MIG Support in OpenShift Container Platform
Introduction
NVIDIA Mult-Instance GPU (MIG) is useful anytime you have an application that does not require the full power of an entire GPU. The new NVIDIA Ampere architecture’s MIG feature allows you to split your hardware resources into multiple GPU instances, each exposed to the operating system as an independent CUDA-enabled GPU. The NVIDIA GPU Operator version 1.7.0 and above provides MIG feature support for the A100 and A30 Ampere cards. These GPU instances are designed to support multiple independent CUDA applications (up to 7), so they operate completely isolated from each other using dedicated hardware resources.
The compute units of the GPU, in addition to its memory, can be partitioned into multiple MIG instances. Each of these instances presents as a stand-alone GPU device from the system perspective and can be bound to any application, container, or virtual machine running on the node.
From the perspective of the software consuming the GPU each of these MIG instances looks like its own individual GPU.
MIG geometry
The NVIDIA GPU Operator version 1.7.0 and above enables OpenShift Container Platform administrators to dynamically reconfigure the geometry of the MIG partitioning. The geometry of the MIG partitioning is how hardware resources are bound to MIG instances, so it directly influences their performance and the number of instances that can be allocated. The A100-40GB, for example, has eight compute units and 40 GB of RAM. When the MIG mode is enabled, the eighth instance is reserved for resource management.
The table below provides a summary of the MIG instance properties of the NVIDIA A100-40GB product:
Profile |
Memory |
Compute Units |
Maximum number of homogeneous instances |
|---|---|---|---|
1g.5gb |
5 GB |
1 |
7 |
2g.10gb |
10 GB |
2 |
3 |
3g.20gb |
20 GB |
3 |
2 |
4g.20gb |
20 GB |
4 |
1 |
7g.40gb |
40 GB |
7 |
1 |
In addition to homogeneous instances, some heterogeneous combinations can be chosen. See the Multi-Instance GPU User Guide documentation for an exhaustive listing.
Here is an example, again for the A100-40GB, with heterogeneous (or “mixed”) geometries:
2x 1g.5gb
1x 2g.10gb
1x 3g.10gb
Prerequisites
The deployment workflow requires these prerequisites.
You already have a OpenShift Container Platform cluster up and running with access to at least one MIG-capable GPU.
You have followed the guidance in Installation and Upgrade Overview proceeding as far as creating the cluster policy <create-cluster-policy>.
Note
The node must be free (drained) of GPU workloads before any reconfiguration is triggered. For guidance on draining a node see, the OpenShift Container Platform documentation Understanding how to evacuate pods on nodes.
Configuring MIG Devices in OpenShift
MIG advertisement strategies
The NVIDIA GPU Operator exposes GPUs to Kubernetes as extended resources that can be requested and exposed into Pods and containers. The first step of the MIG configuration is to decide what Strategy you want. The advertisement strategies are described here:
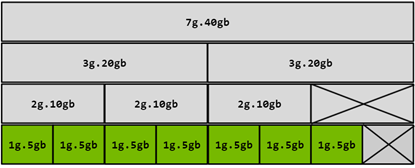
Single defines a homogeneous advertisement strategy, with MIG instances exposed as usual GPUs. This strategy exposes the MIG instances as
nvidia.com/gpuresources, identically, as usual non-MIG capable (or with MIG disabled) devices. In this strategy, all the GPUs in a single node must be configured in a homogenous manner (same number of compute units, same memory size). This strategy is best for a large cluster where the infrastructure teams can configure “node pools” of different MIG geometries and make them available to users. Another advantage of this strategy is backward compatibility where the existing application does not have to be modified to be scheduled this way.Examples for the A100-40GB:
1g.5gb: 7 nvidia.com/gpu instances, or
2g.10gb: 3 nvidia.com/gpu instances, or
3g.20gb: 2 nvidia.com/gpuinstances, or
7g.40gb: 1 nvidia.com/gpu instances
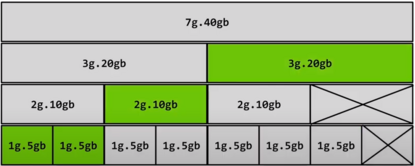
Mixed defines a heterogeneous advertisement strategy. There is no constraint on the geometry; all the combinations allowed by the GPU are permitted. This strategy is appropriate for a smaller cluster, where on a single node with multiple GPUs, each GPU can be configured in a different MIG geometry.
