Abstract
This cuDNN 8.9.4 Developer Guide explains how to use the NVIDIA cuDNN library. While the NVIDIA cuDNN API Reference provides per-function API documentation, the Developer Guide gives a more informal end-to-end story about cuDNN’s key capabilities and how to use them.
1. Overview
Beyond just providing performant implementations of individual operations, the library also supports a flexible set of multi-operation fusion patterns for further optimization. The goal is to achieve the best available performance on NVIDIA GPUs for important deep learning use cases.
In cuDNN version 7 and older, the API was designed to support a fixed set of operations and fusion patterns. We informally call this the “legacy API”. Starting in cuDNN version 8, to address the quickly expanding set of popular fusion patterns, we added a graph API, which allows the user to express a computation by defining an operation graph, rather than by selecting from a fixed set of API calls. This offers better flexibility versus the legacy API, and for most use cases, is the recommended way to use cuDNN.
Note that while the cuDNN library exposes a C API, we also provide an open source C++ layer which wraps the C API and is considered more convenient for most users. It is, however, limited to just the graph API, and does not support the legacy API.
2. Core Concepts
2.1. cuDNN Handle
An application using cuDNN must initialize a handle to the library context by calling cudnnCreate(). This handle is explicitly passed to every subsequent library function that operates on GPU data. Once the application finishes using cuDNN, it can release the resources associated with the library handle using cudnnDestroy(). This approach allows the user to explicitly control the library's functioning when using multiple host threads, GPUs, and CUDA streams.
For example, an application can use cudaSetDevice (prior to creating a cuDNN handle) to associate different devices with different host threads, and in each of those host threads, create a unique cuDNN handle that directs the subsequent library calls to the device associated with it. In this case, the cuDNN library calls made with different handles would automatically run on different devices.
The device associated with a particular cuDNN context is assumed to remain unchanged between the corresponding cudnnCreate() and cudnnDestroy() calls. In order for the cuDNN library to use a different device within the same host thread, the application must set the new device to be used by calling cudaSetDevice() and then create another cuDNN context, which will be associated with the new device, by calling cudnnCreate().
2.2. Tensors and Layouts
2.2.1. Tensor Descriptor
This tensor definition allows, for example, to have some dimensions overlapping each other within the same tensor by having the stride of one dimension smaller than the product of the dimension and the stride of the next dimension. In cuDNN, unless specified otherwise, all routines will support tensors with overlapping dimensions for forward-pass input tensors, however, dimensions of the output tensors cannot overlap. Even though this tensor format supports negative strides (which can be useful for data mirroring), cuDNN routines do not support tensors with negative strides unless specified otherwise.
2.2.1.1. WXYZ Tensor Descriptor
- all the strides are strictly positive
- the dimensions referenced by the letters are sorted in decreasing order of their respective strides
2.2.1.2. 3-D Tensor Descriptor
2.2.1.3. 4-D Tensor Descriptor
- NCHW
- NHWC
- CHWN
2.2.1.4. 5-D Tensor Descriptor
- NCDHW
- NDHWC
- CDHWN
2.2.1.5. Fully-Packed Tensors
- the number of tensor dimensions is equal to the number of letters preceding the fully-packed suffix
- the stride of the i-th dimension is equal to the product of the (i+1)-th dimension by the (i+1)-th stride
- the stride of the last dimension is 1
2.2.1.6. Partially-Packed Tensors
- the strides of all dimensions NOT referenced in the -packed suffix are greater or equal to the product of the next dimension by the next stride
- the stride of each dimension referenced in the -packed suffix in position i is equal to the product of the (i+1)-st dimension by the (i+1)-st stride
- if the last tensor's dimension is present in the -packed suffix, its stride is 1
For example, an NHWC tensor WC-packed means that the c_stride is equal to 1 and w_stride is equal to c_dim x c_stride. In practice, the -packed suffix is usually applied to the minor dimensions of a tensor but can be applied to only the major dimensions; for example, an NCHW tensor that is only N-packed.
2.2.1.7. Spatially Packed Tensors
2.2.1.8. Overlapping Tensors
2.2.2. Data Layout Formats
The recommended way to specify the layout format of a tensor is by setting its strides accordingly. For compatibility with the v7 API, a subset of the layout formats can also be configured through the cudnnTensorFormat_t enum. The enum is only supplied for legacy reasons and is deprecated.
2.2.2.1. Example Tensor
- N is the batch size; 1
- C is the number of feature maps (that is,, number of channels); 64
- H is the image height; 5
- W is the image width; 4
To keep the example simple, the image pixel elements are expressed as a sequence of integers, 0, 1, 2, 3, and so on. Refer to Figure 1.
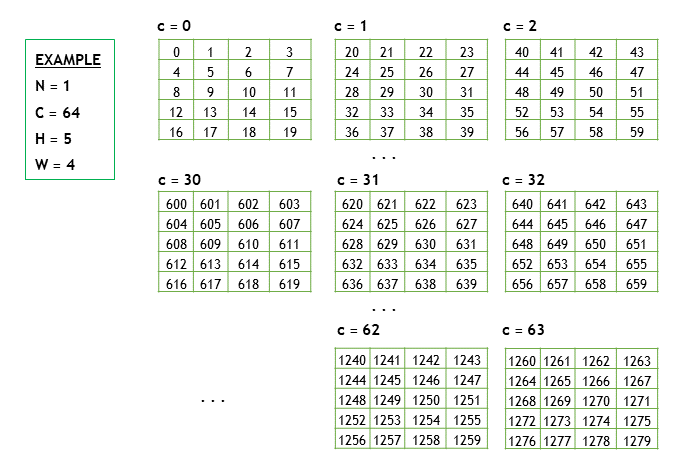
In the following subsections, we’ll use the above example to demonstrate the different layout formats.
2.2.2.2. Convolution Layouts
2.2.2.2.1. NCHW Memory Layout
- Beginning with the first channel (c=0), the elements are arranged contiguously in row-major order.
- Continue with second and subsequent channels until the elements of all the channels are laid out. Refer to Figure 2.
- Proceed to the next batch (if N is > 1).
2.2.2.2.2. NHWC Memory Layout
- Begin with the first element of channel 0, then proceed to the first element of channel 1, and so on, until the first elements of all the C channels are laid out.
- Next, select the second element of channel 0, then proceed to the second element of channel 1, and so on, until the second element of all the channels are laid out.
- Follow the row-major order of channel 0 and complete all the elements. Refer to Figure 3.
- Proceed to the next batch (if N is > 1).
