NMC Autonomous Job Recovery Tutorials#
This section provides tutorials on using the NVIDIA Mission Control Autonomous Job Recovery (AJR) for testing purposes.
Quick Start#
A user can quickly get started with AJR and experience its capabilities by using a simple Slurm batch script that emulates writing some sample failure logs to a file to observe the full end-to-end behavior of the AJR.
#!/bin/bash
#SBATCH -t 00:05:00
#SBATCH --comment='{"APS": {"auto_resume_mode": "requeue", "max_requeue_times": 1}}'
DATETIME=`date +'date_%y-%m-%d_time_%H-%M-%S'`
echo 'Autonomous Recovery Engine light-weight fault simulation test (auto resume mode: requeue)'
# This srun command sets the output file for the job step. In the job step, it simply sleep for 30s, then print a
# log line that will be recognized by the AJR as segment fault, then sleep for another 60s before exiting with 1.
srun --output="$(pwd)/%x_%j_$DATETIME.log" bash -c \
"echo 'Start time: $DATETIME' && echo 'Sleeping 30 seconds' && \
sleep 30 && echo 'Rank0: (1) segmentation fault: artificial segfault' && \
echo 'Sleep another 60 seconds' && \
sleep 60 && exit 1"
- What this script does:
In the comment section of the batch script, we set the auto resume mode to “requeue” and the user level directive to override the maximum number of requeues to be 1. This means that if the job fails, it will be automatically requeued once. If more requeue times are needed, the value of max_requeue_times can be increased accordingly.
The bash script will run for up to 5 minutes before timeout.
In the job step, it creates a log file with compliant output file name format, which includes the job name, job ID, and the current date and time. The script then sleeps for 30 seconds, prints a log line that simulates a segmentation fault, sleeps for another 60 seconds, and finally exits with a non-zero exit code (1).
Step-by-step instructions#
Copy the content of the bash script above and save it into a file, e.g., are_test.sh.
Submit one job to Slurm with the sbatch script, note that you have to specify at least the job name (with -J option) and the partition name (with -p option) since they are not encoded in the script.
sbatch -J are_test -p <your_partition_name> are_test.sh
Monitor the job status using the squeue command.
squeue --me
The log file of the Slurm job step will be created in the same directory where the sbatch script is located after the job starts execution. Since we encode the batch script execution time in the srun output file name, each job attempt will have its own log file. In this case, there will be 2 files created after the whole test is finished.
As the jobs run, if the AJR is deployed and configured correctly, the output of the jobs will be recognized as CRASH anomalies. When the 1st job attempt is finished, there will be a short period of time where the queue will be empty, then the 2nd job attempt will be created and put in user held state briefly, then it gets released and starts running.
Example output of the squeue command as the job management happens:
squeue --me
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
2633 <partition_name> are_test <user-name> PD 0:00 1 (job requeued in held state)
squeue --me
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
2633 <partition_name> are_test <user-name> R 0:10 1 <example-node-name>
Verification through Cockpit After the job is submitted, the user can go to the Cockpit web interface to verify the job status and find the details about the job attempts. When the job is requeued, the job ID will remain the same but the job attempt index will be incremented and result in two different job attempts. Please refer to the Cockpit documentation for more details on how to navigate it.
[Optional] Verification through Slack notification If the user has configured the Slack notification, they will receive messages in the target Slack channel about:
The job being requeued due to the crash.
The anomaly attribution result.
The job being updated and released to resume execution.
Emulated Fault Injector#
This section provides comprehensive instructions on how to use the emulated fault injector for testing purposes. The fault injector is designed to emulate various faults in training jobs to help identify and resolve issues effectively.
Prerequisites#
A fully functional Slurm cluster with GPUs available.
All AJR components must be deployed and in a running state in both Slurm and K8s.
Access to Fault-Injectors and associated Git submodules: Fault-Injectors.
Container images available - configure as needed for your cluster environment.
