Getting Started
This document provides instructions, including pre-requisites for getting started with the NVIDIA GPU Operator.
Red Hat OpenShift 4
For installing the GPU Operator on clusters with Red Hat OpenShift using RHCOS worker nodes, follow the user guide.
Google Cloud Anthos
For getting started with NVIDIA GPUs for Google Cloud Anthos, follow the getting started document.
Prerequisites
Before installing the GPU Operator, you should ensure that the Kubernetes cluster meets some prerequisites.
Nodes must be configured with a container engine such as Docker CE/EE,
cri-o, orcontainerd. For docker, follow the official install instructions.If the HWE kernel (e.g. kernel 5.x) is used with Ubuntu 18.04 LTS or Ubuntu 20.04 LTS, then the
nouveaudriver for NVIDIA GPUs must be blacklisted before starting the GPU Operator. Follow the steps in the CUDA installation guide to disable the nouveau driver and updateinitramfs.Node Feature Discovery (NFD) is a dependency for the Operator on each node. By default, NFD master and worker are automatically deployed by the Operator. If NFD is already running in the cluster prior to the deployment of the operator, then the Operator can be configured to not to install NFD.
For monitoring in Kubernetes 1.13 and 1.14, enable the kubelet
KubeletPodResourcesfeature gate. From Kubernetes 1.15 onwards, its enabled by default.
Note
To enable the KubeletPodResources feature gate, run the following command: echo -e "KUBELET_EXTRA_ARGS=--feature-gates=KubeletPodResources=true" | sudo tee /etc/default/kubelet
Before installing the GPU Operator on NVIDIA vGPU, ensure the following.
The NVIDIA vGPU Host Driver version 12.0 (or later) is pre-installed on all hypervisors hosting NVIDIA vGPU accelerated Kubernetes worker node virtual machines. Please refer to NVIDIA vGPU Documentation for details.
A NVIDIA vGPU License Server is installed and reachable from all Kubernetes worker node virtual machines.
A private registry is available to upload the NVIDIA vGPU specific driver container image.
Each Kubernetes worker node in the cluster has access to the private registry. Private registry access is usually managed through imagePullSecrets. See the Kubernetes Documentation for more information. The user is required to provide these secrets to the NVIDIA GPU-Operator in the driver section of the values.yaml file.
Git and Docker/Podman are required to build the vGPU driver image from source repository and push to local registry.
Note
Uploading the NVIDIA vGPU driver to a publicly available repository or otherwise publicly sharing the driver is a violation of the NVIDIA vGPU EULA.
The rest of this document includes instructions for installing the GPU Operator on supported Linux distributions.
Install Kubernetes
Refer to install-k8s for getting started with setting up a Kubernetes cluster.
Install NVIDIA GPU Operator
Install Helm
The preferred method to deploy the GPU Operator is using helm.
$ curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 \
&& chmod 700 get_helm.sh \
&& ./get_helm.sh
Now, add the NVIDIA Helm repository:
$ helm repo add nvidia https://nvidia.github.io/gpu-operator \
&& helm repo update
Install the GPU Operator
The GPU Operator Helm chart offers a number of customizable options that can be configured depending on your environment.

Chart Customization Options
The following options are available when using the Helm chart. These options can be used with --set when installing via Helm.
Parameter |
Description |
Default |
|---|---|---|
|
Deploys Node Feature Discovery plugin as a daemonset.
Set this variable to |
|
|
By default, the operator assumes your Kubernetes deployment is running with
|
|
|
Controls the strategy to be used with MIG on supported NVIDIA GPUs. Options
are either |
|
|
The GPU operator deploys |
|
|
By default, the Operator deploys NVIDIA drivers as a container on the system.
Set this value to |
|
|
The images are downloaded from NGC. Specify another image repository when using custom driver images. |
|
|
Version of the NVIDIA datacenter driver supported by the Operator. |
Depends on the version of the Operator. See the Component Matrix for more information on supported drivers. |
|
Controls whether the driver daemonset should build and load the |
|
|
By default, the Operator deploys the NVIDIA Container Toolkit ( |
|
|
The MIG manager watches for changes to the MIG geometry and applies reconfiguration as needed. By default, the MIG manager only runs on nodes with GPUs that support MIG (for e.g. A100). |
|
Common Deployment Scenarios
In this section, we present some common deployment recipes when using the Helm chart to install the GPU Operator.
