DOCA SDK Architecture
DOCA provides libraries for networking and data processing programmability that leverage NVIDIA® BlueField® DPU and NVIDIA® ConnectX® NIC hardware accelerators.
DOCA software framework is built on top of DOCA Core, which provides a unified software framework for DOCA libraries, to form a processing pipeline or workflow build of one or many DOCA libraries.
The DOCA SDK allows applications to offload resource intensive tasks to HW, such as encryption, and compression.
The SDK also allows applications to offload network related tasks, such as packet acquisition, and RDMA send.
As such DPUs/NICs provide dedicated HW processing units for executing such tasks.
The DOCA device subsystem provides an abstraction of the HW processing units referred to as device.
DOCA Device subsystem provides means to:
Discover available hardware acceleration units provided by DPUs/NICs
Query capabilities and properties of available hardware acceleration units
Open device to enable libraries to allocate and share resources necessary for HW acceleration
On a given system there can be multiple available devices. An application can choose a device based on the following characteristics:
Topology - E.g., PCIe address
Capabilities - E.g., Encryption support
DOCA Core supports two DOCA Device types:
Local device – this is an actual device exposed in the local system (DPU or host) and can perform DOCA library processing jobs. This can be a PCI physical function (PF) virtual function (VF) or scalable function (SF)
Representor device – this is a representation of a local device. The represented local device is usually on the host (except for SFs) and the representor is always on the DPU side (a proxy on the DPU for the host-side device).
The following figure provides an example of host local devices with representors on DPU:
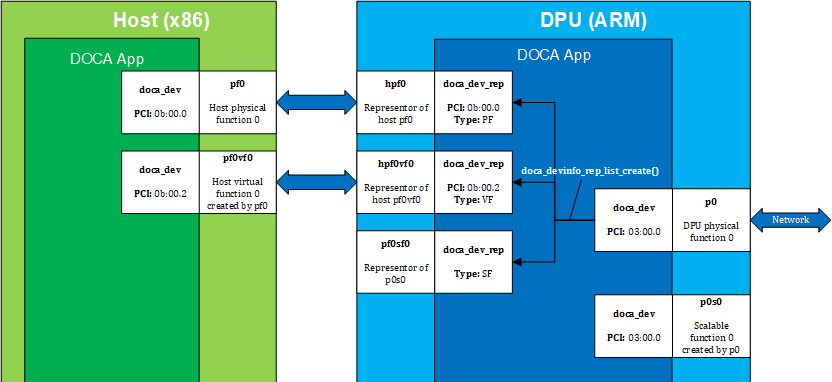
The diagram shows typical topology when using a DPU in DPU mode as described in NVIDIA BlueField DPU Modes of Operation .
The diagram shows a DPU (on the right side of the figure) connected to a host (on the left). The host has physical function PF0 with a child virtual function VF0.
The DPU side has a representor-device per each host function in a 1-to-1 relation (e.g., hpf0 is the representor device for the host's PF0 device and so on) as well as a representor for each SF function, such that both the SF and its representor reside in the DPU.
For more details about DOCA Device subsystem, see section "DOCA Device".
HW processing tasks require data buffers as inputs and/or outputs to processing operations. The application is responsible to provide the input data and/or read the output data.
In order to achieve maximum performance, the SDK uses zero-copy technology to pass data to the HW. To allow zero-copy, the application must register the memory that will hold data buffers beforehand.
The memory management subsystem provides a means to register memory and manage allocation of data buffers on registered memory.
Memory registration:
Defines user application memory range that will be used to hold data buffers.
Allows one or more devices to access the memory range.
Defines the access permission (E.g., read only).
Data buffer allocation management:
Allows allocating data buffers that cover subranges within the registered memory.
Allows memory pool semantics over registered memory.
DOCA memory has the following main components:
doca_buf – Describes a data buffer, and is used as input/output to various HW processing tasks within DOCA libraries.
doca_mmap – Describes registered memory, that is accessible by devices, with a set of permissions. doca_buf is a segment in the memory range represented by doca_mmap.
