NVIDIA DOCA GPU Packet Processing Application Guide
This guide provides a description of the GPU packet processing application to demonstrate the use of DOCA GPUNetIO, DOCA Ethernet, and DOCA Flow libraries to implement a GPU traffic analyzer.
Real-time GPU processing of network packets is a useful technique to several different application domains, including signal processing, network security, information gathering, and input reconstruction. The goal of these applications is to realize an inline packet processing pipeline to receive packets in GPU memory (without staging copies through CPU memory), process them in parallel with one or more CUDA kernels, and then run inference, evaluate, or send the result of the calculation over the network.
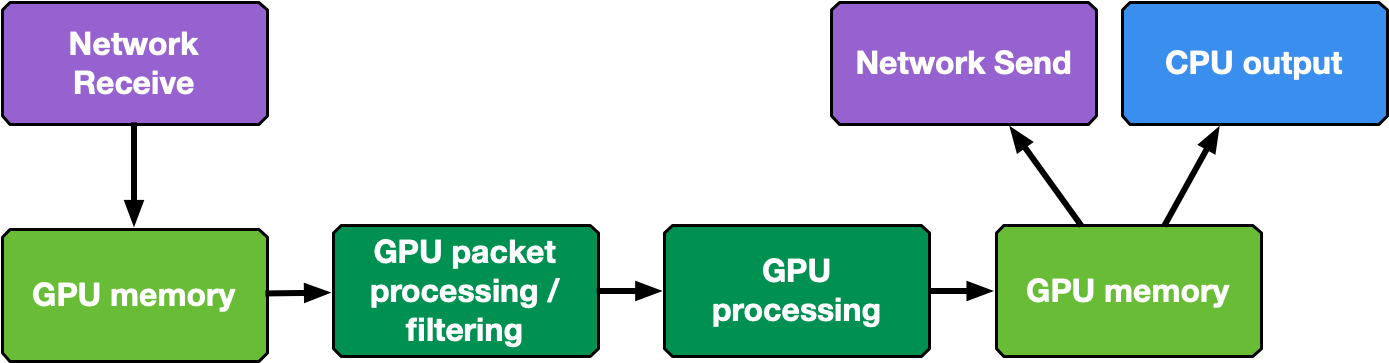
The type of data processing heavily depends on the use case. The goal of this application is to provide a basic layout to reuse in the most common use cases of being able to receive, differentiate and manage the following types of network traffic in multiple queues: UDP, TCP and ICMP.
This application is an enhancement of the use cases presented in this NVIDIA blog post about DOCA GPUNetIO.
This is a receive-and-process DOCA application, so a packet generator sending packets is required to test the application.
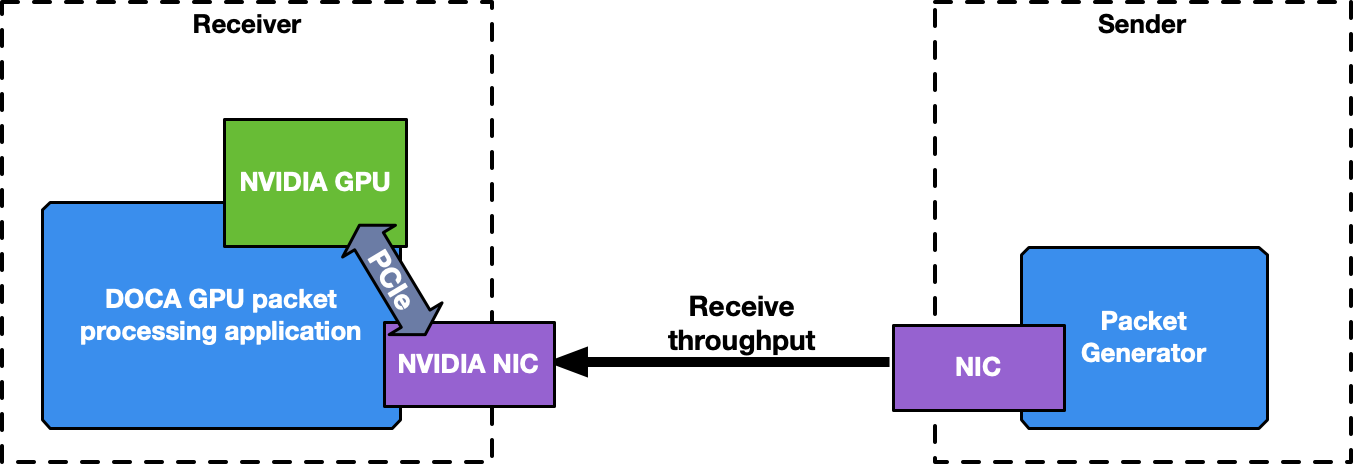
To launch the application, the PCIe address of the GPU and NIC are required.
