Two-Stage SWE RL for Qwen3-30B-A3B-Thinking#
This guide explains how to post-train a thinking MoE model — Qwen3-30B-A3B-Thinking-2507 (30B total / 3B active) — into a stronger software-engineering (SWE) agent using a two-stage RL recipe.
The recipe follows the SWE portion of the Nemotron 3 Super recipe (its Stage 2.1 / 2.2): a single-step pivot stage followed by end-to-end agentic RL. It is adapted for a Qwen3 thinking model in two important ways:
Interleaved thinking via a custom chat template. A custom serving chat template preserves reasoning content across agent turns, so the model performs interleaved thinking over a multi-turn trajectory, instead of discarding the chain of thought between turns.
Multi-harness agent environment. The underlying NeMo-Gym
swe_agentsenvironment drives the model through three agent harnesses — Codex, OpenCode, and OpenHands (CodeAct) — and mixes their prompts during training so the policy generalizes across scaffolds.
The pivot stage uses the PivotRL method (paper): rather than running full end-to-end rollouts, it applies RL on informative single-turn decision points sampled from expert trajectories, with flexible argument matching as the reward — cheap, fast, and a strong warm-start for the expensive agentic stage.
Both stages run with Async GRPO (non-colocated generation) on the Megatron backend through the NeMo-Gym integration. For the foundational concepts, see the GRPO Guide, the Async GRPO Guide, and the NeMo-Gym integration design doc.
The two stages#
RL training proceeds in two stages, each starting from the previous stage’s checkpoint:
Stage |
Name |
Goal |
Environment |
Data (open source) |
Reward |
Rollout |
|---|---|---|---|---|---|---|
1 |
SWE1 (pivot) |
Learn correct tool-call format and argument selection |
|
|
Argument comparison vs. reference action |
Single step, no sandbox — fast |
2 |
SWE2 (e2e agentic) |
Learn to resolve real GitHub issues end-to-end |
|
|
Test-suite pass (resolved) |
Multi-turn agent in an Apptainer sandbox |
The pivot stage (SWE1) is cheap because it is single-turn and requires no execution sandbox — it teaches the model to emit well-formed tool calls with the right arguments before the expensive end-to-end agentic stage. SWE2 then does full multi-turn agentic RL where the model edits a repository inside a per-instance sandbox and is rewarded when the hidden test suite passes.
Note
Both stages use nvidia/Nemotron-RL-Super-Training-Blends: swe1.jsonl for the pivot stage and swe2.jsonl for the end-to-end stage. Prepare them as in the Nemotron 3 Super “Download and prepare the data” section.
What makes this a thinking agent#
Interleaved thinking across turns#
Qwen3-Thinking emits a <think>…</think> block before each response. In a naive multi-turn agent loop the reasoning from earlier turns is discarded, which breaks the chain of thought the model relies on. This recipe keeps it: the policy generation server is configured with a custom serving chat template plus a DeepSeek-R1 reasoning parser, and history thinking is not truncated:
policy:
tokenizer:
chat_template_kwargs:
enable_thinking: true
generation:
vllm_cfg:
enable_thinking: true
http_server_serving_chat_kwargs:
enable_auto_tools: true
tool_parser: hermes
reasoning_parser: deepseek_r1
chat_template: |
... # renders <think>{reasoning_content}</think> for each assistant turn
default_chat_template_kwargs:
enable_thinking: true
truncate_history_thinking: false # <-- preserve thinking across turns
The template re-emits each assistant turn as <|im_start|>assistant\n<think>\n{reasoning_content}\n</think>\n\n{content} and always opens generation with <|im_start|>assistant\n<think>\n. Because truncate_history_thinking: false, the reasoning traces from prior turns remain in the context, giving the model interleaved thinking over the whole trajectory.
Three agent harnesses (mixed-prompt training)#
The Stage 2 swe_agents environment is built on the OpenHands agent framework but exposes three distinct agent harnesses through agent_prompt_overrides, and trains on a mix of them (run_with_mixed_prompts: true):
Harness |
|
Prompt templates |
|---|---|---|
Codex |
|
|
OpenCode |
|
|
OpenHands (CodeAct) |
|
|
Training across multiple scaffolds prevents the policy from overfitting to a single tool/prompt convention and improves robustness when the model is later deployed under a different harness. (Validation uses the CodeAct harness only.)
