HCOLL
To meet the needs of scientific research and engineering simulations, supercomputers are growing at an unrelenting rate. As supercomputers increase in size from mere thousands to hundreds-of-thousands of processor cores, new performance and scalability challenges have emerged. In the past, performance tuning of parallel applications could be accomplished fairly easily by separately optimizing their algorithms, communication, and computational aspects. However, as systems continue to scale to larger machines, these issues become co-mingled and must be addressed comprehensively.
Collective communications execute global communication operations to couple all processes/nodes in the system and therefore must be executed as quickly and as efficiently as possible. Indeed, the scalability of most scientific and engineering applications is bound by the scalability and performance of the collective routines employed. Most current implementations of collective operations will suffer from the effects of systems noise at extreme-scale (system noise increases the latency of collective operations by amplifying the effect of small, randomly occurring OS interrupts during collective progression.) Furthermore, collective operations will consume a significant fraction of CPU cycles, cycles that could be better spent doing the meaningful computation.
Mellanox Technologies has addressed these two issues, lost CPU cycles and performance lost to the effects of system noise, by offloading the communications to the host channel adapters (HCAs) and switches. The technologies of SHARP (Scalable Hierarchical Aggregation and Reduction Protocols) and CORE-Direct® (Collectives Offload Resource Engine) provide the most advanced solution available for handling collective operations, thereby ensuring maximal scalability, minimal CPU overhead, and providing the capability to overlap communication operations with computation allowing applications to maximize asynchronous communication.
Additionally, HCOLL also contains support for building runtime configurable hierarchical collectives. HCOLL leverages hardware multicast capabilities to accelerate collective operations. In HCOLL, the performance and scalability of the UCX point-to-point library in the form of the "ucx_p2p" BCOL is fully taken advantage of. This enables users to leverage Mellanox hardware offloads transparently and with minimal effort.
HCOLL is a standalone library that can be integrated into any MPI or PGAS runtime. Support for HCOLL is currently integrated into Open MPI versions 1.7.4 and higher. HCOLL release currently supports blocking and non-blocking variants of "Allgather", "Allgatherv", "Allreduce", "AlltoAll", "AlltoAllv", "Barrier", and "Bcast".
The following diagram summarizes the HCOLL architecture:
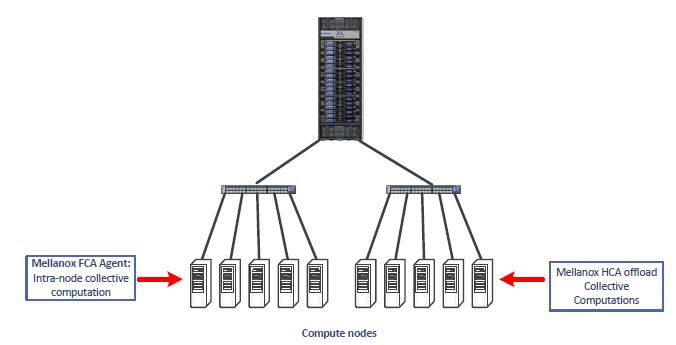
The following diagram shows the HCOLL components and the role that each plays in the acceleration process:
HCOLL is part of the HPC-X software toolkit and does not require any special installation.
Enabling HCOLL in Open MPI
HCOLL is enabled by default with HPC-X. Users can explicitly disable it using the following MCA parameter.
%mpirun -np 32 -mca coll_hcoll_enable 0 ./a.out
Tuning HCOLL Setting
The default HCOLL settings should be optimal for most systems. To check the available HCOLL parameters and their default values, run the following command after loading HPC-X.
% $HPCX_HCOLL_DIR/bin/hcoll_info –all
HCOLL parameters are simply environment variables and can be modified in one of the following ways:
Modify the default HCOLL parameters as part of the mpirun command.
% mpirun ... -x HCOLL_ML_BUFFER_SIZE=
65536Modify the default HCOLL parameter values from SHELL:
% export -x HCOLL_ML_BUFFER_SIZE=
65536% mpirun ...
