Developer Guide
NVIDIA NvNeural SDK Developer Guide.
Introduction and technical details for the NVIDIA NvNeural inference SDK.
Introduction
NvNeural is the inference framework underlying the NVIDIA Nsight Deep Learning Designer product. Built using CUDA and modern C++, it provides efficient inference for convolutional neural networks. Debugging and experimentation are aided by native support for runtime modification and analysis. For scenarios not already supported by the framework, NvNeural provides an extensible object model and stable plugin ABI for defining new inference operations with full tooling support. The framework is guided by four main principles:
-
Flexibility: Layers are designed to adjust output dimensions as required at runtime, without rebuilding the network or reloading weights when conditions change. Many network designs can support arbitrary input sizes, allowing a single network to process video at resolutions ranging from QVGA to 4K. Intrinsic support for custom layers allows rapid edit/debug/profile cycles when designing CUDA inference kernels.
-
Expandability: Common integration points such as weights loaders and input layers can be completely replaced in client applications to fit the problem domain. The development environment was designed with a plugin-first approach, ensuring native support for custom layers and activation functions inside the NVIDIA Nsight Deep Learning Designer user interface. While the framework currently focuses on CUDA-based inference in fp32/NCHW and fp16/NHWC tensor configurations, NvNeural adapts automatically to layers implementing a tensor format that differs from the network default.
-
Compatibility: The NvNeural framework uses a version-safe subset of C++ that is largely toolchain-agnostic. Minor updates to local C++ compilers, CUDA Toolkit revisions, and other build tools do not cause ABI incompatibilities. SDK versioning strives to allow code written against one release of the framework to work unaltered with a subsequent release.
-
Footprint reduction: Individual layer plugins, not framework code, own large dependencies such as numerical solver libraries; the core class libraries depend only on NvRTC, the C++ runtime library, and the installed CUDA driver. Where possible, NVIDIA Nsight Deep Learning Designer provides layers that dynamically generate and compile their own code through NvRTC instead of relying on large precompiled kernel collections. The default device memory allocation policy reuses intermediate tensor buffers automatically to minimize memory overhead.
In this release, the NvNeural framework depends on C++14 (using GCC or Microsoft Visual C++), and targets both Linux and Windows on desktop x86-64 platforms. The build scripts packaged with the SDK use CMake 3.17 or newer.
2. System Architecture
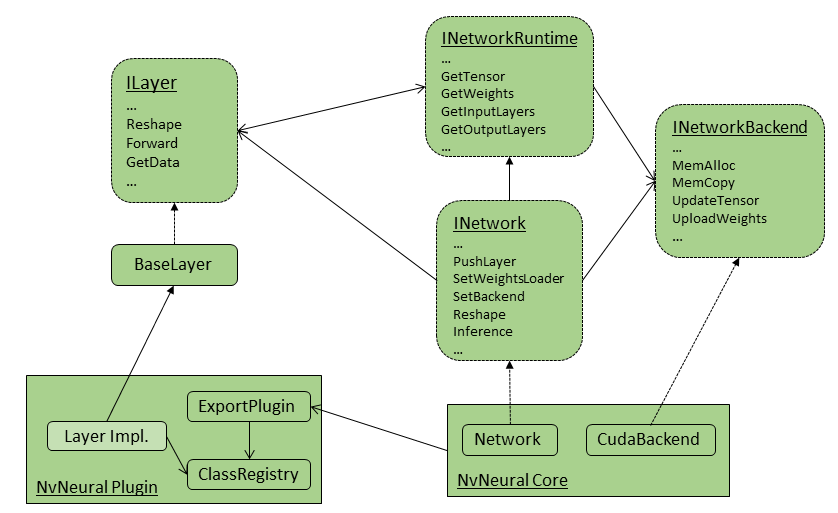
NvNeural is a reference-counted, interface-based system designed to aggregate necessary functionality across arbitrary sets of independently built and versioned plugins. There are seven major object concepts within the framework:
-
Networks are container objects that perform inference for neural networks, typically convolutional neural networks. They own references to the layer objects describing the neural network operations.
-
Backends are the interfaces between networks and GPU execution contexts. Where networks work with opaque device pointers (represented as void*), backends translate environment-agnostic operations requested by networks into specific GPU instructions. This version of NvNeural provides a CUDA backend, which additionally manages device memory through a pluggable allocator class.
-
Layers represent the fundamental operations of a neural network. Each layer object is associated with a backend and tensor format; during network construction, the builder creates the layer objects that most closely match the network's preferred tensor format. The network and backend reshape tensors automatically when layers vary in tensor format.
-
Activations are lightweight operators representing common activation functions such as leaky ReLU. Every layer object in a network may reference up to one activation. Layers may support inline activations as a performance optimizations, but layers lacking built-in support for a given activation can fall back to the generic, standalone activation objects referred to by this term.
-
Client applications are programs that consume the NvNeural framework and perform inference. The term generally refers to your own applications, but tools such as ConverenceNG are also client applications.
-
Plugins are shared libraries that export layers, activations, and other types for consumption by client applications and other modules within NvNeural. Each plugin shipped with NVIDIA Nsight Deep Learning Designer is modular and is designed to be included without additional plugin dependencies.
-
Descriptors are extensible structures exported by plugins that contain metadata about types contained within the plugin. Some descriptors are used to deserialize networks (such as from the nv-neural-model format used by the editor), and others are used to support the editing and analysis functions of NVIDIA Nsight Deep Learning Designer.
Not all classes within the framework are version-stable reference-counted objects deriving from IRefObject. Many utility classes are designed to be helper classes that take advantage of ABI-unstable language features in order to simplify code. Such classes are either short-lived (typically allocated with automatic storage duration and destroyed when leaving scope) or interact with other scopes via a public interface. Definitions inside *Helpers.h headers (rather than *Types.h headers) are always considered to be unversioned.
Threading policy: Unless otherwise stated, objects in NvNeural are single-threaded but thread-agnostic. Reference-counting methods on the IRefObject interface should use atomic integer operations to prevent race conditions when calling addRef, queryInterface, or release. You should not assume that a single object instance supports concurrent operation from multiple threads.
Supported formats: This release of NVIDIA Nsight Deep Learning Designer supports the CUDA backend with these tensor formats:
-
FP16 data, NHWC layout
-
FP32 data, NCHW layout
-
FP16 data, NCHW layout
-
FP32 data, NHWC layout
2.1. Interface-Based Programming
NvNeural expresses ownership using a shared reference-counted model similar to std::shared_ptr, but using slightly different and more toolchain-independent abstractions similar to Microsoft's Component Object Model architecture. In particular, NvNeural adopts COM's self-cleanup approach for object deletion to ensure all objects are deleted using the C++ runtime libraries used to create them.
Objects are referenced within NvNeural applications and plugins using opaque interface pointers rather than concrete class names. A tenet of the framework design is that interfaces are objects. Module boundaries should only be crossed using interface pointers, never class names, and the extension points of most core classes are designed to support cross-module calls. This results in a number of design conventions for object interfaces:
-
Run-time type identification (for example, dynamic_cast) is not reliable across shared library boundaries on many platforms. All casting operations within the framework use queryInterface instead of RTTI.
-
Container types provided by the C++ standard library, especially std::string and std::vector are not ABI-stable and are thus ineligible for public interfaces. Interface types prefer C-style arrays or, for extremely common data structures, custom container types such as ILayerList or IStringList.
-
Exceptions may not cross module boundaries. All public interfaces make extensive use of noexcept to enforce this.
Tip:When an exception would propagate across a noexcept boundary, the C++ compiler calls std::terminate instead of invoking object destructors and continuing unwinding. If your profiling run or NvNeural inference application terminates abruptly with no apparent error messages, this can be a symptom of a noexcept violation.
-
Interfaces are never modified once shipped, only extended with new interfaces. This prevents accidentally modifying the object vtable in a backwards-incompatible fashion. Versioned structures carry a size prefix (generally named structSize and set to the sizeof() the struct) for forward compatibility.
2.2. IRefObject Overview
The fundamental interface type implemented by all shared objects in NvNeural is called IRefObject. It provides the reference counting and RTTI abilities that most other objects depend on.
Creation of an IRefObject typically follows one of two paths: either direct construction with a concrete type name, or indirect construction using IClassRegistry::createObject. Use direct construction when creating internal helper objects, especially those you intend to return to outside code. The make_refobject template simplifies the creation of objects intended to be accessed via RefPtr:
const RefPtr<IMyObject> pMyObject = make_refobject<MyConcreteObject>(constructor_args, ...).as<IMyObject>();
Destruction of an IRefObject occurs automatically when the final reference to the object is released. Internally this is implemented as delete this; when the reference count reaches zero.
Reference tracking is performed with the addRef and release methods.
Conversion between interfaces is done with the queryInterface method. Every interface in NvNeural is associated with a unique, non-signifying, randomly generated 64-bit interface identifier. Use the makeiid program shipped with NVIDIA Nsight Deep Learning Designer or a suitably strong pseudorandom number generator to create new interface identifiers.
Successful calls to queryInterface increment the object's reference count. This can lead to memory leaks if these references are not cleaned up. Use the RefPtr<T>::as<U>() wrapper instead so that the resulting reference is disposed of automatically.
-
Objects must not dynamically add or remove interfaces after construction. Callers may cache the result of a queryInterface call.
-
Queries for a particular interface must always return the same pointer.
-
Queries must be symmetric: if querying ITwo from an instance of IOne is successful, querying for IOne from the previously returned instance of ITwo must succeed and return the original object.
-
Queries must be transitive: if querying IOne => ITwo => IThree is successful, querying for IThree directly from IOne must return the same result.
2.3. RefPtr Overview
The standard smart pointer class used by NvNeural is called RefPtr. It is a templated class that can represent any interface deriving from IRefObject. The type is defined inside the nvneural/RefPtr.h header, and the framework makes extensive use of RefPtr in its own code.
RefPtr objects are designed to be constructible from normal C pointers and make nonstandard reference operations explicit in the calling code. They always represent an owning object reference (even if the object is nullptr) and release the reference when destroyed. There are seven ways to create RefPtr objects:
-
Default-constructed RefPtr objects point to nullptr.
-
Copy-construction of RefPtr increments the reference count of the object pointed to.
-
Move-construction of RefPtr transfers the reference to the new pointer, resets the old pointer to nullptr, and does not involve explicit calls to the IRefObject reference-manipulation functions.
-
Pointers to new objects should be created with make_refobject as described in the previous section. This template forwards its arguments to the object constructor and returns a RefPtr<IRefObject> that can then be converted to a more derived type.
-
Object methods that increment the reference count of a returned object through an output pointer are supported with the put helper. By convention, NvNeural methods always use output pointers when returning strong references to objects:
RefPtr<IThing> pThing; pOtherObject->createThing(pThing.put());
-
To create a long-lived reference to an object previously accessed through C-style pointers, use RefPtr::fromPointer. This calls addRef on the object (if not null). This approach should be used when the result of a lightweight query function (which normally passes a weak reference as its return value) will be saved for later.
-
If for some reason you wish to use RefPtr to take over an existing object reference without adding a new one, use fromPointerNoAddRef. This is not recommended as a general pattern due to the ease of mismatching reference counts. Use detach to disconnect a reference from a RefPtr without releasing it.
RefPtr objects support the normal set of C++ overloaded operators: operator ->, explicit operator bool, and operator == and operator != for equality testing.
Transforming a RefPtr object to a C pointer uses the get method. Use this to pass RefPtr-controlled objects through public interfaces. There is no implicit conversion to the underlying pointer type.