Bare-metal/Passthrough with default configurations on Ubuntu
In this scenario, the default configuration options are used:
$ helm install --wait --generate-name \
nvidia/gpu-operator
Bare-metal/Passthrough with default configurations on CentOS
In this scenario, the CentOS toolkit image is used:
$ helm install --wait --generate-name --set toolkit.version=1.7.1-centos7 \
nvidia/gpu-operator
Note
For CentOS 8 systems, use toolkit.version=1.7.1-centos8.
Replace 1.7.1 toolkit version used here with the latest one available here.
NVIDIA vGPU
Note
The GPU Operator with NVIDIA vGPUs requires additional steps to build a private driver image prior to install. Refer to the document NVIDIA vGPU for detailed instructions on the workflow and required values of the variables used in this command.
The command below will install the GPU Operator with its default configuration for vGPU:
$ helm install --wait --generate-name \
nvidia/gpu-operator --set driver.repository=$PRIVATE_REGISTRY \
--set driver.version=$VERSION \
--set driver.imagePullSecrets={$REGISTRY_SECRET_NAME} \
--set driver.licensingConfig.configMapName=licensing-config
NVIDIA AI Enterprise
Note
The GPU Operator with NVIDIA AI Enterprise requires some tasks to be completed prior to installation. Refer to the document NVIDIA AI Enterprise for instructions prior to running the below commands.
Add the NVIDIA AI Enterprise Helm repository, where api-key is the NGC API key for accessing
the NVIDIA Enterprise Collection that you generated:
$ helm repo add nvaie https://helm.ngc.nvidia.com/nvaie \
--username='$oauthtoken' --password=api-key \
&& helm repo update
Install the NVIDIA GPU Operator:
$ helm install --wait --generate-name nvaie/gpu-operator -n gpu-operator-resources
Bare-metal/Passthrough with pre-installed NVIDIA drivers
In this example, the user has already pre-installed NVIDIA drivers as part of the system image:
$ helm install --wait --generate-name \
nvidia/gpu-operator \
--set driver.enabled=false
Bare-metal/Passthrough with pre-installed drivers and NVIDIA Container Toolkit
In this example, the user has already pre-installed the NVIDIA drivers and NVIDIA Container Toolkit (nvidia-docker2)
as part of the system image.
Note
These steps should be followed when using the GPU Operator v1.8+ on DGX systems such as DGX A100.
Before installing the operator, ensure that the following configurations are modified depending on the container runtime configured in your cluster.
Docker:
Update the Docker configuration to add
nvidiaas the default runtime. Thenvidiaruntime should be setup as the default container runtime for Docker on GPU nodes. This can be done by adding thedefault-runtimeline into the Docker daemon config file, which is usually located on the system at/etc/docker/daemon.json:{ "default-runtime": "nvidia", "runtimes": { "nvidia": { "path": "/usr/bin/nvidia-container-runtime", "runtimeArgs": [] } } }Restart the Docker daemon to complete the installation after setting the default runtime:
$ sudo systemctl restart docker
Containerd:
Update
containerdto usenvidiaas the default runtime and addnvidiaruntime configuration. This can be done by adding below config to/etc/containerd/config.tomland restartingcontainerdservice.version = 2 [plugins] [plugins."io.containerd.grpc.v1.cri"] [plugins."io.containerd.grpc.v1.cri".containerd] default_runtime_name = "nvidia" [plugins."io.containerd.grpc.v1.cri".containerd.runtimes] [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia] privileged_without_host_devices = false runtime_engine = "" runtime_root = "" runtime_type = "io.containerd.runc.v2" [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options] BinaryName = "/usr/bin/nvidia-container-runtime"Restart the Containerd daemon to complete the installation after setting the default runtime:
$ sudo systemctl restart containerd
Install the GPU operator with the following options:
$ helm install --wait --generate-name \
nvidia/gpu-operator \
--set driver.enabled=false \
--set toolkit.enabled=false
Bare-metal/Passthrough with pre-installed NVIDIA Container Toolkit (but no drivers)
In this example, the user has already pre-installed the NVIDIA Container Toolkit (nvidia-docker2) as part of the system image.
Before installing the operator, ensure that the following configurations are modified depending on the container runtime configured in your cluster.
