Fine-Tune Gemma 3 and Gemma 3n#
This document explains how to fine-tune Gemma 3 and Gemma 3n using NeMo AutoModel. It outlines key operations, including initiating SFT and PEFT-LoRA runs and managing experiment configurations using YAML.
To set up your environment to run NeMo AutoModel, follow the Installation Guide.
Data#
MedPix-VQA Dataset#
The MedPix-VQA dataset is a comprehensive medical Visual Question-Answering dataset designed for training and evaluating VQA models in the medical domain. It contains medical images from MedPix, a well-known medical image database, paired with questions and answers that focus on medical image interpretation.
The dataset consists of 20,500 examples with the following structure:
Training Set: 17,420 examples (85%)
Validation Set: 3,080 examples (15%)
Columns:
image_id,mode,case_id,question,answer
Preprocess the Dataset#
NeMo AutoModel provides built-in preprocessing for the MedPix-VQA dataset through the make_medpix_dataset function. Here’s how the preprocessing works:
from nemo_automodel.components.datasets.vlm.datasets import make_medpix_dataset
# Load and preprocess the dataset
dataset = make_medpix_dataset(
path_or_dataset="mmoukouba/MedPix-VQA",
split="train"
)
The preprocessing pipeline performs the following steps:
Loads the dataset using the Hugging Face
datasetslibrary.Extracts question-answer pairs by processing the
questionandanswerfields from the dataset.Converts to the Hugging Face message list format to restructure the data into a chat-style format compatible with the Autoprocessor’s
apply_chat_templatefunction.
# Example of the conversation format created
conversation = [
{
"role": "user",
"content": [
{"type": "image", "image": example["image_id"]},
{"type": "text", "text": example["question"]},
],
},
{
"role": "assistant",
"content": [{"type": "text", "text": example["answer"]}]
},
]
Use the Collate Functions#
NeMo AutoModel provides specialized collate functions for different VLM processors. The collate function is responsible for batching examples and preparing them for model input.
Both Gemma 3 and Gemma 3n models work seamlessly with the Hugging Face AutoProcessor and use the default collate function:
processor = AutoProcessor.from_pretrained("google/gemma-3-4b-it")
# For Gemma 3n, get processor:
# processor = AutoProcessor.from_pretrained("google/gemma-3n-e4b-it")
# For Gemma 3 and Gemma 3n, use the default collate function
def default_collate_fn(examples: list, processor) -> dict[str, torch.Tensor]:
batch = processor.apply_chat_template(
[example["conversation"] for example in examples],
tokenize=True,
add_generation_prompt=False,
return_tensors="pt",
return_dict=True,
)
labels = batch["input_ids"].clone()[:, 1:]
labels = torch.cat([labels, -100 * torch.ones_like(labels[:, :1])], dim=1)
batch["labels"] = labels
loss_mask = create_batch_loss_masks(
batch["input_ids"], processor, start_of_response_token=start_of_response_token
)
batch["loss_mask"] = loss_mask
return batch
The default collate function:
Applies the processor’s chat template to convert message lists into model-ready inputs.
Creates labels for training to guide supervised learning.
Masks prompts and special tokens so that only answer tokens are considered during loss calculation.
Preprocess Custom Datasets#
When using a custom dataset with a model whose Hugging Face AutoProcessor supports the apply_chat_template method, you’ll need to convert your data into the Hugging Face message list format expected by the apply_chat_template.
We provide examples demonstrating how to perform this conversion.
Some models, such as Qwen2.5 VL, have specific preprocessing requirements and require custom collate functions. For instance, Qwen2.5-VL uses the qwen_vl_utils.process_vision_info function to process images:
texts = [processor.apply_chat_template(example["conversation"], tokenize=False) for example in examples]
image_inputs = [process_vision_info(example["conversation"])[0] for example in examples]
batch = processor(
text=texts,
images=image_inputs,
padding=True,
return_tensors="pt",
)
If your dataset requires custom preprocessing logic, you can define a custom collate function. To use it, specify the function in your YAML configuration:
dataloader:
_target_: torchdata.stateful_dataloader.StatefulDataLoader
batch_size: 1
collate_fn:
_target_: nemo_automodel.components.datasets.vlm.collate_fns.qwen2_5_collate_fn
We provide example custom collate functions that you can use as references for your implementation.
Run the Fine-Tune Script#
Use the automodel CLI to launch fine-tuning with a YAML configuration file.