RefPtr<IThing> pThing;
const RefPtr<IOther> pOther = pThing.as<IOther>();
if (const auto pThird = pThing.as<IThirdThing>()) {
pThird->performOperation(...);
}The mapping from C++ type names (such as IRefObject) to interface identifiers (such as 0x14ecc3f9de638e1dul) is done using the InterfaceOf<T> template. The default implementation of this template looks for a static public member named typeID in the requested type, but if providing this member is not feasible for some reason you should feel free to specialize the InterfaceOf template.
Universal adoption of RefPtr idioms can reduce the frequency of common reference-counting bugs in your code. Avoid explicit calls to addRef, queryInterface, and especially release in favor of automatic memory management with RefPtr.
2.4. RefObjectBase Overview
Manually writing each possible code path through IRefObject::queryInterface is verbose and error-prone. Similar frameworks such as COM that inspired the design of NvNeural traditionally used a combination of simple base classes to provide addRef and release, and macro magic to provide queryInterface. This framework avoids macros and uses a templated base class to implement common IRefObject functionality. This base class is called RefObjectBase, and is located in nvneural/RefObject.h.
The RefObjectBase class adapts its behavior to match traits defined in its template parameters. Each template parameter provided adds new behavior to RefObjectBase. Consider the following two interfaces:
class IThing : public IRefObject
{
public:
static const IRefObject::TypeId typeID = ...;
virtual NeuralResult doThing() noexcept = 0;
};
class IOther : public IRefObject
{
public:
static const IRefObject::TypeId typeID = ...;
virtual NeuralResult doOther() noexcept = 0;
};Implementing interfaces is done by adding Implements<T> to the template parameter list. The underlying type T is then publicly inherited by the RefObjectBase specialization and its descendant types. Example:
class MyClass : public RefObjectBase<Implements<IThing>, Implements<IOther>>
{
public:
// IThing
NeuralResult doThing() noexcept override;
// IOther
NeuralResult doOther() noexcept override;
};As you implement additional interfaces, add their Implements<T> traits to the RefObjectBase parent. What happens as interfaces are revisioned, though? Adding Implements<IThing2> will generate compile-time errors about ambiguous casts, and simply replacing Implements<IThing> with Implements<IThing2> would drop support for the older interface entirely:
class IThing2 : public IThing
{
static const IRefObject::TypeId typeID = ...;
virtual NeuralResult doThing2() noexcept = 0;
};The solution is indirect implementation. Indicate to RefObjectBase that one layer is implemented in terms of another:
class MyClass : public RefObjectBase<
Implements<IThing2>,
IndirectlyImplements<IThing, IThing2>,
Implements<IOther>>
{
public:
// IThing2
NeuralResult doThing2() noexcept override;
// IThing
NeuralResult doThing() noexcept override;
// IOther
NeuralResult doOther() noexcept override;
};The older interface is no longer directly inherited when using IndirectlyImplements<T, U>, but is instead assumed to be a base class of U. The resulting queryInterface implementation first casts to U*, then casts to T*, avoiding any ambiguity in the class hierarchy or redundant inheritance.
If direct inheritance of a base class but not its public interfaces is necessary (perhaps because you subclassed an existing concrete type), use PublicBase<T>. This is equivalent to adding public T to the parent classes of RefObjectBase and has no effect on queryInterface.
Normally lifecycle events of RefObjectBase-derived classes are logged at verbosity level 3. Every constructor, destructor, addRef, and release event can be logged, often generating a sea of data but enabling the tracing of object reference leaks. This causes unwanted recursion when the logger is itself implemented using RefObjectBase though. For such cases where you want no chance of log callbacks, add the DisableLifecycleLogging trait to the object template. This prevents the RefObjectBase instance from emitting log messages in response to reference lifecycle events.
2.5. Build Targets
The NvNeural build system uses modern CMake and its native CUDA language support. Most helper classes are defined as ALIAS library targets in the NvNeural namespace. Target names beginning with NvNeural are reserved to the framework.
While much of the code in NvNeural is shipped as binary shared libraries, many ubiquitous helper classes are shipped as source code and INTERFACE library targets to ensure compatibility with your local toolchain. Link these targets with CMake's target_link_libraries command to include their sources in your own build target.
ConverenceNG's C++ exporter (see C++ Exporter Details) generates a stub CMakeLists.txt file that points to the local copy of NvNeural installed with NVIDIA Nsight Deep Learning Designer, but this path is usually suitable for local development only. Set the NVNEURAL_SDK_PATH environment variable before running CMake or define the build script's NVNEURAL_SDK_PATH cache variable with -D to point the build system to alternate SDK paths.
Client applications need to load NvNeural plugins in order to perform inference. Use the NvNeural_InstallStandardPlugins function to define install(FILES...) rules for the plugins shipped with NVIDIA Nsight Deep Learning Designer, and be sure to build the project's install target in order to evaluate them and copy the plugins and your build targets under CMAKE_INSTALL_PREFIX.
The CMake scripts packaged in the SDK define a number of build targets, but in practice very few need to be referenced explicitly. CMake target dependencies automatically link the underlying interface targets and helper libraries. These are the most common targets used to build client applications:
|
Target |
Description |
|---|---|
NvNeural::Host |
Helpers and libraries useful for client applications, including XmlNetworkBuilder and DynamicPluginLoader. |
NvNeural::Layer |
Helpers and libraries useful for layer plugins, including BaseLayer. |
NvNeural::Plugin |
Helpers useful for all plugins, including ExportPlugin. |
NvNeural::CoreABI |
Less common. Links the fundamental NvNeural include files like nvneural/CoreTypes.h but does not provide access to ABI-unstable helper classes. |
NvNeural::Helpers |
Less common. Provides RefPtr, RefObjectBase, and other common utility code. |
In addition, the SDK provides build targets for third-party libraries consumed in the framework build targets. See NvNeuralImports.cmake for details.
3. Building Plugins
NvNeural plugins are C++ objects implementing the IPlugin interface and generally contained inside shared libraries. While it is possible to embed multiple plugins in a single module (executable or shared library) and switch between them using a custom IPluginLoader, in practice plugins are effectively synonymous with the shared libraries that package them.
All plugins shipped with NVIDIA Nsight Deep Learning Designer use ExportPlugin, a standard implementation of IPlugin that interoperates with ClassLibrary and the DefaultLogger helper function. Use of ExportPlugin is not required if you wish to provide your own implementation, and the Implementing IPlugin (Manual Approach) section provides details on what the framework expects. For simplicity, the rest of this document assumes you are using ExportPlugin and ClassRegistry.
3.1. Implementing IPlugin (Automatic Approach)
The ExportPlugin class and corresponding NvNeural::Plugin CMake target wraps all the details of creating an IPlugin object, including the shared library export. ExportPlugin exports all object classes, layer descriptors, activation descriptors, and fusing rules you register statically with ClassLibrary.
To use ExportPlugin, link your CMake shared library target privately against NvNeural::Plugin and provide definitions of the following string variables in one of your library's C++ source files:
/// Plugin "name" attribute to display in the editor and other tools. /// /// Example: "Fused Upscale Layers" extern const char* nvneural::plugin::PluginName; /// Plugin version string to display in the editor and other tools. /// /// Example: "2021.1.0" extern const char* nvneural::plugin::PluginVersion; /// Plugin authorship string to display in the editor and other tools. /// /// Example: "NVIDIA Corporation" extern const char* nvneural::plugin::PluginAuthor; /// Plugin description string to display in the editor and other tools. /// /// Example: "Lightweight convolution layer classes" extern const char* nvneural::plugin::PluginDescription; /// Registration function for initializing exported types. extern void nvneural::plugin::InitializePluginTypes() noexcept(false);
The PluginName, PluginVersion, PluginAuthor, and PluginDescription strings are human-readable text intended for display in log messages and the NVIDIA Nsight Deep Learning Designer Manage Collections dialog.
The InitializePluginTypes function provides a safe time window to call the static registration methods of ClassRegistry without running afoul of C++ static initialization order ambiguities. It takes no arguments and returns no values; unlike most functions in NvNeural, it signals error conditions by throwing exceptions. (ExportPlugin wraps the function call with std::call_once.) This is an example of one InitializePluginTypes code path:
// SamplePlugin.cpp
void RegisterLayerOne();
void RegisterLayerTwo();
void nvneural::plugin::InitializePluginTypes()
{
RegisterLayerOne();
RegisterLayerTwo();
}
// LayerOne.cu
class CudaLayerOne;
static LayerDesc GenerateLayerDescriptor(TensorDataType dataType, TensorDataLayout layout);
void RegisterLayerOne()
{
static const LayerDesc fp32_nhwc_desc = GenerateExportDescriptor(TensorDataType::Float, TensorDataLayout::Nhwc);
static const LayerDesc fp32_nchw_desc = GenerateExportDescriptor(TensorDataType::Float, TensorDataLayout::Nchw);
static const LayerDesc fp16_nhwc_desc = GenerateExportDescriptor(TensorDataType::Half, TensorDataLayout::Nhwc);
static const LayerDesc fp16_nchw_desc = GenerateExportDescriptor(TensorDataType::Half, TensorDataLayout::Nchw);
static const auto register_fp32_nhwc_desc = ClassRegistry::registerLayer<CudaLayerOne>(fp32_nhwc_desc);
static const auto register_fp32_nchw_desc = ClassRegistry::registerLayer<CudaLayerOne>(fp32_nchw_desc);
static const auto register_fp16_nhwc_desc = ClassRegistry::registerLayer<CudaLayerOne>(fp16_nhwc_desc);
static const auto register_fp16_nchw_desc = ClassRegistry::registerLayer<CudaLayerOne>(fp16_nchw_desc);
}
3.2. Implementing IPlugin (Manual Approach)
The DynamicPluginLoader class, when evaluating a shared library as a possible plugin, searches for an exported function with the following signature:
extern "C" NeuralResult NvNeuralCreatePluginV1(IPlugin** ppPluginOut) noexcept;
This function creates a new IPlugin instance and returns a reference through its output parameter.
The name of the entry point is specifically NvNeuralCreatePluginV1. When building for Windows platforms, use a module definition file (.def) to ensure the symbol is exported under that name. The Microsoft Visual C++ __declspec(dllexport) attribute performs name mangling in the absence of a definition file. If your plugin can be opened with LoadLibraryEx but DynamicPluginLoader indicates it has no plugin entry point, check the DLL's exports with DUMPBIN /EXPORTS to confirm correct export of its plugin factory function.
As a future-proofing measure, IPlugin objects are expected to implement IApiVersionQuery as well. The expected version returned by this interface is always nvneural::ApiVersion, defined in nvneural/CoreTypes.h.
IPlugin is the core class factory, introspection, and logger-sharing interface required by all plugins. Additional interfaces are used by ConverenceNG and the editing tools to retrieve the details of available layers and activation functions. Implement the ILayerPlugin and/or IActivationPlugin interfaces alongside IPlugin to provide this information. Without the corresponding interface, layers and activation functions inside the plugin can still be created with IPlugin::createObject but is invisible to tools, the client ClassRegistry object, and XmlNetworkBuilder.
3.3. Implementing ILayer
Layers are the fundamental network building block within NvNeural. Each layer represents an operator that accepts zero or more input tensors and generates an output tensor. Networks automatically order inference calls so that necessary input tensors are available before a layer is inferenced. Where unavoidable cycles exist in the inference graph (such as in recurrent neural networks), the network class picks a starting point to begin inference. The ILayer interface is described in nvneural/LayerTypes.h.
Layers are not provided direct references to INetwork objects under normal circumstances, but instead use a restricted subset of the interface called INetworkRuntime. This distinction maintains access to nondestructive queries and critical bookkeeping operations, but discourages direct modification of the network by its layers. This guide refers solely to "networks" in the interest of simplicity.
