Building LangChain-Based Bots
In this section, let’s build a bot that uses a LangChain runnable to drive the conversation. We will build a LangChain agent that performs DuckDuckGo searches and answers questions in the context of the conversation. You can swap out this agent with their own chains/agents in this tutorial. You can learn about LangChain Runnable Interface, LangServe, LangGraph, and a few other terminologies mentioned by following LangChain Documentation.
The interaction with the LangChain runnable will happen via a custom Plugin server. In this tutorial, we will define a LangChain runnable directly in the custom Plugin server. However, you can also choose to deploy your LangChain runnables via LangServe and have your custom Plugins interact with the LangServe APIs using remote runnables.
The minimal file structure of the LangChain bot looks like this:
my_bots └── langchain_bot └── plugin └── langchain_agent.py └── schemas.py └── plugin_config.yaml └── speech_config.yaml └── model_config.yaml
For the LangChain or custom RAG pipelines that do not require processing or guardrailing with Colang, you can directly connect the Chat Controller to the Plugin server. Follow the plugin server architecture section for more information. We will demonstrate this approach below.
Creating the LangChain Plugin
In this section, let’s build the custom LangChain Plugin and test it as a standalone component.
Define the input and output API schemas used by ACE Agent for communication with the Plugin server and Chat Controller. Update
plugin/schemas.pywith the following contents.from pydantic import BaseModel, Field from typing import Optional, Dict, List, Any class ChatRequest(BaseModel): Query: Optional[str] = Field(default="", description="The user query which needs to be processed.") UserId: str = Field( description="Mandatory unique identifier to recognize which user is interacting with the Chat Engine." ) class EventRequest(BaseModel): EventType: str = Field(default="", description="The event name which needs to be processed.") UserId: str = Field( description="Mandatory unique identifier to recognize which user is interacting with the Chat Engine." ) class ResponseField(BaseModel): Text: str = Field( default="", description="Text response to be sent out. This field will also be picked by a Text to Speech Synthesis module if enabled for speech based bots.", ) CleanedText: str = Field( default="", description="Text response from the Chat Engine with all SSML/HTML tags removed." ) NeedUserResponse: Optional[bool] = Field( default=True, description="This field can be used by end user applications to deduce if user response is needed or not for a dialog initiated query. This is set to true automatically if form filling is active and one or more slots are missing.", ) IsFinal: bool = Field( default=False, description="This field to indicate the final response chunk when streaming. The chunk with IsFinal=true will contain the full Chat Engine response attributes.", ) class ChatResponse(BaseModel): UserId: str = Field( default="", description="Unique identifier to recognize which user is interacting with the Chat Engine. This is populated from the request JSON.", ) QueryId: str = Field( default="", description="Unique identifier for the user query assigned automatically by the Chat Engine unless specified in request JSON.", ) Response: ResponseField = Field( default=ResponseField(), description="Final response template from the Chat Engine. This field can be picked up from domain rule files or can be formulated directly from custom plugin modules.", ) Metadata: Optional[Dict[str, Any]] = Field( default={"SessionId": "", "StreamId": ""}, description="Any additional information related to the request.", ) class EventResponse(BaseModel): UserId: str = Field( default="", description="Unique identifier to recognize which user is interacting with the Chat Engine. This is populated from the request JSON.", ) Events: List[Dict[str, Any]] = Field( default=[], description="The generated event list for the provided EventType from Chat Engine." ) Response: ResponseField = Field( default=ResponseField(), description="Final response template from the Chat Engine. This field can be picked up from domain rule files or can be formulated directly from custom plugin modules.", )
Let’s understand the APIs and their schemas a little. There are two APIs used by the Chat Controller microservice:
/chatand/event.Events such as pipeline creation and deletion are sent by the Chat Controller to the
/eventendpoint. In most cases, you will not need to modify the default/eventendpoint that we will define in the next step.User questions are sent by the Chat Controller to the
/chatendpoint, along with theUserIdand an optionalQueryId. The response schema for this API contains aResponseattribute, which contains the details of the response. In this tutorial, we only need to manage two sub-fields:Response.Text(which contains the chunk that we are streaming) andResponse.IsFinal(which indicates whether the stream is complete).