Async GRPO + MoE setup#
Both stages use the same training backbone. Key configuration choices (full configs below):
Async GRPO, non-colocated: generation runs on a separate pool of nodes from training (
policy.generation.colocated.enabled=false), withgrpo.async_grpo.enabled=true,max_trajectory_age_steps=1, andin_flight_weight_updates=true. This is essential for agentic rollouts whose latency varies widely (a multi-turn SWE trajectory can take many minutes).MoE stability: the router is frozen (
freeze_moe_router=true) and the auxiliary load-balancing loss is disabled (moe_aux_loss_coeff=0), so RL does not perturb expert routing.Megatron parallelism (per 8-GPU node):
TP×EP×CP×PP=2×8×4×2(SWE1) /4×8×4×2(SWE2), with sequence parallel and sequence packing enabled, atmax_total_sequence_length=131072.No KL penalty (
reference_policy_kl_penalty=0), decoupled clipping (ratio_clip_min=0.2,ratio_clip_max=0.28), constant LR1e-6.
Results#
All evaluations are pass@1 on SWE-bench Verified, 500 test samples.
Stage |
Step |
Resolved (%) |
No Patch (%) |
Patch Can’t Apply (%) |
|---|---|---|---|---|
Origin (Qwen3-30B-A3B-Thinking) |
– |
23.6 |
2.8 |
3.0 |
SWE1 (pivot, used as Stage 2 base) |
step230 |
30.4 |
1.6 |
2.6 |
SWE2 |
step40 |
31.0 |
0.8 |
1.8 |
SWE2 |
step69 |
28.6 |
0.8 |
1.2 |
SWE2 |
step100 |
30.4 |
1.0 |
1.4 |
SWE2 |
step118 |
31.2 ★ |
1.2 |
2.2 |
SWE2 |
step151 |
26.8 |
1.4 |
2.0 |
SWE2 |
step172 |
29.8 |
0.4 |
0.8 |
SWE2 |
step190 |
30.8 |
1.0 |
1.2 |
The pivot stage alone lifts the base model from 23.6% → 30.4% by fixing tool-call formatting (note the drop in “No Patch” and “Patch Can’t Apply” rates). End-to-end agentic RL pushes the best checkpoint to 31.2% (SWE2 step118).
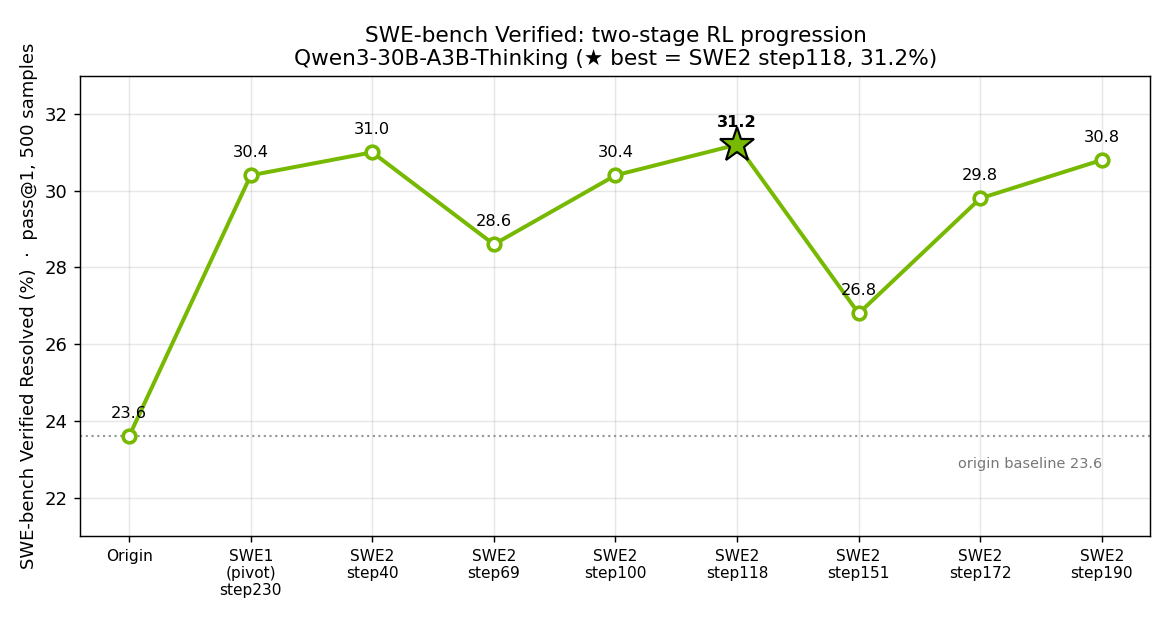
Evaluation uses the NeMo-Skills SWE-bench pipeline, adapted from its qwen3coder_30b_swebench test. The HF-converted checkpoint is served on vLLM (--enable-auto-tool-choice --tool-call-parser hermes --reasoning-parser deepseek_r1 plus the same thinking-preserving chat template used in training) and run through the swe_agent harness with agent_max_turns=200 and sampling temperature=0.7, top_p=0.8, top_k=20.
