DOCA Core
This document provides guidelines on using DOCA Core objects as part of DOCA SDK programming.
The DOCA Core library is supported at beta level.
DOCA Core objects provide a unified and holistic interface for application developers to interact with various DOCA libraries. The DOCA Core API and objects bring a standardized flow and building blocks for applications to build upon while hiding the internal details of dealing with hardware and other software components. DOCA Core is designed to give the right level of abstraction while maintaining performance.
DOCA Core has the same API (header files) for both DPU and CPU installations, but specific API calls may return DOCA_ERROR_NOT_SUPPORTED if the API is not implemented for that processor. However, this is not the case for Windows and Linux as DOCA Core does have API differences between Windows and Linux installations.
DOCA Core exposes C-language API to application writers and users must include the right header file to use according to the DOCA Core facilities needed for their application.
DOCA Core can be divided into the following software modules:
|
DOCA Core Module |
Description |
|
General |
|
|
Device handling |
Note
There is a symmetry between device entities on host and its representor (on the DPU). The convention of adding rep to the API or the object hints that it is representor-specific.
|
|
Memory management |
|
|
Progress engine and job execution |
|
|
Sync events |
|
The following sections describe DOCA Core's architecture and subsystems along with some basic flows that help users get started using DOCA Core.
DOCA Core objects are supported on the DPU target and the host machine. Both must meet the following prerequisites:
DOCA version 2.0.2 or greater
NVIDIA® BlueField® software 4.0.2 or greater
NVIDIA® BlueField®-3 firmware version 32.37.1000 and higher
NVIDIA® BlueField®-2 firmware version 24.37.1000 and higher
Please refer to the DOCA Backward Compatibility Policy
The following sections describe the architecture for the various DOCA Core software modules. Please refer to the NVIDIA DOCA Library APIs for DOCA header documentation.
General
All core objects adhere to same flow that later helps in doing no allocations in the fast path.
The flow is as follows:
- Create the object instance (e.g., doca_mmap_create).
- Configure the instance (e.g., doca_mmap_set_memory_range).
- Start the instance (e.g., doca_mmap_start).
After the instance is started, it adheres to zero allocations and can be used safely in the data path. After the instance is complete, it must be stopped and destroyed (doca_mmap_stop, doca_mmap_destroy).
There are core objects that can be reconfigured and restarted again (i.e., create → configure → start → stop → configure → start). Please read the header file to see if specific objects support this option.
doca_error_t
All DOCA APIs return the status in the form of doca_error_t.
typedef enum doca_error {
DOCA_SUCCESS,
DOCA_ERROR_UNKNOWN,
DOCA_ERROR_NOT_PERMITTED, /**< Operation not permitted */
DOCA_ERROR_IN_USE, /**< Resource already in use */
DOCA_ERROR_NOT_SUPPORTED, /**< Operation not supported */
DOCA_ERROR_AGAIN, /**< Resource temporarily unavailable, try again */
DOCA_ERROR_INVALID_VALUE, /**< Invalid input */
DOCA_ERROR_NO_MEMORY, /**< Memory allocation failure */
DOCA_ERROR_INITIALIZATION, /**< Resource initialization failure */
DOCA_ERROR_TIME_OUT, /**< Timer expired waiting for resource */
DOCA_ERROR_SHUTDOWN, /**< Shut down in process or completed */
DOCA_ERROR_CONNECTION_RESET, /**< Connection reset by peer */
DOCA_ERROR_CONNECTION_ABORTED, /**< Connection aborted */
DOCA_ERROR_CONNECTION_INPROGRESS, /**< Connection in progress */
DOCA_ERROR_NOT_CONNECTED, /**< Not Connected */
DOCA_ERROR_NO_LOCK, /**< Unable to acquire required lock */
DOCA_ERROR_NOT_FOUND, /**< Resource Not Found */
DOCA_ERROR_IO_FAILED, /**< Input/Output Operation Failed */
DOCA_ERROR_BAD_STATE, /**< Bad State */
DOCA_ERROR_UNSUPPORTED_VERSION, /**< Unsupported version */
DOCA_ERROR_OPERATING_SYSTEM, /**< Operating system call failure */
DOCA_ERROR_DRIVER, /**< DOCA Driver call failure */
DOCA_ERROR_UNEXPECTED, /**< An unexpected scenario was detected */
DOCA_ERROR_ALREADY_EXIST, /**< Resource already exist */
DOCA_ERROR_FULL, /**< No more space in resource */
DOCA_ERROR_EMPTY, /**< No entry is available in resource */
DOCA_ERROR_IN_PROGRESS, /**< Operation is in progress */
DOCA_ERROR_TOO_BIG, /**< Requested operation too big to be contained */
} doca_error_t;
See doca_error.h for more.
Generic Structures/Enum
The following types are common across all DOCA APIs.
union doca_data {
void *ptr;
uint64_t u64;
};
enum doca_access_flags {
DOCA_ACCESS_LOCAL_READ_ONLY = 0,
DOCA_ACCESS_LOCAL_READ_WRITE = (1 << 0),
DOCA_ACCESS_RDMA_READ = (1 << 1),
DOCA_ACCESS_RDMA_WRITE = (1 << 2),
DOCA_ACCESS_RDMA_ATOMIC = (1 << 3),
DOCA_ACCESS_DPU_READ_ONLY = (1 << 4),
DOCA_ACCESS_DPU_READ_WRITE = (1 << 5),
};
enum doca_pci_func_type {
DOCA_PCI_FUNC_PF = 0, /* physical function */
DOCA_PCI_FUNC_VF, /* virtual function */
DOCA_PCI_FUNC_SF, /* sub function */
};
For more see doca_types.h.
DOCA Device
Local Device and Representor
Prerequisites
For the representors model, BlueField must be operated in DPU mode. See NVIDIA BlueField DPU Modes of Operation.
Topology
The DOCA device represents an available processing unit backed by hardware or software implementation. The DOCA device exposes its properties to help an application in choosing the right device(s). DOCA Core supports two device types:
- Local device – this is an actual device exposed in the local system (DPU or host) and can perform DOCA library processing jobs.
- Representor device – this is a representation of a local device. The local device is usually on the host (except for SFs) and the representor is always on the DPU side (a proxy on the DPU for the host-side device).
The following figure provides an example topology:
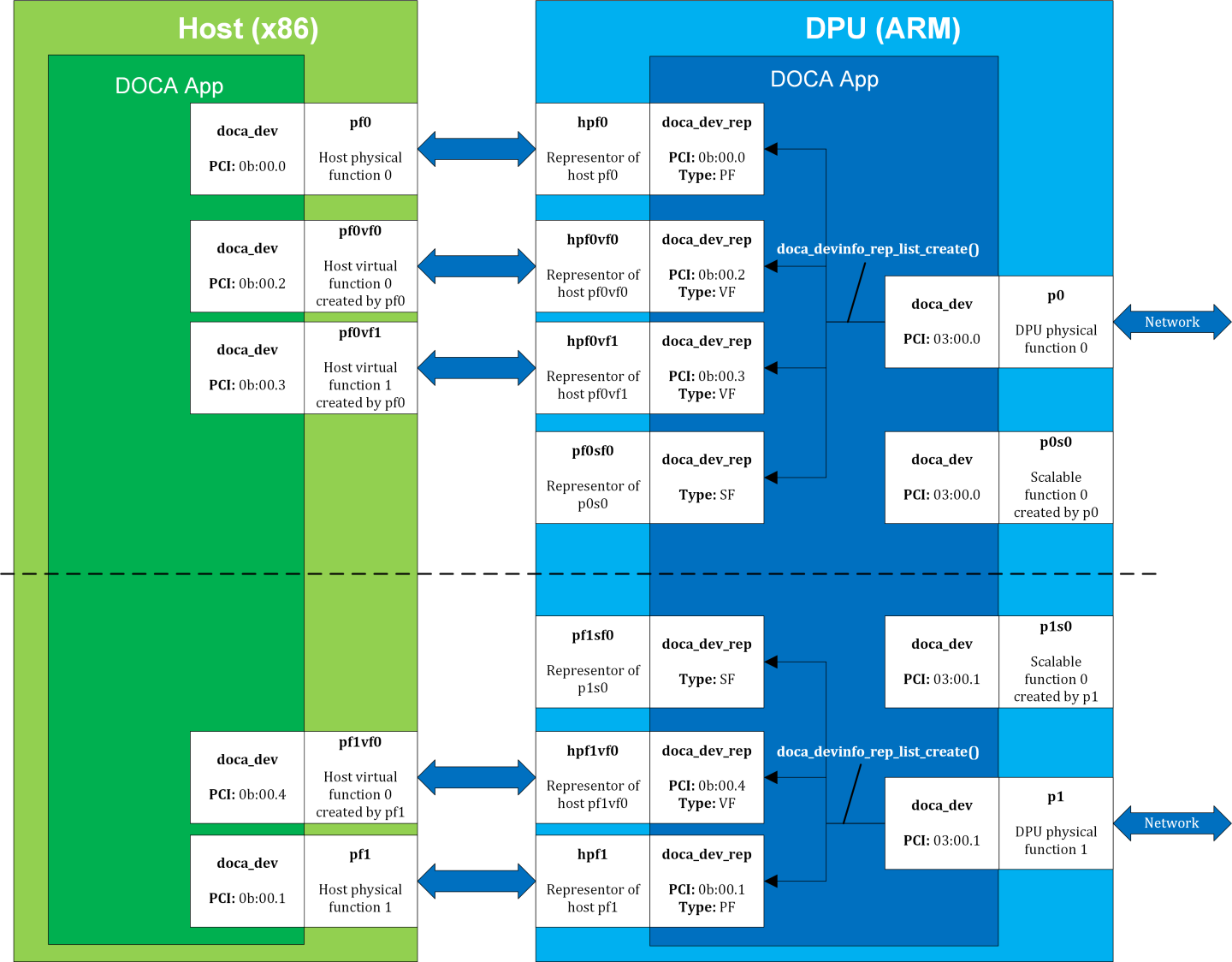
The diagram shows a DPU (on the right side of the figure) connected to a host (on the left side of the figure). The host topology consists of two physical functions (PF0 and PF1). Furthermore, PF0 has two child virtual functions, VF0 and VF1. PF1 has only one VF associated with it, VF0. Using the DOCA SDK API, the user gets these five devices as local devices on the host.