The application manages different types of traffic differently, dedicating up to 4 receive queues to each one using DOCA Flow with RSS mode to assign each packet to the right queue. The more queues the application uses, the higher is the degree of parallelism in how receive data is processed and how long it takes.
It is highly recommended to use more than one receive queue for 100Gb/s or higher network traffic throughput.
ICMP Network Traffic
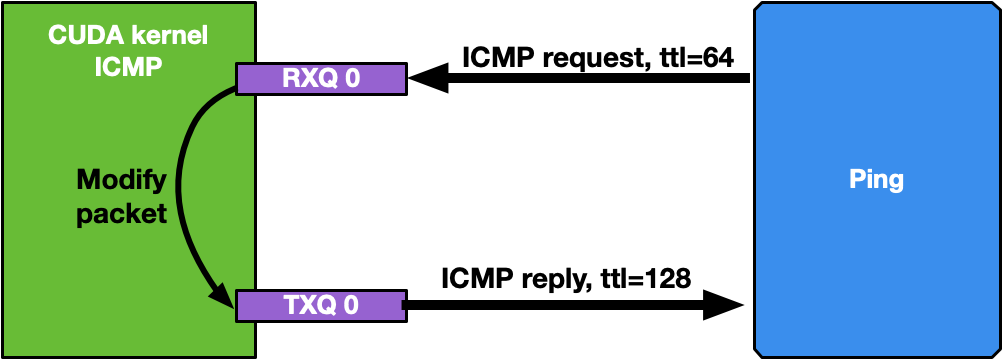
If the network interface used for the application has an IP address, it is possible to ping that interface. ICMP packets are received by a dedicated CUDA kernel (file gpu_kernels/receive_icmp.cu) which:
Receives packets using the DOCA GPUNetIO CUDA warp-level function doca_gpu_dev_eth_rxq_receive_warp .
Checks if the packet is an ICMP echo request.
Forwards the same packet, modifying some header info (e.g., swapping MAC and IP addresses, changing ICMP packet type).
Pushes the modified packet into the send queue using the DOCA GPUNetIO thread-level function doca_gpu_dev_eth_txq_send_enqueue_strong .
Sends the packet using the DOCA GPUNetIO thread-level functions doca_gpu_dev_eth_txq_commit_strong and doca_gpu_dev_eth_txq_push.
This is not a compute intensive use case, so a single CUDA warp with only one receive queue and one send queue is enough to keep up with a decent latency.
By default, the OS CPU ping TTL is set to 64. Therefore, to be sure the GPU is actually replying to ICMP ping requests, TTL is set to 128 in this application.
The following are motivations for this use case:
Providing an easy tool to check connectivity between packet the generator machine and the DOCA application machine
Having a sense of network latency between the two machines using a well-known tool like ping
Showing an easy way to receive and forward modified packets
Providing a warp-level implementation of a CUDA kernel receiving and forwarding traffic
Assuming the IP address of the network interface to ping is 192.168.1.1, this is the expected output:
$ ping 192.168.1.1
PING 192.168.1.1 (192.168.1.1) 56(84) bytes of data.
64 bytes from 192.168.1.1: icmp_seq=1 ttl=64 time=0.324 ms
64 bytes from 192.168.1.1: icmp_seq=2 ttl=64 time=0.332 ms
64 bytes from 192.168.1.1: icmp_seq=3 ttl=64 time=0.299 ms
64 bytes from 192.168.1.1: icmp_seq=4 ttl=64 time=0.309 ms
64 bytes from 192.168.1.1: icmp_seq=5 ttl=64 time=0.323 ms
64 bytes from 192.168.1.1: icmp_seq=6 ttl=64 time=0.300 ms
64 bytes from 192.168.1.1: icmp_seq=7 ttl=64 time=0.274 ms
64 bytes from 192.168.1.1: icmp_seq=8 ttl=64 time=0.314 ms
64 bytes from 192.168.1.1: icmp_seq=9 ttl=64 time=0.327 ms
64 bytes from 192.168.1.1: icmp_seq=10 ttl=64 time=0.384 ms
# At this point, the DOCA application has been started on the 192.168.1.1 interface
# TTL becomes 128 as it's the GPU replying to ICMP requests now instead of the OS
64 bytes from 192.168.1.1: icmp_seq=11 ttl=128 time=0.346 ms
64 bytes from 192.168.1.1: icmp_seq=12 ttl=128 time=0.274 ms
64 bytes from 192.168.1.1: icmp_seq=13 ttl=128 time=0.294 ms
64 bytes from 192.168.1.1: icmp_seq=14 ttl=128 time=0.240 ms
64 bytes from 192.168.1.1: icmp_seq=15 ttl=128 time=0.273 ms
64 bytes from 192.168.1.1: icmp_seq=16 ttl=128 time=0.238 ms
64 bytes from 192.168.1.1: icmp_seq=17 ttl=128 time=0.252 ms
64 bytes from 192.168.1.1: icmp_seq=18 ttl=128 time=0.232 ms
64 bytes from 192.168.1.1: icmp_seq=19 ttl=128 time=0.278 ms
......