Each layer is represented by an ILayer object. The lifecycle of a layer object follows this sequence:
-
Creation: Layers are created through the class registry. Each layer type has an object class string that identifies it to the createObject methods of IClassRegistry and IPlugin.
-
Configuration: The layer object is configured using either type-specific interfaces (for example, IConvolutionLayer) or deserialization of a parameter node (IParameterNode, which frequently wraps the <Parameters> block in an XML network description).
-
Attachment: The layer is added to a network using INetwork::pushLayer. The network object establishes a reciprocal connection by calling ILayer::setNetworkRuntime. Client applications typically connect inputs to layers at this time using ILayer::setInputLayer.
-
Reshape: Once input tensor sizes for the network are known, the client application reshapes the network. The network object calls the reshape method of each layer in sequence. The layer should now allocate scratch space, configure numerical libraries, JIT-compile computation kernels, or perform other high-overhead initialization steps.
Tip:Layers can mark themselves in need of reshape with INetworkRuntime::reshapeLater. Before the next inference pass, the network will reshape any layers so queued as well as all layers depending (even indirectly) on the reshaped layers.
-
Inference: Each time the network performs an inference pass, it calls the evaluateForward method on all affected layer objects and dependent layers. During evaluateForward, the layer should retrieve pointers to input data (including weights data) and launch all inference kernels necessary to fully populate its output tensor.
-
Shutdown: When the network is unloaded it releases references to its layers. Layers should maintain weak references to outside objects so that cycles can be avoided. RefPtr<INetworkRuntime> and <INetworkBackend> are convenient class members to have, but we recommend not preserving long-lived references to other layers in order to prevent reference leaks.
Outside of the basic flow described above, layers can be interacted with by the client application outside of an inference pass to support dynamic control of their inference behavior. One example of such interactions would be an input layer receiving a new tensor through its IStandardInputLayer interface. Layers can also expose runtime options (described below) to support interactive analysis in the NVIDIA Nsight Deep Learning Designer user interface. In such cases, the layer should mark itself as affected so that a subsequent inference pass evaluates the layer and its downstream dependents.
Layers reference each others' output tensor sizes through the dimensions method. Most layers have no significant alignment requirements beyond the default CUDA guarantees. Layers with more restrictive tensor alignment requirements can return a stepping value greater than 1; the network will pad the output tensor allocation such that every dimension is a multiple of the layer's stepping factor. The post-padding tensor size can be accessed with internalDimensions. Use tensorBufferSize and tensorInternalBufferSize to retrieve these sizes as raw byte counts rather than per-element TensorDimension tuples.
Layers can have an optional activation function, attached using the setActivationFunction method. When a layer has an activation function (i.e., not ActivationFunctionId::None), it should evaluate the activation function either as part of its normal inference calculations (typically using a variant of the inference kernel) or by calling INetworkRuntime::defaultForwardActivation(this).
Fusing activations directly into layer inference kernels is more efficient than performing extra launches as defaultForwardActivation does. If you know your layer will usually be accompanied by a particular activation, consider designing support for the activation epilog directly into your layer. An example of a fused activation is shown below:
__global__ void k_Affine(const float* pInput, float* pOutput, size_t inputCount, float scale, float shift)
{
const size_t x = blockIdx.x * blockDim.x + threadIdx.x;
if (x < inputCount)
{
pOutput[x] = pInput[x] * scale + shift;
}
}
__global__ void k_Affine_LeakyReLU(const float* pInput, float* pOutput, size_t inputCount, float scale, float shift, float alpha)
{
const size_t x = blockIdx.x * blockDim.x + threadIdx.x;
if (x < inputCount)
{
float output = pInput[x] * scale + shift;
if (output < 0)
{
output = alpha * output;
}
pOutput[x] = output;
}
}3.3.1. Loading Parameters
While layers often provide type-specific configuration interfaces such as IConvolutionLayer or IShuffleLayer, tools such as ConverenceNG and the NVIDIA Nsight Deep Learning Designer editor are not able to use such interfaces. Instead, they package layer parameters into a key-value store called a parameter node and provide it to a generic configuration method, ILayer::loadFromParameters.
The layer should load its key configuration information from the parameter node object during loadFromParameters. The IParameterNode interface allows direct retrieval of floating-point, (signed and unsigned) integer, string, and TensorDimension data. More complex formats should be loaded as weights data or by external mechanisms. For example, you could store a filename or URL as a string parameter and retrieve its contents inside loadFromParameters.
When adding parameters, it is preferable to make them optional in your loadFromParameters method. This prevents compatibility problems when loading model files that predate the new parameters. Fail the load operation only when parameter values are malformed, not just missing, and try to check as many parameters as possible before giving up.
NeuralResult CudaSpaceToDepthLayer::loadFromParameters(const IParameterNode* pParameters) noexcept
{
NeuralResult status;
const char* pDominanceMode;
status = pParameters->getString("dominant", &pDominanceMode);
m_shuffleMode = ShuffleMode::PixelDominant;
if (succeeded(status))
{
if (pDominanceMode == std::string("channel"))
{
m_shuffleMode = ShuffleMode::ChannelDominant;
}
else if (pDominanceMode == std::string("pixel"))
{
m_shuffleMode = ShuffleMode::PixelDominant;
}
else
{
DefaultLogger()->logWarning(0, "%s: Unknown shuffle mode '%s'", name(), pDominanceMode);
m_shuffleMode = ShuffleMode::Invalid;
return NeuralResult::Failure;
}
}
return NeuralResult::Success;
}
3.3.2. Loading Weights
Many layers like concatenations and shuffles can be expressed purely in terms of their parameters, but the most important operations in neural networks depend on trained weights. Each network object maintains a reference to a client-application-provided weights loader that, in concert with the backend object, provides correctly formatted weights tensors to layers requiring them.
Weights data can be retrieved from the BaseLayer base class using its protected weightsData method. If not using BaseLayer, call INetworkRuntime::getWeightsForLayer. The network class handles the details of reshaping the weights to the layer's requested format and caching them for later use. Confirm the dimension of loaded weights' tensors with BaseLayer::loadedWeightsSize or INetworkRuntime::getWeightsDimensionForLayer to prevent accidental out-of-bounds memory accesses during inference.
Most layers packaged with NVIDIA Nsight Deep Learning Designer can take their weights data from other layers in addition to the system weights loader. This concept is represented in NvNeural with additional, optional input layers. By convention, these inputs are marked in layer input descriptors (described later) as LayerInputType::Secondary and take precedence over tensors returned by the weights loader. An example weights accessor using BaseLayer is shown below:
const uint32_t kInputPrimary = 0;
const uint32_t kInputKernel = 1;
CUdeviceptr SampleLayer::kernelWeightsData() const
{
if (const ILayer* const pKernelLayer = inputLayer(kInputKernel))
{
const TensorFormat format = tensorFormat();
const void* pWeightsData;
const NeuralResult status = pKernelLayer->getConstData(&pWeightsData, format, this);
if (failed(status))
{
return nullptr;
}
return (CUdeviceptr)pWeightsData;
}
else
{
return (CUdeviceptr)weightsData("kernel");
}
}
Finally, layer objects support dimension queries for weights. The ILayer::weightsDimensions method returns size hints to the caller for a particular weights tensor:
-
Queries of type WeightsQuery::Required describe the notional size of the weights tensor when represented externally. Weights loaders use this result to validate the tensors they provide to the network and to generate random weights for profiling.
-
Queries of type WeightsQuery::Aligned describe the requested internal storage size of the weights tensor. If padding along one or more axes is required for efficient inference, the layer should return the padded dimensions in response to this query. If no padding is required, the return value should be equivalent to a WeightsQuery::Required query.
-
Requests for unknown weights or query types should return a zeroed TensorDimension structure.
3.3.3. Implementing Layers with BaseLayer
Implementing the ILayer interface requires writing many getter and setter methods inside the layer object. Most of these methods are boilerplate code and do not vary significantly between layers. We provide the BaseLayer class to speed the implementation of your own layer plugins.
The BaseLayer abstract class is defined in BaseLayer.h. It does not derive from RefObjectBase, but does derive from ILayer. Add it to a RefObjectBase traits list as in the following example:
class IExampleLayer;
class MyExampleLayer : public RefObjectBase<
Implements<BaseLayer>,
IndirectlyImplements<ILayer, BaseLayer>,
Implements<IExampleLayer>>
{
...
};The BaseLayer class provides standardized implementations of most ILayer interface methods. Many methods such as internalDimensions are expressed by default in terms of other, still-virtual methods that must be implememented by the user. Others such as setActivationFunction, getCpuConstData, and setNetworkRuntime use standard algorithms.
Only the following ILayer methods must be provided by the derived class:
-
The reshape and evaluateForward methods perform the layer's actual reconfiguration and inference operations.
-
The dimensions method returns a TensorDimension describing the layer's output tensor size.
-
The serializedType method returns an identifier string describing the layer type (for example, convolution). It is needed by exporters.
-
The loadFromParameters method has a null default implementation, but most layers need custom parameter logic as described in Loading Parameters.
-
The weightsDimensions method has a null default implementation, but layers that use the weights loader (see Loading Weights) should reimplement this method.
BaseLayer defines several convenience methods as part of its protected interface. These methods are accessible to your derived type and simplify writing its code:
-
Use allocateMemoryBlock to allocate long-lived device memory buffers, or the ScopedMemoryAllocation class for temporary scratch memory.
-
The inputLayer method provides indexed access to the layer's ILayer inputs without going through ILayerList and getInputLayers.
-
The data method returns a direct pointer to the layer's output tensor.
BaseLayer uses a registered implementation system to adapt its format to the network's preferred tensor format (accessible with INetworkRuntime::tensorFormat). This allows a single concrete layer object to support multiple tensor formats natively instead of creating separate layer objects for each standard format. Call registerImplementation during the derived layer type's constructor for each tensor format you wish to implement. The public tensorFormat function returns the best match to the network's preferred tensor format. See the SDK reference documentation for details on the selection algorithm.
See the ColorConversionLayer class in the SDK's Samples/Layers/ directory for a fully working example layer using BaseClass. The ElementWiseLayer example in the same directory demonstrates how to generate CUDA inference kernels at runtime rather than relying on a potentially large number of precompiled kernels.
3.3.4. Bypassing Null Inference
Some layer configurations can be simplified to the identity operation, wherein the layer simply copies one of its inputs to its output tensor unmodified. While normal inference and even cudaMemcpyAsync can achieve this goal and preserve network correctness, they still rely on copying a potentially large tensor. This requires a kernel launch and numerous memory accesses for effectively no benefit. NvNeural allows further optimization of this scenario, skipping both the evaluateForward call and the allocation of an output tensor for it to write to.
Layers that can potentially optimize themselves out should implement the IBypassLayer interface, defined in nvneural/LayerTypes.h. The presence of this interface triggers additional checks during inference. The interface has one method, getAliasedInput. When the layer simply forwards an input unaltered, it should return a pointer to that input layer from this method. The network class will then under most circumstances skip evaluation of the bypassable layer during inference, and transparently redirect requests for the layer's output tensor to that of the input it forwards.
You should still implement evaluateForward even when the layer would return a non-null value from getAliasedInput. Activation functions, tensor reformats, cycles in the network graph, and other scenarios can preclude taking advantage of the IBypassLayer optimization.
3.3.5. Runtime Options
The analysis modes of NVIDIA Nsight Deep Learning Designer allow interactive exploration of network behaviors through special-purpose analysis layers. These layers allow runtime adjustment through the analysis parameter editor using the IRuntimeOptionsLayer interface, defined in nvneural/LayerTypes.h.
