DOCA DPA
Supported at beta level.
This chapter provides an overview and configuration instr uctions for DOCA DPA API.
The DOCA DPA library offers a programming model for offloading communication-centric user code to run on the DPA processor on NVIDIA® BlueField®-3 DPU. DOCA DPA provides a high-level programming interface to the DPA processor.
DOCA DPA enables the user to submit a function (called a kernel) that runs on the DPA processor. The user can choose to run the kernel with multiple threads .
DOCA DPA offers:
Support for the DPA subsystem, an offload engine that executes user-written kernels on a highly multi-threaded processor.
Full control on execution-ordering and notifications/synchronization of the DPA and host/DPU.
Abstractions for memory services.
Abstractions for remote communication primitives (integrated with remote event signaling).
C API for application developers.
DPACC is used to compile and link kernels with the DOCA DPA device library to get DPA applications that can be loaded from the host program to execute on the DPA (similar to CUDA usage with NVCC). For more information on DPACC, refer to the NVIDIA DOCA DPACC Compiler.
DOCA DPA applications can run either on the host machine or on the target DPU. Running on the host machine requires EU pre-configuration using the dpaeumgmt tool. For more information, please refer to NVIDIA DOCA DPA EU Management Tool.
Please refer to the NVIDIA DOCA Library APIs.
DOCA enables developers to program the DPA processor using both DOCA DPA library and a suite of other tools (mainly DPACC).
These are the main steps to start DPA offload programming:
Write DPA device code, or kernels, (.c files) with the __dpa_global__ keyword before function (see examples later).
Use DPACC to build a DPA program (i.e., a host library which contains an embedded device executable). Input for DPACC are kernels from the previous steps and DOCA DPA device library.
Build host executable using a host compiler (inputs for the host compiler are DPA program are generated in the previous step and the user application source files).
In your program, create a DPA context which then downloads the DPA executable to the DPA processor to allow invoking (launching) kernels from the host/DPU to run on the DPA.
DPACC is provided by the DOCA SDK installation . For more information, please refer to the NVIDIA DOCA DPACC Compiler.
Deployment View
DOCA DPA is composed of two libraries that come with the DOCA SDK installation:
Host/DPU library and header file (used by user application)
doca_dpa.h
libdoca_dpa.a/libdoca_dpa.so
Device library and header file
doca_dpa_dev.h
doca_dpa_dev_sync_event.h
doca_dpa_dev_buf_array.h
doca_dpa_dev_rdma.h
libdoca_dpa_dev.a
DPA Queries
Before invoking the DPA API, make sure that DPA is indeed supported on the relevant device.
The API that checks whether a device supports DPA is doca_error_t doca_devinfo_get_is_dpa_supported(const struct doca_devinfo *devinfo). Only if this call returns DOCA_SUCCESS can the user invoke DOCA DPA API on the device.
There is a limitation on the maximum number of DPA threads that can run a single kernel. This can be retrieved by calling the host API doca_error_t doca_dpa_get_max_threads_per_kernel(doca_dpa_t dpa, unsigned int *value).
Each kernel launched into the DPA has a maximum runtime limit. This can be retrieved by calling the host API doca_error_t doca_dpa_get_kernel_max_run_time(doca_dpa_t dpa, unsigned long long *value).
If the kernel execution time on the DPA exceeds this maximum runtime limit, it may be terminated and cause a fatal error. To recover, the application must destroy the DPA context and create a new one.
Overview of DOCA DPA Software Objects
|
Term |
Definition |
|
DPA context |
Software construct for the host process that encapsulates the state associated with a DPA process (on a specific device). An application must obtain a DPA context to begin working with the DPA API (several DPA contexts may be created by the application). |
|
Memory |
DOCA DPA provides an API to allocate/manage DPA memory, as well as handling host memory that has been exported to DPA. |
|
Sync Event |
Data structure in either CPU, DPU, GPU, or DPA-heap. An event contains a counter that can be updated and waited on. |
|
Kernel |
User function (and arguments) launched from host and executing on the DPA asynchronously. A kernel may be executed by one or more DPA threads (specified by the application as part of the launch API). |
|
RDMA |
Abstraction around a network transport object (encapsulates RDMA RC QP). Allows sending data to remote RDMA for example, and collect communication completions. |
The DOCA DPA SDK does not use any means of multi-thread synchronization primitives. All DOCA DPA objects are non-thread-safe. Developers should make sure the user program and kernels are written so as to avoid race conditions.
DPA Context
Context creation:
doca_error_t doca_dpa_create(struct doca_dev *dev, doca_dpa_app_t app, doca_dpa_t *dpa, unsigned int flags)
The DPA context encapsulates the DPA device and a DPA process (program). Within this context, the application creates various DPA SDK objects and controls them. After verifying DPA is supported for the chosen device, the DPA context is created. This is a host-side API and it is expected to be the first programming step.
The app parameter of this call is the same name used when running DPACC to get the DPA program.