Docker:
Update the Docker configuration to add
nvidiaas the default runtime. Thenvidiaruntime should be setup as the default container runtime for Docker on GPU nodes. This can be done by adding thedefault-runtimeline into the Docker daemon config file, which is usually located on the system at/etc/docker/daemon.json:{ "default-runtime": "nvidia", "runtimes": { "nvidia": { "path": "/usr/bin/nvidia-container-runtime", "runtimeArgs": [] } } }Restart the Docker daemon to complete the installation after setting the default runtime:
$ sudo systemctl restart docker
Containerd:
Update
containerdto usenvidiaas the default runtime and addnvidiaruntime configuration. This can be done by adding below config to/etc/containerd/config.tomland restartingcontainerdservice.version = 2 [plugins] [plugins."io.containerd.grpc.v1.cri"] [plugins."io.containerd.grpc.v1.cri".containerd] default_runtime_name = "nvidia" [plugins."io.containerd.grpc.v1.cri".containerd.runtimes] [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia] privileged_without_host_devices = false runtime_engine = "" runtime_root = "" runtime_type = "io.containerd.runc.v2" [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options] BinaryName = "/usr/bin/nvidia-container-runtime"Restart the Containerd daemon to complete the installation after setting the default runtime:
$ sudo systemctl restart containerd
Configure toolkit to use the root directory of the driver installation as /run/nvidia/driver, which is the path mounted by driver container.
$ sudo sed -i 's/^#root/root/' /etc/nvidia-container-runtime/config.toml
Once these steps are complete, now install the GPU operator with the following options (which will provision a driver):
$ helm install --wait --generate-name \
nvidia/gpu-operator \
--set toolkit.enabled=false
Custom driver image (based off a specific driver version)
If you want to use custom driver container images (for e.g. using 465.27), then you would need to build a new driver container image. Follow these steps:
Rebuild the driver container by specifying the
$DRIVER_VERSIONargument when building the Docker image. For reference, the driver container Dockerfiles are available on the Git repo hereBuild the container using the appropriate Dockerfile. For example:
$ docker build --pull -t \ --build-arg DRIVER_VERSION=455.28 \ nvidia/driver:455.28-ubuntu20.04 \ --file Dockerfile .
Ensure that the driver container is tagged as shown in the example by using the
driver:<version>-<os>schema.Specify the new driver image and repository by overriding the defaults in the Helm install command. For example:
$ helm install --wait --generate-name \ nvidia/gpu-operator \ --set driver.repository=docker.io/nvidia \ --set driver.version="465.27"
Note that these instructions are provided for reference and evaluation purposes. Not using the standard releases of the GPU Operator from NVIDIA would mean limited support for such custom configurations.
Set the default container runtime as containerd
In this example, we set the default container runtime to be used as containerd.
$ helm install --wait --generate-name \
nvidia/gpu-operator \
--set operator.defaultRuntime=containerd
When setting containerd as the defaultRuntime the following options are also available:
toolkit:
env:
- name: CONTAINERD_CONFIG
value: /etc/containerd/config.toml
- name: CONTAINERD_SOCKET
value: /run/containerd/containerd.sock
- name: CONTAINERD_RUNTIME_CLASS
value: nvidia
- name: CONTAINERD_SET_AS_DEFAULT
value: true
These options are defined as follows:
- CONTAINERD_CONFIGThe path on the host to the
containerdconfigyou would like to have updated with support for the
nvidia-container-runtime. By default this will point to/etc/containerd/config.toml(the default location forcontainerd). It should be customized if yourcontainerdinstallation is not in the default location.
- CONTAINERD_SOCKETThe path on the host to the socket file used to
communicate with
containerd. The operator will use this to send aSIGHUPsignal to thecontainerddaemon to reload its config. By default this will point to/run/containerd/containerd.sock(the default location forcontainerd). It should be customized if yourcontainerdinstallation is not in the default location.
- CONTAINERD_RUNTIME_CLASSThe name of the
Runtime Class you would like to associate with the
nvidia-container-runtime. Pods launched with aruntimeClassNameequal to CONTAINERD_RUNTIME_CLASS will always run with thenvidia-container-runtime. The default CONTAINERD_RUNTIME_CLASS isnvidia.
- CONTAINERD_SET_AS_DEFAULTA flag indicating whether you want to set
nvidia-container-runtimeas the default runtime used to launch all containers. When set to false, only containers in pods with aruntimeClassNameequal to CONTAINERD_RUNTIME_CLASS will be run with thenvidia-container-runtime. The default value istrue.
Proxy Environments
Refer to the section Install GPU Operator in Proxy Environments for more information on how to install the Operator on clusters behind a HTTP proxy.
Air-gapped Environments
Refer to the section Install GPU Operator in Air-gapped Environments for more information on how to install the Operator in air-gapped environments.
Multi-Instance GPU (MIG)
Refer to the document GPU Operator with MIG for more information on how use the Operator with Multi-Instance GPU (MIG) on NVIDIA Ampere products. For guidance on configuring MIG support for the NVIDIA GPU Operator in an OpenShift Container Platform cluster, see the user guide.