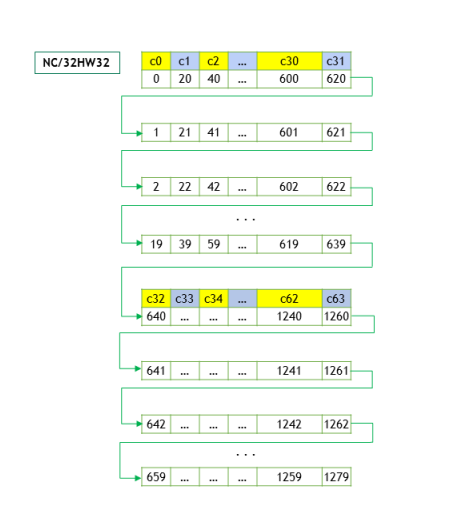
2.2.2.2.3. NC/32HW32 Memory Layout
2.2.2.3. MatMul Layouts
- Packed Row-major: dim [B,M,N] with stride [MN, N, 1], or
- Packed Column-major: dim [B,M,N] with stride [MN, 1, M]
Unpacked layouts for 3-D tensors are supported as well, but their support surface is more ragged.
2.3. Tensor Core Operations
Tensor Core operations accelerate matrix math operations; cuDNN uses Tensor Core operations that accumulate into FP16, FP32, and INT32 values. Setting the math mode to CUDNN_TENSOR_OP_MATH via the cudnnMathType_t enumerator indicates that the library will use Tensor Core operations. This enumerator specifies the available options to enable the Tensor Core and should be applied on a per-routine basis.
The default math mode is CUDNN_DEFAULT_MATH, which indicates that the Tensor Core operations will be avoided by the library. Because the CUDNN_TENSOR_OP_MATH mode uses the Tensor Cores, it is possible that these two modes generate slightly different numerical results due to different sequencing of the floating-point operations.
For example, the result of multiplying two matrices using Tensor Core operations is very close, but not always identical, to the result achieved using a sequence of scalar floating-point operations. For this reason, the cuDNN library requires an explicit user opt-in before enabling the use of Tensor Core operations.
However, experiments with training common deep learning models show negligible differences between using Tensor Core operations and scalar floating point paths, as measured by both the final network accuracy and the iteration count to convergence. Consequently, the cuDNN library treats both modes of operation as functionally indistinguishable and allows for the scalar paths to serve as legitimate fallbacks for cases in which the use of Tensor Core operations is unsuitable.
For more information, refer to NVIDIA Training with Mixed Precision.
- Make sure that the convolution operation is eligible for Tensor Cores by avoiding any combinations of large padding and large filters.
- Transform the inputs and filters to NHWC, pre-pad channel and batch size to be a multiple of 8.
- Make sure that all user-provided tensors, workspace, and reserve space are aligned to 128-bit boundaries. Note that 1024-bit alignment may deliver better performance.
2.3.1. Notes on Tensor Core Precision
For an FP32 accumulation, with FP16 output, the output of the accumulator is down-converted to FP16. Generally, the accumulation type is of greater or equal precision to the output type.
3. Graph API
The user starts by building a graph of operations. At a high level, the user is describing a dataflow graph of operations on tensors. Given a finalized graph, the user then selects and configures an engine that can execute that graph. There are several methods for selecting and configuring engines, which have tradeoffs with respect to ease-of-use, runtime overhead, and engine performance.
- NVIDIA cuDNN Backend API (lowest level entry point into the graph API)
- NVIDIA cuDNN Frontend API (convenience layer on top of the C backend API)
- It is less verbose without loss of control - all functionality accessible through the backend API is also accessible through the frontend API.
- It adds functionality on top of the backend API, like errata filters and autotuning.
- It is open source.
In either case (that is, the backend or frontend API), the high level concepts are the same.
3.1. Key Concepts
3.1.1. Operations and Operation Graphs
I/O tensors connect the operations implicitly, for example, an operation A may produce a tensor X, which is then consumed by operation B, implying that operation B depends on operation A.
3.1.2. Engines and Engine Configurations
An engine has knobs for configuring properties of the engine, like tile size (refer to cudnnBackendKnobType_t).
3.1.3. Heuristics
- Intended to be fast and be able to handle most operation graph patterns. It returns a list of engine configs ranked by the expected performance.
- Intended to be more generally accurate than mode A, but with the tradeoff of higher CPU latency to return the list of engine configs. The underlying implementation may fall back to the mode A heuristic in cases where we know mode A can do better.
- Intended to be fast and provide functional fallbacks without expectation of optimal performance.
The recommended workflow is to query either mode A or B and check for support. The first engine config with support is expected to have the best performance.
You can “auto-tune”, that is, iterate over the list and time for each engine config and choose the best one for a particular problem on a particular device. The cuDNN frontend API provides a convenient function, cudnnFindPlan(), which does this.
If all the engine configs are not supported, then use the mode fallback to find the functional fallbacks.
Expert users may also want to filter engine configs based on properties of the engine, such as numerical notes, behavior notes, or adjustable knobs. Numerical notes inform the user about the numerical properties of the engine such as whether it does datatype down conversion at the input or during output reduction. The behavior notes can signal something about the underlying implementation like whether or not it uses runtime compilation. The adjustable knobs allow fine grained control of the engine’s behavior and performance.
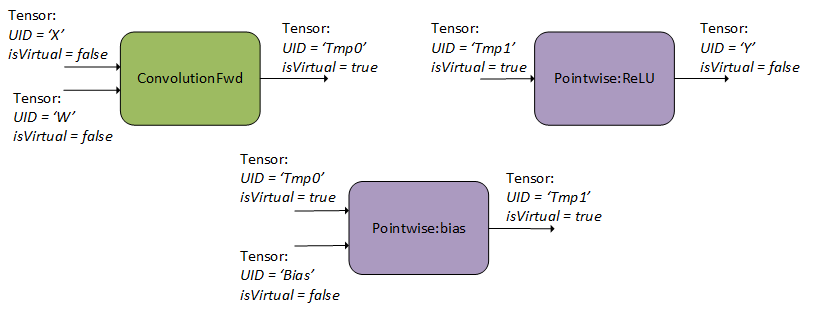
3.2. Graph API Example with Operation Fusion
3.2.1. Creating Operation and Tensor Descriptors to Specify the Graph Dataflow
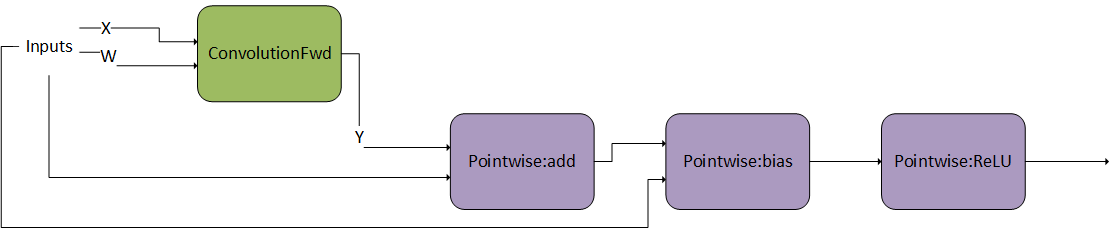
As can be seen in Figure 6, the user specified one forward convolution operation (using CUDNN_BACKEND_OPERATION_CONVOLUTION_FORWARD_DESCRIPTOR), a pointwise operation for the bias addition (using CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR with mode CUDNN_POINTWISE_ADD), and a pointwise operation for the ReLU activation (using CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR with mode CUDNN_POINTWISE_RELU_FWD). Refer to the NVIDIA cuDNN Backend API for more details on setting the attributes of these descriptors. For an example of how a forward convolution can be set up, refer to the Setting Up An Operation Graph For A Grouped Convolution use case in the cuDNN backend API.