Memory Subsystem
A DPA program can allocate (from the host API) and access (from both the host and device API) several memory locations using the DOCA DPA API. DOCA DPA supports access from the host/DPU to DPA heap memory and also enables device access to host memory (e.g., kernel writes to host heap).
Normal memory usage flow would be to:
Allocate memory on the host.
Register the memory.
Export the registered memory so it can be accessed by DPA kernels.
Access/use the memory from the kernel (see device side APIs later).
Host-side API
To free previously allocated DPA memory (if it exists):
doca_dpa_mem_free(doca_dpa_dev_uintptr_t dev_ptr)
To allocate DPA heap memory:
doca_dpa_mem_alloc(doca_dpa_t dpa, size_t size, doca_dpa_dev_uintptr_t *dev_ptr)
To copy previously allocated memory from a host pointer to a DPA heap device pointer:
doca_dpa_h2d_memcpy(doca_dpa_t dpa, doca_dpa_dev_uintptr_t src_ptr,
void*dst_ptr, size_t size)To copy previously allocated memory from a DPA heap device pointer to a host pointer:
doca_dpa_d2h_memcpy(doca_dpa_t dpa,
void*dst_ptr, doca_dpa_dev_uintptr_t src_ptr, size_t size)To set memory:
doca_dpa_memset(doca_dpa_t dpa, doca_dpa_dev_uintptr_t dev_ptr,
intvalue, size_t size)To export host memory to DPA and get a handle to use on your kernels, one must use a DOCA Core Memory Inventory Object in the following manner (refer to TBD DOCA Core Memory Subsystem API):
doca_buf_arr_set_target_dpa(struct doca_buf_arr *buf_arr, struct doca_dpa *dpa_handler) doca_buf_arr_get_dpa_handle(
conststruct doca_buf_arr *buf_arr, struct doca_dpa_dev_buf_arr **dpa_buf_arr)Use the output parameter (dpa handle) by passing it as kernel parameter in doca_dpa_kernel_launch(...) API.
Device-side API
Device APIs are used by user-written kernels. Memory APIs supplied by the DOCA DPA SDK are all asynchronous (i.e., non-blocking).
Kernels get the doca_dpa_dev_buf_t handle in their kernel and invoke the following API:
To obtain a single buffer handle from the buf array handle:
doca_dpa_dev_buf_t doca_dpa_dev_buf_array_get_buf(doca_dpa_dev_buf_arr_t buf_arr,
constuint64_t buf_idx)To get the address pointed to by the buffer handle:
uintptr_t doca_dpa_dev_buf_get_addr(doca_dpa_dev_buf_t buf)
To get the length of the buffer:
uint64_t doca_dpa_dev_buf_get_len(doca_dpa_dev_buf_t buf)
To get a pointer to external memory registered on the host:
doca_dpa_dev_uintptr_t doca_dpa_dev_buf_get_external_ptr(doca_dpa_dev_buf_t buf, uint64_t buf_offset)
To copy memory between two registered memory regions:
doca_dpa_dev_memcpy_nb(doca_dpa_dev_buf_t dst_mem, uint64_t dst_offset, doca_dpa_dev_buf_t src_mem, uint64_t src_offset, size_t length)
To transpose memory between two registered memory regions:
doca_dpa_dev_memcpy_transpose2D_nb(doca_dpa_dev_buf_t dst_mem, uint64_t dst_offset, doca_dpa_dev_buf_t src_mem, uint64_t src_offset, size_t length, size_t element_size, size_t num_columns, size_t num_rows)
Since memory operations in the device are non-blocking, developers are given the following API to drain all previous memory operations:
doca_dpa_dev_memcpy_synchronize()
Sync Events
Sync events fulfill the following roles:
DOCA DPA execution model is asynchronous and sync events are used to control various threads running in the system (allowing order and dependency)
DOCA DPA supports remote sync events so the programmer is capable of invoking remote nodes by means of DOCA sync events
Host-side API
Please refer to "DOCA Sync Event".
Device-side API
To get the current event value:
doca_dpa_dev_sync_event_get(doca_dpa_dev_sync_event_t event, uint64_t *value)
To add/set to the current event value:
doca_dpa_dev_sync_event_update_<add|set>(doca_dpa_dev_sync_event_t event, uint64_t value)
To wait until event is greater than threshold:
doca_dpa_dev_sync_event_wait_gt(doca_dpa_dev_sync_event_t event, uint64_t value, uint64_t mask)
Use mask to apply (bitwise AND) on the DOCA sync event value for comparison with the wait threshold.
Communication Model
DOCA DPA communication primitives allow sending data from one node to another. The communication object between two nodes is called an RDMA DPA handle. RDMAs represent a unidirectional communication pipe between two nodes. Currently, RDMA DPA handles are built on top of RDMA RC QP implementation. RDMA DPA handles can be used by kernels only. The RDMA DPA handle allows the DPA to track the completion of all communications since they are asynchronous.
RDMA DPA handles are created when setting a DOCA RDMA context to DPA data path. For more information, please refer to DOCA RDMA.
