Accelerating Hugging Face Gemma Inference with Transformer Engine
Introduction
Generative AI has made remarkable strides in recent years, with Large Language Models (LLMs) like ChatGPT at the forefront. These models have revolutionized how we interact with machine-generated content, providing capabilities that range from writing assistance to complex decision support. The core functionality of these models is the generation process, which involves predicting the next token in a sequence based on the preceding text. This task is critical for applications such as automated content creation, translation, and more, emphasizing the importance of efficient implementation.
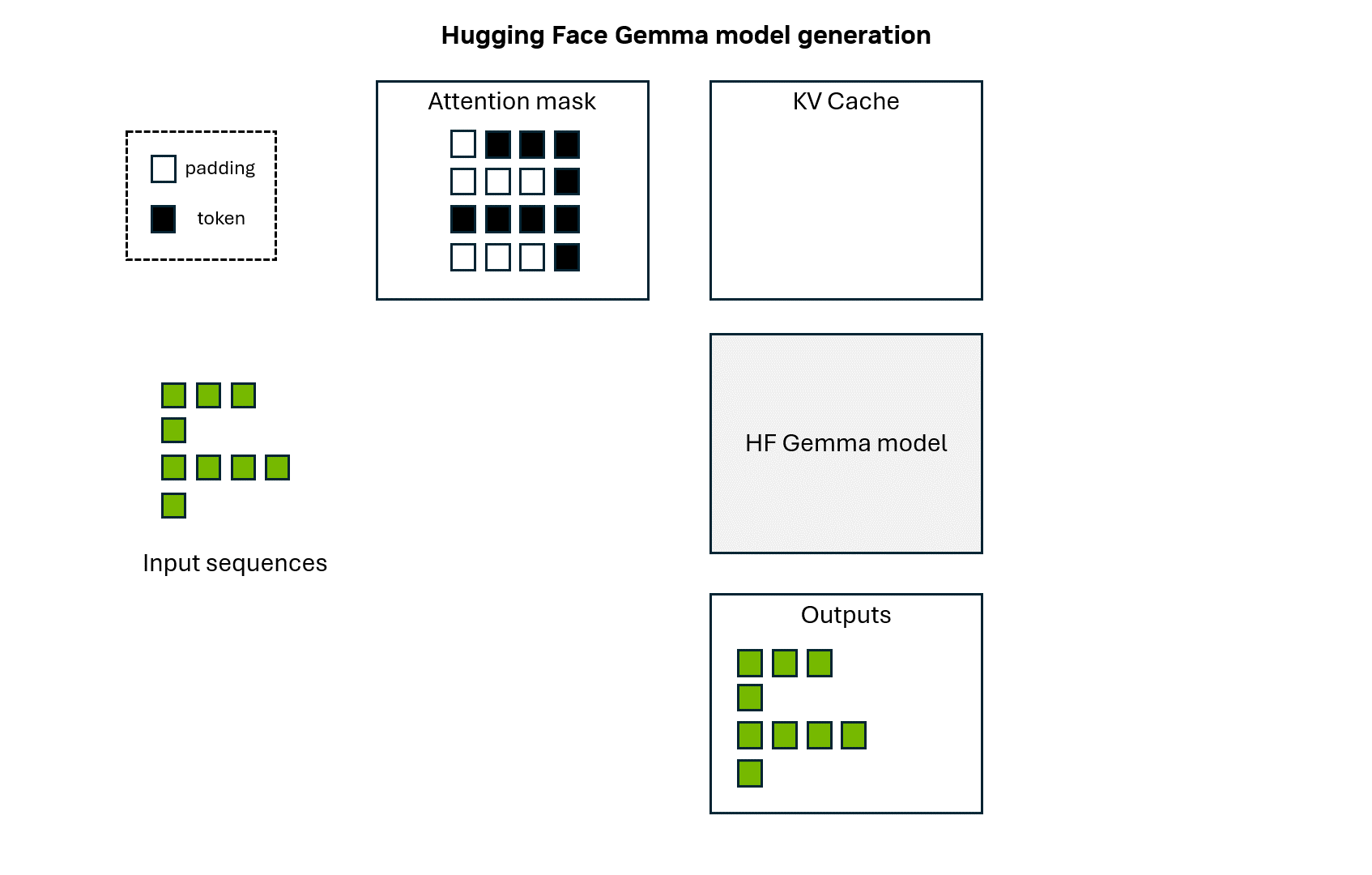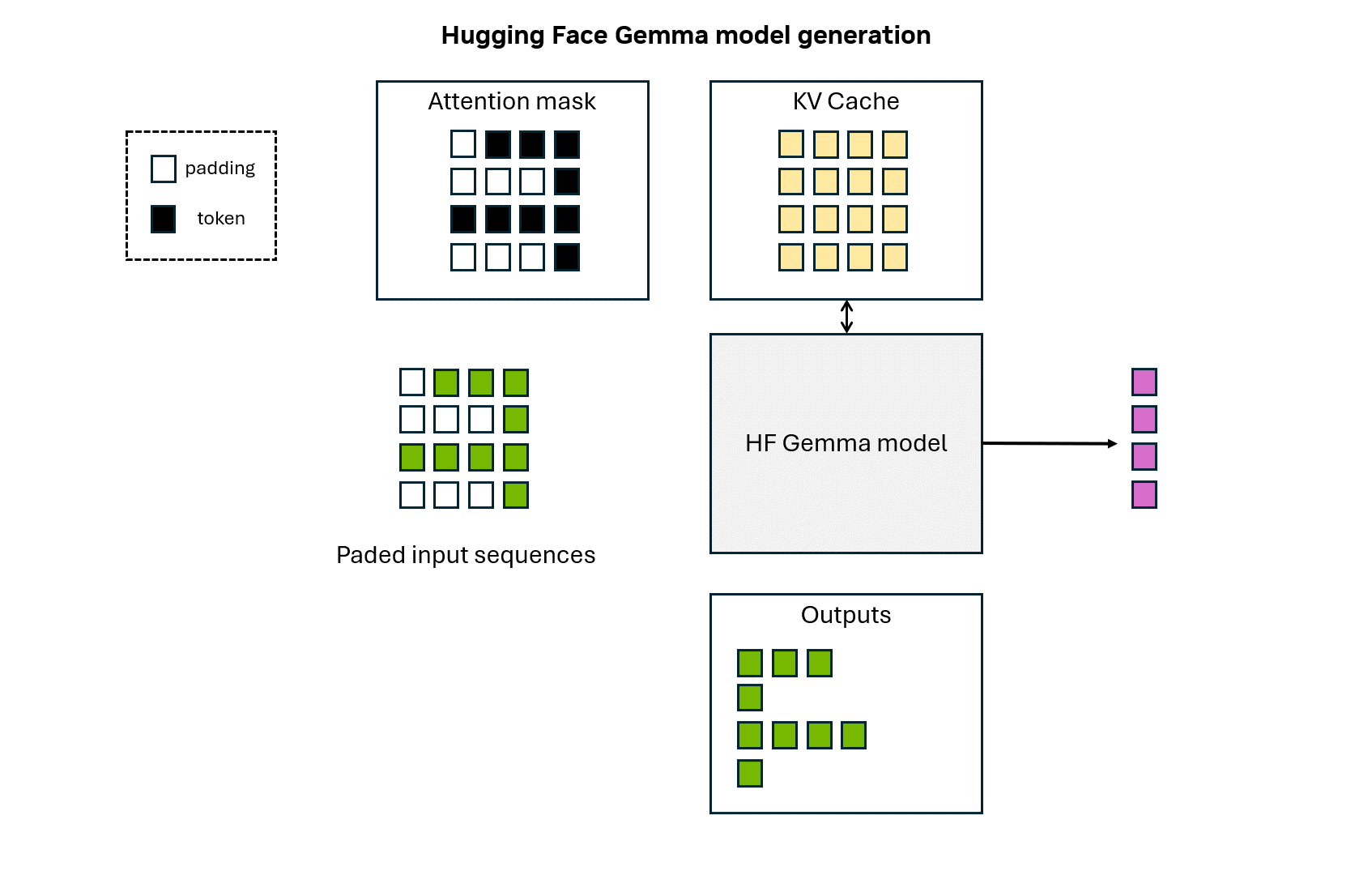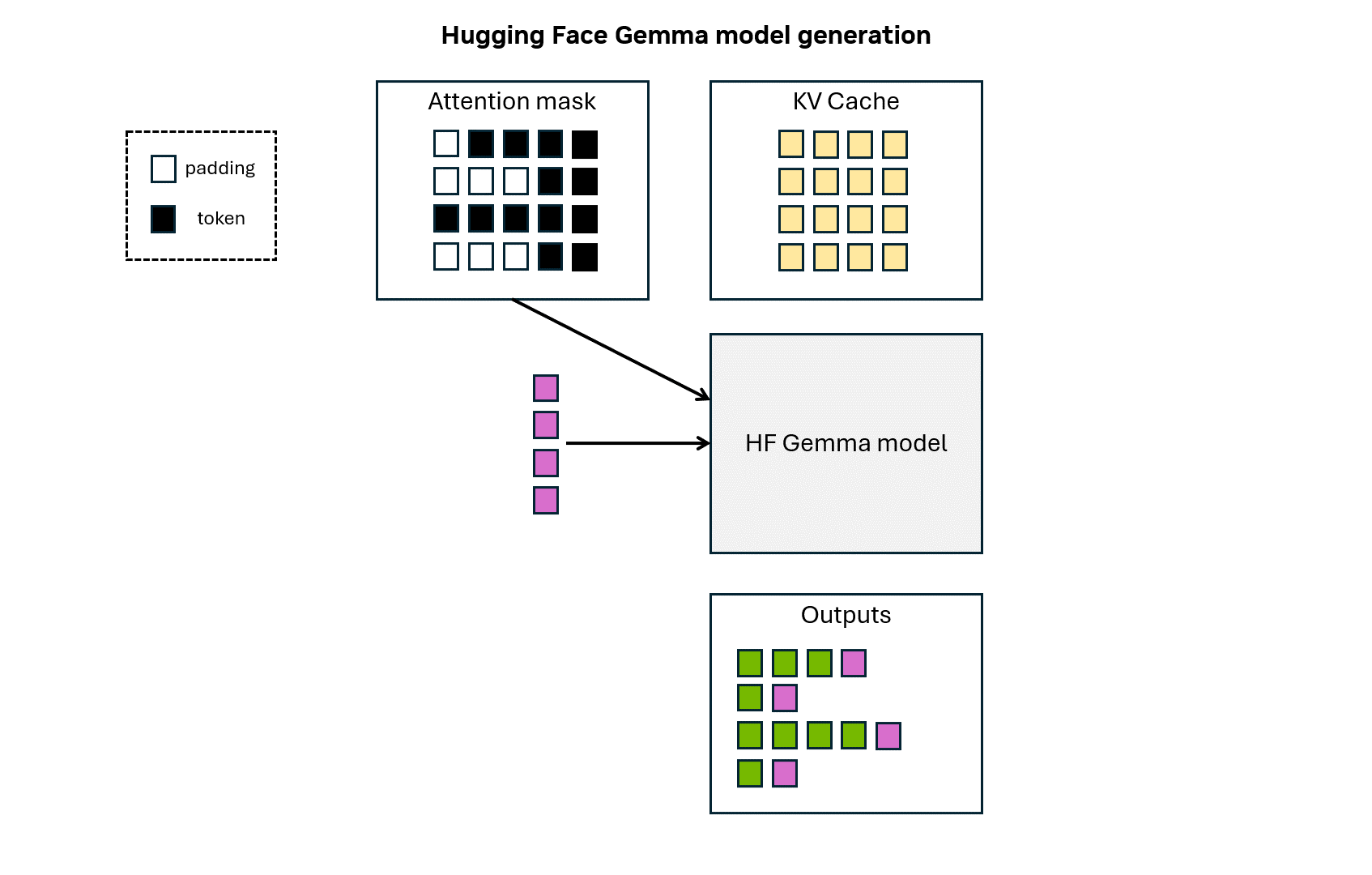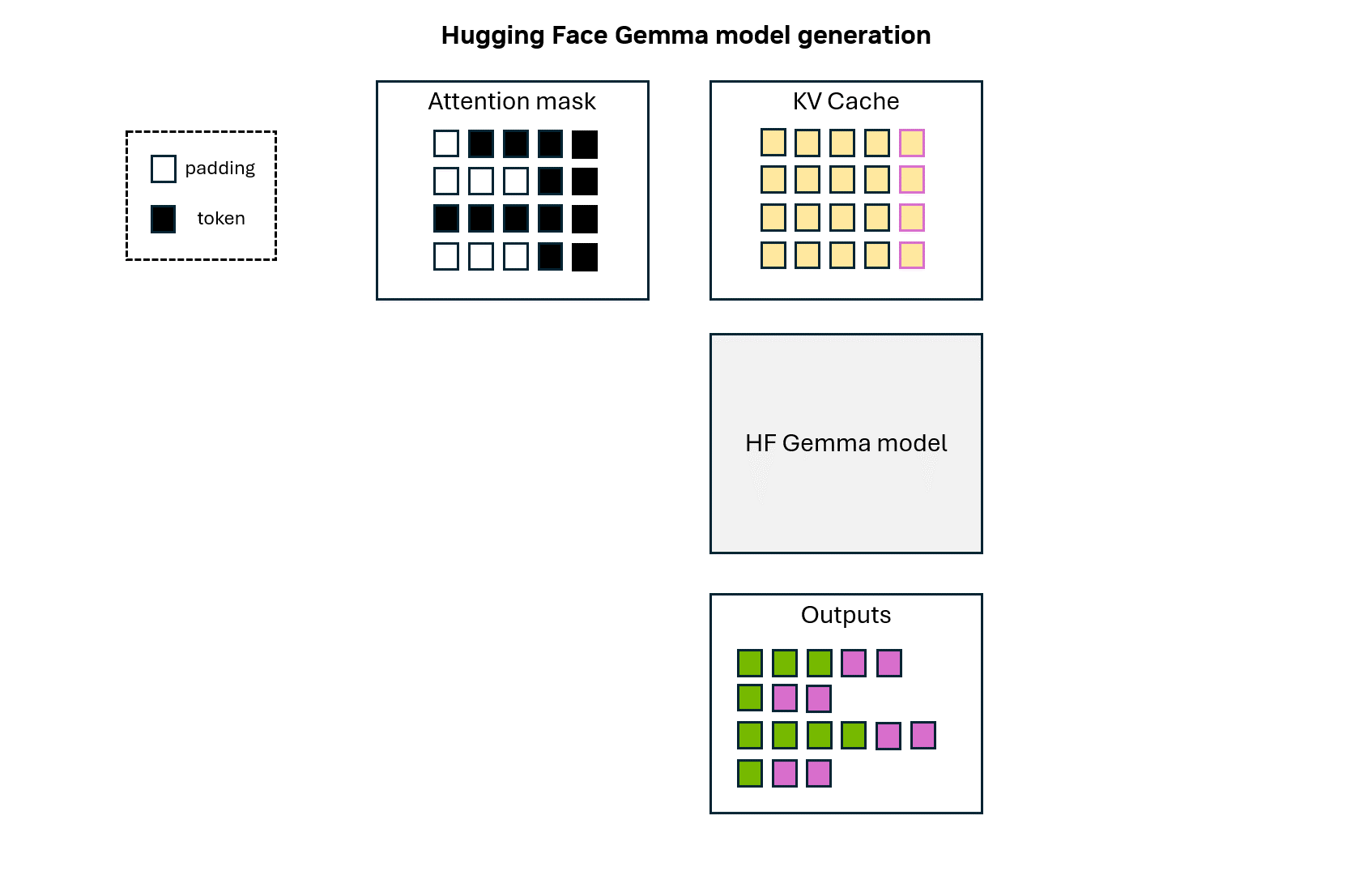
Animation 1: Hugging Face Gemma model token generation.
For those seeking a deeper understanding of text generation mechanisms in Transformers, it is recommended to check out the HuggingFace generation tutorial.
In a previous tutorial on Llama, it was demonstrated how finetuning of an open-source Llama model can be accelerated using Transformer Engine’s TransformerLayer. Building on that foundation, this tutorial showcases how to accelerate the token generation from the open-source Hugging Face Gemma 7B model.
