Key Components of the DGX SuperPOD#
The DGX SuperPOD architecture is designed to meet the high demands of AI factories for the era of reasoning. AI factories require specialized components like high-performance GPUs and CPUs, advanced networking, and cooling systems to support the intensive computational needs of AI workloads. These factories excel at AI reasoning—enabling faster, more accurate decision-making across industries. And using NVIDIA’s end-to-end accelerated computing platform, they’re optimized for energy efficiency while accelerating AI inference performance, helping enterprises deploy secure, future-ready AI infrastructure.
DGX SuperPOD is the integration of key NVIDIA components, as well as storage solutions from partners certified to work in a DGX SuperPOD environment. By leveraging the concept of Scalable Units (SUs, as defined below in this document), DGX SuperPOD reduces AI factory deployment times from months to weeks, which in turn reduces time-to-solution and time-to-market of next generation models and applications.
DGX SuperPOD is to be deployed on-premises, meaning the customer owns and manages the hardware. This can be within a customer’s data center or co-located at a commercial data center, but the customer owns the hardware, the service it provides, and is responsible for their cluster infrastructure.
The key components of DGX GB200 SuperPOD are shown below, each component will be discussed in detail:
NVIDIA DGX GB200 NVL72 rack system
NVIDIA InfiniBand
Mission Control software platform
NVIDIA DGX GB200 Rack System#
The NVIDIA DGX GB200 system (Figure 2) is an AI powerhouse that enables enterprises to expand the frontiers of business innovation and optimization. Each DGX GB200 delivers breakthrough AI performance in a rack-scale, 72 GPU configuration. The NVIDIA Blackwell GPU architecture provides the latest technologies that brings months of computational effort down to days and hours, on some of the largest AI/ML workloads.
To accommodate the high compute density per rack and at the same time to more efficiently use datacenter space, the DGX GB200 rack system employs a sophisticated hybrid cooling solution to manage the substantial heat generated by the powerful GPUs and other components. The most power-intensive components, such as GPUs and CPUs, are liquid cooled. Other components are air cooled. NVIDIA’s Infrastructure Specialist team can provide end-to-end assistance for datacenter planning, system deployment, and bring-up services.

Figure 2 DGX GB200 (4 racks are shown here)#
DGX GB200 Compute Tray#
The compute nodes for DGX GB200 rack system are using the 72x1 NVLink topology, which contains 72 GPUs in a single NVLink domain. There are 18 compute nodes (AKA trays) in a DGX GB200 rack system. Each compute tray contains two GB200 Superchips, and each Superchip has two B200 GPUs and one Grace CPU. A coherent chip-to-chip interconnect link, called NVLink-C2C, bridges the two Superchips and enables them to act as a single logical unit for a single OS instance to operate.
The compute tray integrates four ConnectX-7 (CX-7) NICs to support InfiniBand NDR (400Gbps) connectivity for the cross racks Compute network, and two BlueFiled-3 (BF3) NICs to support 2x200Gbps connectivity for the In-band Management and Storage networks. All network ports are located at the front-side of the rack, intentionally for the cold aisle.
Each compute tray also provides a total of 4x 3.84TB E1.S NVMe as RAID0 for local storage and 1x 1.92TB M.2 NVMe for the OS image.
Figure 3 and Figure 4 show the front and rear of a DGX GB200 compute tray respectively.

Figure 3 GB200 Compute Tray Front#

Figure 4 GB200 Compute Tray Rear#
Figure 5 shows the block diagram of the GB200 compute tray with two GB200 Superchips, each chip combines two NVIDIA B200 Tensor Core GPUs and one NVIDIA Grace CPU, connected over a 900GB/s ultra-low-power NVLink-C2C interconnect.