A DOCA Progress Engine is attached to the DOCA Ethernet Txq context used to forward ICMP packets. Those packets are sent from the GPU with the DOCA_GPU_SEND_FLAG_NOTIFY flag, which result in creating a notification after every packet is sent by the NIC.
All the notifications are then analyzed by the CPU through the doca_pe_progress function. The final effect is the output of the application which returns the distance, in seconds, between two pings. The following is an example with a ping every 0.5 seconds:
$ ping -i 0.5 192.168.1.1
PING 192.168.1.1 (192.168.1.1) 56(84) bytes of data.
64 bytes from 192.168.1.1: icmp_seq=1 ttl=128 time=0.202 ms
64 bytes from 192.168.1.1: icmp_seq=2 ttl=128 time=0.179 ms
64 bytes from 192.168.1.1: icmp_seq=3 ttl=128 time=0.199 ms
64 bytes from 192.168.1.1: icmp_seq=4 ttl=128 time=0.180 ms
64 bytes from 192.168.1.1: icmp_seq=5 ttl=128 time=0.200 ms
64 bytes from 192.168.1.1: icmp_seq=6 ttl=128 time=0.189 ms
......
On the DOCA side, the application should print a log for all the ICMP packets received and retransmitted:
Seconds 5
[UDP] QUEUE: 0 DNS: 0 OTHER: 0 TOTAL: 0
[TCP] QUEUE: 0 HTTP: 0 HTTP HEAD: 0 HTTP GET: 0 HTTP POST: 0 TCP [SYN: 0 FIN: 0 ACK: 0] OTHER: 0 TOTAL: 0
[13:54:19:202061][2688665][DOCA][INF][gpu_packet_processing.c:77][debug_send_packet_icmp_cb] ICMP debug event: Queue 0 packet 3 sent at 1702302859201997120 time from last ICMP is 0.512025 sec
[13:54:19:713960][2688665][DOCA][INF][gpu_packet_processing.c:77][debug_send_packet_icmp_cb] ICMP debug event: Queue 0 packet 4 sent at 1702302859713896620 time from last ICMP is 0.511899 sec
[13:54:20:225891][2688665][DOCA][INF][gpu_packet_processing.c:77][debug_send_packet_icmp_cb] ICMP debug event: Queue 0 packet 5 sent at 1702302860225868072 time from last ICMP is 0.511971 sec
[13:54:20:737823][2688665][DOCA][INF][gpu_packet_processing.c:77][debug_send_packet_icmp_cb] ICMP debug event: Queue 0 packet 6 sent at 1702302860737781760 time from last ICMP is 0.511914 sec
[13:54:21:249763][2688665][DOCA][INF][gpu_packet_processing.c:77][debug_send_packet_icmp_cb] ICMP debug event: Queue 0 packet 7 sent at 1702302861249723044 time from last ICMP is 0.511941 sec
[13:54:21:761614][2688665][DOCA][INF][gpu_packet_processing.c:77][debug_send_packet_icmp_cb] ICMP debug event: Queue 0 packet 8 sent at 1702302861761588848 time from last ICMP is 0.511866 sec