This tutorial introduces several features of the Transformer Engine library that contribute towards this goal. A brief explanation is as follows:
1. From vanilla KV-caching to Paged Attention for inference in Transformer Engine
The original Attention mechanism ushered in an era of Large Language Models, but the same attention mechanism, if used for deployment in inference scenarios, can be computationally wasteful. It is primarily due to a lot of redundant computation that happens in attention when the Transformer models are used autoregressively to compute the next token. Several tutorials on the internet explain in detail how KV Caching helps to reduce that redundant computation, e.g., tutorial 1, tutorial 2, etc.
Further, even though the performance benefit of KV Cache is immense, it comes at the cost of increased memory usage, which becomes a problem especially for longer context lengths. The major problems are:
Internal fragmentation
External Fragmentation
More information can be found in the Paged Attention paper. The authors solve the above problems by treating the KV cache as a virtual memory with the actual physical blocks being much smaller than the overall cache size. This makes it easier to swap them in and out of GPU HBM as needed - very similar to how Operating Systems implement virtual memory to swap the individual pages in and out of the CPU RAM.
Transformer Engine allows users to use both “Non-paged” and “Paged” forms of KV Caching, and the results in this tutorial are posted for both use cases.
2. CUDA Graphs API
The speed of GPUs is increasing at a rapid pace. It turns out that sometimes the runtime of kernels is shorter than the time it takes for the CPU to finish processing and then launch the kernels, which can lead to significant overhead. CUDA Graphs can address this issue. When such blocks of computation are executed repeatedly, CUDA Graphs allow us to record and replay them with less CPU involvement. This becomes particularly useful in applications like token generation, where multiple “Transformer/Decoder Layers” are run for every token that needs to be generated.
One can read more about CUDA Graphs here.
PyTorch exposes graphs via a raw torch.cuda.CUDAGraph class and two convenience wrappers: torch.cuda.graph and torch.cuda.make_graphed_callables. More information about the CUDA graphs in Pytorch can be found here.

Figure 1: CUDA Graphs reduce the overhead generated by the long time it takes to launch a single kernel. It enables the recording and replaying of subsequent launches, thus reducing the total time used by the CPU.
3. FP8 Scaling Factors Calibration
This tutorial uses the DelayedScaling recipe for FP8 precision, which relies on the correct calculation of “scaling factors”.
If a model is trained in BF16/FP32, obtaining correct FP8 scaling factors becomes important when it is then run under autocast() context manager. The value of these scaling factors defaults to their initial values, which do not capture the distribution of higher precision weights and input tensors and can cause numerical errors upon usage. Calibration involves capturing an appropriate distribution of higher precision weights and input tensor values and, in turn, calculating appropriate FP8
scaling factors from those. Once these factors are computed, the model becomes numerically stable.
It is highly recommended to familiarize oneself with the tutorial on FP8 precision to understand the importance of proper scaling factors.

Figure 2: Assuming that the model is trained in FP32/BF16 precision and the goal is to execute it in FP8 precision, the process isn’t straightforward due to the absence of appropriate FP8 scaling factors. In this scenario, FP8 calibration becomes essential. By conducting several forward passes on sample data, the FP8 scaling parameters can be computed. This calibration allows the model to operate correctly in FP8 precision.
4. FP8 Model Weights
The typical approach is to store weights in higher precision and then cast them to FP8 before operations. This may prevent accuracy drops in training. However, for inference, this level of precision is not necessary.
The Transformer Engine includes a wrapper quantized_model_init, which allows for the creation of models that store only the FP8 copy of the weights. This eliminates the need to cast model weights from higher precision to FP8 every time, thus saving time in the forward pass during token generation.

Figure 3: Model under autocast() stores weights in high precision by default, and casts them if needed. If used without consideration, it could potentially not provide the expected speedup and also end up unnecessarily increasing overall GPU memory usage. Using quantized_model_init() results in storing model weights in FP8 by default, which can help with these potential issues.
Benchmarking
We’ll evaluate the generation time across one benchmark: token generation with context/prefill phase max sequence length = 20, batch size = 64, and number of generated tokens = 492 on random texts with random lengths. This is a purely synthetic benchmark.
Note
This tutorial focuses on showcasing the mentioned features of the Transformer Engine in the context of token generation. It’s important to note, however, that NVIDIA provides TensorRT-LLM, which is optimized for inference tasks and should be considered for such use cases.
Dependencies for this tutorial
The following files and media are necessary to effectively run this tutorial:
te_gemma.pyThis file contains the code to load a Hugging Face Gemma checkpoint weights in Transformer Engine’s
TransformerLayerinstead of Hugging Face’sGemmaDecoderLayer. Further, it contains necessary abstractions like a subclass ofGemmaForCausalLM-TEGemmaForCausalLMthat is used for generation with Transformer Engine’sTransformerLayer, CUDA Graphs, and FP8 calibration for generation in FP8 precision.
te_gemma_loading_weights.pyThis file contains the logic of mapping the parameters from
GemmaDecoderLayerinto theTransformerLayer.
utils.pyThis file contains the code related to dataloading, hyperparameters, setting up model/optimizers/accelerator, model training, and other miscellaneous tasks like restarting the Jupyter notebook from within the cell.
requirements.txtThis file contains the necessary Python packages for this tutorial.
media/This directory contains the images and other artefacts used in this tutorial.
Setup and checks
[1]:
# Uncomment and run this cell when running the tutorial for the first time
# %pip install -r requirements.txt
[2]:
import warnings
warnings.filterwarnings("ignore")
import torch
cudnn_version = torch.backends.cudnn.version()
assert cudnn_version >= 90100, "cuDNN version >= 9.1.0 is needed to run this tutorial."
