Using AIPerf to Benchmark#
NVIDIA AIPerf is a client-side generative AI benchmarking tool, providing key metrics such as TTFT, ITL, TPS, RPS and more. It supports any LLM inference service conforming to the OpenAI API specification, a widely accepted de facto standard in the industry. This section includes a step-by-step walkthrough, using AIPerf to benchmark a Llama-3 model inference engine, powered by NVIDIA NIM.
Step 1. Setting Up an OpenAI-Compatible LLama-3 Inference Service with NVIDIA NIM#
NVIDIA NIM provides the easiest and quickest way to put a LLM into production. See the NIM LLM documentation to get started, beginning with hardware requirements, and setting your NVIDIA NGC API keys.
For convenience, the following commands have been provided for deploying NIM and executing inference from the Getting Started Guide:
## Set Environment Variables
export NGC_API_KEY=<value>
# Choose a container name for bookkeeping
export CONTAINER_NAME=llama3-8b-instruct
# Set the repository from the registry output (for example, nim/meta/llama-3.1-8b-instruct)
export REPOSITORY=nim/meta/llama-3.1-8b-instruct
# Set the tag to latest or a specific version (for example, 1.13.1)
export TAG=latest
# Choose a LLM NIM Image from NGC
export IMG_NAME="nvcr.io/${REPOSITORY}:${TAG}"
# Choose a path on your system to cache the downloaded models
export LOCAL_NIM_CACHE=~/.cache/nim
mkdir -p "$LOCAL_NIM_CACHE"
# Start the LLM NIM
docker run -it --rm --name=$CONTAINER_NAME \
--runtime=nvidia \
--gpus all \
--shm-size=16GB \
-e NGC_API_KEY \
-v "$LOCAL_NIM_CACHE:/opt/nim/.cache" \
-u $(id -u) \
-p 8000:8000 \
$IMG_NAME
This example sets up the Meta llama3-8b-instruct model and uses that name as the name of the container. The examples refer to and mount a local directory as a cache directory. During startup, the NIM container downloads the required resources and begins serving the model behind an API endpoint. The following message indicates a successful startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
Once up and running, NIM provides an OpenAI-compatible API that you can query, as shown in the following example.
# Run `pip install openai` before running this Python code
from openai import OpenAI
client = OpenAI(base_url="http://0.0.0.0:8000/v1", api_key="not-used")
prompt = "Once upon a time"
response = client.completions.create(
model="meta-llama/llama-3.1-8b-instruct",
prompt=prompt,
max_tokens=16,
stream=False
)
completion = response.choices[0].text
print(completion)
Note
In our extensive benchmarking tests, we have observed that by specifying additional Docker flags, either –security-opt seccomp=unconfined (which disables the Seccomp security profile) or –privileged (which grants the container almost all the capabilities of the host machine, including direct access to hardware, device files, and certain kernel functionalities), inference performance can be further improved, up to 5% with the NIM TensorRT-LLM v0.10.0 backend, and up to 20% with the OSS vLLM (tested on v0.4.3) or the NIM vLLM backend (tested on NIM 1.0.0). This has been verified on DGX A100 and H100 systems, but potentially broadly applicable to other GPU systems. Disabling Seccomp or using privileged mode can eliminate some of the overhead associated with containerization security measures, allowing NIM and vLLM to utilize resources more efficiently. However, while there are performance benefits, these flags should be used with utmost diligence due to the elevated security vulnerabilities. See Docker documentation for further details.
Step 2. Setting Up AIPerf and Warming Up: Benchmarking a Single Use Case#
Once the NIM LLama-3 inference service is running, you can set up a benchmarking tool. The easiest way to do this is using a pre-built docker container. We recommend starting a AIPerf container on the same server as NIM to avoid network latency, unless you specifically want to factor in the network latency as part of the measurement.
Note
Consult AIPerf documentation for a comprehensive guide for getting started.
