DOCA Erasure Coding
This guide provides instructions on how to use the DOCA Erasure Coding API .
This library is currently supported at alpha version.
The DOCA Erasure Coding ( known also as forward error correction or FEC) library provides an API to encode and decode data using hardware acceleration, supporting both host and NVIDIA® BlueField®-3 (and higher) DPU memory regions.
DOCA Erasure Coding recovers lost data fragments by creating generic redundancy fragments (backup). Each redundancy block that the library creates can help recover any block in the original data should a total loss of fragment occur. This increases data redundancy and reduces data overhead.
The library provides an API for executing erasure coding (EC) operations on DOCA buffers residing in either the DPU or host memory.
This document is intended for software developers wishing to accelerate their application's EC memory operations.
Glossary
Familiarize yourself with the following terms to better understand the information in this document:
|
Term |
Definition |
|
Data |
Original data, original blocks, blocks of original data to be protected/preserved |
|
Coding matrix |
Coefficients, the matrix used to generate the redundancy blocks and recovery |
|
Redundancy blocks |
Codes; encoded data; the extra blocks that help recover data loss |
|
Encoding |
The process of creating the redundancy blocks. Encoded data is referred to as the original blocks or redundancy blocks. |
|
Decoding |
The process of recovering the data. Decoded data is referred to as the original blocks alone. |
