RAPIDS Accelerator with On-prem Cluster or Local Mode#
Spark Deployment Methods#
The way you decide to deploy Spark affects the steps you must take to install and setup Spark and the RAPIDS Accelerator for Apache Spark. The primary methods to deploy Spark are:
Local mode - this is for dev/testing only, not for production
Apache Spark Setup for GPU#
Each GPU node where you are running Spark needs to have the following installed. If you are running with Docker on Kubernetes then skip these as you will do this as part of the docker build.
Install Java 8
Ubuntu:
sudo apt install openjdk-8-jdk-headlessWhile JDK11 is supported by Spark, RAPIDS Accelerator is built and tested with JDK8, so JDK8 is recommended.
Install the GPU driver and CUDA toolkit
Download and install GPU drivers and the CUDA Toolkit. A reboot will be required after installation.
1wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin
2sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
3wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-keyring_1.0-1_all.deb
4sudo dpkg -i cuda-keyring_1.0-1_all.deb
5sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ /"
6sudo apt-get update
7sudo apt-get -y install cuda
You can check if the GPU driver and CUDA toolkit is installed successfully by running the nvidia-smi command.
Below are sections on installing Spark and the RAPIDS Accelerator on a single node. You may want to read the deployment method sections before doing any installations.
Install Spark#
To install Apache Spark please follow the official instructions. Supported versions of Spark are listed on the download page. Please note that only scala version 2.12 is currently supported by the accelerator.
Download the RAPIDS Accelerator jar#
The accelerator jar is available in the download section.
Download the RAPIDS Accelerator for Apache Spark plugin jar. Each jar is for a specific version of CUDA and will not run on other versions. The jars use a classifier to keep them separate.
CUDA 11.x => classifier cuda11
For example, here is a sample version of the jar with CUDA 11.x support:
rapids-4-spark_2.12-23.12.2-cuda11.jar
For simplicity export the location to this jar. This example assumes the
sample jar above has been placed in the /opt/sparkRapidsPlugin
directory:
1export SPARK_RAPIDS_DIR=/opt/sparkRapidsPlugin
2export SPARK_RAPIDS_PLUGIN_JAR=${SPARK_RAPIDS_DIR}/rapids-4-spark_2.12-23.12.2-cuda11.jar
Install the GPU Discovery Script#
If you are using Apache Spark’s GPU scheduling feature please be sure to follow what your cluster administrator recommends. Often this will involve downloading a GPU discovery script and this example will assume as such. Download the getGpusResource.sh script and install it on all the nodes. Put it into a local folder. You may put it in the same directory as the plugin jar (/opt/sparkRapidsPlugin in the example).
Local Mode#
This is for testing/dev setup only. It is not to be used in production. In this mode Spark runs everything in a single process on a single node.
Launch your Spark shell session.
Default configs usually work fine in local mode. The required changes are setting the config spark.plugins to com.nvidia.spark.SQLPlugin and including the jar as a dependency. All of the other config settings and command line parameters are to try and better configure spark for GPU execution.
1$SPARK_HOME/bin/spark-shell \
2 --master local \
3 --num-executors 1 \
4 --conf spark.executor.cores=1 \
5 --conf spark.rapids.sql.concurrentGpuTasks=1 \
6 --driver-memory 10g \
7 --conf spark.rapids.memory.pinnedPool.size=2G \
8 --conf spark.sql.files.maxPartitionBytes=512m \
9 --conf spark.plugins=com.nvidia.spark.SQLPlugin \
10 --jars ${SPARK_RAPIDS_PLUGIN_JAR}
You can run one of the examples below such as the Example Join Operation
Spark Standalone Cluster#
For reference, the Spark documentation is here.
Spark Standalone mode requires starting the Spark master and worker(s). You can run it on a single machine or multiple machines for distributed setup.
The first step is to Install Spark, the RAPIDS Accelerator for Spark jar, and the GPU discovery script on all the nodes you want to use. See the note at the end of this section if using Spark 3.1.1 or above. After that choose one of the nodes to be your master node and start the master. Note that the master process does not need a GPU to function properly.
On the master node:
Make sure
SPARK_HOMEis exportedrun
$SPARK_HOME/sbin/start-master.shThis script will print a message saying starting Master and have a path to a log file. Examine the log file to make sure there are no errors starting the Spark Master process.
export MASTER_HOST=[the hostname of the master]Go to the Spark Master UI to verify it has started. The UI should be accessible at
http://${MASTER_HOST}:8080Find the Spark URL for the Spark Master. This can be found in the Spark Master logs or from the Spark Master UI. It will likely be:
spark://${MASTER_HOST}:7077. You will need this URL for starting the workers and submitting applications.