Create the actual custom Plugin with the LangChain agent and the
/chatand/eventAPIs. Updateplugin/langchain_agent.pywith the following code:from fastapi import APIRouter, status, Body, Response from fastapi.responses import StreamingResponse import logging import os import sys from typing_extensions import Annotated from typing import Union, Dict import json from langchain_community.chat_models import ChatOpenAI from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder from langchain_core.output_parsers import StrOutputParser from langchain_core.runnables.history import RunnableWithMessageHistory from langchain.memory import ChatMessageHistory from langchain.tools.ddg_search import DuckDuckGoSearchRun from langchain_core.runnables import ( RunnableParallel, RunnablePassthrough, ) from langchain.tools import tool logger = logging.getLogger("plugin") router = APIRouter() sys.path.append(os.path.dirname(__file__)) from schemas import ChatRequest, EventRequest, EventResponse, ChatResponse EVENTS_NOT_REQUIRING_RESPONSE = [ "system.event_pipeline_acquired", "system.event_pipeline_released", "system.event_exit", ] duckduckgo = DuckDuckGoSearchRun() @tool def ddg_search(query: str): """Performs a duckduck go search""" logger.info(f"Input to DDG: {query}") answer = duckduckgo.run(query) logger.info(f"Answer from DDG: {answer}") return answer rephraser_prompt = ChatPromptTemplate.from_messages( [ ( "system", f"You are an assistant whose job is to rephrase the question into a standalone question, based on the conversation history." f"The rephrased question should be as short and simple as possible. Do not attempt to provide an answer of your own!", ), MessagesPlaceholder(variable_name="history"), ("human", "{query}"), ] ) wiki_prompt = ChatPromptTemplate.from_messages( [ ( "system", "Answer the given question from the provided context. Only use the context to form an answer.\nContext: {context}", ), ("user", "{query}"), ] ) chat_history_map = {} llm = ChatOpenAI() output_parser = StrOutputParser() chain = ( rephraser_prompt | llm | output_parser | RunnableParallel({"context": ddg_search, "query": RunnablePassthrough()}) | wiki_prompt | llm | output_parser ) chain_with_history = RunnableWithMessageHistory( chain, lambda session_id: chat_history_map.get(session_id), input_messages_key="query", history_messages_key="history", ) @router.post( "/chat", status_code=status.HTTP_200_OK, ) async def chat( request: Annotated[ ChatRequest, Body( description="Chat Engine Request JSON. All the fields populated as part of this JSON is also available as part of request JSON." ), ], response: Response, ) -> StreamingResponse: """ This endpoint can be used to provide response to query driven user request. """ req = request.dict(exclude_none=True) logger.info(f"Received request JSON at /chat endpoint: {json.dumps(req, indent=4)}") try: session_id = req["UserId"] question = req["Query"] if session_id not in chat_history_map: chat_history_map[session_id] = ChatMessageHistory(messages=[]) def generator(question: str, session_id: str): full_response = "" if question: for chunk in chain_with_history.stream( {"query": question}, config={"configurable": {"session_id": session_id}} ): if not chunk: continue full_response += chunk json_chunk = ChatResponse() json_chunk.Response.Text = chunk json_chunk = json.dumps(json_chunk.dict()) yield json_chunk json_chunk = ChatResponse() json_chunk.Response.IsFinal = True json_chunk.Response.CleanedText = full_response json_chunk = json.dumps(json_chunk.dict()) yield json_chunk return StreamingResponse(generator(question, session_id), media_type="text/event-stream") except Exception as e: response.status_code = status.HTTP_500_INTERNAL_SERVER_ERROR return {"StatusMessage": str(e)} @router.post("/event", status_code=status.HTTP_200_OK) async def event( request: Annotated[ EventRequest, Body( description="Chat Engine Request JSON. All the fields populated as part of this JSON is also available as part of request JSON." ), ], response: Response, ) -> Union[EventResponse, Dict[str, str]]: """ This endpoint can be used to provide response to an event driven user request. """ req = request.dict(exclude_none=True) logger.info(f"Received request JSON at /event endpoint: {json.dumps(req, indent=4)}") try: resp = EventResponse() resp.UserId = req["UserId"] resp.Response.IsFinal = True if req["EventType"] in EVENTS_NOT_REQUIRING_RESPONSE: resp.Response.NeedUserResponse = False return resp except Exception as e: response.status_code = status.HTTP_500_INTERNAL_SERVER_ERROR return {"StatusMessage": str(e)}
Let’s understand the above code.