- Note that graphs with more than one operation node do not support in-place operations (that is, where any of the input UIDs matches any of the output UIDs). Such in-place operations are considered cyclic in later graph analysis and deemed unsupported. In-place operations are supported for single-node graphs.
- Also note that the operation descriptors can be created and passed into cuDNN in any order, as the tensor UIDs are enough to determine the dependencies in the graph.
3.2.2. Finalizing The Operation Graph
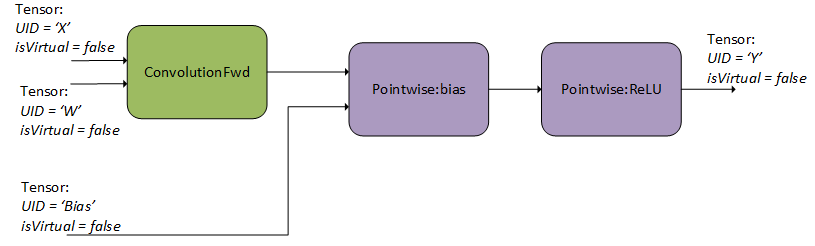
3.2.3. Configuring An Engine That Can Execute The Operation Graph
3.2.4. Executing The Engine
3.3. Supported Graph Patterns
Since these engines have some overlap in the patterns they support, a given pattern may result in zero, one, or more engines.
3.3.1. Pre-compiled Single Operation Engines
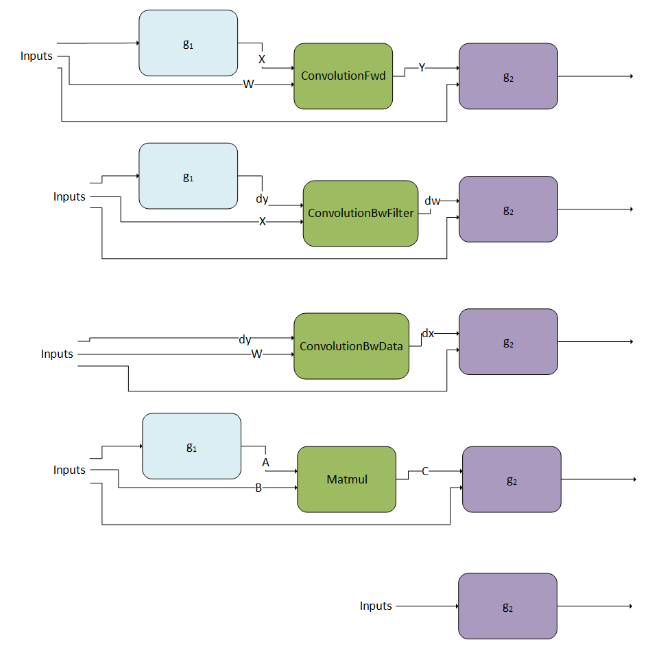
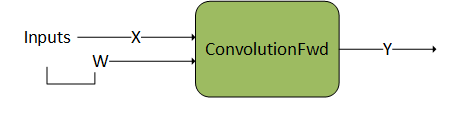
3.3.1.1. ConvolutionFwd
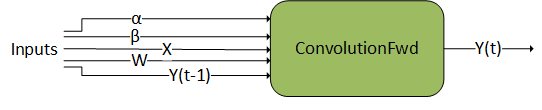
3.3.1.2. ConvolutionBwFilter

3.3.1.3. ConvolutionBwData
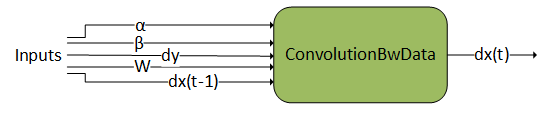
3.3.1.4. NormalizationForward
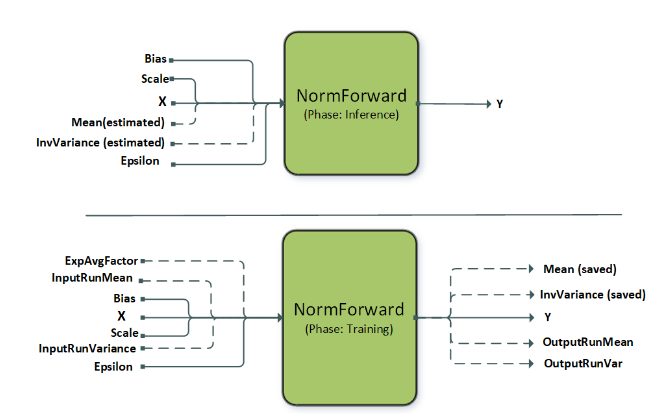
This operation supports different normalization modes which are set by the attribute CUDNN_ATTR_OPERATION_NORM_FWD_MODE. The dashed lines indicate optional inputs, which are typically used in the batch norm mode of this operation. Currently, the precompiled engines support instance and layer norm while batch norm is supported using a specialized runtime compiled engine (refer to BnAddRelu).
