added one at a time: q_spec.add(name='Dense', is_keras_class=True) q_spec.add(name='conv2d_2') """ q_spec.add(name=layer_name, is_keras_class=layer_is_keras_class) # 2. Quantize model q_model = quantize_model(model, quantization_mode='partial', quantization_spec=q_spec) q_model.summary() tf.keras.backend.clear_session()
Select inputs at specific index for multi-input layers
For layers with multiple inputs, the user can choose which ones need to be quantized. Assume a network that has two layers of class Add.
Goal: Quantize index 1 of add layer, index 0 of add_1 layer and the 3rd Conv2D layer.
# 1. Create QuantizationSpec object and add layer information q_spec = QuantizationSpec() layer_name = ['add', 'add_1', 'conv2d_2'] layer_q_indices = [[1], [0], None] """ # Alternatively, each layer configuration can be added one at a time: q_spec.add(name='add', quantization_index=[1]) q_spec.add(name='add', quantization_index=[0]) q_spec.add(name='conv2d_2') """ q_spec.add(name=layer_name, quantization_index=layer_q_indices) # 2. Quantize model q_model = quantize_model(model, quantization_mode='partial', quantization_spec=q_spec) q_model.summary() tf.keras.backend.clear_session()
Quantize only weight and NOT input
Goal: Quantize the 2nd Conv2D, 4th Conv2D and 1st Dense layer in the following network. In addition to that, quantize only the weights of the 2nd Conv2D.
# 1. Find out layer names print(model.summary()) # 2. Create quantization spec and add layer names q_spec = QuantizationSpec() layer_name = ['conv2d_1', 'conv2d_3', 'dense'] layer_q_input = [False, True, True] """ # Alternatively, each layer configuration can be added one at a time: q_spec.add('conv2d_1', quantize_input=False) q_spec.add('conv2d_3') q_spec.add('dense') """ q_spec.add(name=layer_name, quantize_input=layer_q_input) # 3. Quantize model q_model = quantize_model(model, quantization_mode='partial', quantization_spec=q_spec) print(q_model.summary()) tf.keras.backend.clear_session()
tensorflow_quantization.CustomQDQInsertionCase
Example
class EfficientNetQDQCase(CustomQDQInsertionCase):
def __init__(self) -> None:
super().__init__()
def info(self):
return "In Multiply operation quantize inputs at index 0 and 1."
def case(self, keras_model: 'tf.keras.Model', qspec: 'QuantizationSpec') -> 'QuantizationSpec':
se_block_qspec_object = QuantizationSpec()
for layer in keras_model.layers:
if isinstance(layer, tf.keras.layers.Multiply):
se_block_qspec_object.add(layer.name, quantize_input=True, quantize_weight=False, quantization_index=[0, 1])
return se_block_qspec_object
tensorflow_quantization.BaseQuantizeWrapper
Example
Conv2DTranspose layer is a weighted layer used to perform transformations going in the opposite direction of Convolution.
Note
Conv2DTranspose is a Keras class, thus new wrapper class is Conv2DTransposeQuantizeWrapper. This follows toolkit naming conventions.
from tensorflow.python.util import tf_inspect
from tensorflow_quantization.quantize_wrapper_base import BaseQuantizeWrapper
class Conv2DTransposeQuantizeWrapper(BaseQuantizeWrapper):
def __init__(self, layer, kernel_type="kernel", **kwargs):
"""
Create a quantize emulate wrapper for a keras layer.
This wrapper provides options to quantize inputs, outputs amd weights of a quantizable layer.
