Overview of NVIDIA NeMo Retriever Embedding NIM#
The NVIDIA NeMo Retriever Embedding API provides easy access to state-of-the-art models that are foundational building blocks for enterprise semantic search applications, delivering accurate answers quickly at scale. Developers can use these APIs to create robust copilots, chatbots, and AI assistants from start to finish. NeMo Retriever Embedding models are built on the NVIDIA software platform, incorporating CUDA to offer out-of-the-box GPU acceleration.
The following NeMo Retriever microservices provide superior natural language processing and understanding, boosting retrieval performance:
NeMo Retriever Embedding NIM - Boosts question-answering retrieval performance, providing high-quality embeddings for many downstream NLP tasks.
NeMo Retriever Reranking NIM - Enhances the retrieval performance further with a fine-tuned reranker, finding the most relevant passages to provide as context when querying an LLM.
The following diagram shows how the NeMo Retriever Embedding API can help a question-answering RAG application find the most relevant data in an enterprise setting.
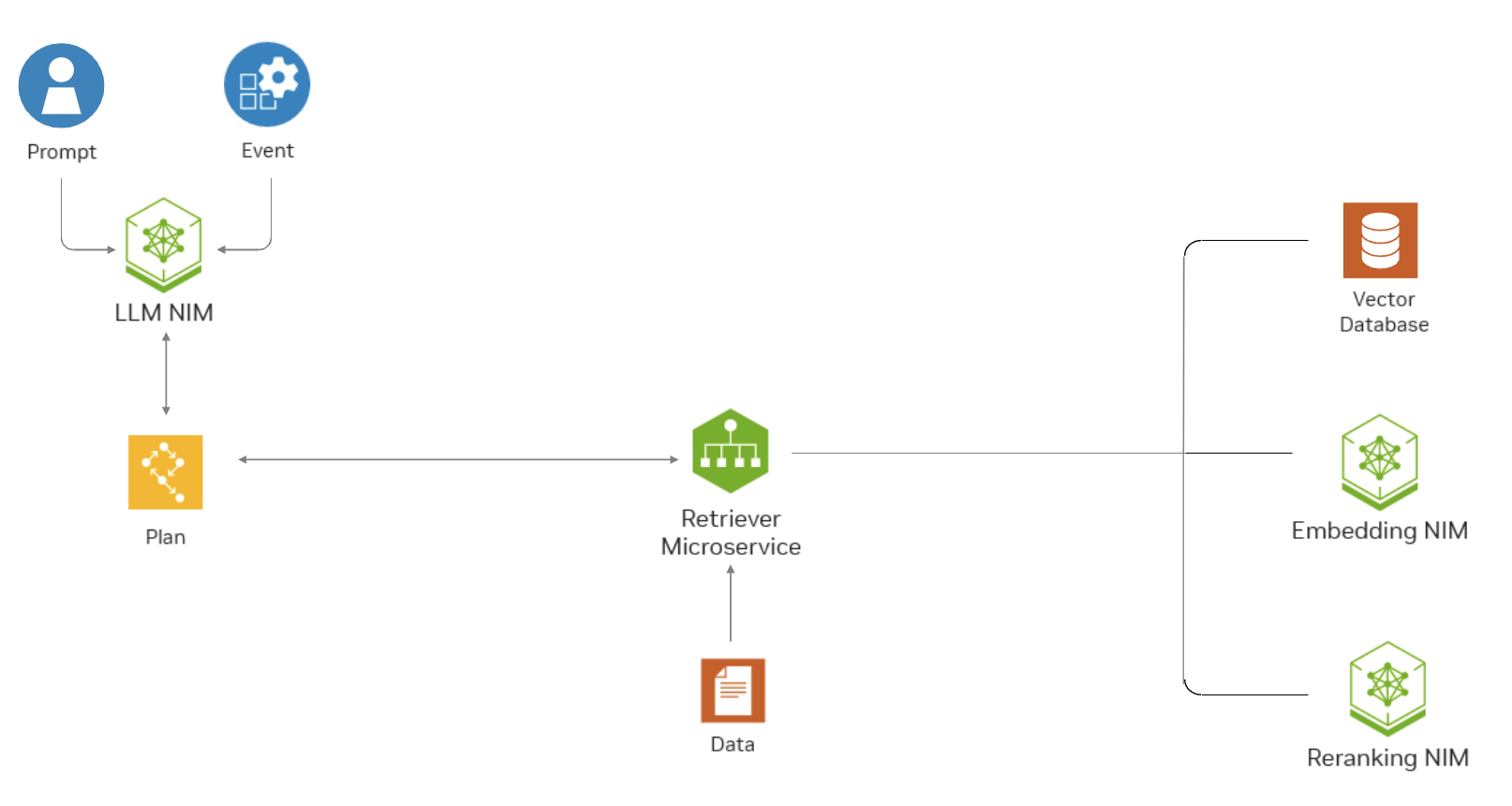
NeMo Retriever Embedding NIM#
NVIDIA NeMo Retriever Embedding NIM (Embedding NIM) brings the power of state-of-the-art text and image embedding models to your applications, offering unparalleled natural language processing and understanding capabilities. You can use the Embedding NIM for semantic search, Retrieval Augmented Generation (RAG), or any application that uses embeddings. The Embedding NIM is built on the NVIDIA software platform, incorporating CUDA to offer out-of-the-box GPU acceleration.
Architecture#
Each NeMo Retriever Embedding NIM packages an embedding model, such as nvidia/llama-nemotron-embed-vl-1b-v2, into a Docker container image. All NeMo Retriever Embedding NIM Docker containers expose an API compatible with OpenAI’s API standard.
For a full list of supported models, see Supported Models.
Custom Model Artifacts#
Model artifacts typically consist of a framework, architecture, and weights. As long as the framework and architecture match a supported model, you can use your own custom weights.
NeMo Retriever Embedding NIM supports custom model artifacts for the models listed in Support Matrix.
To use pre-downloaded model artifacts,
stage a Hugging Face-style safetensors model directory on the host
and set NIM_MODEL_PATH to the in-container path for that directory.
For details, refer to Custom Model Artifact Support in NVIDIA NeMo Retriever Embedding NIM.
Enterprise-Ready Features#
The Embedding NIM comes with enterprise-ready features, such as a high-performance inference server, flexible integration, and enterprise-grade security.
High Performance - The Embedding NIM is optimized for high-performance deep learning inference on NVIDIA GPUs.
Scalable Deployment - The Embedding NIM seamlessly scales from a few users to millions.