Outdated Kernels
Refer to the section Considerations when Installing with Outdated Kernels in Cluster for more information on how to install the Operator successfully when nodes in the cluster are not running the latest kernel
Verify GPU Operator Install
Once the Helm chart is installed, check the status of the pods to ensure all the containers are running and the validation is complete:
$ kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
default gpu-operator-d6ccd4d8d-f7m57 1/1 Running 0 5m51s
default gpu-operator-node-feature-discovery-master-867c4f7bfb-cbxck 1/1 Running 0 5m51s
default gpu-operator-node-feature-discovery-worker-wv2rq 1/1 Running 0 5m51s
gpu-operator-resources gpu-feature-discovery-qmftl 1/1 Running 0 5m35s
gpu-operator-resources nvidia-container-toolkit-daemonset-tx4rd 1/1 Running 0 5m35s
gpu-operator-resources nvidia-cuda-validator-ip-172-31-65-3 0/1 Completed 0 2m29s
gpu-operator-resources nvidia-dcgm-exporter-99t8p 1/1 Running 0 5m35s
gpu-operator-resources nvidia-device-plugin-daemonset-nkbtz 1/1 Running 0 5m35s
gpu-operator-resources nvidia-device-plugin-validator-ip-172-31-65-3 0/1 Completed 0 103s
gpu-operator-resources nvidia-driver-daemonset-w97sh 1/1 Running 0 5m35s
gpu-operator-resources nvidia-operator-validator-2djn2 1/1 Running 0 5m35s
kube-system calico-kube-controllers-b656ddcfc-4sgld 1/1 Running 0 8m11s
kube-system calico-node-wzdbr 1/1 Running 0 8m11s
kube-system coredns-558bd4d5db-2w9tf 1/1 Running 0 8m11s
kube-system coredns-558bd4d5db-cv5md 1/1 Running 0 8m11s
kube-system etcd-ip-172-31-65-3 1/1 Running 0 8m25s
kube-system kube-apiserver-ip-172-31-65-3 1/1 Running 0 8m25s
kube-system kube-controller-manager-ip-172-31-65-3 1/1 Running 0 8m25s
kube-system kube-proxy-gpqc5 1/1 Running 0 8m11s
kube-system kube-scheduler-ip-172-31-65-3 1/1 Running 0 8m25s
We can now proceed to running some sample GPU workloads to verify that the Operator (and its components) are working correctly.
Running Sample GPU Applications
CUDA VectorAdd
In the first example, let’s run a simple CUDA sample, which adds two vectors together:
$ cat << EOF | kubectl create -f -
apiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vectoradd
image: "nvidia/samples:vectoradd-cuda11.2.1"
resources:
limits:
nvidia.com/gpu: 1
EOF
The sample should run fairly quickly. If you view the logs of the container:
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
CUDA FP16 Matrix multiply
In the second example, let’s try running a CUDA load generator, which does an FP16 matrix-multiply on the GPU using the Tensor Cores when available:
$ cat << EOF | kubectl create -f -
apiVersion: v1
kind: Pod
metadata:
name: dcgmproftester
spec:
restartPolicy: OnFailure
containers:
- name: dcgmproftester11
image: nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04
args: ["--no-dcgm-validation", "-t 1004", "-d 30"]
resources:
limits:
nvidia.com/gpu: 1
securityContext:
capabilities:
add: ["SYS_ADMIN"]
EOF
and then view the logs of the dcgmproftester pod:
$ kubectl logs -f dcgmproftester
You should see the FP16 GEMM being run on the GPU:
Skipping CreateDcgmGroups() since DCGM validation is disabled
CU_DEVICE_ATTRIBUTE_MAX_THREADS_PER_MULTIPROCESSOR: 1024
CU_DEVICE_ATTRIBUTE_MULTIPROCESSOR_COUNT: 40
CU_DEVICE_ATTRIBUTE_MAX_SHARED_MEMORY_PER_MULTIPROCESSOR: 65536
CU_DEVICE_ATTRIBUTE_COMPUTE_CAPABILITY_MAJOR: 7
CU_DEVICE_ATTRIBUTE_COMPUTE_CAPABILITY_MINOR: 5
CU_DEVICE_ATTRIBUTE_GLOBAL_MEMORY_BUS_WIDTH: 256
CU_DEVICE_ATTRIBUTE_MEMORY_CLOCK_RATE: 5001000
Max Memory bandwidth: 320064000000 bytes (320.06 GiB)
CudaInit completed successfully.