[Baseline] Running Hugging Face generation with Gemma model
HuggingFace Transformers library offers generation API. HuggingFace generation for the Gemma model will be used as a baseline.
[1]:
# Restart the notebook (to flush the GPU memory)
from utils import restart_jupyter_notebook
restart_jupyter_notebook()
from utils import *
# Provide Huggingface Access Token
run_config.hf_access_token = ""
assert run_config.hf_access_token, "Provide a HF API Access Token!"
run_config.model_name = "google/gemma-7b"
# Provide a directory to cache weights in to avoid downloading them every time.
# (By default, weights are cached in `~/.cache/huggingface/hub/models`)
run_config.weights_cache_dir = ""
# Set specific hyperparameters
# (Default run_config are defined in `utils.py` in class `Hyperparameters`)
run_config.batch_size = 64
run_config.max_seq_length = 512
model = init_baseline_model(run_config)
print_sample_of_generated_texts(model, run_config)
benchmark_generation(model, run_config)
============================== Generation example 1 ==============================
Prompt: "Here are the two facts about GPUs:"
Generated text: "
1. They are very good at doing a lot of the same thing at the same time.
2. They are very bad at doing different things at the same time.
The first fact is why GPUs are so good at graphics. The"
============================== Generation example 2 ==============================
Prompt: "Some facts about NVIDIA:"
Generated text: "
* NVIDIA is a global technology company that designs and builds advanced computer graphics and video processing chips for the PC and video game console markets.
* The company is a leading provider of graphics processing units (GPUs) for the PC and video game"
================================================================================
Benchmarking for batch_size = 64, prefill tokens = 20 and max new tokens = 492
Time: 46.60 s.
Let’s put this time into the table for later comparison.
Models |
Time |
Speedup |
|---|---|---|
HF (baseline) |
46.6 s |
[Optimization 1] Accelerating generation with Transformer Engine
Similar to the Llama finetuning tutorial, a GemmaDecoderLayer is substituted by a tuned TransformerLayer from the Transformer Engine library. Let’s run it and compare the time with the baseline.
[1]:
# Restart the notebook (to flush the GPU memory)
from utils import restart_jupyter_notebook
restart_jupyter_notebook()
from utils import *
# Provide Huggingface Access Token
run_config.hf_access_token = ""
assert run_config.hf_access_token, "Provide a HF API Access Token!"
run_config.model_name = "google/gemma-7b"
# Provide a directory to cache weights in to avoid downloading them every time.
# (By default, weights are cached in `~/.cache/huggingface/hub/models`)
run_config.weights_cache_dir = ""
# Set specific hyperparameters
# (Default run_config are defined in `utils.py` in class `Hyperparameters`)
run_config.batch_size = 64
run_config.max_seq_length = 512
run_config.is_paged = False # <-- Toggle this to `True` to run generation with `Paged Attention`
model = init_te_gemma_model(run_config)
print_sample_of_generated_texts(model, run_config)
benchmark_generation(model, run_config)
============================== Generation example 1 ==============================
Prompt: "Here are the two facts about GPUs:"
Generated text: "
1. They are very good at doing a lot of the same thing at the same time.
2. They are very bad at doing different things at the same time.
The first fact is why they are so good at graphics. The second"
============================== Generation example 2 ==============================
Prompt: "Some facts about NVIDIA:"
Generated text: "
* NVIDIA is a global technology company that designs and builds the world’s most advanced computer chips and systems for the AI era.
* NVIDIA is the world leader in AI computing.
* NVIDIA is the world leader in graphics processing units (GP"
================================================================================
Benchmarking for batch_size = 64, prefill tokens = 20 and max new tokens = 492
Time: 12.25 s.
With just using Transformer Engine with default (non-paged) KV cache, a speedup of 3.8x was obtained. Neat!
Models |
Time (non-paged kv cache) |
Speedup (non-paged kv cache) |
Time (paged kv cache) |
Speedup (paged kv cache) |
|---|---|---|---|---|
HF (baseline) |
46.6 s |
|||
TE (subsitution of |
12.25 s |
3.8x |
12.24 s |
3.8x |
[Optimization 2] More acceleration with CUDA Graphs
Transformer Engine includes a function transformer_engine.pytorch.make_graphed_callables, which behaves similarly to the corresponding feature in PyTorch. It is capable of recording any modules from the Transformer Engine. Below is a code excerpt from te_gemma.py from class TEGemmaForCausalLMCudaGraphs:
def __init__(self, config : GemmaConfig):
"""
Here "the trick" happens. `_model_context_phase` and
`_model_generation_phase` from TEGemmaForCausalLM are replaced with
their recorded version. Once the graphs are recorded, they can be
replayed with minimal usage of CPU and that leads to speedup.
"""
(...)
# Record the graph for context/prefill phase.
self._model_context_phase =
self.record_graph(self._model_context_phase, self.hidden_states_buffer)
(...)
# Record the graph for generation phase.
self._model_generation_phase =
self.record_graph(self._model_generation_phase, self.generation_buffer)
@torch.no_grad()
def record_graph(self, function, input_tensor):
"""
Records the graph for the given function. The function is invoked on
argument (self.hidden_states,) and all kernels are recorded.
It then returns the captured callable, which can be run later while
minimizing CPU usage.
