Multi-Node Training with Tanzu Overview
At the end of this lab, you will understand how to train a deep learning model on a GPU accelerated Kubernetes cluster using GPU and MPI operators with NVIDIA AI Enterprise frameworks. We will go through and understand each level of software in greater detail in upcoming lab sections.
NVIDIA AI Enterprise software used in this lab includes:
Kubernetes on VMware Tanzu
MPI operator
Horovod
Tensorflow
Once you have gained an understanding of NVIDIA AI Enterprise software, you will train an AI model for Image Classification using a MobileNet model on the Stanford Online Products dataset.
Run through a single node preprocessing and AI training workflow.
Install MPI operator on a GPU accelerated Tanzu cluster.
Build a container for MPI workloads using NVIDIA AI Enterprise base containers.
Port the single node workflow to Horovod to run on multiple nodes.
Use MPI operator to run the Multinode workflow on Kubernetes.
One of the most computationally intensive steps in the machine learning pipeline is training the model. Its predictive capability and robustness largely depends on the amount of data it has been trained on. For organizations which have access to large amounts of data, Data Scientists will typically work on a smaller sample of the larger dataset to ensure that the model performs to agreed upon threshold. In production however, the model is trained on the full dataset and then deployed for inference.
Language models are systems that understand and generate text. In recent times, large language models based on the transformer neural network architectures have been gaining popularity because of their impressive accuracy in generating and understanding text for tasks like question answering, text summarization and sentence completion etc. These large language models are neural networks that are tens of gigabytes in size and with billions of parameters and are trained on petabytes of text data. Some of these models are so large that they don’t fit a single GPU and the ones that do fit take weeks to train on the dataset. This is one of the reasons why training large language models are usually left to the bigger organizations which have large amounts of compute at their disposal. Others generally take these large pretrained models and finetune them on a smaller domain specific dataset for their tasks. For example, A medical startup can take a pre-trained ASR (Automatic Speech Recognition) model from NVIDIA’s RIVA SDK and fine tune it on medical domain audio dataset to improve accuracy of obscure medical terms.
As models grow bigger, fine tuning the models also becomes a computationally intensive task and may require more than one GPU to speedup training. As such, the task can be divided among multiple GPU workers spanning multiple hosts. This is called distributed training. There are two types of distributed model training paradigms; Model Parallelism and Data Parallelism.
Model Parallelism
A large model, like GPT-3, has 175B parameters (requires 700 GB of GPU memory) and will not fit within a single GPU’s memory. Model parallelism involves splitting the model and running each part of the model on a different GPUs. The first batch of the dataset is read and then passed to the input layer on GPU-0. This result of the part of the model on GPU-0 is then passed over to GPU-1 and so on until the output from the final GPU is collected and the error is back propagated to tune the model.
Data Parallelism
A more commonly used distributed training technique is Data Parallelism. It is based upon a divide and conquer concept. Let’s look at an example below to understand the workflow.
If we have a dataset of 1000 images and the training is run on a single GPU, then all of the 1000 images are fed batch-by-batch to the model on the GPU. But if we want to speed up the training by distributing the load to 10 GPUs, it requires multiple copies of the model, each running on a single GPU. As such, each copy of the model receives a shard (part) of the dataset, in this case 100 images (1000/10). First, the copy trains itself on its own share of data and sends its network parameters to a centralized parameter server. The parameter server receives these weights from each copy, averages them and sends the averaged weights back to each copy/GPU. This operation is called all reduce. Thus in this case the training time is reduced by a factor of 10 in ideal cases. In practice though, the training time is reduced by what is called the scale factor of training. The scale factor depends on a number of things like the network bandwidth of the connected nodes of the cluster (higher the bandwidth the faster the communication), the size and architecture of the network etc. The larger the network the more the number of parameters and more the number of values that has to be sent over the network.