Selecting Ports and Devices
and port you would like HCOLL to run over:
-x HCOLL_MAIN_IB=<device_name>:<port_num>
Enabling Offloaded MPI Non-blocking Collectives
In order to use hardware offloaded collectives in non-blocking MPI calls (e.g. MPI_Ibcast()), set the following parameter
-x HCOLL_ENABLE_NBC=1
The supported non-blocking MPI collectives are:Note that enabling non-blocking MPI collectives will disable multicast acceleration in blocking MPI collectives.
MPI_Ibarrier
MPI_Ibcast
MPI_Iallgather
MPI_Iallreduce (4b, 8b, SUM, MIN, PROD, AND, OR, LAND, LOR)
Enabling Multicast Accelerated Collectives
HCOLL uses hardware multicast to accelerate certain collective operations. In order to take full advantage of this unique capability, you must first have IPoIB configured on every adapter card/port pair that collective message traffic flows through.
Configuring IPoIB
To configure IPoIB, you need to define an IP address on the IB interface.
Use /usr/bin/ibdev2netdev to show all IB interfaces.
hpchead ~ >ibdev2netdev mlx4_0 port
1==> ib0 (Down) mlx4_0 port2==> ib1 (Down) mlx5_0 port1==> ib2 (Down) mlx5_0 port2==> ib3 (Down)Use /sbin/ifconfig to get the address information for a specific interface (e.g. ib0).
hpchead ~ >ifconfig ib0 ifconfig uses the ioctl access method to get the full address information, which limits hardware addresses to
8bytes. Since InfiniBand address has20bytes, only the first8bytes are displayed correctly. Ifconfig is obsolete! For replacement check ip. ib0 Link encap:InfiniBand HWaddr A0:04:02:20:FE:80:00:00:00:00:00:00:00:00:00:00:00:00:00:00inet addr:192.168.1.1Bcast:192.168.1.255Mask:255.255.255.0BROADCAST MULTICAST MTU:2044Metric:1RX packets:58errors:0dropped:0overruns:0frame:0TX packets:1332errors:0dropped:0overruns:0carrier:0collisions:0txqueuelen:1024RX bytes:3248(3.1KiB) TX bytes:80016(78.1KiB)Or you can use /sbin/ip for the same purpose
hpchead ~ >ip addr show ib0
4: ib0: <BROADCAST,MULTICAST> mtu2044qdisc mq state DOWN qlen1024link/infiniband a0:04:02:20:fe:80:00:00:00:00:00:00:00:02:c9:03:00:21:f9:31brd00:ff:ff:ff:ff:12:40:1b:ff:ff:00:00:00:00:00:00:ff:ff:ff:ff inet192.168.1.1/24brd192.168.1.255scope global ib0-
In the example above, the IP is defined (192.168.1.1). If it is not defined, then you can define an IP address now.
Enabling Mellanox SHARP Software Accelerated Collectives
As of v1.7, HPC-X supports Mellanox SHARP Software Accelerated Collectives. These collectives are enabled by default if HCOLL v3.5 and above detects that it is running in a supported environment.
-x HCOLL_ENABLE_SHARP=1
-x HCOLL_ENABLE_SHARP=0
-x HCOLL_BCOL_P2P_ALLREDUCE_SHARP_MAX=<threshold> ( default: tune based on sharp resources)
The maximum small message allreduce algorithm runs through SHARP. Messages with a size greater than the above will use SHARP streaming aggregation or fall back to non-SHARP-based algorithms (multicast based or non-multicast based).
For instructions on how to deploy Mellanox SHARP software in InfiniBand fabric, see Mellanox Scalable Hierarchical Aggregation and Reduction Protocol (SHARP) Deployment Guide.