Run the following commands to use the pre-built container.
export RELEASE="25.05" # recommend using latest releases in yy.mm format
export WORKDIR=<YOUR_GENAI_PERF_WORKING_DIRECTORY>
docker run -it --net=host --gpus=all -v $WORKDIR:/workdir nvcr.io/nvidia/tritonserver:${RELEASE}-py3-sdk
Once inside the container, you first install AIperf with:
pip install aiperf
Note
This test will use the llama-3 tokenizer from HuggingFace, which is a guarded repository. You will need to apply for access, then login with your HF credential.
pip install huggingface_hub
huggingface-cli login
After that, you can start the AIPerf evaluation harness as follows, which runs a warming load test on the NIM backend.
export INPUT_SEQUENCE_LENGTH=200
export INPUT_SEQUENCE_STD=10
export OUTPUT_SEQUENCE_LENGTH=200
export CONCURRENCY=10
export REQUEST_COUNT=$(($CONCURRENCY * 3))
export MODEL=meta-llama/llama-3.1-8b-instruct
cd /workdir
aiperf profile \
-m $MODEL \
--endpoint-type chat \
--streaming \
-u localhost:8000 \
--synthetic-input-tokens-mean $INPUT_SEQUENCE_LENGTH \
--synthetic-input-tokens-stddev $INPUT_SEQUENCE_STD \
--concurrency $CONCURRENCY \
--request-count $REQUEST_COUNT \
--output-tokens-mean $OUTPUT_SEQUENCE_LENGTH \
--extra-inputs min_tokens:$OUTPUT_SEQUENCE_LENGTH \
--extra-inputs ignore_eos:true \
--tokenizer meta-llama/llama-3.1-8b-instruct \
--profile-export-file ${INPUT_SEQUENCE_LENGTH}_${OUTPUT_SEQUENCE_LENGTH}.json
This example specifies the input and output sequence length and a concurrency to test. It also tells the backend to ignore the special “EOS” tokens, so that the output reaches the intended length.
Note
See AIPerf documentation for the full set of options and parameters.
Upon successful execution, you should see the results similar to the following in the terminal:
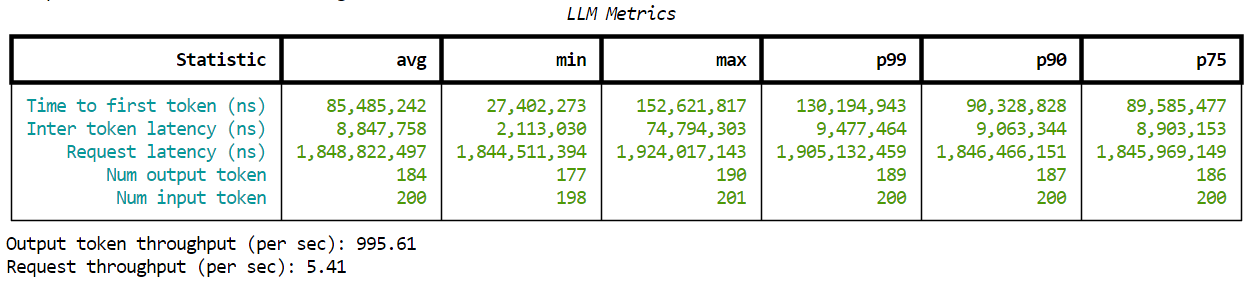
Figure 6. Sample output by AIPerf.#
Step 3. Sweeping through a Number of Use Cases#
Typically with benchmarking, a test would be set up to sweep over a number of use cases, such as input/output length combinations, and load scenarios, such as different concurrency values. Use the following bash script to define the parameters so that AIPerf executes through all the combinations.
