Technical Brief
As the global service economy grows, companies rely increasingly on contact centers to address customer concerns. Contact centers can benefit from transcriptions of customer conversations during a call and leverage the information long after the calls are completed. Product teams at the companies which the contact centers represent can then mine batches of call transcripts for sentiment analysis, market segmentation, etc. Contact centers also benefit from integrating text-to-speech (TTS) into their conversational application pipelines. Playing answers to common questions helps the caller, but contact center employees can’t possibly record responses to every contingency in advance. With TTS combined with natural language processing (NLP) tasks such as dialog management and question answering, a contact center can deploy an AI based-solution with a natural-sounding voice to address callers’ concerns.
To reduce the time to develop an intelligent virtual assistant for a contact center, NVIDIA has developed two workflows centered around Speech AI:
- Audio Transcription
- Intelligent Virtual Assistant
The audio transcription solution demonstrates how to use NVIDIA Riva AI Services, specifically automatic speech recognition (ASR) for transcription.
The intelligent virtual assistant integrates ASR and TTS into the conversational application pipelines by illustrating how to combine Riva services with third party open-source NLP services like Haystack and open-source dialog managers like Rasa.
These workflows provide a reference for you to get started and build your own AI solution with minimal preparation, and include enterprise-ready implementation best practices which range from authentication, monitoring, reporting, and load balancing, helping you achieve the desired AI outcome more quickly while still allowing a path for you to deviate.
Both workflows each contain:
Training and inference pipelines for Audio Transcription and Intelligent Virtual Assistant.
A reference for solution deployment in production, includes components like authentication, logging and monitoring the workflow.
Cloud Native deployable bundle packaged as helm charts
Guidance on performing training and customization of the AI solution to fit your specific use case
NVIDIA AI Workflows are designed as microservices, which means they can be deployed on Kubernetes alone or with other microservices to create a production-ready application for seamless scaling in your Enterprise environment.
These components and instructions used in the workflow are intended to be used as examples for integration, and may not be sufficiently production-ready on their own as stated. The workflow should be customized and integrated into one’s own infrastructure, using the workflow as reference.
Audio transcription uses the Riva ASR AI service to enable the AI to provide contextual insights, measure sentiment, and recommend the best action to the agent, ensuring a great personalized customer experience. Within the audio transcription AI workflow solution, we will highlight how to both customize Riva ASR and deploy and integrate it into a reference enterprise-ready solution. The audio transcription workflow components are packaged together into a deployable solution described in diagram below:

These components are used to build and deploy training and inference pipelines, integrated together with the additional components as indicated in the below diagram:

More information about the components used can be found in the Audio Transcription Workflow Guide and the NVIDIA Cloud Native Service Add-on Pack Deployment Guide.
Training Pipeline
A sample training pipeline is provided to fine-tune the models used by Riva for ASR services.
Riva ASR customization
Riva ASR can be customized to improve the recognition of spoken words. This can be done at various stages (training and inference) of the ASR pipeline. The following diagram describes where customization can occur:

The audio transcription solution adds Riva customization for a domain-specific use case i.e Financial Services Industry (FSI). Following is the set of customizations for the Riva transcription ASR microservice:
- Lexicon Mapping for Financial Services Jargon
- Fine-Tuning the Riva English Language Model on a Financial Services Dataset
- Fine-Tuning the Acoustic Model on SPGI Financial Dataset
Explicitly guides the decoder to map pronunciations (that is, token sequences) to specific words. The lexicon decoder emits words that are present in the decoder lexicon. It is possible to modify the lexicon used by the decoder to improve recognition. (Labeled #2 and #3 in the diagram above)
Trains a new language model for the application domain to improve the recognition of domain-specific terms. The Riva ASR pipeline supports the use of n-gram language models. Using a language model that is tailored to your use case can greatly help in improving the accuracy of transcripts. (Labeled #4 in the diagram above)
Fine-tunes an existing acoustic model using a small amount of SPGI financial dataset to better suit the financial domain. (Labeled #5 in the diagram above)
The above customizations are performed by NVIDIA TAO Toolkit, using a sample pipeline described in the diagram below:
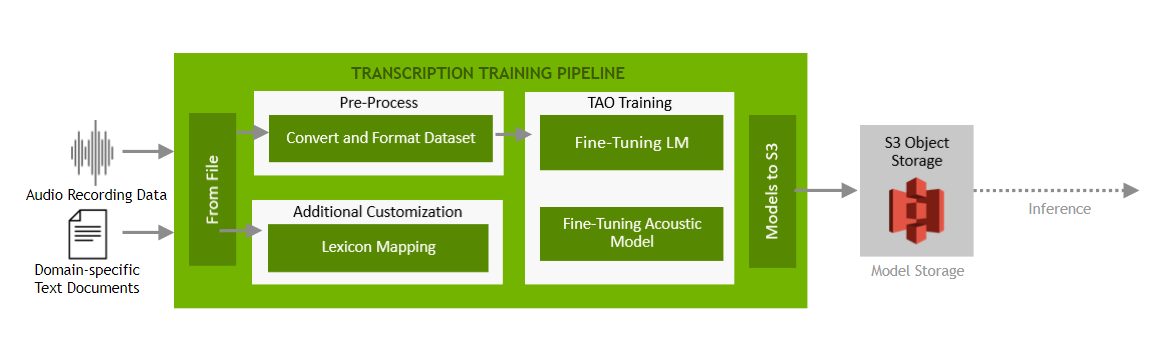
This pipeline is deployed separately from the Inference Pipeline below, and should be run on a regular basis, for example monthly, to ensure that the models remain accurate for the target use case and input data.
Inference Pipeline
The audio transcription solution, once customization is complete, is deployed as a single helm chart running a Riva microservice. This helm chart includes Automatic Speech Recognition(ASR) as well as Text to Speech (TTS) services, Riva ASR service is used for transcription. The helm chart also integrates with Cloud Native components like Keycloak, Prometheus and Grafana for authentication and monitoring.