Skipping WatchFields() since DCGM validation is disabled
TensorEngineActive: generated ???, dcgm 0.000 (26096.4 gflops)
TensorEngineActive: generated ???, dcgm 0.000 (26344.4 gflops)
TensorEngineActive: generated ???, dcgm 0.000 (26351.2 gflops)
TensorEngineActive: generated ???, dcgm 0.000 (26359.9 gflops)
TensorEngineActive: generated ???, dcgm 0.000 (26750.7 gflops)
TensorEngineActive: generated ???, dcgm 0.000 (25378.8 gflops)
You will observe that on an NVIDIA T4, this has resulted in ~26 TFLOPS of FP16 GEMM performance.
Jupyter Notebook
In the next example, let’s try running a TensorFlow Jupyter notebook.
First, deploy the pods:
$ kubectl apply -f https://nvidia.github.io/gpu-operator/notebook-example.yml
Check to determine if the pod has successfully started:
$ kubectl get pod tf-notebook
NAMESPACE NAME READY STATUS RESTARTS AGE
default tf-notebook 1/1 Running 0 3m45s
Since the example also includes a service, let’s obtain the external port at which the notebook is accessible:
$ kubectl get svc -A
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default tf-notebook NodePort 10.106.229.20 <none> 80:30001/TCP 4m41s
..
And the token for the Jupyter notebook:
$ kubectl logs tf-notebook
[I 21:50:23.188 NotebookApp] Writing notebook server cookie secret to /root/.local/share/jupyter/runtime/notebook_cookie_secret
[I 21:50:23.390 NotebookApp] Serving notebooks from local directory: /tf
[I 21:50:23.391 NotebookApp] The Jupyter Notebook is running at:
[I 21:50:23.391 NotebookApp] http://tf-notebook:8888/?token=3660c9ee9b225458faaf853200bc512ff2206f635ab2b1d9
[I 21:50:23.391 NotebookApp] or http://127.0.0.1:8888/?token=3660c9ee9b225458faaf853200bc512ff2206f635ab2b1d9
[I 21:50:23.391 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 21:50:23.394 NotebookApp]
To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-1-open.html
Or copy and paste one of these URLs:
http://tf-notebook:8888/?token=3660c9ee9b225458faaf853200bc512ff2206f635ab2b1d9
or http://127.0.0.1:8888/?token=3660c9ee9b225458faaf853200bc512ff2206f635ab2b1d9
The notebook should now be accessible from your browser at this URL: http:://<your-machine-ip>:30001/?token=3660c9ee9b225458faaf853200bc512ff2206f635ab2b1d9
Demo
Check out the demo below where we scale GPU nodes in a K8s cluster using the GPU Operator:

GPU Telemetry
To gather GPU telemetry in Kubernetes, the GPU Operator deploys the dcgm-exporter. dcgm-exporter, based
on DCGM exposes GPU metrics for Prometheus and can be visualized using Grafana. dcgm-exporter is architected to take advantage of
KubeletPodResources API and exposes GPU metrics in a format that can be
scraped by Prometheus.
With GPU Operator users can customize the metrics to be collected by dcgm-exporter. Below are the steps for this
Fetch the metrics file and save as dcgm-metrics.csv
$ curl https://raw.githubusercontent.com/NVIDIA/dcgm-exporter/main/etc/dcp-metrics-included.csv > dcgm-metrics.csv
Edit the metrics file as required to add/remove any metrics to be collected.
Create a Namespace
gpu-operator-resourcesif one is already not present.$ kubectl create namespace gpu-operator-resources
Create a ConfigMap using the file edited above.
$ kubectl create configmap metrics-config -n gpu-operator-resources --from-file=dcgm-metrics.csv
Install GPU Operator with additional options
--set dcgmExporter.config.name=metrics-configand
--set dcgmExporter.env[0].name=DCGM_EXPORTER_COLLECTORS --set dcgmExporter.env[0].value=/etc/dcgm-exporter/dcgm-metrics.csv
The rest of this section walks through how to setup Prometheus, Grafana using Operators and using Prometheus with dcgm-exporter.