Note
Before doing a benchmarking sweep, it is recommended to run a warming-up test. In our case, this was performed in Step 3 previously.
declare -A useCases
# Populate the array with use case descriptions and their specified input/output lengths
useCases["Translation"]="200/200"
useCases["Text classification"]="200/5"
useCases["Text summary"]="1000/200"
# Function to execute AIPerf with the input/output lengths as arguments
runBenchmark() {
local description="$1"
local lengths="${useCases[$description]}"
IFS='/' read -r inputLength outputLength <<< "$lengths"
echo "Running AIPerf for $description with input length $inputLength and output length $outputLength"
#Runs
for concurrency in 1 2 5 10 50 100 250; do
local INPUT_SEQUENCE_LENGTH=$inputLength
local INPUT_SEQUENCE_STD=0
local OUTPUT_SEQUENCE_LENGTH=$outputLength
local CONCURRENCY=$concurrency
local REQUEST_COUNT=$(($CONCURRENCY * 3))
local MODEL=meta-llama/llama-3.1-8b-instruct
aiperf profile \
-m $MODEL \
--endpoint-type chat \
--streaming \
-u localhost:8000 \
--synthetic-input-tokens-mean $INPUT_SEQUENCE_LENGTH \
--synthetic-input-tokens-stddev $INPUT_SEQUENCE_STD \
--concurrency $CONCURRENCY \
--request-count $REQUEST_COUNT \
--output-tokens-mean $OUTPUT_SEQUENCE_LENGTH \
--extra-inputs min_tokens:$OUTPUT_SEQUENCE_LENGTH \
--extra-inputs ignore_eos:true \
--tokenizer meta-llama/llama-3.1-8b-instruct \
--artifact-dir artifact/ISL${INPUT_SEQUENCE_LENGTH}_OSL${OUTPUT_SEQUENCE_LENGTH}/CON${CONCURRENCY}
done
}
# Iterate over all defined use cases and run the benchmark script for each
for description in "${!useCases[@]}"; do
runBenchmark "$description"
done
Save this script in a working directory, such as under /workdir/benchmark.sh. You can then execute it with the following command.
cd /workdir
bash benchmark.sh
Note
The “–request-count” parameter specifies the number of requests for the measurement, which we set to 3x the concurrency level to obtain a stable measurement. However, high concurrency on a large model with a large ISL/OSL scenario can result in a significantly longer benchmarking time.
Step 4. Analyzing the Output#
When the tests are complete, AIPerf generates the structured outputs in a directory named “artifact” under your mounted working directory (/workdir in these examples), organized by input/output length and concurrency. Your results should resemble the following.
/workdir/artifacts
└── ISL200_OSL200
├── CON1
│ ├── logs
│ │ └── aiperf.log
│ ├── profile_export_aiperf.csv
│ └── profile_export_aiperf.json
├── CON10
│ ├── logs
│ │ └── aiperf.log
│ ├── profile_export_aiperf.csv
│ └── profile_export_aiperf.json
├── CON100
│ ├── logs
│ │ └── aiperf.log
│ ├── profile_export_aiperf.csv
│ └── profile_export_aiperf.json
├── CON2
│ ├── logs
│ │ └── aiperf.log
│ ├── profile_export_aiperf.csv
│ └── profile_export_aiperf.json
…
The “profile_export_aiperf.json” files contain the main benchmarking results. Using the following Python code snippet to parse a file for a given use case into a JSON object.
import json
with open('artifact/ISL200_OSL5/CON1/profile_export_aiperf.json', 'r') as f:
data = json.load(f)
You can also read all the tokens-per-second and TTFT metrics across all concurrencies for a given use cases using the following Python script.
import os
ISL = 200
OSL = 5
concurrencies = [1, 2, 5, 10, 50, 100, 250]
TPS = []
TTFT = []
for con in concurrencies:
with open(f'artifact/ISL{ISL}_OSL{OSL}/CON{con}/profile_export_aiperf.json', 'r') as f:
data = json.load(f)
TPS.append(data['records']['output_token_throughput']['avg'])
TTFT.append(data['records']['ttft']['avg'])
Finally, we can plot and analyze the latency-throughput curve using the collected data with the code below. Here, each data point corresponds to a concurrency value.
