Running Generative AI applications using Metropolis Microservices on Jetson
Overview
Generative AI is enabling unprecedented use cases with computer vision both by redefining traditionally addressed problems such as object detection (eg: through open vocabulary support), and through new use cases such as support for search,and with multi modality support for video/image to text. The NVIDIA Jetson Generative AI Lab is a great place to find models, repos and tutorials to explore generative AI support on Jetson.
The Metropolis Microservices on Jetson software stack provides several platform level features to facilitate testing, deployment and maturation of generative AI applications. This section provides a breakdown of these features and illustrates their integration into Python applications using the NanoOWL example for open vocabulary object detection.
Video Ingestion
It is typical for generative AI video applications to be developed accepting file input for video source. In production, these applications need to interact with video streams from the real world, also including from cameras and network streams. The Video Storage Toolkit microservice provides an out of the box mechanism to ingest video, including camera discovery, camera reconnection, monitoring and camera events notification. In the process, VST provides a proxy RTSP link for camera video sources that applications can query for based on VST APIs.
VST supports the ONVIF protocol for discovering cameras. These cameras could be connected directly to the Jetson system through a dedicated power over Ethernet (PoE) switch; or to the network that the device is connected to. Another option is for users to manually add devices based on its IP address.
Given that users can add/remove cameras dynamically, applications need to be notified of camera changes so that they can incorporate addition or deletion of the new streams. Instead of applications having to poll VST APIs periodically to register the changes, camera event information is sent over the Redis message bus, that generative AI applications can subscribe to. Camera event information contains name, resolution, RTSP URL endpoint information that can be used by the application to start processing (or omit) video stands from the camera.
External API access through Ingress, Firewall and IoTGateway
Generative AI applications using REST APIs for configuration and output of results can leverage the combination of Ingress, Firewall and IoTGateway modules offered as part of platform services to enable secure and remote access of the APIs. The NanoOWL example for instance uses REST APIs to enable user configuration of prompts, which is presented externally using these modules.
With APIs at the core of Metropolis Microservices, Ingress provides a centralized means of accessing them by providing a common endpoint with designated routes to each microservice. For example, the VST microservice is typically accessed at:
http://<JETSON-DEVICE-IP>:30080/vst/api/
Where 30080 is the network port where Ingress is running, and vst is the route registered by the VST microservice through the Ingress configuration file.
Developers can similarly register their own generative AI application microservice at system deployment time by providing the ‘route’ along with the internal port in which their application is serving its APIs. Upon receiving incoming requests for that path, the ingress microservice automatically forwards the request to the right microservice.
A standard pattern used is a securing APIs is to to leverage Ingress in combination with the Firewall platform service, so that the only the ingress port is accessible from externally, and all the internal microservices (such as Redis) and internal ports being served by the various microservices are encapsulated from the outside world.
Finally, the IOTGateway enables generative AI and other microservice APIs to be accessible remotely by having requests from clients routed through the Reference Cloud software (Reference Cloud for Jetson devices running Metropolis Microservices) offered as part of Metropolis Microservices. Rich clients such as mobile app can access this functionality from anywhere, as is the norm with product grade systems. The cloud ensures that this interaction is secure by providing user authentication, authorization as functionality out of the box.