DOCA Erasure Coding library follows the architecture of a DOCA Core Context, it is recommended read the following sections before:
DOCA Erasure Coding-based applications can run either on the host machine or on the DPU target (NVIDIA® BlueField®-3 and above).
Erasure Coding can only be run with DPU configured in DPU mode as described in NVIDIA BlueField DPU Modes of Operation.
DOCA Erasure Coding is a DOCA Context as defined by DOCA Core. This library leverages the DOCA Core architecture to expose asynchronous tasks/events that are offloaded to hardware.
The following diagram presents a high-level view of the EC transmission flow:
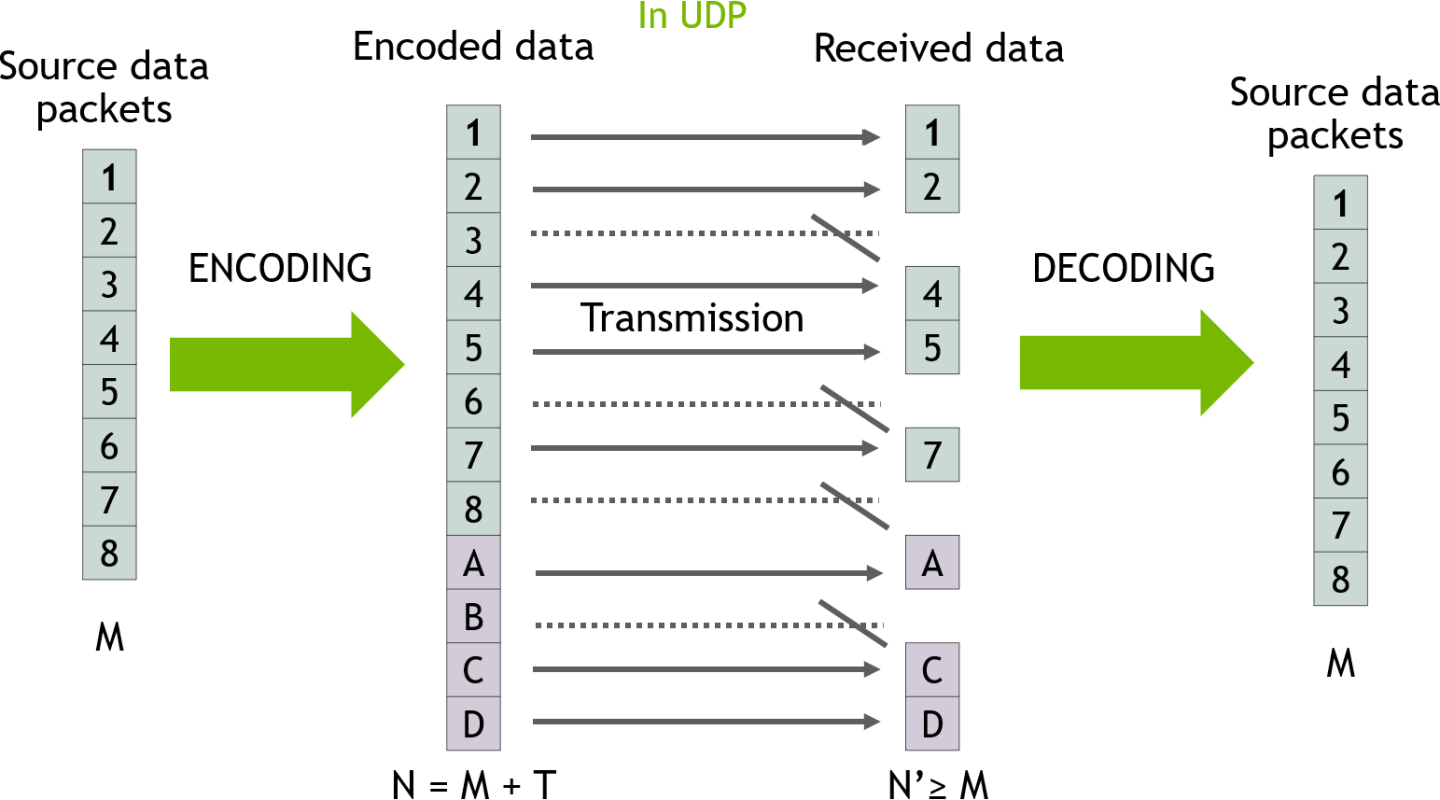
M packets are sent from the source (8 in this case).
Before the source send them, the source encode the data by adding to it T redundancy packets (4 in this case).
The packets are transmitted to the destination in UDP protocol. Some packets are lost and N' packets are received (in this case 4 packets are lost and 8 are received).
The destination decodes the data using all the packets available (both original data in green and redundancy data in red) and gets back the M original data packets.
Flows
Regular EC flow consists of the following elements:
Creating redundancy blocks from data (EC create).
Updating redundancy blocks from updated data (EC update).
Recovering data blocks from redundancy blocks (EC recover).
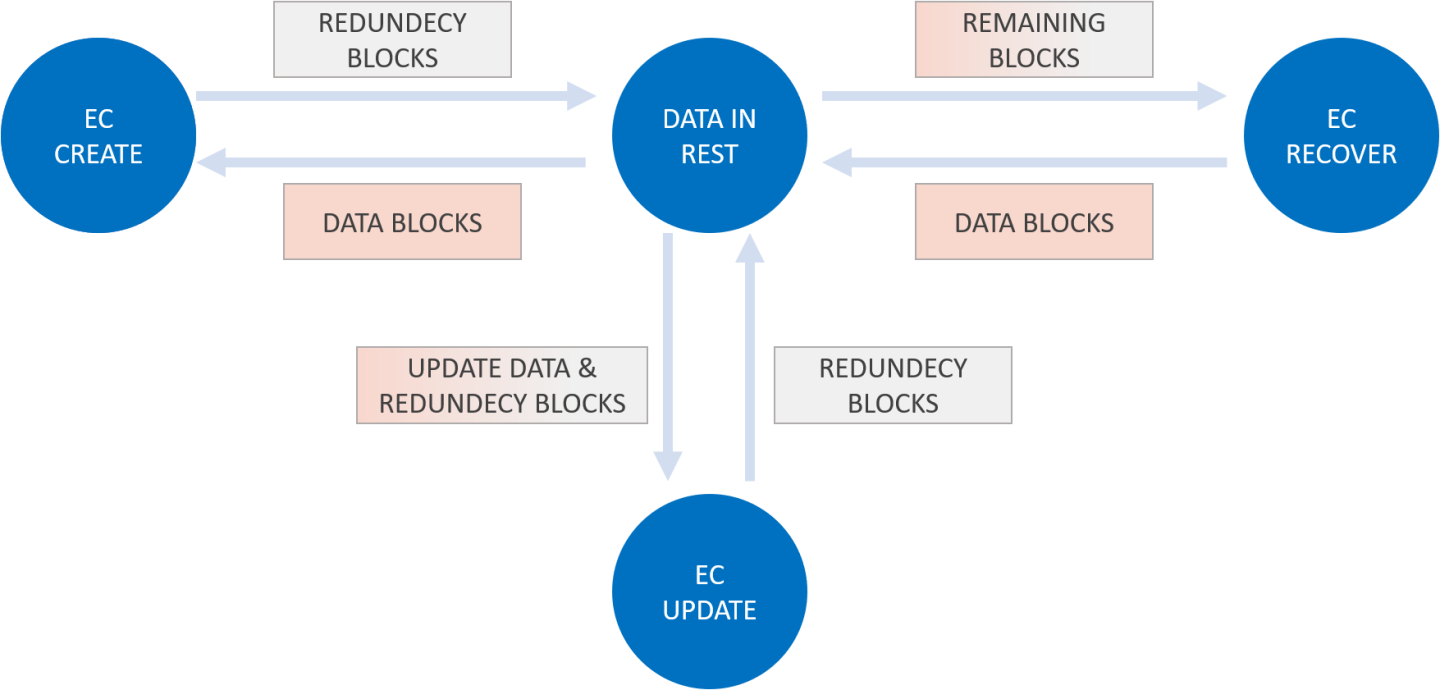
The following sections examine an M:K (where M is the original data and K is redundancy) EC.