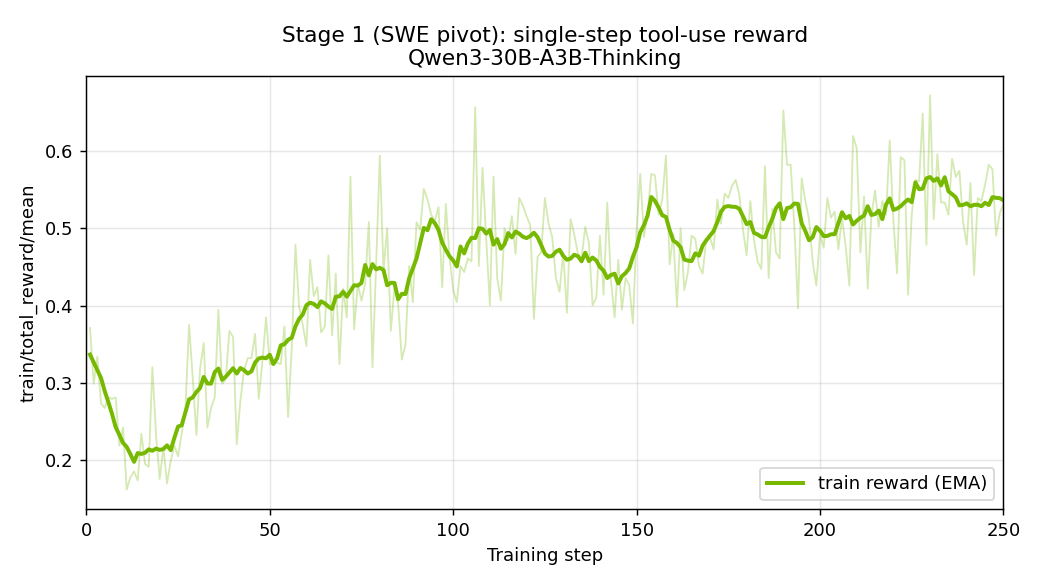
Stage 1 (SWE1, pivot) training reward#
Single-step tool-use reward climbs steadily from ~0.2 to ~0.55 over the first 250 steps as the model learns valid tool calls and argument selection. The step 230 checkpoint is taken as the pivot endpoint and used as the Stage 2 base:
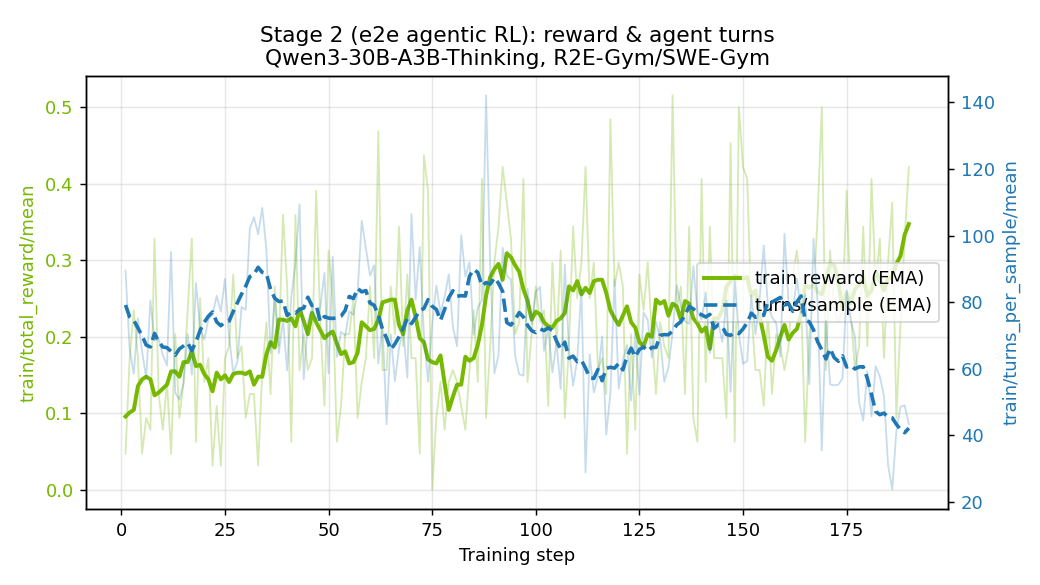
Stage 2 (SWE2) training reward & agent turns#
End-to-end reward (train/total_reward/mean) trends upward while the mean number of agent turns per sample (train/turns_per_sample/mean) decreases — the policy resolves issues with fewer, more decisive actions as training progresses:
Launch#
Both stages use the NeMo-Gym GRPO entry point:
uv run --frozen ./examples/nemo_gym/run_grpo_nemo_gym.py --config <config.yaml> {overrides}
Prerequisites#
Container. Build from the repo
docker/Dockerfile, which already installs Apptainer (symlinked assingularity) for the Stage 2 sandbox. Then pre-fetch the SWE virtual environments and mount the NeMo-Gym repo at3rdparty/Gym-workspace/Gym, as in Nemotron 3 Super → “Rebuild the container for SWE”.Data: download and split
swe1.jsonl/swe2.jsonlfollowing the Nemotron 3 Super “Download and prepare the data” section.Stage 2 sandbox images. Provide per-instance
.sifimages for the SWE-bench / R2E-Gym environments viacontainer_formatter; build and convert them as in Nemotron 3 Super Stage 2.2.Set
HF_TOKEN,WANDB_API_KEY, and your data/model paths.