Monitoring
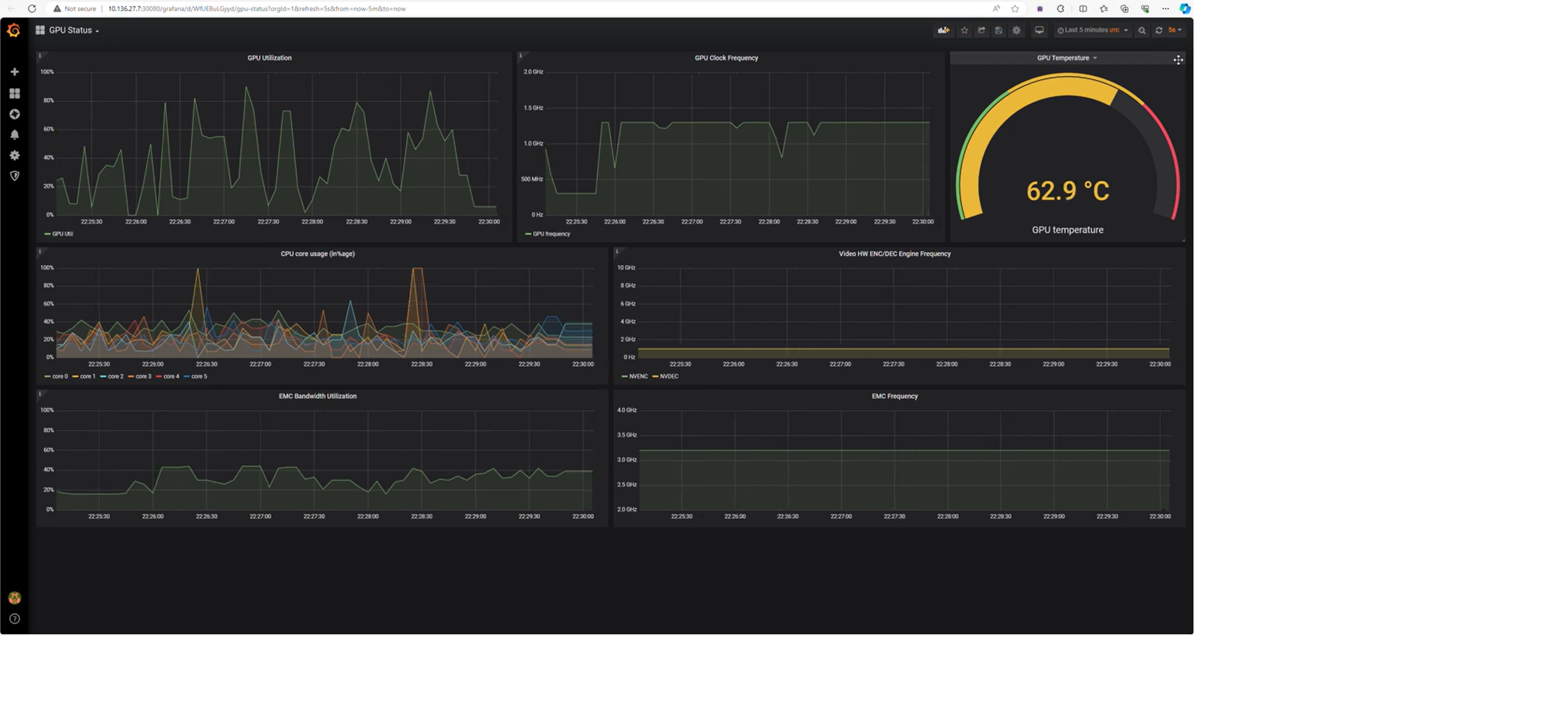
Metropolis Microservices provides monitoring as a ready to use platform service to enable developers to track system utilization and performance KPIs. Given generative AI applications push the system capabilities both in terms of GPU utilization and memory availability, the Prometheus based monitoring dashboards provide a ready means to observe utilization of these metrics as applications are run. These metrics update live presenting users to get a real time view of the utilization as the application executes and starts processing different input.
Secure Storage
Generative AI applications use and generate various data, including model, inference output etc. The Metropolis Microservices on Jetson stack offers encryption of storage used by microservices that can be leveraged by Generative AI applications so that their data (model, weights, input, output) is safe at rest. The storage platform service describes how to enable encryption and also how microservices can request storage quotas from attached external storage such as hard disk.
App integration into Metropolis Microservices based systems
To facilitate integration of Generative AI applications (typically written in Python) into Metropolis Microservices based systems, we highlight a collection of Python modules that developers can leverage. The NanoOWL example released on NVIDIA GitHub (link TBD) illustrates use of these modules to achieve this integration.
The list of these Python modules include:
jetson-containers : provides containers, models, vectorDB, and other building blocks for generative AI applications on Jetson
jetson-utils : NVIDIA provided python module for hardware accelerated image and multimedia operations relating supporting RTSP stream input/output, video decode, and efficient video overlay creation
moj-utils: New NVIDIA provided python module for integration with rest of Metropolis Microservice platform.
This module can be installed from the TBD GitHub repo:
pip install git+https://github.com/NVIDIA-AI-IOT/mmj_utils
The module provides the functionalities for integration into the Metropolis Microservices into python applications, including:
Support for Video Storage Toolkit (VST): VST APIs enable among other functionality, stream discovery and introspection. The the vst submodule provides a class abstraction to invoke the relevant APIs to discover, add, remove streams among other operations
Metadata creation: Metropolis Microservices use a the Metropolis schema as the standardized spec to capture model output; the schema_gen submodule provides a ready JSON schema generator based on object detection output from models like NanoOWL.
Overlay Generation: the DetectionOverlayCUDA submodule enables hardware accelerated bounding box and text overlay generation to facilitate visualization of model output in live video
NanoOwl example
The mmj_genai project available on NVIDIA GitHub showcases integration of a Jetson Generative AI application into Metropolis Microservices based on NanoOwl example. It demonstrates integration of Ingress, VST, monitoring and Redis services from the platform into the application.
Based on the open world detection capabilities, users are able to issue queries to the NanoOwl software whose APIs are exposed through the ingress controller. A typical prompt to set the detection class is shown below:
curl “http://localhost:30080/genai/prompt?objects=a%20person,a%20hardhat,a%20magenta%20box&thresholds=0.45,0,12,0.1”
Where 30080 represents the port where the ingress controller is executing. Person, hard hat, and magenta box are the prompted objects.
This will render an RTSP output with image overlay such as shown below:

System utilization metrics can be retrieved using the monitoring dashboard. This includes utilization of various metrics that are key to model throughput such as: GPU, CPU utilization and memory bandwidth.