Examples for the A100-40GB:
All the single configurations are possible
A “balanced” configuration:
1g.5gb: 2 nvidia.com/mig-1g.5gb instances, and
2g.10gb: 1 nvidia.com/mig-2g.10gb instance, and
3g.20gb: 1 nvidia.com/mig-3g.20gb instance
Version 1.8 and greater of the NVIDIA GPU Operator supports updating the Strategy in the ClusterPolicy after deployment.
The default configmap defines the combination of single (homogeneous) and mixed (heterogeneous) profiles that are supported for A100-40GB, A100-80GB and A30-24GB. The configmap allows administrators to declaratively define a set of possible MIG configurations they would like applied to all GPUs on a node. The tables below describe these configurations:
GPU Type |
Custom label |
Profile |
MIG instances |
|---|---|---|---|
A100-40GB |
|||
all-1g.5gb |
1g.5gb |
7 |
|
all-2g.10gb |
2g.10gb |
3 |
|
all-3g.20gb |
3g.20gb |
2 |
|
all-7g.40gb |
7g.40gb |
1 |
|
A100-80GB |
|||
all-1g.10gb |
1g.10gb |
7 |
|
all-2g.20gb |
2g.20gb |
3 |
|
all-3g.40gb |
3g.40gb |
2 |
|
all-7g.80gb |
7g.80gb |
1 |
|
A30-24GB |
|||
all-1g.6gb |
1g.6gb |
4 |
|
all-2g.12gb |
2g.12gb |
2 |
|
all-4g.24gb |
4g.24gb |
1 |
|
All-balanced is composed of 3 distinct configurations, with a device-filter filtering, based on the device UID. The possible supported combinations are described below:
GPU Type |
Custom label |
Profile and MIG instances |
|---|---|---|
A100-40GB |
||
all-balanced |
1g.5gb: 2 2g.10gb:1 3g.20gb:1 |
|
A100-80GB |
||
all-balanced |
1g.10gb:2 2g.20gb:1 3g.40gb:1 |
|
A30-24GB |
||
all-balanced |
1g.6gb: 2 2g.12gb:1 |
|
Set the MIG advertisement strategy and apply the MIG partitioning
Having decided on your advertisement strategy you need to set this by editing the default cluster policy and then apply the MIG partitioning profile.
For example to set the advertisement strategy to mixed and the MIG partitioning profile to 3x 2g.10gb MIG devices follow the step below:
In the OpenShift Container Platform CLI run the following:
$ STRATEGY=mixed && \ oc patch clusterpolicy/gpu-cluster-policy --type='json' -p='[{"op": "replace", "path": "/spec/mig/strategy", "value": '$STRATEGY'}]'
Note
This may take a while so be patient and wait at least 10-20 minutes before digging deeper into any form of troubleshooting.
In the OpenShift Container Platform web console, from the side menu, select Operators > Installed Operators, then click the NVIDIA GPU Operator.
Select the ClusterPolicy tab. The status of the newly deployed ClusterPolicy gpu-cluster-policy for the NVIDIA GPU Operator displays
State:readyonce the installation succeeded.
Apply the desired MIG partitioning profile. To configure 3x 2g.10gb MIG devices run the following:
$ MIG_CONFIGURATION=all-2g.10gb && \ oc label node/$NODE_NAME nvidia.com/mig.config=$MIG_CONFIGURATION --overwrite
Wait for the
mig-managerto perform the reconfiguration:$ oc -n nvidia-gpu-operator logs ds/nvidia-mig-manager --all-containers -f --prefixThe status of the reconfiguration should change from success → pending → success.
Verify the new configuration is applied:
$ oc get pods -n nvidia-gpu-operator -lapp=nvidia-driver-daemonset -owide
Select the name of the Pod on the MIG GPU enabled node and run the following:
$ oc rsh -n nvidia-gpu-operator $POD_NAME nvidia-smi mig -lgi
+----------------------------------------------------+ | GPU instances: | | GPU Name Profile Instance Placement | | ID ID Start:Size | |====================================================| | 0 MIG 2g.10gb 19 3 4:2 | +----------------------------------------------------+ | 0 MIG 2g.10gb 19 5 0:2 | +----------------------------------------------------+ | 0 MIG 2g.10gb 19 6 2:2 | +----------------------------------------------------+
With the profile in step 4 applied the A100 is configured into 3 MIG devices.