The DPU side has a representor-device per each host function in a 1-to-1 relation (e.g., hpf0 is the representor device for the host's PF0 device and so on) as well as a representor for each SF function, such that both the SF and its representor reside in the DPU.
If the user queries local devices on the DPU side (not representor devices), they get the two (in this example) DPU PFs, p0 and p1. These two DPU local devices are the parent devices for:
7 representor devices –
- 5 representor devices shown as arrows to/from the host (devices with the prefix hpf*) in the diagram
- 2 representor devices for the SF devices, pf0sf0 and pf1sf0
- 2 local SF devices (not the SF representors), p0s0 and p1s0
In the diagram, the topology is split into two parts (note the dotted line), each part is represented by a DPU physical device, p0 and p1, each of which is responsible for creating all other local devices (host PFs, host VFs, and DPU SFs). As such, the DPU physical device can be referred to as the parent device of the other devices and would have access to the representor of every other function (via doca_devinfo_rep_list_create).
Local Device and Representor Matching
Based on the topology diagram, the mmap export APIs can be used as follows:
|
Device to Select on Host When Using doca_mmap_export_dpu() |
DPU Matching Representor |
Device to Select on DPU When Using doca_mmap_create_from_export() |
|
pf0 – 0b:00.0 |
hpf0 – 0b:00.0 |
p0 – 03:00.0 |
|
pf0vf0 – 0b:00.2 |
hpf0vf0 – 0b:00.2 |
|
|
pf0vf1 – 0b:00.3 |
hpf0vf1 – 0b:00.3 |
|
|
pf1 – 0b:00.1 |
hpf1 – 0b:00.1 |
p1 – 03:00.1 |
|
pf1vf0 – 0b:00.4 |
hpf1vf0 – 0b:00.4 |
Expected Flow
Device Discovery
To work with DOCA libraries or DOCA Core objects, application must open and use a device on the DPU or host.
There are usually multiple devices available depending on the setup. See section "Topology" for more information.
An application can decide which device to select based on capabilities, the DOCA Core API, and every other library which provides a wide range of device capabilities. The flow is as follows:

- The application gets a list of available devices.
- Select a specific doca_devinfo to work with according to one of its properties and capabilities. This example looks for a specific PCIe address.
- Once the doca_devinfo that suits the user's needs is found, open doca_dev.
- After the user opens the right device, they can close the doca_devinfo list and continue working with doca_dev. The application eventually must close the doca_dev.
Representor Device Discovery
To work with DOCA libraries or DOCA Core objects, some applications must open and use a representor device on the DPU. Before they can open the representor device and use it, applications need tools to allow them to select the appropriate representor device with the necessary capabilities. The DOCA Core API provides a wide range of device capabilities to help the application select the right device pair (device and its DPU representor). The flow is as follows:
- The application "knows" which device it wants to use (e.g., by its PCIe BDF address). On the host, it can be done using DOCA Core API or OS services.
- On the DPU side, the application gets a list of device representors for a specific DPU local device.
- Select a specific doca_devinfo_rep to work with according to one of its properties. This example looks for a specific PCIe address.
- Once the doca_devinfo_rep that suits the user's needs is found, open doca_dev_rep.
- After the user opens the right device representor, they can close the doca_devinfo_rep list and continue working with doca_dev_rep. The application eventually must close doca_dev too.
As mentioned previously, the DOCA Core API can identify devices and their representors that have a unique property (e.g., the BDF address, the same BDF for the device, and its DPU representor).
Regarding representor device property caching, the function doca_devinfo_rep_create_list provides a snapshot of the DOCA representor device properties when it is called. If any representor's properties are changed dynamically (e.g., BDF address changes after bus reset), t he device properties that the function returns would not reflect this change. One should create the list again to get the updated properties of the representors.
DOCA Memory Subsystem
DOCA memory subsystem is designed to optimize performance while keeping a minimal memory footprint (to facilitate scalability) as main design goal.
DOCA memory has the following main components:
- doca_buf – this is the data buffer descriptor. This is not the actual data buffer, rather, it is a descriptor that holds metadata on the "pointed" data buffer.
- doca_mmap – this is the data buffers pool which doca_buf points at. The application provides the memory as a single memory region, as well as permissions for certain devices to access it.
As the doca_mmap serves as the memory pool for data buffers, there is also an entity called doca_buf_inventory which serves as a pool of doca_buf with same characteristics (see more in sections "DOCA Core Buffers" and "DOCA Core Inventories"). As all DOCA entities, memory subsystem objects are opaque and can be instantiated by DOCA SDK only.
The following diagram shows the various modules within the DOCA memory subsystem.
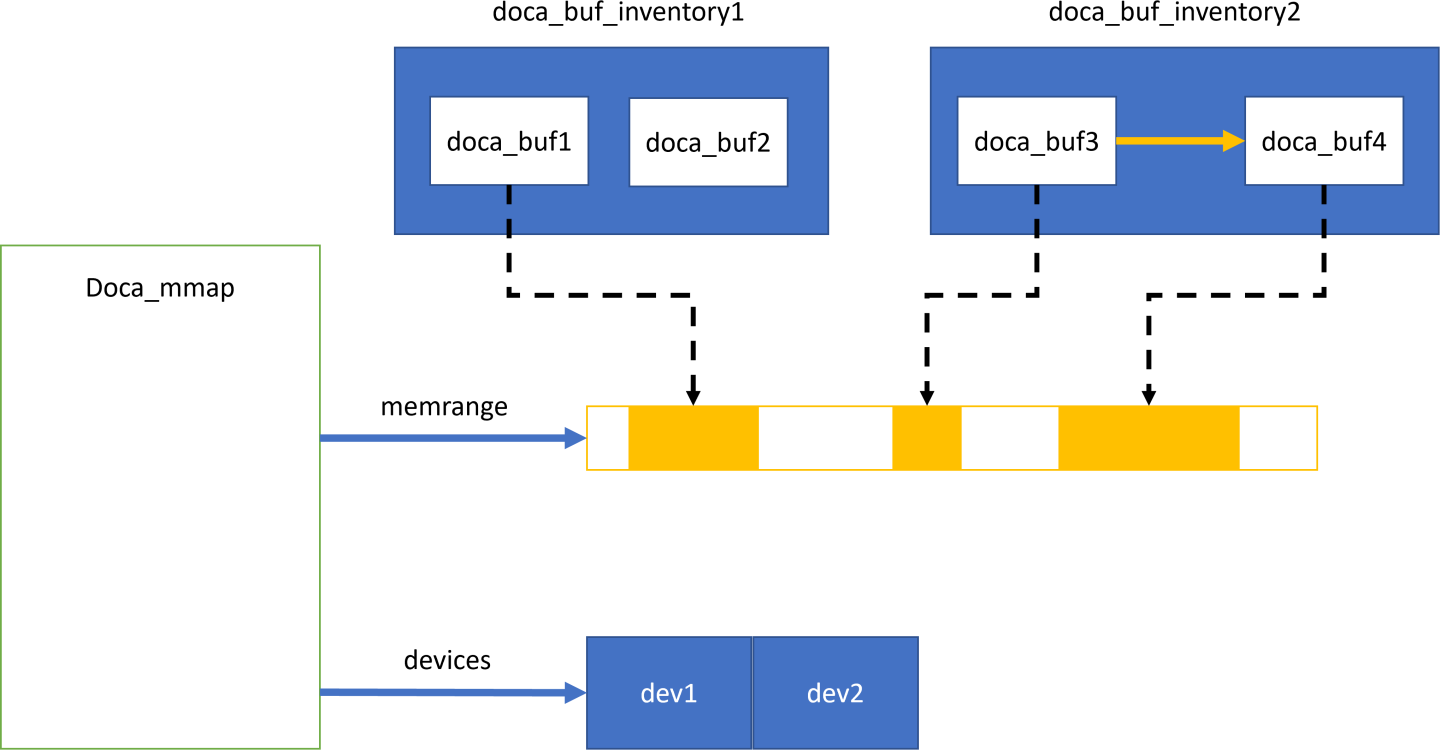
In the diagram, you may see two doca_buf_inventorys. Each doca_buf points to a portion of the memory buffer which is part of a doca_mmap. The mmap is populated with one continuous memory buffer memrange and is mapped to two devices, dev1 and dev2.
Requirements and Considerations
The DOCA memory subsystem mandates the usage of pools as opposed to dynamic allocation
- Pool for doca_buf → doca_buf_inventory
- Pool for data memory → doca_mmap
- The memory buffer in the mmap can be mapped to one device or more
- Devices in the mmap are restricted by access permissions defining how they can access the memory buffer
- doca_buf points to a specific memory buffer (or part of it) and holds the metadata for that buffer
- The internals of mapping and working with the device (e.g., memory registrations) is hidden from the application
- As best practice, the application should start the doca_mmap in the initialization phase as the start operation is time consuming. doca_mmap should not be started as part of the data path unless necessary.
- The host-mapped memory buffer can be accessed by DPU
doca_mmap
doca_mmap is more than just a data buffer as it hides a lot of details (e.g., RDMA technicalities, device handling, etc.) from the application developer while giving the right level of abstraction to the software using it. doca_mmap is the best way to share memory between the host and the DPU so the DPU can have direct access to the host-side memory or vice versa.
DOCA SDK supports several types of mmap that help with different use cases: local mmap and mmap from export.
Local mmap
This is the basic type of mmap which maps local buffers to the local device(s).
- The application creates the doca_mmap.
- The application sets the memory range of the mmap using doca_mmap_set_memrange. The memory range is memory that the application allocates and manages (usually holding the pool of data sent to the device's processing units).
- The application adds devices, granting the devices access to the memory region.