Host-side API
To obtain a DPA RDMA handle:
doca_ctx_set_datapath_on_dpa(doca_ctx rdma_as_doca_ctx ,doca_dpa_t dpa) doca_rdma_get_dpa_handle(struct doca_rdma *rdma, struct doca_dpa_dev_rdma **dpa_rdma)
DPA RDMAs are not thread-safe and, therefore, must not be used from different kernels/threads concurrently.
Device-side API
The flow in DOCA DPA begins with creation and configuration of an object on the host/DPU side and then exporting it to a device so the kernels and DPA can use v arious entities. This is no different for RDMA. After the host application connects two RDMAs, the local RDMA is exported to the device and can be used by the device-side API.
To read to a local buffer from the remote side buffer:
doca_dpa_dev_rdma_read(doca_dpa_dev_rdma_t rdma, doca_dpa_dev_buf_t dst_mem, uint64_t dst_offset, doca_dpa_dev_buf_t src_mem, uint64_t src_offset, size_t length)
To copy local memory to the remote side buffer:
doca_dpa_dev_rdma_write(doca_dpa_dev_rdma_t rdma, doca_dpa_dev_buf_t dst_mem, uint64_t dst_offset, doca_dpa_dev_buf_t src_mem, uint64_t src_offset, size_t length)
To do an atomic add operation on the remote side buffer:
doca_dpa_dev_rdma_atomic_fetch_add(doca_dpa_dev_rdma_t rdma, doca_dpa_dev_buf_t dst_mem, uint64_t dst_offset, size_t value)
To signal a remote event:
doca_dpa_dev_rdma_signal_<add|set>(doca_dpa_dev_rdma_t rdma, doca_dpa_dev_sync_event_remote_t remote_sync_event, uint64_t count)
As all DPA RDMA operations are non-blocking, the following API is provided to kernel developers to wait until all previous RDMA operations are done (blocking call) to drain the RDMA DPA handle:
doca_dpa_dev_rdma_synchronize(doca_dpa_dev_rdma_t rdma)
When this call returns, all previous non-blocking operations on the DPA RDMA have completed (i.e., sent to the remote RDMA). It is expected that the doca_dpa_dev_rdma_synchronize() call would use the same thread as the handle calls.
Since DPA RDMAs are non-thread safe, each DPA RDMA must be accessed by a single thread at any given time. If user launches a kernel that should be executed by more than one thread and this kernel includes RDMA communication, it is expected that a user will use array of RDMAs so that each RDMA will be accessed by single thread (each thread can access it's RDMA instance by using doca_dpa_dev_thread_rank() as its index in the array of RDMA handles).
When using the Remote Event Exchange API, void doca_dpa_dev_rdma_signal_<add|set>(..., doca_dpa_dev_event_remote_t event_handle, ...), within your kernel, note that event is a remote event. That is, an event created on the remote node and exported to a remote node (doca_dpa_event_dev_remote_export(event_handle)).
Limitations
DOCA DPA has only been enabled and tested with InfiniBand networking protocol.
RDMAs are not thread-safe.
Execution Model
DOCA DPA provides an API which enables full control for launching and monitoring kernels.
Understanding the following terms and concepts is important:
Thread – just as with modern operating systems, DOCA DPA provides a notion of sequential execution of programmer code in an "isolated" environment (i.e., variables which are thread-local and not global or shared between other threads). Moreover, DOCA DPA provides hardware threads which allow a dedicated execution pipe per thread without having the execution of one thread impact other ones (no preemption, priorities etc).
Kernel – this is a C function written by the programmer and compiled with DPACC that the programmer can invoke from their host application. Programmers can use the doca_dpa_kernel_launch_update_<add|set>(...) API to run their kernels. One of the parameters for this call is the number of threads to run this kernel (minimum is 1). So, for example, a programmer can launch their kernel and ask to run it with 16 threads.
Since DOCA DPA libraries are not thread-safe, it is up to the programmer to make sure the kernel is written to allow it to run in a multi-threaded environment. For example, to program a kernel that uses RDMAs with 16 concurrent threads, the user should pass an array of 16 RDMAs to the kernel so that each thread can access its RDMA using its rank (doca_dpa_dev_thread_rank()) as an index to the array.
Host-side API
doca_dpa_kernel_launch_update_<add|set>(doca_dpa_t dpa, struct doca_sync_event *wait_event, uint64_t wait_threshold, struct doca_sync_event *comp_event, uint64_t comp_count, unsigned int nthreads, doca_dpa_func_t *func, ... /* args */)
This function asks DOCA DPA to run func in DPA by nthreads and give it the supplied list of arguments (variadic list of arguments).
This function is asynchronous so when it returns, it does not mean that func started/ended its execution.
To add control or flow/ordering to these asynchronous kernels, two optional parameters for launching kernels are available:
wait_event – the kernel does not start its execution until the event is signaled (if NULL, the kernel starts once DOCA DPA has resources to run it) which means that DOCA DPA would not run the kernel until the event's counter is bigger than wait_threshold.
