Introduction
This manual is intended for system administrators responsible for the installation, configuration, management and maintenance of the software and hardware of VPI (InfiniBand, Ethernet) adapter cards. It is also intended for application developers.
NVIDIA OFED is a single Virtual Protocol Interconnect (VPI) software stack which operates across all NVIDIA network adapter solutions supporting the following uplinks to servers:
|
Uplink/NICs |
Driver Name |
Uplink Speed |
|
BlueField-2 |
mlx5 |
|
|
BlueField |
|
|
|
ConnectX-6 Dx |
|
|
|
ConnectX-6 Lx |
|
|
|
ConnectX-6 |
|
|
|
ConnectX-5/ConnectX-5 Ex |
|
|
|
ConnectX-4 Lx |
|
|
|
ConnectX-4 |
|
56GbE is an NVIDIA proprietary link speed and can be achieved while connecting an NVIDIA adapter card to
NVIDIA SX10XX switch series or when connecting an NVIDIA adapter card to another NVIDIA adapter card.Supports both NRZ and PAM4 modes.
All NVIDIA network adapter cards are compatible with OpenFabrics-based RDMA protocols and software and are supported by major operating system distributions.
NVIDIA OFED is certified with the following products:
NVIDIA Messaging Accelerator (VMA™) software: Socket acceleration library that performs OS bypass for standard socket-based applications.
Please note, VMA support is provided separately from NVIDIA OFED support. For further information, please refer to the VMA documentation (docs.nvidia.com/networking/category/vma).NVIDIA Unified Fabric Manager (UFM®) software: Powerful platform for managing demanding scale-out computing fabric environments, built on top of the OpenSM industry standard routing engine.
Fabric Collective Accelerator (FCA)—FCA is a NVIDIA MPI-integrated software package that utilizes CORE-Direct technology for implementing the MPI collectives communications.
The figure below shows a diagram of the NVIDIA OFED stack, and how upper layer protocols (ULPs) interface with the hardware and with the kernel and userspace. The application level also shows the versatility of markets that NVIDIA OFED applies to.
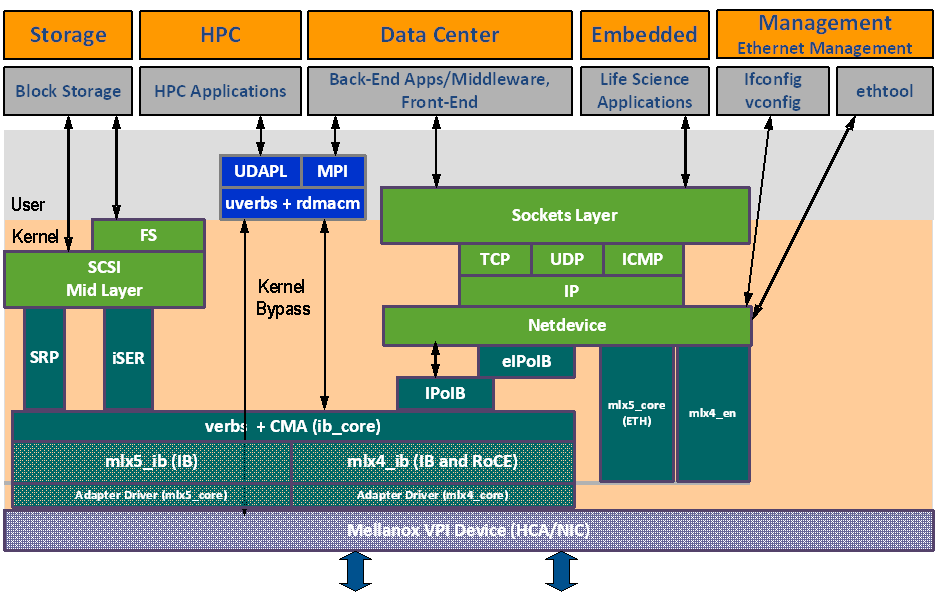
The following subsections briefly describe the various components of the NVIDIA OFED stack.
mlx4 VPI Driver
This driver is no longer supported in MLNX_OFED. To work with ConnectX-3 and ConnectX-3 Pro NICs, please refer to MLNX_OFED LTS version available on the web.
mlx5 Driver
mlx5 is the low-level driver implementation for the Connect-IB® and ConnectX®-4 and above adapters designed by NVIDIA. ConnectX®-4 and above adapter cards operate as a VPI adapter (Infiniband and Ethernet). The mlx5 driver is comprised of the following kernel modules:
Please note that Connect-IB card is no longer supported in MLNX_OFED. To work with this card, please refer to MLNX_OFED LTS version available on the web.
mlx5_core
Acts as a library of common functions (e.g. initializing the device after reset) required by ConnectX®-4 and above adapter cards. mlx5_core driver also implements the Ethernet interfaces for ConnectX®-4 and above. mlx5 drivers do not require the mlx5_en module as the Ethernet functionalities are built-in in the mlx5_core module.
mlx5_ib
Handles InfiniBand-specific functions and plugs into the InfiniBand mid layer.
libmlx5
libmlx5 is the provider library that implements hardware specific user-space functionality. If there is no compatibility between the firmware and the driver, the driver will not load and a message will be printed in the dmesg.