Layers implementing IRuntimeOptionsLayer interface describe a set of runtime-modifiable parameters with its runtimeOptionCount and runtimeOptionByIndex methods. The analysis tools present each such runtime option in the editor for adjustment by the user. An individual runtime option is a JSON object literal. See the description of the IRuntimeOptionsLayer interface for full details, but at minimum each option description must have the following members:
-
name: This is a C-style identifier string that uniquely identifies the option to the layer instance. Scoping the name with per-layer prefixes is not necessary; for example, you can simply use scale instead of affine_layer_4__scale. The inference process automatically associates runtime option controls to specific ILayer objects.
-
text: This is the human-readable caption string for the runtime option.
-
type: This is the type of data the runtime option expects. The analysis tools use this type string and available type-specific details to construct an appropriate input control.
Some option types allow further customization by providing additional key-value pairs in the JSON object. See the description of the runtimeoptionstype namespace in nvneural/LayerTypes.h for specific details of the extra attributes currently supported by NVIDIA Nsight Deep Learning Designer.
New runtime option values from the analysis tool are communicated to the layer as strings through setRuntimeOptionValue. When a new runtime option value is received, the layer should do the following:
-
Validate the option value. The GUI for the option might be a simple text entry field, and validation checks are always desirable there. Check for both structure (for example, numeric data should be convertible to a number with std::stof or similar functions) and range (for example, a blending factor should generally be between 0 and 1).
-
Update internal member variables used by evaluateForward.
-
Set itself as affected so that a subsequent inference pass re-evaluates the layer.
-
If the layer's output dimensions will change as a result of the new value, call BaseLayer::requestReshape.
Finally, the layer is provided a callback object through setRuntimeOptionsHost. This object represents the hosting analysis tool and can be used to send notifications back to the GUI. At this time, the only supported notification is optionsRefreshed; invoke this method when the set of runtime options returned by the layer has changed, either in quantity or JSON descriptions.
3.3.6. Exporting Layers
Layers use descriptor structures to export metadata used by tools and client applications. Descriptor structures should be initialized and exported during the execution of nvneural::plugin::InitializePluginTypes as described in Implementing IPlugin (Automatic Approach). Create a long-lived instance of the LayerDesc structure for each permutation of network backend (currently CUDA) and tensor format supported by the ILayer object, and export it with ClassRegistry::registerLayer.
Each call to BaseLayer::registerImplementation during the constructor of your ILayer object generally requires a corresponding LayerDesc structure.
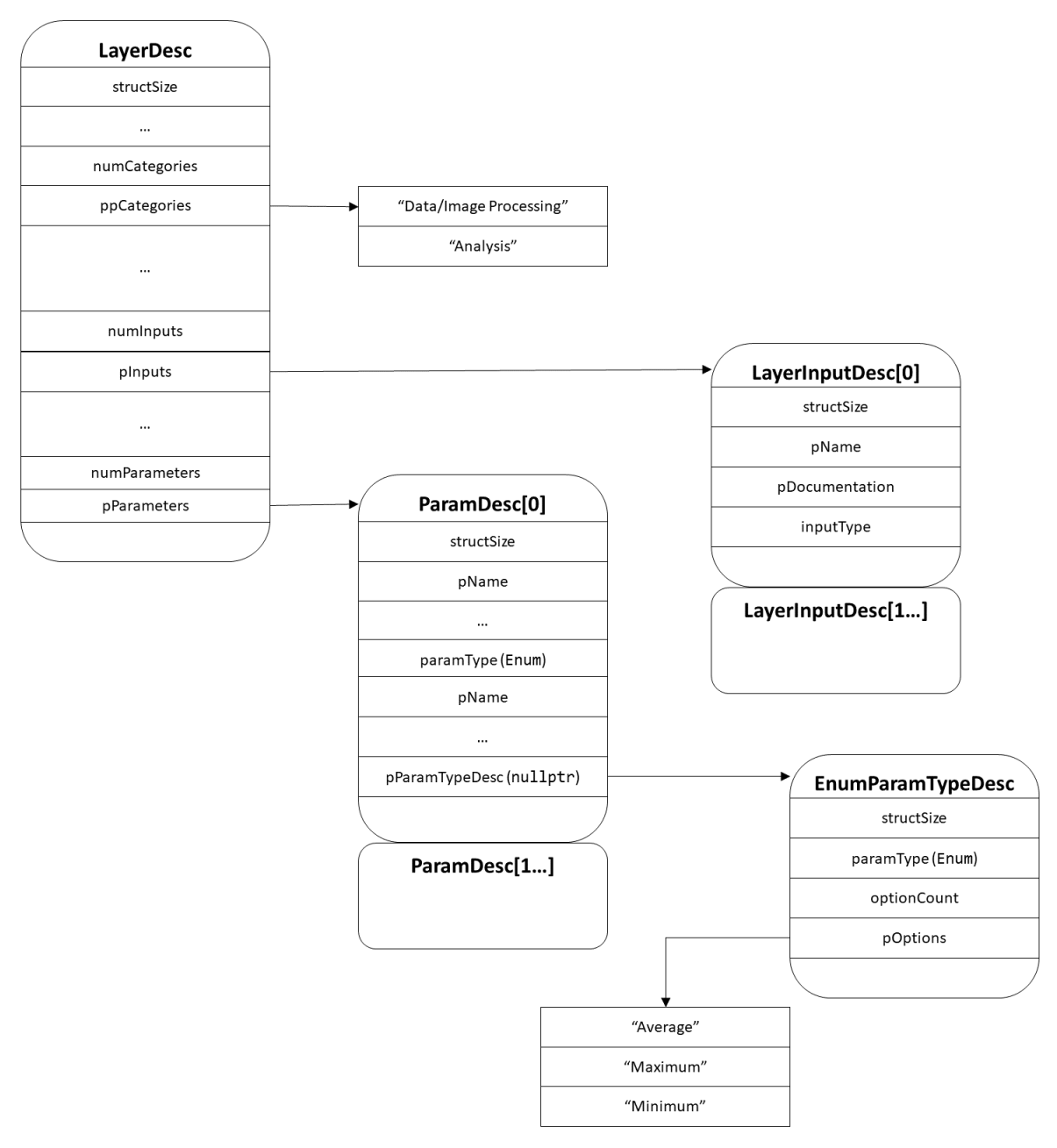
See the SDK reference documentation for specifics on LayerDesc, but the structure contains several pointers to other arrays of descriptor structures. Generally, you do not need to create separate arrays of these sub-descriptor objects for each exported instance of your LayerDesc structure.
-
structSize is the size of LayerDesc. Future versions of NvNeural may extend this structure; should this happen, the framework will use the value of this field to distinguish between versions of this structure.
-
pObjectClass is the name that should be passed to IPlugin::createObject when creating instances of this object. In this example, "com.example.mylayer" would be an appropriate object class name.
-
pSerializedName is the name used by utilities such as XmlNetworkBuilder and the NVIDIA Nsight Deep Learning Designer editor to identify the layer in saved model designs. It should be the same name as that returned by ILayer::serializedType. In this example, "my_layer" would be the serialized name.
-
pDocumentation is optional documentation to be displayed in the editor's documentation browser. It should use the restricted subset of HTML supported by Qt. If you do not wish to provide documentation, this member can be nullptr.
-
pDisplayName is the human-readable name shown in the editor. If no display name is provided, the editor uses pSerializedName. In this example, "My Layer" would be the display name.
-
numCategories and ppCategories describe an optional array of null-terminated category strings. The editor uses these categories to sort layers in the layer palette. Predefined standard categories are provided in the nvneural::common_categories namespace.
-
backend and tensorFormat describe a native backend and tensor format supported by this layer. Each tensorFormat should mirror a BaseLayer::registerImplementation call if using that base class.
-
numInputs and pInputs describe an array of LayerInputDesc structures. Each of these structures describes an input terminal in the editor:
-
Most inputs are primary inputs, even if optional.
-
Inputs that replace tensors provided by the weights loader are secondary inputs.
-
Layers such as concatenation and element_wise that take arbitrary numbers of additional inputs should include an input of type PrimaryInfinite.
The array of LayerInputDesc structures exported by the plugin is currently used only by the editor, not during network construction. Be sure the descriptors reflect the actual behavior of your layer. Define primary and secondary inputs as appropriate for mandatory and optional-but-significant tensors. For example, a layer that performs convolution and concatenates the result with an arbitrary set of input tensors should declare the following inputs:
-
A primary input representing the convolution input.
-
A secondary input representing the convolution kernel.
-
A secondary input representing the convolution bias.
-
A PrimaryInfinite input representing the extra tensors to concatenate.
-
-
generatesOutput is typically true for all layers. Layers for whom the output tensor is meaningless (for example, because the evaluateForward method generates side effects rather than an output tensor) should set this member to false so that the editor does not display an output terminal for this layer type.
-
numParameters and pParameters describe an array of ParamDesc structures. Each structure describes a single editable parameter:
-
pName is the serialized name of the parameter.
-
pDefault is the default value the editor should assign to this parameter. Keep it in sync with the behavior of your layer object's loadFromParameters method.
-
paramType represents the preferred format of the parameter value. The editor customizes its input control for the parameter type; Boolean parameters, for example, are shown with checkboxes rather than text entry fields. Currently string, unsigned-integer, floating-point, enumeration, dimension, and Boolean types are supported. See the SDK reference documentation for ParamType for more details.
-
pDocumentation is optional documentation to be shown in the editor's documentation browser. It should use the restricted subset of HTML supported by Qt. If you do not wish to provide documentation, this method can be nullptr.
-
pParamTypeDetails is an optional pointer to a ParamType-specific options structure. For example, Enum parameters use this structure to pass a list of strings describing acceptable values for the parameter. See the nvneural/CoreTypes.h SDK documentation for more details.
-
3.4. Default Fusing Rules
Layer plugins can export default fusing rules for use by the NVIDIA Nsight Deep Learning Designer editor and ConverenceNG (using its --default-fusing-rules command-line parameter).
static const auto register_fusing_rule_bn = ClassRegistry::registerFusingRule(2, "fp16|nhwc|convolution_bn = batch_normalization[act == 'none' || act == 'relu' || act == 'leaky_relu'] {convolution[act == 'none' || act == 'relu' || act == 'leaky_relu']}");Develop your fusing rule in the editor in tandem with your layer plugin. When you are satisfied that the layer supports all situations where the fusing rule would apply, move the rule's definition to the plugin so other users can make use of it automatically.
3.5. Implementing IActivationFunction
Activation functions in NvNeural are epilog functions applied at the end of performing inference with an ILayer object. The most well-known examples of such functions are ReLU, Leaky ReLU, and sigmoid, but NvNeural supports user-written activation functions using the plugin system.
Optimized networks should not rely directly on IActivationFunction objects. Every generic activation function provided with NVIDIA Nsight Deep Learning Designer launches a CUDA kernel that modifies every individual element of the attached layer's output tensor. The kernel launch and resulting cache misses contribute unavoidable overhead to the inference operation. When building custom layer objects, consider implementing extra kernel variants that perform common activation functions. Pointwise operations such as ReLU can be computed with effectively zero overhead when writing tensor outputs.
The network class instantiates available activation functions described by its attached IClassRegistry. At the conclusion of inference, layers should call INetworkRuntime::defaultForwardActivation whenever their attached activation function is not fused as described above. The network chooses the IActivationFunction most closely matching the layer's tensor format and executes it with invoke. If the activation function was registered with a different tensor format than the layer's native output, the network class creates a temporary working copy of the layer's output tensor when necessary.