| Node and Other Attributes | Instance Normalization Forward | Layer Normalization Forward |
|---|---|---|
| name | instance | layer |
| operation | normFwd | normFwd |
| X | [N, C, (D), H, W], input, I/O type | [N, C, (D), H, W], input, I/O type |
| Mean | [N,C,(1),1,1], output, compute type, only applicable to fmodeCUDNN_NORM_FWD_TRAINING | [N,1,(1),1,1], output, compute type, only applicable to fmodeCUDNN_NORM_FWD_TRAINING |
| InvVariance | [N,C,(1),1,1], output, compute type, only applicable to fmodeCUDNN_NORM_FWD_TRAINING | [N,1,(1),1,1], output, compute type, only applicable to fmodeCUDNN_NORM_FWD_TRAINING |
| Scale | [1,C,(1),1,1], input, compute type | [1,C,(D),H,W], input, compute type |
| Bias | [1,C,(1),1,1], input, compute type | [1,C,(D),H,W], input, compute type |
| Y | [N, C, (D), H, W], output, I/O type | [N, C, (D), H, W], output, I/O type |
| epsilonDesc | [1,1,1,1], input, constant | [1,1,1,1], input, constant |
| mode | CUDNN_INSTANCE_NORM | CUDNN_LAYER_NORM |
| Supported fmode | CUDNN_NORM_FWD_TRAINING, CUDNN_NORM_FWD_INFERENCE | CUDNN_NORM_FWD_TRAINING, CUDNN_NORM_FWD_INFERENCE |
| Supported layout | NC(D)HW, N(D)HWC | NC(D)HW, N(D)HWC |
| Supported I/O types | FP16, FP32 | FP16, FP32 |
| Supported compute type | FP32 | FP32 |
| Alignment requirements for I/O type | 8 bytes aligned | 16 bytes aligned |
3.3.1.5. NormalizationBackward
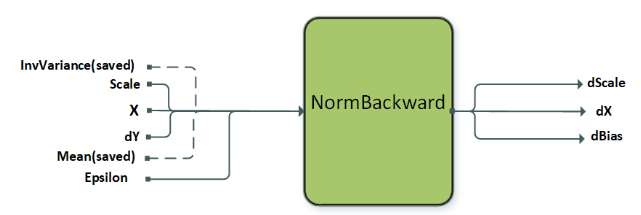
| Node and Other Attributes | Instance Normalization Backward | Layer Normalization Backward |
|---|---|---|
| name | instance | layer |
| operation | normBwd | normBwd |
| X | [N, C, (D), H, W], input, I/O type | [N, C, (D), H, W], input, I/O type |
| Mean | [N,C,(1),1,1], input, compute type | [N,1,(1),1,1], input, compute type |
| InvVariance | [N,C,(1),1,1], input, compute type | [N,1,(1),1,1], input, compute type |
| Scale | [1,C,(1),1,1], input, compute type | [1,C,(D),H,W], input, compute type |
| DY | [N, C, (D), H, W], input, I/O type | [N, C, (D), H, W], input, I/O type |
| DX | [N, C, (D), H, W], output, I/O type | [N, C, (D), H, W], output, I/O type |
| Dscale | [1,C,(1),1,1], output, compute type | [1,C,(D),H,W], output, compute type |
| Dbias | [1,C,(1),1,1], output, compute type | [1,C,(D),H,W], output, compute type |
| mode | CUDNN_INSTANCE_NORM | CUDNN_LAYER_NORM |
| Supported layout | NC(D)HW, N(D)HWC | NC(D)HW, N(D)HWC |
| Supported I/O types | FP16, FP32 | FP16, FP32 |
| Supported compute type | FP32 | FP32 |
| Alignment requirements for I/O type | 8 bytes aligned | 16 bytes aligned |
3.3.2. Generic Runtime Fusion Engines
- CUDNN_BACKEND_OPERATION_CONCAT_DESCRIPTOR
- CUDNN_BACKEND_OPERATION_SIGNAL_DESCRIPTOR
- CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR
- CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR
- CUDNN_BACKEND_OPERATION_RESAMPLE_FWD_DESCRIPTOR
- CUDNN_BACKEND_OPERATION_RESAMPLE_BWD_DESCRIPTOR
- CUDNN_BACKEND_OPERATION_GEN_STATS_DESCRIPTOR
- CUDNN_BACKEND_OPERATION_REDUCTION_DESCRIPTOR
- CUDNN_BACKEND_OPERATION_SIGNAL_DESCRIPTOR
3.3.2.1. Limitations
Limitations per Generic Pattern
Tensor Layout Requirements
Lastly, there are some layout requirements to the I/O tensors involved in fusion graphs. For more information, refer to the Tensor Descriptor and Data Layout Formats sections. The following table describes the requirements per fusion pattern:
3.3.2.2. Examples of Supported Patterns
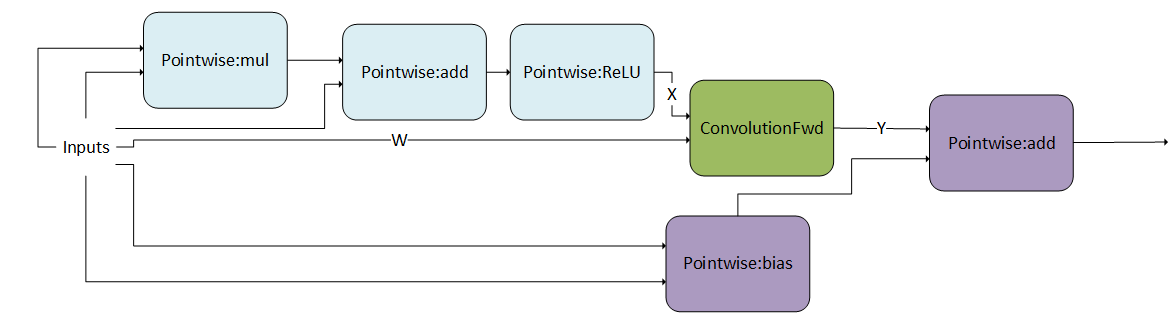
For illustration purposes, we abbreviated the operations used. For a full mapping to the actual backend descriptors, refer to the Mapping with Backend Descriptors.


3.3.2.2.5. Convolution Producer Node in Middle of DAG
3.3.2.3. Operation specific Constraints for the Runtime Fusion Engines
Note that these constraints are in addition to (1) any constraints mentioned in the NVIDIA cuDNN Backend API, and (2) limitations in relation to other operations in the directed acyclic graph (DAG), as mentioned in the Limitations section.
3.3.2.3.1. Convolutions
- ConvolutionFwd
- This operation represents forward convolution, that is, computing the response tensor of image tensor convoluted with filter tensor. For complete details on the interface, as well as general constraints, refer to the CUDNN_BACKEND_OPERATION_CONVOLUTION_FORWARD_DESCRIPTOR section.
- ConvolutionBwFilter
- This operation represents convolution backward filters, that is, computing filter gradients from a response and an image tensor. For complete details on the interface, as well as general constraints, refer to the CUDNN_BACKEND_OPERATION_CONVOLUTION_BACKWARD_FILTER_DESCRIPTOR section.
- ConvolutionBwData
- This operation represents convolution backward data, that is, computing input data gradients from a response and a filter tensor. For complete details on the interface, as well as general constraints, refer to the CUDNN_BACKEND_OPERATION_CONVOLUTION_BACKWARD_DATA_DESCRIPTOR section.
| Input Tensor Attribute Name | Output Tensor Attribute Name | |
|---|---|---|
| ConvolutionFwd |
CUDNN_ATTR_OPERATION_CONVOLUTION_FORWARD_X CUDNN_ATTR_OPERATION_CONVOLUTION_FORWARD_W |
CUDNN_ATTR_OPERATION_CONVOLUTION_FORWARD_Y |
| ConvolutionBwFilter |
CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_DATA_DX CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_DATA_DY |
CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_DATA_W |
| ConvolutionBwData |
CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_FILTER_DW CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_FILTER_DY |
CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_FILTER_X |
| Tensor Data Type | Number of input and output channels for NVIDIA Hopper Architecture | Number of input and output channels for NVIDIA Ampere and Ada Lovelace | Number of input and output channels for NVIDIA Volta/Turing Architecture |
|---|---|---|---|
| INT8 | Multiple of 4 | Multiple of 4 | Multiple of 16 |
| FP8 | Multiple of 16 | N/A | N/A |
| FP16/BF16 | Multiple of 2 | Multiple of 2 | Multiple of 8 |
| FP32(TF32) | Any value | Any value | Multiple of 4 |
The FP8 data type since Hopper architecture has two variants: CUDNN_DATA_FP8_E4M3 and CUDNN_DATA_FP8_E5M2 as I/O data types. Using them as inputs to the operation will result in FP8 Tensor Cores being used. The precision of the accumulation inside the FP8 Tensor Cores is controlled by the compute type, which may have one of two possible values: CUDNN_DATA_FLOAT and CUDNN_DATA_FAST_FLOAT_FOR_FP8.