Detailed information about the pipeline can be found in the Audio Transcription Workflow Guide.
The intelligent virtual assistant workflow demonstrates using Riva ASR to transcribe a user’s spoken question, interpreting the user’s intent in the question, and constructing a relevant response, which is delivered to the user in synthesized natural speech using Riva TTS.
The Virtual Assistant is deployed on a cloud K8s distribution as a collection of Helm charts, each running a microservice. The following three Helm charts will be provided.
Riva ASR and TTS services
Rasa dialog manager with Intent and slot management
Haystack NLP service for Information Retrieval Question Answering (IRQA)
The helm charts also integrate with Cloud Native components like Keycloak, Prometheus and Grafana for authentication and monitoring.
The additional components involved in the above microservices are described in the diagram below:

The overall training and inference pipelines, as well as how all of these additional components interact are largely the same as the previously described Transcription workflow. However, the inference pipeline contains the additional Rasa and Haystack services, which will be described in more detail in a later section of this document.

Instructions on deploying and customizing these components can be found in the Intelligent Virtual Assistant Workflow Guide.
Audio Transcription Components
The virtual assistant workflow uses the same ASR customizations from the previous Transcription Workflow for the Financial Service industry use case. These Riva ASR customizations include language model training, fine-tuning acoustic model, and lexicon mapping.

For more information about these customizations, see the Audio Transcription Workflow Guide.
Additional Third Party Intelligent Virtual Assistant Components
The virtual assistant workflow differs from the previous Transcription workflow by also including additional services for creating a virtual assistant. The goal of including these components is to demonstrate how Riva ASR and TTS services may be used and integrated with additional third-party components to create a more advanced and complete AI solution.
For the purposes of this workflow, a high level overview of the additional components is provided. The customization and configuration of the additional third party services is not described in detail; however, the integration steps and interaction between Riva and these third party services is provided in the Intelligent Virtual Assistant Workflow Guide.
Rasa Dialog Management and Training the Intent Slot Classification Model
Every intelligent virtual assistant requires a way to manage the state and flow of the conversation. A dialog manager recognizes the user intent and routes the question to the correct prepared response or a fulfillment service. This provides context for the question and frames how the Virtual Assistant is able to give the proper response. Rasa also maintains the dialog state, by filling slots set by the developer for remembering the context of the conversation. Rasa can be trained to understand user intent by giving it a few examples of each intent and slots to be recognized.
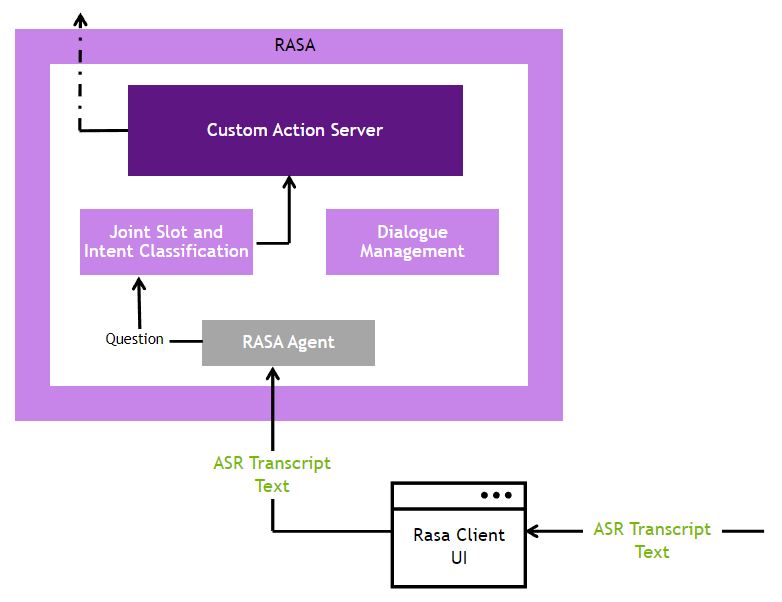
Information Retrieval and Question Answering (IRQA) with Haystack NLP
The Haystack IRQA pipeline is used to search a list of given documents and generate a long form response to the user question. This is helpful for companies with massive amounts of unstructured data that need to be consumed in a form that is helpful to the user.