Check the node has been labeled:
$ oc get nodes/$NODE_NAME --show-labels | tr ',' '\n' | grep nvidia.com
with labels:
nvidia.com/gpu.present=true nvidia.com/cuda.driver.major=470 nvidia.com/cuda.driver.minor=57 nvidia.com/cuda.driver.rev=02 nvidia.com/cuda.runtime.major=11 nvidia.com/cuda.runtime.minor=4 nvidia.com/gpu.compute.major=8 nvidia.com/gpu.compute.minor=0 nvidia.com/gpu.count=1 nvidia.com/gpu.family=ampere nvidia.com/gpu.machine=... nvidia.com/gpu.memory=40536 nvidia.com/gpu.product=NVIDIA-A100-SXM4-40GB nvidia.com/mig-2g.10gb.count=3 nvidia.com/mig-2g.10gb.engines.copy=2 nvidia.com/mig-2g.10gb.engines.decoder=1 nvidia.com/mig-2g.10gb.engines.encoder=0 nvidia.com/mig-2g.10gb.engines.jpeg=0 nvidia.com/mig-2g.10gb.engines.ofa=0 nvidia.com/mig-2g.10gb.memory=9984 nvidia.com/mig-2g.10gb.multiprocessors=28 nvidia.com/mig-2g.10gb.slices.ci=2 nvidia.com/mig-2g.10gb.slices.gi=2 nvidia.com/mig.config.state=success nvidia.com/mig.config=all-2g.10gb nvidia.com/mig.strategy=mixed [...]
Note
The extract above shows the strategy is set to
mixedwith the MIG configuration set toall-2g.10gb.Verify that the MIG instances are exposed:
$ oc get node/$NODE_NAME -ojsonpath={.status.allocatable} | jq . | grep nvidia
"nvidia.com/mig-2g.10gb": "3",Note
You can ignore values set to 0.
Creating and applying a custom MIG configuration
Follow the guidance below to create a new slicing profile.
Prepare a custom
configmapresource file for examplecustom_configmap.yaml. Use the configmap as guidance to help you build that custom configuration. For more documentation about the file format see mig-parted.Note
For a list of all supported combinations and placements of profiles on A100 and A30, refer to the section on supported profiles.
Create the custom configuration within the
nvidia-gpu-operatornamespace:$ CONFIG_FILE=/path/to/custom_configmap.yaml && \ oc create configmap custom-mig-parted-config \ --from-file=config.yaml=$CONFIG_FILE \ -n nvidia-gpu-operator
Edit the cluster policy and enter the name of the config map in the field
spec.migManager.config.name:$ oc edit clusterpolicy spec: migManager: config: name: custom-mig-parted-config
Label the node with this newly created profile following the guidance in Set the MIG advertisement strategy and apply the MIG partitioning.
Example: Mixed MIG strategy
Introduction and default MIG configuration
For each MIG configuration, you specify a strategy and a MIG configuration label.
This example shows how to configure a mixed strategy with the all-balanced configuration on one NVIDIA DGX H100 host with 8 x H100 80GB GPUs.
The DGX H100 host runs a single node installation of OpenShift.
By default, MIG is disabled and is configured with the single strategy:
$ oc describe node | grep nvidia.com/mig
Example Output
nvidia.com/mig.capable=true
nvidia.com/mig.config=all-disabled
nvidia.com/mig.config.state=success
nvidia.com/mig.strategy=single
With the default configuration, the host supports up to 8 pods with GPUs:
$ oc describe node | egrep "Name:|Roles:|Capacity|nvidia.com/gpu|Allocatable:|Requests +Limits"
Example Output
Name: myworker.redhat.com
Roles: control-plane,master,worker
Capacity:
nvidia.com/gpu: 8
Allocatable:
nvidia.com/gpu: 8
Resource Requests Limits
nvidia.com/gpu 0 0
Procedure
The following steps show how to apply the mixed strategy with the MIG configuration label all-balanced.