- The application can set a custom access token for a device in the mmap, using
doca_mmap_set_export_access_tokenso that mmap export operations use that token instead of an automatically generated random one. The application can specify the access permission for the devices to that memory range using doca_mmap_set_permissions.
- If the mmap is used only locally, then DOCA_ACCESS_LOCAL_* must be specified
- If the mmap is created on the host but shared with the DPU (see step 6), then DOCA_ACCESS_PCI_* must be specified
- If the mmap is created on the DPU but shared with the host (see step 6), then DOCA_ACCESS_PCI_* must be specified
- If the mmap is shared with a remote RDMA target, then DOCA_ACCESS_RDMA_* must be specified
The application starts the mmap.
WarningFrom this point no more changes can be made to the mmap.
- To share the mmap with the DPU/host or the RDMA remote target, call doca_mmap_export_pci or doca_mmap_export_rdma respectively. If appropriate access has not been provided, the export fails.
- The generated blob from the previous step can be shared out of band using a socket. If shared with a DPU, it is recommended to use the DOCA Comm Channel instead. See the DMA Copy application for the exact flow.
mmap from Export
This mmap is used to access the host memory (from the DPU) or the remote RDMA target's memory.
- The application receives a blob from the other side. The blob contains data returned from step 6 in the former bullet.
- The application calls doca_mmap_create_from_export and receives a new mmap that represents memory defined by the other side.
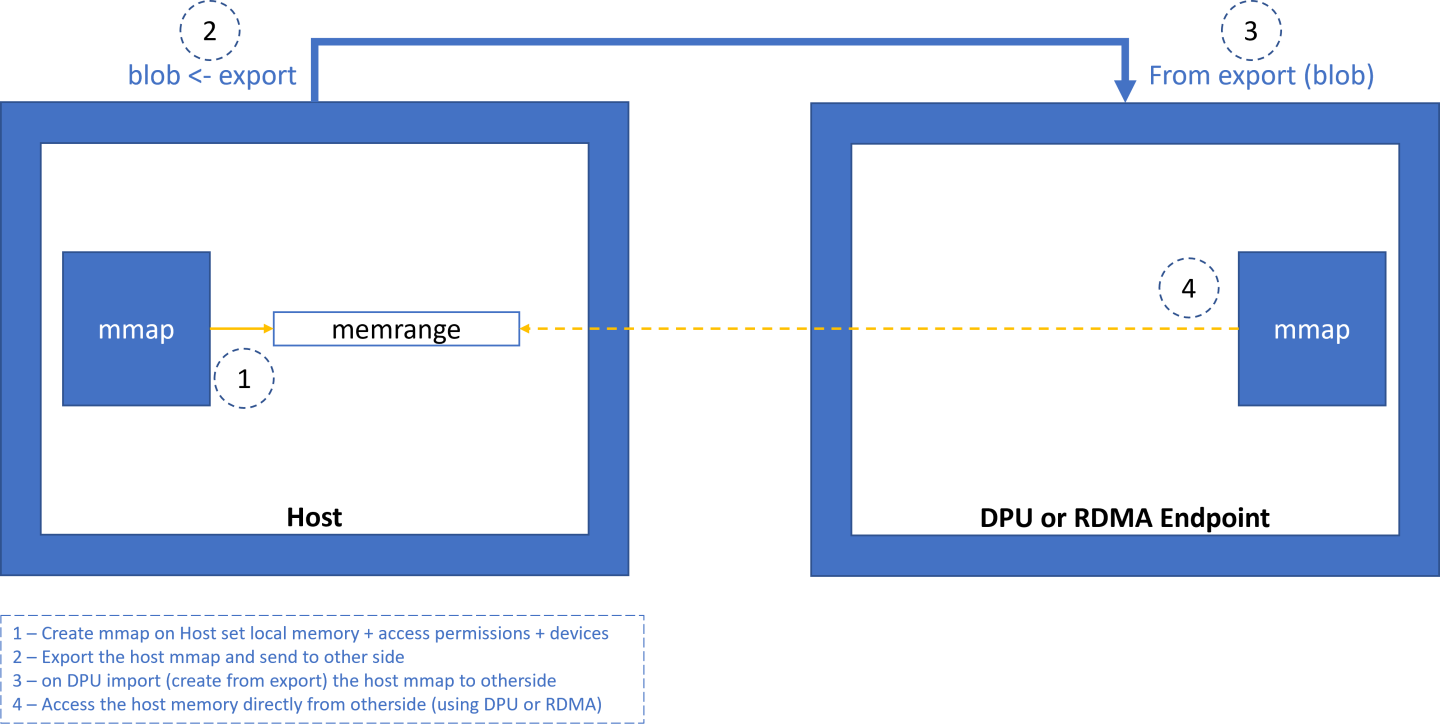
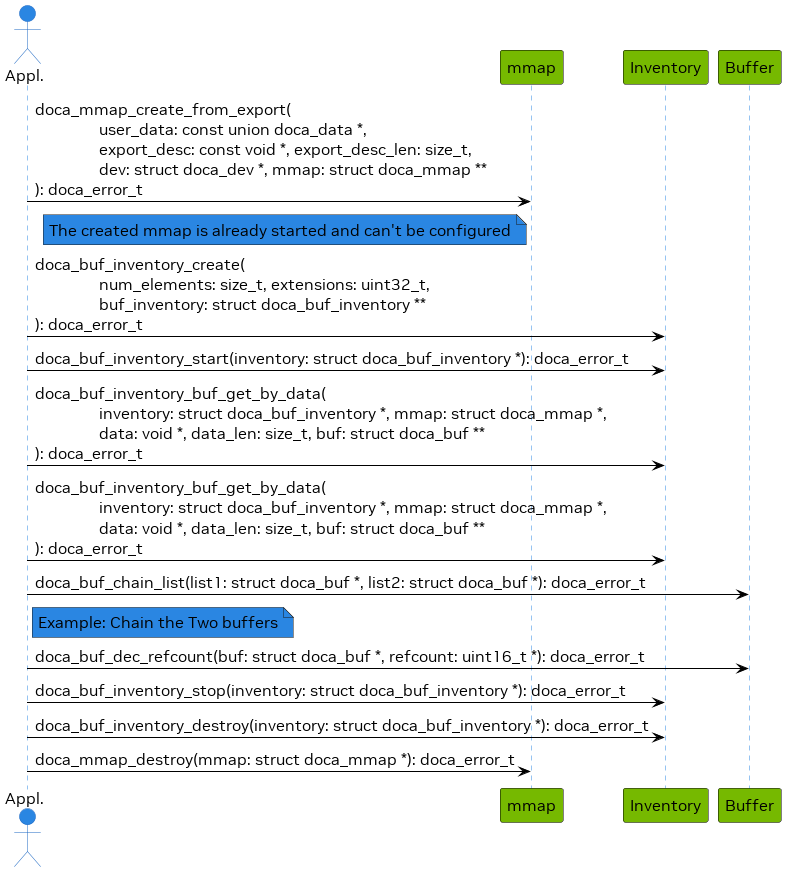
Now the application can create doca_buf to point to this imported mmap and have direct access to the other machine's memory.
The DPU can access memory exported to the DPU if the exporter is a host on the same machine. Or it can access memory exported through RDMA which can be on the same machine, a remote host, or on a remote DPU.
The host can only access memory exported through RDMA. This can be memory on a remote host, remote DPU, or DPU on same machine.
Buffers
The DOCA buffer object is used to reference memory that is accessible by the DPU hardware. The buffer can be utilized across different DPU accelerators. The buffer may reference CPU, GPU, host, or even RDMA memory. However, this is abstracted so once a buffer is created, it can be handled in a similar way regardless of how it got created. This section covers usage of the DOCA buffer after it is allocated.
The DOCA buffer has an address and length describing a memory region. Each buffer can also point to data within the region using the data address and data length. This distinguishes three sections of the buffer: The headroom, the dataroom, and the tailroom.
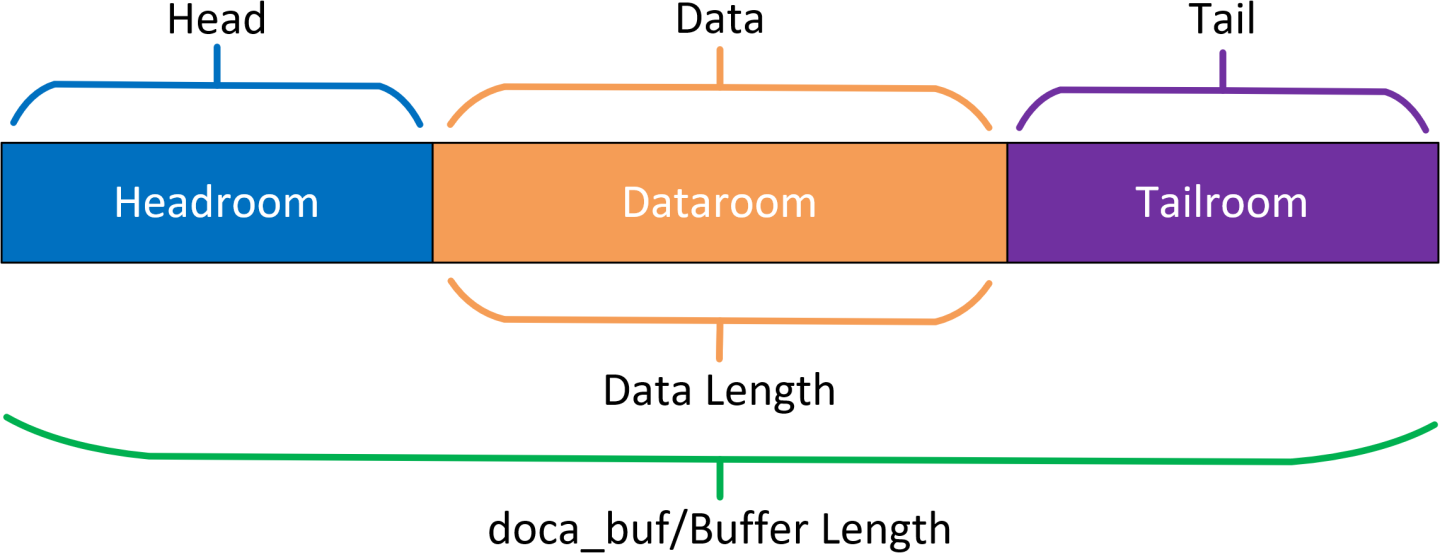
- Headroom – memory region starting from the buffer's address up to the buffer's data address
- Dataroom – memory region starting from the buffer's data address with a length indicated by the buffer's data length
- Tailroom – memory region starting from the end of the dataroom to the end of the buffer
- Buffer length – the total length of the headroom, the dataroom, and the tailroom
Buffer Considerations
- There are multiple ways to create the buffer but, once created, it behaves in the same way (see section "Inventories").
