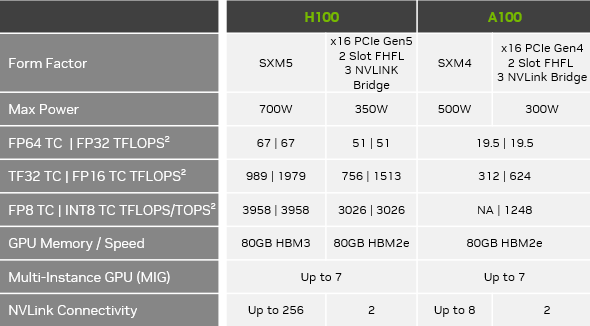
NVIDIA H100
The NVIDIA H100 GPU includes the following units:
7 or 8 GPCs, 57 TPCs, 2 SMs/TPC, 114 SMs per GPU
128 FP32 CUDA Cores/SM, 14592 FP32 CUDA Cores per GPU
4 4th-generation Tensor Cores per SM, 456 per GPU
80 GB HBM2e, 5 HBM2e stacks, 10 512-bit memory controllers
50 MB L2 cache
Fourth-generation NVLink and PCIe Gen 5 Support
This ninth-generation data center GPU is designed to deliver an order-of-magnitude performance leap for large-scale AI and HPC over the prior-generation NVIDIA A100 Tensor Core GPU. H100 carries over the major design focus of A100 to improve strong scaling for AI and HPC workloads, with substantial improvements in architectural efficiency.
Using its PCIe Gen 5 interface, H100 can interface with the highest performing x86 CPUs and SmartNICs / DPUs (Data Processing Units). H100 is designed for optimal connectivity with NVIDIA BlueField-3 DPUs for 400 Gb/s Ethernet or NDR (Next Data Rate) 400 Gb/s InfiniBand networking acceleration for secure HPC and AI workloads. With a memory bandwidth of 2 TB/s communication can be accelerated at data center scale. H100 also supports Single Root Input/Output Virtualization (SR-IOV), which allows sharing and virtualizing a single PCIe-connected GPU for multiple processes or Virtual Machines (VMs). H100 also allows a Virtual Function (VF) or Physical Function (PF) from a single SR-IOV PCIe-connected GPU to access a peer GPU over NVLink.

As the name suggests, Transformer Engine supercharges transformer-based deep learning models on H100, revolutionizing fields such as natural language processing, computer vision, and drug discovery. The TE uses software and custom NVIDIA Hopper Tensor Core technology designed to accelerate training for models built from transformers.
The challenge for models is to intelligently manage the precision to maintain accuracy while gaining the performance of smaller, faster numerical formats. TE enables this with custom, NVIDIA-tuned heuristics that dynamically choose between FP8 and FP16 calculations and automatically handle re-casting and scaling between these precisions in each layer. TE provides a collection of highly optimized building blocks for popular Transformer architectures and an automatic mixed precision-like API that can be used seamlessly with your PyTorch code. TE also includes a framework agnostic C++ API that can be integrated with other deep learning libraries to enable FP8 support for Transformers.
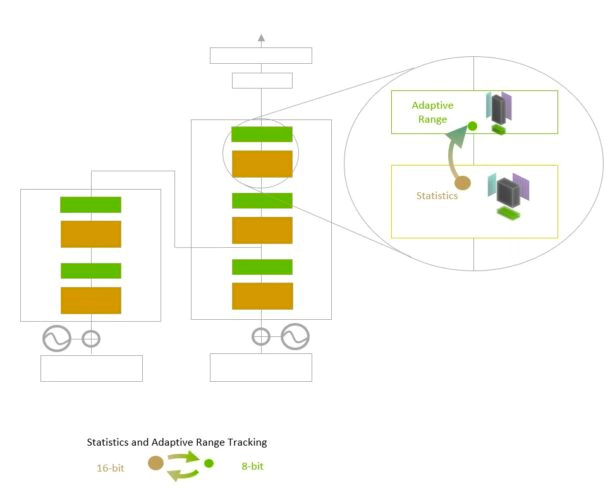
Transformer Engine uses per-layer statistical analysis to determine the optimal precision (FP16 or FP8) for each model layer, achieving the best performance while preserving model accuracy.
The H100 GPU can be partitioned into right-sized slices for workloads that don’t require a full GPU, which can be particularly beneficial for inference workloads. MIG enables multiple workloads to run on the same GPU for optimal efficiency. NVIDIA H100 introduces second-generation MIG partitioning, providing approximately 3x more compute capacity and nearly 2x more memory bandwidth per GPU instance. Additionally, H100 allows changing MIG profiles dynamically – no longer requiring a GPU reset.
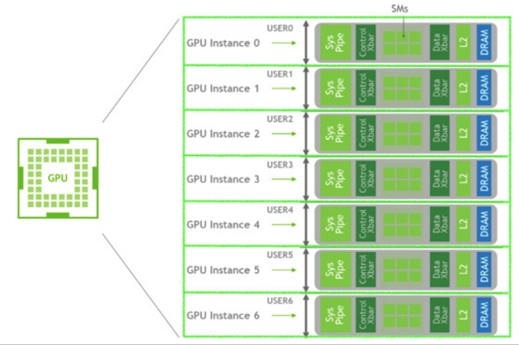
Confidential Computing capability with MIG-level Trusted Execution Environments (TEE) is now provided for the first time. Up to seven individual GPU Instances are supported, each with dedicated NVDEC and NVJPG units. Each Instance now includes its own set of performance monitors that work with NVIDIA developer tools. The following diagram illustrates a sample MIG configuration of CPU and GPU cooperatively providing multiple TEEs for multiple users sharing a single GPU.
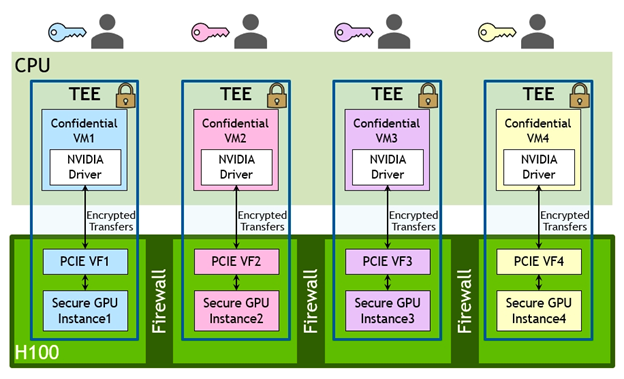
The H100 GPU can be divided into secure MIG instances. Encrypted transfers occur between CPU and GPU. GPU hardware virtualization is provided using PCIe SR-IOV (with one Virtual Function (VF) per MIG Instance). Multiple hardware-based security features provide confidentiality and data integrity, and hardware firewalls provide memory isolation between the GPU Instances.