With this strategy and label, each H100 GPU enables these MIG profiles:
2 x 1g.10gb
1 x 2g.20gb
1 x 3g.40g
For the NVIDIA DGX H100 that has 8 H100 GPUs, performing the steps results in the following GPU capacity on the cluster:
16 x 1g.10gb (8 x 2)
8 x 2g.20gb (8 x 1)
8 x 3g.40gb (8 x 1)
Specify the host name, strategy, and configuration label in environment variables:
$ NODE_NAME=myworker.redhat.com $ STRATEGY=mixed $ MIG_CONFIGURATION=all-balanced
Apply the strategy:
$ oc patch clusterpolicy/gpu-cluster-policy --type='json' \ -p='[{"op": "replace", "path": "/spec/mig/strategy", "value": '$STRATEGY'}]'
Label the node with the configuration label:
$ oc label node $NODE_NAME nvidia.com/mig.config=$MIG_CONFIGURATION --overwrite
MIG manager applies a
mig.config.statelabel to the GPU and then terminates all the GPU pods in preparation to enable MIG mode and configure the GPU into the specified configuration.Optional: Verify that MIG manager configured the GPUs:
$ oc describe node | grep nvidia.com/mig.config
Example Output
nvidia.com/mig.config=all-balanced nvidia.com/mig.config.state=success
Confirm that the GPU resources are available:
$ oc describe node | egrep "Name:|Roles:|Capacity|nvidia.com/gpu:|nvidia.com/mig-.* |Allocatable:|Requests +Limits"
The following sample output shows the expected 32 GPU resources:
16 x 1g.10gb
8 x 1g.10gb
8 x 3g.40gb
Name: myworker.redhat.com Roles: control-plane,master,worker Capacity: nvidia.com/gpu: 0 nvidia.com/mig-1g.10gb: 16 nvidia.com/mig-2g.20gb: 8 nvidia.com/mig-3g.40gb: 8 Allocatable: nvidia.com/gpu: 0 nvidia.com/mig-1g.10gb: 16 nvidia.com/mig-2g.20gb: 8 nvidia.com/mig-3g.40gb: 8 Resource Requests Limits nvidia.com/mig-1g.10gb 0 0 nvidia.com/mig-2g.20gb 0 0 nvidia.com/mig-3g.40gb 0 0
Optional: Start a pod to run the
nvidia-smicommand and display the GPU resources.Start the pod:
$ cat <<EOF | oc apply -f - apiVersion: v1 kind: Pod metadata: name: command-nvidia-smi spec: restartPolicy: Never containers: - name: cuda-container image: nvcr.io/nvidia/cuda:12.1.0-base-ubi8 command: ["/bin/sh","-c"] args: ["nvidia-smi"] EOF
Confirm the pod ran successfully:
$ oc get podsExample Output
NAME READY STATUS RESTARTS AGE command-nvidia-smi 0/1 Completed 0 3m34s
Confirm that the
nvidia-smioutput includes 32 MIG devices:$ oc logs command-nvidia-smiExample Output
+---------------------------------------------------------------------------------------+ | NVIDIA-SMI 535.104.12 Driver Version: 535.104.12 CUDA Version: 12.2 | |-----------------------------------------+----------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+======================+======================| | 0 NVIDIA H100 80GB HBM3 On | 00000000:1B:00.0 Off | On | | N/A 25C P0 71W / 700W | N/A | N/A Default | | | | Enabled | +-----------------------------------------+----------------------+----------------------+ | 1 NVIDIA H100 80GB HBM3 On | 00000000:43:00.0 Off | On | | N/A 26C P0 70W / 700W | N/A | N/A Default | | | | Enabled | +-----------------------------------------+----------------------+----------------------+ | 2 NVIDIA H100 80GB HBM3 On | 00000000:52:00.0 Off | On | | N/A 31C P0 72W / 700W | N/A | N/A Default | | | | Enabled | +-----------------------------------------+----------------------+----------------------+ | 3 NVIDIA H100 80GB HBM3 On | 00000000:61:00.0 Off | On | | N/A 29C P0 71W / 700W | N/A | N/A Default | | | | Enabled | +-----------------------------------------+----------------------+----------------------+ | 4 NVIDIA H100 80GB HBM3 On | 00000000:9D:00.0 Off | On | | N/A 26C P0 71W / 700W | N/A | N/A Default | | | | Enabled | +-----------------------------------------+----------------------+----------------------+ | 5 NVIDIA H100 80GB HBM3 On | 00000000:C3:00.0 Off | On | | N/A 25C P0 70W / 700W | N/A | N/A Default | | | | Enabled | +-----------------------------------------+----------------------+----------------------+ | 6 NVIDIA H100 80GB HBM3 On | 00000000:D1:00.0 Off | On | | N/A 29C P0 73W / 700W | N/A | N/A Default | | | | Enabled | +-----------------------------------------+----------------------+----------------------+ | 7 NVIDIA H100 80GB HBM3 On | 00000000:DF:00.0 Off | On | | N/A 31C P0 72W / 700W | N/A | N/A Default | | | | Enabled | +-----------------------------------------+----------------------+----------------------+ +---------------------------------------------------------------------------------------+ | MIG devices: | +------------------+--------------------------------+-----------+-----------------------+ | GPU GI CI MIG | Memory-Usage | Vol| Shared | | ID ID Dev | BAR1-Usage | SM Unc| CE ENC DEC OFA JPG | | | | ECC| | |==================+================================+===========+=======================| | 0 2 0 0 | 16MiB / 40448MiB | 60 0 | 3 0 3 0 3 | | | 0MiB / 65535MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 0 3 0 1 | 11MiB / 20096MiB | 32 0 | 2 0 2 0 2 | | | 0MiB / 32767MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 0 9 0 2 | 5MiB / 9984MiB | 16 0 | 1 0 1 0 1 | | | 0MiB / 16383MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 0 10 0 3 | 5MiB / 9984MiB | 16 0 | 1 0 1 0 1 | | | 0MiB / 16383MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 1 2 0 0 | 16MiB / 40448MiB | 60 0 | 3 0 3 0 3 | | | 0MiB / 65535MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 1 3 0 1 | 11MiB / 20096MiB | 32 0 | 2 0 2 0 2 | | | 0MiB / 32767MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 1 9 0 2 | 5MiB / 9984MiB | 16 0 | 1 0 1 0 1 | | | 0MiB / 16383MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 1 10 0 3 | 5MiB / 9984MiB | 16 0 | 1 0 1 0 1 | | | 0MiB / 16383MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 2 2 0 0 | 16MiB / 40448MiB | 60 0 | 3 0 3 0 3 | | | 0MiB / 65535MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 2 3 0 1 | 11MiB / 20096MiB | 32 0 | 2 0 2 0 2 | | | 0MiB / 32767MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 2 9 0 2 | 5MiB / 9984MiB | 16 0 | 1 0 1 0 1 | | | 0MiB / 16383MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 2 10 0 3 | 5MiB / 9984MiB | 16 0 | 1 0 1 0 1 | | | 0MiB / 16383MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 3 2 0 0 | 16MiB / 40448MiB | 60 0 | 3 0 3 0 3 | | | 0MiB / 65535MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 3 3 0 1 | 11MiB / 20096MiB | 32 0 | 2 0 2 0 2 | | | 0MiB / 32767MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 3 9 0 2 | 5MiB / 9984MiB | 16 0 | 1 0 1 0 1 | | | 0MiB / 16383MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 3 10 0 3 | 5MiB / 9984MiB | 16 0 | 1 0 1 0 1 | | | 0MiB / 16383MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 4 1 0 0 | 16MiB / 40448MiB | 60 0 | 3 0 3 0 3 | | | 0MiB / 65535MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 4 5 0 1 | 11MiB / 20096MiB | 32 0 | 2 0 2 0 2 | | | 0MiB / 32767MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 4 13 0 2 | 5MiB / 9984MiB | 16 0 | 1 0 1 0 1 | | | 0MiB / 16383MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 4 14 0 3 | 5MiB / 9984MiB | 16 0 | 1 0 1 0 1 | | | 0MiB / 16383MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 5 1 0 0 | 16MiB / 40448MiB | 60 0 | 3 0 3 0 3 | | | 0MiB / 65535MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 5 5 0 1 | 11MiB / 20096MiB | 32 0 | 2 0 2 0 2 | | | 0MiB / 32767MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 5 13 0 2 | 5MiB / 9984MiB | 16 0 | 1 0 1 0 1 | | | 0MiB / 16383MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 5 14 0 3 | 5MiB / 9984MiB | 16 0 | 1 0 1 0 1 | | | 0MiB / 16383MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 6 2 0 0 | 16MiB / 40448MiB | 60 0 | 3 0 3 0 3 | | | 0MiB / 65535MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 6 3 0 1 | 11MiB / 20096MiB | 32 0 | 2 0 2 0 2 | | | 0MiB / 32767MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 6 9 0 2 | 5MiB / 9984MiB | 16 0 | 1 0 1 0 1 | | | 0MiB / 16383MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 6 10 0 3 | 5MiB / 9984MiB | 16 0 | 1 0 1 0 1 | | | 0MiB / 16383MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 