Now you can see the Prometheus and Grafana pods:
$ kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
default gpu-operator-1597965115-node-feature-discovery-master-fbf9rczx5 1/1 Running 1 6h57m
default gpu-operator-1597965115-node-feature-discovery-worker-n58pm 1/1 Running 1 6h57m
default gpu-operator-774ff7994c-xh62d 1/1 Running 1 6h57m
default gpu-operator-test 0/1 Completed 0 8h
gpu-operator-resources nvidia-container-toolkit-daemonset-grnnd 1/1 Running 1 6h57m
gpu-operator-resources nvidia-dcgm-exporter-nv5z7 1/1 Running 7 6h57m
gpu-operator-resources nvidia-device-plugin-daemonset-qq6lq 1/1 Running 7 6h57m
gpu-operator-resources nvidia-device-plugin-validation 0/1 Completed 0 6h57m
gpu-operator-resources nvidia-driver-daemonset-vwzvq 1/1 Running 1 6h57m
gpu-operator-resources nvidia-driver-validation 0/1 Completed 3 6h57m
kube-system calico-kube-controllers-578894d4cd-pv5kw 1/1 Running 1 10h
kube-system calico-node-ffhdd 1/1 Running 1 10h
kube-system coredns-66bff467f8-nwdrx 1/1 Running 1 10h
kube-system coredns-66bff467f8-srg8d 1/1 Running 1 10h
kube-system etcd-ip-172-31-80-124 1/1 Running 1 10h
kube-system kube-apiserver-ip-172-31-80-124 1/1 Running 1 10h
kube-system kube-controller-manager-ip-172-31-80-124 1/1 Running 1 10h
kube-system kube-proxy-kj5qb 1/1 Running 1 10h
kube-system kube-scheduler-ip-172-31-80-124 1/1 Running 1 10h
prometheus alertmanager-prometheus-operator-159799-alertmanager-0 2/2 Running 0 12s
prometheus prometheus-operator-159799-operator-78f95fccbd-hcl76 2/2 Running 0 16s
prometheus prometheus-operator-1597990146-grafana-5c7db4f7d4-qcjbj 2/2 Running 0 16s
prometheus prometheus-operator-1597990146-kube-state-metrics-645c57c8x28nv 1/1 Running 0 16s
prometheus prometheus-operator-1597990146-prometheus-node-exporter-6lchc 1/1 Running 0 16s
prometheus prometheus-prometheus-operator-159799-prometheus-0 2/3 Running 0 2s
You can view the services setup as part of the operator and dcgm-exporter:
$ kubectl get svc -A
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default gpu-operator-1597965115-node-feature-discovery-master ClusterIP 10.110.46.7 <none> 8080/TCP 6h57m
default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 10h
default tf-notebook NodePort 10.106.229.20 <none> 80:30001/TCP 8h
gpu-operator-resources nvidia-dcgm-exporter ClusterIP 10.99.250.100 <none> 9400/TCP 6h57m
kube-system kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 10h
kube-system prometheus-operator-159797-kubelet ClusterIP None <none> 10250/TCP,10255/TCP,4194/TCP 4h50m
kube-system prometheus-operator-159799-coredns ClusterIP None <none> 9153/TCP 32s
kube-system prometheus-operator-159799-kube-controller-manager ClusterIP None <none> 10252/TCP 32s
kube-system prometheus-operator-159799-kube-etcd ClusterIP None <none> 2379/TCP 32s