Activation functions use the flyweight design pattern. Assuming tensor formats are uniform within the network, a single activation function instance can be used for all unfused activations of its type. Fully worked examples of the ReLU, Leaky ReLU, and sigmoid activation functions are provided in the Samples/Activations directory of the NvNeural SDK.
To create a custom activation function, first implement IActivationFunction:
-
The setNetworkRuntime function is called by the network during construction. It provides a link to the owning network instance. The INetwork::unload function is sufficient to break ownership cycles, so you may take either a strong or weak reference to the network object. Most activation functions simply cache the pointer in a member variable.
-
The serializedType function is not used during inference. Tools like ConverenceNG call it to represent IActivationFunction instances inside human-readable log messages and generated source code. Return the same string used by the descriptor structure. Descriptor structures are described later in this section.
-
The invoke function performs activation for the provided ILayer object. Retrieve the layer's output tensor with ILayer::getData, necessary activation coefficients (generally called alphas), and launch a CUDA kernel to implement the operation in place on the output tensor.
C++ code generation support for all activation functions is built into the exporter, but the other output formats require additional code. See Supporting Network Export for more details.
Assign a unique integer identifier to the activation function. This identifier must be a 32-bit unsigned integer that is greater than or equal to ActivationFunctionId::CustomBase.
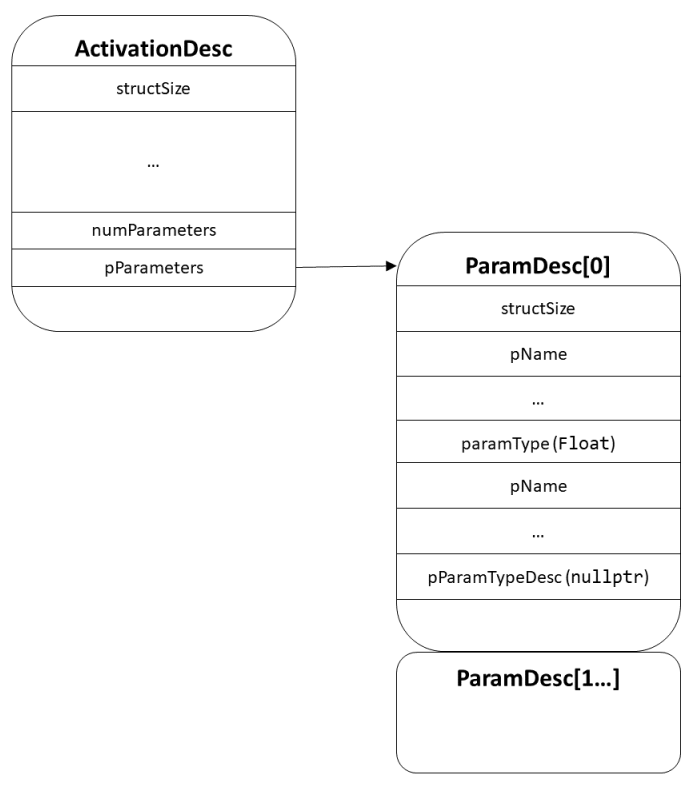
Finally, register the activation function with the module's class registry. This should be done during execution of nvneural::plugin::InitializePluginTypes as described in Implementing IPlugin (Automatic Approach). Create a long-lived instance of the ActivationDesc structure for each permutation of network backend (currently CUDA) and tensor format supported by the IActivationFunction object, and export it with ClassRegistry::registerActivation. See the SDK reference documentation for specifics on ActivationDesc, but the structure currently contains the following members:
-
structSize is the size of ActivationDesc. Future versions of NvNeural may extend this structure; should this happen, the framework will use the value of this field to distinguish between versions of the structure.
-
pObjectClass is the name that will be used by IPlugin::createObject to describe instances of this object. In this example, "com.example.myactivation" would be an appropriate object class name.
-
pSerializedName is the name used by utilities such as XmlNetworkBuilder and the NVIDIA Nsight Deep Learning Designer editor to identify the activation in saved model designs. It should be the same name as that returned by IActivationFunction::serializedType. In this example, "my_activation" would be the serialized name.
-
pDocumentation is optional documentation to be displayed in the editor's documentation browser. It should use the restricted subset of HTML supported by Qt. If you do not wish to provide documentation, this member can be nullptr.
-
pDisplayName is the human-readable name shown in the editor. If no display name is provided, the editor uses pSerializedName. In this example, "My Activation" would be the display name.
-
activationFunction is the unique-per-function integer identifier chosen as described above.
-
backend should always be NetworkBackendId::Cuda. Future versions of the framework may support other backends.
-
tensorFormat is a tensor format this activation function supports natively. If multiple formats are supported, register multiple ActivationDesc structures.
-
numParameters and pParameters describe an array of ParamDesc structures. Only numeric (ParamType::Float) parameters are currently supported for activation functions as they are mapped directly to calls to ILayer::setActivationCoefficient. The relationship of ActivationDesc to ParamDesc is shown below:
Tip:When registering multiple ActivationDesc variants, you can point each to the same parameter array. There is no need to copy them for each descriptor instance.
4. Designing Client Applications
NvNeural supports both development-time and deployed-application inference scenarios using the same core set of classes and plugins. Many interface points with the host operating system and application shell can be customized or replaced. This section describes the basic skeleton of an inference application and highlights common integrations where you may wish to provide your own code.
4.1. Application Inference Overview
The inference process relies on five major steps: initializing NvNeural, building the network, assigning input tensors, performing inference, and retrieving the output tensors.
Once the network is built, applications can repeat the latter three steps as needed without reconstructing the network. Changes to the sizes of input tensors automatically reshape downstream layers during the next inference pass.
4.2. Initializing NvNeural
Before building a network, you must first provide its interface to the plugin system and GPU. This section describes the necessary steps that must be performed before creating layer objects and adding them to the network.
- Create a logger and set it as the default.
Objects in NvNeural output diagnostic and debug information to a common logger interface called ILogger. Create a logger object instance and make it application-global using SetDefaultLogger. The default plugin loader provides newly loaded plugins with references to the default logger automatically.
The SimpleLogger class writes all log messages below a configurable verbosity level to the C++ default iostream objects. Informational messages are sent to std::cout, and both warning and error messages are sent to std::cerr. You can choose a different stream destination with its redirectAllOutput method. - Create a plugin loader and load plugins.
The loading and lifespan of IPlugin objects is normally managed by objects implementing the IPluginLoader interface. You must load the NvNeuralNetworkPlugin and NvNeuralCudaBackendPlugin plugins as well as any layer and activation plugins required by your network.
The DynamicPluginLoader class is a standard implementation of IPluginLoader and provides basic controls for loading either individual libraries or an entire directory at once. Development-time scenarios may wish to use the latter approach for expediency, but loading specific libraries is more secure and prevents accidental code injection attacks. We include the source for DynamicPluginLoader in the SDK if further customization is necessary. - Create a class registry and import loaded plugins.
Network objects and associated types use IClassRegistry to create other objects in a plugin-independent fashion. Types visible to an IClassRegistry are accessible whether defined in plugin libraries or in the client application's executable. Make the loaded plugins visible by providing the plugin loader object to IClassRegistry::importPluginLoader.
ClassRegistry is the standard implementation of IClassRegistry.
- Create a network object.
Instantiate an INetwork object with the class registry. The object class is NVNEURAL_INETWORK_OBJECTCLASS. Set a preferred tensor format with setDefaultTensorFormat. Layers will attempt to execute in this tensor format if possible.
- Create a weights loader and attach it to the network.
The weights loader, an object implementing IWeightsLoader, is responsible for providing weights data such as convolution kernels when layer objects request them. Attach the weights loader to the network with setWeightsLoader.
The FilesystemWeightsLoader class is a reference implementation used by ConverenceNG, but you should create your own weights loader for deployed applications. - Create a network backend and attach it to the network.
Instantiate an INetworkBackend object with the class registry. The object class is NVNEURAL_INETWORKBACKENDCUDA_OBJECTCLASS. Initialize the backend with the CUDA device ordinal of your inference GPU (i.e., the value you would pass to cuDeviceGet). Attach the backend to the network with attachBackend and mark its id() as the default network backend with setDefaultBackendId.
Tip:Future versions of NvNeural may provide alternate network backends and execution environments other than CUDA contexts. The deviceIdentifier and initializeFromDeviceIdentifier methods are futureproofing to support interoperability scenarios, and are not necessary for CUDA-only applications.
The infrastructure objects are now fully constructed. You can now add layers to the network.
4.3. Building a Network (Automatic Approach)
This section assumes you wish to create layer objects automatically. You can also construct layer objects manually as described in Building a Network (Manual Approach).
- Create an XmlNetworkBuilder object.
This is a short-lived helper object and should be created with automatic storage duration.
- Configure fusing rules.
Automatic fusing (using fusing rules provided by loaded plugins) can be controlled with setLoadDefaultFusingRules. You can also add your own manually defined fusing rules with addFusingRule.
- Build the network.
If the XML network definition is stored on disk, use buildNetworkFromFile. If the network definition is instead located in memory, use buildNetworkFromXmlLiteral.
Reshape the network with INetwork::reshapeAll when done. This ensures that all layers are fully initialized before inference. The network is now ready to accept input data.
4.4. Building a Network (Manual Approach)
This section assumes you wish to create layer objects individually. You can also use the XmlNetworkBuilder class as described in Building a Network (Automatic Approach).
Constructing the network manually requires the network design to be fully reduced to a graph of layers and activations. Templates and fusing rules are higher-level abstractions that must be applied before instantiating individual layer objects. Use the File > Export > Preprocessed Model... command in the editor to save a copy of a network design after the preprocessor expands templates and applies fusing rules.
- Create a layer object.
Create an ILayer object for each layer in the network using the class registry. Layer object classes can be determined by examining the output of the C++ code generator, or by running ConverenceNG at log verbosity level 2.
- Add the layer to the network.
Use INetwork::pushLayer to attach the layer to the network.
- Configure the layer.
Layers can be configured with the generic loadFromParameters method or by using layer-specific interfaces.
-
To use the generic method, create an IParameterNode object and pass it to ILayer::loadFromParameters. This is how ConverenceNG configures layers.
Tip:The StringMapParameterNode class wraps a simple std::map<std::string, std::string> of name-value pairs behind the IParameterNode interface.
-
Layers ma
y also provide type-specific interfaces such as IConvolutionLayer or IStandardInputLayer. See the header files in nvneural/layers/ for the layer-specific interfaces included with this SDK.
-
- Set the layer's activation.
If the layer has an attached activation function like ReLU or sigmoid, call setActivationFunction to indicate this. Standard activation functions are listed in the ActivationFunctionId enumeration in nvneural/CoreTypes.h but you can define your own enum values for custom activations. If the activation requires additional data, set each parameter with setActivationCoefficient.
- Repeat for each layer.
Create all layer objects, configure them, and add them to the network.
- Connect each layer's inputs.
For each layer, call setInputLayer to connect each of the layer's inputs. Inputs that are not connected to a layer can be skipped or set explicitly to nullptr as you prefer. Input indices are zero-based.
Tip:Assigning inputs can also be done incrementally as you attach layers to the network. The code generators and XmlNetworkBuilder do this as a separate step to avoid special handling for cycles.
Reshape the network with INetwork::reshapeAll when done. This ensures that all layers are fully initialized before inference. The network is now ready to accept input data.
4.5. Assigning Input Tensors
Networks using the input layer from StandardInputPlugin accept input data from disk or system memory using the IStandardInputLayer interface. Data can be treated as images or as tensors.