Methodology#
The fault injector is a modified codebase of the Megatron core, designed to raise different types of faults (such as crash, straggler, hang) after a specified time. It is intended for ad-hoc runs done by humans.
To run the job, use the command:
./nmcare-tests.t -debug -v
The debug options provide a more verbose output to understand the tests better.
Once faults are injected into the training process, the AJR infrastructure identifies the fault and resumes the workflow with any necessary corrective actions.
Faults Demonstrated#
Fault Type (launch_run param -m) |
Fault Description |
|---|---|
No fault (good) |
No fault, job successfully completes. |
User-buffer hang (hang_ub) |
User-buffers related hang which stalls the NCCL kernels such as all_reduce. Not all jobs use UB. I’m not sure if there is a watchdog for this so the job might not exit. |
Segfault crash (crash_segfault) |
Segmentation fault in the middle of the run. Job will crash. |
GPU throughput straggler |
One or more GPUs lagging in throughput compared to SoL. Job will not exit on its own. |
NCCL all-reduce hang |
After some # of allreduce calls, NCCL will have a specific rank spin-wait. After some amount of time, it’s likely the Pytorch NCCL watchdog will catch this and kill the job. |
NCCL push-recv hang |
Like above, except that it will hang on a point-to-point communication. This is not used in jobs without pipeline parallelism, so it’s not always going to show up. I’m not sure that the watchdog will show up here, job might not crash. |
Job hangs after straggler??? |
This causes a straggler in a kernel, and after that happens, a UB hang is induced (the one indicated above). |
Running the Tests#
Checkout the main branch of the fault-injector codebase and run:
git submodule update -init
This will pull in the changes to the Megatron-core changes in the git submodule.
Review and modify the config file for your cluster under the appropriate path in automation/config/ as needed.
Run the tests from the automation sub-directory using:
nmcare-tests.t
Quickstart for AJR/NVRx 0.4.1 Checkpointing Integration#
NVIDIA resilience extension (NVRx) provides extra resilience features. Techniques from it can work hand-in-hand with AJR to further enhance the training resilience and recovery capabilities. More instructions on how to integrate NVRx in your training jobs can be found in NVRx documentation.
This example demonstrates how to make jobs with NVRx checkpointing (v0.4.1) with AJR for enhanced resilience.
Prerequisites#
A fully functional Slurm cluster with GPUs available.
Access to a training workload with checkpointing enabled.
Container image configured for your training environment.
Optional#
If the Lustre file system is available, access to the lfs utility to stride container sqsh file to the max OSTs.
Configuring the Job#
Add the AJR spec to your batch script to enable AJR to monitor and manage the job:
#SBATCH --comment='{"APS": {"auto_resume_mode": "requeue"}}'
In current release, AJR relies on certain log patterns to identify job checkpointing events. By default the patterns below are recognized:
save-checkpoint
SAVE_CHECKPOINT: iteration:.*, ckpt saving takes .* seconds
Saved checkpoint to
If the job uses megatron-lm framework, no additional configuration is needed since the default patterns already cover them.
If the job implements its own training loop with NVRx checkpointing mechanism, in order for AJR to properly recognize the checkpoint save event, there are a few options that the user can take:
Ensure that the log lines containing one of the above patterns are printed when a checkpoint is saved
Integrate with the AJR training telemetry client library to report checkpoint events. Please see AJR Training Telemetry Client Library Integration section for more details.
Contact the admin of the cluster to add the additional pattern.
Running the Job#
Submit the job to Slurm and let it run for some time to save at least one checkpoint. The user can then use the AJR Cockpit page to monitor the job and checkpoint status.
If the job fails, AJR will automatically restart it, continuing up to the maximum number of requeues allowed or until manually cancelled with scancel.
Monitoring and Performance#
The Cockpit performance info section logs the exact times when each checkpoint was saved. For example, this link shows the first job submitted by a user, 1778(0) – 1778 is the Slurm job ID and 0 shows this is the first job. Checkpoints saved with native Megatron checkpointing mechanism or NVRx checkpointing mechanism will be recognized and shown here.
