

Engineering an Enterprise-Grade Text-to-SQL Dataset with NeMo Data Designer
Engineering an Enterprise-Grade Text-to-SQL Dataset with NeMo Data Designer
While LLMs have mastered generic coding, Text-to-SQL remains one of the most challenging frontiers in enterprise AI. In many ways this is due to (i) SQL tasks relying on both code and data and (ii) real-world data and databases being quite messy. Focusing on careful data design that accounts for real-world diversity and complexity, we built a NeMo Data Designer pipeline that includes conditional sampling, three-stage LLM generation, code validators, and multi-dimensional judge scoring to generate reasoning-heavy text-to-SQL samples across PostgreSQL, MySQL, and SQLite, and automatically filter down to the highest quality 96.5k records. Each sample pairs a natural-language prompt and a fully synthetic database schema context with a target SQL query. To improve robustness and mimic the messiness of production databases, the pipeline injects distractor tables and columns into the schema context, forcing the model to learn to ignore irrelevant schema elements. The final dataset is validated and filtered through per-dialect syntax validators and five LLM-as-a-critic judges.
The “Real-World” Gap: Why Academic Data Wasn’t Enough
The gap between academic benchmarks and the messy reality of enterprise data warehouses is massive. On academic benchmarks like Spider (where schemas are clean, tables are few, and queries are straightforward), frontier models score above 85%. On BIRD (which introduces dirty data, larger schemas, and external knowledge requirements), the best open models reach roughly 70% execution accuracy --- and on Spider 2.0 Lite (which uses real enterprise databases with hundreds of tables, multiple dialects, and complex business logic), even the best models score below 50%.
The problem isn’t model capability --- it’s training data. Most open-source text-to-SQL datasets assume a “happy path”: intuitive column names, perfect data types, and straightforward questions. Production SQL is different:
- Dialect specificity. Generic “SQL” doesn’t compile. We needed valid, executable code for MySQL, PostgreSQL, and SQLite that respects their unique syntax ---
date('now')in SQLite vs.CURRENT_DATEin Postgres,DISTINCT ONin PostgreSQL vs. nested subqueries in MySQL. - Dirty data. Real columns contain currency symbols (
$57,500), mixed date formats, and JSON blobs. The model needs to learn defensive SQL: writing queries that useCAST,STR_TO_DATE, and string manipulation functions to clean data at query time before attempting any aggregation. We explicitly prompted the generation engine to introduce anti-patterns like storing dates as text ('01-Jan-2023'), including currency symbols in pricing columns, or burying critical flags inside JSON blobs. - Distractor tables and schema linking. In production, you rarely get just the 2 tables you need; you’re more likely to get a schema with 50 tables, many of which look identical. We injected semantically similar “distractor” tables into every context ---
sales_ordersvs.sales_orders_archive,customer_leadsvs.active_customers--- forcing the model to perform schema linking based on column constraints and relationships, not just table names. - Industry-specific schemas. Healthcare EHR tables look nothing like financial trading systems. The column names, relationships, and business logic are domain-specific.
- Complexity gradients. Junior analysts write simple SELECTs; senior engineers write recursive CTEs with window functions. Training data needs the full spectrum.
Domain diversity and complexity coverage matter more than dataset size.
Pipeline Overview
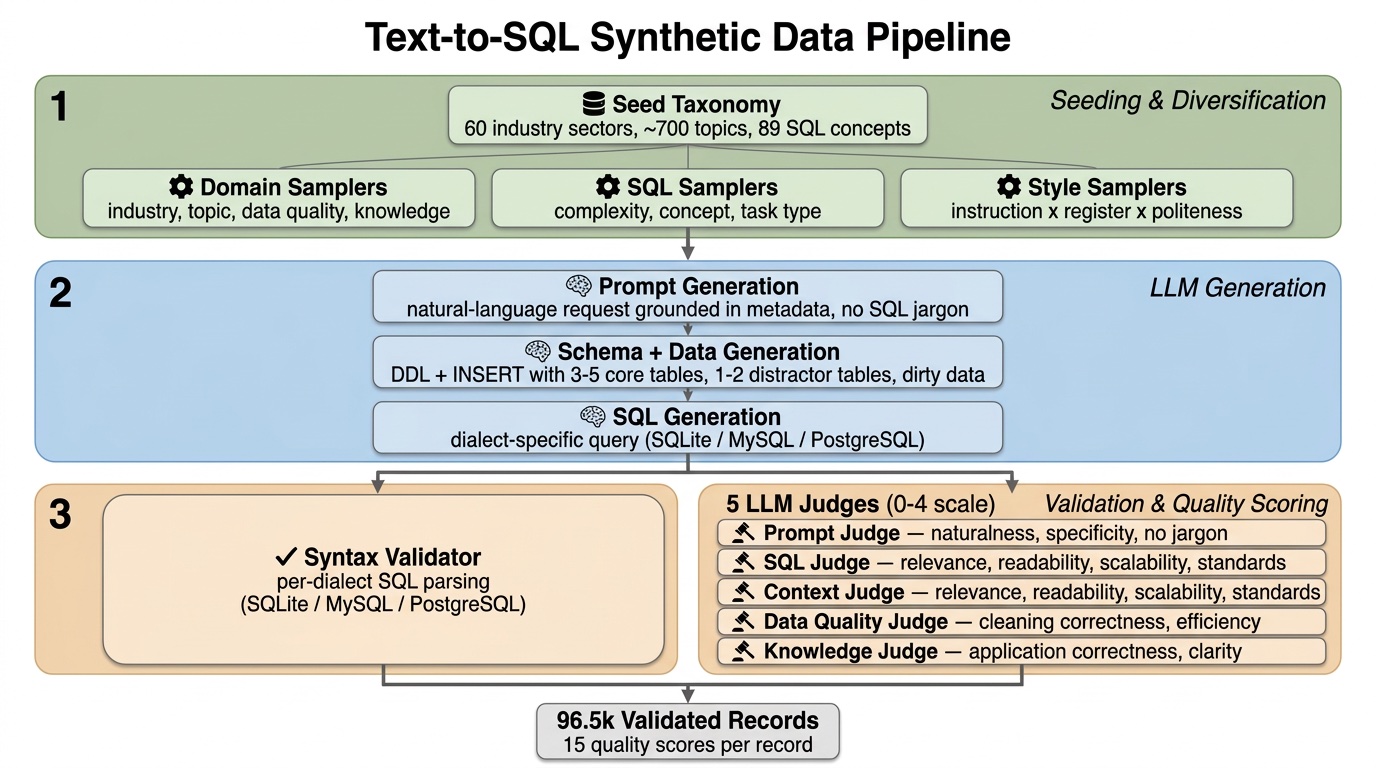