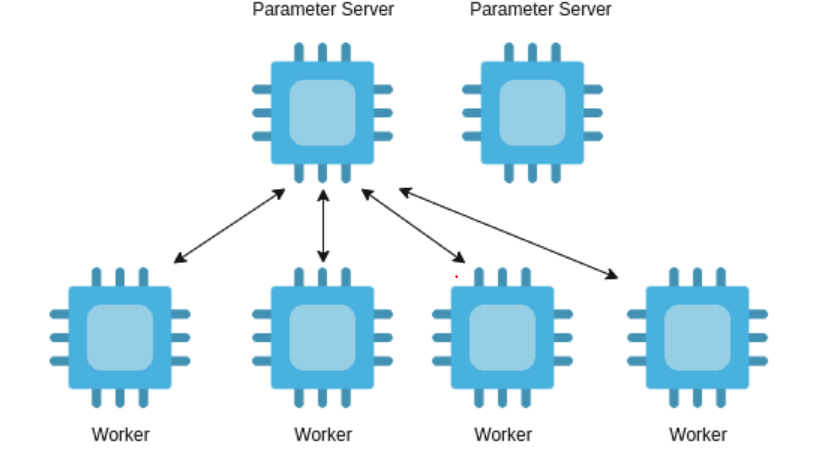
Horovod is the framework implementation of Data Parallelism. Horovod is an open-source library that enables multi-node training out-of-box and is included in the NVIDIA AI Enterprise container images like Tensorflow and Pytorch. Horovod is a distributed deep learning framework and is framework agnostic, therefore it has support for all deep learning frameworks like Tensorflow, Pytorch and MXnet etc and removes the need to learn framework specific APIs for deep learning (For example nn.distributed in Pytorch). Horovod is based on the Message Passing Interface(MPI) model used in High Performance Computing (HPC). It uses MPI and NVIDIA Collective communications Library (NCCL) underneath to run distributed GPU workloads.
What is Message Passing Interface (MPI)?
The Message Passing Interface (MPI) is an open source API for communicating data between processes (local and remote) via messages. MPI is commonly used in High Performance Computing to build applications that can scale multiple nodes. The two major functions of the MPI API are mpi_send and mpi_recv are used for Inter process communication. Below are some of the concepts used in MPI.
Say you have launched an MPI Job on a GPU cluster with 8 GPUs on 4 nodes. Then:
World size is the total number of processes, in this case one per GPU, so 8.
Rank of a process is the index of the process i.e ProcessID in MPI Job.
Allreduce is an operation that aggregates data among multiple processes and distributes results back to them. This is used for training the neural network model in a distributed fashion as explained in the model parallelism section.
What is the NVIDIA Collective Communications Library (NCCL)?
NVIDIA Collective communications Library(NCCL) is a library providing primitives for inter-GPU communication. NCCL is hardware topology aware i.e NCCL constructs the map of GPU PCIe tree of the server to help in GPU to GPU communication.
Hardware Used For Distributed Training
In a typical high performance computing environment, the GPUs in the servers are attached to a PCIe bus and Intranode GPU peer to peer communication happens over the bus. The cluster also requires that there be a high bandwidth interconnection between the nodes of the cluster so that MPI and NCCL can communicate the weights faster between two processes on two separate machines.
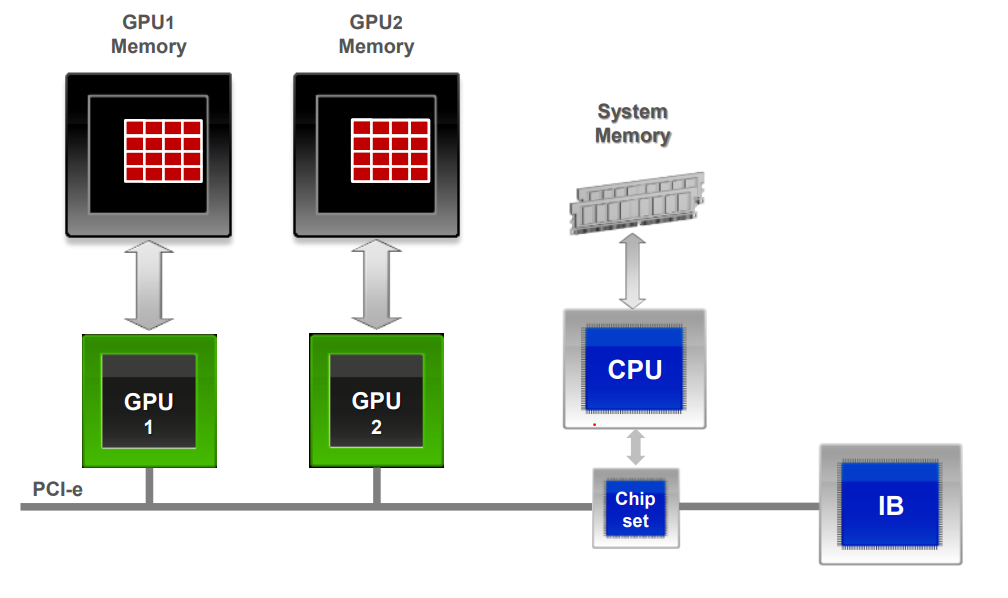
If we use traditional networking hardware with common networking protocol paradigms like TCP over socket then the internode communication becomes a bottleneck and can affect the speed of training the network. NVIDIA Mellanox CX cards solve this by using high bandwidth (100 Gbps to 200 Gbps) interconnect over Infiniband or Ethernet and Remote Direct Memory Access (RDMA) to solve this bottleneck.