import matplotlib.pyplot as plt
# Assuming TTFT, TPS, and concurrencies are defined lists or arrays
# (e.g., TTFT = [0.5, 1.2, 2.0], TPS = [100, 80, 50], concurrencies = [1, 2, 4])
# Create the figure and axes
plt.figure()
# Plot the line
plt.plot(TTFT, TPS, marker='o') # 'marker' helps see the points
# Add the text labels (equivalent to 'text=concurrencies')
if 'concurrencies' in locals() and concurrencies is not None:
for i in range(len(TTFT)):
plt.text(TTFT[i], TPS[i], str(concurrencies[i]),
ha='center', va='bottom', fontsize=9) # Adjust ha/va/fontsize as needed
# Set axis labels (equivalent to update_layout)
plt.xlabel("Single User: time to first token(s)")
plt.ylabel("Total System: tokens/s")
# Add a grid (Plotly usually has one by default)
plt.grid(True)
# Display the plot (equivalent to fig.show())
plt.show()
The resulting plot using AIPerf measurement data looks like the following.
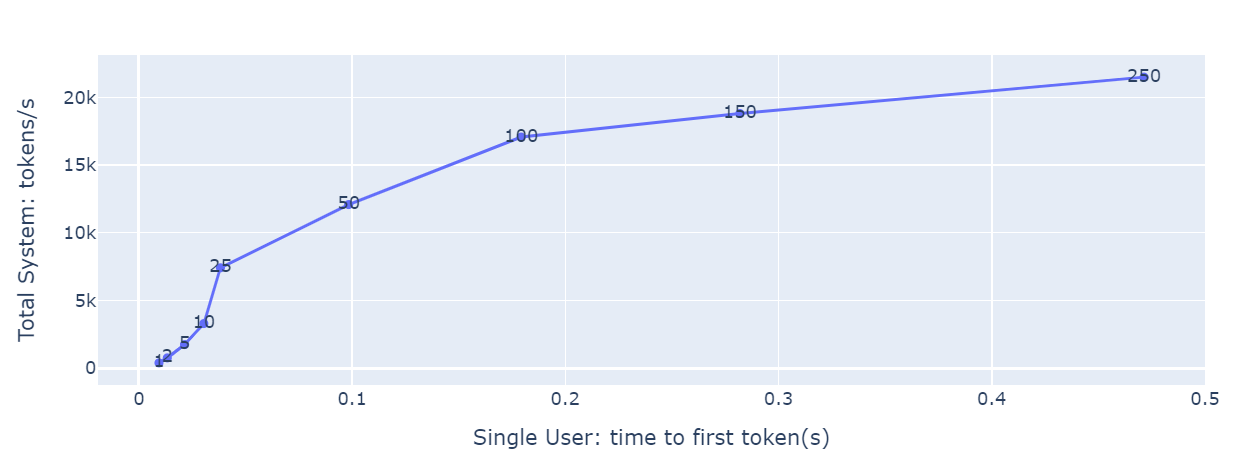
Figure 7: Latency-throughput curve plot using data generated by AIPerf.#
Step 5. Interpreting the Results#
The previous plot shows TTFT on the x-axis, total system throughput on the y-axis, and concurrencies on each dot. There are two ways to use the plot:
An LLM application owner who has the latency budget, where the maximum TTFT that is acceptable, uses that value for x, and looks for the matching y value and the concurrencies. That shows the highest throughput that can be achieved with that latency limit and corresponding concurrency value.
An LLM application owner can use the concurrency values to locate the dot on the graph. The x and y values that match show the latency and throughput for that concurrency level.
The plot also shows the concurrencies where latency grows quickly with little or no throughput gain. For example, in the plot above, concurrency=100 is one such value.
Similar plots can use ITL, e2e_latency, or TPS_per_user as X-axis, showing the trade-off between total system throughput and individual user latency.