DGX SuperPOD Software#
NVIDIA Mission Control software delivers a full-stack data center solution engineered for enterprise infrastructure deployments, like NVIDIA DGX SuperPOD. It integrates essential management and operational capabilities into a unified platform, providing enterprise customers with seamless control over their infrastructure deployments at scale.
Figure 20 shows the detailed decomposition of DGX GB200 SuperPOD software stack.
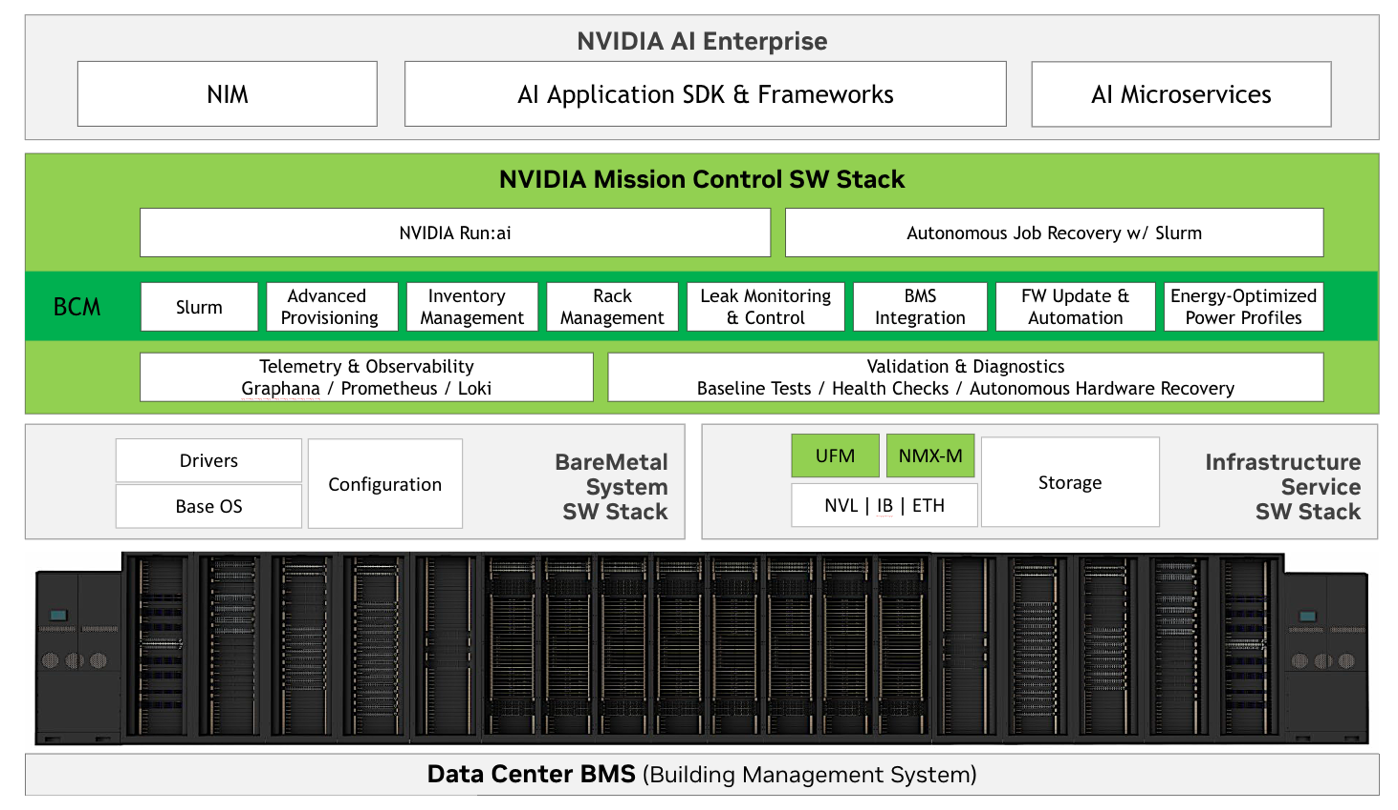
Figure 20 NVIDIA DGX GB200 SuperPOD Software Stack#
NVIDIA Mission Control software stack comprises a five-layer architecture that builds from foundational system health and diagnostics to advanced NVIDIA DGX SuperPOD cluster management operations. It leverages NVIDIA Base Command Manager (BCM) technology and NVIDIA Run:ai functionality to provide scheduler access with SLURM and Kubernetes for AI and HPC workload orchestration. The Telemetry and Observability layer leverages proprietary diagnostic tools and health-checks for system insights, while the Validation and Diagnostics layer, supports the built-in autonomous recovery engine that ensures rapid failure recovery and system restoration with minimal time to recovery.
NVIDIA Mission Control also handles deployment optimization and system health monitoring, seamlessly cooperating NVIDIA Base Command Manager (BCM) technology for coordinating cluster provisioning & operations. Included in the software stack there is also Network Management eXpert (NMX) for monitoring & control of NVLINK Switch trays.
NVIDIA Mission Control delivers critical innovations that directly impact DL and HPC environments, improving efficiency, reducing downtime, and optimizing resource utilization. Here’s how these advancements translate into tangible business value:
Automated Failure Detection & Self-Recovery: NVIDIA Mission Control’s automated failure detection and recovery mechanisms significantly minimize downtime compared to manual interventions. With faster recovery times, AI training continues without significant disruption, resulting in improved GPU utilization. This reduces the risk of resource wastage.
Optimized Workload Migration & Resource Allocation: NVIDIA Mission Control ensures that workloads are continuously reassigned to healthy nodes, preventing idle GPU time. This leads to increased overall GPU efficiency, enabling the system to process more workloads within the same timeframe. By optimizing resource allocation, NVIDIA Mission Control helps organizations achieve higher throughput for AI training tasks, thereby accelerating time-to-results.
Unified Diagnostics for Infrastructure & Applications: By combining infrastructure and application-level diagnostics, NVIDIA Mission Control helps significantly reduce troubleshooting time. Model builders can identify and resolve issues much faster compared to traditional methods. This considerably decreases the operational burden on SREs and DevOps, leading to savings in personnel costs and reducing the time to production.
In-Memory Checkpointing for Seamless Job Recovery: NVIDIA Mission Control enables recovery of training workloads by automatically restarting failed processes/ranks from the most recent valid checkpoint, ensuring no data loss or rework. In environments with frequent failures, it significantly reduces retraining time, thereby eliminating downtime and preventing interruptions in the training loop. This results in an increase in model iteration speed and faster go-to-market timelines for AI products.
Run:ai#
Included with NVIDIA Mission Control, the Run:ai platform employs a distributed architecture consisting of two primary components: the control plane (backend) and the cluster. The control plane serves as the central management system, capable of orchestrating multiple Run:ai clusters across an organization. For BCM-managed installations, the control plane is hosted on the control plane while cluster components are deployed directly onto the customer’s Kubernetes infrastructure. This separation of responsibilities allows for centralized management while maintaining workload execution close to computational resources.
Figure 21 showcases the architecture of NVIDIA Run:ai
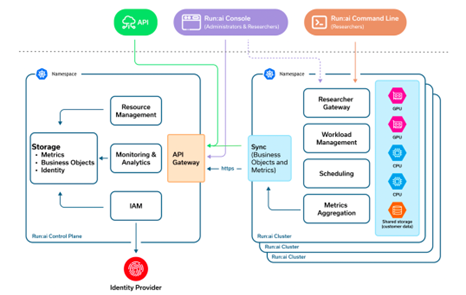
Figure 21 NVIDIA Run:ai#