Now for each worker node:
Setup worker configs on each node
cp $SPARK_HOME/conf/spark-env.sh.template $SPARK_HOME/conf/spark-env.shEdit
$SPARK_HOME/conf/spark-env.shand add any worker options. The example below sets the number of GPUs per worker to 4 and points to the discovery script. Change this for your setup.SPARK_WORKER_OPTS="-Dspark.worker.resource.gpu.amount=4 -Dspark.worker.resource.gpu.discoveryScript=/opt/sparkRapidsPlugin/getGpusResources.sh"
Start the worker(s)
For multiple workers:
You can add each hostname to the file
$SPARK_HOME/conf/workersand use the scripts provided by Spark to start all of them. This requires password-less ssh to be setup. If you do not have a password-less setup, you can set the environment variableSPARK_SSH_FOREGROUNDand serially provide a password for each worker.Run
$SPARK_HOME/sbin/start-workers.sh
For a single worker:
$SPARK_HOME/sbin/start-worker.sh spark://${MASTER_HOST}:7077
Now you can go to the master UI at http://${MASTER_HOST}:8080 and verify all the workers have started.
Submitting a Spark application to a standalone mode cluster requires a few configs to be set. These configs can be placed in the Spark default confs if you want all jobs to use the GPU. The plugin requires its jar to be in the executor classpath. GPU scheduling also requires the Spark job to ask for GPUs. The plugin cannot utilize more than one GPU per executor.
In this case we are asking for 1 GPU per executor (the plugin cannot utilize more than one), and 4 CPU tasks per executor (but only one task will be on the GPU at a time). This allows for overlapping I/O and computation.
1$SPARK_HOME/bin/spark-shell \
2 --master spark://${MASTER_HOST}:7077 \
3 --conf spark.executor.extraClassPath=${SPARK_RAPIDS_PLUGIN_JAR} \
4 --conf spark.driver.extraClassPath=${SPARK_RAPIDS_PLUGIN_JAR} \
5 --conf spark.rapids.sql.concurrentGpuTasks=1 \
6 --driver-memory 2G \
7 --conf spark.executor.memory=4G \
8 --conf spark.executor.cores=4 \
9 --conf spark.task.cpus=1 \
10 --conf spark.executor.resource.gpu.amount=1 \
11 --conf spark.task.resource.gpu.amount=0.25 \
12 --conf spark.rapids.memory.pinnedPool.size=2G \
13 --conf spark.sql.files.maxPartitionBytes=512m \
14 --conf spark.plugins=com.nvidia.spark.SQLPlugin
Please note that the RAPIDS Accelerator for Apache Spark plugin jar does not need to be installed on all the nodes and the configs spark.executor.extraClassPath and spark.driver.extraClassPath can be replaced in the above command with --jars ${SPARK_RAPIDS_PLUGIN_JAR}. This will automatically distribute the jar to the nodes for you.
Running on YARN#
YARN requires you to Install Spark, the RAPIDS Accelerator for Spark jar, and the GPU discovery script on a launcher node. YARN handles shipping them to the cluster nodes as needed. If you want to use the GPU scheduling feature in Spark it requires YARN version >= 2.10 or >= 3.1.1 and ideally you would use >= 3.1.3 in order to get support for nvidia-docker version 2.
It is recommended to run your YARN cluster with Docker, cgroup isolation and GPU scheduling enabled. This way your Spark containers run isolated and can only see the GPUs that were requested. If you do not run in an isolated environment then you need to ensure you run on hosts that have GPUs and there is a mechanism that allows you to allocate GPUs when the GPUs are in process-exclusive mode. See the nvidia-smi documentation for more details on setting up process-exclusive mode. If you have a pre-existing method for allocating GPUs and dealing with multiple applications you could write your own custom discovery class to deal with that.
This assumes you have YARN already installed and set up. Setting up a YARN cluster is not covered in these instructions. Spark must have been built specifically for the Hadoop/YARN version you use - either 3.x or 2.x.
YARN GPU scheduling does not support MIG enabled GPUs by default, see section MIG GPU on YARN on how to add support.
YARN 3.1.3 with Isolation and GPU Scheduling Enabled#
Configure YARN to support GPU scheduling and isolation.