The following are the libmlx5 Legacy and RDMA-Core environment variables:
MLX5_FREEZE_ON_ERROR_CQE
Causes the process to hang in a loop of completion with error, which is not flushed with error or retry exceeded occurs/
Otherwise disabled
MLX5_POST_SEND_PREFER_BF
Configures every work request that can use blue flame will use blue flame
Otherwise, blue flame depends on the size of the message and inline indication in the packet
MLX5_SHUT_UP_BF
Disables blue flame feature
Otherwise, do not disable
MLX5_SINGLE_THREADED
All spinlocks are disabled
Otherwise, spinlocks enabled
Used by applications that are single threaded and would like to save the overhead of taking spinlocks.
MLX5_CQE_SIZE
64—completion queue entry size is 64 bytes (default)
128—completion queue entry size is 128 bytes
MLX5_SCATTER_TO_CQE
Small buffers are scattered to the completion queue entry and manipulated by the driver. Valid for RC transport.
Default is 1, otherwise disabled
The following are libmlx5 Legacy only environment variables:
MLX5_ENABLE_CQE_COMPRESSION
Saves PCIe bandwidth by compressing a few CQEs into a smaller amount of bytes on PCIe. Setting this variable enables CQE compression.
Default value 0 (disabled)
MLX5_RELAXED_PACKET_ORDERING_ON
See “Out-of-Order (OOO) Data Placement” section.
Mid-layer Core
Core services include management interface (MAD), connection manager (CM) interface, and Subnet Administrator (SA) interface. The stack includes components for both user-mode and kernel applications. The core services run in the kernel and expose an interface to user-mode for verbs, CM and management.
Upper Layer Protocols (ULPs)
IP over IB (IPoIB)
The IP over IB (IPoIB) driver is a network interface implementation over InfiniBand. IPoIB encapsulates IP datagrams over an InfiniBand connected or datagram transport service. IPoIB pre-appends the IP datagrams with an encapsulation header and sends the outcome over the InfiniBand transport service. The transport service is Unreliable Datagram (UD) by default, but it may also be configured to be Reliable Connected (RC), in case RC is supported. The interface supports unicast, multicast and broadcast. For details, see “IP over InfiniBand (IPoIB)” section.
iSCSI Extensions for RDMA (iSER)
iSCSI Extensions for RDMA (iSER) extends the iSCSI protocol to RDMA. It permits data to be transferred directly into and out of SCSI buffers without intermediate data copies. For further information, please refer to “iSCSI Extensions for RDMA (iSER)” section.
SCSI RDMA Protocol (SRP)
SCSI RDMA Protocol (SRP) is designed to take full advantage of the protocol offload and RDMA features provided by the InfiniBand architecture. SRP allows a large body of SCSI software to be readily used on InfiniBand architecture. The SRP driver—known as the SRP Initiator—differs from traditional low-level SCSI drivers in Linux. The SRP Initiator does not control a local HBA; instead, it controls a connection to an I/O controller—known as the SRP Target—to provide access to remote storage devices across an InfiniBand fabric. The SRP Target resides in an I/O unit and provides storage services. See “SRP—SCSI RDMA Protocol” section.
User Direct Access Programming Library (uDAPL)
User Direct Access Programming Library (uDAPL) is a standard API that promotes data center application data messaging performance, scalability, and reliability over RDMA interconnects InfiniBand and RoCE. The uDAPL interface is defined by the DAT collaborative. This release of the uDAPL reference implementation package for both DAT 1.2 and 2.0 specification is timed to coincide with OFED release of the Open Fabrics (www.openfabrics.org) software stack.
MPI
Message Passing Interface (MPI) is a library specification that enables the development of parallel software libraries to utilize parallel computers, clusters, and heterogeneous networks. NVIDIA OFED includes the following MPI implementation over InfiniBand:
Open MPI – an open source MPI-2 implementation by the Open MPI Project
NVIDIA OFED also includes MPI benchmark tests such as OSU BW/LAT, Intel MPI BeBenchmarkand Presta.
InfiniBand Subnet Manager
All InfiniBand-compliant ULPs require a proper operation of a Subnet Manager (SM) running on the InfiniBand fabric, at all times. An SM can run on any node or on an IB switch. OpenSM is an InfiniBand-compliant Subnet Manager, and it is installed as part of NVIDIA OFED1.