Args:
layer: The keras layer to be quantized.
kernel_type: Options=['kernel' for Conv2D/Dense, 'depthwise_kernel' for DepthwiseConv2D]
**kwargs: Additional keyword arguments to be passed to the keras layer.
"""
self.kernel_type = kernel_type
self.channel_axis = kwargs.get("axis", -1)
super(Conv2DTransposeQuantizeWrapper, self).__init__(layer, **kwargs)
def build(self, input_shape):
super(Conv2DTransposeQuantizeWrapper, self).build(input_shape)
self._weight_vars = []
self.input_vars = {}
self.output_vars = {}
self.channel_axis = -1
if self.kernel_type == "depthwise_kernel":
self.channel_axis = 2
# quantize weights only applicable for weighted ops.
# By default weights is per channel quantization
if self.quantize_weights:
# get kernel weights dims.
kernel_weights = getattr(self.layer, self.kernel_type)
min_weight = self.layer.add_weight(
kernel_weights.name.split(":")[0] + "_min",
shape=(kernel_weights.shape[self.channel_axis]),
initializer=tf.keras.initializers.Constant(-6.0),
trainable=False,
)
max_weight = self.layer.add_weight(
kernel_weights.name.split(":")[0] + "_max",
shape=(kernel_weights.shape[self.channel_axis]),
initializer=tf.keras.initializers.Constant(6.0),
trainable=False,
)
quantizer_vars = {"min_var": min_weight, "max_var": max_weight}
self._weight_vars.append((kernel_weights, quantizer_vars))
# Needed to ensure unquantized weights get trained as part of the wrapper.
self._trainable_weights.append(kernel_weights)
# By default input is per tensor quantization
if self.quantize_inputs:
input_min_weight = self.layer.add_weight(
self.layer.name + "_ip_min",
shape=None,
initializer=tf.keras.initializers.Constant(-6.0),
trainable=False,
)
input_max_weight = self.layer.add_weight(
self.layer.name + "_ip_max",
shape=None,
initializer=tf.keras.initializers.Constant(6.0),
trainable=False,
)
self.input_vars["min_var"] = input_min_weight
self.input_vars["max_var"] = input_max_weight
def call(self, inputs, training=None):
if training is None:
training = tf.keras.backend.learning_phase()
# Quantize all weights, and replace them in the underlying layer.
if self.quantize_weights:
quantized_weights = []
quantized_weight = self._last_value_quantizer(
self._weight_vars[0][0],
training,
self._weight_vars[0][1],
per_channel=True,
channel_axis=self.channel_axis
)
quantized_weights.append(quantized_weight)
# Replace the original weights with QDQ weights
setattr(self.layer, self.kernel_type, quantized_weights[0])
# Quantize inputs to the conv layer
if self.quantize_inputs:
quantized_inputs = self._last_value_quantizer(
inputs,
training,
self.input_vars,
per_channel=False)
else:
quantized_inputs = inputs
args = tf_inspect.getfullargspec(self.layer.call).args
if "training" in args:
outputs = self.layer.call(quantized_inputs, training=training)
else:
outputs = self.layer.call(quantized_inputs)
return outputs
tensorflow_quantization.utils
Introduction to Quantization
What is Quantization?
Quantization is the process of converting continuous values to discrete set of values using linear/non-linear scaling techniques.
Why Quantization?
High precision is necessary during training for fine-grained weight updates.
High precision is not usually necessary during inference and may hinder the deployment of AI models in real-time and/or in resource-limited devices.
INT8 is computationally less expensive and has lower memory footprint.
INT8 precision results in faster inference with similar performance.
Quantization Basics
See whitepaper for more detailed explanations.
Let [β, α] be the range of representable real values chosen for quantization and b be the bit-width of the signed integer representation.
The goal of uniform quantization is to map real values in the range [β , α] to lie within [-2b-1, 2b-1 - 1]. The real values that lie outside this range are clipped to the nearest bound.
Affine Quantization
Considering 8 bit quantization (b=8), a real value within range [β, α] is quantized to lie within the quantized range [-128, 127] (see source):
xq=clamp(round(x/scale)+zeroPt)
where, scale = (α - β) / (2b-1)
zeroPt = -round(β * scale) - 2b-1
round is a function that rounds a value to the nearest integer. The quantized value is then clamped between -128 to 127.
Affine DeQuantization
DeQuantization is the reverse process of quantization (see source):
x=(xq−zeroPt)∗scale
Quantization in TensorRT
TensorRT™ only supports symmetric uniform quantization, meaning that zeroPt=0 (i.e. the quantized value of 0.0 is always 0).