Install Spark, the RAPIDS Accelerator for Spark jar, and the GPU discovery script on the node from which you are launching your Spark application.
Use the following configuration settings when running Spark on YARN, changing the values as necessary:
1$SPARK_HOME/bin/spark-shell \
2 --master yarn \
3 --conf spark.rapids.sql.concurrentGpuTasks=1 \
4 --driver-memory 2G \
5 --conf spark.executor.memory=4G \
6 --conf spark.executor.cores=4 \
7 --conf spark.executor.resource.gpu.amount=1 \
8 --conf spark.task.cpus=1 \
9 --conf spark.task.resource.gpu.amount=0.25 \
10 --conf spark.rapids.memory.pinnedPool.size=2G \
11 --conf spark.sql.files.maxPartitionBytes=512m \
12 --conf spark.plugins=com.nvidia.spark.SQLPlugin \
13 --conf spark.executor.resource.gpu.discoveryScript=./getGpusResources.sh \
14 --files ${SPARK_RAPIDS_DIR}/getGpusResources.sh \
15 --jars ${SPARK_RAPIDS_PLUGIN_JAR}
YARN 2.10 with Isolation and GPU Scheduling Enabled#
Configure YARN to support GPU scheduling and isolation
Install Spark, the RAPIDS Accelerator for Spark jar, and the GPU discovery script on the node from which you are launching your Spark application.
Use the following configs when running Spark on YARN, changing the values as necessary:
1$SPARK_HOME/bin/spark-shell \
2 --master yarn \
3 --conf spark.rapids.sql.concurrentGpuTasks=1 \
4 --driver-memory 2G \
5 --conf spark.executor.memory=4G \
6 --conf spark.executor.cores=4 \
7 --conf spark.task.cpus=1 \
8 --conf spark.task.resource.gpu.amount=0.25 \
9 --conf spark.rapids.memory.pinnedPool.size=2G \
10 --conf spark.sql.files.maxPartitionBytes=512m \
11 --conf spark.plugins=com.nvidia.spark.SQLPlugin \
12 --conf spark.executor.resource.gpu.amount=1 \
13 --conf spark.executor.resource.gpu.discoveryScript=./getGpusResources.sh \
14 --files ${SPARK_RAPIDS_DIR}/getGpusResources.sh \
15 --jars ${SPARK_RAPIDS_PLUGIN_JAR}
YARN without Isolation#
If you run YARN without isolation then you can run the RAPIDS Accelerator for Spark as long as you run your Spark application on nodes with GPUs and the GPUs are configured in EXCLUSIVE_PROCESS mode. Without this, there would need to be a mechanism to ensure that only one executor is accessing a GPU at once. Note it does not matter if GPU scheduling support is enabled.
On all your YARN nodes, ensure the GPUs are in
EXCLUSIVE_PROCESSmode:Run
nvidia-smito see how many GPUs and get the indexes of the GPUsForeach GPU index set it to
EXCLUSIVE_PROCESSmode:nvidia-smi -c EXCLUSIVE_PROCESS -i $index
Install Spark, the RAPIDS Accelerator for Spark jar, and the GPU discovery script on the node from which you are launching your Spark application.
Use the following configs when running Spark on YARN. Note that we are configuring a resource discovery plugin. Spark will first try to discover the GPUs using this plugin and then fall back to the discovery script if this doesn’t work. This plugin knows how to atomically acquire a GPU in process exclusive mode and expose it to the tasks.
1$SPARK_HOME/bin/spark-shell \
2 --master yarn \
3 --conf spark.rapids.sql.concurrentGpuTasks=1 \
4 --driver-memory 2G \
5 --conf spark.executor.memory=4G \
6 --conf spark.executor.cores=4 \
7 --conf spark.task.cpus=1 \
8 --conf spark.task.resource.gpu.amount=0.25 \
9 --conf spark.rapids.memory.pinnedPool.size=2G \
10 --conf spark.sql.files.maxPartitionBytes=512m \
11 --conf spark.plugins=com.nvidia.spark.SQLPlugin \
12 --conf spark.resources.discoveryPlugin=com.nvidia.spark.ExclusiveModeGpuDiscoveryPlugin \
13 --conf spark.executor.resource.gpu.amount=1 \
14 --conf spark.executor.resource.gpu.discoveryScript=./getGpusResources.sh \
15 --files ${SPARK_RAPIDS_DIR}/getGpusResources.sh \
16 --jars ${SPARK_RAPIDS_PLUGIN_JAR}
MIG GPU on YARN#
Using MIG enabled GPUs on YARN requires enabling YARN GPU scheduling and using NVIDIA Docker runtime v2. The way to set this up depends on the version of YARN and the version of Spark. It is important to note that CUDA 11 only supports enumeration of a single MIG instance. This means that using any MIG device on YARN means only 1 GPU per container is allowed. See the limitations section in the documentation referred to below for the specific YARN version you are using.