The
ddg_searchtool takes in the query, performs a DuckDuckGo search, and returns the top responses.The
rephraser_promptis used to rephrase the current question into a single, simple question based on the conversation history, represented by thehistoryplaceholder.The
chainrunnable performs rephrasing of the query, passes the rephrased to theddg_searchtool, and finally calls the LLM again to fetch the answer from the DuckDuckGo search results.The
chain_with_historyis the actual runnable that we will be using to generate answers. It fetches the correct conversation history based on thesession_idand populates therephraser_promptwith the right inputs.Finally, the
/chatendpoint invokes thechain_with_historywith the right inputs. In this case, we return a generator where we call thestreammethod of the runnable, format the response into theChatResponseschema, and push the chunk into the response stream.
If you are using a custom LangChain runnable or if you want to modify the way you call the runnable, you will only need to make changes in the
generatormethod.Register this plugin. Add the following to
plugin_config.yaml.config: workers: 1 timeout: 30 plugins: - name: langchain path: ./plugin/langchain_agent.py
Add the Python dependencies used by this runnable in
deploy/docker/dockerfiles/plugin_server.Dockerfile. This will install the custom dependencies when the Plugin server is being built.############################## # Install custom dependencies ############################## RUN pip install langchain==0.1.1 \ langchain-community==0.0.13 \ langchain-core==0.1.12 \ duckduckgo-search==5.3.1b1
Note