Images represent R8G8B8 data, and are normalized, shifted, and scaled during import to the NvNeural input layer. First the color channels are mapped linearly (0x00 .. 0xFF becoming 0.0 .. 1.0). They are then translated by the value of the shift parameter, and multiplied by the scale parameter. They are zero-padded beyond the original three channels to a specified minimum channel count, and finally zero-padded along H and W to be multiples of the specified tiling factor.
If alpha channels are significant in your network, call setImagesUseAlpha to preserve the fourth channel instead of zeroing it.
Load images from on-disk image files using loadImage or from uncompressed RGB(A) data using loadImageBuffer.
Tensors represent fully processed floating-point data in NCHW or NHWC ordering. They are zero-padded along the H and W axes to match the tiling factor, but are otherwise unaltered when loading.
Load tensors from on-disk Numpy files (.npy format) using loadNumpy or from raw float or Float16 arrays using loadCpuBuffer.
File format autodetection (i.e., npy files using loadNumpy and image data using loadImage) is possible using the loadDetectedFile method.
When all inputs have been assigned, you can perform inference. Input layers retain their tensors across inference runs, so only changed data must be reloaded.
4.6. Performing Inference
The INetwork::inference method is used to perform inference on a network. The framework calls the reshape method on any layer objects queued for reconfiguration, then inferences all affected layers and their dependencies in forward order.
Subgraphs with no affected layers do not perform work during inference.
When inference is complete, the tensors of network outputs and permanent layers can be retrieved. Layers not marked permanent are not guaranteed to preserve their contents after inference; NvNeural may recycle their tensor buffers to provide intermediate result storage for other layers.
4.7. Reading Output Tensors
You can read layer tensor outputs after a successful inference pass. Tensor data can be copied to host memory or read directly from the GPU. Reading tensor memory in a format other than the layer's tensorFormat automatically converts it to the requested data type and layout as necessary. Attempts to access an intermediate layer's output tensor after it has been freed will fail. Mark a layer as permanent before inference if you intend to read from it.
To copy a layer tensor to the CPU, use the ILayer::getCpuConstData method. If you are unsure of the appropriate buffer size, you can pass nullptr as the output buffer and the pBytesCopied pointer will receive the minimum buffer size.
Layer tensors can also be accessed directly from the GPU. Use ILayer::getConstData to receive a read-only device pointer to the layer's output tensor in the requested format.
4.8. Common Integration Points
The NvNeural framework is designed to be customizable for the demands of the application environment. Many operations can be intercepted or outright replaced with alternate implementations.
Weights loading can be customized by attaching a different IWeightsLoader implementation to the network than the standard FilesystemWeightsLoader class. This allows use of resource layouts than individual NCHW Numpy tensors, and the framework also supports direct access of weights resident on the GPU.
-
Weights in host memory are represented in IWeightsData objects with a backend ID of NetworkBackendId::Cpu. The CUDA backend will copy the object's buffer to device memory.
-
Weights in device memory are represented in IWeightsData objects with a backend ID of NetworkBackendId::Cuda. Use the memManagedExternally flag to prevent the backend from assuming ownership of the weights buffer.
Input layers are simply layers that implement IInputLayer. There is nothing special about the IStandardInputLayer objects other than ConverenceNG and the NVIDIA Nsight Deep Learning Designer analysis tools interacting with that interface. Within the bounds of a custom client application it may be worthwhile to replace the standard input layer with one more suited to the application's native data formats.
Logging can be redirected to a custom object instead of the SimpleLogger used by ConverenceNG. Applications without a visible stdout and stderr (for example, graphical applications on Windows) should consider providing their own logger.
Inference operations can be intercepted with an instance of the INetworkDebugger class. This class receives callbacks from the INetwork object when layers and networks begin and end inference. Many functions of ConverenceNG are implemented using network debuggers.
Device memory allocation can be controlled by replacing the ICudaMemoryAllocator object used by the CUDA backend. The CUDA backend and layer classes shipped with NVIDIA Nsight Deep Learning Designer do not call cuMemAlloc or other allocation functions directly; only the ICudaMemoryAllocator object directly allocates CUDA device memory. Applications wishing to exercise more control over the details of GPU memory allocation should replace the allocator with a custom implementation.
5. Supporting Network Export
NVIDIA Nsight Deep Learning Designer allows you to export your network design in a variety of formats. This section describes how each export option is implemented inside NvNeural or its accompanying Python scripts, and how you can support these exporters in your own custom plugins.
See Exporters in the User Guide for instructions on how these export options are presented in the NVIDIA Nsight Deep Learning Designer user interface.
5.1. C++ Exporter Details
NvNeural supports automated generation of C++ client applications from network definitions using the ConverenceNG tool. The details of exporting individual layers and activation functions are embedded into their respective object implementations.
See nvneural/CodeGenTypes.h for more details on the interfaces described in this section.
5.1.1. C++ Exporter Architecture
ConverenceNG generates up to four files as part of the C++ export process. Developers are encouraged to customize or replace this source code as required for their applications, though the exporter makes no attempts to preserve inline edits when re-exporting.
The generated source code is designed around the concept of a factory function that recreates the exported network inside an NvNeural network object. Two of the generated artifacts, the network header and network source, provide the declaration and definition of this function. While the generated code can be further customized, it is designed to be safely reexportable should the network definition change during development of your application. The other two generated artifacts, the application source and CMake build script, demonstrate how to consume the network factory function in a simple inference application. You will typically replace these entirely with your own code.
In the following examples, MyNetwork represents the name of the exported network.
The network header describes a factory function that takes a network object and class registry, and constructs the network in place. The name of the factory function can be changed using ConverenceNG command-line arguments.
// This file is automatically generated.
#pragma once
#include <nvneural/CoreTypes.h>
#include <nvneural/RefPtr.h>
// Forward-declare what we can inside nvneural
namespace nvneural {
class INetwork;
class ClassRegistry;
} // namespace nvneural
/// Construct the layers corresponding to MyNetwork inside a new network.
///
/// \param pNetwork Network to build
/// \param registry Class registry able to construct the needed layer objects
nvneural::NeuralResult MyNetwork(nvneural::RefPtr<nvneural::INetwork>; pNetwork, const nvneural::IClassRegistry* pRegistry);
<!-- REGION: HEADER FRAGMENTS CAN BE ADDED HERE -->
The network source provides the implementation of the factory function. Rather than show the (extremely verbose) source code unaltered, this guide will present excerpts instead to illustrate where layers can insert C++ fragments to customize the generation process.
// This file is automatically generated.
// <!-- REGION: INCLUDES -->
#include <ClassRegistry.h>
#include <StringMapParameterNode.h>
#include <ZlibResourceDictionary.h>
#include <map>
#include <nvneural/CodeGenTypes.h>
#include <nvneural/CoreHelpers.h>
#include <nvneural/NetworkTypes.h>
#include <nvneural/layers/IConvolutionLayer.h>
#include <nvneural/layers/IPrototypeLayer.h>
#include <nvneural/layers/IStandardInputLayer.h>
#include <string>
// <!-- END INCLUDES -->
nvneural::NeuralResult MyNetwork(nvneural::RefPtr<nvneural::INetwork> pNetwork, const nvneural::IClassRegistry* pRegistry)
{
nvneural::NeuralResult status;
status = pNetwork->setNetworkName("ISRModel2X");
if (nvneural::failed(status)) return status;
// Layer pointers
nvneural::RefPtr<nvneural::ILayer> pLayer_input;
nvneural::RefPtr<nvneural::ILayer> pLayer_upsample;
// ... other layers omitted for brevity ...
// <!-- PER-LAYER INITIALIZATION -->
// Initialize input
{
// <!-- REGION: OBJECT CLASS -->
pRegistry->createObject(pLayer_input.put_refobject(),"com.nvidia.layers.input.cuda");
if (!pLayer_input)
{
nvneural::DefaultLogger()->logError(0, "input: could not create object com.nvidia.layers.input.cuda");
return nvneural::NeuralResult::Failure;
}
status = pLayer_input->setName("input");
if (nvneural::failed(status)) return status;
// <!-- REGION: INITIALIZATION FRAGMENT -->
const auto pInputLayer_input = pLayer_input.as<nvneural::IStandardInputLayer>();
if (!pInputLayer_input)
{
nvneural::DefaultLogger()->logError(0, "%s: Not an input layer", pLayer_input->name());
return nvneural::NeuralResult::Failure;
}
pInputLayer_input->setPlaceholderSize(nvneural::TensorDimension{1u, 8u, 256u, 256u});
pInputLayer_input->setImagesUseAlpha(false);
pInputLayer_input->setTilingFactor(16);
status = pNetwork->pushLayer(pLayer_input.get());
if (nvneural::failed(status)) return status;
// <!-- END INITIALIZATION FRAGMENT -->
}
// Initialize upsample
{
pRegistry->createObject(pLayer_upsample.put_refobject(),"com.nvidia.layers.upscale.cuda");
if (!pLayer_upsample)
{
nvneural::DefaultLogger()->logError(0, "upsample: could not create object com.nvidia.layers.upscale.cuda");
return nvneural::NeuralResult::Failure;
}
status = pLayer_upsample->setName("upsample");
if (nvneural::failed(status)) return status;
// <!-- NOTE: THIS IS A DEFAULTED INITIALIZATION FRAGMENT -->
const auto pParameterNode = nvneural::make_refobject<nvneural::StringMapParameterNode>(nvneural::StringMapParameterNode::StringMap{
{ "factor", "2x2" },
{ "method", "bilinear" },
}).as<nvneural::IParameterNode>();
status = pLayer_upsample->loadFromParameters(pParameterNode.get());
if (nvneural::failed(status)) return status;
status = pNetwork->pushLayer(pLayer_upsample.get());
if (nvneural::failed(status)) return status;
}
// ...layers omitted for brevity...
// Initialize conv1_BatchNorm
{
pRegistry->createObject(pLayer_conv1_BatchNorm.put_refobject(),"com.nvidia.layers.batch-normalization.cuda");
if (!pLayer_conv1_BatchNorm)
{
nvneural::DefaultLogger()->logError(0, "conv1_BatchNorm: could not create object com.nvidia.layers.batch-normalization.cuda");
return nvneural::NeuralResult::Failure;
}
status = pLayer_conv1_BatchNorm->setName("conv1_BatchNorm");
if (nvneural::failed(status)) return status;
status = pLayer_conv1_BatchNorm->setActivationFunction(static_cast<nvneural::ActivationFunctionId>(0x2u)); // leaky_relu
if (nvneural::failed(status)) return status;
status = pLayer_conv1_BatchNorm->setActivationCoefficient(0, 0.1f);
if (nvneural::failed(status)) return status;
// Layer has no parameters
status = pNetwork->pushLayer(pLayer_conv1_BatchNorm.get());
if (nvneural::failed(status)) return status;
}
// ...other layers omitted for brevity...
// Connect layer inputs
{
status = pLayer_upsample->setInputLayer(0, pLayer_input.get());
if (nvneural::failed(status)) return status;
status = pLayer_conv1->setInputLayer(0, pLayer_input.get());
if (nvneural::failed(status)) return status;
status = pLayer_conv1_BatchNorm->setInputLayer(0, pLayer_conv1.get());
if (nvneural::failed(status)) return status;
// ...other layers omitted for brevity...
}
return nvneural::NeuralResult::Success;
}
The application source is a simple command-line inference tool that initializes NvNeural, creates the network and supporting objects, populates the network with the generated factory function, and performs inference. You should replace this with your own application shell.
The generated source typically varies only in the names of input and output layers, and which tensor format to use by default. Customized input layers can alter the default parsing behavior for their associated command-line argument and call appropriate APIs to load tensor data using the argument.
