Troubleshooting
This section includes errors that users may encounter when performing various checks during installing the NVIDIA GPU Operator on the OpenShift Container Platform cluster.
Node Feature Discovery checks
Verify the Node Feature Discovery has been created:
$ oc get NodeFeatureDiscovery -n openshift-nfdNAME AGE nfd-instance 4h11m
Note
If empty the Node Feature Discovery Custom Resource (CR) must be created.
Check there are nodes with GPU. In this example the check is performed for the NVIDIA GPU which uses the PCI ID 10de.
$ oc get nodes -l feature.node.kubernetes.io/pci-10de.presentNAME STATUS ROLES AGE VERSION ip-10-0-133-209.ec2.internal Ready worker 4h13m v1.21.1+9807387
GPU Operator checks
Check the Custom Resource Definition (CRD) is deployed.
$ oc get crd/clusterpolicies.nvidia.comNAME CREATED AT clusterpolicies.nvidia.com 2021-09-02T10:33:50Z
Note
If missing, then the OperatorHub install went wrong.
Check the cluster policy is deployed:
$ oc get clusterpolicyNAME AGE gpu-cluster-policy 8m25s
Note
If missing, the custom resource (CR) must be created from the OperatorHub.
Check that the Operator is running:
$ oc get pods -n openshift-operators -lapp=gpu-operator
gpu-operator-6b8b8c5fd9-zcs9r 1/1 Running 0 3h55mNote
If ImagePullBackOff is reported, maybe the NVIDIA registry is down. If CrashLoopBackOff is reported then the operator logs can be reviewed:
$ oc logs -f -n openshift-operators -lapp=gpu-operator
Validate the GPU stack
The GPU Operator validates the stack through the nvidia-device-plugin-validator and the nvidia-cuda-validator pod. If both completed successfully, the stack works as expected.
$ oc get po -n gpu-operator-resourcesNAME READY STATUS RESTARTS AGE gpu-feature-discovery-kfmcm 1/1 Running 0 4h14m nvidia-container-toolkit-daemonset-t5vgq 1/1 Running 0 4h14m nvidia-cuda-validator-2wjlm 0/1 Completed 0 97m nvidia-dcgm-exporter-tsjk7 1/1 Running 0 4h14m nvidia-dcgm-r7qbd 1/1 Running 0 4h14m nvidia-device-plugin-daemonset-zlchl 1/1 Running 0 4h14m nvidia-device-plugin-validator-76pts 0/1 Completed 0 96m nvidia-driver-daemonset-6zk6b 1/1 Running 32 4h14m nvidia-node-status-exporter-27jdc 1/1 Running 1 4h14m nvidia-operator-validator-cjsw7 1/1 Running 0 4h14m
Check the cuda validator logs:
$ oc logs -f nvidia-cuda-validator-2wjlm -n gpu-operator-resourcescuda workload validation is successfulCheck the nvidia-device-plugin-validator logs:
$ oc logs nvidia-device-plugin-validator-76pts -n gpu-operator-resources | tail
device-plugin workload validation is successful
Check the NVIDIA driver deployment
This is an illustrated example of a situation where the deployment of the Operator is not proceeding as expected.
Check the pods deployed to the gpu-operator-resources namespace:
$ oc get pods -n gpu-operator-resourcesNAME READY STATUS RESTARTS AGE gpu-feature-discovery-kfmcm 0/1 Init:0/1 0 53m nvidia-container-toolkit-daemonset-t5vgq 0/1 Init:0/1 0 53m nvidia-dcgm-exporter-tsjk7 0/1 Init:0/2 0 53m nvidia-dcgm-r7qbd 0/1 Init:0/1 0 53m nvidia-device-plugin-daemonset-zlchl 0/1 Init:0/1 0 53m nvidia-driver-daemonset-6zk6b 0/1 CrashLoopBackOff 13 53m nvidia-node-status-exporter-27jdc 1/1 Running 0 53m nvidia-operator-validator-cjsw7 0/1 Init:0/4 0 53m
The Init status indicates the driver pod is not ready. In this example the driver Pod is in state CrashLoopBackOff. This combined with the RESTARTS equal to 13 indicates a problem.
Check the main console page:
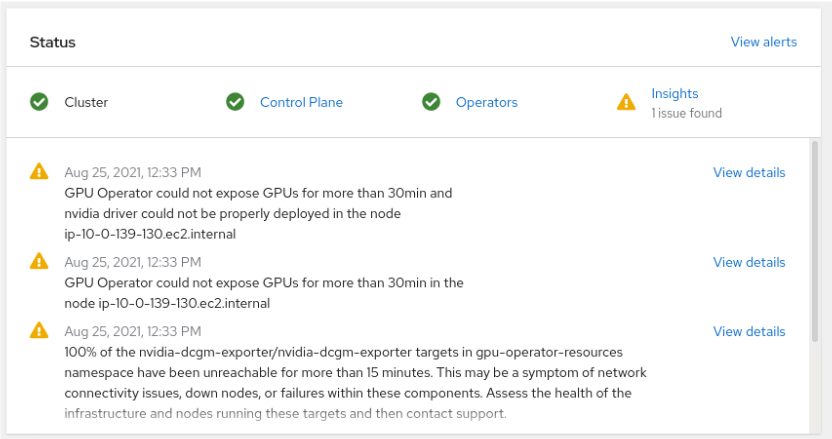
The first alert shows that the “nvidia driver could not be deployed”.
Note
Alerts are automatically enabled and logged in the console. For more information on alerts see, the OpenShift Container Platform documentation.
Check the NVIDIA driver logs:
$ oc logs -f nvidia-driver-daemonset-6zk6b -n gpu-operator-resources+ echo 'Installing elfutils...' Installing elfutils... + dnf install -q -y elfutils-libelf.x86_64 elfutils-libelf-devel.x86_64 Error: Unable to find a match: elfutils-libelf-devel.x86_64 ++ rm -rf /tmp/tmp.3jt46if6eF + _shutdown + _unload_driver + rmmod_args=() + local rmmod_args + local nvidia_deps=0 + local nvidia_refs=0 + local nvidia_uvm_refs=0 + local nvidia_modeset_refs=0 + echo 'Stopping NVIDIA persistence daemon...' Stopping NVIDIA persistence daemon...
In the logs this line below indicates there is an entitlement issue:
+ dnf install -q -y elfutils-libelf.x86_64 elfutils-libelf-devel.x86_64 Error: Unable to find a match: elfutils-libelf-devel.x86_64
This error indicates that the UBI-based driver pod does not have subscription entitlements correctly mounted so that additional required UBI packages are not found. Please refer to this section Obtaining an entitlement certificate.