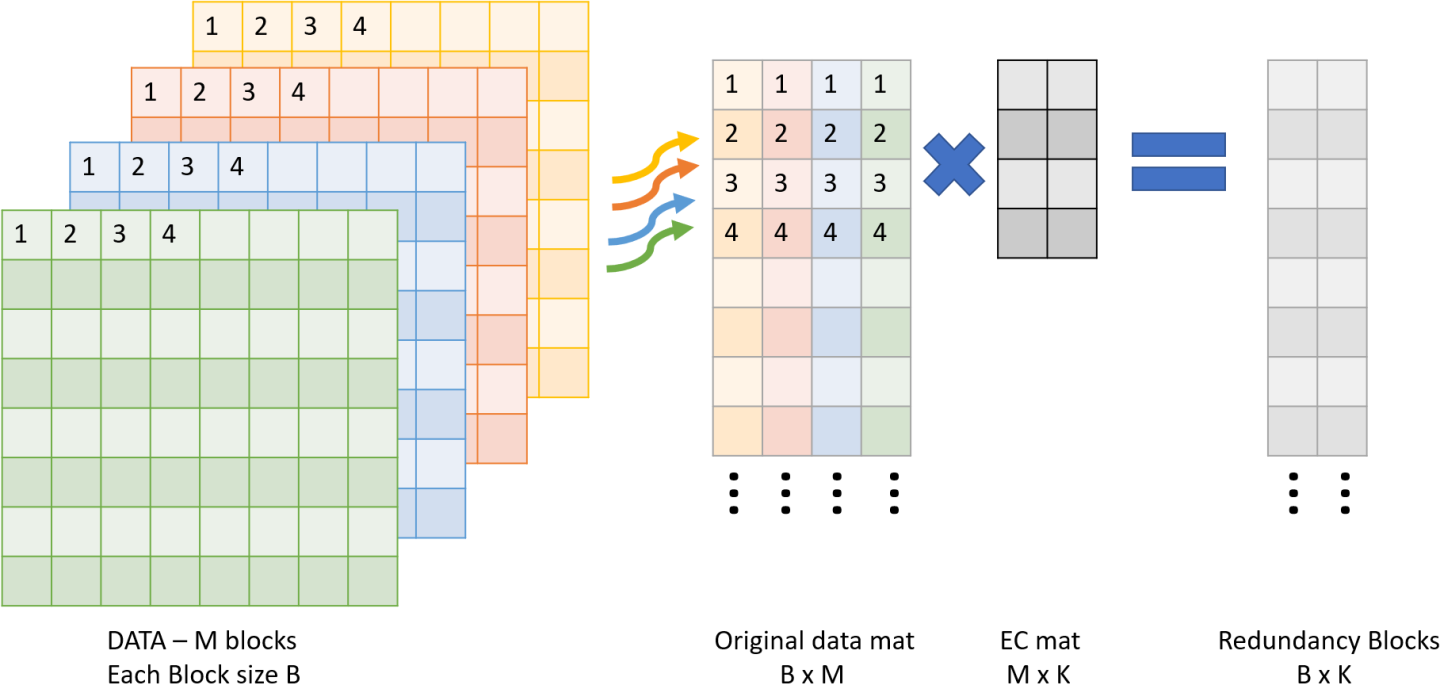
Create Redundancy Blocks
The user must perform the following:
Input M data blocks via doca_buf (filled with data, each block size B)
Output K empty blocks via doca_buf (each block size B)
Use DOCA Erasure Coding to create a coding matrix of M by K via doca_buf.