Apply YAML-Based Configuration#
NeMo AutoModel uses a flexible configuration system that combines YAML configuration files with command-line overrides. This allows you to maintain base configurations while easily experimenting with different parameters.
The simplest way to run fine-tuning is with a YAML configuration file. We provide configs for both Gemma 3 and Gemma 3n.
Note
These VLM recipes require the optional vlm dependency set. If you see ImportError: qwen_vl_utils is not installed, install VLM dependencies first:
uv sync --frozen --extra vlm
(If you’re using pip: pip3 install "nemo-automodel[vlm]".)
Run Gemma 3 Fine-Tuning#
Single-GPU
automodel examples/vlm_finetune/gemma3/gemma3_vl_4b_medpix.yaml
Multi-GPU
automodel --nproc-per-node=2 examples/vlm_finetune/gemma3/gemma3_vl_4b_medpix.yaml
Run Gemma 3n Fine-Tuning#
Single-GPU
automodel examples/vlm_finetune/gemma3n/gemma3n_vl_4b_medpix.yaml
Multi-GPU
automodel --nproc-per-node=2 examples/vlm_finetune/gemma3n/gemma3n_vl_4b_medpix.yaml
Override Configuration Parameters#
You can override any configuration parameter using dot-notation without modifying the YAML file:
automodel examples/vlm_finetune/gemma3/gemma3_vl_4b_medpix.yaml \
--step_scheduler.ckpt_every_steps 100 \
--step_scheduler.max_steps 1000 \
--optimizer.lr 2e-5 \
--rng.seed 1234
Configure Model Freezing#
NeMo AutoModel supports parameter freezing, allowing you to control which parts of a model remain trainable during fine-tuning. This is especially useful for VLMs, where you may want to preserve the pre-trained visual and audio encoders while adapting only the language model components.
With the freezing configuration, you can selectively freeze specific parts of the model to suit your training objectives:
freeze_config:
freeze_embeddings: true # Freeze embeddings
freeze_vision_tower: true # Freeze vision encoder (recommended for VLMs)
freeze_audio_tower: true # Freeze audio encoder (for multimodal models)
freeze_language_model: false # Allow language model adaptation
Run Parameter-Efficient Fine-Tuning#
For memory-efficient training, you can use Low-Rank Adaptation (LoRA) instead of full fine-tuning. NeMo AutoModel provides a dedicated PEFT recipe for Gemma 3:
To run PEFT with Gemma 3:
automodel examples/vlm_finetune/gemma3/gemma3_vl_4b_medpix_peft.yaml
The LoRA configuration excludes vision and audio components from adaptation to preserve pre-trained visual representations:
peft:
peft_fn: nemo_automodel._peft.lora.apply_lora_to_linear_modules
match_all_linear: False
exclude_modules: # exclude all vision and audio modules and lm_head
- "*vision_tower*"
- "*vision*"
- "*visual*"