Please note that the valid values for wait_threshold and wait_event counter and are [0-254]. Values out of this range might cause anomalous behavior.
comp_event – once the last thread running the kernel is done, DOCA DPA updates this event (either sets or adds to its current counter value with comp_count).
DOCA DPA takes care of packing (on host/DPU) and unpacking (in DPA) the kernel parameters.
func must be prefixed with the __dpa_global__ macro for DPACC to compile it as a kernel (and add it to DPA executable binary) and not as part of host application binary.
The programmer must declare func in their application also by adding the line extern doca_dpa_func_t func.
Device-side API
-
unsigned
intdoca_dpa_dev_thread_rank()Retrieves the running thread's rank for a given kernel on the DPA. If, for example, a kernel is launched to run with 16 threads, each thread running this kernel is assigned a rank ranging from 0 to 15 within this kernel. This is helpful for making sure each thread in the kernel only accesses data relevant for its execution to avoid data-races.
-
unsigned
intdoca_dpa_dev_num_threads()Returns the number of threads running current kernel.
Examples
Linear Execution Example
Kernel code:
#include "doca_dpa_dev.h"
#include "doca_dpa_dev_sync_event.h"
__dpa_global__ void
linear_kernel(doca_dpa_dev_sync_event_t wait_ev, doca_dpa_dev_sync_event_t comp_ev)
{
if (wait_ev)
doca_dpa_dev_sync_event_wait_gt(wait_ev, wait_th = 0);
doca_dpa_dev_sync_event_update_add(comp_ev, comp_count = 1);
}
Application pseudo-code:
#include <doca_dev.h>
#include <doca_error.h>
#include <doca_sync_event.h>
#include <doca_dpa.h>
int main(int argc, char **argv)
{
/*
A
|
B
|
C
*/
/* Open DOCA device */
open_doca_dev(&doca_dev);
/* Create doca dpa conext */
doca_dpa_create(doca_dev, dpa_linear_app, &dpa_ctx, 0);
/* Create event A - subscriber is DPA and publisher is CPU */
doca_sync_event_create(&ev_a);
doca_sync_event_publisher_add_location_cpu(ev_a, doca_dev);
doca_sync_event_subscriber_add_location_dpa(ev_a, dpa_ctx);
doca_sync_event_start(ev_a);
/* Create event B - subscriber and publisher are DPA */
doca_sync_event_create(&ev_b);
doca_sync_event_publisher_add_location_dpa(ev_b, dpa_ctx);
doca_sync_event_subscriber_add_location_dpa(ev_b, dpa_ctx);
doca_sync_event_start(ev_b);
/* Create event C - subscriber and publisher are DPA */
doca_sync_event_create(&ev_c);
doca_sync_event_publisher_add_location_dpa(ev_c, dpa_ctx);
doca_sync_event_subscriber_add_location_dpa(ev_c, dpa_ctx);
doca_sync_event_start(ev_c);
/* Create completion event for last kernel - subscriber is CPU and publisher is DPA */
doca_sync_event_create(&comp_ev);
doca_sync_event_publisher_add_location_dpa(comp_ev, dpa_ctx);
doca_sync_event_subscriber_add_location_cpu(comp_ev, doca_dev);
doca_sync_event_start(comp_ev);
/* Export kernel events and acquire their handles */
doca_sync_event_export_to_dpa(ev_b, dpa_ctx, &ev_b_handle);
doca_sync_event_export_to_dpa(ev_c, dpa_ctx, &ev_c_handle);
doca_sync_event_export_to_dpa(comp_ev, dpa_ctx, &comp_ev_handle);
/* Launch kernels */
doca_dpa_kernel_launch_update_add(wait_ev = ev_a, wait_threshold = 1, &linear_kernel, kernel_args:
NULL, ev_b_handle);
doca_dpa_kernel_launch_update_add(wait_ev = NULL, &linear_kernel, nthreads = 1, kernel_args:
ev_b_handle, ev_c_handle);
doca_dpa_kernel_launch_update_add(wait_ev = NULL, &linear_kernel, nthreads = 1, kernel_args:
ev_c_handle, comp_ev_handle);
/* Update host event to trigger kernels to start executing in a linear manner */
doca_sync_event_update_set(ev_a, 1)
/* Wait for completion of last kernel */
doca_sync_event_wait_gt(comp_ev, 0);
/* Tear Down... */
teardown_resources();
}
Diamond Execution Example
Kernel code:
#include "doca_dpa_dev.h"
#include "doca_dpa_dev_sync_event.h"
__dpa_global__ void
diamond_kernel(doca_dpa_dev_sync_event_t wait_ev, uint64_t wait_th, doca_dpa_dev_sync_event_t comp_ev1, doca_dpa_dev_sync_event_t comp_ev2)
{
if (wait_ev)
doca_dpa_dev_sync_event_wait_gt(wait_ev, wait_th);
doca_dpa_dev_sync_event_update_add(comp_ev1, comp_count = 1);
if (comp_ev2) // can be 0 (NULL)
doca_dpa_dev_sync_event_update_add(comp_ev2, comp_count = 1);
}
Application pseudo-code:
#include <doca_dev.h>
#include <doca_error.h>
#include <doca_sync_event.h>
#include <doca_dpa.h>
int main(int argc, char **argv)
{
/*
A
/ \
C B
/ /
D /
\ /
E
*/
/* Open DOCA device */
open_doca_dev(&doca_dev);
/* Create doca dpa conext */
doca_dpa_create(doca_dev, dpa_diamond_app, &dpa_ctx, 0);
/* Create root event A that will signal from the host the rest to start */
doca_sync_event_create(&ev_a);