7 2 0 0 | 16MiB / 40448MiB | 60 0 | 3 0 3 0 3 | | | 0MiB / 65535MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 7 3 0 1 | 11MiB / 20096MiB | 32 0 | 2 0 2 0 2 | | | 0MiB / 32767MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 7 9 0 2 | 5MiB / 9984MiB | 16 0 | 1 0 1 0 1 | | | 0MiB / 16383MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 7 10 0 3 | 5MiB / 9984MiB | 16 0 | 1 0 1 0 1 | | | 0MiB / 16383MiB | | | +------------------+--------------------------------+-----------+-----------------------+ +---------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=======================================================================================| | No running processes found | +---------------------------------------------------------------------------------------+
Delete the sample pod:
$ oc delete pod command-nvidia-smiExample Output
pod "command-nvidia-smi" deleted
Example: Single MIG strategy
This example shows how to configure a single strategy with the all-3g.40gb configuration on one NVIDIA DGX H100 host with 8 x H100 80GB GPUs.
The DGX H100 host runs a single node installation of OpenShift.
For information about the initial default MIG configuration and viewing it, refer to the beginning of Example: Mixed MIG strategy.
Specify the host name, strategy, and configuration label in environment variables:
$ NODE_NAME=myworker.redhat.com $ STRATEGY=single $ MIG_CONFIGURATION=all-3g.40gb
Apply the strategy:
$ oc patch clusterpolicy/gpu-cluster-policy --type='json' \ -p='[{"op": "replace", "path": "/spec/mig/strategy", "value": '$STRATEGY'}]'
Label the node with the configuration label:
$ oc label node $NODE_NAME nvidia.com/mig.config=$MIG_CONFIGURATION --overwrite
MIG manager applies a
mig.config.statelabel to the GPU and then terminates all the GPU pods in preparation to enable MIG mode and configure the GPU into the specified configuration.Confirm that the GPU resources are available:
$ oc describe node | egrep "Name:|Roles:|Capacity|nvidia.com/gpu:|nvidia.com/mig-.* |Allocatable:|Requests +Limits"
The following sample output shows the expected 16 GPUs:
Name: myworker.redhat.com Roles: control-plane,master,worker Capacity: nvidia.com/gpu: 16 nvidia.com/mig-1g.10gb: 0 nvidia.com/mig-2g.20gb: 0 nvidia.com/mig-3g.40gb: 0 Allocatable: nvidia.com/gpu: 16 nvidia.com/mig-1g.10gb: 0 nvidia.com/mig-2g.20gb: 0 nvidia.com/mig-3g.40gb: 0 Resource Requests Limits nvidia.com/mig-1g.10gb 0 0 nvidia.com/mig-2g.20gb 0 0 nvidia.com/mig-3g.40gb 0 0
Optional: Start a pod to run the
nvidia-smicommand and display the GPU resources.Start the pod:
$ cat <<EOF | oc apply -f - apiVersion: v1 kind: Pod metadata: name: command-nvidia-smi spec: restartPolicy: Never containers: - name: cuda-container image: nvcr.io/nvidia/cuda:12.1.0-base-ubi8 command: ["/bin/sh","-c"] args: ["nvidia-smi"] EOF
Confirm the pod ran successfully:
$ oc get podsExample Output
NAME READY STATUS RESTARTS AGE command-nvidia-smi 0/1 Completed 0 3m34s
Confirm that the
nvidia-smioutput includes 16 MIG devices:$ oc logs command-nvidia-smiExample Output
+---------------------------------------------------------------------------------------+ | NVIDIA-SMI 535.104.12 Driver Version: 535.104.12 CUDA Version: 12.2 | |-----------------------------------------+----------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+======================+======================| | 0 NVIDIA H100 80GB HBM3 On | 00000000:1B:00.0 Off | On | | N/A 25C P0 75W / 700W | N/A | N/A Default | | | | Enabled | +-----------------------------------------+----------------------+----------------------+ | 1 NVIDIA H100 80GB HBM3 On | 00000000:43:00.0 Off | On | | N/A 27C P0 74W / 700W | N/A | N/A Default | | | | Enabled | +-----------------------------------------+----------------------+----------------------+ | 2 NVIDIA H100 80GB HBM3 On | 00000000:52:00.0 Off | On | | N/A 32C P0 75W / 700W | N/A | N/A Default | | | | Enabled | +-----------------------------------------+----------------------+----------------------+ | 3 NVIDIA H100 80GB HBM3 On | 00000000:61:00.0 Off | On | | N/A 30C P0 74W / 700W | N/A | N/A Default | | | | Enabled | +-----------------------------------------+----------------------+----------------------+ | 4 NVIDIA H100 80GB HBM3 On | 00000000:9D:00.0 Off | On | | N/A 27C P0 75W / 700W | N/A | N/A Default | | | | Enabled | +-----------------------------------------+----------------------+----------------------+ | 5 NVIDIA H100 80GB HBM3 On | 00000000:C3:00.0 Off | On | | N/A 25C P0 73W / 700W | N/A | N/A Default | | | | Enabled | +-----------------------------------------+----------------------+----------------------+ | 6 NVIDIA H100 80GB HBM3 On | 00000000:D1:00.0 Off | On | | N/A 30C P0 77W / 700W | N/A | N/A Default | | | | Enabled | +-----------------------------------------+----------------------+----------------------+ | 7 NVIDIA H100 80GB HBM3 On | 00000000:DF:00.0 Off | On | | N/A 31C P0 76W / 700W | N/A | N/A Default | | | | Enabled | +-----------------------------------------+----------------------+----------------------+ +---------------------------------------------------------------------------------------+ | MIG devices: | +------------------+--------------------------------+-----------+-----------------------+ | GPU GI CI MIG | Memory-Usage | Vol| Shared | | ID ID Dev | BAR1-Usage | SM Unc| CE ENC DEC OFA JPG | | | | ECC| | |==================+================================+===========+=======================| | 0 1 0 0 | 16MiB / 40448MiB | 60 0 | 3 0 3 0 3 | | | 0MiB / 65535MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 0 2 0 1 | 16MiB / 40448MiB | 60 0 | 3 0 3 0 3 | | | 0MiB / 65535MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 1 1 0 0 | 16MiB / 40448MiB | 60 0 | 3 0 3 0 3 | | | 0MiB / 65535MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 1 2 0 1 | 16MiB / 40448MiB | 60 0 | 3 0 3 0 3 | | | 0MiB / 65535MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 2 1 0 0 | 16MiB / 40448MiB | 60 0 | 3 0 3 0 3 | | | 0MiB / 65535MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 2 2 0 1 | 16MiB / 40448MiB | 60 0 | 3 0 3 0 3 | | | 0MiB / 65535MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 3 1 0 0 | 16MiB / 40448MiB | 60 0 | 3 0 3 0 3 | | | 0MiB / 65535MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 3 2 0 1 | 16MiB / 40448MiB | 60 0 | 3 0 3 0 3 | | | 0MiB / 65535MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 4 1 0 0 | 16MiB / 40448MiB | 60 0 | 3 0 3 0 3 | | | 0MiB / 65535MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 4 2 0 1 | 16MiB / 40448MiB | 60 0 | 3 0 3 0 3 | | | 0MiB / 65535MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 5 1 0 0 | 16MiB / 40448MiB | 60 0 | 3 0 3 0 3 | | | 0MiB / 65535MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 5 2 0 1 | 16MiB / 40448MiB | 60 0 | 3 0 3 0 3 | | | 0MiB / 65535MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 6 1 0 0 | 16MiB / 40448MiB | 60 0 | 3 0 3 0 3 | | | 0MiB / 65535MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 6 2 0 1 | 16MiB / 40448MiB | 60 0 | 3 0 3 0 3 | | | 0MiB / 65535MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 7 1 0 0 | 16MiB / 40448MiB | 60 0 | 3 0 3 0 3 | | | 0MiB / 65535MiB | | | +------------------+--------------------------------+-----------+-----------------------+ | 7 2 0 1 | 16MiB / 40448MiB | 60 0 | 3 0 3 0 3 | | | 0MiB / 65535MiB | | | +------------------+--------------------------------+-----------+-----------------------+ +---------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=======================================================================================| | No running processes found | +---------------------------------------------------------------------------------------+
Delete the sample pod:
$ oc delete pod command-nvidia-smiExample Output
pod "command-nvidia-smi" deleted
Running a sample GPU application
Let’s run a simple CUDA sample, in this case vectorAdd by requesting a GPU resource as you would normally do in Kubernetes.
