User Interface Guide#
Version 1.5.0
Fleet Intelligence is designed to provide organizations with robust inventory, integrity, and health monitoring capabilities for their NVIDIA GPU fleet. By installing a host-based agent that communicates with NVIDIA’s Fleet Intelligence service, you have access to a near-real-time visualization of all hosts with GPUs enrolled.
Accessing Fleet Intelligence#
Open the Fleet Intelligence dashboard. When the page loads, log in with NVIDIA GPU Cloud (NGC).
After you log in, you see the accounts, organizations, and teams you can access. Select the team your administrator enabled for Fleet Intelligence, then click Continue. For more information about NGC accounts, organizations, and teams, see the NGC User Guide.
If NGC Catalog opens after you log in, use the upper-left menu: click NGC Catalog, then select Fleet Intelligence.

You are now on the Fleet Intelligence home screen. The following section walks through the dashboard: customizing the view, adding and grouping hosts, inspecting machine details, reviewing events, and generating reports.
The Dashboard#
The dashboard, shown in the following figure, is the central panel for Fleet Intelligence. The core features of the header include, from left to right:
NVIDIA GPU Cloud tool (upper-left) — Fleet Intelligence.
Fleet Intelligence tabs — Dashboard, Inventory, Debugging, Reports, Settings.
Info icon — shows the current version of Fleet Intelligence.
Alerts — opens active alerts for your GPU fleet.
Help (?) — opens NVIDIA GPU Cloud help.
NVIDIA GPU Cloud menu.
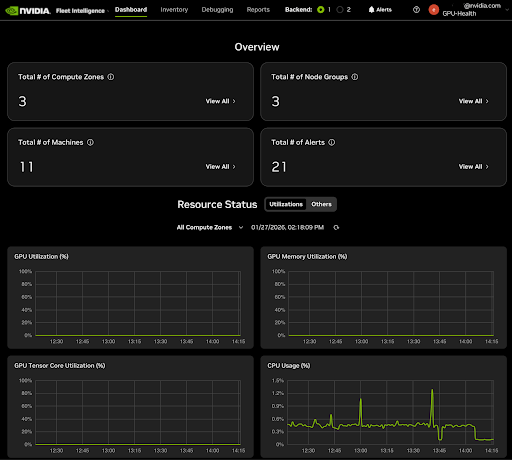
The main panel provides an inventory overview, alert summary, and a time-based overview of the usage and utilization of your entire GPU fleet. The main panel view can easily be switched to GPU power, speed, and memory usage by clicking the Others button in the Resource Status section.
Selecting the View All button in the All Compute Zones, All Node Groups, or All Total Machines panels opens the corresponding pages in the Inventory tab. See the Inventory section of this guide for details.
The Total # of Alerts panel View All button and the Alerts button in the header open a quick summary of all active alerts in your GPU fleet. Alerts are grouped by nodes and can be expanded to show the type of alert for each host.
Inventory#
Under the Inventory tab, you see the three views and an Add New Node button. Start by adding a node; a new window opens with the installation wizard.
The wizard walks you through downloading the .deb or
.rpm package from the Fleet Intelligence Agent GitHub page, or
through instructions for a Helm chart installation on Kubernetes.
Select the installation method and the commands to install the agent for your selected method will be presented (for example, Ubuntu and Red Hat derivatives), including adding the CUDA repository to your system for the DCGM installation if needed. If the NVIDIA Data Center GPU Manager (DCGM) repository is added, the Fleet Intelligence agent installation will include it as a dependency.
In step 3, follow the link to the Fleet Intelligence enrollment token management page. Create a new token or reuse an existing, unexpired token. If you generate a new token, choose the validity period and click Next. The token is shown for you to copy.
Note
Enrollment tokens are shown only once. Copy and store them securely before exiting the wizard.
Lastly, run the command shown under Enable Backend Communication to enroll the agent with the Fleet Intelligence service. Be sure to pass the compute-zone and node-group to the agent, as these will be used to group the node in the Fleet Intelligence service.
Note
As of version 1.4.2 of the Fleet Intelligence service, compute-zone and node-group are passed from the agent and may no longer be assigned in the Fleet Intelligence service user interface.
Once the agent initializes, it should take about one to five minutes for the node information to appear in the Inventory -> Machine View list. The Compute Zones and Node Groups will appear as passed from the agent or Unassigned if not passed from the agent.