The Haystack NLP workflow for the intelligent virtual assistant is as follows:
Indexing Pipeline
Data Collection/Crawler: All the relevant documents are collected, in our case by crawling the web pages (docs.nvidia.com).
Preprocessing: The web pages crawled are cleaned and preprocessed (removing unicode, escape characters and some extra regular expression based cleaning)
Embedding: The documents are then split into paragraphs, embedded to sentence embedding vectors using NLP models (like s-bert or s-roberta) and pushed to a document store (like elasticsearch).
Search Pipeline
Retrieval: Running a QA model to compare the question embedded vector with all the possible embedding vectors in the document store is an expensive task. Instead, a list of K-relevant documents is selected using faster techniques like Dense Passage Retrieval BERT model or FAISS.
Long Form Question Answering: Based on the K most relevant documents taken from the retrieval step as the input, a generative seq2seq model like BART can be used to build a human-like answer.
The diagram below demonstrates how all of the different customizations and components interact with each other:

Inference Pipeline

The entire pipeline is deployed on the cloud as a series of microservices after the Riva ASR customization and the NLP Haystack indexing workflow are completed. The front-facing UI has two components: the Riva client and the Rasa client. Initially, the customer can access a Virtual Assistant UI as a cloud-hosted service to send voice input. The voice input is sent to the Riva ASR service for transcription. The text from Riva ASR is then sent to the Rasa client, which then sends it to the Rasa server for BERT intent classification. Once the intent is recognized, the Rasa custom action server asks for fulfillment from the NLP Haystack IRQA search pipeline. Once the answer is provided, it is sent back to the Riva TTS service which generates a customized TTS response and then sends it back to the client.
Authentication
The Transcription and Intelligent Virtual Assistant helm charts show how to integrate with a cloud-native application level load balancer (Envoy) and an Identity Provider (Keycloak) for JSON Web Token Authentication as an example for those who would like to host transcription as a service on the cloud. For more information about the authentication portion of the workflow, refer to the Authentication section in the Appendix.
Monitoring
NVIDIA Triton Inference Server provides Prometheus metrics indicating GPU and request statistics in plain text so you can view them directly. By default, these metrics are available at http://envoy_proxy_ip:8002/metrics. The metrics are only available by accessing the endpoint and are not pushed or published to any remote server. The metrics are viewed using a sample Grafana dashboard. Some of the Triton metrics available for example are shown below, and depending on these usage metrics the RIVA pods can be scaled manually or automatically. Additional Riva metrics are available for both the transcription and intelligent virtual assistant workflows. Based on the Triton Inference Server metrics, we have calculated metrics that are specific and important to Riva as shown in the table below
Metric name |
Metrics formula |
Definition |
|---|---|---|
Average queue time |
avg(delta(nv_inference_queue_duration_us[1m])/(1+delta(nv_inference_request_success[1m]))/1000) |
Time in milliseconds a request stays in the Triton Inference Server queue averaged over all the requests in a one-minute time window. This is a measure of your server’s computing capability; if this increases over a threshold, consider scaling your server to more replicas |
Number of successful requests per minute |
sum(delta(nv_inference_request_success[1m])) |
Total number of successful inference requests captured over a one minute time window |
Number of failed requests per minute |
sum(delta(nv_inference_request_failure[1m])) |
Total number of successful inference requests captured over a one minute time window |
P99 latency is seconds |
quantile_over_time(0.99, nv_inference_compute_infer_duration_us[1m]) / 1000 / 1000 |
The p99 ASR latency of all the request samples captured over a one minute time window |
P95 latency is seconds |
quantile_over_time(0.95, nv_inference_compute_infer_duration_us[1m]) / 1000 / 1000 |
The p95 ASR latency of all the request samples captured over a one minute time window |
GPU memory utilization |
avg(nv_gpu_memory_used_bytes / 1024 / 1024 / 1024) |
GPU memory used by the Riva server |
Number of Riva Servers |
count (count by (instance) (nv_cache_hit_lookup_duration_per_model)) |
Riva server replicas on the Kubernetes cluster. |
GPU Utilization |
avg(nv_gpu_utilization) |
Average GPU utilization |
GPU Power Utilization |
avg(nv_gpu_power_usage) |
GPU power consumption over a period of time |