Deepstream Overview
NVIDIA’s DeepStream SDK delivers a complete streaming analytics toolkit for AI-based multi-sensor processing for video, image, and audio understanding. DeepStream is an integral part of NVIDIA Metropolis, the platform for building end-to-end services and solutions that transform pixels and sensor data into actionable insights. DeepStream SDK features hardware-accelerated building blocks, called plugins, that bring deep neural networks and other complex processing tasks into a processing pipeline. The DeepStream SDK allows you to focus on building optimized Vision AI applications without having to design complete solutions from scratch.
The DeepStream SDK uses AI to perceive pixels and generate metadata while offering integration from the edge-to-the-cloud. The DeepStream SDK can be used to build applications across various use cases including retail analytics, patient monitoring in healthcare facilities, parking management, optical inspection, managing logistics and operations etc.
The deep learning and computer vision models that you’ve trained can be deployed on edge devices, such as a Jetson Xavier or Jetson Nano, a discrete GPU, or in the cloud with NVIDIA GPUs. TAO Toolkit has been designed to integrate with DeepStream SDK, so models trained with TAO Toolkit will work out of the box with DeepStream SDK.
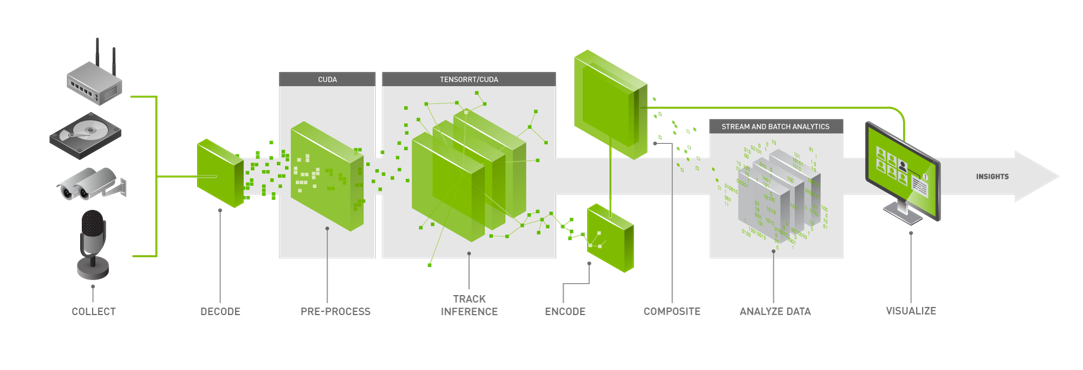
The above figure shows the Deepstream workflow. It is based on a source, infer and sink model. The streaming data is collected from various sources, the streams are then decoded and preprocessed before sending it to and inference engine and the inference results are post processed and run analytics on and are finally sent to various sinks (RTSP, UDP and files etc) The Deepstream SDK has Python and C++ APIs for each step of the process above that can be used to create applications.
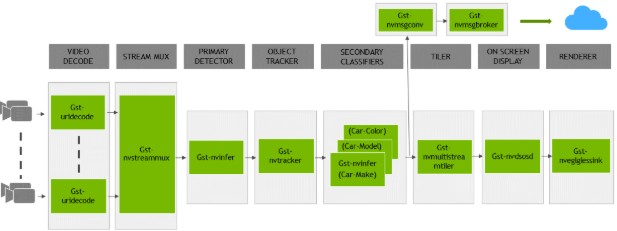
DeepStream SDK ships with an end-to-end reference application which is fully configurable. Users can configure input sources, inference models, and output sinks. The app requires a primary object detection model, followed by an optional secondary classification model. The reference application is installed as deepstream-app. The graphic below shows the architecture of the reference application.
This section will describe how to deploy your trained model to DeepStream SDK.
To deploy a model trained by TAO Toolkit to DeepStream we have two options:
Option 1: Integrate the encrypted tlt (
.etlt) model directly in the DeepStream app. The model file is generated by export.Option 2: Generate a device specific optimized TensorRT engine using
tao-converter. The generated TensorRT engine file can also be ingested by DeepStream.
We have generated both these files as the last step of the TAO workflow.
The deepstream reference app takes in one configuration file (deepstream_app_source1_detection_models.txt) that covers all parts of the workflow above. We will be using this configuration file to deploy our reference YOLOv4 application.
Broadly speaking the application config below can be organized into four parts the sources (can be a RTSP feed from IP cameras or a video file etc), the inference engine block which takes and an inference config config_infer_primary_yolov4_dgpu.txt (explained later), the post processing (on screen display (osd)) blocks and sinks that can be used to read the output as (video files or RTSP feeds etc). For our launchpad application we will be taking input from a stock video (sample_ride_bike.mov) which is part of the deepstream container and we will be outputting another video file out.mp4 which will have the objects detected from the input file in a frame by frame fashion.
All the configuration files of the reference apps are available here.