CUDNN_DATA_FAST_FLOAT_FOR_FP8 is faster and sufficiently accurate for inference or the forward pass of training. However, for FP8 training backward pass computations (that is, computing weight and activation gradients), we recommend choosing the more accurate CUDNN_DATA_FLOAT compute type to preserve a higher level of accuracy which may be necessary for some models.
3.3.2.3.2. MatMul
The following two tables list the constraints for MatMul operations, in addition to any general constraints as listed in the NVIDIA cuDNN Backend API, and any constraints listed in the Limitations section, in relation to other operations. Note that these additional constraints only apply when MatMul is used in the runtime fusion engines. Besides the layouts of operand A, B, and C, there must be row major, column major, and row major, respectively, for the INT8 tensor data type.
| Tensor Data Type | Number of input and output channels for NVIDIA Hopper architecture | Innermost dimension for NVIDIA Ampere architecture and NVIDIA Ada Lovelace | Innermost dimension for NVIDIA Volta and NVIDIA Turing architecture |
|---|---|---|---|
| INT8 | Multiple of 4 | Multiple of 4 | Multiple of 16 |
| FP8 | Multiple of 16 | N/A | N/A |
| FP16/BF16 | Multiple of 2 | Multiple of 2 | Multiple of 8 |
| FP32(TF32) | Any value | Any value | Multiple of 4 |
3.3.2.3.3. Pointwise
The following table lists the constraints for pointwise operations, in addition to the general constraints listed above, and any constraints listed in the Limitations section, in relation to other operations. Note that these additional constraints only apply when these operations are used in the runtime fusion engines.
3.3.2.3.4. GenStats
The following table lists the constraints for GenStats operations, in addition to the general constraints listed above, and any constraints listed in the Limitations section, in relation to other operations. Note that these additional constraints only apply when GenStats operations are used in the runtime fusion engines.
3.3.2.3.5. Reduction
The following two tables are constraints for Reduction forward operations, in addition to the general constraints listed above, and any constraints listed in the Limitations section, in relation to other operations. Note that these additional constraints only apply when Reduction operations are used in the runtime fusion engines.
| Attribute | Requirement |
|---|---|
| Tensor data type for CUDNN_ATTR_OPERATION_REDUCTION_YDESC | CUDNN_DATA_FLOAT |
| CUDNN_ATTR_REDUCTION_COMP_TYPE | CUDNN_DATA_FLOAT |
| Tensor layout for CUDNN_ATTR_OPERATION_REDUCTION_XDESC and CUDNN_ATTR_OPERATION_REDUCTION_YDESC | NHWC/NDHWC/BMN fully packed |
| CUDNN_ATTR_REDUCTION_OPERATOR | CUDNN_REDUCE_TENSOR_ADD, CUDNN_REDUCE_TENSOR_MIN, and CUDNN_REDUCE_TENSOR_MAX |
| Reduction Operation | Reduction Pattern | |
|---|---|---|
| Input | Output | |
| Standalone reduction operation | [N, C, H, W] | [N, 1, H, W] |
| [1, C, 1, 1] | ||
| [1, 1, 1, 1] | ||
| Reduction fused after convolution fprop | [N, K, P, Q] | [N, 1, P, Q] |
| [1, K, 1, 1] | ||
| [1, 1, 1, 1] | ||
| Reduction fused after convolution backward data gradient | [N, C, H, W] | [N, 1, H, W] |
| [1, C, 1, 1] | ||
| [1, 1, 1, 1] | ||
| Reduction fused after convolution backward filter gradient | [K, C, R, S] | [K, 1, 1, 1] |
| [1, C, R, S] | ||
| [1, 1, 1, 1] | ||
| Reduction fused after matrix multiplication operation | [B, M, N] | [B, M, 1] |
| [B, 1, N] | ||
3.3.2.3.6. ResampleFwd
The following are constraints for Resample operations, in addition to the general constraints listed above, and any constraints listed in the Limitations section, in relation to other operations. Note that these additional constraints only apply when Resample forward operations are used in the runtime fusion engines.
- Supported layout: NHWC or NDHWC, NCHW or NCDHW
- Spatial dimensions supported: 2 or 3
- Input dimensions supported: 4 or 5
- Packed boolean data type is not supported.
- If specified, the index tensor dimension should be equal to the response tensor dimension.
- Upsampling is not supported.
- Int64_t indices are not supported.
- Only supports symmetric padding using the prepadding backend API.
There are some mode specific restrictions also. The following tables list the values that are allowed for particular parameters. For the parameters not listed, we allow any value which is mathematically correct.
- CUDNN_RESAMPLE_AVGPOOL_INCLUDE_PADDING
- CUDNN_RESAMPLE_AVGPOOL_EXCLUDE_PADDING
- CUDNN_RESAMPLE_MAXPOOL
| Attribute | Average Pooling | Max Pooling |
|---|---|---|
| CUDNN_ATTR_RESAMPLE_PADDING_MODE | CUDNN_ZERO_PAD | CUDNN_NEG_INF_PAD |
| CUDNN_ATTR_OPERATION_RESAMPLE_FWD_ALPHA | 1.0 | 1.0 |
| CUDNN_ATTR_OPERATION_RESAMPLE_FWD_BETA | 0.0 | 0.0 |
| CUDNN_ATTR_RESAMPLE_COMP_TYPE | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT |
For the upsampling modes, CUDNN_RESAMPLE_NEAREST is not supported for any combination of parameters. CUDNN_RESAMPLE_BILINEAR has the following support specifications.
| Attribute | Bilinear |
|---|---|
| Input dimensions | Equal to 0.5 x output dimensions |
| CUDNN_ATTR_RESAMPLE_PRE_PADDINGS | 0.5 |
| CUDNN_ATTR_RESAMPLE_POST_PADDINGS | 1 |
| CUDNN_ATTR_RESAMPLE_STRIDES | 0.5 |
| CUDNN_ATTR_RESAMPLE_WINDOW_DIMS | 2 |
| Data type for CUDNN_ATTR_OPERATION_RESAMPLE_FWD_XDESC and CUDNN_ATTR_OPERATION_RESAMPLE_FWD_YDESC | CUDNN_DATA_FLOAT |
| CUDNN_ATTR_RESAMPLE_COMP_TYPE | CUDNN_DATA_FLOAT |
| CUDNN_ATTR_OPERATION_RESAMPLE_FWD_ALPHA | 1.0 |
| CUDNN_ATTR_OPERATION_RESAMPLE_FWD_BETA | 0.0 |
| CUDNN_ATTR_RESAMPLE_PADDING_MODE | CUDNN_EDGE_VAL_PAD |
3.3.2.3.6.1. Resampling Index Tensor Dump for Training
- Zero-indexed row-major position of maximum value of input tensor in the resampling window.
- In case of multiple input pixels with maximum value, the first index in a left-to-right top-to-bottom scan is selected.
