Overview of NVIDIA NIM for Object Detection#
NVIDIA NeMo™ Retriever NIM APIs provide easy access to state-of-the-art models designed to be core building blocks for enterprise semantic search applications – delivering accuracy, scalability, and real-time information retrieval. These NIM microservices enable developers to build powerful AI-driven extraction and retrieval pipelines that parse, process and connect multimodal data to generative applications. Built on the NVIDIA software platform, NeMo Retriever NIM microservices leverage NVIDIA® CUDA®, NVIDIA TensorRT™ and NVIDIA Triton™ Inference Server for out-of-the-box GPU acceleration, optimizing performance for large-scale AI workloads.
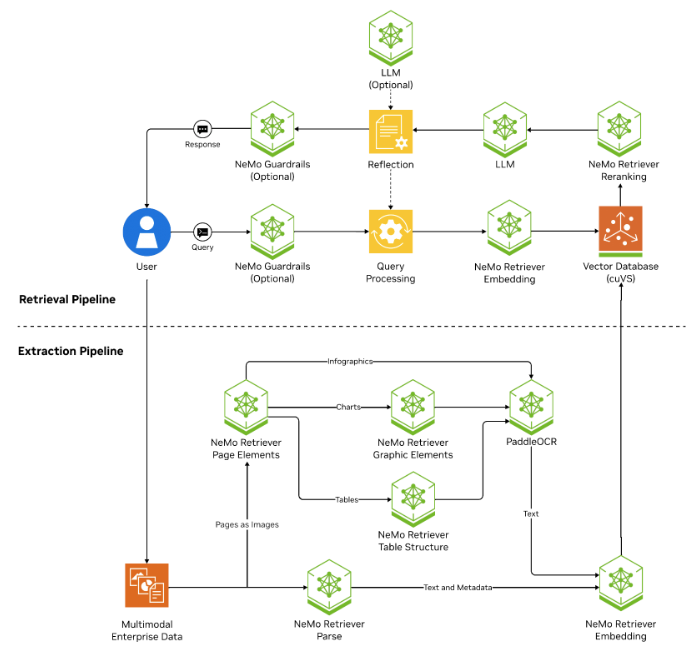
NeMo Retriever includes NIM microservices for creating advanced large-scale, multimodal extraction and retrieval pipelines, which is critical for generative AI applications like retrieval-augmented generation (RAG).
Extraction pipelines retrieve documents from external sources beyond the foundational model’s scope. NeMo Retriever microservices handle large-scale multimodal documents, detecting, contextualizing, and extracting content from text, tables, charts, and infographics.
The Object Detection NIM orchestrates this with the following three microservices:
NVIDIA NIM for page elements- Identifies charts, tables & infographics within an enterprise document. The NIM accepts a page as input and outputs detected charts, tables, and infographics with bounding box coordinates.
NVIDIA NIM for table structure - Preserves the structure of table figures for high retrieval and answer generation accuracy. The NIM accepts an image of a table and outputs the bounding boxes of the rows, columns, and the individual cells, assisting with converting the table to Markdown format. All content within the cells are extracted with the Image OCR NIM.
NVIDIA NIM for graphic elements- Detects components within a chart, such as titles, legends, axes, and more. The NIM accepts an image of a chart as input and outputs the bounding boxes of the detected elements. All content within the detected elements are extracted with the Image OCR NIM.
The retrieval pipeline fetches relevant document data and generates responses during inference. The following NeMo Retriever microservices provide superior natural language processing and understanding, boosting retrieval performance.
NeMo Retriever Embedding NIM - Boosts question-answering retrieval performance, providing high quality embeddings for many downstream NLP tasks.
NeMo Retriever Reranking NIM - Enhances the retrieval performance further with a fine-tuned reranking model, finding the most relevant passages to provide as context when querying an LLM.
The following diagram shows how NeMo Retriever NIM microservices are used to create advanced extraction and retrieval pipelines for a question-answering RAG application in enterprise settings.