If you see a crash in the plugin server or an issue with fetching a response from DuckDuckGo, try using a more recent duckduckgo-search version.
Deploy the Plugin server for testing.
Set the OpenAI API key if it is not already set.
export OPENAI_API_KEY=...
Run the bot using the Docker Environment.
export BOT_PATH=./my_bots/langchain_bot/ source deploy/docker/docker_init.sh docker compose -f deploy/docker/docker-compose.yml up --build plugin-server -d
We can test the endpoint by running the following CURL command:
curl -X 'POST' \ 'http://localhost:9002/langchain/chat' \ -H 'accept: application/json' \ -H 'Content-Type: application/json' \ -d '{ "Query": "Who is the president of the United States?", "UserId": "user1" }'
After you are done testing the plugin, to stop the server, run:
docker compose -f deploy/docker/docker-compose.yml down
Connecting the Plugin to the Chat Controller
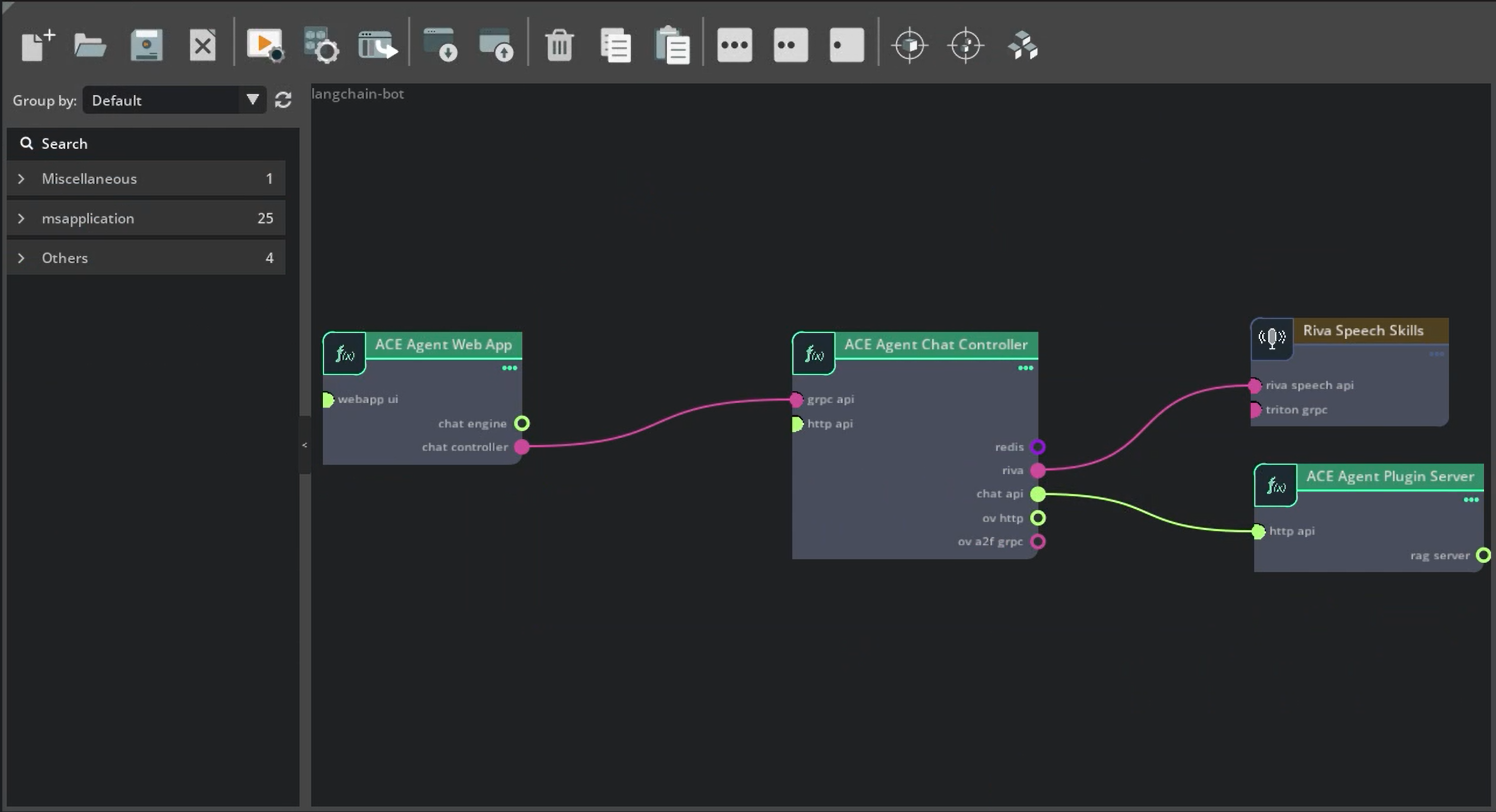
Now that the Plugin is functional, let’s create the configs to connect the Chat Controller to the Plugin server, as well as enable speech.
Copy the
model_config.yamlandspeech_config.yamlfiles fromsamples/chitchat_bot. They represent the common settings for a speech pipeline.Update the
serverURL in thedialog_managercomponent to point to the plugin we created in the previous section.dialog_manager: DialogManager: server: "http://localhost:9002/langchain" use_streaming: true
With this change, the Chat Controller will directly call the
/chatand/eventendpoints of the Plugin server.Deploy the bot using the Docker environment.
Set environment variables required for the
docker-compose.ymlfile.export BOT_PATH=./my_bots/langchain_bot/ source deploy/docker/docker_init.sh