[13:54:22:273689][2688665][DOCA][INF][gpu_packet_processing.c:77][debug_send_packet_icmp_cb] ICMP debug event: Queue 0 packet 9 sent at 1702302862273643536 time from last ICMP is 0.512055 sec
[13:54:22:785543][2688665][DOCA][INF][gpu_packet_processing.c:77][debug_send_packet_icmp_cb] ICMP debug event: Queue 0 packet 10 sent at 1702302862785527576 time from last ICMP is 0.511884 sec
[13:54:23:297545][2688665][DOCA][INF][gpu_packet_processing.c:77][debug_send_packet_icmp_cb] ICMP debug event: Queue 0 packet 11 sent at 1702302863297501448 time from last ICMP is 0.511974 sec
[13:54:23:809406][2688665][DOCA][INF][gpu_packet_processing.c:77][debug_send_packet_icmp_cb] ICMP debug event: Queue 0 packet 12 sent at 1702302863809350664 time from last ICMP is 0.511849 sec
Seconds 10
[UDP] QUEUE: 0 DNS: 0 OTHER: 0 TOTAL: 0
[TCP] QUEUE: 0 HTTP: 0 HTTP HEAD: 0 HTTP GET: 0 HTTP POST: 0 TCP [SYN: 0 FIN: 0 ACK: 0] OTHER: 0 TOTAL: 0
[13:54:24:321405][2688665][DOCA][INF][gpu_packet_processing.c:77][debug_send_packet_icmp_cb] ICMP debug event: Queue 0 packet 13 sent at 1702302864321391148 time from last ICMP is 0.512040 sec
[13:54:24:833338][2688665][DOCA][INF][gpu_packet_processing.c:77][debug_send_packet_icmp_cb] ICMP debug event: Queue 0 packet 14 sent at 1702302864833270356 time from last ICMP is 0.511879 sec
[13:54:25:345302][2688665][DOCA][INF][gpu_packet_processing.c:77][debug_send_packet_icmp_cb] ICMP debug event: Queue 0 packet 15 sent at 1702302865345282728 time from last ICMP is 0.512012 sec
[13:54:25:857199][2688665][DOCA][INF][gpu_packet_processing.c:77][debug_send_packet_icmp_cb] ICMP debug event: Queue 0 packet 16 sent at 1702302865857133664 time from last ICMP is 0.511851 sec
[13:54:26:369131][2688665][DOCA][INF][gpu_packet_processing.c:77][debug_send_packet_icmp_cb] ICMP debug event: Queue 0 packet 17 sent at 1702302866369128728 time from last ICMP is 0.511995 sec......
UDP Network Traffic
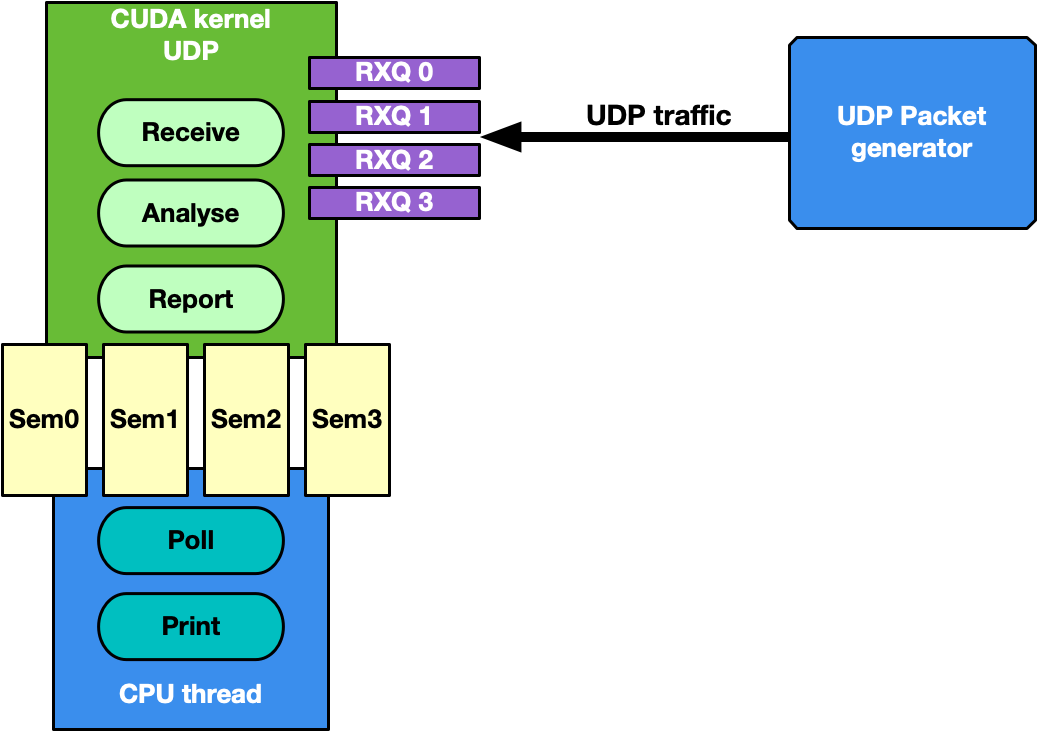
This is the most generic use case of receive-and-analyze packet headers. Designed to keep up with 100Gb/s of incoming network traffic, the CUDA kernel responsible for the UDP traffic dedicates one CUDA block of 512 CUDA threads (file gpu_kernels/receive_udp.cu) to a different Ethernet UDP receive queue.