- The buffer may reference memory that is not accessible by the CPU (e.g., RDMA memory)
- The buffer is a thread-unsafe object
- The buffer can be used to represent non-continuous memory regions (scatter/gather list)
- The buffer does not own nor manage the data it references. Freeing a buffer does not affect the underlying memory.
Headroom
The headroom is considered user space. For example, this can be used by the user to hold relevant information regarding the buffer or data coupled with the data in the buffer's dataroom.
This section is ignored and remains untouched by DOCA libraries in all operations.
Dataroom
The dataroom is the content of the buffer, holding either data on which the user may want to perform different operations using DOCA libraries or the result of such operations.
Tailroom
The tailroom is considered as free writing space in the buffer by DOCA libraries (i.e., a memory region that may be written over in different operations where the buffer is used as output).
Buffer as Source
When using doca_buf as a source buffer, the source data is considered as the data section only (the dataroom).
Buffer as Destination
When using doca_buf as a destination buffer, data is written to the tailroom (i.e., appended after existing data, if any).
When DOCA libraries append data to the buffer, the data length is increased accordingly.
Scatter/Gather List
To execute operations on non-continuous memory regions, it is possible to create a buffer list. The list would be represented by a single doca_buf which represents the head of the list.
To create a list of buffers, the user must first allocate each buffer individually and then chain them. Once they are chained, they can be unchained as well:
- The chaining operation, doca_buf_chain_list(), receives two lists (heads) and appends the second list to the end of the first list
- The unchaining operation, doca_buf_unchain_list(), receives the list (head) and an element in the list, and separates them
- Once the list is created, it can be traversed using doca_buf_get_next_in_list(). NULL is returned once the last element is reached.
Passing the list to another library is same as passing a single buffer; the application sends the head of the list. DOCA libraries that support this feature can then treat the memory regions that comprise the list as one contiguous.
When using the buffer list as a source, the data of each buffer (in the dataroom) is gathered and used as continuous data for the given operation.
When using the buffer list as destination, data is scattered in the tailroom of the buffers in the list until it is all written (some buffers may not be written to).
Buffer Use Cases
The DOCA buffer is widely used by the DOCA acceleration libraries (e.g., DMA, compress, SHA). In these instances, the buffer can be provided as a source or as a destination.
Buffer use-case considerations:
- If the application wishes to use a linked list buffer and concatenate several doca_bufs to a scatter/gather list, the application is expected to ensure the library indeed supports a linked list buffer. For example, to check linked-list support for DMA memcpy task, the application may call doca_dma_cap_task_memcpy_get_max_buf_list_len().
- Operations made on the buffer's data are not atomic unless stated otherwise
Once a buffer has been passed to the library as part of the job, ownership of the buffer moves to the library until that job is complete
WarningWhen using doca_buf as an input to some processing library (e.g., doca_dma), doca_buf must remain valid and unmodified until processing is complete.
- Writing to an in-flight buffer may result in anomalous behavior. Similarly, there are no guarantees for data validity when reading from an in-flight buffer.
Inventories
The inventory is the object responsible for allocating DOCA buffers. The most basic inventory allows allocations to be done without having to allocate any system memory. Other inventories involve enforcing that buffer addresses do not overlap.
Inventory Considerations
- All inventories adhere to zero allocation after start.
Allocation of a DOCA buffer requires a data source and an inventory.
- The data source defines where the data resides, what can access it, and with what permissions.
- The data source must be created by the application. For creation of mmaps, see doca_mmap.
- The inventory describes the allocation pattern of the buffers, such as, random access or pool, variable-size or fixed-size buffers, and continuous or non-continuous memory.
- Some inventories require providing the data source, doca_mmap, when allocating the buffers, others require it on creation of the inventory.
- All inventory types are thread-unsafe.
Inventory Types
|
Inventory Type |
Characteristics |
When to Use |
Notes |
|
doca_buf_inventory |
Multiple mmaps, flexible address, flexible buffer size. |
When multiple sizes or mmaps are used. |
Most common use case. |
|
doca_buf_array |
Single mmap, fixed buffer size. User receives an array of pointers to DOCA buffers. |
Use for creating DOCA buffers on GPU. |
doca_buf_arr is configured on the CPU and created on the GPU. |
|
doca_bufpool |
Single mmap, fixed buffer size, address not controlled by the user. |
Use as a pool of buffers of the same characteristics when buffer address is not important. |
Slightly faster than doca_buf_inventory. |
Example Flow
The following is a simplified example of the steps expected for exporting the host mmap to the DPU to be used by DOCA for direct access to the host memory (e.g., for DMA):
Create mmap on the host (see section "Expected Flow" for information on how to choose the doca_dev to add to mmap if exporting to DPU). This example adds a single doca_dev to the mmap and exports it so the DPU/RDMA endpoint can use it.

Import to the DPU/RDMA endpoint (e.g., use the mmap descriptor output parameter as input to doca_mmap_create_from_export).
DOCA Execution Model
The execution model is based on hardware processing on data and application threads. DOCA does not create an internal thread for processing data.
The workload is made up of tasks and events. Some tasks transform source data to destination data. The basic transformation is a DMA operation on the data which simply copies data from one memory location to another. Other operations allow users to receive packets from the network or involve calculating the SHA value of the source data and writing it to the destination.
For instance, a transform workload can be broken into three steps:
- Read source data (doca_buf see memory subsystem).
- Apply an operation on the read data (handled by a dedicated hardware accelerator).
- Write the result of the operation to the destination (doca_buf see memory subsystem).
Each such operation is referred to as a task (doca_task).
Tasks describe operations that an application would like to submit to DOCA (hardware or DPU). To do so, the application requires a means of communicating with the hardware/DPU. This is where the doca_pe comes into play. The progress engine (PE) is a per-thread object used to queue tasks to offload to DOCA and eventually receive their completion status.
doca_pe introduces three main operations:
- Submission of tasks.
- Checking progress/status of submitted tasks.
- Receiving a notification on task completion (in the form of a callback).
A workload can be split into many different tasks that can be executed on different threads; each thread represented by a different PE. Each task must be associated to some context, where the context defines the type of task to be done.
A context can be obtained from some libraries within the DOCA SDK. For example, to submit DMA tasks, a DMA context can be acquired from doca_dma.h, whereas SHA context can be obtained using doca_sha.h. Each such context may allow submission of several task types.
A task is considered asynchronous in that once an application submits a task, the DOCA execution engine (hardware or DPU) would start processing it, and the application can continue to do some other processing until the hardware finishes. To keep track of which job has finished, there are two modes of operation: polling mode and event-driven mode.
Requirements and Considerations
- The task submission/execution flow/API is optimized for performance (latency)
- DOCA does not manage internal (operating system) threads. Rather, progress is managed by application resources (calling DOCA API in polling mode or waiting on DOCA notification in event-driven mode).
- The basic object for executing the task is a doca_task. Each task is allocated from a specific DOCA library context.
doca_pe represents a logical thread of execution for the application and tasks submitted to the progress engine (PE)
WarningPE is not thread safe and it is expected that each PE is managed by a single application thread (to submit a task and manage the PE).
- Execution-related elements (e.g., doca_pe, doca_ctx, doca_task) are opaque and the application performs minimal initialization/configuration before using these elements
- A task submitted to PE can fail (even after the submission succeeds). In some cases, it is possible to recover from the error. In other cases, the only option is to reinitialize the relevant objects.
- PE does not guarantee order (i.e., tasks submitted in certain order might finish out-of-order). If the application requires order, it must impose it (e.g., submit a dependent task once the previous task is done).
- A PE can either work in polling mode or event-driven mode, but not in both at same time
- All DOCA contexts support polling mode (i.e., can be added to a PE that supports polling mode)
DOCA Context
DOCA Context (struct doca_ctx) defines and provides (implements) task/event handling. A context is an instance of a specific DOCA library (i.e., when the library provides a DOCA Context, its functionality is defined by the list of tasks/events it can handle). When more than one type of task is supported by the context, it means that the supported task types have a certain degree of similarity to implement and utilize common functionality.
The following list defines the relationship between task contexts:
- Each context utilizes at least one DOCA Device functionality/accelerated processing capabilities
- For each task type there is one and only context type supporting it
- A context virtually contains an inventory per supported task type
- A context virtually defines all parameters of processing/execution per task type (e.g., size of inventory, device to accelerate processing)
Each context needs an instance of progress engine (PE) as a runtime for its tasks (i.e., a context must be associated with a PE to execute tasks).
The following diagram shows the high-level (domain model) relations between various DOCA Core entities.
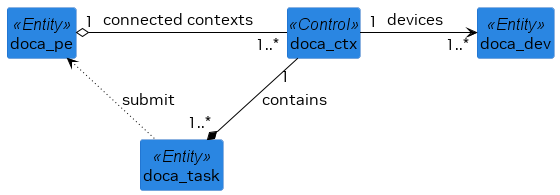
- doca_task is associated to a relevant doca_ctx that executes the job (with the help of the relevant doca_dev).
- doca_task, after it is initialized, is submitted to doca_pe for execution.
- doca_ctxs are connected to the doca_pe. Once a doca_task is queued to doca_pe, it is executed by the doca_ctx that is associated with that task in this PE.
The following diagram describes the initialization sequence of a context:

After the context is started, it can be used to enable the submission of tasks to a PE based on the types of tasks that the context supports. See section "DOCA Progress Engine" for more information.