Use DOCA Erasure Coding Create task to get the K output redundancy blocks.
WarningThis step can be repeated in a stream use case, as the DPU would not be the recovery or update point.
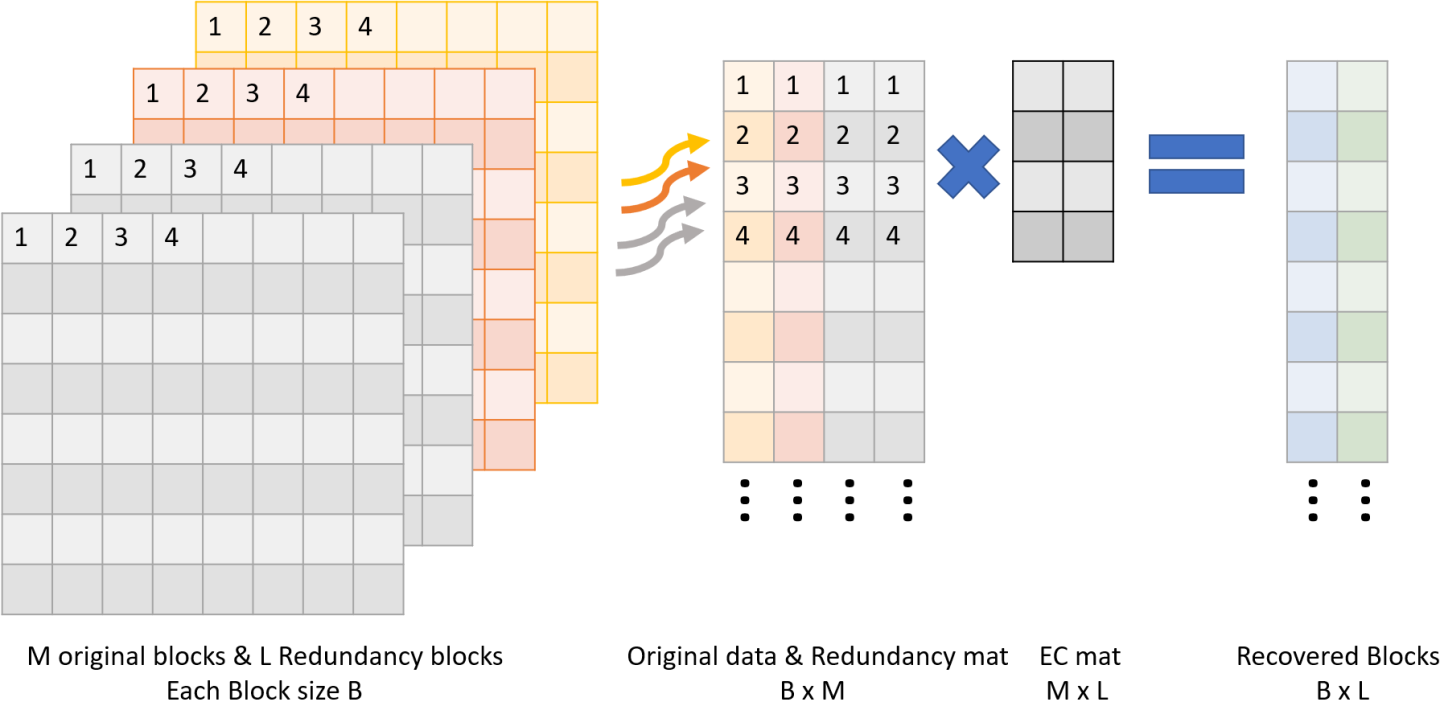
Recover Block
The user must perform the following:
Input M-L original blocks via doca_buf (blocks that weren't impaired).
Input L≤K (any) redundancy blocks via doca_buf (redundancy blocks originating from create \ update tasks).
Input bitmask or array, indicating which blocks to recover.
Output L empty blocks via doca_buf (same size of data block).
Use DOCA Erasure Coding to create a recover coding matrix of M by L via doca_buf (unique per bitmask).
Use DOCA Erasure Coding Recover task to get the L output recovered data blocks.
Objects
Device and Device Representor
The DOCA Erasure Coding library requires a DOCA device to operate. The device is used to access memory and perform the encoding and decoding operations. See DOCA Core Device Discovery.