Stage 1 — SWE1 (pivot)#
Single-step, no sandbox. The environment is wired through NeMo-Gym config_paths:
env:
should_use_nemo_gym: true
nemo_gym:
config_paths:
- responses_api_models/vllm_model/configs/vllm_model_for_training.yaml
- resources_servers/single_step_tool_use_with_argument_comparison/configs/swe_pivot_single_step_tool_use_with_argument_comparison.yaml
The recipe values are baked into examples/nemo_gym/grpo_qwen3_30ba3b_thinking_swe1.yaml — you only need to point it at your data:
uv run --frozen ./examples/nemo_gym/run_grpo_nemo_gym.py \
--config examples/nemo_gym/grpo_qwen3_30ba3b_thinking_swe1.yaml \
data.train.data_path=/path/to/data/swe1/train-split.jsonl \
data.validation.data_path=/path/to/data/swe1/val-split.jsonl
Stage 1 runs with 16 training nodes + 8 generation nodes, num_prompts_per_step=64, num_generations_per_prompt=8, train_global_batch_size=512, TP=2. The best checkpoint (step230) is converted to HF format and used as the starting point for Stage 2.
Stage 2 — SWE2 (end-to-end agentic)#
Multi-turn OpenHands agent in a sandbox. The environment swaps in the swe_agents config and sets the agent budget:
env:
nemo_gym:
config_paths:
- responses_api_models/vllm_model/configs/vllm_model_for_training.yaml
- responses_api_agents/swe_agents/configs/swebench_openhands_training.yaml
swe_agents_train:
responses_api_agents:
swe_agents:
run_with_mixed_prompts: true # Codex + OpenCode + CodeAct
container_formatter: [ "/path/to/images/...{instance_id}.sif", ... ]
Use examples/nemo_gym/grpo_qwen3_30ba3b_thinking_swe2.yaml, pointing policy.model_name at the Stage 1 checkpoint, the data at the swe2 split, and container_formatter at your .sif images:
uv run --frozen ./examples/nemo_gym/run_grpo_nemo_gym.py \
--config examples/nemo_gym/grpo_qwen3_30ba3b_thinking_swe2.yaml \
policy.model_name=/path/to/swe1_checkpoint_hf \
data.train.data_path=/path/to/data/swe2/train-split.jsonl \
data.validation.data_path=/path/to/data/swe2/val-split.jsonl
Stage 2 uses a smaller global batch (num_prompts_per_step=8, train_global_batch_size=64) because each rollout is an expensive multi-turn trajectory (agent_max_turns=200, swebench_agent_timeout=1800s), and bumps Megatron TP to 4. policy.model_name points at the HF-converted SWE1 checkpoint.
What to monitor#
train/total_reward/mean— primary signal and the checkpointing metric for both stages.train/turns_per_sample/mean(Stage 2) — a falling trend indicates the agent is solving tasks more efficiently; a runaway-high value suggests the agent is thrashing or hitting the turn limit.No-Patch / Patch-Can’t-Apply rates during eval — these should fall after the pivot stage if tool-call formatting has been learned.
References#
PivotRL: High Accuracy Agentic Post-Training at Low Compute Cost — the pivot-stage method (NVIDIA).
Nemotron 3 Super recipe — the multi-stage RLVR + SWE + RLHF recipe this is adapted from (data prep, SWE container, sandbox
.sifbuild).NeMo-Skills SWE-bench eval — the evaluation pipeline adapted for these results.
NeMo-Gym — agent/resource servers (
swe_agents,single_step_tool_use_with_argument_comparison).Qwen3-30B-A3B-Thinking-2507 · Nemotron-RL-Super-Training-Blends dataset (
swe1.jsonl,swe2.jsonl).