YARN version 3.3.0+#
YARN version 3.3.0 and newer support a pluggable device framework which allows adding support for MIG devices via a plugin. See NVIDIA GPU Plugin for YARN with MIG support for YARN 3.3.0+. If you are using that plugin with a Spark version older than 3.2.1 and/or specifying the resource as nvidia/miggpu you will also need to specify the config:
--conf spark.rapids.gpu.resourceName=nvidia/miggpu
This tells the RAPIDS Accelerator for Apache Spark plugin to look for the Spark GPU resource assigned to it using the name nvidia/miggpu. If you are using the Spark config spark.yarn.resourceGpuDeviceName and using the normal gpu Spark resource name, this is not required.
YARN version 3.1.2 until 3.3.0#
If you are using YARN version from 3.1.2 up until 3.3.0, it requires making modifications to YARN and deploying a version that adds support for MIG to the built-in YARN GPU resource plugin.
See NVIDIA Support for GPU for YARN with MIG support for YARN 3.1.2 until YARN 3.3.0 for details.
Running on Kubernetes#
Please refer to Getting Started with RAPIDS and Kubernetes.
RAPIDS Accelerator Configuration and Tuning#
Most of what you need you can get from tuning guide.
The following configs will help you to get started but must be configured based on your cluster and application.
If you are using the KryoSerializer with Spark, e.g.:
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer, you will have to register the GpuKryoRegistrator class, e.g.:--conf spark.kryo.registrator=com.nvidia.spark.rapids.GpuKryoRegistrator.Configure the amount of executor memory like you would for a normal Spark application. If most of the job will run on the GPU then often you can run with less executor heap memory than would be needed for the corresponding Spark job on the CPU.
In case of a “com.esotericsoftware.kryo.KryoException: Buffer overflow” error it is advisable to increase the spark.kryoserializer.buffer.max setting to a value higher than the default.
Example Command Running on YARN#
1$SPARK_HOME/bin/spark-shell --master yarn \
2 --num-executors 1 \
3 --conf spark.plugins=com.nvidia.spark.SQLPlugin \
4 --conf spark.executor.cores=6 \
5 --conf spark.rapids.sql.concurrentGpuTasks=2 \
6 --executor-memory 20g \
7 --conf spark.executor.memoryOverhead=10g \
8 --conf spark.rapids.memory.pinnedPool.size=8G \
9 --conf spark.sql.files.maxPartitionBytes=512m \
10 --conf spark.executor.resource.gpu.discoveryScript=./getGpusResources.sh \
11 --conf spark.task.resource.gpu.amount=0.166 \
12 --conf spark.executor.resource.gpu.amount=1 \
13 --files $SPARK_RAPIDS_DIR/getGpusResources.sh
14 --jars ${SPARK_RAPIDS_PLUGIN_JAR}
Example Join Operation#
Once you have started your Spark shell you can run the following commands to do a basic join and look at the UI to see that it runs on the GPU.