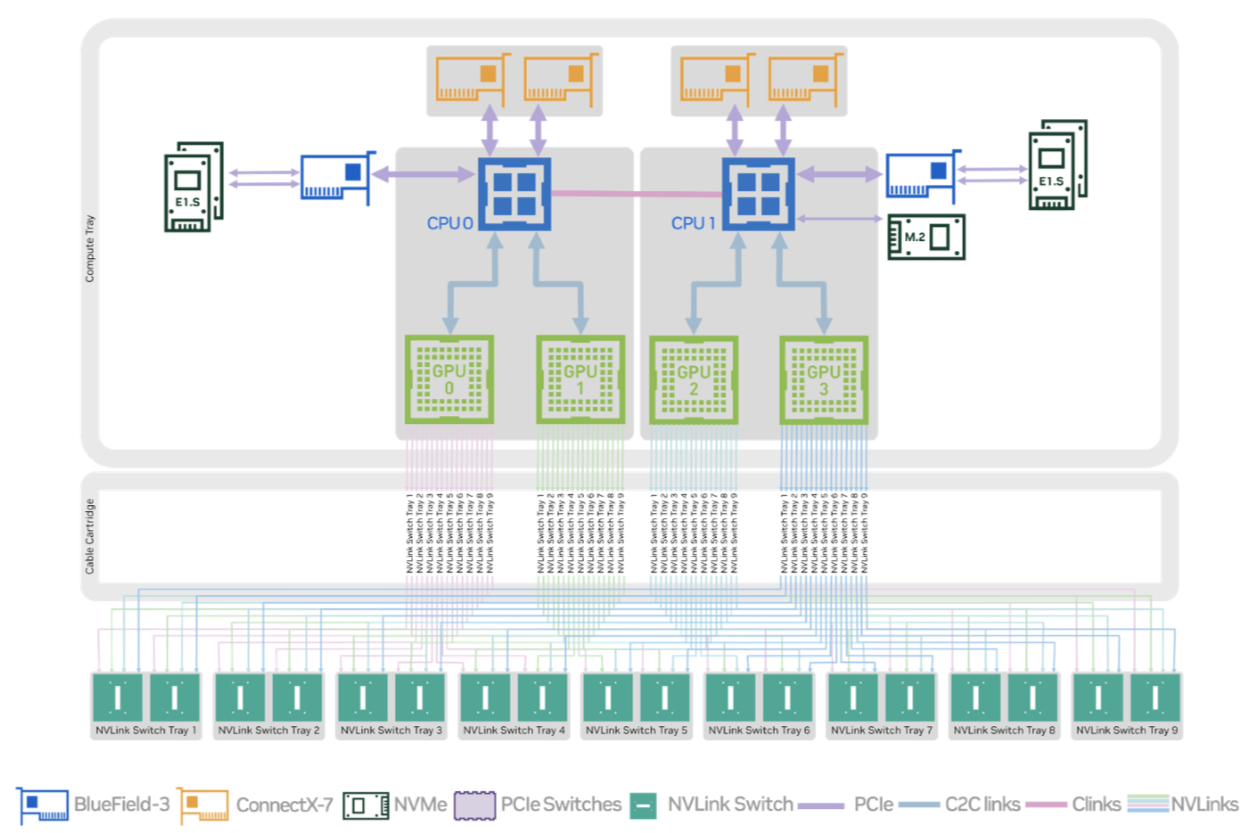
Figure 5 GB200 Compute Tray Block Diagram#
NVLink Switch Tray#
Each DGX GB200 NVL72system rack also features nine NVLink switches (AKA NVLink switch tray). All NVLink interconnections are done through the rear-side, blind-mate connectors to the cable cartridges within the rack. Each switch tray features two COMe RJ45 ports for NVOS and one BMC module for out-of-band management with one RJ45 port. Figure 6 showcases the front design of a NVLink Switch Tray.

Figure 6 GB200 Compute Tray Block Diagram#
DGX Power Shelves#
The power shelf used for DGX DGX GB200 SuperPOD has six 5.5kW PSUs configured as N redundancy and can deliver up to 33kW of power. There are eight total power shelves in a single DGX GB200 NVL72 rack system. At the rear of the power shelf is a set of RJ45 ports used for power brake and current sharing feature. The power shelves are daisy chained to each other using these RJ45 ports. At the front of the power shelf is the BMC port. Figure 7 shows the front of the power shelf.

Figure 7 Power Shelf#
NVIDIA InfiniBand Technology#
InfiniBand is a high-performance, low latency, RDMA capable networking technology, proven over 20 years in the harshest compute environments to provide the best inter-node network performance. InfiniBand continues to evolve and lead data center network performance.