GPUDirect RDMA
Traditional network communication protocols like TCP are not suitable for high performance computing. When the GPU peer to peer communication happens over TCP then an additional bounce buffer needs to be maintained on the system memory and the messages received over the network by the Network Interface Card (NIC) need to be first copied over to this bounce buffer by the CPU and then to GPU memory. This creates additional latency. Also during the copy calls to the bounce buffer, the control needs to be handed over to the OS kernel causing additional latency. With GPUDirect RDMA the contents to messages are copied directly from the NIC to the GPU memory without additional bounce buffer and by passing the OS kernel. This leads to a high bandwidth and low latency communication between processes on different nodes.
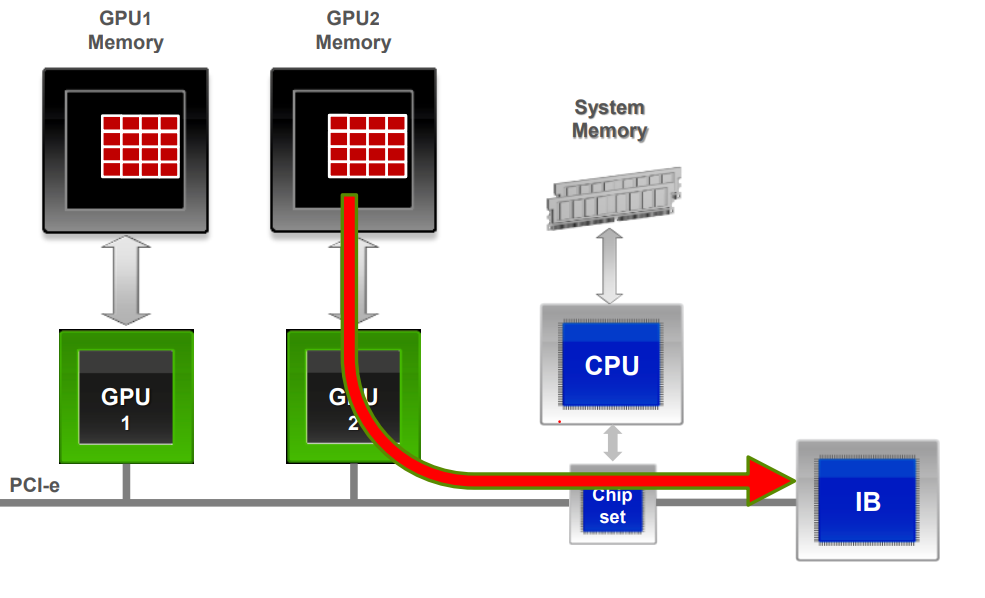
Now that we have understood the inner workings of distributed training on GPUs and all the libraries involved with it. Let’s focus a bit on implementation details. As noted before Horovod is framework agnostic i.e it can be used to write distributed applications on top of any deep learning frameworks like Tensorflow and Pytorch.
As part of this lab, you will use Tensorflow and Keras, a sample Jupyter Notebook will be provided to you. Highlighted below are the steps to transform your single node GPU training workload to Multi Node. More details can be found on the horovod website here:
Add hvd.init() at the beginning of your training script.
Pin each GPU to a single process. With the typical setup of one GPU per process, set this to local rank. The first process on the server will be allocated the first GPU, the second process will be allocated the second GPU, and so forth.
gpus = tf.config.experimental.list_physical_devices('GPU') for gpu in gpus: tf.config.experimental.set_memory_growth(gpu, True) if gpus: tf.config.experimental.set_visible_devices(gpus[hvd.local_rank()],'GPU')
When the script is run, each process (in the distributed workflow) will know its rank from
hvd.local_rank()Scale the learning rate by the number of workers. Effective batch size in synchronous distributed training is scaled by the number of workers. An increase in learning rate compensates for the increased batch size.
Shard the dataset i.e give each process i.e rank a piece of the dataset to work on this can be done using the shard function in Tensorflow.
local_dataset = dataset.shard(hvd.size(), hvd.rank())
The code above roughly translates to split the dataset into
hvd.local_rank()i.e number of GPU parts and give this worker one part to work on.Wrap the optimizer in
hvd.DistributedOptimizer. The distributed optimizer delegates gradient computation to the original optimizer, averages gradients using allreduce we discussed previously, and then applies those averaged gradients.Add hvd.callbacks.BroadcastGlobalVariablesCallback(0) to broadcast initial variable states from rank 0 to all other processes. This is necessary to ensure consistent initialization of all workers when training is started with random weights or restored from a checkpoint.
Modify your code to save checkpoints only on worker 0 to prevent other workers from corrupting them. Accomplish this by guarding model checkpointing code with
hvd.rank() != 0. Only the master process i.e rank 0 process will save the model this way.