Deploy the Riva ASR and TTS speech models.
docker compose -f deploy/docker/docker-compose.yml up model-utils-speech
Deploy the Plugin server with LangChain plugin.
docker compose -f deploy/docker/docker-compose.yml up --build plugin-server -d
Deploy the Chat Controller microservice with the gRPC interface.
docker compose -f deploy/docker/docker-compose.yml up chat-controller -d
Deploy the speech sample frontend application.
docker compose -f deploy/docker/docker-compose.yml up frontend-speech
Notice that we are not deploying the Chat Engine microservice at all.
You can interact with the bot using your browser at
http://<YOUR_IP_ADDRESS>:9001.
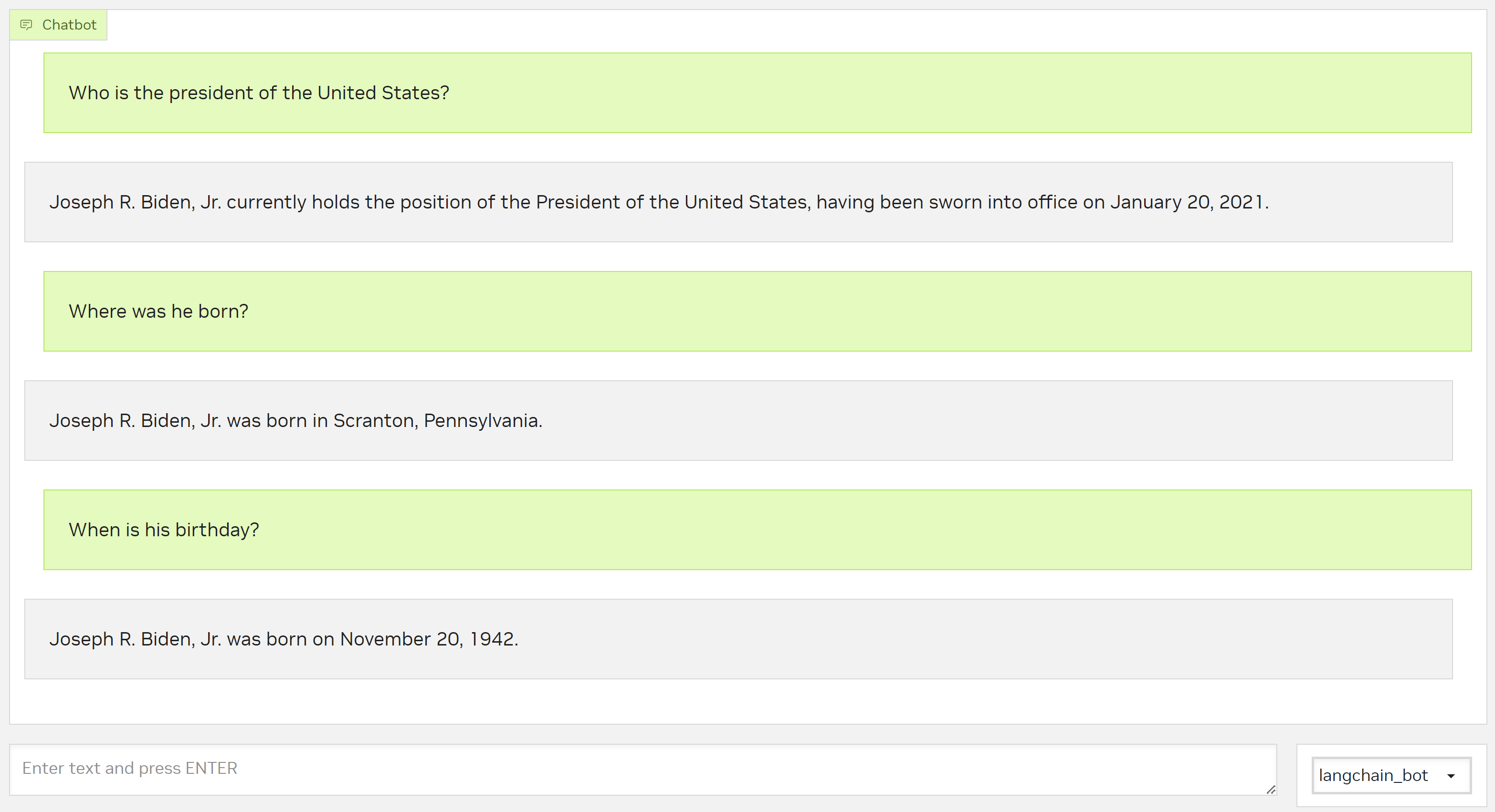
Here’s an example dialog with the bot.
Connecting the Plugin to the Chat Engine
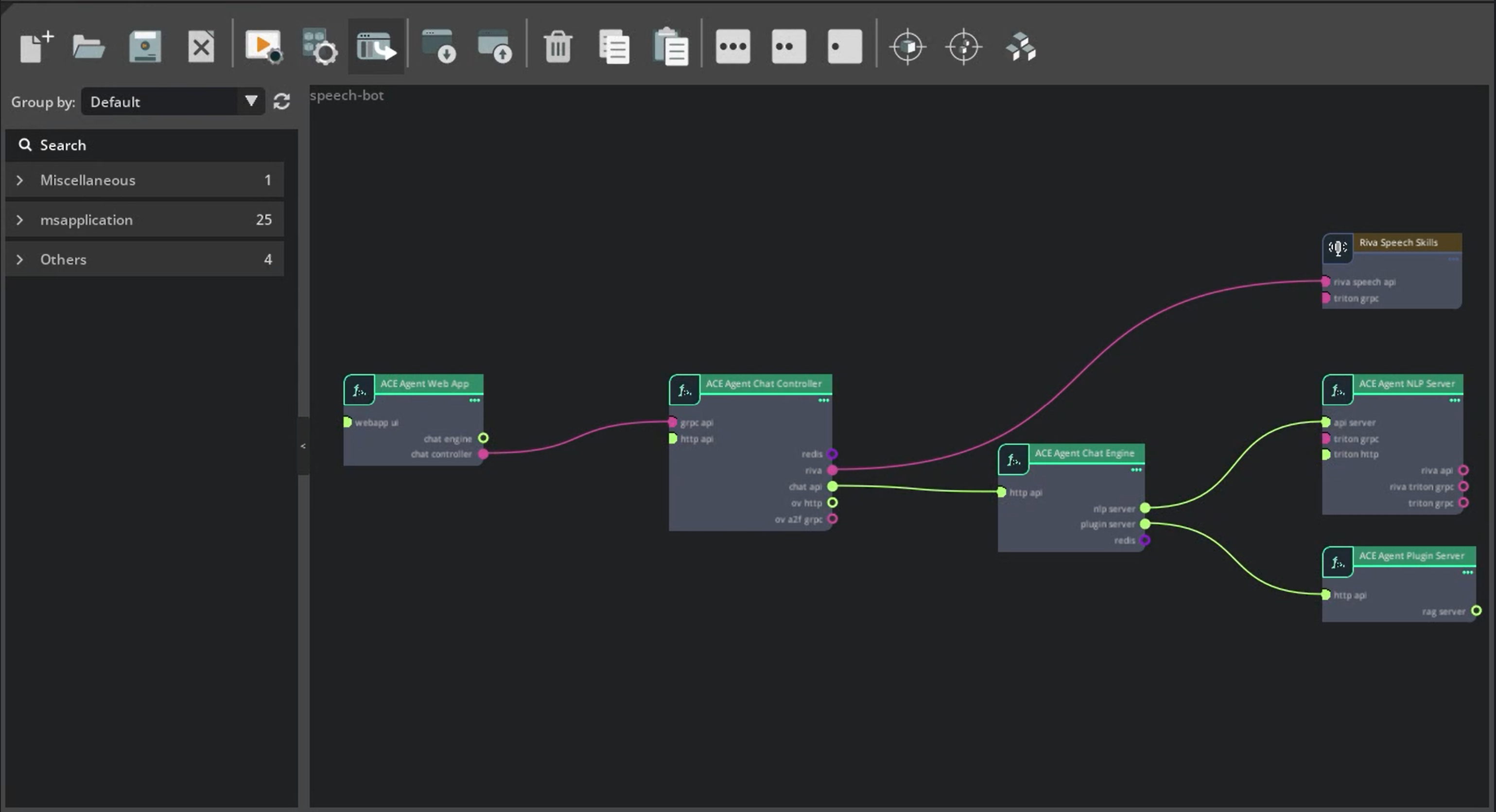
You can add guardrails to the bot or add any custom logic in Colang to your LangChain bot by creating the configurations needed for the Chat Engine and connecting the Plugin server to the Chat Engine using the Chat Engine Server Architecture.
Creating the Bot and Colang Configurations
bot_config.yaml is the configuration entry point for any bot. Let’s create this file and add a few important configuration parameters.
Give the bot a name. In
bot_config.yaml, you need to add a unique name of the bot on top of the file. Let’s stick with the namelangchain_bot.bot: langchain_bot
All the intelligence in our LangChain bot will be present in the Plugin. Since our Colang configs are only meant to route the queries to the plugin, let’s keep the model section empty.
models: []
Create a Colang file called