Context is a thread-unsafe object which can be connected to a single PE only.
Configuration Phase
A DOCA context must be configured before attempting to start it using doca_ctx_start(). Some configurations are mandatory (e.g., providing doca_dev) while others are not.
- Configurations can be useful to allow certain tasks/events, to enable features which are disabled by default, and to optimize performance depending on a specific workload.
- Configurations are provided using setter functions. Refer to context documentation for a list of mandatory and optional configurations and their corresponding APIs.
- Configurations are provided after creating the context and before starting it. Once the context is started, it can no longer be configured unless it is stopped again.
Examples of common configurations:
- Providing a device – usually done as part of the create API
- Enabling tasks or registering to events – all tasks are disabled by default
Execution Phase
Once context configuration is complete, the context can be used to execute tasks. The context executes the tasks by offloading the workload to hardware, while software polls the tasks (i.e., waits) until they are complete.
In this phase, an application uses the context to allocate and submit asynchronous tasks, and then polls tasks (waits) until completion.
The application must build an event loop to poll the tasks (wait), utilizing one of the following modes:
In this phase, the context and all core objects perform zero allocations by utilizing memory pools. It is recommended that the application utilizes same approach for its own logic.
State Machine
|
State |
Description |
|
Idle |
|
|
Starting |
This state is mandatory for CTXs where transition to running state is conditioned by one or more async op completions/external events. For example, when a client connects to comm channel, it enters running state. Waiting for state change can be terminated by a voluntary (user) doca_ctx_stop() call or involuntary context state change due to internal error. |
|
Running |
|
|
Stopping |
|
The following diagram describes DOCA Context state transitions:
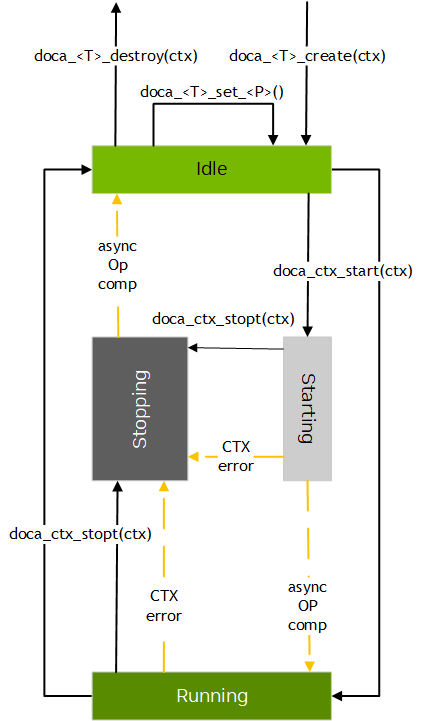
Internal Error
DOCA Context states can encounter internal errors at any time. If the state is starting or running, an internal error can cause an involuntary transition to stopping state.
For instance, an involuntary transition from running to stopping can happen when a task execution fails. This results in a completion with error for the failed task and all subsequent task completions.
After stopping, the state may become idle. However, doca_ctx_start() may fail if there is a configuration issue or if an error event prevented proper transition to starting or running state.
DOCA Task
A task is a unit of (functional/processing) workload offload-able to hardware. The majority of tasks utilize NVIDIA® BlueField® and NVIDIA® ConnectX® hardware to provide accelerated processing of the workload defined by the task. Tasks are asynchronous operations (e.g., tasks submitted for processing via non-blocking doca_task_submit() API).
Upon task completion, the preset completion callback is executed in context of doca_pe_progress() call. The completion callback is a basic/generic property of the task, similar to user data. Most tasks are IO operations executed/accelerated by NVIDIA device hardware.
Task Properties
Task properties share generic properties which are common to all task types and type-specific properties. Since task structure is opaque (i.e., its content not exposed to the user), the access to task properties provided by set/get APIs.
The following are generic task properties:
- Setting completion callback – it has separate callbacks for successful completion and completion with failure.
- Getting/setting user data – used in completion callback as some structure associated with specific task object.
- Getting task status – intended to retrieve error code on completion with failure.
For each task there is only one owner: a context object. There is a doca_task_get_ctx() API to get generic context object.
The following are generic task APIs:
- Allocating and freeing from CTX (internal/virtual) inventory
- Configuring via setters (or init API)
- Submit-able (i.e., implements doca_task_submit(task))
Upon completion, there is a set of getters to access the results of the task execution.
Task Lifecycle
This section describes the lifecycle of DOCA Task. Each DOCA Task object lifecycle:
- starts on the event of entering Running state by the DOCA Context owning the task i.e., once Running state entered application can obtain the task from CTX by calling doca_<CTX name>_task_<Task name>_alloc_init(ctx, ... &task).
- ends on the event of entering Stopped state by the DOCA Context owning the task i.e., application can no longer allocate tasks once the related DOCA Context left the Running state.
From application perspective DOCA Context provides a virtual task inventory The diagram below shows the how ownership if the DOCA Task passed from DOCA Context virtual inventory to application and than from application back to CTX, pay attention to the colors used in activation bars for application (APP) participant & DOCA Context (CTX) participant and DOCA Context Task virtual inventory (Task).
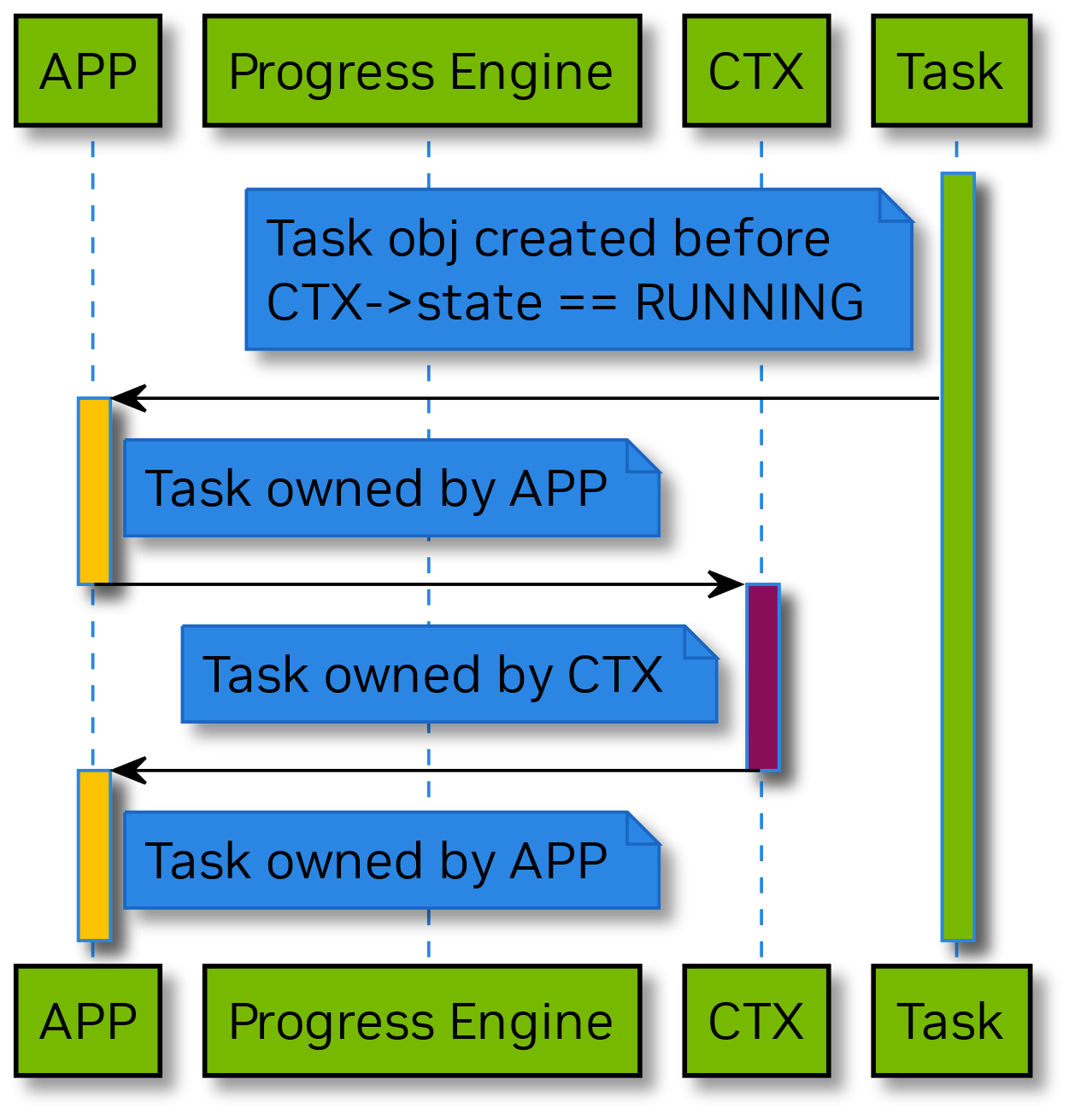
The diagram below shows the lifecycle of DOCA Task staring from its allocation to its submission.
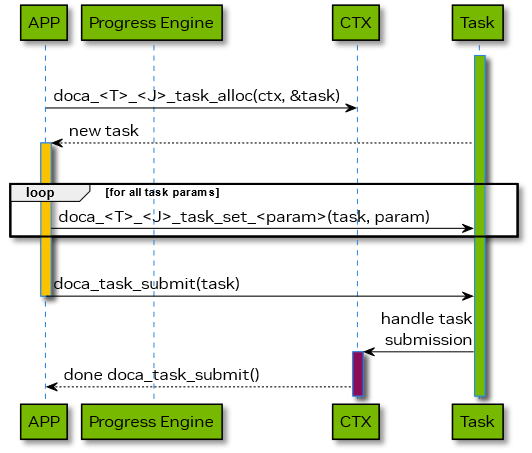
The diagram above displays following ownership transitions during DOCA Task object lifecycle:
- starting from allocation task ownership passed from context to application
- application may modify task attributes via API templated as doca_<CTX name>_task_<Task name>_set_<Parameter name>(task, param); on return from the task modification call the ownership of the task object returns to application.