[application]
enable-perf-measurement=1
perf-measurement-interval-sec=1
[tiled-display]
enable=0
rows=1
columns=1
width=1280
height=720
gpu-id=0
[source0]
enable=1
#Type - 1=CameraV4L2 2=URI 3=MultiURI
type=3
num-sources=1
uri=file://../../streams/sample_ride_bike.mov
gpu-id=0
[streammux]
gpu-id=0
batch-size=1
batched-push-timeout=40000
## Set muxer output width and height
width=1920
height=1080
[sink0]
enable=0
#Type - 1=FakeSink 2=EglSink 3=File
type=2
sync=1
source-id=0
gpu-id=0
[osd]
enable=1
gpu-id=0
border-width=3
text-size=15
text-color=1;1;1;1;
text-bg-color=0.3;0.3;0.3;1
font=Arial
[primary-gie]
enable=1
gpu-id=0
# Modify as necessary
batch-size=1
#Required by the app for OSD, not a plugin property
bbox-border-color0=1;0;0;1
bbox-border-color1=0;1;1;1
bbox-border-color2=0;0;1;1
bbox-border-color3=0;1;0;1
gie-unique-id=1
# Replace the infer primary config file when you need to
# use other detection models
config-file=config_infer_primary_yolov4_dgpu.txt
[sink1]
enable=0
type=3
#1=mp4 2=mkv
container=1
#1=h264 2=h265 3=mpeg4
codec=1
#encoder type 0=Hardware 1=Software
#enc-type=0
sync=0
enc-type=1
bitrate=2000000
#H264 Profile - 0=Baseline 2=Main 4=High
#H265 Profile - 0=Main 1=Main10
profile=0
output-file=out.mp4
source-id=0
[sink2]
enable=1
#Type - 1=FakeSink 2=EglSink 3=File 4=RTSPStreaming 5=Overlay
type=4
#1=h264 2=h265
codec=1
#encoder type 0=Hardware 1=Software
enc-type=1
sync=0
bitrate=4000000
#H264 Profile - 0=Baseline 2=Main 4=High
#H265 Profile - 0=Main 1=Main10
profile=0
# set below properties in case of RTSPStreaming
rtsp-port=8554
udp-port=5400
[tracker]
enable=0
# For NvDCF and DeepSORT tracker, tracker-width and tracker-height must be a multiple of 32, respectively
tracker-width=640
tracker-height=384
ll-lib-file=/opt/nvidia/deepstream/deepstream/lib/libnvds_nvmultiobjecttracker.soll-config-file required to set different tracker types
ll-config-file=../deepstream-app/config_tracker_IOU.yml
gpu-id=0
enable-batch-process=1
enable-past-frame=1
display-tracking-id=1
[tests]
file-loop=1
The next file we have to take a look at is the inference config file that is part [primary-gie] block above i.e config_infer_primary_yolov4_dgpu.txt . This file contains all the information about the model configuration needed to run the inference (location of the TAO model etc).
In particular, to create the Inference config file, we will use four files that are part of the ~/tao-launchpad/workspace/results/export directory we generated as part of the last step i.e the export step of the TAO workflow.
labels.txt: This has the line by line entries of the classes we trained on (Bus and Bicycle). This file is used as the input to the main Deepstream config file.nvinfer_config.txt: The DeepStream related configuration generated as part of the export. Note that the config file is NOT a complete configuration file and requires the user to update the sample config files in DeepStream with the parameters generated.model.etlt: This is the actual model file in encrypted TAO format as discussed in the TAO workflow in Step #1.model.engine: This is the TensorRT engine file optimized for deployment as discussed in the TAO workflow in Step #1.
The contents of config file config_infer_primary_yolov4_dgpu.txt which is part of the in the main deepstream config file above are shown below. Here we specify the model engine and the TAO encoded model file (etlt file) that we exported as part of the TAO training in step #1 and the labels.txt of the model we just trained (contains bicycle and bus). The [property] block that we see below is taken from the nvinfer_config.txt we generated in the TAO workflow. All the configuration files of the reference apps are available here.
config_infer_primary_yolov4_dgpu.txt
[property]
gpu-id=0
net-scale-factor=1.0
offsets=103.939;116.779;123.68
model-color-format=1
labelfile-path=/results/export/labels.txt
model-engine-file=/results/export/trt.engine
tlt-encoded-model=/results/export/yolov4_resnet18_epoch_010.etlt
tlt-model-key=nvidia_tlt
infer-dims=3;1024;1024
maintain-aspect-ratio=0
uff-input-order=0
uff-input-blob-name=Input
batch-size=1
## 0=FP32, 1=INT8, 2=FP16 mode
network-mode=2
num-detected-classes=2
interval=0
output-tensor-meta=0
gie-unique-id=1
is-classifier=0
network-type=0
cluster-mode=3
output-blob-names=BatchedNMS
parse-bbox-func-name=NvDsInferParseCustomBatchedNMSTLT
custom-lib-path=/opt/nvidia/deepstream/deepstream/lib/libnvds_infercustomparser.so
[class-attrs-all]
pre-cluster-threshold=0.3
roi-top-offset=0
roi-bottom-offset=0
detected-min-w=0
detected-min-h=0
detected-max-w=0
detected-max-h=0
[class-attrs-1]
nms-iou-threshold=0.9
yolov4_labels.txt
bicycle
bus