// set publisher to CPU, subscriber to DPA and start event
/* Create events B,C,D,E */
doca_sync_event_create(&ev_b);
doca_sync_event_create(&ev_c);
doca_sync_event_create(&ev_d);
doca_sync_event_create(&ev_e);
// for events B,C,D,E, set publisher & subscriber to DPA and start event
/* Create completion event for last kernel */
doca_sync_event_create(&comp_ev);
// set publisher to DPA, subscriber to CPU and start event
/* Export kernel events and acquire their handles */
doca_sync_event_export_to_dpa(&ev_b_handle, &ev_c_handle, &ev_d_handle, &ev_e_handle, &comp_ev_handle);
/* wait threshold for each kernel is the number of parent nodes */
constexpr uint64_t wait_threshold_one_parent {1};
constexpr uint64_t wait_threshold_two_parent {2};
/* launch diamond kernels */
doca_dpa_kernel_launch_update_set(wait_ev = ev_a, wait_threshold = 1, nthreads = 1, &diamond_kernel, kernel_args:
NULL, 0, ev_b_handle, ev_c_handle);
doca_dpa_kernel_launch_update_set(wait_ev = NULL, nthreads = 1, &diamond_kernel, kernel_args:
ev_b_handle, wait_threshold_one_parent, ev_e_handle, NULL);
doca_dpa_kernel_launch_update_set(wait_ev = NULL, nthreads = 1, &diamond_kernel, kernel_args:
ev_c_handle, wait_threshold_one_parent, ev_d_handle, NULL);
doca_dpa_kernel_launch_update_set(wait_ev = NULL, nthreads = 1, &diamond_kernel, kernel_args:
ev_d_handle, wait_threshold_one_parent, ev_e_handle, NULL);
doca_dpa_kernel_launch_update_set(wait_ev = NULL, nthreads = 1, &diamond_kernel, kernel_args:
ev_e_handle, wait_threshold_two_parent, comp_ev_handle, NULL);
/* Update host event to trigger kernels to start executing in a diamond manner */
doca_sync_event_update_set(ev_a, 1);
/* Wait for completion of last kernel */
doca_sync_event_wait_gt(comp_ev, 0);
/* Tear Down... */
teardown_resources();
}
Performance Optimizations
The time interval between a kernel launch call from the host and the start of its execution on the DPA is significantly optimized when the host application calls doca_dpa_kernel_launch_update_<add|set>() repeatedly to execute with the same number of DPA threads. So, if the application calls doca_dpa_kernel_launch_update_<add|set>(..., nthreads = x), the next call with nthreads = x would have a shorter latency (as low as ~5-7 microseconds) for the start of the kernel's execution.
Applications calling for kernel launch with a wait event (i.e., the completion event of a previous kernel) also have significantly lower latency in the time between the host launching the kernel and the start of the execution of the kernel on the DPA. So, if the application calls doca_dpa_kernel_launch_update_<add|set>( ..., completion event = m_ev, ...) and then doca_dpa_kernel_launch_update_<add|set>( wait event = m_ev, ...), the latter kernel launch call would have shorter latency (as low as ~3 microseconds) for the start of the kernel's execution.
Limitations
The order in which kernels are launched is important. If an application launches K1 and then K2, K1 must not depend on K2's completion (e.g., wait on its wait event that K2 should update).
Not following this guideline leads to unpredictable results (at runtime) for the application and might require restarting the DOCA DPA context (i.e., destroying, reinitializing, and rerunning the workload).
DPA threads are an actual hardware resource and are, therefore, limited in number to 256 (including internal allocations and allocations explicitly requested by the user as part of the kernel launch API)
DOCA DPA does not check these limits. It is up to the application to adhere to this number and track thread allocation across different DPA contexts.
Each doca_dpa_dev_rdma_t consumes one thread.
The DPA has an internal watchdog timer to make sure threads do not block indefinitely. Kernel execution time must be finite and not exceed the time returned. by doca_dpa_get_kernel_max_run_time.
The nthreads parameter in the doca_dpa_kernel_launch call cannot exceed the maximum allowed number of threads to run a kernel returned. by doca_dpa_get_max_threads_per_kernel.
Logging
The following device-side API (to be used in kernels) supports logging to stdout:
doca_dpa_dev_printf(const char *format, ...)
Error Handling
DPA context can enter an error state caused by the device flow. The application can check this error state by calling the following host API call:
doca_dpa_peek_at_last_error(const doca_dpa_t dpa)
This data path call indicates if an error occurred on device. If so, the DPA context enters a fatal state and can no longer be used by the application. Therefore, the application must destroy the DPA context.