For same Bluefield card, it does not matter which device is used (PF/VF/SF), as all these devices utilize the same HW component. In case there are multiple cards, then it is possible to create an EC instance per card, providing each instance with a device from a different card.
For accessing memory that is not local (from Host to DPU and vice versa), the DPU side of the application will need to pick a device with appropriate representor. See DOCA Core Device Representor Discovery
The device must stay valid until the EC instance is destroyed.
Memory Buffers
Executing any DOCA EC task requires two DOCA buffers, a source buffer and a destination buffer.
Depending on the allocation pattern of the buffers, refer to the Inventory Types table.
Buffers must not be modified or read during the execution of any task.
To start using the library, first, you need to go through a configuration phase as described in DOCA Core Context Configuration Phase.
This section describes how to configure and start the context, to allow execution of tasks and retrieval of events.
Configurations
The context can be configured to match the application use case.
To find if a configuration is supported, or what the min/max value, please refer to Device Support.
Mandatory Configurations
These configurations are mandatory and must be set by the application before attempting to start the context:
At least 1 task/event type needs to be configured. See configuration of Tasks.
A device with appropriate support must be provided on creation.
Device Support
DOCA Erasure Coding needs a device to operate. For picking a device, see DOCA Core Device Discovery.
Erasure Coding can be used in BlueField-3 with some limitations (see architecture). Any device can be used PF/VF/SF.
As device capabilities may change in the future, it is recommended to choose your device using the following methods:
doca_ec_cap_task_galois_mul_is_supported
doca_ec_cap_task_create_is_supported
doca_ec_cap_task_update_is_supported
doca_ec_cap_task_recover_is_supported
Some devices can allow different capabilities as follows:
The maximum buffer list length
The maximum block size
Current BlueField-3 limitations:
Data block count range: 1-128
Redundancy block count: 1-32
Block size: 64B-128MB
Buffer Support
Tasks support buffers with the following features:
|
Buffer Type |
Source Buffer |
Destination Buffer |
|
Linked list buffer |
Depends on the device; check the max_buf_list_len capability |
No |
|
Local mmap buffer |
Yes |
Yes |
|
Mmap from PCIe export buffer |
Yes |
Yes |
|
Mmap from RDMA export buffer |
No |
No |
This section describes execution on CPU or DPU using the DOCA Core Progress Engine .
Matrix Generate
All tasks require a coding matrix.
Create
An encoding matrix is necessary for executing the create task, to create redundancy blocks.
The matrices used for updates and recovery are based on an encoding matrix.
The following subsections describe the available options for creating matrices.
Generic
Generic creation, with the doca_ec_matrix_create() function, is used for simple setup using one of matrix types provided by the library.
Input
|
Name |
Description |
|
type |
One of matrix types provided by the library |
|
data block count |
The number of original data blocks |
|
redundancy block count |
The number of redundancy blocks |
Custom
Custom creation, with the doca_ec_matrix_create_from_raw() function, is used if the desired type of matrix is not provided by the library.
Input
|
Name |
Description |
Notes |
|
data |
The data of a coding matrix |
The size of the data should be data_block_count*rdnc_block_count |
|
data block count |
The number of original data blocks |
– |
|
redundancy block count |
The number of redundancy blocks |
– |
Update
This matrix is necessary for executing the update task, to update the redundancy blocks after a change in the data blocks.
The matrix is created using the doca_ec_matrix_create_update() function.
Input
|
Name |
Description |
Notes |
|
coding matrix |
A coding matrix created by doca_ec_matrix_create() or doca_ec_matrix_create_from_raw() |
– |
|
update indices |
An array specifying the indices of the updated data blocks |
|
|
number of updates |
The number of updated blocks. The length of the update indices array. |
– |
Recover
This matrix is necessary for executing the recover task, to recover original data blocks.
The matrix is created using the doca_ec_matrix_create_recover() function.
Input
|
Name |
Description |
Notes |
|
coding matrix |
A coding matrix created by doca_ec_matrix_create() or doca_ec_matrix_create_from_raw() |
– |
|
missing indices |
An array specifying the indices of the missing data blocks |
|
|
number of missing |
The number of updated blocks. The length of the update indices array. |
– |
Tasks
Galois Mul Task
This task executes Galois multiplication between the original blocks and the coding matrix.