"""
fp8_recipe = get_default_fp8_recipe()
# We need both autocasts: FP8 for operations that can run in lower
# precision and BF16 for those that cannot.
with autocast("cuda", dtype=torch.bfloat16, cache_enabled=False):
graphed_function = te.pytorch.make_graphed_callables(
function,
(input_tensor,),
enabled=self.config.fp8,
recipe=fp8_recipe,
allow_unused_input=True,
num_warmup_iters=5,
sample_kwargs=sample_kwargs,
)
return graphed_function
It is strongly recommended to review the entire code of the class TEGemmaForCausalLMCudaGraphs. Let’s now proceed to evaluate the performance improvement offered by CUDA Graphs.
Note the usage of static buffers and corresponding configuration in the following cell, which is necessary for CUDA Graphs to function.
[1]:
# Restart the notebook (to flush the GPU memory)
from utils import restart_jupyter_notebook
restart_jupyter_notebook()
from utils import *
# Provide Huggingface Access Token
run_config.hf_access_token = ""
assert run_config.hf_access_token, "Provide a HF API Access Token!"
run_config.model_name = "google/gemma-7b"
# Provide a directory to cache weights in to avoid downloading them every time.
# (By default, weights are cached in `~/.cache/huggingface/hub/models`)
run_config.weights_cache_dir = ""
# Set specific hyperparameters
# (Default run_config are defined in `utils.py` in class `Hyperparameters`)
run_config.max_seq_length = 512
run_config.batch_size = 64
run_config.is_paged = False # <-- Toggle this to `True` to run generation with `Paged Attention`
# It is necessary to preallocate a static buffer.
# CUDA graphs require static input tensors for every kernel.
# This approach may result in a slight increase in memory consumption;
# however, the substantial speedup achieved makes it worthwhile.
run_config.generation_cuda_graphs = True
run_config.cuda_graphs_static_batch_size = 64
run_config.cuda_graphs_static_max_seq_len = 512
run_config.cuda_graphs_static_max_context_len = 512
model = init_te_gemma_model(run_config)
print_sample_of_generated_texts(model, run_config)
benchmark_generation(model, run_config)
============================== Generation example 1 ==============================
Prompt: "Here are the two facts about GPUs:"
Generated text: "
1. They are very good at doing a lot of the same thing at the same time.
2. They are very bad at doing different things at the same time.
The first fact is why they are so good at graphics. The second"
============================== Generation example 2 ==============================
Prompt: "Some facts about NVIDIA:"
Generated text: "
* NVIDIA is a global technology company that designs and builds the world’s most advanced computer chips and systems for the AI era.
* NVIDIA is the world leader in AI computing.
* NVIDIA is the world leader in graphics processing units (GP"
================================================================================
Benchmarking for batch_size = 64, prefill tokens = 20 and max new tokens = 492
Time: 6.39 s.
A speed up of 7.2x was obtained by using CUDA Graphs with TE’s TransformerLayer.
Models |
Time (non-paged kv cache) |
Speedup (non-paged kv cache) |
Time (paged kv cache) |
Speedup (paged kv cache) |
|---|---|---|---|---|
HF (baseline) |
46.6 s |
|||
TE (subsitution of GemmaDecoderLayer with te.TransformerLayer) |
12.25 s |
3.8x |
12.24 s |
3.8x |
TE (te.TransformerLayer) + CUDA Graphs |
6.39 s |
7.2x |
6.47 s |
7.2x |
Let’s profile the code from one of the cells above, which runs generation with the Gemma model, and examine the resulting traces in NVIDIA Nsight Systems to understand the performance characteristics and sources of speedup. A few things to recap:
For the TE Gemma model implementation,
model.generate()internally callsmodel_context_phaseandmodel_generation_phase.They are just wrappers around the Gemma model’s layers, and they are graphed separately when CUDA graphs are enabled.
So, for each token generated (after the first token), a single invocation of
model_generation_phasehappens as a complete CUDA graph.The following illustration zooms in on a single
TransformerLayerlayer forward pass (within the largermodel_generation_phasegraphed callable) for clarity.
(For details, refer to the implementation in te_gemma.py)
<img src=”./media/transformer_cuda_graphed.png” width=”80%” “>
Figure 4: (Without CUDA graphs) Blue blobs in the top figure are GPU kernels, and whitespace b/w those indicates that GPUs are idle waiting for the CPU to finish processing and then launch kernels. (With CUDA graphs) The whitespace gets virtually eliminated because all the GPU kernels are bundled into a single highly optimized unit of work with no CPU time in between. (Note that for reference, the kernels are mapped across both cases, and the sizes of those kernels only seem different because of the presence of large voids in the former case, but the sizes are actually the same.)
[Optimization 3] Even more acceleration with FP8 precision
Calibrating FP8 scaling factors for correctness
Implementing token generation in FP8 precision with the Gemma model is not straightforward because this model was initially trained using BF16 precision, and the necessary FP8 scaling factors are missing when used with autocast context manager. As Figure 5 shows, scaling factors are needed for two types of tensors for this tutorial:
Model weight tensors
Input tensors
If the model is run in FP8 precision with incorrect scaling factors, the resulting FP8-cast model weights and FP8-cast inputs (both converted from BF16 precision) will be significantly misaligned, potentially leading to large errors and inaccurate results.
To address this issue, “calibration” is used. This involves running several forward iterations in BF16 precision within the context te.autocast(enabled=False, calibration=True). This setup allows the forward pass to operate at higher precision, while simultaneously collecting amax_history and other parameters related to the FP8 precision, which are essential for calculating the “scaling factors” that are then used to cast higher precision tensors to FP8 precision more accurately.
Calibration in the forward passes calculates the scaling factors for weight and input tensors.