The data path loop is:
Receive packets using the DOCA GPUNetIO CUDA block-level function doca_gpu_dev_eth_rxq_receive_block .
Each CUDA thread works on a subset of received packets.
DOCA buffer containing the packet is retrieved.
Packet payload is analyzed to differentiate between DNS packets from other UDP generic packets.
Packet payload is wiped-out to ensure that old stale packets are not analyzed again.
Each CUDA block reports to the CPU thread statistics about types of received packets through a DOCA GPUNetIO semaphore.
CPU thread polls on semaphores to retrieve and print the statistics to the console.
The motivation for this use case is mostly to provide an application template to:
Receive and analyze packet headers to differentiate across different UDP protocols
Report statistics to the CPU through the DOCA GPUNetIO semaphore
Several well-known packet generators can be used to test this mode like T-Rex or DPDK testpmd.
TCP Network Traffic and HTTP Echo Server
By default, the TCP flow management is the same as UDP: Receive TCP packets and analyze their headers to report to the CPU statistics about the types of received packets. This is good for passive traffic analyzers or sniffers but sometimes a packet processing application requires receiving packets directly from TCP peers which implies the establishment of a TCP-reliable connection through the 3-way handshake method. Therefore, it is possible to enable TCP "server" mode through the -s command-line flag which enables an "HTTP echo server" mode where the CPU and GPU cooperate to establish a TCP connection and process TCP data packets.
Specifically, in this case there are two different sets of receive queues:
CPU DPDK receive queues which receive TCP "control" packets (e.g. SYN, FIN or RST)
DOCA GPUNetIO receive queues to receive TCP "data" packets
This distinction is possible thanks to DOCA Flow capabilities.
The application's flow requires CPU and GPU collaboration as described in the following subsections.
Step 1: TCP Connection Establishment
A CPU thread through DPDK queues receives a TCP SYN packet from a remote TCP peer. The CPU thread establishes a TCP reliable connection (replies with a TCP SYN-ACK packet) with the peer and uses DOCA Flow to create a new steering rule to redirect TCP data packets to one of the DOCA GPUNetIO receive queues. The new steering rule excludes control packets (e.g., SYN, FIN or RST).
Step 2: TCP Data Processing
The CUDA kernel responsible for TCP processing receives TCP data packets and performs TCP packet header analysis. If it receives an HTTP GET request, it stores the relevant packet's info in the next item of a DOCA GPUNetIO semaphore, setting it to READY.
Step 3: HTTP Echo Server
A second CUDA kernel responsible for HTTP processing polls the DOCA GPUNetIO semaphore. Once it detects the update of the next item to READY, it reads the HTTP GET packet info and crafts an HTTP response packet with an HTML page.
If the request is about index.html or contacts.html, the CUDA kernel replies with the appropriate HTML page using a 200 OK code. For all other requests, the it returns a "Page not found" and 404 Error code.
HTTP response packets are sent by this second HTTP CUDA kernel using DOCA GPUNetIO.
Care must be taken to maintain TCP sequence/ack numbers in the packet headers.
Step 4: TCP Connection Closure
If the CPU receives a TCP FIN packet through the DPDK queues, it closes the connection with the remote TCP peer and removes the DOCA Flow rule from the DOCA GPUNetIO queues so the CUDA kernel cannot receive anymore packets from that TCP peer.