The pipeline generates text-to-SQL training data through a five-stage process. Each record flows through seeding & diversification, three LLM generation steps, and a validation + quality scoring layer. All three LLM generation stages use a reasoning model whose internal chain-of-thought improves schema design and SQL correctness. The pipeline runs independently for each SQL dialect, with dialect-specific prompts, validators, and judge prompts.
ASCII version of the pipeline diagram
Step 1: Seeding & Diversification — Controlling Diversity at the Source
Rather than relying on LLM creativity alone for diversity, the pipeline samples structured metadata that deterministically controls every axis of variation. A JSON taxonomy file defines the problem space:
Standard categorical samplers draw independently from their value lists. Data Designer’s SubcategorySamplerParams creates hierarchical dependencies --- what we call “Semantic Blueprints” --- that ensure internally consistent records. When industry_sector samples “Healthcare”, topic is drawn only from healthcare-specific subcategories. When sql_complexity samples “Beginner”, sql_concept is restricted to foundational SQL operations. This is the difference between realistic training data and random noise.
Code snippets in this post are illustrative
The code blocks below show the key configuration patterns for each pipeline stage. Model aliases (prompt_gen, context_gen, etc.) and companion files (prompts.py, rubrics.py) are referenced but not fully defined inline. For a complete, runnable pipeline, see the Enterprise Text-to-SQL Recipe.
Prompt diversity is controlled independently through three additional samplers (instruction style, linguistic register, politeness level). Because these are combinatorial (5 × 5 × 4 = 100 style combinations), even records with identical domain and SQL metadata will produce stylistically distinct prompts. A CFO asking “Can you pull the Q3 numbers?” and an engineer saying “Write a query that joins sales on customer_id” should both produce correct SQL.
Step 2: Generating Natural-Language Prompts
The prompt generation step produces a single natural-language request to a data assistant. The LLM receives all sampled metadata via Jinja2 template variables and must produce a request that:
- Describes a business problem, not a SQL specification (no SQL jargon allowed)
- Matches the sampled instruction style, linguistic register, and politeness level
- Implicitly requires the sampled SQL concept, task type, data quality handling, and knowledge dependency
- Uses realistic thresholds appropriate for small sample data (5-10 rows per table)
Here are example prompts generated from the same underlying SQL concept (window functions) but with different style settings:
Step 3: Schema and Data Generation with Distractor Injection
This is the most distinctive stage of the pipeline. For each record, the LLM generates a complete database schema (DDL) and sample data (INSERT statements) in the target SQL dialect. The schema must include both the tables needed to answer the prompt and deliberate noise:
- 3–5 core tables directly related to the industry/topic, connected via foreign keys
- 1–2 distractor tables that are plausible for the domain but not needed to answer the prompt, each with FK relationships to core tables and 5-10 rows of realistic data
- 3–5 distractor columns per table (e.g.,
created_at,updated_by,description,is_active) that are realistic but irrelevant to the query - Dirty data injected according to the sampled
data_quality_concept— stored in TEXT/VARCHAR columns so the schema itself doesn’t enforce type correctness
In production, you rarely get just the 2 tables you need; you’re more likely to get a schema with 50 tables, many of which look identical. Injecting semantically similar “distractor” tables --- sales_orders vs. sales_orders_archive, customer_leads vs. active_customers --- forces the model to perform schema linking based on column constraints and relationships, not just table names. This is the skill gap between academic benchmarks and production.