1val df = sc.makeRDD(1 to 10000000, 6).toDF
2val df2 = sc.makeRDD(1 to 10000000, 6).toDF
3df.select( $"value" as "a").join(df2.select($"value" as "b"), $"a" === $"b").count
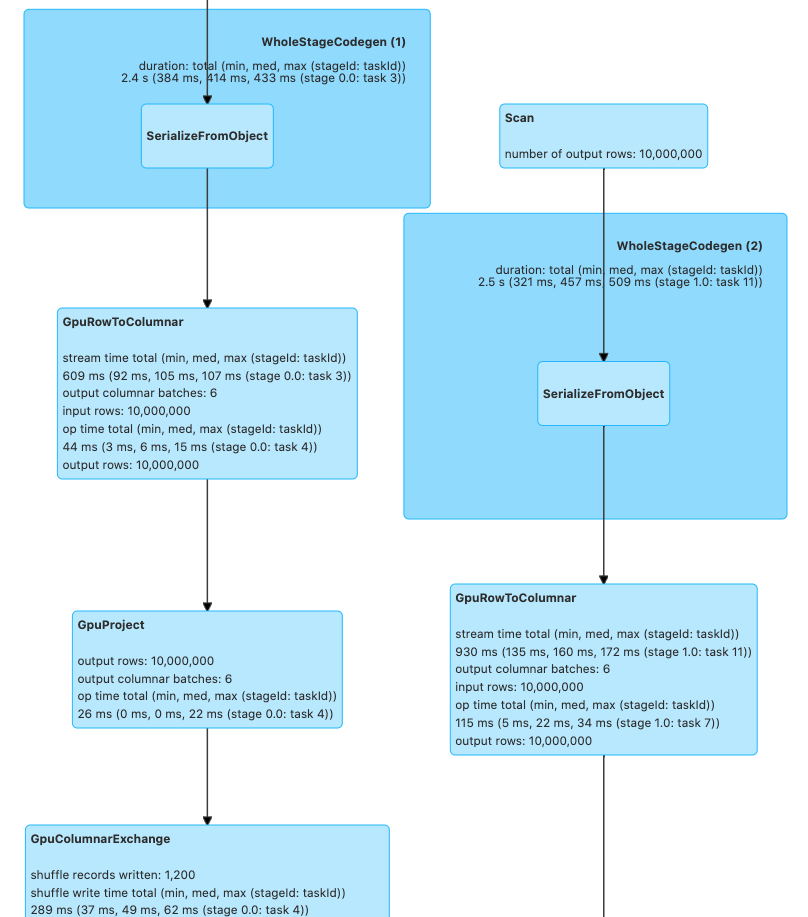
Go to the Spark UI and click on the application you ran and on the “SQL” tab. If you click the operation “count at …”, you should see the graph of Spark Execs and some of those should have the label Gpu. For instance, in the screenshot below you will see GpuRowToColumn, GpuProject, and GpuColumnarExchange. Those correspond to operations that run on the GPU.
Enabling RAPIDS Shuffle Manager#
The RAPIDS Shuffle Manager is an implementation of the ShuffleManager interface in Apache Spark that allows custom mechanisms to exchange shuffle data, enabling Remote Direct Memory Access (RDMA) and peer-to-peer communication between GPUs (NVLink/PCIe), by leveraging Unified Communication X (UCX).
You can find out how to enable the accelerated shuffle in the RAPIDS Shuffle Manager documentation.
Advanced Configuration#
See the RAPIDS Accelerator for Apache Spark Configuration Guide for details on all of the configuration settings specific to the RAPIDS Accelerator for Apache Spark.
Monitoring#
Since the plugin runs without any API changes, the easiest way to see what is running on the GPU is to look at the “SQL” tab in the Spark web UI. The SQL tab only shows up after you have actually executed a query. Go to the SQL tab in the UI, click on the query you are interested in and it shows a DAG picture with details. You can also scroll down and twisty the “Details” section to see the text representation.
If you want to look at the Spark plan via the code you can use the explain() function call. For example: if query is the resulting DataFrame from the query then query.explain() will print the physical plan from Spark. From the query’s physical plan you can see what nodes were replaced with GPU calls.
The following is an example of a physical plan with operators running on the GPU:
1== Physical Plan ==
2GpuColumnarToRow false
3+- GpuProject [cast(c_customer_sk#0 as string) AS c_customer_sk#40]
4 +- GpuFileGpuScan parquet [c_customer_sk#0] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex[file:/tmp/customer], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<c_customer_sk:int>
Debugging#
For now, the best way to debug is how you would normally do it on Spark. Look at the UI and log files to see what failed. If you got a segmentation fault from the GPU find the hs_err_pid.log file. To make sure your hs_err_pid.log file goes into the YARN application log dir you
can add in the config: --conf spark.executor.extraJavaOptions="-XX:ErrorFile=<LOG_DIR>/hs_err_pid_%p.log"
If you want to see why an operation did not run on the GPU you can turn on the configuration: --conf spark.rapids.sql.explain=NOT_ON_GPU. A log message will then be emitted to the driver log as to why a Spark operation is not able to run on the GPU.
Out of GPU Memory#
GPU out of memory errors can show up in multiple ways. You can see an error that it out of memory or it can also manifest as crashes. Generally this means your partition size is too big. In that case go back to the Configuration section for the partition size and/or the number of partitions. Possibly reduce the number of concurrent GPU tasks to 1. The Spark UI may give you a hint at the size of the data. Look at either the input data or the shuffle data size for the stage that failed.