flows.co, which will contain all the Colang logic. Let’s updateflows.coto route all queries to the LangChain plugin.define flow user ... $answer = execute chat_plugin(\ endpoint="langchain/chat",\ ) bot respond define bot respond "{{$answer}}"
The above flow routes all user utterances to a POST endpoint called
/generatein a plugin calledlangchain. It passes the user’s question as well as asession_idto the endpoint as request parameters.Note
If you want to add more complicated logic in Colang, you must update
flows.coand possibly the bot config file according to your use case. Refer to Using Colang or Building a Bot using Colang 1.0 for more information.Change the server URL for the
dialog_managercomponent to connect the Chat Engine microservice inspeech_config.yaml.dialog_manager: DialogManager: server: "http://localhost:9000" use_streaming: true
Testing the Bot
Set the OpenAI API key if it is not already set.
export OPENAI_API_KEY=...
Run the bot in gRPC Interface using Docker Environment.
Set the environment variables required for the
docker-compose.ymlfile.export BOT_PATH=./my_bots/langchain_bot/ source deploy/docker/docker_init.sh
Deploy the Riva ASR and TTS speech models.
docker compose -f deploy/docker/docker-compose.yml up model-utils-speech
Deploy the ACE Agent microservices. Deploy the Chat Controller, Chat Engine, Plugin server, and NLP server microservices. The NLP server will not have any models deployed for this bot.
docker compose -f deploy/docker/docker-compose.yml up --build speech-bot -d
Interact with the bot using the Speech sample frontend application.
docker compose -f deploy/docker/docker-compose.yml up frontend-speech
You can interact with the bot using your browser at
http://<YOUR_IP_ADDRESS>:9001.