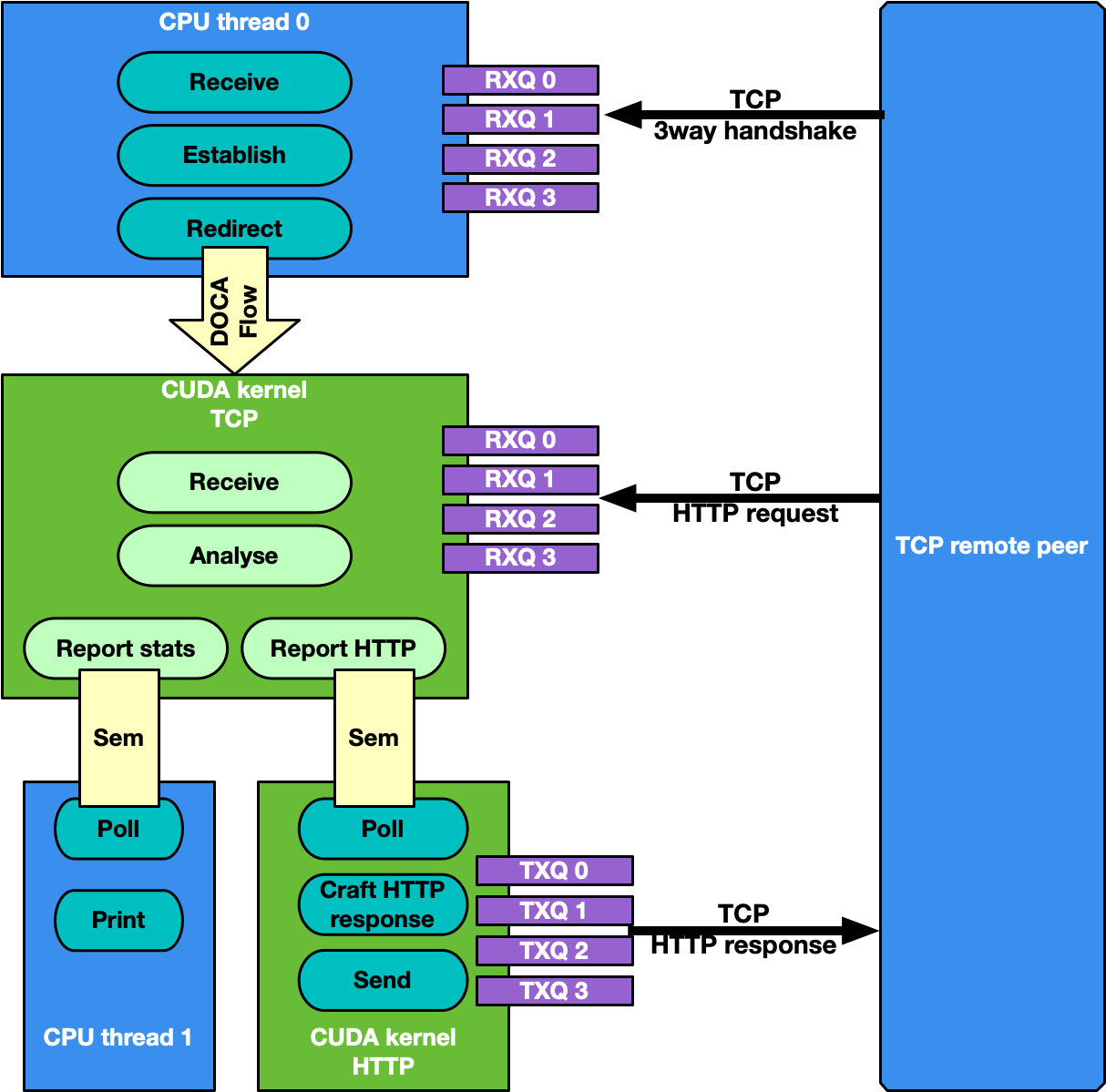
Motivations for this use case:
Receiving and analyzing packet headers to differentiate across different TCP protocols
Processing TCP packets on GPU in passive mode (sniffing) and active mode (reliable connection)
Having a DOCA-DPDK application able to establish a TCP reliable connection without using any OS socket and bypassing kernel routines
Having CUDA-kernel-to-CUDA-kernel communication through a DOCA GPUNetIO semaphore
Showing how to create and send a packet from scratch with DOCA GPUNetIO
Assuming the network interface used to run the application has the IP address 192.168.1.1 , it is possible to test this HTTP echo server mode using simple tools like curl or wget.
Example with curl:
$ curl http://192.168.1.1/index.html -ivvv
* Trying 192.168.1.1:80...
* Connected to 192.168.1.1 (192.168.1.1) port 80 (#0)
> GET /index.html HTTP/1.1
> Host: 192.168.1.1
> User-Agent: curl/7.81.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
HTTP/1.1 200 OK
< Date: Sun, 30 Apr 2023 20:30:40 GMT
Date: Sun, 30 Apr 2023 20:30:40 GMT
< Content-Type: text/html; charset=UTF-8
Content-Type: text/html; charset=UTF-8
< Content-Length: 158
Content-Length: 158
< Last-Modified: Sun, 30 Apr 2023 22:38:34 GMT
Last-Modified: Sun, 30 Apr 2023 22:38:34 GMT
< Server: GPUNetIO
Server: GPUNetIO
< Accept-Ranges: bytes
Accept-Ranges: bytes
< Connection: keep-alive
Connection: keep-alive
< Keep-Alive: timeout=5
Keep-Alive: timeout=5
<
<html>
<head>
<title>GPUNetIO index page</title>
</head>
<body>
<p>Hello World, the GPUNetIO server Index page!</p>
</body>
</html>
* Connection #0 to host 192.168.1.1 left intact
This application leverages the following DOCA libraries:
Refer to their respective programming guide for more information.