- submit the task for processing in the PE, once all required modifications/settings of the task object completed. On task submission the ownership of the object passed to the related context.
The next two diagrams below shows the lifecycle of DOCA Task on its completion.
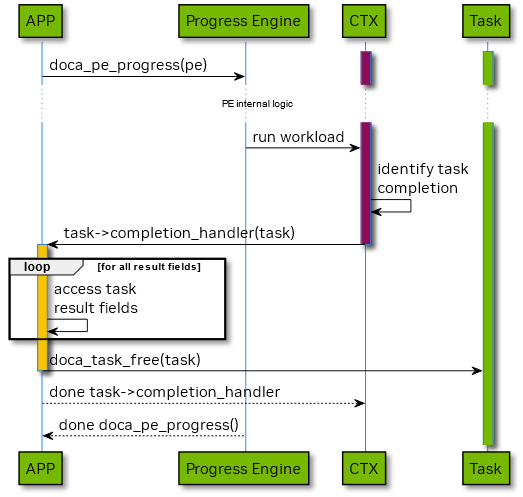
The diagram above displays following ownership transitions during DOCA Task object lifecycle:
- on DOCA Task completion the appropriate handler provided by application invoked; on handler invocation the DOCA Task ownership passed to application.
- after DOCA Task completion application may access task attributes & result fields utilizing appropriate APIs; application remains owner of the task object.
- application may call doca_task_free() when task is no longer needed; on return from the call task ownership passed to DOCA Context while task became uninitialized & pre-allocated till the context enters Idle state.
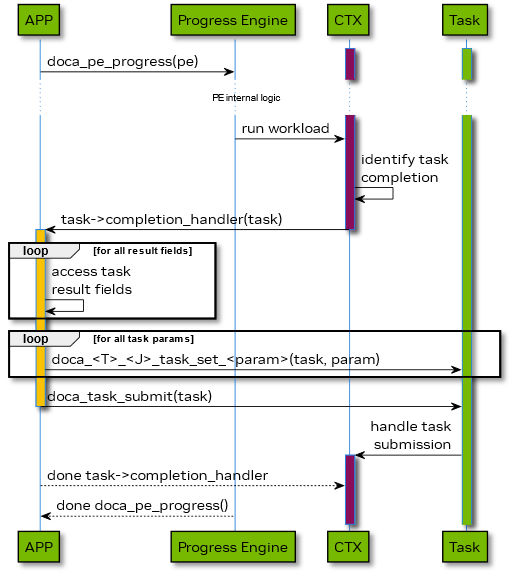
The diagram above displays similar to the previous diagram ownership transitions during DOCA Task object lifecycle with the only difference that instead of doca_task_free(task) doca_task_submit(task) was called:
- DOCA Task result (related attributes) can be accessed right after enter successful task completion callback, similar to the previous case
- lifecycle of the DOCA Task results ends on exit from the task completion callback scope.
- On doca_task_free() or doca_<CTX name>_task_<Task name>_set_<Parameter name>(task, param) call all task results should be considered invalidated regardless of scope.
The diagram below shows the lifecycle of DOCA Task set-able parameters while API to set such a parameter templated as doca_<CTX name>_task_<Task name>_set_<Parameter name>(task, param) .
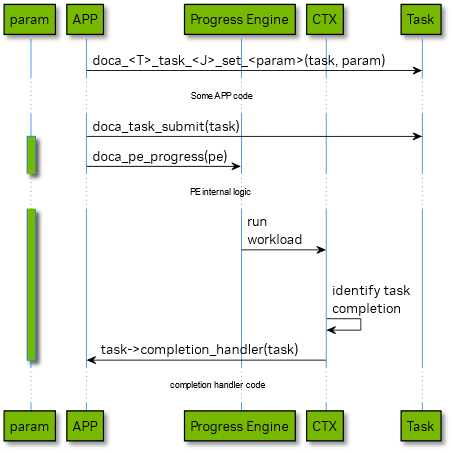
Green activation of param participant describes the time slice when all DOCA Task parameters owned by DOCA library. On doca_task_submit() call the ownership on all task arguments passed from application to the DOCA Context the related Task object belongs to. The ownership of task arguments passed back to application on task completion. The application should not modify and/or destroy/free Task argument related objects if it doesn’t own the argument.
DOCA Progress Engine
The progress engine (PE) enables asynchronous processing and handling of multiple tasks and events of different types in a single-threaded execution environment. It is an event loop for all context-based DOCA libraries, with I/O completion being the most common event type.
PE is designed to be thread unsafe (i.e., it can only be used in one thread at a time) but a single OS thread can use multiple PEs. The user can assign different priorities to different contexts by adding them to different PEs and adjusting the polling frequency for each PE accordingly. Another way to view the PE is as a queue of workload units that are scheduled for execution.
There are no explicit APIs to add and/or schedule a workload to/on a PE but a workload can be added by:
- Adding a DOCA context to PE
- Registering a DOCA event to probe (by the PE) and executing the associated handler if the probe is positive
PE is responsible for scheduling workloads (i.e., picking the next workload to execute). The order of workload execution is independent of task submission order, event registration order, or order of context associations with a given PE object. Multiple task completion callbacks may be executed in an order different from the order of related task submissions.
The following diagram describes the initialization flow of the PE:
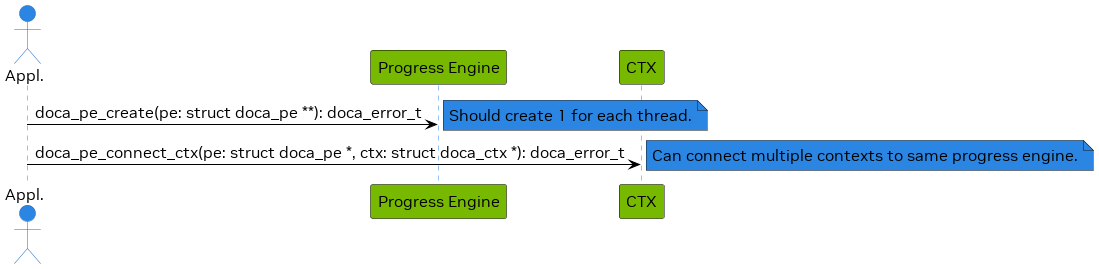
After a PE is created and connected to contexts, it can start progressing tasks which are submitted to the contexts. Refer to context documentation to find details such as what tasks can be submitted using the context.
Note that the PE can be connected to multiple contexts. Such contexts can be of the same type or of different types. This allows submitting different task types to the same PE and waiting for any of them to finish from the same place/thread.
After initializing the PE, an application can define an event loop using one of these modes:
PE as Event Loop Mode of Operation
All completion handlers for both tasks and events are executed in the context of doca_pe_progress(). doca_pe_progress() loops for every workload (i.e., for each workload unit) scheduled for execution:
Run the selected workload unit. For the following cases:
- Task completion, execute associated handler and break the loop and return status made some progress
- Positive probe of event, execute associated handler and break the loop and return status made some progress
- Considerable progress is made to contribute to future task completion or positive event probe, break the loop and return status made some progress
Otherwise, reach the end of the loop and return status no progress.
Polling Mode
In this mode, the application submits a task and then does busy-wait to find out when the task has completed.
The following diagram demonstrates this sequence:
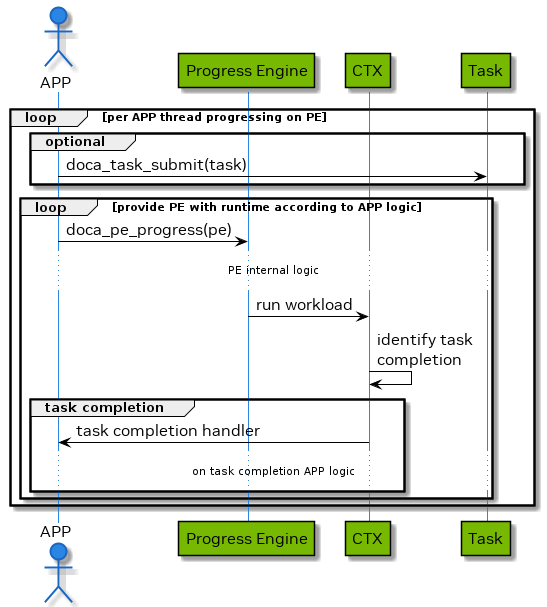
- The application submits all tasks (one or more) and tracks the number of task completions to know if all tasks are done.
The application waits for a task to complete by consecutive polls on doca_pe_progress().
- If doca_pe_progress() returns 1, it means progress is being made (i.e., some task completed or some event handled).
- Each time a task is completed or an event is handled, its preset completion or event handling callback is executed accordingly.
- If a task is completed with an error, preset task completion with error callback is executed (see section "Error Handling").
- The application may add code to completion callbacks or event handlers for tracking the amount of completed and pending workloads.
In this mode, the application is always using the CPU even when it is doing nothing (busy-wait).
Blocking Mode - Notification Driven
In this mode, the application submits a task and then waits for a notification to be received before querying the status.