Configur1ation
|
Description |
API to Set the Configuration |
API to Query Support |
|
Enable the task |
doca_ec_task_galois_mul_set_conf |
doca_ec_cap_task_galois_mul_is_supported |
|
Maximum block size |
– |
doca_ec_cap_get_max_block_size |
|
Maximum buffer list length |
– |
doca_ec_cap_get_max_buf_list_len |
Input
Common input as described in DOCA Core Task.
|
Name |
Description |
Notes |
|
coding matrix |
A coding matrix as created by doca_ec_matrix_create() or doca_ec_matrix_create_from_raw() |
– |
|
source buffer |
Source original data buffer, holding a sequence containing all original blocks (e.g., block_1, block_2, etc.); the order matters |
|
|
destination buffer |
A destination buffer for the multiplication outcome blocks. T he sequence containing all multiplication outcome blocks ( dst_block_1, dst_block_2, etc.) is written to it upon successful completion of the task. |
|
If a Galois multiplication task matrix is 10x4 (i.e., 10 original blocks, 4 multiplication outcome blocks), and the block size is 64KB:
src_buf data length should be 10x64KB = 640KB
The available memory for writing in dst_buf should be at least 4x64KB = 256KB
Output
Common output as described in DOCA Core Task .
Task Successful Completion
After the task completes successfully, the following happens:
The destination buffer holds a sequence containing all multiplication outcome blocks (e.g., dst_block_1, dst_block_2 , etc.)
The destination buffer data segment is extended to include the outcome blocks
Task Failed Completion
If the task fails midway:
The context may enter stopping state if a fatal error occurs
The source and destination doca_buf objects are not modified
The destination buffer contents may be modified
Limitations
The operation is not atomic
Once the task has been submitted, the source and destination buffer should not be read from/written to
Source and destination buffers must not overlap
Other limitations are described in DOCA Core Task
Create Task
This task creates redundancy blocks for the given original data blocks using a given coding matrix.
Configuration
|
Description |
API to Set the Configuration |
API to Query Support |
|
Enable the task |
doca_ec_task_create_set_conf |
doca_ec_cap_task_create_is_supported |
|
Maximum block size |
– |
doca_ec_cap_get_max_block_size |
|
Maximum buffer list length |
– |
doca_ec_cap_get_max_buf_list_len |
Input
Common input as described in DOCA Core Task.
|
Name |
Description |
Notes |
|
coding matrix |
A coding matrix created by doca_ec_matrix_create() or doca_ec_matrix_create_from_raw() |
– |
|
original data blocks |
Source original data buffer, holding a sequence containing all original blocks (block_1, block_2, etc.); the order matters |
|
|
redundancy blocks |
A destination buffer for the redundancy blocks. The sequence containing all redundancy blocks (rdnc_block_1, rdnc_block_2, etc.) is written to it upo n successful completion of the task. |
|
If a create task matrix is 10x4 (i.e., 10 original blocks, 4 redundancy blocks), and the block size is 64KB:
original_data_blocks data length should be 10x64KB = 640KB
The available memory for writing in redundancy_blocks should be at least 4x64KB = 256KB
Output
Common output as described in DOCA Core Task .
Task Successful Completion
After the task completes successfully, the following happens:
The destination buffer holds a sequence containing all redundancy blocks (rdnc_block_1, rdnc_block_2, etc.)
The destination buffer data segment is extended to include the redundancy blocks
Task Failed Completion
If the task fails midway:
The context may enter stopping state if a fatal error occurs
The source and destination doca_buf objects are not modified
The destination buffer contents may be modified
Limitations
The operation is not atomic
Once the task is submitted, the source and destination buffers should not be read from/written to
Source and destination buffers must not overlap
Other limitations are described in DOCA Core Task
Update Task
This task executes updates the redundancy blocks for the given original data blocks, using an update coding matrix.
Configuration
|
Description |
API to Set the Configuration |
API to Query Support |
|
Enable the task |
doca_ec_task_update_set_conf |
doca_ec_cap_task_update_is_supported |
|
Maximum block size |
– |
doca_ec_cap_get_max_block_size |
|
Maximum buffer list length |
– |
doca_ec_cap_get_max_buf_list_len |
Input
Common input as described in DOCA Core Task.