1. OpenSM is disabled by default. See “OpenSM” section for details on enabling it.
Diagnostic Utilities
NVIDIA OFED includes the following two diagnostic packages for use by network and data center managers:
ibutils—NVIDIA diagnostic utilities
infiniband-diags—OpenFabrics Alliance InfiniBand diagnostic tools
NVIDIA Firmware Tools (MFT)
The NVIDIA Firmware Tools package is a set of firmware management tools for a single InfiniBand node. MFT can be used for:
Generating a standard or customized NVIDIA firmware image
Burning a firmware image to a single InfiniBand node
MFT includes a set of tools used for performing firmware update and configuration, as well as debug and diagnostics, and provides MST service. For the full list of available tools within MFT, please refer to MFT documentation (docs.nvidia.com/networking/category/mft).
ISO Image
NVIDIA OFED for Linux (MLNX_OFED_LINUX) is provided as ISO images or as a tarball, one per supported Linux distribution and CPU architecture, that includes source code and binary RPMs, firmware, utilities, and documentation. The ISO image contains an installation script (called mlnxofedinstall) that performs the necessary steps to accomplish the following:
Discover the currently installed kernel
Uninstall any InfiniBand stacks that are part of the standard operating system distribution or another vendor's commercial stack
Install the MLNX_OFED_LINUX binary RPMs (if they are available for the current kernel)
Identify the currently installed InfiniBand HCAs and perform the required firmware updates
Software Components
MLNX_OFED_LINUX contains the following software components:
NVIDIA Host Channel Adapter Drivers
mlx5
mlx5_ib
mlx5_core (includes Ethernet)
Mid-layer core
Verbs, MADs, SA, CM, CMA, uVerbs, uMADs
Upper Layer Protocols (ULPs)
IPoIB, SRP Initiator and SRP
MPI
Open MPI stack supporting the InfiniBand, RoCE and Ethernet interfaces
MPI benchmark tests (OSU BW/LAT, Intel MPI Benchmark, Presta)
OpenSM: InfiniBand Subnet Manager
Utilities
Diagnostic tools
Performance tests
Sysinfo (see Sysinfo User Manual)
Firmware tools (MFT)
Source code for all the OFED software modules (for use under the conditions mentioned in the modules' LICENSE files)
Documentation
Firmware
The ISO image includes the following firmware item:
mlnx-fw-updater RPM/DEB package, which contains firmware binaries for supported devices (using mlxfwmanager tool).
Directory Structure
The ISO image of MLNX_OFED_LINUX contains the following files and directories:
mlnxofedinstall—the MLNX_OFED_LINUX installation script.
ofed_uninstall.sh—This is the MLNX_OFED_LINUX un-installation script.
<RPMS folders>—Directory of binary RPMs for a specific CPU architecture.
src/—Directory of the OFED source tarball.
MLNX_OFED includes the OFED source RPM packages used as a build platform for kernel code but does not include the sources of NVIDIA proprietary packages.
mlnx_add_kernel_support.sh—Script required to rebuild MLNX_OFED_LINUX for customized kernel version on supported Linux Distribution
RPM based—A script required to rebuild MLNX_OFED_LINUX for customized kernel version on supported RPM-based Linux Distribution
docs/—Directory of NVIDIA OFED related documentation
mlx5_core Module Parameters
The mlx5_core module supports a single parameter used to select the profile which defines the number of resources supported.
|
prof_sel |
The parameter name for selecting the profile. The supported values for profiles are:
|
|
guids |
charp |
|
node_guid |
guids configuration. This module parameter will be obsolete! |
|
debug_mask |
debug_mask: 1 = dump cmd data, 2 = dump cmd exec time, 3 = both. Default=0 (uint) |
|
probe_vf |
probe VFs or not, 0 = not probe, 1 = probe. Default = 1 (bool) |
|
num_of_groups |
Controls the number of large groups in the FDB flow table. Default=4; Range=1-1024 |
ib_core Parameters
|
send_queue_size |
Size of send queue in number of work requests (int) |
|
recv_queue_size |
Size of receive queue in number of work requests (int) |
|
force_mr |
Force usage of MRs for RDMA READ/WRITE operations (bool) |
|
roce_v1_noncompat_gid |
Default GID auto configuration (Default: yes) (bool) |
ib_ipoib Parameters
|
max_nonsrq_conn_qp |
Max number of connected-mode QPs per interface (applied only if shared receive queue is not available) (int) |
|
mcast_debug_level |
Enable multicast debug tracing if > 0 (int) |
|
send_queue_size |
Number of descriptors in send queue (int) |
|
recv_queue_size |
Number of descriptors in receive queue (int) |
|
debug_level |
Enable debug tracing if > 0 (int) |
|
ipoib_enhanced |
Enable IPoIB enhanced for capable devices (default = 1) (0-1) (int) |
Normally, an application needs to query the device capabilities before attempting to create a resource. It is essential for the application to be able to operate over different devices with different capabilities.
Specifically, when creating a QP, the user needs to specify the maximum number of outstanding work requests that the QP supports. This value should not exceed the queried capabilities. However, even when you specify a number that does not exceed the queried capability, the verbs can still fail since some other factors such as the number of scatter/gather entries requested, or the size of the inline data required, affect the maximum possible work requests. Hence an application should try to decrease this size (halving is a good new value) and retry until it succeeds.