The following diagram demonstrates this sequence:
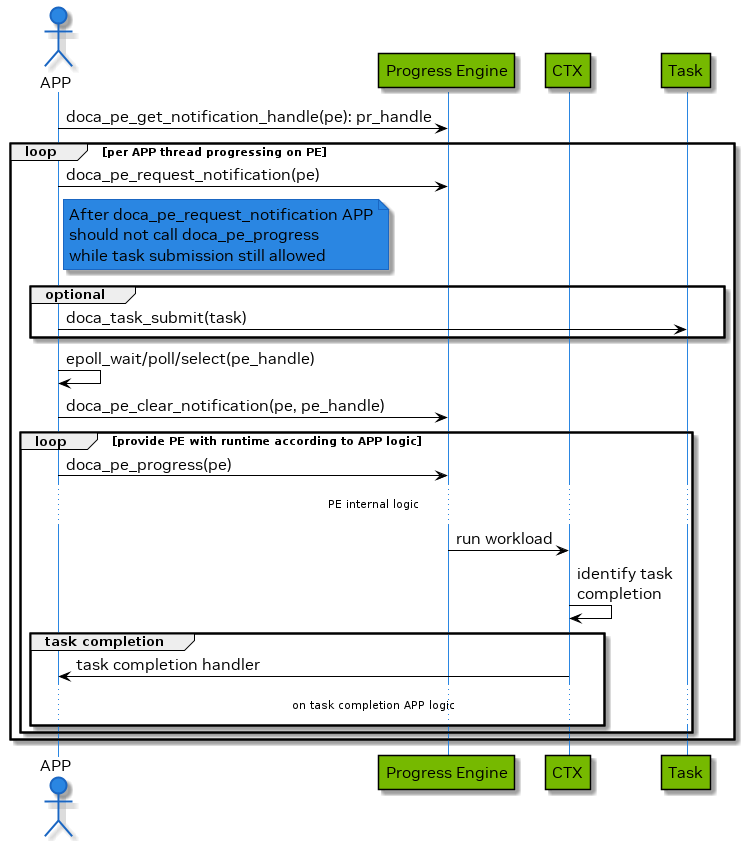
- The application gets a notification handle from the doca_pe representing a Linux file descriptor which is used to signal the application that some work has finished.
The application then arms the PE with doca_pe_request_notification().
WarningThis must be done every time an application is interested in receiving a notification from the PE.
WarningAfter doca_pe_request_notification(), no calls to doca_pe_progress() are allowed. In other words, doca_pe_request_notification() should be followed by doca_pe_clear_notification before any calls to doca_pe_progress().
- The application submits a task.
- The application waits (e.g., Linux epoll/select) for a signal to be received on the pe-fd.
- The application clears the notifications received, notifying the PE that a signal has been received and allowing it to perform notification handling.
The application attempts to handle received notifications via (multiple) calls to doca_pe_progress().
WarningThere is no guarantee that the call to doca_pe_progress() would execute any task completion/event handler, but the PE can continue the operation.
- The application handles its internal state changes caused by task completions and event handlers called in the previous step.
- Repeat steps 2-7 until all tasks are completed and all expected events are handled.
Progress Engine versus Epoll
The epoll mechanism in Linux and the DOCA PE handles high concurrency in event-driven architectures. Epoll, like a post office, tracks "mailboxes" (file descriptors) and notifies the "postman" (the epoll_wait function) when a "letter" (event) arrives. DOCA PE, like a restaurant, uses a single "waiter" to handle "orders" (workload units) from "customers" (DOCA contexts). When an order is ready, it is placed on a "tray" (task completion handler/event handler execution) and delivered in the order received. Both systems efficiently manage resources while waiting for events or tasks to complete.
DOCA Event
An event is a type of occurrence that can be detected or verified by the DOCA software, which can then trigger a handler (a callback function) to perform an action. Events are associated with a specific source object, which is the entity whose state or attribute change defines the event's occurrence. For example, a context state change event is caused by the change of state of a context object.
To register an event, the user must call the doca_<event_type>_reg(pe, ...) function, passing a pointer to the user handler function and an opaque argument for the handler. The user must also associate the event handler with a PE, which is responsible for running the workloads that involve event detection and handler execution.
Once an event is registered, it is periodically checked by the doca_pe_progress() function, which runs in the same execution context as the PE to which the event is bound. If the event condition is met, the handler function is invoked. Events are not thread-safe objects and should only be accessed by the PE to which they are bound.
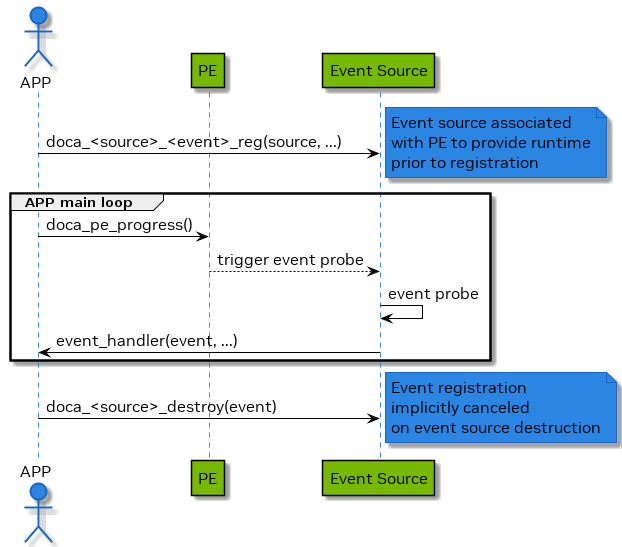
Error Handling
After a task is submitted successfully, consequent calls to doca_pe_progress() may fail (i.e., task failure completion callback is called).
Once a task fails, the context may transition to stopping state, in this state, the application has to progress all in-flight tasks until completion before destroying or restarting the context.
The following diagram shows how an application may handle an error from doca_pe_progress():
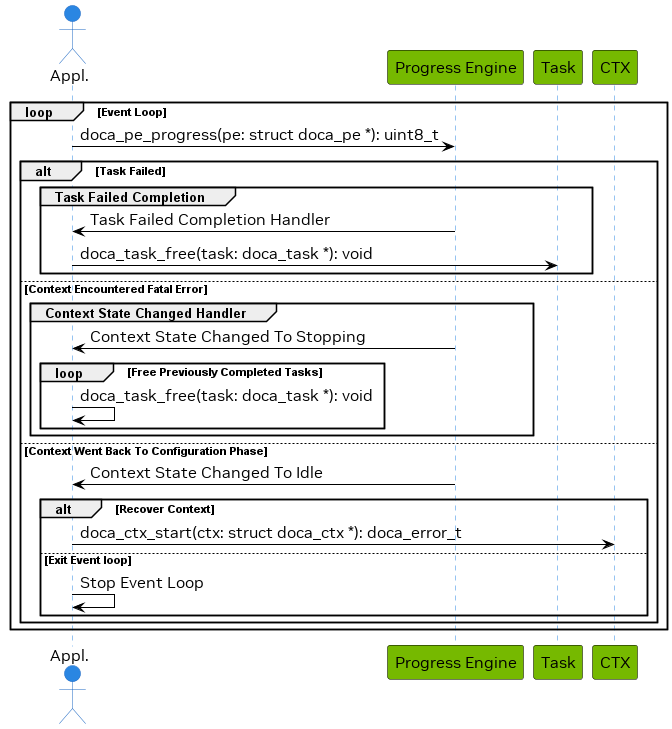
- Application runs event loop.
Any of the following may happen:
[Optional] Task fails, and the task failed completion handler is called
- This may be caused by bad task parameters or another fatal error
- Handler releases the task and all associated resources
[Optional] Context transitions to stopping state, and the context state changed handler is called
- This may be caused by failure of a task or another fatal error
- In this state, all in-flight tasks are guaranteed to fail
- Handler releases tasks that are not in-flight if such tasks exist
[Optional] Context transitions to idle state, and the context state changed handler is called
- This may happen due to encountering an error and the context does not have any resources that must be freed by the application
- In this case, the application may decide to recover the context by calling start again or it may decide to destroy the context and possibly exit the application
DOCA Graph Execution
DOCA Graph facilitates running a set of actions (jobs, user callbacks, graphs) in a specific order and dependencies. DOCA Graph runs on a DOCA work queue.
DOCA Graph creates graph instances that are submitted to the work queue (doca_workq_graph_submit).
Nodes
DOCA Graph is comprised of context, user, and sub-graph nodes. Each of these types can be in any of the following positions in the network:
- Root nodes – a root node does not have a parent. The graph can have one or more root nodes. All roots begin running when the graph instance is submitted.
- Edge nodes – an edge node is a node that does not have child nodes connected to it. The graph instance is completed when all edge nodes are completed.
- Intermediate node – a node connected to parent and child nodes
Context Node
A context node runs a specific DOCA job and uses a specific DOCA context (doca_ctx). The context must be added to the work queue before the graph is started.
The job lifespan must be longer or equal to the life span of the graph instance.
User Node
A user node runs a user callback to facilitate performing actions during the run time of the graph instance (e.g., adjust next node job data, compare results).
Sub-graph Node
A sub-graph node runs an instance of another graph.
Using DOCA Graph
- Create the graph using doca_graph_create.
- Create the graph nodes (e.g., doca_graph_ctx_node_create).
Define dependencies using doca_graph_add_dependency.
WarningDOCA graph does not support circle dependencies (e.g., A => B => A).
- Start the graph using doca_graph_start.
- Add the graph to a work queue using doca_graph_workq_add.
- Create the graph instance using doca_graph_instance_create.
- Set the nodes data (e.g., doca_graph_instance_set_ctx_node_data).
- Submit the graph instance to the work queue using doca_workq_graph_submit.
Call doca_workq_progress_retrieve until it returns DOCA_SUCCESS:
- doca_workq_progress_retrieve returns DOCA_ERROR_AGAIN for every node and returns DOCA_SUCCESS when the graph instance is completed.
- doca_event::type == DOCA_GRAPH_JOB indicates that a graph instance is completed.
- doca_event::result::u64 contains the graph instance status (0 implies DOCA_SUCCESS).
- Work queue can run graph instances and standalone jobs simultaneously.
DOCA Graph Limitations
- DOCA Graph does not support circle dependencies
- DOCA Graph must contain at least one context node. A graph containing a sub-graph with at least one context node is a valid configuration.
DOCA Graph Sample
The graph sample is based on the DOCA SHA and DOCA DMA libraries. The sample calculates a SHA value and copies a source buffer to a destination buffer in parallel.
The graph ends with a user callback node that prints the SHA value and compares the source with the DMA destination.
Running DOCA Graph Sample
Refer to the following documents:
- NVIDIA DOCA Installation Guide for Linux for details on how to install BlueField-related software.
- NVIDIA DOCA Troubleshooting Guide for any issue you may encounter with the installation, compilation, or execution of DOCA samples.