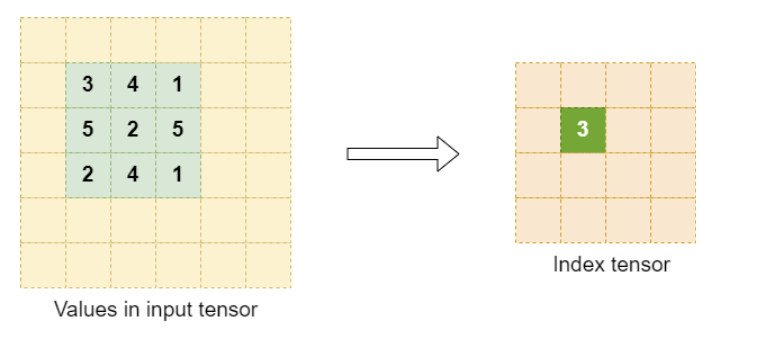
Select an appropriate element size for the index tensor. As a reference, any element size such that the maximum zero-indexed window position fits should be sufficient.
3.3.2.3.7. ResampleBwd
The following are constraints for Resample backward operations, in addition to the general constraints listed above, and any constraints listed in the Limitations section, in relation to other operations. Note that these additional constraints only apply when Resample backward operations are used in the runtime fusion engines.
- Supported layout: NHWC or NDHWC, NCHW or NCDHW
- Spatial dimensions supported: 2 or 3
- Input dimensions supported: 4 or 5
- The index tensor should be provided for only max pooling mode, and should adhere to the format described in the resampling forward index dump section.
- The index tensor dimensions should be equal to the input gradient tensor dimensions.
- X, Y, and DY are required when max pooling mode is used.
- Int64_t indices are not supported.
There are some mode specific restrictions also. The following tables list the values that are allowed for particular parameters. For the parameters not listed, we allow any value which is mathematically correct.
- CUDNN_RESAMPLE_AVGPOOL_INCLUDE_PADDING
- CUDNN_RESAMPLE_AVGPOOL_EXCLUDE_PADDING
- CUDNN_RESAMPLE_MAXPOOL
| Attribute | Average Pooling | Max Pooling |
|---|---|---|
| CUDNN_ATTR_RESAMPLE_PADDING_MODE | CUDNN_ZERO_PAD | CUDNN_NEG_INF_PAD |
| CUDNN_ATTR_OPERATION_RESAMPLE_BWD_ALPHA | 1.0 | 1.0 |
| CUDNN_ATTR_OPERATION_RESAMPLE_BWD_BETA | 0.0 | 0.0 |
| CUDNN_ATTR_RESAMPLE_COMP_TYPE | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT |
Backward upsampling modes are currently not supported.
3.3.3. Specialized Runtime Fusion Engines
The following sections highlight the supported patterns.
3.3.3.1. BnAddRelu
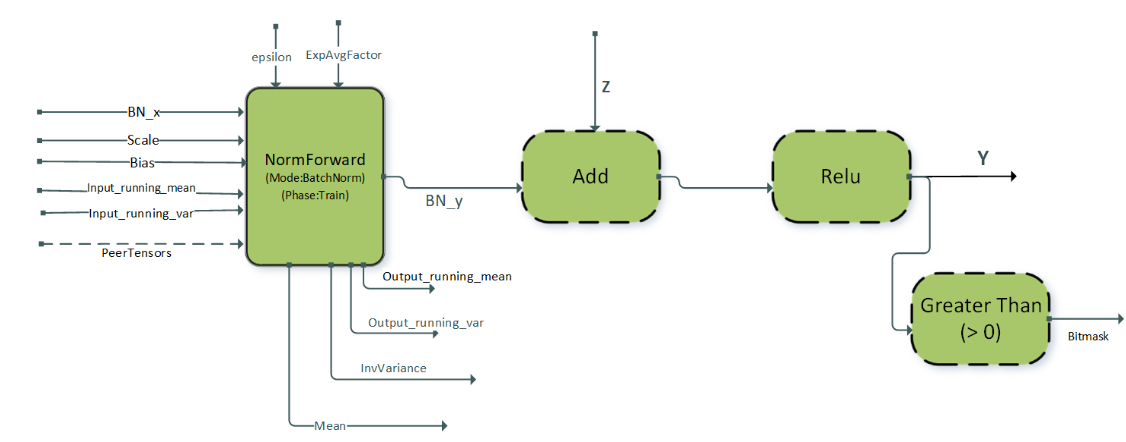
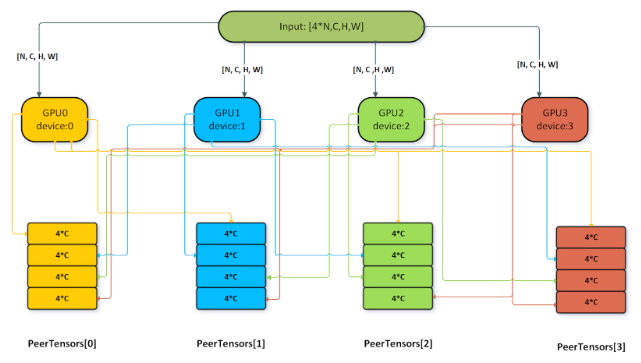
3.3.3.2. DReluForkDBn
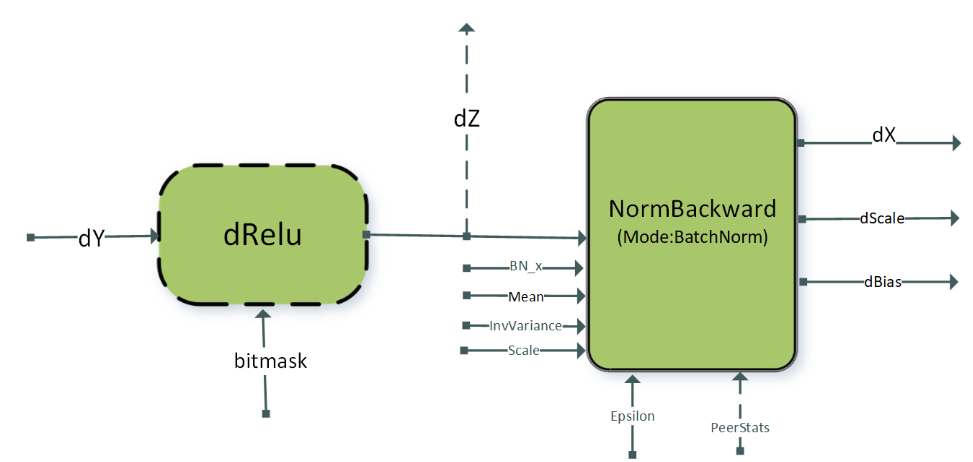
The single node multi-GPU version of this pattern is typically used for dScale and dBias gradient aggregation across GPUs. For using the multi-GPU version, the attribute CUDNN_ATTR_OPERATION_NORM_BWD_PEER_STAT_DESCS of the NormBackward operation must be set. Other restrictions for the peerTensors vector listed in the previous section apply for this pattern as well.
