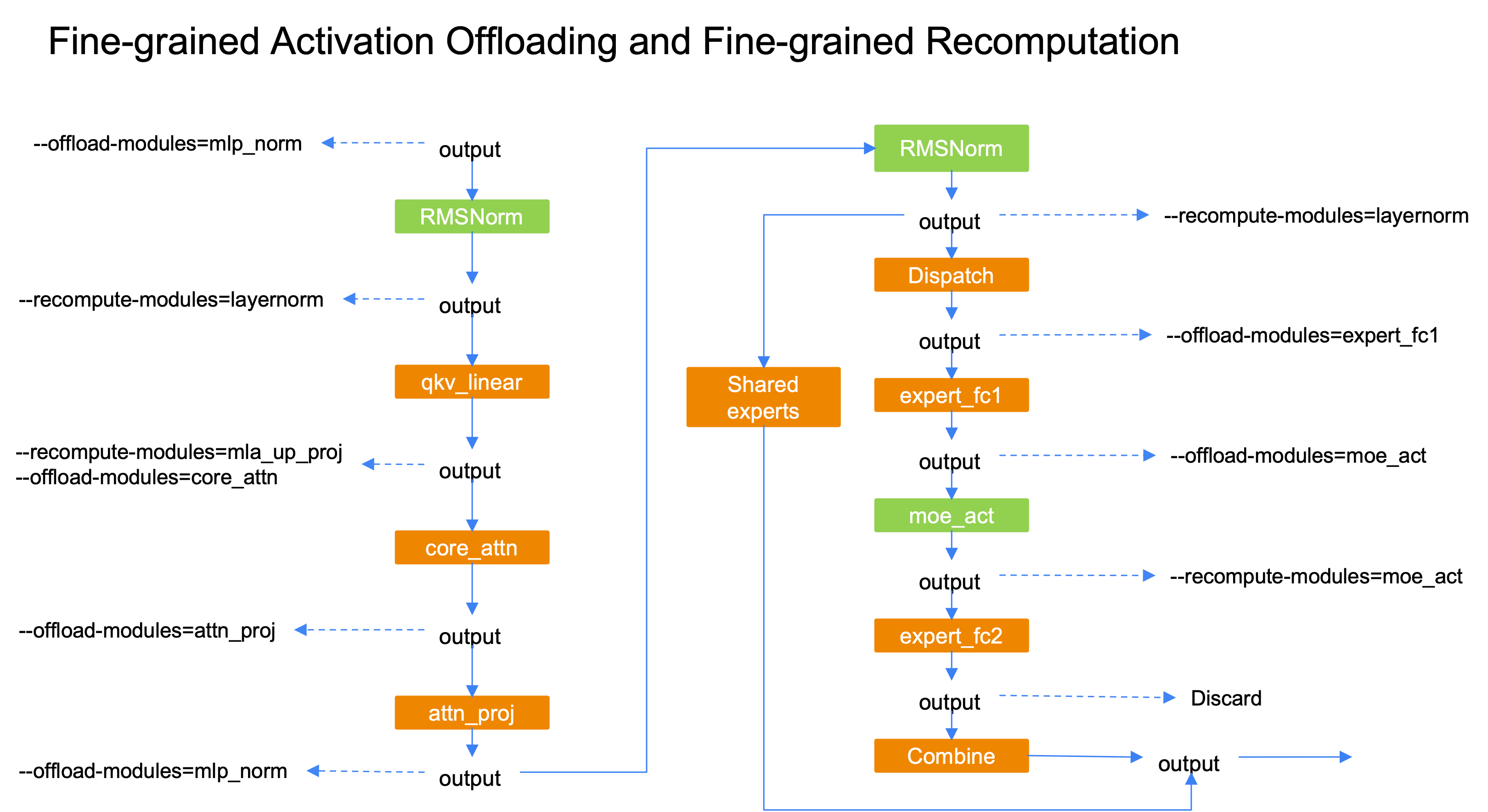
Fine-Grained Activation Offloading#
Contributed in collaboration with RedNote.
Memory is often the limiting factor for very large sparse MoE models such as DeepSeek-V3 and Qwen3-235B. Fine-grained recomputation lowers activation memory at the cost of extra compute. Offloading can use host-device bandwidth so that reload overlaps compute and keeps overhead small in many setups. Fine-grained activation offloading moves activations at module granularity so you can tune how much activation memory leaves the device and adjust training throughput.
Supported offloading modules are "attn_norm", "core_attn", "attn_proj", "mlp_norm", "expert_fc1", and "moe_act". They can be combined with fine-grained recomputation to free almost all activations for a transformer layer on the device.
Features#
Pipeline parallelism: PP=1, PP, and interleaved PP
Compatible with fine-grained recomputation
FP8 training
MTP
Mixed dense and MoE layers
A2A overlap
CUDA graphs
Note: A CUDA graph capture cannot include the offloading modules (temporary limitation).
Usage#
# Enable fine-grained activation offloading
--fine-grained-activation-offloading
# Modules whose inputs are offloaded (refer to your training script for list or delimiter syntax).
# Choices: "attn_norm", "core_attn", "attn_proj", "mlp_norm", "expert_fc1", "moe_act".
--offload-modules expert_fc1
Max inflight offloads#
# Optional: cap inflight D2H offloads per offload group to N (omit or None in most setups).
# Required as a non-None non-negative integer when fine-grained activation offloading is used with
# local full-iteration CUDA graphs (full_iteration in cuda_graph_scope); see prose below.
--fine-grained-offloading-max-inflight-offloads <N>
TransformerConfig.fine_grained_offloading_max_inflight_offloads caps, per offload group (for example moe_act, qkv_linear), how many D2H copies may be in flight before a main-stream wait_event. 0 waits after each offload; larger values allow more overlap; None skips these joins.
With full-iteration CUDA graphs (local graph impl, full_iteration in cuda_graph_scope) and fine-grained activation offloading enabled, set it to a non-None integer: that path does not rely on record_stream, so explicit joins are required.
Compatible With Fine-Grained Recomputation#
For low-overhead modules such as LayerNorm or
moe_act, use recomputation to save activation memory.For other modules, use offloading to save activation memory.
Overlap offload and reload with compute when possible.