Once Mellanox SHARP software is deployed, you need to only specify the HCA device (device_name) and port number (port_num) that is connected to the Mellanox SHARP software tree in the following way:
-x HCOLL_MAIN_IB=<device_name>:<port_num>
GPU Buffer Support in HCOLL
HCOLL of version >= 4.4 supports collective operations over GPU buffers. The supported GPU HW includes NVIDIA® GPUs starting from Tesla K80.
Minimal SW requirement: CUDA® (version >= 9.0).
If CUDA runtime is available during MPI job, HCOLL will automatically enable GPU support. Collective operations that support GPU buffers:
Allreduce
Bcast
Allgather
If some other collective operation API of libhcoll is called with GPU buffer, then the call would return HCOLL_ERROR after the buffer type check.
Recommended Additional SW
NCCL (version >= 2.4).
It is recommended to install libnccl for better performance. If it is not available, HCOLL will print a warning regarding potentially lower performance. The warning can be suppressed by setting “-x HCOLL_CUDA_BCOL=ucx_p2p -x HCOLL_CUDA_SBGP=p2p”.GPUDirect RDMA nv_peer_mem. If nv_peer_mem module is loaded on all nodes, then Bcast operation over GPU buffers will be optimized with HW Multicast.
The control parameter is HCOLL_GPU_ENABLE = <0,1,-1>
where:
Parameter | Description |
0 | GPU support disabled. The type of the user buffers’ pointers is not checked. In such a case, if the user provides the buffer allocated on GPU, the behavior is undefined. |
1 | GPU support enabled. The buffer pointer is checked and HCOLL GPU collectives are enabled. This is the default value if the CUDA runtime is available. |
-1 | Partial GPU support. The buffer pointer is checked and HCOLL falls back to the runtime in the case of GPU buffer. |
Limitations
Not all combinations of (OP, DTYPE) are supported for MPI_Allreduce with GPU buffers.
Supported operations:
SUM
PROD
MIN
MAX
Supported types:
INT8,16,32,64
UINT8,16,32,64
FLOAT16,32,64
Limitations
As of v4.1 release, HCOLL does not fully support mixed MPI datatypes. In this context, mixed datatypes refers to collective operations where the datatype layout of input and output buffers may be different on different ranks. For example:
For an arbitrary MPI collective operation:MPI_Collective_op( input, count1, datatype-in_i, output, count2,datatype-out_i, communicator)
Where i = 0,...,(number_of_mpi_processes - 1)
Mixed mode means when i is not equal to j, (datatype-in_i, datatype-out_i) is not necessarily equal to (datatype-in_j, datatype-out_j).
Mixed MPI datatypes, in general, can prevent protocol consensus inside HCOLL, resulting in hangs. However, because HCOLL contains a datatype engine with packing and unpacking flows built into the collective algorithms, mixed MPI datatypes will work under the following scenarios:
If the packed length of the data (a value all ranks must agree upon regardless of datatype) can fit inside a single HCOLL buffer (the default is (64Kbytes - header_space)), then mixed datatypes will work.
If the packed length of count*datatype is bigger than an internal HCOLL buffer, then HCOLL will need to fragment the message. If the datatypes and counts are defined on each rank so that all ranks agree on the number of fragments needed to complete the operation, then mixed datatypes will work. Our datatype engine cannot split across primitive types and padding, this may result in non-agreement on the number of fragments required to process the operation. When this happens, HCOLL will hang with some ranks expecting incoming fragments and other believing the operation is complete.
The environment variable HCOLL_ALLREDUCE_ZCOPY_TUNE=<static/dynamic> (default - dynamic) selects the level of automatic runtime tuning of HCOLL’s large data allreduce algorithm. “Static” means no tuning is applied at runtime. “Dynamic” - allows HCOLL to dynamically adjust the algorithms radix and zero-copy threshold selection based on runtime sampling of performance.
Note: The “dynamic” mode should not be used in cases where numerical reproducibility is required, as this mode may result in a variation of the floating point reduction result from one run to another due to non-fixed reduction order.