Note that other tensors might need calibration in specific use-cases, but for the generation process in this tutorial, calibrating only the input and weight tensors is needed, and so only the forward pass is considered.

Figure 5: The default FP8 scaling factors are incorrect, and so the BF16 to FP8 conversion, as is, can lead to numerical errors. Calibration allows for collecting statistics/metadata about the input and weight tensors in higher precision during the forward pass.
The code below outlines the steps to initialize the BF16 model and conduct several forward iterations within the specified context. After these iterations, the model is saved, and these weights will be utilized in subsequent steps.
[1]:
# Restart the notebook (to flush the GPU memory)
from utils import restart_jupyter_notebook
restart_jupyter_notebook()
import transformer_engine.pytorch as te
from utils import *
# Provide Huggingface Access Token
run_config.hf_access_token = ""
assert run_config.hf_access_token, "Provide a HF API Access Token!"
run_config.model_name = "google/gemma-7b"
# Provide a directory to cache weights in to avoid downloading them every time.
# (By default, weights are cached in `~/.cache/huggingface/hub/models`)
run_config.weights_cache_dir = ""
run_config.fuse_qkv_params = True
model = init_te_gemma_model(run_config)
# Calibration
with te.autocast(enabled=False, calibrating=True), torch.autocast(
device_type="cuda", dtype=torch.bfloat16
):
model.train()
run_forward_pass(model, run_config, num_iters=64)
# Compute scale_fwd with enabled fp8 autocast
with te.autocast(enabled=True), torch.autocast(
device_type="cuda", dtype=torch.bfloat16
):
run_forward_pass(model, run_config, 1)
# Some parameters are in pointing to the same tensors, double save is avoided here.
dict_to_save = {
k: v
for k, v in model.state_dict().items()
if ("_context_phase" not in k and "_generation_phase" not in k)
}
torch.save(
dict_to_save, "calibrated_weights.pth"
) # <-- Add path to save calibrated weights.
Generation with better FP8 scaling factors

Figure 6: After the calibration process, FP8 scaling factors are correct and prevent numerical errors.
Now that the calibration has produced correct scaling factors, FP8 inference is ready to be run.
[1]:
# Restart the notebook (to flush the GPU memory)
from utils import restart_jupyter_notebook
restart_jupyter_notebook()
from utils import *
# Provide Huggingface Access Token
run_config.hf_access_token = ""
assert run_config.hf_access_token, "Provide a HF API Access Token!"
run_config.model_name = "google/gemma-7b"
# Provide a directory to cache weights in to avoid downloading them every time.
# (By default, weights are cached in `~/.cache/huggingface/hub/models`)
run_config.weights_cache_dir = ""
# Set specific hyperparameters
# (Default run_config are defined in `utils.py` in class `Hyperparameters`)
run_config.fuse_qkv_params = True # This is needed by the last improvement.
run_config.is_paged = False # <-- Toggle this to `True` to run generation with `Paged Attention`
# CUDA Graphs related config
run_config.generation_cuda_graphs = True
run_config.cuda_graphs_static_batch_size = 64
run_config.cuda_graphs_static_max_seq_len = 512
run_config.cuda_graphs_static_max_context_len = 512
# Enable FP8
run_config.fp8 = True
# Calibrated fp8 weights are loaded directly from the file.
run_config.fp8_model_weights_filename = (
"calibrated_weights.pth" # <-- Add calibrated weights location here.
)
model = init_te_gemma_model(run_config)
print_sample_of_generated_texts(model, run_config)
benchmark_generation(model, run_config)
============================== Generation example 1 ==============================
Prompt: "Here are the two facts about GPUs:"
Generated text: "
1. They are very good at doing the same thing over and over again.
2. They are very bad at doing different things at the same time.
This is why GPUs are so good at rendering graphics. The GPU is very good at"
============================== Generation example 2 ==============================
Prompt: "Some facts about NVIDIA:"
Generated text: "
* NVIDIA is a global technology company that designs and develops high-performance computer graphics and video processing chips.
* NVIDIA is a leading provider of graphics processing units (GPUs) for the gaming and professional markets.
* NVIDIA is a key player"
================================================================================
Benchmarking for batch_size = 64, prefill tokens = 20 and max new tokens = 492
Time: 8.73 s.
One can observe that the outputs are coherent; however, the generation time has increased. Why is this the case?
Use of FP8-only model weights
Running the model in FP8 precision does not imply that the weights are stored in FP8. By default, they are stored in higher precision and are cast to FP8, using saved scaling factors before GEMM operations (matrix multiplications).
This approach is appropriate during training since gradients during the backward pass are produced in higher precision, and therefore, having higher precision copies of model weights helps, as they have enough dynamic range to encompass incoming information from the gradients. During the forward pass, the higher precision model weights and the batch inputs are cast to FP8, and the GEMMs occur in FP8 precision, which helps save training time overall if the time saved from running GEMM in FP8 precision (than in higher precision) is more than the extra time spent during the cast operation.

Figure 7: Running the model at higher precision involves only one operation - GEMM. However, when the model operates in FP8, it requires casting inputs to the GEMM - namely, model weights and batch inputs from higher precision to FP8, which involves extra kernels in addition to the low-precision GEMM kernel.
However, things change during inference. Since the weights need no update and remain frozen, higher precision copies of weights could be avoided completely. It is possible to cast the higher precision weights only once to FP8 precision while initializing the model with appropriate scaling factors and then use those FP8-only copies of weights during the entirety of token generation. This provides two-fold benefits:
Lower memory usage - since the model weights are stored in FP8 precision only (compared to training, where both BF16 and FP8 copies end up being present in the memory during peak usage).
