Overview of NVIDIA NIM for Large Language Models (LLMs)#
NVIDIA NIM is a set of easy-to-use microservices designed to accelerate the deployment of generative AI models across the cloud, data center, and workstations. For example, NVIDIA NIM for Large Language Models (LLMs) brings the power of state-of-the-art LLMs to enterprise applications, providing unmatched natural language processing and understanding capabilities.
NIM makes it easy for IT and DevOps teams to self-host large language models (LLMs) in their own managed environments while still providing developers with industry standard APIs that allow them to build powerful copilots, chatbots, and AI assistants that can transform their business. Leveraging NVIDIA’s cutting-edge GPU acceleration and scalable deployment, NIM offers the fastest path to inference with unparalleled performance.
NIM Options#
Whether your priority is achieving top performance with a specific LLM or having the versatility to run many different models, NIM simplifies self-hosting in secure enterprise settings. NVIDIA NIM for Large Language Models (LLMs) is available in two options:
Multi-LLM compatible NIM: A single container that enables the deployment of a broad range of models, offering maximum flexibility.
LLM-specific NIM: Each container is focused on individual models or model families, offering maximum performance.
Which NIM Option Should I Use?#
NIM Container Option |
Multi-LLM NIM container |
LLM-specific NIM container |
|---|---|---|
Recommended For |
When NVIDIA does not yet offer an LLM-specific container for the model you want to deploy (see supported LLM families here) for multi-LLM compatible NIM deployment. |
When NVIDIA offers an LLM-specific container for the model you want to deploy (see list of those here) |
Performance |
Offers good baseline performance with the flexibility to build optimized engines on-the-fly for higher throughput on supported models. |
Provides pre-built, optimized engines for specific model/GPU combinations, delivering maximum performance out-of-the-box for supported configurations. |
Flexibility |
Maximum flexibility. Supports a broad range of models, formats, and quantization types from various sources (NGC, HuggingFace, local disk). |
Limited to a single model per container. |
Security |
You are responsible for verifying the safety and integrity of models sourced from non-NVIDIA locations. |
NVIDIA curates, security-scans, and provides both models and containers. |
Support |
NVIDIA AI Enterprise provides support for the NIM container. Support for the model itself may vary; see model support details. |
NVIDIA AI Enterprise provides support for the NIM container. Support for the model itself may vary; see model support details. |
High Performance Features#
NIM abstracts away model inference internals such as execution engine and runtime operations. They are also the most performant option available whether it be with TRT-LLM, vLLM or others. NIM offers the following high performance features:
Scalable Deployment that is performant and can easily and seamlessly scale from a few users to millions.
Advanced Language Model support with pre-generated optimized engines for a diverse range of cutting edge LLM architectures.
Flexible Integration to easily incorporate the microservice into existing workflows and applications. Developers are provided with an OpenAI API compatible programming model and custom NVIDIA extensions for additional functionality.
Enterprise-Grade Security emphasizes security by using safetensors, constantly monitoring and patching CVEs in our stack and conducting internal penetration tests.
Applications#
Chatbots & Virtual Assistants: Empower bots with human-like language understanding and responsiveness.
Content Generation & Summarization: Generate high-quality content or distill lengthy articles into concise summaries with ease.
Sentiment Analysis: Understand user sentiments in real-time, driving better business decisions.
Language Translation: Break language barriers with efficient and accurate translation services.
And many more… The potential applications of NIM are vast, spanning across various industries and use-cases.
Architecture#
Multi-LLM NIM#
The LLM NIM container is designed to support a broad range of model architectures. It includes a runtime that can operate on any NVIDIA GPU with enough memory, with certain model and GPU combinations offering additional optimizations.
You can download this NIM as an NGC container image through the NVIDIA NGC Catalog. Models for use with the container can be sourced from NGC, HuggingFace, or your local disk, giving you flexibility in how you deploy and manage models.
Warning
NVIDIA cannot guarantee the security of any models hosted on non-NVIDIA systems such as HuggingFace. Malicious or insecure models can result in serious security risks up to and including full remote code execution. We strongly recommend that before attempting to load it, you manually verify the safety of any model not provided by NVIDIA, through such mechanisms as a) ensuring that the model weights are serialized using the safetensors format, b) conducting a manual review of any model or inference code to ensure that it is free of obfuscated or malicious code, and c) validating the signature of the model, if available, to ensure that it comes from a trusted source and has not been modified.
LLM-specific NIM#
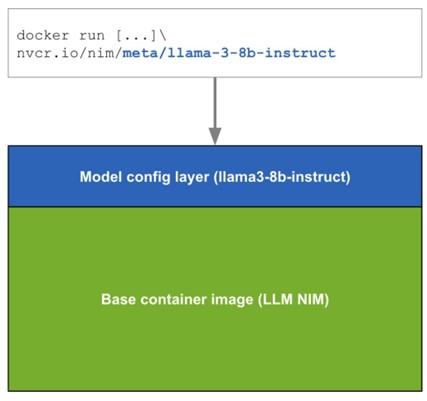
These NIMs are packaged as container images on a per model/model family basis. Each NIM is its own Docker container with a model, such as meta/llama3-8b-instruct. NIMs include a runtime that runs on any NVIDIA GPU with sufficient GPU memory, but some model/GPU combinations are optimized.
LLM-specific NIMs automatically download the model from NGC, leveraging a local filesystem cache if available. Each NIM is built from a common base, so once a NIM has been downloaded, downloading additional NIMs is extremely fast.
When a NIM is first deployed, NIM inspects the local hardware configuration, and the available optimized model in the model registry, and then automatically chooses the best version of the model for the available hardware. For a subset of NVIDIA GPUs (see Supported Models for NVIDIA NIM for LLMs), NIM downloads the optimized TRT engine and runs an inference using the TRT-LLM library. For all other NVIDIA GPUs, NIM downloads a non-optimized model and runs it using the vLLM library.
NIMs are distributed as NGC container images through the NVIDIA NGC Catalog. A security scan report is available for each container within the NGC catalog, which provides a security rating of that image, breakdown of CVE severity by package, and links to detailed information on CVEs.
LLM-specific NIM Deployment Lifecycle#
The NVIDIA Developer Program#
Want to learn more about NIMs? Join the NVIDIA Developer Program to get free access to self-hosting NVIDIA NIMs and microservices on up to 16 GPUs on any infrastructure-cloud, data center, or personal workstation.
Once you join the free NVIDIA Developer Program and access NIMs through the NVIDIA API Catalog at any time. For enterprise-grade security, support, and API stability, select the option to access NIM through our free 90-day NVIDIA AI Enterprise Trial with a business email address.
See the NVIDIA NIM FAQ for additional information.