kube-system prometheus-operator-159799-kube-proxy ClusterIP None <none> 10249/TCP 32s
kube-system prometheus-operator-159799-kube-scheduler ClusterIP None <none> 10251/TCP 32s
kube-system prometheus-operator-159799-kubelet ClusterIP None <none> 10250/TCP,10255/TCP,4194/TCP 18s
prometheus alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 28s
prometheus prometheus-operated ClusterIP None <none> 9090/TCP 18s
prometheus prometheus-operator-159799-alertmanager ClusterIP 10.106.93.161 <none> 9093/TCP 32s
prometheus prometheus-operator-159799-operator ClusterIP 10.100.116.170 <none> 8080/TCP,443/TCP 32s
prometheus prometheus-operator-159799-prometheus NodePort 10.102.169.42 <none> 9090:30090/TCP 32s
prometheus prometheus-operator-1597990146-grafana ClusterIP 10.104.40.69 <none> 80/TCP 32s
prometheus prometheus-operator-1597990146-kube-state-metrics ClusterIP 10.100.204.91 <none> 8080/TCP 32s
prometheus prometheus-operator-1597990146-prometheus-node-exporter ClusterIP 10.97.64.60 <none> 9100/TCP 32s
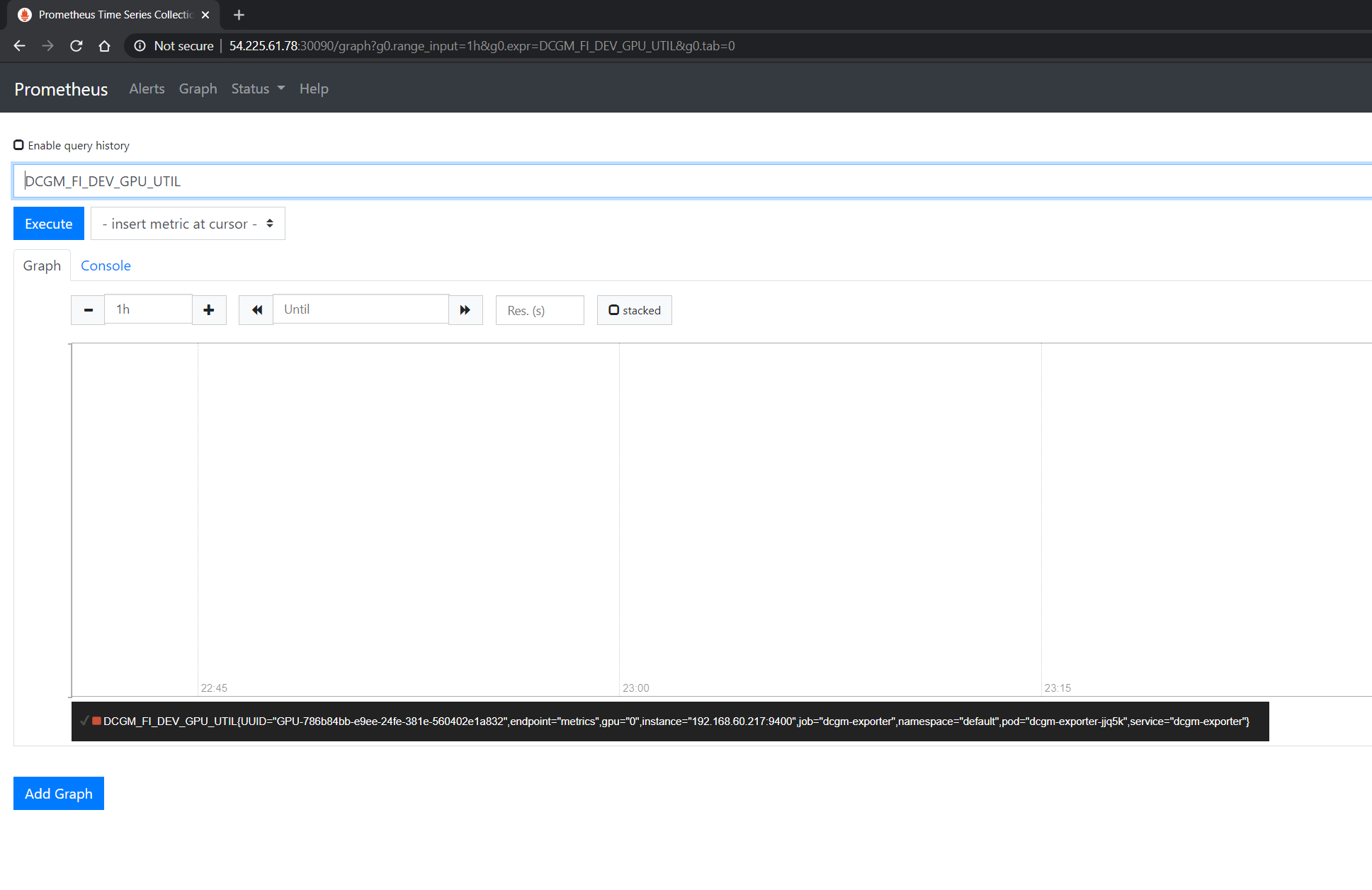
You can observe that the Prometheus server is available at port 30090 on the node’s IP address. Open your browser to http://<machine-ip-address>:30090.
It may take a few minutes for DCGM to start publishing the metrics to Prometheus. The metrics availability can be verified by typing DCGM_FI_DEV_GPU_UTIL
in the event bar to determine if the GPU metrics are visible:
Using Grafana
You can also launch the Grafana tools for visualizing the GPU metrics.
There are two mechanisms for dealing with the ports on which Grafana is available - the service can be patched or port-forwarding can be used to reach the home page. Either option can be chosen based on preference.
Patching the Grafana Service
By default, Grafana uses a ClusterIP to expose the ports on which the service is accessible. This can be changed to a NodePort instead, so the page is accessible
from the browser, similar to the Prometheus dashboard.
You can use kubectl patch to update the service API
object to expose a NodePort instead.
First, modify the spec to change the service type:
$ cat << EOF | tee grafana-patch.yaml
spec:
type: NodePort
nodePort: 32322
EOF
And now use kubectl patch:
$ kubectl patch svc prometheus-operator-1597990146-grafana -n prometheus --patch "$(cat grafana-patch.yaml)"
service/prometheus-operator-1597990146-grafana patched
You can verify that the service is now exposed at an externally accessible port:
$ kubectl get svc -A
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
<snip>
prometheus prometheus-operator-1597990146-grafana NodePort 10.108.187.141 <none> 80:32258/TCP 17h
Open your browser to http://<machine-ip-address>:32258 and view the Grafana login page. Access Grafana home using the admin username.