The following dependencies must be installed and configured:
CUDA Toolkit - version 12.1 or newer
DOCA's GPU packages (requires CUDA and not installed by default)
For Ubuntu/Debian:
$
sudoaptinstall-y doca-gpu doca-gpu-devFor CentOS/RedHat:
$
sudoyuminstall-y doca-gpu doca-gpu-devel
gdrcopy
gdrdrv kernel module – active and running on the system
nvidia-peermem kernel module – active and running on the system
Installation
Refer to the NVIDIA DOCA Installation Guide for Linux for details on how to install BlueField-related software.
Prerequisites
NIC correctly configured for direct PCIe connection with the GPU
Environment variable necessary for gdrcopy:
$
exportLD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/opt/mellanox/gdrcopy/srcAllocate 4 hugepages of 1GB (DOCA Flow and DPDK requirement):
Hugepages 1GB
$
sudovim /etc/default/grub# Add hugepages size and number along with other options you have in the CMDLINE# GRUB_CMDLINE_LINUX_DEFAULT="default_hugepagesz=1G hugepagesz=1G hugepages=4"$sudoupdate-grub $sudoreboot# After rebooting, check huge pages info$grep-i huge /proc/meminfo AnonHugePages: 0 kB ShmemHugePages: 0 kB HugePages_Total: 16 HugePages_Free: 15 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 1048576 kB Hugetlb: 16777216 kB
Application Execution
The GPU packet processing application is provided in both source and binary forms. The binary is located under /opt/mellanox/doca/applications/gpu_packet_processing/bin/doca_gpu_packet_processing.
Application usage instructions:
Usage: doca_gpu_packet_processing [DOCA Flags] [Program Flags] DOCA Flags: -h, --help Print a help synopsis -v, --version Print program version information -l, --log-level Set the (numeric) log level
forthe program <10=DISABLE,20=CRITICAL,30=ERROR,40=WARNING,50=INFO,60=DEBUG,70=TRACE> --sdk-log-level Set the SDK (numeric) log levelforthe program <10=DISABLE,20=CRITICAL,30=ERROR,40=WARNING,50=INFO,60=DEBUG,70=TRACE> -j, --json <path> Parse all command flags from an input json file Program Flags: -g, --gpu <GPU PCIe address> GPU PCIe address to be used by the app -n, --nic <NIC PCIe address> DOCA device PCIe address used by the app -q, --queue <GPU receive queues> DOCA GPUNetIO receive queue per flow -s, --httpserver <Enable GPU HTTP server> Enable GPU HTTP server modeNoteThis usage printout can be printed to the command line using the -h (or --help) options:
/opt/mellanox/doca/applications/gpu_packet_processing/bin/doca_gpu_packet_processing -h
NoteFor additional information, refer to section "Command Line Flags".
CLI example for running the application on the host:
Assuming a GPU PCIe address ca:00.0 and NIC PCIe address 17:00.0 with 2 GPUNetIO receive queues:
doca_gpu_packet_processing -n 17:00.0 -g ca:00.0 -q 2
WarningRefer to section "Running DOCA Application on Host" in the NVIDIA DOCA Virtual Functions User Guide.
Command Line Flags
|
Flag Type |
Short Flag |
Long Flag |
Description |
|
General flags |
h |
help |
Prints a help synopsis |
|
v |
version |
Prints program version information |
|
|
l |
log-level |
Set the log level for the application:
|
|
|
N/A |
sdk-log-level |
Sets the log level for the program:
|
|
|
j |
json |
Parse all command flags from an input JSON file |
|
|
Program flags |
g |
gpu |
GPU PCIe address in <bus>:<device>.<function> format. This can be obtained using the nvidia-smi or lspci commands. |
|
n |
nic |
Network card port PCIe address in <bus>:<device>.<function> format. This can be obtained using the lspci command. |
|
|
q |
queue |
Number of receive queues to use in the example. Default is 1, maximum allowed is 4. |
|
|
s |
httpserver |
Enable the TCP HTTP server mode. With this flag, TCP packets are not received by GPUNetIO as regular sniffer as it requires a TCP 3-way handshake to establish a reliable connection first. |
Refer to DOCA Arg Parser for more information regarding the supported flags and execution modes.
Troubleshooting
Refer to the NVIDIA DOCA Troubleshooting Guide for any issue encountered with the installation or execution of the DOCA applications .
In addition to providing the application in binary form, the installation also includes all of the application sources and compilation instructions so as to allow modifying the sources and recompiling the application. For more information about the applications, as well as development and compilation tips, refer to the DOCA Applications page.