The schema prompt requires four clearly labeled sections (-- Core Tables, -- Distractor Tables, -- Sample Data for Core Tables, -- Sample Data for Distractor Tables) and enforces determinism by forbidding real-time functions like NOW() or CURRENT_DATE in INSERT statements.
Step 4: Dialect-Specific SQL Generation
The SQL generation step receives the natural-language prompt and the generated schema context, then produces an executable query in the target dialect. The prompt enforces several constraints that are critical for training quality:
- Only reference defined tables/columns — the LLM is strictly forbidden from inventing schema elements
- Handle dirty data — the query must clean data issues (CAST, REPLACE, SUBSTR, regex) before computing results
- Ignore distractors — no unnecessary joins or column selections; distractor elements must be left untouched
- Anchor relative time — instead of
CURRENT_DATE, anchor to(SELECT MAX(date_col) FROM table)for reproducibility - Dialect-specific syntax — SQLite uses
strftime, MySQL usesDATE_SUB, PostgreSQL uses::casting andinterval. Each dialect also has prompt-level constraints to ensure portability (e.g., SQLite prompts excludeLATERALjoins andREGEXP_REPLACE; MySQL prompts excludeREGEXP_REPLACEfor pre-8.0 compatibility andCONVERT_TZto avoid unpopulated timezone table issues)
The pipeline runs independently for each dialect (SQLite, MySQL, PostgreSQL), producing ~32k records per dialect that are combined into the final 96.5k-record dataset. Separating prompt, schema, and query generation across three stages is essential --- when you ask a single prompt to generate all three, the SQL tends to reference tables that don’t exist in the schema, or the schema doesn’t contain the columns the SQL needs.
The chain-of-thought traces from the reasoning model teach it to think like a Data Engineer: decomposing complex problems, handling edge cases, and verifying logic before writing a single line of code. A typical reasoning trace looks like:
“The user wants to filter by date, but the ‘timestamp’ column is stored as TEXT. I need to first normalize this column using STR_TO_DATE before I can apply the WHERE clause…”
Step 5: The Quality Waterfall
Generating 300,000 samples is straightforward. Ensuring they are correct is the hard part. We implemented a rigorous “Quality Waterfall” that rejected over 68% of the generated data.
Hard Validation
Data Designer’s built-in code validator checks each SQL query for syntactic correctness against the target dialect:
The validator returns is_valid (boolean) and error_messages (string). Records that fail parsing are flagged immediately. Supported dialects: SQL_SQLITE, SQL_POSTGRES, SQL_MYSQL, SQL_TSQL, SQL_BIGQUERY, SQL_ANSI.
Five LLM Judges
Beyond syntax validity, we evaluate record quality across five judges, each scoring on a 0-4 scale:
The SQL judge rubric explicitly penalizes distractor usage:
“The SQL should only JOIN or reference tables that are strictly necessary to answer the prompt. The database context may include distractor tables that look relevant but are not needed — penalize queries that unnecessarily join or reference these tables.”
Each judge provides a score and reasoning for each dimension, making it easy to diagnose why a record scored low. After configuring the five LLMJudgeColumnConfig columns (see the full recipe for complete judge definitions), expression columns extract numeric scores into flat columns for downstream filtering:
Rich Metadata for Precision Training
We didn’t just generate text pairs --- we generated structured data. Unlike standard datasets that give you a black box of question → SQL, every single record is tagged with rich, granular metadata:
This allows researchers and engineers to “slice and dice” the training data with surgical precision. If you want to fine-tune a model specifically for Finance analytics using Window Functions in PostgreSQL, you can filter for exactly that subset.
Results
The high rejection rate is a feature, not a bug. By generating 3x more data than we needed and filtering aggressively, we ensured every record in the final dataset is both syntactically valid and semantically meaningful.
BIRD Benchmark Results
This dataset was shipped in the SFT stage of Nemotron Super v3. On the BIRD SQL benchmark (1,534 dev samples, 5-run average), Nemotron Super achieves 41.80% EX (execution accuracy) --- outperforming GPT-OSS-120B at 38.25%. Including our synthetic dataset in the SFT blend raised Nemotron Super’s EX on BIRD by 15 points, from 26.77% to 41.80%.

