Open topic with navigation
Overview
Buffers are memory on the CUDA device or in system memory. Bandwidth to device memory is higher than bandwidth to system memory, but the caches and shared memory provide much lower latency and higher bandwidth. Thus, the most efficient way to access device and system memory is to avoid re-accessing the same buffer data multiple times if it can be stored in shared memory or cache. Since the initial accesses to device and system memory must be done, they are often a performance bottleneck, so it is important to monitor bandwidth to buffers.
Chart
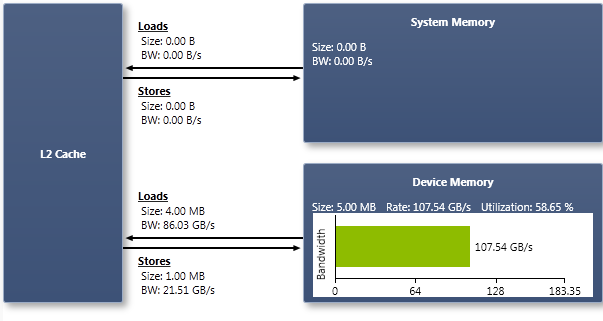
Buffers
All accesses to buffers from the GPU are routed through the L2 write-back cache. System memory can be accessed directly from a CUDA kernel using zero-copy, where the CUDA API is used to allocate system memory mapped into the CUDA device's address space. The Buffers chart shows the amount of data loaded and stored separately, and the sum of loads and stores in the System Memory and Device Memory regions, along with a percentage of overall bandwidth utilization.
|
Analysis
-
If the transfer rate to/from system is lower than expected …
-
… try making larger transfers. Small, sparse transfers can have high overhead.
-
If the transfer rate to/from device memory is at the limits of GPU, and still a bottleneck …
-
… try to improve cache efficiency, so less bandwidth is needed.
-
… check to ensure bandwidth is not being wasted due to inefficient access patterns incurring large numbers of cache transactions.
-
… consider using lower resolution data, or compressed data that can be staged in shared memory.
-
… consider a multi-GPU or cluster solution.
-
If the transfer rate to/from system memory is at the limits of PCI, and still a bottleneck …
-
… try to hide the latency of the transfer by overlapping it with concurrent computation or transfers in the opposite direction.
-
… try to improve cache efficiency, so less bandwidth is needed.
-
… check to ensure bandwidth is not being wasted due to inefficient access patterns incurring large numbers of cache transactions.
-
… ensure the CUDA device is using the highest supported PCI-Express version.
-
… consider using a GPU with more device memory, so large problems can fit entirely into the memory of one device.
-
… consider using lower resolution data, or compressed data that can be staged in device memory or shared memory
-
… consider a multi-GPU or cluster solution.
NVIDIA GameWorks Documentation Rev. 1.0.150630 ©2015. NVIDIA Corporation. All Rights Reserved.