Machine Details#
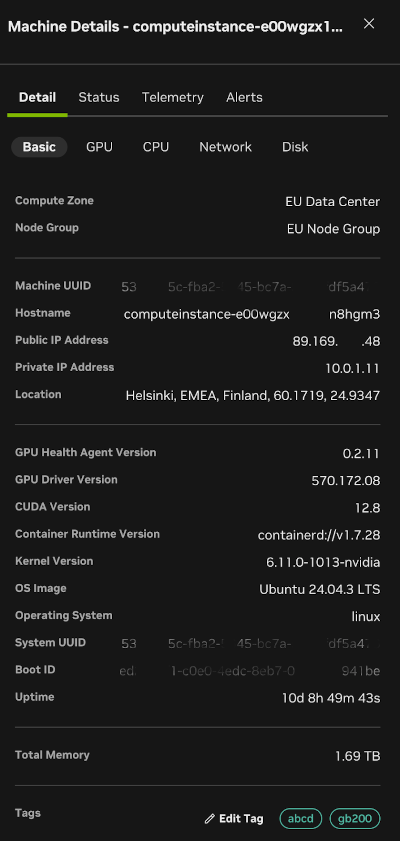
In any of the inventory panels, when you click a machine’s host name, a side panel opens on the right with details about the state of the machine. There are four tabs on this panel. The Detail tab presents metadata about the machine, including the Fleet Intelligence agent, GPU driver, CUDA, kernel, and OS versions. Sub-tabs of the Detail tab (not shown) provide collected metadata for GPU, CPU, network, and disk.
|
|
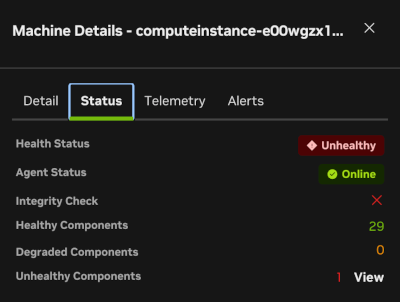
The Status tab summarizes major component status, includes the GPU integrity check, and shows overall node status.
The third tab, Telemetry, shows graphs of the collected telemetry for utilization, temperature, and power consumption for major components such as CPU, GPU, memory, and disk.
The last tab, Alerts, shows the current alerts that cause the node to be marked as “Unhealthy”. If the node is healthy, there are no critical alerts. There can still be active alerts for non-critical issues such as low disk space, low memory, and security alerts.
Alerts can have two or three levels of detail. Select the  menu
next to an alert to mute events for the whole fleet or to create
a notification rule for email, a Slack channel, or a
webhook. See the Alert Configuration section for more details.
menu
next to an alert to mute events for the whole fleet or to create
a notification rule for email, a Slack channel, or a
webhook. See the Alert Configuration section for more details.
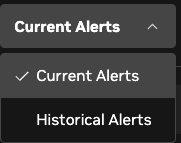
The machine Alerts panel can also use “Historical Alerts” mode, which shows alerts that occurred in the past but have since been resolved.
Events/Alerts#
For a fleet-wide view of alert and event status, in the upper menu
bar, click  . An Alerts panel opens on the right.
Unlike the machine-specific panel, it lists alerts for all
machines in the fleet. Each alert has multiple levels you can
drill into to see individual alerts and each reported instance.
. An Alerts panel opens on the right.
Unlike the machine-specific panel, it lists alerts for all
machines in the fleet. Each alert has multiple levels you can
drill into to see individual alerts and each reported instance.
Alerts can have two or three levels of detail. Select the menu
next to an alert to mute events for the whole fleet or to create
a notification rule for email, a Slack channel, or a
webhook. See the Alert Configuration section for more details.
The Alerts panel can also use “Historical Alerts” mode, which shows alerts that occurred in the past but have since been resolved.
Debugging - Detailed Analysis#
In the Debugging tab, use the Debugging Scope control (filter) on the left to choose a single node for detailed telemetry. You must also select a telemetry component group and a time range. Within that group you can select multiple metrics to show on one screen.
Settings#
The Settings tab lets you configure Fleet Intelligence options such as:
Managing agent enrollment tokens.
Data retention period.
Alert configuration.
Agent Enrollment Token Management#
The Agent Enrollment Token Management page lets you create new tokens, view existing token expiration dates, and revoke existing tokens.