Flexible Integration - The Embedding NIM can be easily incorporated into existing data pipelines and applications. Developers are provided with an OpenAI-compatible API in addition to custom NVIDIA extensions.
Enterprise-Grade Security - The Embedding NIM comes with security features such as the use of safetensors, continuous patching of CVEs, and constant monitoring with our internal penetration tests.
Applications#
Retrieval Augmented Generation#
In a Retrieval Augmented Generation (RAG) application, we use the embedding model to encode the knowledge base (offline) and user question (online) into contextual embeddings, so that the LLM can retrieve the most relevant context and provide the users with the correct answers. We need high quality embeddings model to ensure high relevancy of the retrieved context.
1. Encoding the knowledge base (offline): Given a knowledge base containing documents in text, images, PDF, HTML, or other formats, we first split the knowledge base into chunks, then encode each chunk into a dense vector representation, also called embedding, using an embedding model. The resulting embeddings, along with their corresponding documents and other metadata, are saved in a vector database. The diagram below illustrates the knowledge base encoding process.

2. Deployment (online): Once deployed, the RAG application can access the vector database and answer questions in real time. To answer a user question, the RAG application first finds relevant chunks from the vector database, then it uses the retrieved chunks as context to generate a response.
Phase 1: Retrieval from the vector database based on the user’s query
The user’s query is first embedded as a dense vector using the embedding model. Then the query embedding is used to search the vector database for the most relevant document chunks with respect to the user’s query. The diagram below illustrates the retrieval process.

Phase 2: Use an LLM to generate a response leveraging the retrieved context
The most relevant chunks are joined to form the context for the user query. The LLM combines the context and the user query to generate a response. The diagram below illustrates the response generation process.

Text and Image Embeddings for Classification and Clustering#
Embeddings can be used for text and image classification tasks, such as sentiment analysis and topic categorization. They can also be used for clustering tasks, such as topic discovery and recommender systems. A high-quality embedding model improves the performance of these tasks by capturing the contextual information in the dense vector representation.
Custom Applications#
The NeMo Retriever Embedding NIM API is designed to be versatile. Developers can leverage the text and image embeddings for a variety of applications based on their specific use cases, experiment and integrate the API seamlessly into their projects.