|
Name |
Description |
Notes |
|
update matrix |
An update coding matrix created by doca_ec_matrix_create_update() or doca_ec_matrix_create_from_raw() |
- |
|
original updated and RDNC blocks |
A source buffer with data, holding a sequence containing the original data block and its updated data block, for each block that was updated, followed by the old redundancy blocks (old_data_block_i, updated_data_block_i, old_data_block_j, updated_data_block_j, ..., rdnc_block_1, rdnc_block_2, etc.) |
|
|
updated RDNC blocks |
A destination buffer for the updated redundancy blocks. The sequence containing the updated redundancy blocks ( rdnc_block_1, rdnc_block_2, etc.) is written to it upo n successful completion of the task |
|
using an update task matrix, in which 3 data block were updated and there are 4 redundancy blocks, and the block size is 64KB:
original_updated_and_rdnc_blocks data length should be (3+3+4=10)x64KB = 640KB
The available memory for writing in updated_rdnc_blocks should be at least 4x64KB = 256KB
Output
Common output as described in DOCA Core Task.
Task Successful Completion
After the task completes successfully, the following happens:
The destination buffer holds a sequence containing the updated redundancy blocks (rdnc_block_1, rdnc_block_2, etc.)
The destination buffer data segment is extended to include the updated redundancy blocks
Task Failed Completion
If the task fails midway:
The context may enter stopping state if a fatal error occurs
The source and destination doca_buf objects is not modified
The destination buffer contents may be modified
Limitations
The operation is not atomic
Once the task has been submitted, the source and destination buffers should not be read from/written to
Source and destination buffers must not overlap
Other limitations described in DOCA Core Task
Recover Task
This task executes recovers data blocks for, using given available original data blocks and redundancy blocks and a given coding matrix.
Configuration
|
Description |
API to Set the Configuration |
API to Query Support |
|
Enable the task |
doca_ec_task_recover_set_conf |
doca_ec_cap_task_recover_is_supported |
|
Maximum block size |
– |
doca_ec_cap_get_max_block_size |
|
Maximum buffer list length |
– |
doca_ec_cap_get_max_buf_list_len |
Input
Common input as described in DOCA Core Task.
|
Name |
Description |
Notes |
|
recover matrix |
A coding matrix create by doca_ec_matrix_create() or doca_ec_matrix_create_from_raw() |
– |
|
available blocks |
A source buffer with data, holding a sequence containing available data blocks and redundancy blocks (data_block_a, data_block_b, data_block_c, ..., rdnc_block_x, rdnc_block_y, etc.) |
|
|
recovered data blocks |
A destination buffer for the recovered data blocks. The sequence containing the recovered data blocks (data_block_i, data_block_j, etc.) is written to it upo n successful completion of the task |
|
Using a recover task matrix, based on an original 10x4 coding matrix (i.e., 10 original blocks, 4 redundancy blocks), and a block size of 64KB:
10 available blocks should be given in total (e.g., 7 data blocks and 3 redundancy blocks)
available_blocks data length should be 10x64KB = 640KB
The available memory for writing in recovered_data_blocks should be at least 3x64KB = 192KB
Output
Common output as described in DOCA Core Task.
Task Successful Completion
After the task is completed successfully t he data is transformed to destination.
Task Failed Completion
If the task fails midway:
The context may enter stopping state if a fatal error occurs
The source and destination doca_buf objects are not modified
The destination buffer contents may be modified
Limitations
The operation is not atomic
Once the task is submitted, the source and destination buffers should not be read from/written to
Source and destination must not overlap
The amount of blocks that can be recovered are limited to the number of redundancy blocks created
Other limitations are described in DOCA Core Task
This section provides DOCA Erasure Coding sample implementation on top of the BlueField-3 DPU (and higher).
Sample Prerequisites
N/A
Running the Sample
Refer to the following documents:
NVIDIA DOCA Installation Guide for Linux for details on how to install BlueField-related software.
NVIDIA DOCA Troubleshooting Guide for any issue you may encounter with the installation, compilation, or execution of DOCA samples.
To build a given sample:
cd/opt/mellanox/doca/samples/doca_erasure_coding/<sample_name> meson /tmp/build ninja -C /tmp/buildWarningThe binary doca_<sample_name> is created under /tmp/build/.