// This file was automatically generated, but should be customized/replaced to meet your needs.
// <!-- REGION: INCLUDES -->
#include "MyNetwork.h"
#include <CLI11/CLI11.hpp>
// ...
#include <nvneural/CudaTypes.h>
#include <nvneural/NetworkTypes.h>
#include <nvneural/layers/IStandardInputLayer.h>
#include <string>
#include <vector>
// <!-- END INCLUDES -->
static uint64_t currentTimeInUsec(nvneural::INetworkBackend* pBackend)
{
pBackend->synchronize();
using namespace std::chrono;
return duration_cast<microseconds>(high_resolution_clock::now().time_since_epoch()).count();
}
int main(int argc, char** argv)
{
// ...omitted...
cliApp.add_flag("-v,--verbose", verbosity, "Increase log verbosity");
cliApp.add_flag("--fp16,!--fp32", fp16, "use FP16 (half-precision) tensors")->capture_default_str();
cliApp.add_flag("--nhwc,!--nchw", nhwc, "use NHWC tensor layout")->capture_default_str();
cliApp.add_option("--device", cudaDeviceIndex, "CUDA index of desired compute device")->capture_default_str();
cliApp.add_option("--weights", weightsPath, "path to weights tensors")->required();
cliApp.add_option("--iterations", passCount, "number of iterations to run")->capture_default_str();
// <!-- EACH INPUT AND OUTPUT HAS A STRING-VALUED PARAMETER -->
cliApp.add_option("--input,-i,--i-input", inputPaths["input"], "tensor source for the \"input\" layer")->required();
cliApp.add_option("--output,-o,--o-out_element_wise_sum", outputPaths["out_element_wise_sum"], "save location for output tensor of the \"out_element_wise_sum\" layer");
CLI11_PARSE(cliApp, argc, argv);
const auto pLogger = make_refobject<SimpleLogger>(verbosity).as<ILogger>();
SetDefaultLogger(pLogger.get());
const TensorDataType tensorType = fp16 ? TensorDataType::Half : TensorDataType::Float;
const TensorDataLayout tensorLayout = nhwc ? TensorDataLayout::Nhwc : TensorDataLayout::Nchw;
const TensorFormat tensorFormat = { tensorType, tensorLayout };
pLogger->log(1, "Loading plugins");
const auto pPluginLoader = make_refobject<DynamicPluginLoader>().as<IPluginLoader>();
std::uint32_t loadCount = 0;
status = pPluginLoader->loadDirectory(".", &loadCount);
if (failed(status) || (0 == loadCount))
{
pLogger->logError(0, "Unable to load plugins");
return 1;
}
// ...extra object creation omitted...
pLogger->log(1, "Creating network");
status = MyNetwork(pNetwork, pRegistry.get());
if (failed(status))
{
pLogger->logError(0, "Unable to construct network");
return 1;
}
// Assign input for layer 'input'
{
// <!-- REGION: INPUT FRAGMENT -->
nvneural::ILayer* const pLayer_input = pNetwork->getLayerByName("input");
const auto pInputLayer_input = nvneural::RefPtr<nvneural::ILayer>::fromPointer(pLayer_input).as<nvneural::IStandardInputLayer>();
if (!pInputLayer_input)
{
nvneural::DefaultLogger()->logError(0, "%s: Not an input layer", pLayer_input->name());
return 1;
}
const auto loadStatus = pInputLayer_input->loadDetectedFile((inputPaths["input"]).c_str());
if (nvneural::failed(loadStatus))
{
nvneural::DefaultLogger()->logError(0, "%s: Unable to load file", pLayer_input->name());
return 1;
}
// <!-- END INPUT FRAGMENT -->
}
// ...inference code omitted...
pNetwork->unload();
return 0;
}
The build script is an example CMake project that imports the NvNeural CMake definitions and bundles them with your generated application and network sources.
ConverenceNG integrates the SDK into the generated build process in order to ensure that internal helper types such as RefPtr and ClassRegistry use your preferred compiler flags and toolchain. While these types operate on or provide ABI-stable interfaces to other modules, they internally rely on matching the ABI behaviors of the module they are linked into. Developers intending to replace CMake with other build systems should replicate this behavior and build their own local copy of the core NvNeural headers and helpers.
Because inference relies on the application loading the correct NvNeural plugins, be sure to use make install or otherwise execute the CMake install(...) rules when building, and run from the installation location (${CMAKE_INSTALL_PREFIX}). Your application will otherwise not be able to create any of its prerequisite layer, network, or backend objects.
5.1.2. C++ Exporter Host Responsibilities
ConverenceNG serves as the exporter host, and provides an instance of ICppCodeGenerationHost to generator objects. It follows this general procedure for generating source code:
-
Load plugins and construct a network. This uses the standard XmlNetworkBuilder creation path and is described elsewhere in this document.
-
Reshape the network. This ensures that layers have accurate tensor dimensions and can generate necessary kernel sources.
-
Loop over each ILayer in the network, calling ICppCodeGenerationLayer::generateLayerCpp where available.
-
Write the output files requested by the user.
ConverenceNG provides a "resource dictionary" concept for generated code. Layers that need to cache kernel sources, large objects, or even entire compiled CUDA modules may call addResource to include the resource in the generated factory function. Resources are compressed and deduplicated during code generation. The IResourceDictionary::ResourceId returned by this method call can be used to retrieve the decompressed object at runtime.
For a future release, we are considering a "deployment mode" for code generation. In such a mode, layers would be provided a list of GPU architectures to optimize for and could precompile CUDA kernels during export for later retrieval through the resource dictionary system. This would enable faster startup with potentially less dependency on just-in-time kernel compilation through ICudaRuntimeCompiler and NvRTC.
5.1.3. C++ Exporter Layer Responsibilities
The exporter provides default layer code generators for any ILayer object without an accompanying ICppCodeGenerationLayer interface. Default code generation has the following properties:
-
No additional header fragments. Only standard includes are necessary.
-
No additional source fragments.
-
No input fragments. The layer cannot accept data paths from the command line.
-
Layer object classes are determined using the LayerDesc structure selected by XmlNetworkBuilder when building the network for export.
-
Layer initialization uses the ILayer::loadFromParameters method. The IParameterNode provided is a lightweight wrapper around a constant std::map<std::string, std::string> object. All parameters present in the original XML are included in the StringMapParameterNode.
For many layers, this interface is typically sufficient as it matches the behavior of ConverenceNG and the NVIDIA Nsight Deep Learning Designer analysis tools, but you can implement ICppCodeGenerationLayer::generateLayerCpp for more control over the generated sources.
The ICppCodeGenerationHost object provided to your generator gives access to the variable names used by the generated code to describe standard layer concepts. Generated code fragments should target C++14 and should consume the nvneural namespace explicitly to prevent accidental identifier shadowing. See the ICppCodeGenerationHost interface documentation for specific details of expression types.
Layers can change their own object class in the generated code. This allows conversion to purpose-built subclasses where advantageous. For example, convolution layers that are compatible with lightweight evaluation generate initialization code using object classes compatible with the lightweight convolution plugin.
Layers may add extra #include lines to the generated network and application sources with addInclude, add extra lines of source code to the network header and source with addSourceFragment and addHeaderFragment respectively, and override initialization and input argument parsing using setInitializationFragment and setInputFragment. NvNeural does not prescribe the use of any particular formatting or templating libraries for generating source code; you may use whichever mechanisms you prefer. We provide helper classes in the nvneural/CodeGenHelpers.h header for more easily assembling large blocks of indented code. See the description of SourceWriter for details and an example.
5.1.4. C++ Exporter Activation Responsibilities
Activation functions neither require nor support custom generation behavior. After the associated layer object is created, the exporter emits code to call ILayer::setActivationFunction and ILayer::setActivationCoefficient as required. As with design-time tool-based inference using ConverenceNG or the NVIDIA Nsight Deep Learning Designer analysis features, individual IActivationFunction objects are used only if the attached layers do not implement their own optimized activation path.
5.2. ONNX Exporter Details
NvNeural performs ONNX export using the ConverenceNG tool. The details of exporting individual layers and activation functions are embedded into their respective object implementations.
ONNX export uses opaque node and attribute interfaces instead of passing Protocol Buffer messages directly. This is done to ensure plugins use the same ONNX message formats and remove cross-module dependencies on std::string and other ABI-unstable types. Plugins do not need to embed or compile their own copies of onnx.proto, and do not need to link directly against libprotobuf.
See nvneural/OnnxTypes.h for more details on the interfaces described in this section.
5.2.1. ONNX Exporter Host Responsibilities
ConverenceNG serves as the exporter host, and provides an instance of IOnnxGenerationHost to generator objects. It follows this general procedure for converting networks to ONNX:
-
Load plugins and construct a network. This uses the standard XmlNetworkBuilder creation path and is described elsewhere in this document.
-
Reshape the network. This ensures that layers have accurate tensor dimensions if the user has requested explicit tensor sizes in the ONNX graph definition.
-
Create an ONNX ModelProto message and wrap it in an IOnnxGenerationHost.
-
Convert each ILayer in the network to ONNX.
If the layer provides the IOnnxGenerationLayer interface and returns successfully from generateLayerOnnx, no placeholders are needed for this layer. If the layer does not provide this interface, or returns NeuralResult::Unsupported from the generator, the tool creates a placeholder node instead. Valid instances of IBypassLayer are replaced with Identity operators to indicate the optimization. Other layers are replaced by empty operators in the com.nvidia.nvneural.placeholders ONNX operator namespace to indicate where the user needs to patch the network to provide appropriate custom operators.
-
Convert each ILayer object's assigned activation function to ONNX.
If the layer provides the IOnnxGenerationActivation interface and returns successfully from generateActivationOnnx, no placeholders are needed for this activation. If the activation does not provide this interface, or returns NeuralResult::Unsupported from the generator, the tool creates a placeholder node instead. The activation function is replaced by an empty operator in the com.nvidia.nvneural.placeholders ONNX operator namespace to indicate where the user needs to patch the network to provide appropriate custom operators.
-
Mark all network outputs (as returned by INetworkRuntime::getOutputLayers) as graph outputs.
-
Add
the collected set of operator set imports to the model. If multiple layers imported different versions of the same operator set, only the newest version of the operator set is marked for import. Operator sets can be referenced inside a generator by calling importOperatorSet.
Tip:ConverenceNG imports a default version of the ONNX standard operator set, but this baseline version will be increased very infrequently to avoid breaking downstream conversion tools that are tied to the operator set. Layers and activations should always import the operator set versions their exporters provide.
Layers and activation functions manipulate the ModelProto network graph using the IOnnxGenerationHost interface. Each individual NvNeural operation (layer or activation function) may require multiple operator nods for its ONNX representation, so referencing the ONNX output of a previously converted NvNeural layer should be done with the getLayerOutputName function. If the final tensor in an exported sequence does not match the original name assigned to a layer output, the generator should call setLayerOutputName to update future references to the layer.
All of the addGraphInput, addGraphOutput, addWeightsConstant, and addGraphInitializer overloads take a bool fp16Eligible parameter. Normally the graph edges and initializers are declared as 32-bit floating point tensors. When this parameter is true and the exporter is configured to optimize for fp16 inference (IOnnxGenerationHost::automaticFp16ConversionEnabled() or the --fp16-tensors parameter to ConverenceNG), the exporter will change the tensor declarations it emits to fp16 data, automatically downsampling weights data as required.
Overloads of addGraphInput and addGraphOutput that include a TensorDimension tensorDim parameter will use that size to provide an explicit shape value for the tensor. When shouldUseExplicitTensorSizes returns true, generators should use these explicitly sized overloads, computing the created tensor shapes from their own current dimensions. Using the shorter overload to skip this parameter assigns a dynamic shape to the resulting tensor description.