The latest generation InfiniBand, NDR, has a peak speed of 400 Gbps per direction with an extremely low port-to-port latency. It is backwards compatible with the previous generations of InfiniBand specifications. InfiniBand is more than just peak bandwidth and low latency. It provides additional features to optimize performance including adaptive routing (AR), collective communication with SHARPTM, dynamic network healing with SHIELDTM, and supports several network topologies including fat-tree, Dragonfly, and multi-dimensional Torus to build the largest network fabrics and computer systems possible.
NVIDIA Mission Control#
The DGX GB200 SuperPOD Reference Architecture represents the best practices for building high-performance AI factories. There is flexibility in how these systems can be presented to customers and users. NVIDIA Mission Control software is used to manage all DGX GB200 SuperPOD deployments.
NVIDIA Mission Control is a sophisticated full-stack software solution. As an essential part of the DGX SuperPOD experience, it optimizes developer workload performance and resiliency, ensures continuous uptime with automated failure handling, and provides unified cluster-scale telemetry and manageability. Key features include full-stack resiliency, predictive maintenance, unified error reporting, data center optimizations, cluster health checks, and automated node management.
Mission Control software incorporates the same technology that NVIDIA uses to manage thousands of systems for our ad-winning data scientists and provides an immediate path to a TOP500 supercomputer for organizations that need the best of the best.
DGX SuperPOD is to be deployed on-premises, meaning the customer owns and manages the hardware. This can be within a customer’s data center or co-located at a commercial data center, but the customer owns the hardware, the service it provides, and is responsible for their cluster infrastructure as well as providing the building management system for integration.
Components#
The hardware components of DGX SuperPOD are described in Table 1. The software components are shown in Table 2.
Component |
Technology |
Description |
|---|---|---|
8x Compute Racks |
NVIDIA DGX GB200 NVL72 |
The world’s premier rack-scale, purpose-built AI systems featuring NVIDIA Grace-Blackwell GB200 modules. GB200 Superchips. NVL72 scale-out GPU interconnect and integrated NVLink switch trays. |
NVLink Fabric |
NVIDIA NVLink 5 |
NVLink Switches supports fast, direct memory access between GPUs on the same compute rack. |
Compute Fabric |
NVIDIA Quantum QM9700 InfiniBand switches |
Rail-optimized, non-blocking, full fat-tree network with eight NDR400 connections per system for cross rack GPU communications. |
Storage and In-band Management Fabric |
NVIDIA Spectrum 4 SN5600 Ethernet switches |
The fabric is optimized to match peak performance of the configured storage array, built with 64 port 800 Gbps Ethernet switch providing high port density with high performance. |
InfiniBand management |
NVIDIA Unified Fabric Manager Appliance, Enterprise Edition |
NVIDIA UFM combines enhanced, real-time network telemetry with AI powered cyber intelligence and analytics to manage scale-out InfiniBand data centers |
NVLink Management |
NVIDIA Network Manager eXperience (NMX) |
NVIDIA NMX manages, operates the NVLink switches and provides real-time network telemetry to manage all NVLink infrastructure |
Out-of-band (OOB) management network |
NVIDIA SN2201 switch |
48 x 1 Gbps Ethernet switch leveraging copper ports to minimize complexity |
Component |
Description |
|---|---|
Mission Control Software |
NVIDIA Mission Control software delivers a full stack data center solution engineered for NVIDIA DGX SuperPOD with DGX GB200 or DGX B200 infrastructure deployments. It integrates essential management and operational capabilities into a unified platform, thereby providing enterprise customers with simplified control over their NVIDIA DGX SuperPOD infrastructure deployments at scale. NVIDIA Mission Control also leverages NVIDIA Run;ai functionality, providing seamless workload orchestration. |
NVIDIA AI Enterprise |
NVIDIA AI Enterprise is an end-to-end, cloud-native software platform that accelerates data science pipelines and streamlines development and deployment of production-grade LLMs and other generative AI applications. |
Magnum IO |
Enables increased performance for AI and HPC |
NVIDIA NGC |
The NGC catalog provides a collection of GPU-optimized containers for AI and HPC |
Slurm |
A classic workload manager used to manage complex workloads in a multi-node, batch-style, compute environment |
Design Requirements#
DGX SuperPOD is designed to minimize system bottlenecks throughout the tightly coupled configuration to provide the best performance and application scalability. Each subsystem has been thoughtfully designed to meet this goal. In addition, the overall design remains flexible so that SuperPOD can be tailored to better integrate into existing data centers.