3.3.3.3. Fused Attention fprop
- Input sizes supported contain small sequence lengths (<= 512).
- The operation graph is flexible to switch between different types of masks, different operations between the two matrix multiplications, and so on.

g3 can be an empty graph or a single scale operation with the scale being a scalar value (CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR with mode CUDNN_POINTWISE_MUL).
g4 can be empty or the combination of the following DAGs of cuDNN operations. Each of these DAGs is optional, as shown by the dotted line.

The combination has to obey the order in which we present them. For example, if you want to use the padding mask and softmax, the padding mask has to appear before softmax.
These operations are commonly used in attention. In the following diagram, we depict how to create a DAG for each of the operations. In later versions, we will be expanding the possible DAGs for g3 and g4.
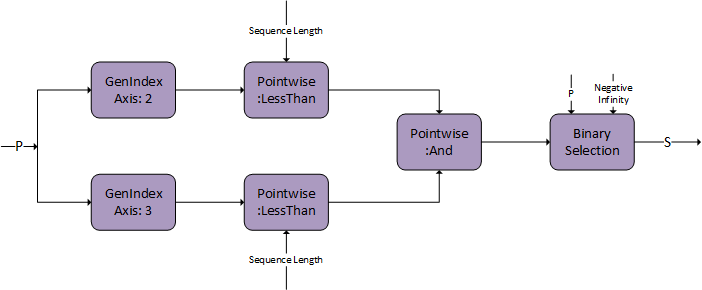
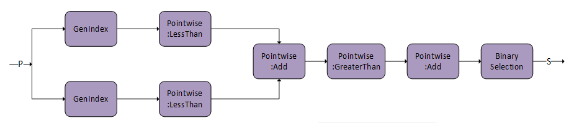

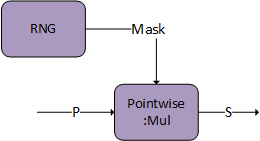
Dropout
g4 is capable of storing an intermediate tensor to global memory marked as S, which can be used for fused multi-head attention bprop. Both DAG:Softmax and DAG:Dropout have this capability. Set S as the output from the last DAG in the graph.
The tensor descriptor marked as S must have the CUDNN_ATTR_TENSOR_REORDERING_MODE set to CUDNN_TENSOR_REORDERING_F16x16. This is because the tensor is stored in a special format and can only be consumed by fused attention bprop.
There is an additional option of generating the mask on the user end and passing it directly to the pointwise multiply. The mask needs to be of I/O data type FP16/BF16 and S will store the mask in the sign bit to communicate to bprop.
3.3.3.4. Fused Attention bprop
cuDNN supports the corresponding backpropagation graph for fused attention. This can be used together with the fused attention fprop graph to perform training on models that have similar architectures to BERT and T5. This is not compatible with the flash fused attention bprop operation graph.
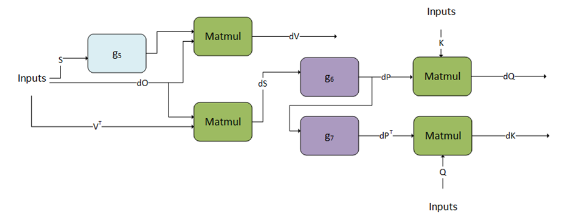
g5, g6, and g7 can only support a fixed DAG. We are working towards generalizing these graphs.

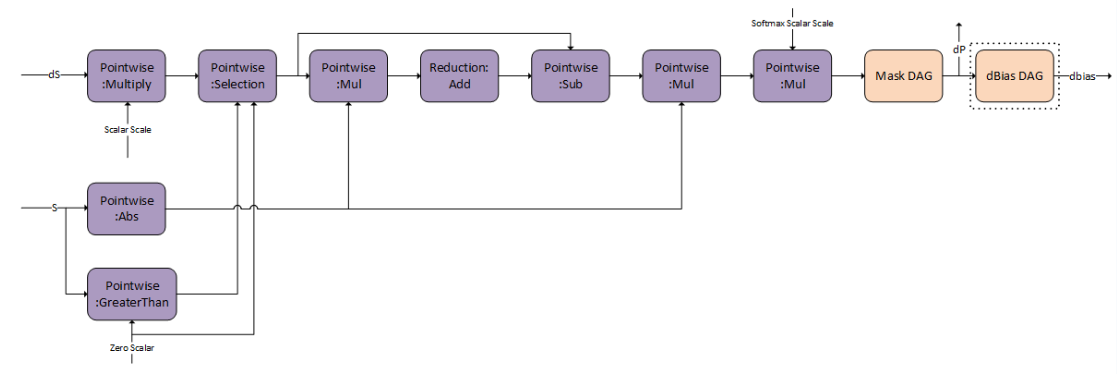
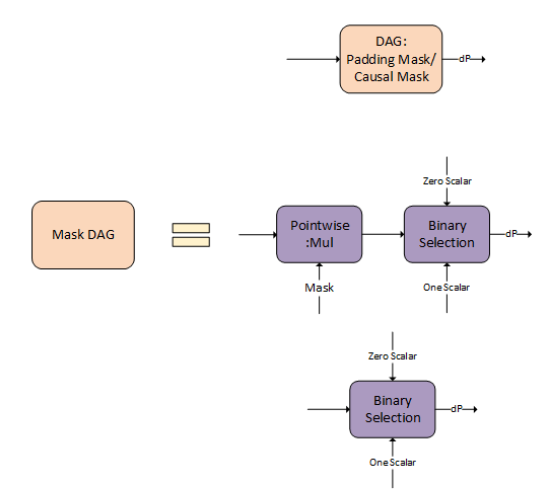


3.3.3.5. Fused Flash Attention fprop

The compound operations for example: Causal Mask, Softmax, and so on, can be represented using the following operation graphs in cuDNN.
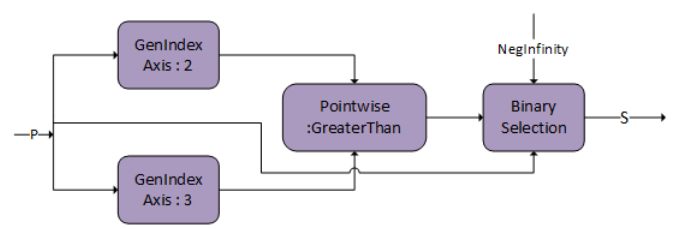
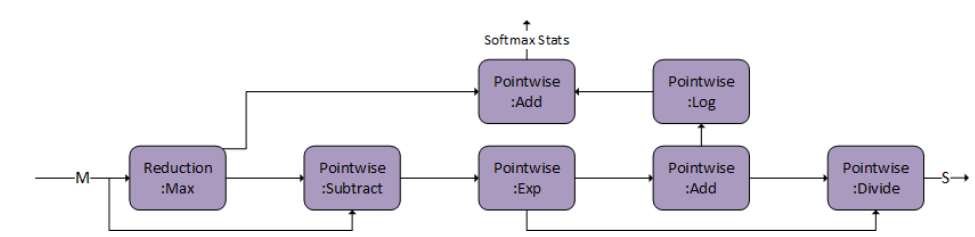
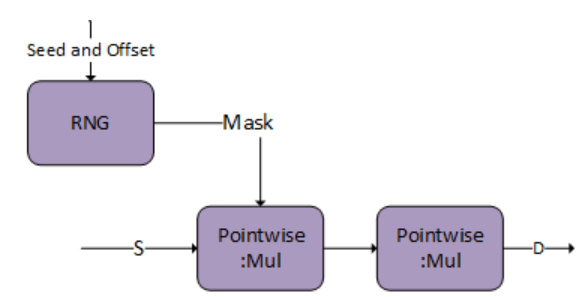
Inference mode can be turned on by passing the Softmax stats as a virtual tensor and setting the RNG node probability to 0.0f. Currently, the pattern is only supported on A100 and H100 GPUs.