If the cluster is configured with the mixed advertisement strategy.
Request the MIG instance with
nvidia.com/mig-2g.10gb: 1as follows:Note
There is no need for a nodeSelector, as the Pod is necessarily scheduled on a
2g.10gbMIG instance.$ cat << EOF | oc create -f - apiVersion: v1 kind: Pod metadata: name: cuda-vectoradd spec: restartPolicy: OnFailure containers: - name: cuda-vectoradd image: "nvidia/samples:vectoradd-cuda11.2.1" resources: limits: nvidia.com/mig-2g.10gb: 1
pod/cuda-vectoradd createdCheck the logs of the container:
$ oc logs cuda-vectoradd[Vector addition of 50000 elements] Copy input data from the host memory to the CUDA device CUDA kernel launch with 196 blocks of 256 threads Copy output data from the CUDA device to the host memory Test PASSED Done
If the cluster is configured with the single advertisement strategy.
Request the MIG instance with
nvidia.com/gpu: 1and enforce the Pod scheduling on a node with a2g.10gbMIG instance with thenodeSelectorstanza as follows:$ cat << EOF | oc create -f - apiVersion: v1 kind: Pod metadata: name: cuda-vectoradd spec: restartPolicy: OnFailure containers: - name: cuda-vectoradd image: "nvidia/samples:vectoradd-cuda11.2.1" resources: limits: nvidia.com/gpu: 1 nodeSelector: nvidia.com/gpu.product: A100-SXM4-40GB-MIG-1g.5gb EOF
Disable the MIG mode
To turn MIG mode off so that you can utilize the full capacity of the GPU run the following:
$ MIG_CONFIGURATION=all-disabled && \ oc label node/$NODE_NAME nvidia.com/mig.config=$MIG_CONFIGURATION --overwrite
Troubleshooting
The MIG reconfiguration is handled exclusively by the controller deployed within the nvidia-mig-manager DaemonSet. Inspecting the logs of these Pods should give a clue about what went wrong.
Check the logs of the container:
$ oc logs nvidia-mig-managerThe cluster administrator is expected to drain the node from any GPU workload, before requesting the MIG reconfiguration. If the node is not properly drained, the
nvidia-mig-managerwill fail with this error in the logs:Updating MIG config: map[2g.10gb:3] Error clearing MigConfig: error destroying Compute instance for profile '(0, 0)': In use by another client Error clearing MIG config on GPU 0, erroneous devices may persist Error setting MIGConfig: error attempting multiple config orderings: all orderings failed Restarting all GPU clients previously shutdown by reenabling their component-specific nodeSelector labels Changing the 'nvidia.com/mig.config.state' node label to 'failed'
Resolve this issue by:
Correctly draining the node. For guidance on draining a node see, the OpenShift Container Platform documentation Understanding how to evacuate pods on nodes.
Retrigger the reconfiguration by forcing the label update:
$ oc label node/$NODE_NAME nvidia.com/mig.config- --overwrite
$ oc label node/$NODE_NAME nvidia.com/mig.config=$MIG_CONFIGURATION --overwrite