System Design#
DGX SuperPOD is optimized for a customers’ particular workload of multi-node AI and HPC applications:
A modular architecture based on Scalable Units (SUs) of 8 DGX GB200 systems.NVL72 rack systems.
A fully tested system scales to two SUs, but larger deployments can be built based on customer requirements
Rack-A fully tested system scales for a single SU, seamlessly.
level integrated design which allows rapid installation and deployment of liquid cooled, high density compute racks.
Storage partner equipment that has been certified to work in DGX SuperPOD environment.
Storage partner equipment that has been certified to work in DGX SuperPOD environments.
Full system support—including compute, storage, network, and software—is provided by NVIDIA Enterprise Support (NVEX).
Compute Fabric#
The compute fabric is rail-optimized to the top layer of the fabric.
The compute fabric is a balanced, full-fat tree.
The compute fabric is designed with current state-of-the-art, top performing, high-performance, low-latency network switches, and supports future generation of networking hardware.
Managed NDR switches are used throughout the design to provide better management of the fabric.
The fabric is designed to support the latest SHARPv3 features.
Storage Fabric (High Speed Storage)#
The storage fabric provides high bandwidth to shared storage. It also has the following characteristics:
It is independent of the compute fabric to maximize performance of both storage and application performance.
Provides single-node line-rate of 2x 200Gbps to each DGX GB200 compute tray.
Storage is provided over RDMA over Converged Ethernet to provide maximum performance and minimize CPU overhead.
User-accessible management nodes provide access to shared storage.
In-Band Management Network#
The in-band management network fabric is Ethernet-based and is used for node provisioning, data movement, Internet access, and other services that must be accessible by the users.
The in-band management network connections for compute and management nodes operate at 200 Gbps and are bonded for resiliency.
Out-of-Band Management Network#
The OOB management network connects all the baseboard management controllers (BMC), BlueField baseboard management controllers, NVSwitch Management Interfaces (COMe), as well as other devices that should be physically isolated from system users.
Storage Requirements#
The DGX SuperPOD compute architecture must be paired with a high-performance, balanced, storage system to maximize overall system performance. DGX SuperPOD is designed to use two separate storage systems, high-performance storage (HPS) and user storage, optimized for key operations of throughput, parallel I/O, as well as higher IOPS and metadata workloads.
High-Performance Storage#
High-Performance Storage is provided via RDMA over Converged Ethernet v2 (RoCEv2) connected storage from a DGX SuperPOD certified storage partner, and is engineered and tested with the following attributes in mind:
High-performance, resilient, POSIX-style file system optimized for multi-threaded read and write operations across multiple nodes.
Certified for Grace-based systems.
Native RoCE support.
Local system RAM for transparent caching of data.
Leverage local flash device transparently for read and write caching.
The specific storage fabric topology, capacity, and components are determined by the DGX SuperPOD certified storage partner as part of the DGX SuperPOD design process.
User Storage#
User Storage differs from High-Performance storage in that it exposes an NFS share on the in-band management fabric for multiple uses. It is typically used for “home directory” type usage (especially with clusters deployed with SLURM), administrative scratch space, and shared storage as needed by DGX SuperPOD components in a High Availability configuration (e.g., Mission Control), the requirement for log files collection, and system configuration files.
With that in mind, User Storage has the following requirements:
Designed for high metadata performance, IOPS, and key enterprise features such as log collection, data capacity. This is different than the HPS, which is optimized for parallel I/O and large capacity.
Communicate over Ethernet, using NFS.
100GbE DR1 Connectivity.
User storage in a DGX SuperPOD is often satisfied with existing NFS servers already deployed, such that a new export is created and made accessible to the DGX SuperPOD’s in-band management network. User Storage is therefore not described in detail in this DGX SuperPOD reference architecture.