Considering 8 bit quantization (b=8), a real value within range [min_float, max_float] is quantized to lie within the quantized range [-127, 127], opting not to use -128 in favor of symmetry. It is important to note that we loose 1 value in symmetric quantization representation, however, loosing 1 out of 256 representable value for 8 bit quantization is insignificant.
Quantization
The mathematical representation for symmetric quantization (zeroPt=0) is:
xq=clamp(round(x/scale))
Since TensorRT supports only symmetric range, the scale is calculated using the max absolute value: max(abs(min_float), abs(max_float)).
Let α = max(abs(min_float), abs(max_float)),
scale = α/(2b-1-1)
Rounding type is rounding-to-nearest ties-to-even.
The quantized value is then clamped between -127 and 127.
DeQuantization Symmetric dequantization is the reverse process of symmetric quantization:
x=(xq)∗scale
Intutions
Quantization Scale
Scaling factor divides a given range of real values into a number of partitions.
Lets understand intution behind scaling factor formula by taking 3 bit quantization as an example.
Asymmetric Quantization
Real values range: [β, α]
Quantized values range: [-23-1, 23-1-1]
i.e. [-4, -3, -2, -1, 0, 1, 2, 3]
As expected there are 8 quantized (23) values for 3 bit quantization.
Scale divides range into partitions. There are 7 (23-1) partitions for 3 bit quantization.
Thus,
scale = (α - β) / (23-1)
Symmetric Quantization
Symmetric quantization brings in two changes
Real values are not free now but are restricted. i.e [-α, α]
where α =max(abs(min_float), abs(max_float))One value from quantization range is dropped in favor of symmetry leading to a new range [-3, -2, -1, 0, 1, 2, 3].
There are now 6 (23-2) partitions (unlike 7 for asymmetric quantization).
Scale divides range into partitions.
scale = 2*α /(23 - 2) = α/(23-1-1)
Similar intution holds true for b bit quantization.
Quantization Zero Point
The constant zeroPt is of the same type as quantized values xq, and is in fact the quantized value xq corresponding to the real value 0. This allows us to auto-matically meet the requirement that the real value r = 0 be exactly representable by a quantized value. The motivation for this requirement is that efficient implementation of neural network operators often requires zero-padding of arrays around boundaries.
If we have values with negative data, then the zero point can offset the range. So if our zero point was 128, then unscaled negative values -127 to -1 would be represented by 1 to 127, and positive values 0 to 127 would be represented by 128 to 255.
Quantization Aware Training (QAT)
The process of converting continuous to discrete values (Quantization) and vice-versa (Dequantization), requires scale and zeroPt (zero-point) parameters to be set.
There are two quantization methods based on how these two parameters are calculated:
- Post Training Quantization (PTQ)
Post Training Quantization computes scale after network has been trained. A representative dataset is used to capture the distribution of activations for each activation tensor, then this distribution data is used to compute the scale value for each tensor. Each weight's distribution is used to compute weight scale.
TensorRT provides a workflow for PTQ, called calibration.
flowchart LR id1(Calibration data) --> id2(Pre-trained model) --> id3(Capture layer distribution) --> id4(Compute 'scale') --> id5(Quantize model)
- Quantization Aware Training (QAT)
Quantization Aware Training aims at computing scale factors during training. Once the network is fully trained, Quantize (Q) and Dequantize (DQ) nodes are inserted into the graph following a specific set of rules. The network is then further trained for few epochs in a process called Fine-Tuning. Q/DQ nodes simulate quantization loss and add it to the training loss during fine-tuning, making the network more resilient to quantization. In other words, QAT is able to better preserve accuracy when compared to PTQ.
flowchart LR id1(Pre-trained model) --> id2(Add Q/DQ nodes) --> id3(Finetune model) --> id4(Store 'scale') --> id5(Quantize model)
Attention
This toolkit supports only QAT as a quantization method. Note that we follow the quantization algorithm implemented by TensorRT™ when inserting Q/DQ nodes in a model. This leads to a quantized network with optimal layer fusion during the TensorRT™ engine building step.
Note
Since TensorRT™ only supports symmetric quantization, we assume zeroPt = 0.