- "*audio*"
- "*image_encoder*"
- "*lm_head*"
dim: 8
alpha: 32
use_triton: True
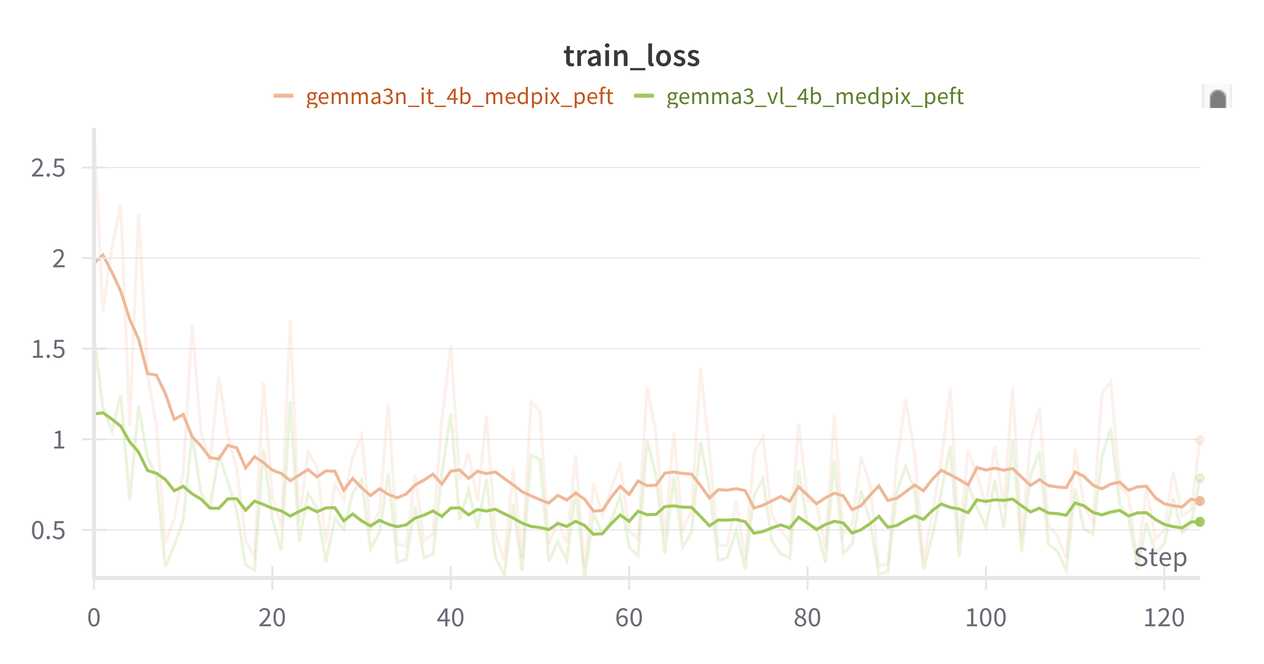
The training loss should look similar to the example below:
Checkpointing#
We support training state checkpointing in either Safetensors or PyTorch DCP format.
checkpoint:
enabled: true
checkpoint_dir: vlm_checkpoints/
model_save_format: torch_save # or "safetensors"
save_consolidated: false
Integrate Weights & Biases#
You can enable W&B logging by setting your API key and configuring the logger:
export WANDB_API_KEY=<YOUR_WANDB_API_KEY>
Then, add the W&B configuration to your YAML file:
wandb:
project: nemo_automodel_vlm
entity: your_entity
name: gemma3_medpix_vqa_experiment
save_dir: ./wandb_logs
Run Inference#
After fine-tuning your Gemma 3 or Gemma 3n model, you can use it for inference on new image-text tasks.
Generation Script#
The inference functionality is provided through examples/vlm_generate/generate.py, which supports loading fine-tuned checkpoints and performing image-text generation.
Basic Usage#
uv run examples/vlm_generate/generate.py \
--checkpoint-path /path/to/checkpoint \
--prompt "Describe this image." \
--base-model google/gemma-3-4b-it \
--image /path/to/image.jpg
The output can be either text (default) or json, with an optional write file.
For models trained on MedPix-VQA, load the trained checkpoint and generate outputs using the following command. Be sure to specify the same base model used during training:
uv run examples/vlm_generate/generate.py \
--checkpoint-path vlm_checkpoints/epoch_0_step_200 \
--prompt "What medical condition is shown in this image?" \
--base-model google/gemma-3-4b-it \
--image medical_image.jpg
When checkpoints are saved from PEFT training, they contain only the adapter weights. To use them for generation, you need to specify the PEFT configuration. Run the following command to load and generate from adapters trained on MedPix-VQA:
uv run examples/vlm_generate/generate.py \
--checkpoint-path peft_vlm_checkpoints/epoch_0_step_200/ \
--prompt "What medical condition is shown in this image?" \
--image-url medical_image.jpg \
--base-model google/gemma-3-4b-it \
--is-peft \
--peft-exclude-modules *vision_tower* *vision* *visual* *audio* *image_encoder* *lm_head*
Given the following image:
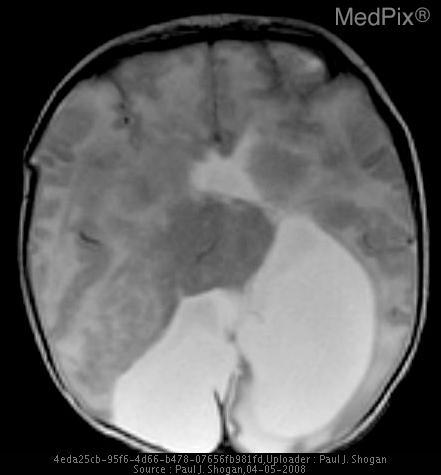
And the prompt:
How does the interhemispheric fissure appear in this image?
Example Gemma 3 response:
The interhemispheric fissure appears as a dark streak, indicating significant tissue loss.
Example Gemma 3n response:
The interhemispheric fissure appears somewhat obscured by the fluid-filled mass.