The password credentials for the login are available in the prometheus.values file we edited in the earlier section of the doc:
## Deploy default dashboards.
##
defaultDashboardsEnabled: true
adminPassword: prom-operator
Upgrade
Using Helm
Starting with GPU Operator v1.8.0, the GPU Operator supports dynamic updates to existing resources. This allows the GPU Operator to ensure settings from the ClusterPolicy Spec are always applied and current.
Since Helm doesn’t support auto upgrade of existing CRDs, the user needs to follow a two step process to upgrade the GPU Operator chart:
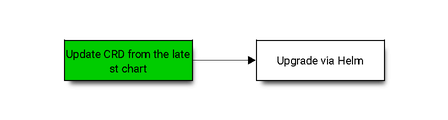
With this workflow, all existing GPU operator resources are updated inline and the ClusterPolicy resource is patched with updates from values.yaml.
Download the CRD from the specific <release-tag> from the Git repo. For example:
$ wget https://gitlab.com/nvidia/kubernetes/gpu-operator/-/raw/<release-tag>/deployments/gpu-operator/crds/nvidia.com_clusterpolicies_crd.yaml
Apply the CRD using the file downloaded above:
$ kubectl apply -f nvidia.com_clusterpolicies_crd.yaml
Fetch latest values from the chart (replace the .x below with the desired version)
$ helm show values nvidia/gpu-operator --version=1.8.x > values-1.8.x.yaml
Update the values file as needed.
And upgrade via Helm:
$ helm upgrade gpu-operator -n gpu-operator-resources -f values-1.8.x.yaml
Cluster Policy Updates
The GPU Operator also supports dynamic updates to the ClusterPolicy CustomResource using kubectl:
$ kubectl edit clusterpolicy
After the edits are complete, Kubernetes will automatically apply the updates to cluster.
Additional Controls for Driver Upgrades
While most of the GPU Operator managed daemonset pods can be updated without dependencies, the NVIDIA driver daemonset needs special handling. This is due to the fact that the driver kernel modules have to be unloaded and loaded again on each driver container restart. In turn this has certain dependencies:
All clients to the GPU driver have to be disabled
The current GPU driver kernel modules have to be unloaded
The updated driver pods need to start
The GPU driver has to be installed and new kernel modules loaded
The driver clients disabled initially have to be enabled again
In order to achieve this, a new component called k8s-driver-manager is added which will ensure that, all existing GPU driver clients are disabled and current modules are unloaded. This component is added as an initContainer within the driver daemonset.
Since the k8s-driver-manager evicts pods from the node to complete the driver upgrade, users can control the node drain
behavior using environment variables as specified in the GPU Operator Helm chart (see the driver.manager.env variables):
imagePullPolicy: IfNotPresent
env:
- name: ENABLE_AUTO_DRAIN
value: "true"
- name: DRAIN_USE_FORCE
value: "false"
- name: DRAIN_POD_SELECTOR_LABEL
value: ""
- name: DRAIN_TIMEOUT_SECONDS
value: "0s"
- name: DRAIN_DELETE_EMPTYDIR_DATA
value: "false"
The DRAIN_POD_SELECTOR_LABEL env can be used to let k8s-driver-manager only evict GPU pods with matching labels from the node. This way, CPU only pods will not be affected during driver upgrades.
DRAIN_USE_FORCE needs to be enabled for evicting GPU pods that are not managed by any of the replication controllers (Deployment, Daemonset, StatefulSet, ReplicaSet).
Using OLM in OpenShift
For upgrading the GPU Operator when running in OpenShift, refer to the official documentation on upgrading installed operators: https://docs.openshift.com/container-platform/4.8/operators/admin/olm-upgrading-operators.html
Uninstall
To uninstall the operator:
$ helm delete $(helm list | grep gpu-operator | awk '{print $1}')
You should now see all the pods being deleted:
$ kubectl get pods -n gpu-operator-resources
No resources found.
Also, ensure that CRDs created during the operator install have been removed:
$ kubectl get crds -A | grep -i clusterpolicies.nvidia.com
Note
After un-install of GPU Operator, the NVIDIA driver modules might still be loaded. Either reboot the node or unload them using the following command:
$ sudo rmmod nvidia_modeset nvidia_uvm nvidia