Procedure Outline
Write DPA device code (i.e., kernels or .c files).
Use DPACC to build a DPA program (i.e., a host library which contains an embedded device executable). Input for DPACC:
Kernels from step 1.
DOCA DPA device library.
Build host executable using a host compiler. Input for the host compiler:
DPA program.
User host application .c/.cpp files.
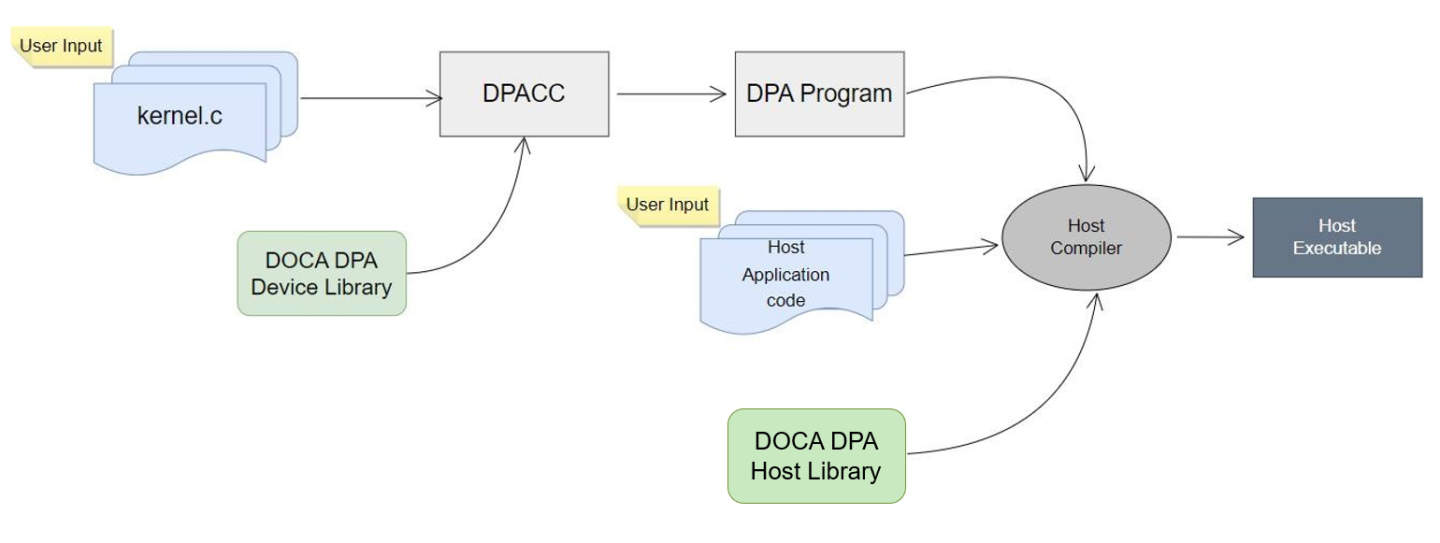
Procedure Steps
The following code snippets show a very basic DPA code that eventually prints "Hello World" to stdout.
Prepare kernel code:
#include
"doca_dpa_dev.h"__dpa_global__voidhello_world_kernel(void) { doca_dpa_dev_printf("Hello World\n"); }Prepare application code:
#include <stdio.h> #include <unistd.h> #include <doca_dev.h> #include <doca_error.h> #include
"doca_dpa.h"/*** A struct that includes all needed info on registered kernels and is initialized during linkage by DPACC.* Variable name should be the token passed to DPACC with --app-name parameter.*/extern doca_dpa_app_t dpa_hello_world_app;/*** kernel declaration that the user must declare for each kernel and DPACC is responsible to initialize.* Only then, user can use this variable in the kernel launch API as follows:* doca_dpa_kernel_launch_update_set(..., &hello_world_kernel, ...);*/doca_dpa_func_t hello_world_kernel;intmain(intargc,char**argv) {/* local variables... *//* Open doca device */printf("\n----> Open DOCA device\n");/* Open appropriate DOCA device doca_dev... *//* Create doca_dpa context */printf("\n----> Create DOCA DPA context\n"); doca_dpa_create(doca_dev, dpa_hello_world_app, &doca_dpa,0);/* Create a CPU event that will be signaled when kernel is finished */printf("\n----> Create DOCA Sync event\n"); doca_sync_event_create(&cpu_event); doca_sync_event_publisher_add_location_dpa(cpu_event, doca_dpa); doca_sync_event_subscriber_add_location_cpu(cpu_event, doca_dev); doca_sync_event_start(cpu_event);/* Kernel launch */printf("\n----> Launch hello_world_kernel\n"); doca_dpa_kernel_launch_update_set(doca_dpa, NULL,0, cpu_event,1,1, &hello_world_kernel);/* Waiting for completion of kernel launch */printf("\n----> Waiting for hello_world_kernel to finish\n"); doca_sync_event_wait_gt(cpu_event,0,0xFFFFFFFFFFFFFFFF);/* Tear down */printf("\n----> Destroy DOCA Sync event\n"); doca_sync_event_destroy(cpu_event); printf("\n----> Destroy DOCA DPA context\n"); doca_dpa_destroy(doca_dpa); printf("\n----> Destroy DOCA device\n"); doca_dev_close(doca_dev); printf("\n----> DONE!\n");return0; }Build DPA program:
/opt/mellanox/doca/tools/dpacc \ libdoca_dpa_dev.a \ kernel.c \ -o dpa_program.a \ -hostcc=gcc \ -hostcc-options=
"-Wno-deprecated-declarations"\ --devicecc-options="-D__linux__ -Wno-deprecated-declarations"\ --app-name="dpa_hello_world_app"\ -I/opt/mellanox/doca/include/Build host application:
gcc hello_world.c -o hello_world \ dpa_program.a libdoca_dpa.a \ -I/opt/mellanox/doca/include/ \ -DDOCA_ALLOW_EXPERIMENTAL_API \ -L/opt/mellanox/doca/lib/x86_64-linux-gnu/ -ldoca_common \ -L/opt/mellanox/flexio/lib/ -lflexio \ -lstdc++ -libverbs -lmlx5
Execution:
$ ./hello_world mlx5_0 *********************************************** ********** Hello World Example ********** *********************************************** ----> Open DOCA device ----> Create DOCA DPA context ----> Create DOCA Sync event ----> Launch hello_world_kernel ----> Waiting
forhello_world_kernel to finish ----> Destroy DOCA Sync event /7/Hello World ----> Destroy DOCA DPA context ----> Destroy DOCA device ----> DONE!
This section provides DPA sample implementation on top of the BlueField-3 DPU.
DPA Sample Prerequisites
The BlueField-3 DPU's link layer must be configured to InfiniBand, and it must also be set to operate in DPU mode.
Running DPA Sample
Refer to the following documents:
NVIDIA DOCA Installation Guide for Linux for details on how to install BlueField-related software.
NVIDIA DOCA Troubleshooting Guide for any issue you may encounter with the installation, compilation, or execution of DOCA samples.
To build a given sample:
cd /opt/mellanox/doca/samples/doca_dpa/<sample_name> meson /tmp/build ninja -C /tmp/build
The binary doca_<sample_name> will be created under /tmp/build/.
Sample (e.g., dpa_kernel_launch) usage:
Usage: doca_dpa_kernel_launch [DOCA Flags] [Program Flags] DOCA Flags: -h, --help Print a help synopsis -v, --version Print program version information -l, --log-level Set the (numeric) log level
forthe program <10=DISABLE,20=CRITICAL,30=ERROR,40=WARNING,50=INFO,60=DEBUG,70=TRACE> --sdk-log-level Set the SDK (numeric) log levelforthe program <10=DISABLE,20=CRITICAL,30=ERROR,40=WARNING,50=INFO,60=DEBUG,70=TRACE> -j, --json <path> Parse all command flags from an input json file Program Flags: -d, --device <IB device name> IB device name that supports DPA (optional). If not provided then a random IB device will be chosenFor additional information per sample, use the -h option:
/tmp/build/doca_<sample_name> -h
Samples
DPA Kernel Launch
This sample illustrates how to launch a DOCA DPA kernel with a completion event.
The sample logic includes:
Allocating DOCA DPA resources.
Initializing completion event for the DOCA DPA kernel.
Running hello_world DOCA DPA kernel that prints "Hello from kernel".
Waiting on completion event of the kernel.
Destroying the event and resources.
Reference:
/opt/mellanox/doca/samples/doca_dpa/dpa_kernel_launch/dpa_kernel_launch_main.c
/opt/mellanox/doca/samples/doca_dpa/dpa_kernel_launch/host/dpa_kernel_launch_sample.c
/opt/mellanox/doca/samples/doca_dpa/dpa_kernel_launch/device/dpa_kernel_launch_kernels_dev.c
/opt/mellanox/doca/samples/doca_dpa/dpa_kernel_launch/meson.build
/opt/mellanox/doca/samples/doca_dpa/dpa_common.h
/opt/mellanox/doca/samples/doca_dpa/dpa_common.c
/opt/mellanox/doca/samples/doca_dpa/build_dpacc_samples.sh
DPA Wait Kernel Launch
This sample illustrates how to launch a DOCA DPA kernel with wait and completion events.
The sample logic includes:
Allocating DOCA DPA resources.
Initializing wait and completion events for the DOCA DPA kernel.
Running hello_world DOCA DPA kernel that waits on the wait event.
Running a separate thread that triggers the wait event.
hello_world DOCA DPA kernel prints "Hello from kernel".
Waiting for the completion event of the kernel.
Destroying the events and resources.
