NeMo Framework Now Supports Google Gemma 3n: Efficient Multimodal Fine-Tuning Made Simple#
Introduction#
Gemma 3n is a generative AI model that takes inputs from a variety of modalities, including images and audio, and is optimized for efficient resource usage and fast inference on everyday devices. It introduces innovations such as Per-Layer Embedding parameter caching and the MatFormer architecture, which help reduce compute and memory demands, making it ideal for lightweight deployments. Some key highlights:
Optimized architecture featuring MatFormer’s nested transformers, Per-Layer Embeddings (PLE), and KV cache sharing. These enable sub-model extraction, reduced GPU memory usage, and faster prefill speeds. For more details, check out documentation.
Multimodal capabilities with integrated image and audio encoders alongside the language model, enabling diverse tasks across modalities.
Pretrained checkpoints are available under the Gemma 3n releases on Hugging Face.
Today, we are excited to announce that NeMo Automodel now supports Gemma 3n, making it easier than ever to load, train, and inference with Gemma 3n models.
Fine-tuning Gemma 3n with NeMo Automodel#
NeMo Framework’s Automodel path (“Nemo AutoModel”) offers day-0 support for :hugs:Hugging Face models via a unified interface to load and finetune models across modalities, abstracting away backend complexity. With Gemma 3n support:
Load models with a single
from_pretrainedcallFine-tune models using full parameter training or PEFT (LoRA) with predefined recipes
Accelerate training with kernel optimizations
Leverage FSDP2/nvFSDP for efficient distributed training
Check out our tutorial on SFT and PEFT for both Gemma 3 and Gemma 3n models!
Observations#
Training Dynamics#
During the first hundred optimization steps we observed suspiciously large gradients. However, after a few iterations it quickly stabilizes. While the run remains numerically stable after this “warm-up,” overall convergence still lags behind Gemma 3. We continue to investigate the source of this discrepancy.
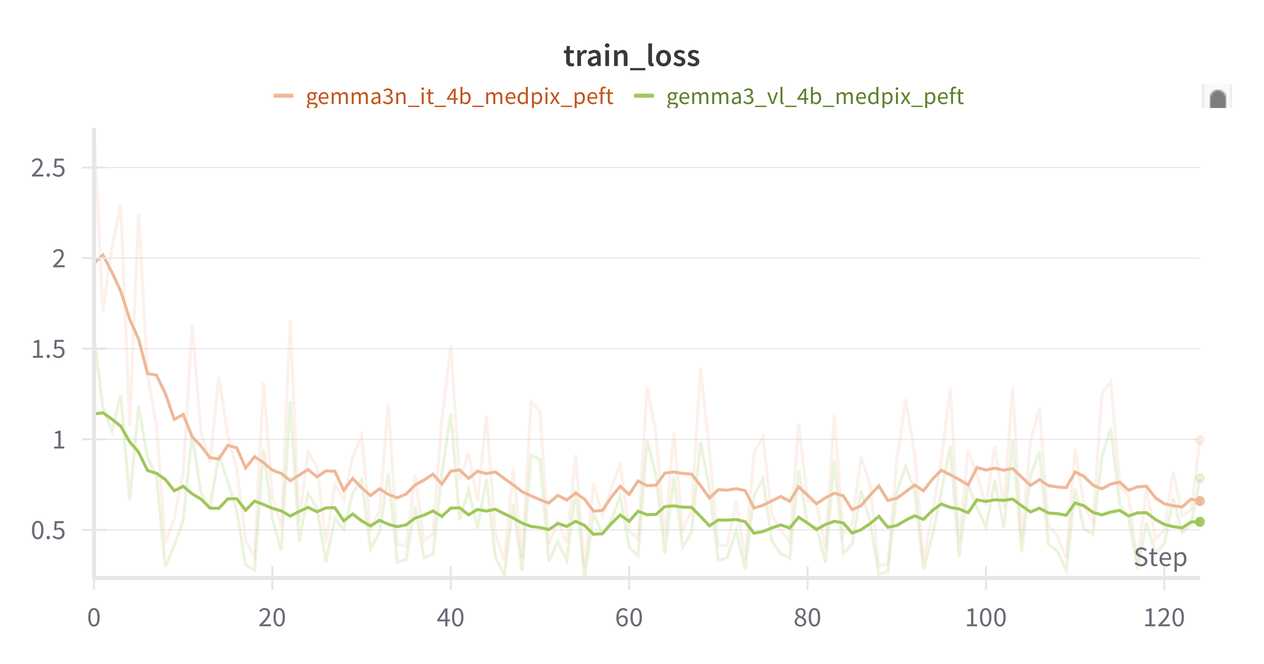
Our preliminary benchmark on vision and audio capabilities shows some gaps between Gemma 3n and existing alternatives. We will follow up with more concrete results later.
Conclusion#
Gemma 3n brings impressive efficiency and opens up new possibilities for multimodal tasks on devices. With NeMo Automodel, getting started and fine-tuning these efficient models requires only a few commands!
We look forward to seeing what you build with Gemma 3n and NeMo Automodel. Check out the documentation guide for a full walkthrough, and reach out on GitHub Discussions if you have questions.