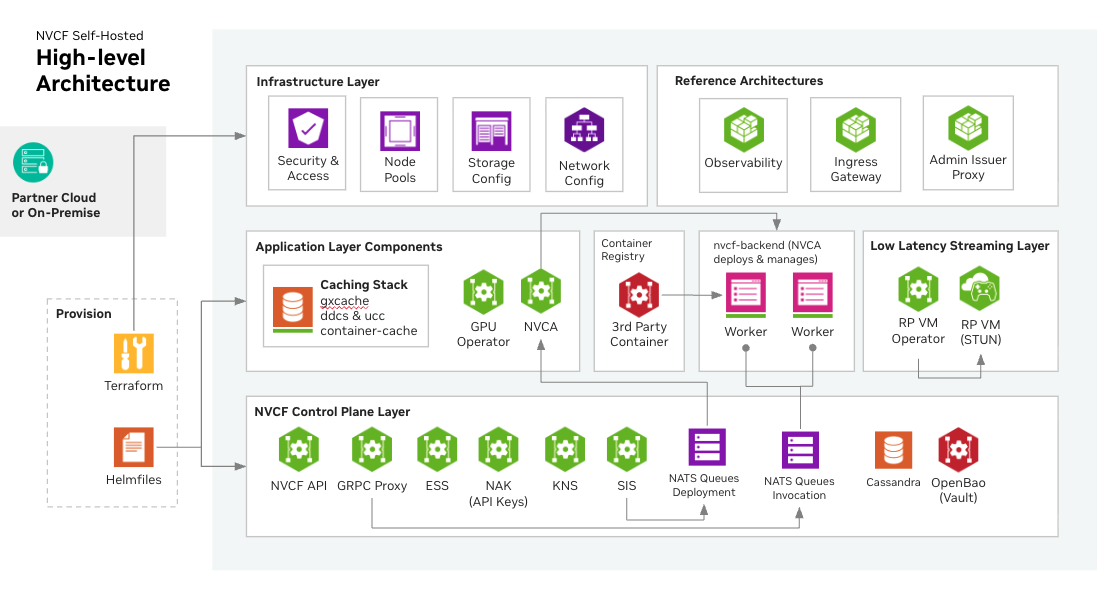
Deployment#
Self-hosted NVCF installation includes the core components required for NVCF inference. Additional optional components such as caching and low latency streaming support are also available.
For a full list of required artifacts, see Artifact Manifest.
Tip
Want to try NVCF locally first? See Local Development (k3d) for a guide to running the full stack on your laptop using k3d.
Overview#
Installation steps are as follows:
Mirror NVCF artifacts to your registry — Choose your mirroring approach based on your deployment method:
Terraform with EKS/ECR (Recommended): Use Automated ECR Mirroring by setting
create_sm_ecr_repos = truein your Terraform configuration. This handles all image and Helm chart mirroring automatically.All other deployments: Follow the manual mirroring instructions to pull artifacts from NGC and push to your registry.
Create a Kubernetes cluster (Optional, can bring any existing Kubernetes cluster or create an EKS cluster from example Terraform, see EKS Cluster Terraform (Optional))
Install NVCF Self-hosted Control Plane (Required) — Choose your installation method:
Helmfile Installation (recommended) — automated deployment using
helmfile. Use Helmfile < 1.2.0 (see Helmfile Installation prerequisites for details).Helm Chart Installation — individual
helm installcommands, for fine-grained control or GitOps pipelines.
Install Low Latency Streaming (Optional, for streaming workloads, see LLS Installation)
Install Optional GPU Cluster Enhancements (Optional, such as caching components, see Optional GPU Cluster Enhancements)
Configure the NVIDIA Cluster Agent (Optional, for GPU clusters that run functions; see Self-Managed Clusters)
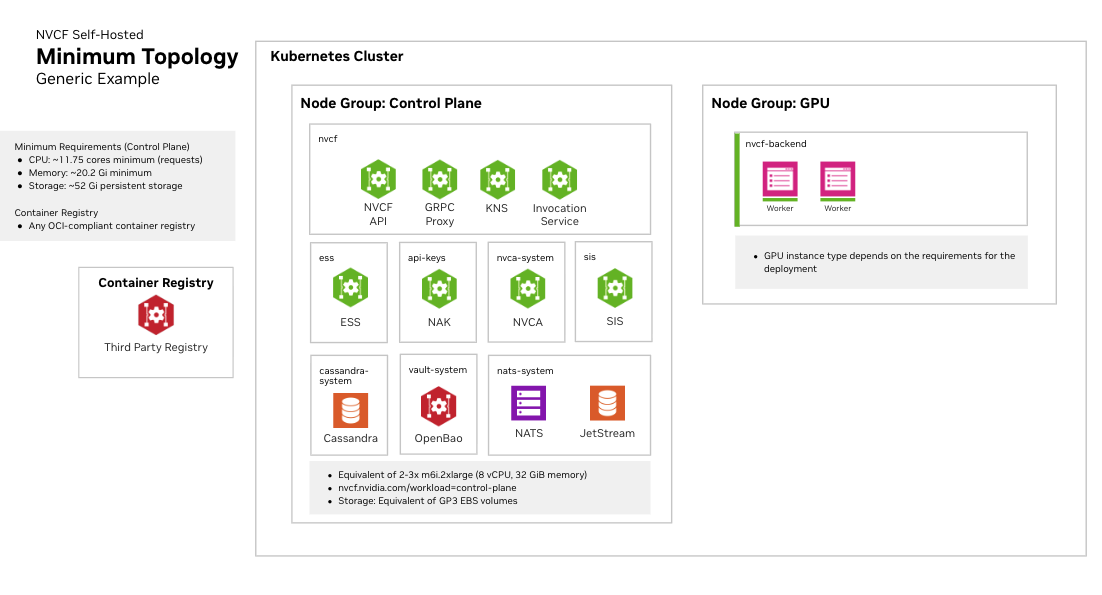
Kubernetes Cluster Requirements#
Cluster Version#
Any official supported Kubernetes version
Support for dynamic persistent volume provisioning
Required Operators and Components#
- NVIDIA GPU Operator
Required for GPU workload scheduling. The GPU Operator automates the management of all NVIDIA software components needed to provision GPUs in Kubernetes, including:
NVIDIA device drivers
Kubernetes device plugin for GPU discovery
GPU feature discovery for node labeling
Container runtime integration (containerd, CRI-O, or Docker)
Monitoring and telemetry tools
See NVIDIA GPU Operator documentation for installation instructions.
Note
Fake GPU Operator for Development/Testing:
For environments without actual GPU hardware, install the fake GPU operator to simulate GPU resources. See Fake GPU Operator (Development / Testing) for full instructions.
- Network Policies
Your cluster must support Kubernetes Network Policies if network isolation is required.
- Persistent Storage
A StorageClass must be configured for persistent volumes. Common options:
Amazon EKS:
gp3(default)Local development:
local-pathOther platforms: Any CSI-compatible storage class
Note
Some cloud providers have minimum PVC size requirements. For example, AWS EBS gp3 volumes have a 1Gi minimum.
Cluster Sizing and Storage#
See Infrastructure Sizing for node pool specifications, storage recommendations, and three recommended sizing tiers (Development, Minimal HA, and Production).