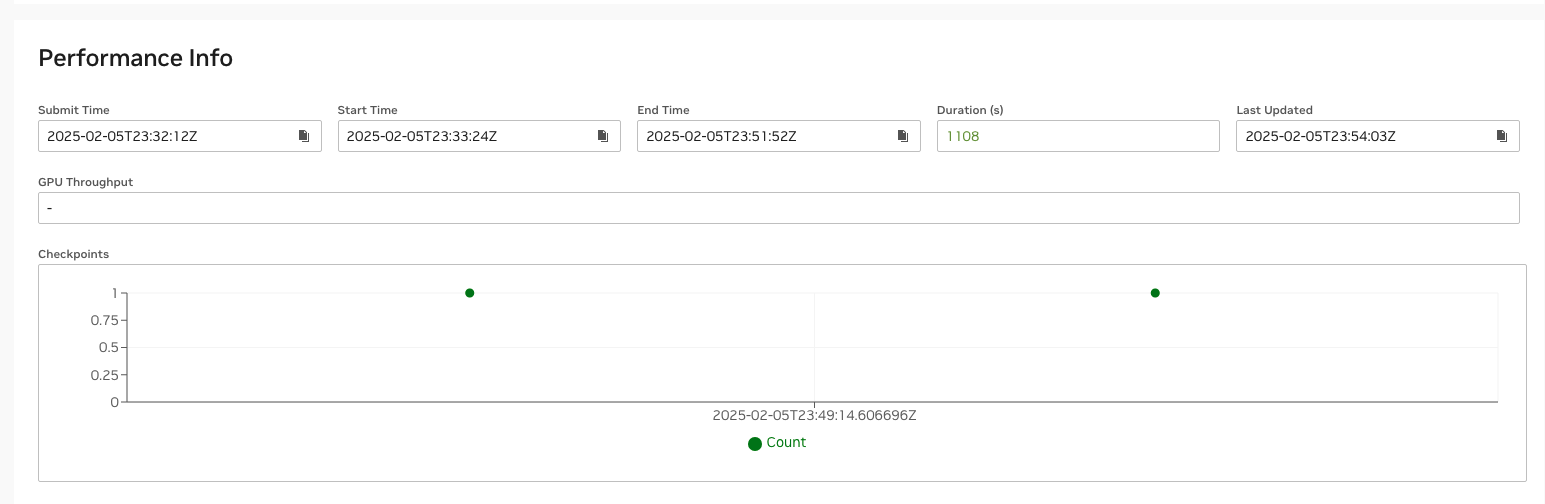
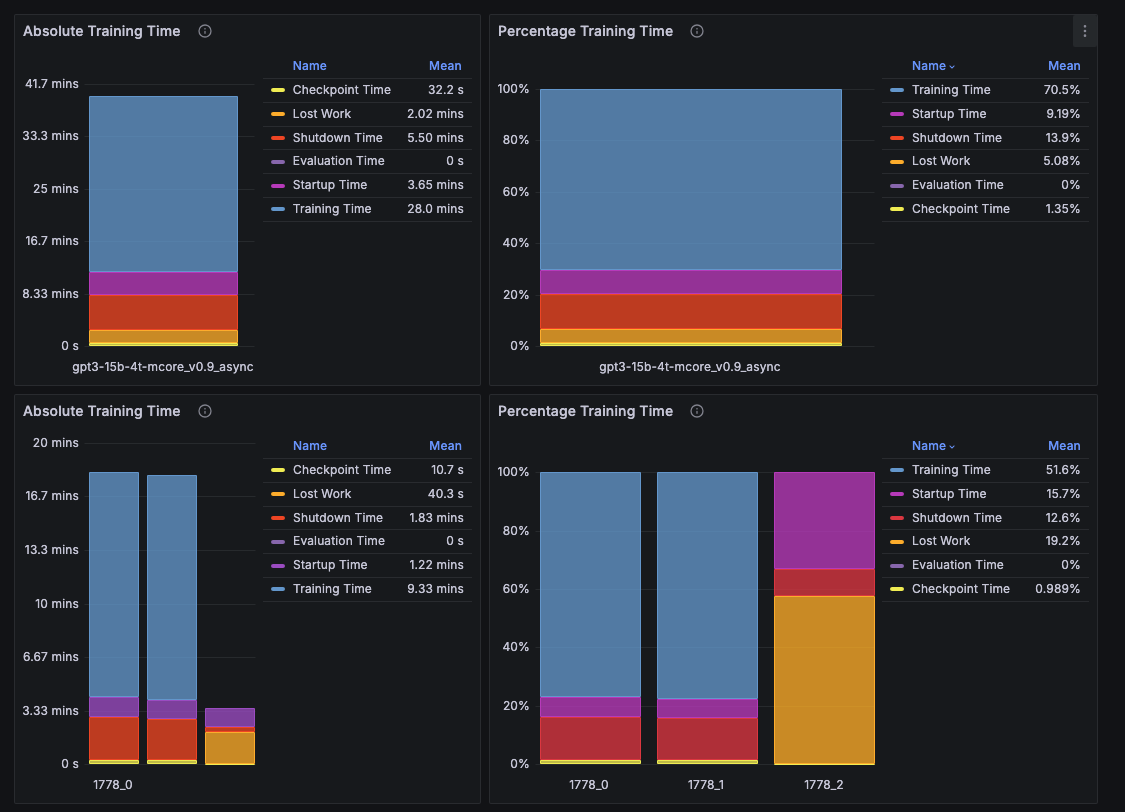
The Training efficiency KPI dashboard displays the downtime for each job and the aggregated downtime across all jobs. For example, the training time efficiency for job 1778, which automatically restarted twice, is shown to be 70.5%. The low efficiency is due to the second restart (1778_2), where the job was manually canceled before reaching the first checkpoint save to illustrate the impact of a failure restart. As expected, the performance data for this restart shows no checkpoint save. AJR uses the first checkpoint save as the criterion for determining restart success or failure. This threshold is configurable per system deployment.