To build a given sample:
cd /opt/mellanox/doca/samples/doca_common/graph/ meson build ninja -C build
Sample (e.g., doca_graph) usage:
./build/doca_graph
No parameters required.
Alternative Data Path
DOCA Progress Engine utilizes the CPU to offload data path operations to hardware. However, some libraries support utilization of DPA and/or GPU.
Considerations:
- Not all contexts support alternative datapath
- Configuration phase is always done on CPU
- Datapath operations are always offloaded to hardware. The unit that offloads the operation itself can be either CPU/DPA/GPU.
- The default mode of operation is CPU
- Each mode of operation introduces a different set of APIs to be used in execution path. The used APIs are mutually exclusive for specific context instance.
DPA
Users must first refer to the programming guide of the relevant context (e.g., DOCA RDMA) to check if datapath on DPA is supported. Additionally, the guide provides what operations can be used.
To set the datapath mode to DPA, acquire a DOCA DPA instance, then use the doca_ctx_set_datapath_on_dpa() API.
After the context has been started with this mode, it becomes possible to get a DPA handle, using an API defined by the relevant context (e.g., doca_rdma_get_dpa_handle()). This handle can then be used to access DPA data path APIs within DPA code.
GPU
Users must first refer to the programming guide of the relevant context (E.g., DOCA Ethernet) to check if datapath on GPU is supported. Additionally, the guide provides what operations can be used.
To set the data path mode to GPU, acquire a DOCA GPU instance, then use the doca_ctx_set_datapath_on_gpu() API.
After the context has been started with this mode, it becomes possible to get a GPU handle, using an API defined by the relevant context (e.g., doca_eth_rxq_get_gpu_handle()). This handle can then be used to access GPU data path APIs within GPU code.
Object Life Cycle
Most DOCA Core objects share the same handling model in which:
- The object is allocated by DOCA so it is opaque for the application (e.g., doca_buf_inventory_create, doca_mmap_create).
- The application initializes the object and sets the desired properties (e.g., doca_mmap_set_memrange).
- The object is started, and no configuration or attribute change is allowed (e.g., doca_buf_inventory_start, doca_mmap_start).
- The object is used.
- The object is stopped and deleted (e.g., doca_buf_inventory_stop → doca_buf_inventory_destroy, doca_mmap_stop → doca_mmap_destroy).
The following procedure describes the mmap export mechanism between two machines (remote machines or host-DPU):
- Memory is allocated on Machine1.
- Mmap is created and is provided memory from step 1.
- Mmap is exported to the Machine2 pinning the memory.
- On the Machine2, an imported mmap is created and holds a reference to actual memory residing on Machine1.
- Imported mmap can be used by Machine2 to allocate buffers.
- Imported mmap is destroyed.
- Exported mmap is destroyed.
- Original memory is destroyed.
RDMA Bridge
The DOCA Core library provides building blocks for applications to use while abstracting many details relying on the RDMA driver. While this takes away complexity, it adds flexibility especially for applications already based on rdma-core. The RDMA bridge allows interoperability between DOCA SDK and rdma-core such that existing applications can convert DOCA-based objects to rdma-core-based objects.
Requirements and Considerations
- This library enables applications already using rdma-core to port their existing application or extend it using DOCA SDK.
- Bridge allows converting DOCA objects to equivalent rdma-core objects.
DOCA Core Objects to RDMA Core Objects Mapping
The RDMA bridge allows translating a DOCA Core object to a matching RDMA Core object. The following table shows how the one object maps to the other.
|
RDMA Core Object |
DOCA Equivalent |
RDMA Object to DOCA Object |
DOCA Object to RDMA Object |
|
ibv_pd |
doca_dev |
doca_dev_open_from_pd |
doca_dev_get_pd |
|
ibv_mr |
doca_buf |
- |
doca_buf_get_mkey |
Progress Engine Samples
All progress engine (PE) samples use DOCA DMA because of its simplicity. PE samples should be used to understand the PE not DOCA DMA.
pe_common
pe_common.c and pe_common.h contain code that is used in most or all PE samples.
Users can find core code (e.g., create MMAP) and common code that uses PE (e.g., poll_for_completion).
Struct pe_sample_state_base (defined in pe_common.h) is the base state for all PE samples, containing common members that are used by most or all PE samples.
pe_polling
The polling sample is the most basic sample for using PE. Start with this sample to learn how to use DOCA PE.
You can diff between pe_polling_sample.c and any other pe_x_sample.c to see the unique features that the other sample demonstrates.
The sample demonstrates the following functions:
How to create a PE
How to connect a context to the PE
How to allocate tasks
How to submit tasks
How to run the PE
How to cleanup (e.g., destroy context, destroy PE)
WarningPay attention to the order of destruction (e.g., all contexts must be destroyed before the PE).
The sample performs the following:
Uses one DMA context.
Allocates and submits 16 DMA tasks.
NoteTask completion callback checks that the copied content is valid.
Polls until all tasks are completed.
pe_async_stop
A context can be stopped while it still processes tasks. This stop is asynchronous because the context must complete/abort all tasks.
The sample demonstrates the following functions:
How to asynchronously stop a context
How to implement a context state changed callback (with regards to context moving from stopping to idle)
How to implement task error callback (check if this is a real error or if the task is flushed)
The sample performs the following:
Submits 16 tasks and stops the context after half of the tasks are completed.
Polls until all tasks are complete (half are completed successfully, half are flushed).
The difference between pe_polling_sample.c and pe_async_stop_sample.c is to learn how to use PE APIs for event-driven mode.
pe_event
Event-driven mode reduces CPU utilization (wait for event until a task is complete) but may increase latency or reduce performance.
The sample demonstrates the following functions:
How to run the PE in event-driven mode
The sample performs the following:
Runs 16 DMA tasks.
Waits for event.
The difference between pe_polling_sample.c and pe_event_sample.c is to learn how to use PE APIs for event-driven mode.
pe_multi_context
A PE can host more than one instance of a specific context. This facilitates running a single PE with multiple BlueField devices.
The sample demonstrates the following functions:
How to run a single PE with multiple instances of a specific context
The sample performs the following:
Connects 4 instances of DOCA DMA context to the PE.
Allocates and submits 4 tasks to every context instance.
Polls until all tasks are complete.
The difference between pe_polling_sample.c and pe_multi_context_sample.c is to learn how to use PE with multiple instances of a context.
pe_reactive
PE and contexts can be maintained in callbacks (task completion and state changed).
The sample demonstrates the following functions:
How to maintain the context and PE in the callbacks instead of the program's main function
The user must make sure to:
Review the task completion callback and the state changed callbacks
Review the difference between poll_to_completion and the polling loop in main
The sample performs the following:
Runs 16 DMA tasks.
Stops the DMA context in the completion callback after all tasks are complete.
The difference between pe_polling_sample.c and pe_reactive_sample.c is to learn how to use PE in reactive model.
pe_single_task_cb
A DOCA task can invoke a success or error callback. Both callbacks share the same structure (same input parameters).
DOCA recommends using 2 callbacks:
Success callback – does not need to check the task status, thereby improving performance
Error callback – may need to run a different flow than success callback
The sample demonstrates the following functions:
How to use a single callback instead of two callbacks
The sample performs the following:
Runs 16 DMA tasks.
Handles completion with a single callback.
The difference between pe_polling_sample.c and pe_single_task_comp_cb_sample.c is to learn how to use PE with a single completion callback.
pe_task_error
Task execution may fail causing the associated context (e.g., DMA) to move to stopping state due to this fatal error.
The sample demonstrates the following functions:
How to mitigate a task error during runtime
The user must make sure to:
Review the state changed callback and the error callback to see how the sample mitigates context error
The sample performs the following:
Submits 255 tasks.
Allocates the second task with invalid parameters that cause the HW to fail.
Mitigates the failure and polls until all submitted tasks are flushed.
The difference between pe_polling_sample.c and pe_task_error_sample.c is to learn how to mitigate context error.
pe_task_resubmit
A task can be freed or reused after it is completed:
Task resubmit can improve performance because the program does not free and allocate the task.
Task resubmit can reduce memory usage (using a smaller task pool).
Task members (e.g., source or destination buffer) can be set, so resubmission can be used if the source or destination are changed every iteration.
The sample demonstrates the following functions:
How to re-submit a task in the completion callback
How to replace buffers in a DMA task (similar to other task types)
The sample performs the following:
Allocates a set of 4 tasks and 16 buffer pairs.
Uses the tasks to copy all sources to destinations by resubmitting the tasks.
The difference between pe_polling_sample.c and pe_task_resubmit_sample.c is to learn how to use task resubmission.
pe_task_try_submit
doca_task_submit does not validate task inputs (to increase performance). Developers can use doca_task_try_submit to validate the tasks during development.
Task validation impacts performance and should not be used in production.
The sample demonstrates the following functions:
How to use doca_task_try_submit instead of doca_task_submit
The sample performs the following:
Allocates and tries to submit tasks using doca_task_try_submit.
The difference between pe_polling_sample.c and pe_task_try_submit_sample.c is to learn how to use doca_task_try_submit.
Graph Sample
The graph sample demonstrates how to use DOCA graph with PE. The sample can be used to learn how to build and use DOCA graph.
The sample uses two nodes of DOCA DMA and one user node.
The graph runs both DMA nodes (copying a source buffer to two destinations). Once both nodes are complete, the graph runs the user node that compares the buffers.
The sample runs 10 instances of the graph in parallel.
This section lists changes to the DOCA SDK which impacts backward compatibility.
DOCA Core doca_buf
Up to DOCA 2.0.2, the data length of the buffer is ignored when using the buffer as an output parameter, and the new data was written over the data that was there beforehand. From now on, new data is appended after existing data (if any) while updating the data length accordingly.
Because of this change, it is recommended that a destination buffer is allocated without a data section (data length 0), for ease of use.
In cases where the data length is 0 in a destination buffer, this change would go unnoticed (as appending the data and writing to the data section has the same result).
Reusing buffers requires resetting the data length when wishing to write to the same data address (instead of appending the data), overwriting the existing data. A new function, doca_buf_reset_data_len(), has been added specifically for this need.