The sources of the application can be found under the /opt/mellanox/doca/applications/gpu_packet_processing/src directory.
Recompiling All Applications
The applications are all defined under a single meson project, so the default compilation recompiles all the DOCA applications.
To build all the applications together, including the GPU-enabled applications, run:
cd /opt/mellanox/doca/applications/
meson /tmp/build -Denable_gpu_support=true
ninja -C /tmp/build
doca_gpu_packet_processing is created under /tmp/build/gpu_packet_processing/src/.
Recompiling GPU Packet Processing Application Only
To directly build only the GPU packet processing application:
cd /opt/mellanox/doca/applications/
meson /tmp/build -Denable_gpu_support=true -Denable_all_applications=false -Denable_gpu_packet_processing=true
ninja -C /tmp/build
doca_gpu_packet_processing is created under /tmp/build/gpu_packet_processing/src/.
Alternatively, users can set the desired flags in the meson_options.txt file instead of providing them in the compilation command line:
Edit the following flags in /opt/mellanox/doca/applications/meson_options.txt:
Set enable_all_applications to false
Set enable_gpu_support to true
Set enable_gpu_packet_processing to true
Run the following compilation commands :
cd /opt/mellanox/doca/applications/ meson /tmp/build ninja -C /tmp/build
Notedoca_gpu_packet_processing is created under /tmp/build/gpu_packet_processing/src/.
Troubleshooting
Refer to the NVIDIA DOCA Troubleshooting Guide for any issue encountered with the compilation of the application .
The following explains the application's flow, highlighting main code blocks and functions:
Parse application argument.
doca_argp_init(); register_application_params(); doca_argp_start();
Initialize network device as DOCA device, initialize DPDK, and get device DPDK port ID.
init_doca_device();
Calls rte_eal_init() with empty flags to initialize EAL resources.
Initialize a GPU device, creating a DOCA GPUNetIO handle for it.
doca_gpu_create();
Initialize DOCA Flow, starting the DPDK port.
init_doca_flow();
Flags to initialize DOCA Flow are VNF, HW steering, and isolated mode (to prevent the default RSS flows from interfering with the GPUNetIO queues).
Create RX and TX queue related objects (i.e., Ethernet handlers, GPUNetIO handlers, flow rules, semaphores) to manage UDP, TCP and ICMP flows.
create_udp_queues(); create_tcp_queues(); create_icmp_queues();
/* Depending on TCP mode (HTTP server or not) properly connect different DOCA Flow pipes */create_root_pipe();Allocate generic exit flag. All CUDA kernels periodically poll on this flag. If the CPU set it to 1, CUDA kernels exit from their main loop and return.
doca_gpu_mem_alloc(gpu_dev, sizeof(uint32_t), alignment, DOCA_GPU_MEM_GPU_CPU, (
void**)&gpu_exit_condition, (void**)&cpu_exit_condition);Launch CUDA kernels, each on a different stream.
kernel_receive_udp(rx_udp_stream, gpu_exit_condition, &udp_queues); kernel_receive_tcp(rx_tcp_stream, gpu_exit_condition, &tcp_queues, app_cfg.http_server); kernel_receive_icmp(rx_icmp_stream, gpu_exit_condition, &icmp_queues);
if(app_cfg.http_server) kernel_http_server(tx_http_server, gpu_exit_condition, &tcp_queues, &http_queues);Launch the CPU thread responsible to poll on DOCA GPUNetIO semaphores and print UDP and TCP stats on the console.
rte_eal_remote_launch((
void*)stats_core, NULL, current_lcore);Launch CPU thread responsible for managing TCP 3-way handshake connections.
if(app_cfg.http_server) { ... rte_eal_remote_launch(tcp_cpu_rss_func, &tcp_queues, current_lcore); }Wait for the user to send a signal to quit the application. When this happens, the signal handler function sets the force_quit flag to true which causes the main thread to move forward and set the exit condition to 1.
while(DOCA_GPUNETIO_VOLATILE(force_quit) ==false); DOCA_GPUNETIO_VOLATILE(*cpu_exit_condition) =1;Wait for CUDA kernels to exit and finalize all DOCA Flow and GPUNetIO resources.
cudaStreamSynchronize(rx_udp_stream); cudaStreamSynchronize(rx_tcp_stream); cudaStreamSynchronize(rx_icmp_stream);
if(app_cfg.http_server) cudaStreamSynchronize(tx_http_server); destroy_flow_queue(); doca_gpu_destroy();
/opt/mellanox/doca/applications/gpu_packet_processing/src