Sample (e.g., doca_erasure_coding_recover) usage:
Usage: doca_erasure_coding_recover [DOCA Flags] [Program Flags] DOCA Flags: -h, --help Print a help synopsis -v, --version Print program version information -l, --log-level Set the (numeric) log level for the program <10=DISABLE, 20=CRITICAL, 30=ERROR, 40=WARNING, 50=INFO, 60=DEBUG, 70=TRACE> --sdk-log-level Set the SDK (numeric) log level for the program <10=DISABLE, 20=CRITICAL, 30=ERROR, 40=WARNING, 50=INFO, 60=DEBUG, 70=TRACE> -j, --json <path> Parse all command flags from an input json file Program Flags: -p, --pci-addr DOCA device PCI device address - default: 03:00.0 -i, --input Input file/folder to ec - default: self -o, --output Output file/folder to ec - default: /tmp -b, --both Do both (encode & decode) - default: false -x, --matrix Matrix - {cauchy, vandermonde} - default: cauchy -t, --data Data block count - default: 2 -r, --rdnc Redundancy block count - default: 2 -d, --delete_index Indices of data blocks to delete comma seperated i.e. 0,3,4 - default: 0
WarningCurrent BlueField-3 limitations:
Data block count range – 1-128
Redundancy block count – 1-32
Block size – 64B-128MB
For additional information per sample, use the -h option:
/tmp/build/doca_<sample_name> -h
Samples
Erasure Coding Recover
This sample illustrates how to use DOCA Erasure Coding (EC) library to encode and decode a file block (and entire file).
The sample logic includes 3 steps:
Encoding – create redundancy.
Deleting – simulating disaster.
Decoding – recovering data.
The encode logic includes:
Locating a DOCA device.
Initializing the required DOCA Core structures, such as the progress engine (PE), memory maps, and buffer inventory.
Reading source original data file and splitting it to a specified number of blocks, <data block count>, specified for the sample to the output directory.
Populating two DOCA memory maps with a memory range, one for the source data and one for the result.
Allocating buffers from DOCA buffer inventory for each memory range.
Creating an EC object.
Connecting the EC context to the PE.
Setting a state change callback function for the PE, with the following logic:
Printing a log with every state change
Indicating that the user may stop progress the PE once it is back in idle state
Setting the configuration to the EC create task, including setting callback functions as follows:
Successful completion callback:
Writing the resulting redundancy blocks to the output directory (count is specified by <redundancy block count>).
Freeing the task.
Saving the result of the task and the callback. If there was an error in step a., the relevant error value is saved.
Stopping the context.
Failed completion callback:
Saving the result of the task and the callback.
Freeing the task.
Stopping the context.
Creating EC encoding matrix by the matrix type specified to the sample.
Allocating and s ubmitting an EC create task.
Progressing the PE until the context returns to idle state, either as a result of a successful run in which all tasks have been successfully completed, or as a result of a fatal error.
Destroying all EC and DOCA Core structures.
The delete logic includes:
Deleting the block files specified with <indices of data blocks to delete>.
The decode logic includes:
Locating a DOCA device.
Initializing the required DOCA Core structures, such as the PE, memory maps, and buffer inventory.
Reading the output directory (source remaining data) and determining the block size and which blocks are missing (needing recovery).
Populating two DOCA memory maps with a memory range, one for the source data and one for the result.
Allocating buffers from DOCA buffer inventory for each memory range.
Creating an EC object.
Connecting the EC context to the PE.
Setting a state change callback function for the PE, with the following logic:
Printing a log with every state change
Indicating that the user may stop progress the PE once it is back in idle state
Setting the configuration to the EC recover task, including setting callback functions as following:
Successful completion callback:
Writing the resulting recovered blocks to the output directory.
Writing the recovered file to the output path.
Freeing the task.
Saving the result of the task and the callback. If there was an error in step a., the relevant error value is saved.
Stopping the context.
Failed completion callback:
Saving the result of the task and the callback.
Freeing the task.
Stopping the context.
Creating EC encoding matrix by the matrix type specified to the sample.
Creating EC decoding matrix, with doca_ec_matrix_create_recover(), using the encoding matrix.
Allocating and s ubmitting an EC recover task.
Progressing the PE until the context returns to idle state, either as a result of a successful run in which all tasks have been successfully completed, or as a result of a fatal error.
Destroying all DOCA EC and DOCA Core structures.
References:
/opt/mellanox/doca/samples/doca_erasure_coding/doca_erasure_coding_recover/erasure_coding_recover_sample.c
/opt/mellanox/doca/samples/doca_erasure_coding/doca_erasure_coding_recover/erasure_coding_recover_main.c
/opt/mellanox/doca/samples/doca_erasure_coding/doca_erasure_coding_recover/meson.build