Reference:
/opt/mellanox/doca/samples/doca_dpa/dpa_wait_kernel_launch/dpa_wait_kernel_launch_main.c
/opt/mellanox/doca/samples/doca_dpa/dpa_wait_kernel_launch/host/dpa_wait_kernel_launch_sample.c
/opt/mellanox/doca/samples/doca_dpa/dpa_wait_kernel_launch/device/dpa_wait_kernel_launch_kernels_dev.c
/opt/mellanox/doca/samples/doca_dpa/dpa_wait_kernel_launch/meson.build
/opt/mellanox/doca/samples/doca_dpa/dpa_common.h
/opt/mellanox/doca/samples/doca_dpa/dpa_common.c
/opt/mellanox/doca/samples/doca_dpa/build_dpacc_samples.sh
DPA Binary Tree
This sample illustrates how to launch multiple DOCA DPA kernels in a binary tree pattern.
The sample logic includes:
Allocating DOCA DPA resources.
Initializing wait and completion events for the DOCA DPA kernels.
Running 7 DOCA DPA kernels, such that each kernel (except the first) waits on the parent kernel in a binary tree-like pattern.
Waiting on all 7 completion events (completion event for each kernel).
Destroying the events and resources.
Reference:
/opt/mellanox/doca/samples/doca_dpa/dpa_binary_tree/dpa_binary_tree_main.c
/opt/mellanox/doca/samples/doca_dpa/dpa_binary_tree/host/dpa_binary_tree_sample.c
/opt/mellanox/doca/samples/doca_dpa/dpa_binary_tree/device/dpa_binary_tree_kernels_dev.c
/opt/mellanox/doca/samples/doca_dpa/dpa_binary_tree/meson.build
/opt/mellanox/doca/samples/doca_dpa/dpa_common.h
/opt/mellanox/doca/samples/doca_dpa/dpa_common.c
/opt/mellanox/doca/samples/doca_dpa/build_dpacc_samples.sh
DPA Diamond Tree
This sample illustrates how to launch multiple DOCA DPA kernels in a diamond tree-like pattern.
The sample logic includes:
Allocating DOCA DPA resources.
Initializing wait and completion events for the DOCA DPA kernel.
Running 4 kernels, such that each kernel (except the first) waits on the parent kernel in a diamond tree-like pattern.
Waiting on the completion event of the last kernel.
Destroying the events and resources.
Reference:
/opt/mellanox/doca/samples/doca_dpa/dpa_diamond_tree/dpa_diamond_tree_main.c
/opt/mellanox/doca/samples/doca_dpa/dpa_diamond_tree/host/dpa_diamond_tree_sample.c
/opt/mellanox/doca/samples/doca_dpa/dpa_diamond_tree/device/dpa_diamond_tree_kernels_dev.c
/opt/mellanox/doca/samples/doca_dpa/dpa_diamond_tree/meson.build
/opt/mellanox/doca/samples/doca_dpa/dpa_common.h
/opt/mellanox/doca/samples/doca_dpa/dpa_common.c
/opt/mellanox/doca/samples/doca_dpa/build_dpacc_samples.sh
DPA RDMACopy
This sample illustrates how to perform RDMA copy using DOCA DPA kernels and DOCA DPA RDMAs. This sample launches another thread considered to be a "remote thread" to copy to (the thread is not actually remote as the main process spawns it).
To avoid confusion, the main process is referred to as the "main thread".
The goal is to illustrate how the main thread can copy a buffer (in this example, an integer) to the remote thread's memory.
The sample logic includes:
The main thread allocating DOCA DPA resources.
The main thread creating DOCA DPA events for wait and completion of DOCA DPA kernels, and another event for communication with the remote thread.
Launching the remote thread.
The main thread preparing the DOCA DPA RDMA resources, registering the buffer to copy as a DOCA DPA host memory, and signaling (using the communication event) to the remote thread that it is ready.
The remote thread preparing the DOCA DPA RDMA resources, registering a buffer to copy to it as a DOCA DPA host memory, and signaling (using the communication event) to the main thread that it is ready.
The main and remote threads connecting to each other's RDMAs.
The main thread launching a DOCA DPA kernel that copies the main thread's buffer to the remote thread's buffer.
The DOCA DPA kernel synchronizing the RDMA and finishing.
The main thread waiting on the completion event of the kernel.
The main thread signaling to the remote event that the copy has finished.
The remote thread destroying its resources and joining the main thread.
The main thread destroying the events and resources.
Reference:
/opt/mellanox/doca/samples/doca_dpa/dpa_rdma_copy/dpa_rdma_copy_main.c
/opt/mellanox/doca/samples/doca_dpa/dpa_rdma_copy/host/dpa_rdma_copy_sample.c
/opt/mellanox/doca/samples/doca_dpa/dpa_rdma_copy/device/dpa_rdma_copy_kernels_dev.c
/opt/mellanox/doca/samples/doca_dpa/dpa_rdma_copy/meson.build
/opt/mellanox/doca/samples/doca_dpa/dpa_common.h
/opt/mellanox/doca/samples/doca_dpa/dpa_common.c
/opt/mellanox/doca/samples/doca_dpa/build_dpacc_samples.sh