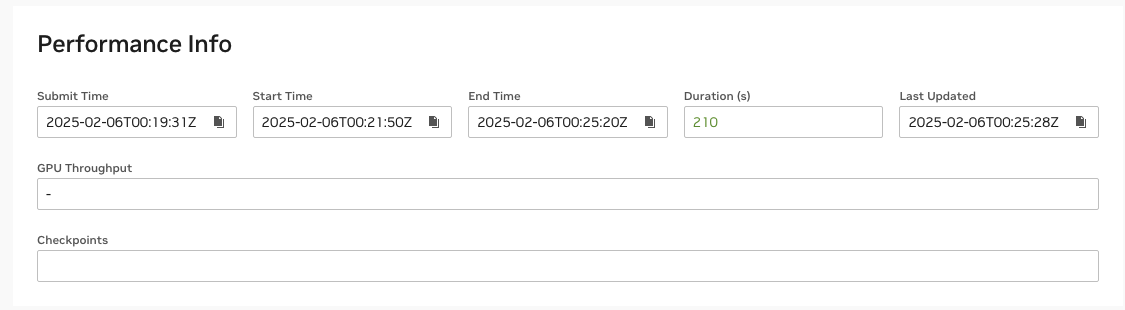
For customers who are using the Lustre file system to stage container squshfs images, the start time also includes the container initialization and loading time, which can be significant at large scale.
Creating a Container Sqsh Image#
To create a container sqsh image that stride maximally for container loading time optimization:
# Creating a properly stripped sqsh image file directory /lustre/fsw...
mkdir high_stride_images
lfs setstripe -c -1 highly_stride_images
cp <your sqsh file> ./highly_stride_images
lfs getstripe highly_stride_images/adlr+megatron-lm+pytorch+24.08-py3-nemotron5.sqsh
# You should see 168 stripes