Faster forward pass - since there is no cast kernel to cast higher precision weights to FP8 every time before a GEMM operation. (Unless the inputs are in FP8 precision already, there’s still one cast kernel to cast inputs to FP8 precision.)
Transformer Engine supports maintaining FP8-only weights with the quantized_model_init context manager. Let’s see a small example:
[1]:
import torch
import transformer_engine.pytorch as te
H = 2**14
D = 2**14
print(f"Memory required for {H}x{D} linear layer: \n"
f"FP32 - {H*D*4/1024**2} MB, \n"
f"BF16 - {H*D*2/1024**2} MB, \n"
f"FP8 - {H*D*1/1024**2} MB, \n")
linear_fp32 = te.Linear(H, D, params_dtype=torch.float32)
print(f"Actual GPU memory usage with a TE FP32 linear layer: {torch.cuda.memory_allocated()/1024**2:.2f} MB")
del linear_fp32
linear_bf16 = te.Linear(H, D, params_dtype=torch.bfloat16)
print(f"Actual GPU memory usage with a TE BF16 linear layer: {torch.cuda.memory_allocated()/1024**2:.2f} MB")
del linear_bf16
# Initialize model weights in FP8 precision
with torch.no_grad(), te.quantized_model_init(enabled=True):
linear_fp8 = te.Linear(H, D)
print(f"Actual GPU memory usage with a TE FP8 linear layer: {torch.cuda.memory_allocated()/1024**2:.2f} MB")
del linear_fp8
Memory required for 16384x16384 linear layer:
FP32 - 1024.0 MB,
BF16 - 512.0 MB,
FP8 - 256.0 MB,
Actual GPU memory usage with a TE FP32 linear layer: 1024.06 MB
Actual GPU memory usage with a TE BF16 linear layer: 512.03 MB
Actual GPU memory usage with a TE FP8 linear layer: 256.08 MB

Figure 8: Using quantized_model_init stores the weights directly in FP8 format, which reduces both time and memory usage. Note that the inputs still need a cast kernel.
Let’s run the code with quantized_model_init:
[1]:
# Restart the notebook (to flush the GPU memory)
from utils import restart_jupyter_notebook
restart_jupyter_notebook()
# Import necessary packages and methods
from utils import *
# Provide Huggingface Access Token
run_config.hf_access_token = ""
assert run_config.hf_access_token, "Provide a HF API Access Token!"
run_config.model_name = "google/gemma-7b"
# Provide a directory to cache weights in to avoid downloading them every time.
# (By default, weights are cached in `~/.cache/huggingface/hub/models`)
run_config.weights_cache_dir = ""
# Set specific hyperparameters
# (Default run_config are defined in `utils.py` in class `Hyperparameters`)
run_config.fuse_qkv_params = True # This is needed by the last improvement.
run_config.is_paged = False # <-- Toggle this to `True` to run generation with `Paged Attention`
# CUDA Graphs related config
run_config.generation_cuda_graphs = True
run_config.cuda_graphs_static_batch_size = 64
run_config.cuda_graphs_static_max_seq_len = 512
run_config.cuda_graphs_static_max_context_len = 512
# Enable FP8 math and FP8 model weights
run_config.fp8 = True
run_config.quantized_model_init = True # This will result in storing only fp8 weights.
run_config.fp8_model_weights_filename = (
"calibrated_weights.pth" # <-- Add calibrated weights location here.
)
model = init_te_gemma_model(run_config)
print_sample_of_generated_texts(model, run_config)
benchmark_generation(model, run_config)
============================== Generation example 1 ==============================
Prompt: "Here are the two facts about GPUs:"
Generated text: "
1. They are very good at doing the same thing over and over again.
2. They are very bad at doing different things at the same time.
This is why GPUs are so good at rendering graphics. The GPU is very good at"
============================== Generation example 2 ==============================
Prompt: "Some facts about NVIDIA:"
Generated text: "
* NVIDIA is a global technology company that designs and develops high-performance computer graphics and video processing chips.
* NVIDIA is a leading provider of graphics processing units (GPUs) for the gaming and professional markets.
* NVIDIA is a key player"
================================================================================
Benchmarking for batch_size = 64, prefill tokens = 20 and max new tokens = 492
Time: 4.99 s.
The final speedup is 9.3x.
Models |
Time (non-paged kv cache) |
Speedup (non-paged kv cache) |
Time (paged kv cache) |
Speedup (paged kv cache) |
|---|---|---|---|---|
HF (baseline) |
46.6 s |
|||
TE (subsitution of GemmaDecoderLayer with te.TransformerLayer) |
12.25 s |
3.8x |
12.24 s |
3.8x |
TE (te.TransformerLayer) + CUDA Graphs |
6.39 s |
7.2x |
6.47 s |
7.2x |
TE (te.TransformerLayer) + CUDA Graphs + FP8 (with |
4.99 s |
9.3x |
5.05 s |
9.2x |
Conclusions
This tutorial focuses primarily on making the token generation faster with an off-the-shelf model downloaded from Hugging Face using the following features of the Transformer Engine:
Support for KV Caching (both non-paged and paged),
Integration with CUDA Graphs,
FP8 scaling factors calibration,
Keeping model parameters in FP8 precision.
It’s worth noting that these features in TE are also readily applicable to other use-cases which haven’t been extensively talked about in the tutorial:
Longer context lengths (with paged KV cache)
Using less memory during generation (by storing weights in FP8 precision using
quantized_model_init)
Readers are encouraged to explore these use cases by playing around with this tutorial, especially with larger models.