doca_buf_inventory – pool of doca_buf with the same characteristics (see more in sections "DOCA Core Buffers" and "DOCA Core Inventories")
The following diagram shows the various modules within the DOCA memory subsystem:
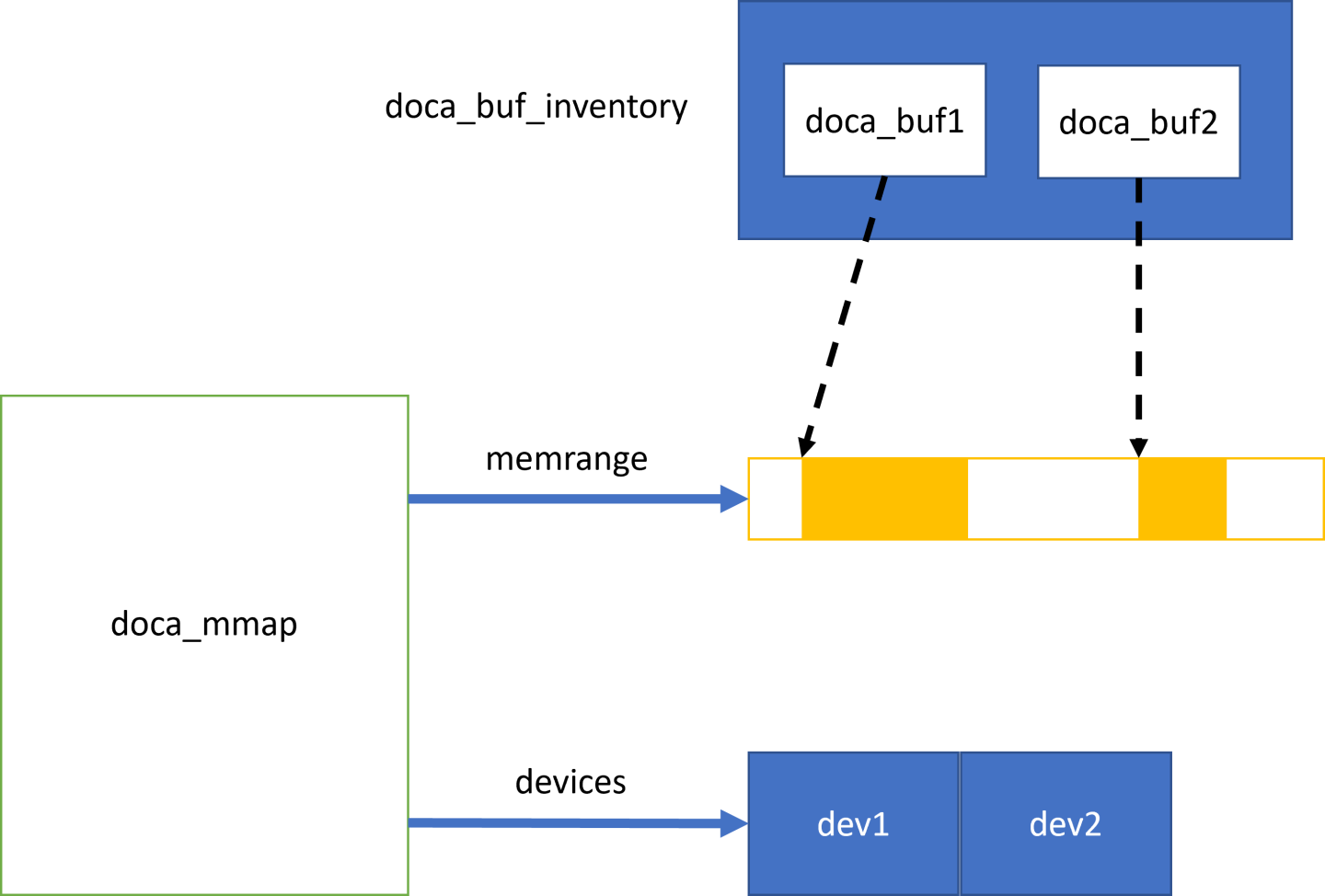
The diagram shows a doca_buf_inventory containing 2 doca_bufs. Each doca_buf points to a portion of the memory buffer which is part of a doca_mmap. The mmap is populated with one continuous memory range and is registered with Two DOCA Devices, dev1 and dev2.
For more details about DOCA Memory management subsystem, see section "DOCA Memory Subsystem".
DOCA SDK introduces libraries that utilize HW processing units. Each library defines dedicated APIs for achieving a specific processing task (E.g., Encryption). The library abstracts all the low level details related to operation of the HW, and instead lets the application focus on what matters. This type of library is referred to as a context.
Since a context utilizes a HW processing unit, it needs a device in order to operate. This device will also determine which buffers are accessible by that context.
Contexts provide HW processing operation APIs in the form of tasks and events.
Task:
Application prepares the task arguments.
Application submits the task, this will issue a request to the relevant HW processing unit.
Application receives a completion in the form of a callback once the HW processing is completed.
Event:
Application registers to the event. This will inform HW to report whenever the event occurs.
Application receives a completion in form of a callback every time HW identifies that the event occurred.
Since HW processing is asynchronous in nature. DOCA provides an object that allows waiting on processing operations (tasks & events). This object is referred to as Progress Engine or PE.
The PE allows waiting on completions using the following methods:
Busy waiting/polling mode - in this case the application will repeatedly invoke a method that checks if some completion has occurred.