Data Retention Period#
The Data Retention Period page lets you set how long Fleet Intelligence retains data. The default retention period is 365 days.
Alert Configuration#
Note
Please see the Cross-Organizational Data Sharing section for details on alert configuration when accessing Fleet Intelligence as a member of an external group.
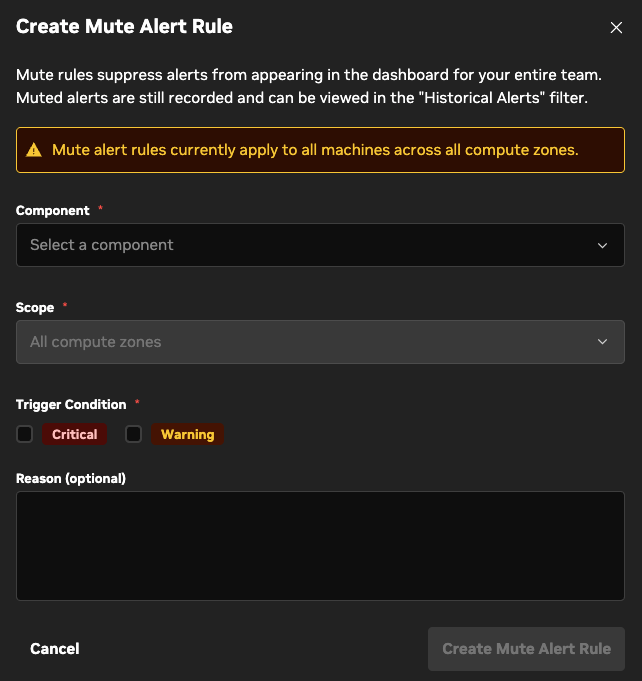
The Alert Configuration page configures notification and mute settings for Fleet Intelligence. It summarizes alert rules, which you can create or delete from individual machine pages.
There are two primary tabs on the page:
Notify Alert: Create and manage notify alert rules for specific components and scopes.
Mute Alert: Create and manage mute alert rules for specific components; mute rules always apply to the entire fleet.
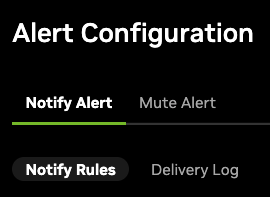
Each tab lists the full set of alert rules (notify or mute). The Notify tab also includes a delivery log of sent notifications.
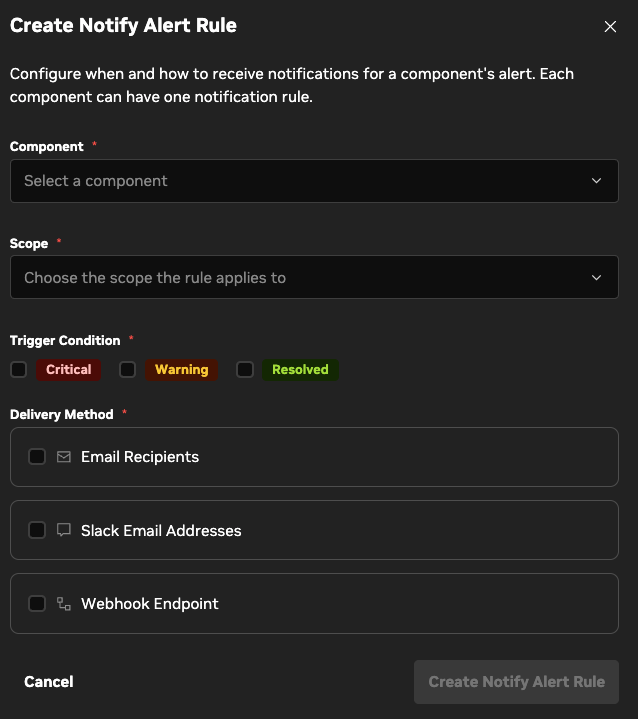
To create an alert rule, click Create Alert Rule in the upper-right corner of the tab. The Create Alert Rule dialog opens. Use it to choose the component and scope, notification method (email, Slack, webhook), and notification frequency.
To edit or delete an existing alert rule, click the button to the
right of the rule in the list.
Mute Alert Rules are similar to notify rules, but are applied to the entire fleet. These rules mute alerts from being seen and notifying or displaying on the dashboard.