| Model | BIRD EX (%) |
|---|---|
| Nemotron Super (before synthetic text-to-SQL SFT data) | 26.77 |
| GPT-OSS-120B | 38.25 |
| Nemotron Super (after synthetic text-to-SQL SFT data) | 41.8 |
Caveat on BIRD: BIRD measures execution accuracy (EX) --- whether the query returns the correct result set when run against the ground-truth database. This is stricter than exact-match or string similarity, but it can also be inflated by semantically different queries that happen to produce identical result sets on small test data. BIRD’s dev set includes dirty data, external knowledge requirements, and multi-table schemas, making it more representative of production SQL than earlier benchmarks like Spider --- but it does not cover all production challenges (e.g., multi-statement transactions, DDL, stored procedures, or the hundreds-of-tables schemas common in enterprise warehouses). Results here are on the 1,534-sample dev split averaged over 5 runs.
Key Takeaways
-
Conditional sampling prevents incoherent records.
SubcategorySamplerParamsensures “Geospatial SQL” only appears with “Advanced” complexity, and “Electronic Health Records” only appears with “Healthcare”. Independent samplers would produce nonsensical combinations that confuse training. -
Three-stage generation beats one-shot. Separating prompt, schema, and query generation ensures the SQL actually references the tables that exist. One-shot generation frequently hallucinates tables.
-
Dirty data must be intentional. Explicitly prompting for anti-patterns (dates as text, currency symbols, JSON blobs) forces the model to learn defensive SQL. Clean schemas produce clean-only training data.
-
Distractor tables teach schema linking. Injecting semantically similar but irrelevant tables forces the model to read the schema instead of guessing from table names. This is the skill gap between academic benchmarks and production.
-
Per-dialect generation avoids lowest-common-denominator SQL. Rather than generating ANSI SQL and hoping it works everywhere, the pipeline produces dialect-specific schemas and queries with appropriate syntax (
strftimevsDATE_SUBvsinterval). Each dialect gets its own tailored prompts, validators, and judge prompts. -
Hard validators are non-negotiable for code. LLM judges can assess quality, but they can’t reliably detect syntax errors. Syntax validators catch parsing failures that the judge misses.
-
Multi-dimension scoring enables targeted filtering. A query that scores 4 on Relevance but 1 on Efficiency tells you the model understood the task but wrote a bad plan. You can filter differently depending on what you’re training for.
-
Chain-of-thought teaches reasoning, not just syntax. Including reasoning traces in the training data teaches models to decompose problems, handle edge cases, and verify logic --- acting as a Data Engineer rather than a translator.
Next Steps
- Code Sandbox for semantic correctness. The current Quality Waterfall validates syntax and assesses quality (LLM judges), but it doesn’t verify whether the query actually returns the right results. A natural next step would be adding Code Sandbox support to Data Designer --- executing generated SQL against a ground-truth database and comparing results to enable execution-based filtering, end-to-end verification, and hard negative mining for preference training.
- RL on BIRD. Run reinforcement learning experiments using the NeMo Gym RL environment for BIRD, training models to improve execution accuracy through reward signals from actual query execution.
- Schema representation. Improve how schemas are represented in prompts to close the gap with SOTA approaches that use richer structural encodings (e.g., foreign key graphs, column descriptions, value examples).
- More benchmarks. Incorporate additional SQL benchmarks --- Spider 2.0, LiveSQLBench --- to evaluate generalization beyond BIRD and drive the next iteration of the pipeline.
Try It Yourself
The snippet below builds a simplified text-to-SQL pipeline for SQLite using Data Designer. It covers the core stages — seeding & diversification, prompt generation, schema generation with distractors, SQL generation, syntax validation, and LLM judge scoring.
Minimal example: text-to-SQL pipeline for SQLite
Full recipe: enterprise_text_to_sql.py (self-contained, runnable)
Download Recipe
Summary
This dataset is the result of a cross-functional effort across the NeMo Data Designer and Nemotron teams at NVIDIA, combining expertise in synthetic data generation, SQL engineering, and large-scale model training.
Because this pipeline is encapsulated in Data Designer, the configuration can be shared with any team --- allowing them to fork our baseline, swap in their own schemas or industry verticals, and generate a custom, high-fidelity dataset for their specific domain.
Key Resources:
- NeMo Data Designer: github.com/NVIDIA-NeMo/DataDesigner
- BIRD Benchmark: bird-bench.github.io
- Spider 2.0 Benchmark: spider2-sql.github.io
Want to learn more about NeMo Data Designer? Check out our documentation and start building your own high-fidelity synthetic datasets today.