5.2.2. ONNX Exporter Layer Responsibilities
ONNX export support can be added to a layer by implementing the IOnnxGenerationLayer interface on the layer object alongside ILayer. This interface has a single method, generateLayerOnnx. The generator method takes an instance of IOnnxGenerationHost provided by the exporter tool (currently ConverenceNG) and adds nodes to the model graph representing the operations performed by the layer.
Implementations of IOnnxGenerationLayer::generateLayerOnnxmust convert inner activations (those controlled with IInnerActivationLayer; for example, Upscale > ReLU > Concat). NvNeural does not provide introspection interfaces for splitting fused operators into component operators. Implementations must not convert the layer's "official" activation function as returned by ILayer::activationFunction.
Each layer must create at least one ONNX operator using IOnnxGenerationHost::createGraphNode. Basic properties of the node (documentation string, operator type, named inputs and outputs) can be set using the IOnnxGenerationGraphNode interface itself, but operator attributes must be created by calling the node's createAttribute method and assigning name and value data to the resulting IOnnxGenerationGraphAttribute object. Graph attributes currently support scalar floating-point, integer, string, and byte-array payloads. (Both map to the ONNX string data type in the resulting protocol buffer message, but the "string" method takes a null-terminated string for convenience and the "bytes" method takes an opaque and explicitly-sized array of characters.) Vector variants of each type are also provided; "assign" methods assume scalar data, and "push" methods append to vector data.
By convention, ONNX operators associated with a layer should be named either after the layer or use a pattern like LAYERNAME__suboperator to aid visual inspection of the generated network and reduce opportunities for accidental name collisions.
Each node typically requires at least one tensor input and one tensor output. Use the addInput and addOutput methods to add these to the node. Unconnected optional inputs and outputs should be represented by empty strings. If the input comes from a layer output not created by the generator, then use IOnnxGenerationHost::getLayerOutputName to retrieve the layer's official output tensor name. Input layers may also need to call IOnnxGenerationHost::addInput to mark the tensor as coming from outside the network intermediate tensor set.
Layers that require loaded weights data should call IWeightsLoader::getWeightsForLayer to retrieve the weights tensor, add it to the graph with addWeightsConstant, and then consume the same weights tensor name as a node input. Graph initializers (constant data not mapping directly to on-disk weights, such as scalar mean and variance values) can be added using a similar pattern. Note that some layers can use other layers as weights sources instead of relying on constant data; simply consume the relevant layer output tensors as necessary, though you may have to reshape the tensor with additional operators. The standard ONNX operator set does not assume four-dimensional tensors as NvNeural does.
If a particular layer configuration cannot be represented using appropriate ONNX operators, fail early by returning NeuralResult::Unsupported so the exporter can attempt to add a placeholder. ONNX generation is not currently transacted, so intermediate nodes are not removed upon generator failure. Return NeuralResult::Failure to signal a fatal error and cancel the export operation.
5.2.3. ONNX Exporter Activation Responsibilities
ONNX export support can be added to an activation function by implementing the IOnnxGenerationActivation interface on the activation object alongside IActivationFunction. This interface has a single method, generateActivationOnnx. The generator method takes an instance of IOnnxGenerationHost provided by the exporter tool, and an instance of ILayer representing the layer the activation is attached to, and adds nodes to the model graph representing the operations performed by the activation.
Most of the behaviors performed by the generator mirror those performed by layers' own ONNX generators. The exporter host does not currently restrict any interfaces to layer-only export or activation-only export. As such, see ONNX Exporter Layer Responsibilities for the basic principles of ONNX export.
Most activation functions create a node called LAYERNAME__activation representing the ONNX equivalent of the activation function, though some may need to create multiple nodes. The activation function generator must call setLayerOutputName to update future layer references to the appropriate activation function operator. The generator should call ILayer::activationCoefficient to retrieve necessary per-layer constants (for example, the leaky ReLU threshold specified for the layer).
5.3. DirectML Exporter Details
NvNeural performs DirectML export using the DmlCodeGenerator.py script. Most custom layers and activations do not map gracefully to the DirectML operator set and require custom HLSL to implement, but the script can be customized by modifying either it or the DmlTraits.py library.
In order to ensure compatibility across different runtime environments, DirectML export uses a different runtime framework (NvDml) with no CUDA dependencies. Instead of RefPtr smart pointers for reference management of NvNeural objects, NvDml uses WRL ComPtr smart pointers to manage Windows and Direct3D COM objects. The ResourceUploadBatch class from the DirectX Toolkit is used for transferring groups of resources to the GPU.
NvDml is designed to work within a monolithic application. It is not plugin-aware and does not attempt to provide ABI stability except across COM interfaces. A working knowledge of Direct3D 12 is assumed. Because DirectML does not support changing operator parameters once the associated operator initializer has been created, NvDml is not capable of reshaping networks at runtime. If you wish to modify input sizes or other layer parameters dynamically, you must destroy the network and recreate it when doing so; you should preserve weights' tensors already resident on the GPU to minimize the overhead from recopying static data from disk to the GPU.
Developers should use Microsoft's DirectML redistributable packages from NuGet rather than relying on the versions shipped inside Windows. NuGet packages evolve much more quickly than the inbox libraries, allowing access to newer feature levels of DirectML even on older operating system revisions.
5.3.1. DirectML Exporter Procedure
The DirectML exporter follows this basic procedure to generate DirectML code:
-
Load the network and convert it into a NetworkGraph object representation. This is a simple key-value dictionary mapping layer names to Operator descriptions.
-
Transform element-wise layers with more than two inputs into sequences of two-input element-wise layers, as DirectML does not currently allow arbitrary input counts for its element-wise operators.
-
Separate activation functions into their own operators when the attached layers do not support inline activation in DirectML, or where the activation function is not itself compatible with inline activation.
-
Add slice layers preceding outputs where the output layer is not a trivial forwarder of its input, and remove other layers such as dropout where no inference-time operations are required.
-
Compile a master list of weights used by the operators in the network.
-
Assign intermediate tensor buffers to each operator in the network. Buffers are recycled where possible to reduce the network's memory footprint on the GPU.
-
Write the requested C++ source files.
5.3.2. Built-In DirectML Operators
The details of converting graph operators to DirectML code fragments can be found in the DmlTraits.py module. Every operator class is registered with the DmlTraits library using the @register_operator decorator, and should inherit from either the DmlOperator or DmlActivation classes as appropriate.
Layers should validate their parameters by implementing the validate_operator method, and store necessary data for later use. Raise exceptions when the operator configuration is not exportable.
Layers must calculate their output sizes before NvDml can allocate the necessary intermediate buffers and bind them to operators. Activation functions are assumed to operate in-place and not modify tensor shapes, but most operators should implement the write_reshape_fragment method. Assign an output size for the operator, typically describing it in terms of an input's tensor size.
If the layer relies on weights data or externally-set constants, implement the input_weights or constant_weights methods as appropriate. Input weights are tensors that can be provided from either the weights loader or secondary graph inputs; they are described using InputWeights tuples. Constant weights are typically used only by the batch normalization operator. Constant weights are single scalars repeated out to fill a preset tensor size. The NvDml framework provides a memset shader for fast initialization of these resources.
Layers must generate their own operator creation fragments. This C++ code should construct a DML_SOMETHING_OPERATOR_DESC operator descriptor structure, typically called opSomethingDesc, using any layer-specific parameters and the DML_TENSOR_DESC structures provided for the operator's inputs and weights. The fragment must then create a DML_OPERATOR_DESC variable named opDesc referencing the operator-specific descriptor structure.
Operator initializer and operator evaluation tensor bindings are described using the initializer_input_bindings and execution_input_bindings methods. Return a list of the layer inputs, and any necessary weights, in the order consumed by the DirectML operator. Empty bindings are represented with None. The generated binding tables will automatically create the necessary DML_BUFFER_BINDING and DML_BUFFER_ARRAY_BINDING descriptors from this list.
5.3.3. Custom HLSL Operators
The DirectML exporter and NvDml framework allow for custom operators as well when DirectML has no simple match for the desired layer behavior. Provide a NetworkHostBase::CreateCustomOperator implementation that initializes the relevant std::unique_ptr<CustomOperatorBase> for the operator. You may throw exceptions or return failure HRESULT values as you prefer. A custom operator must support four major operations:
Like built-in operators, custom operators must be able to compute an appropriate output size given inputs. Implement CalculateOutputSize to do this.
Once sized, custom operators may perform other initialization-time work needed inside the InitializeOperator method. Many layers can simply return S_OK from this function if all work is done inside the CPU at construction time and no additional dispatch calls are necessary.
Binding is done with the BindOperator method. Typically a custom operator creates a UAV for each input and output of the shader, storing them in its own descriptor heap.
Finally, inference dispatch is done with the DispatchInference method. The operator should switch to its own descriptor heap, set a root signature and pipeline state, update its compute root descriptor table, dispatch the shader, and insert a UAV resource barrier on its output tensor resource.
See the nvdml_host_integrations.h header for more details on custom operators.
5.4. PyTorch Exporter Details
NvNeural performs PyTorch export using the XMLtoPyTorch.py script. Many custom layers do not map gracefully to the PyTorch built-in operator set and require Python to implement, but the script and its outputs can be customized.
Change the custom_layers.py script to define new layers. Both plugin-defined ILayer objects and model-defined custom layers should be represented in this file. Three functions are necessary:
-
The output_chans function takes a set of input names in comma-delimited-string format (not a tuple or list) and the main layer dictionary as parameters. It should return the number of channels in the layer's output tensor. Batch count is assumed to be one.
-
The import_string function takes the main layer dictionary and should return the fully qualified class name of the layer source. It is used to create fragment of the model import script as in the example below:
convolution=nn.Conv2d space_to_depth=model_support.SpaceToDepth depth_to_space=model_support.DepthToSpace my_layer=MyLibrary.MyLayer
-
The create_op_string function takes the layer name and main layer dictionary and should return a Python source fragment that evaluates to a fully configured instance of the layer. This function is optional; the default maps all layer parameters in the model definition to Python keyword arguments.
Register the three layer definition functions by adding them to the custom_layers dictionary. Your layer is now ready for export.
Create a local copy of the ExportScripts/ToPyTorch directory to avoid modifying files in protected locations like the NVIDIA Nsight Deep Learning Designer subdirectory under Program Files.
Notices
Notice
ALL NVIDIA DESIGN SPECIFICATIONS, REFERENCE BOARDS, FILES, DRAWINGS, DIAGNOSTICS, LISTS, AND OTHER DOCUMENTS (TOGETHER AND SEPARATELY, "MATERIALS") ARE BEING PROVIDED "AS IS." NVIDIA MAKES NO WARRANTIES, EXPRESSED, IMPLIED, STATUTORY, OR OTHERWISE WITH RESPECT TO THE MATERIALS, AND EXPRESSLY DISCLAIMS ALL IMPLIED WARRANTIES OF NONINFRINGEMENT, MERCHANTABILITY, AND FITNESS FOR A PARTICULAR PURPOSE.
Information furnished is believed to be accurate and reliable. However, NVIDIA Corporation assumes no responsibility for the consequences of use of such information or for any infringement of patents or other rights of third parties that may result from its use. No license is granted by implication of otherwise under any patent rights of NVIDIA Corporation. Specifications mentioned in this publication are subject to change without notice. This publication supersedes and replaces all other information previously supplied. NVIDIA Corporation products are not authorized as critical components in life support devices or systems without express written approval of NVIDIA Corporation.