Notification-driven mode - in this case the application can use OS primitives (E.g., linux event fd) to notify thread whenever some completion has occurred.
Once completion has occurred, whether caused by Task or Event, the relevant callback will be invoked as part of PE method.
A single PE instance allows waiting on multiple Tasks/Events from different contexts. As such it is possible for application to utilize a single PE per thread.
The following diagram shows how a combination of various DOCA modules combine DOCA cross-library processing runtime.
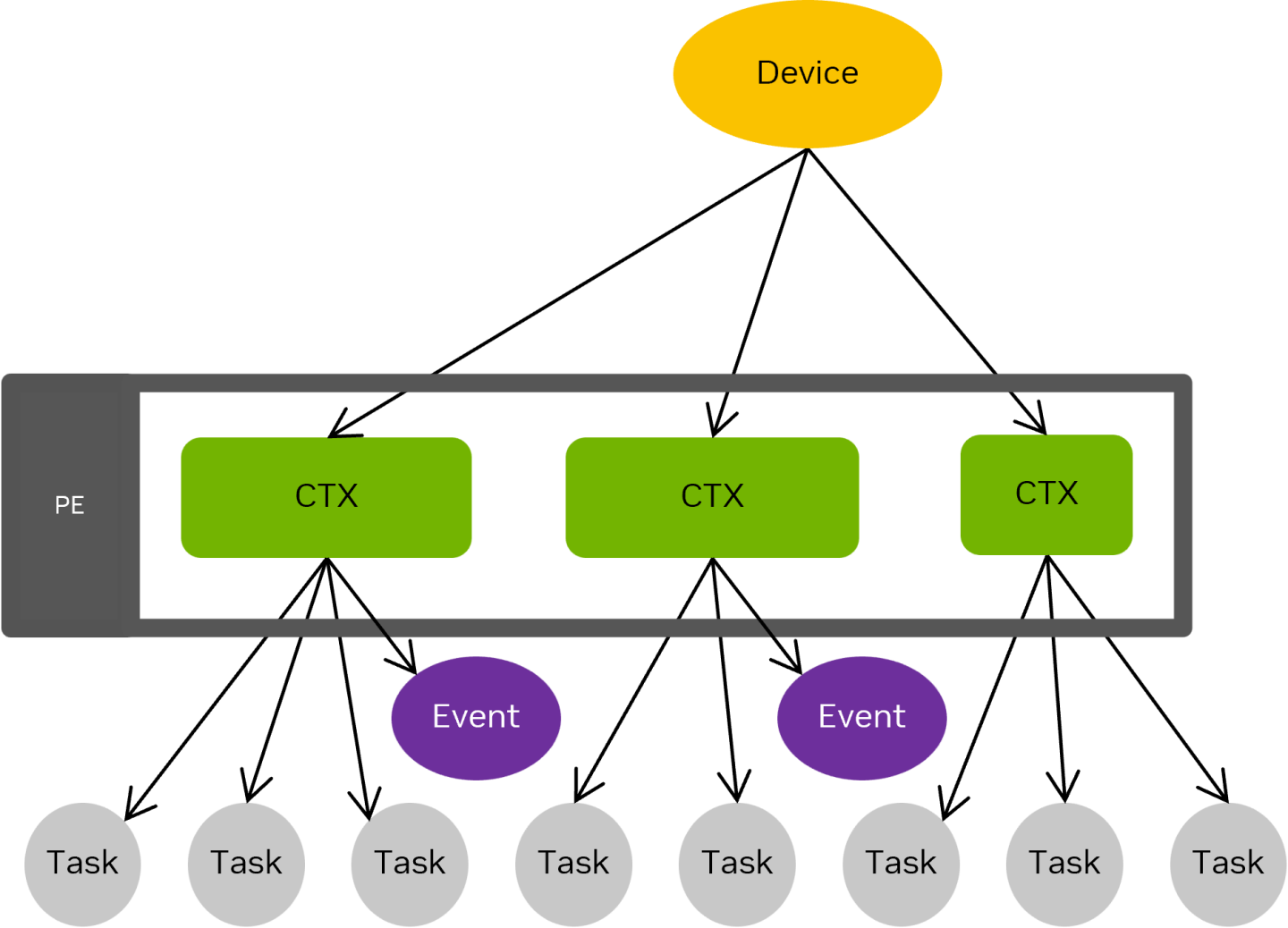
The diagram shows 3 contexts that are utilizing the same device, each context has some tasks/events that have been submitted/registered by application. All 3 contexts are connected to the same PE, where application can use same PE to wait on all completions at once.
For more details about DOCA Execution model see section "DOCA Execution Model".