3.3.3.6. Fused Flash Attention bprop
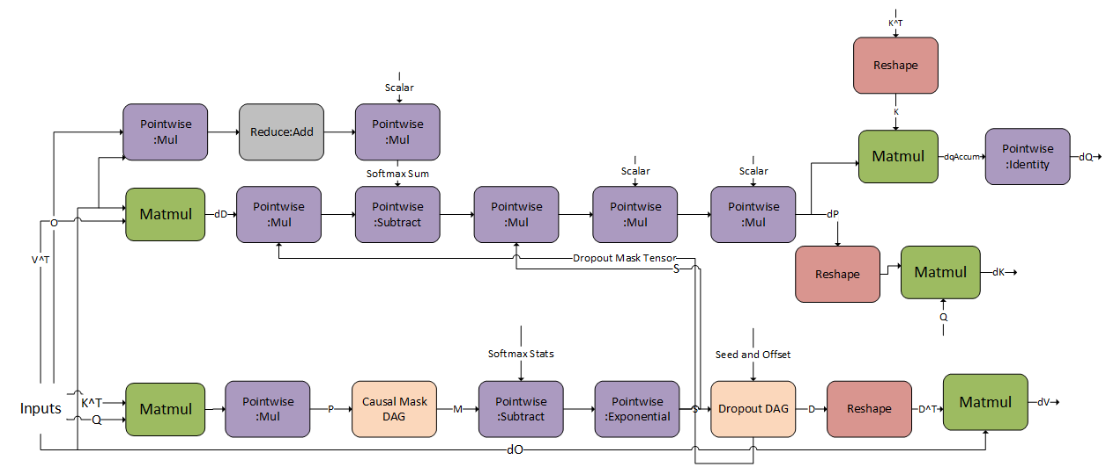
Currently, the pattern is only supported on A100 and H100 GPUs.
3.3.4. Specialized Pre-Compiled Engines
In most cases, the specialized patterns are just special cases of the generic patterns used in the runtime fusion engines, but there are some cases where the specialized pattern does not fit any of the generic patterns. If your graph pattern matches a specialized pattern, you will get at least a pattern matching engine, and you might also get runtime fusion engines as another option.
Currently, the following patterns are supported by the pattern matching engines. Some nodes are optional. Optional nodes are indicated by dashed outlines.
3.3.4.1. ConvBNfprop

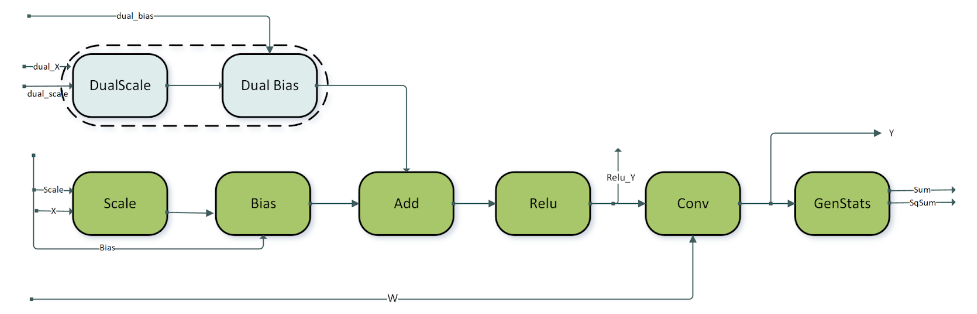
3.3.4.2. ConvBNwgrad

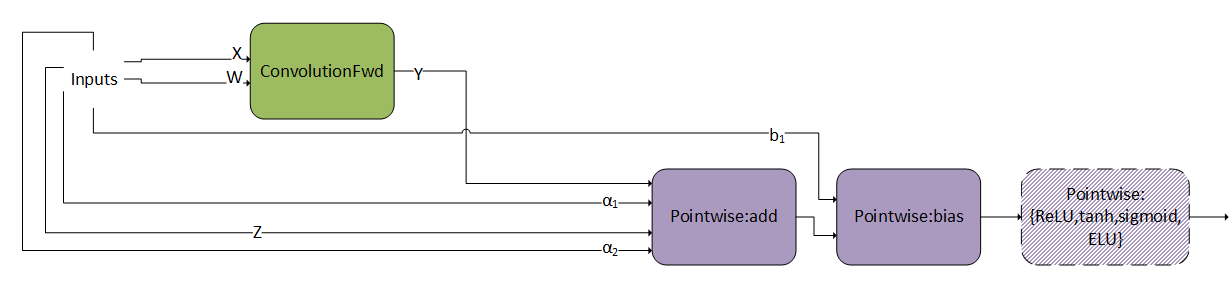
3.3.4.4. ConvScaleBiasAct
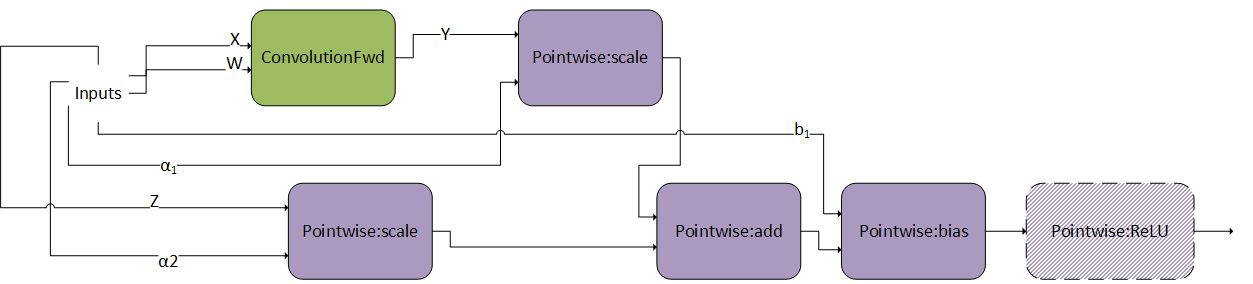
This pattern is very similar as ConvBiasAct. The difference is that here, the scales and are tensors, not scalars. If they are scalars, this pattern becomes a normal ConvBiasAct.
3.3.4.5. DgradDreluBNBwdWeight
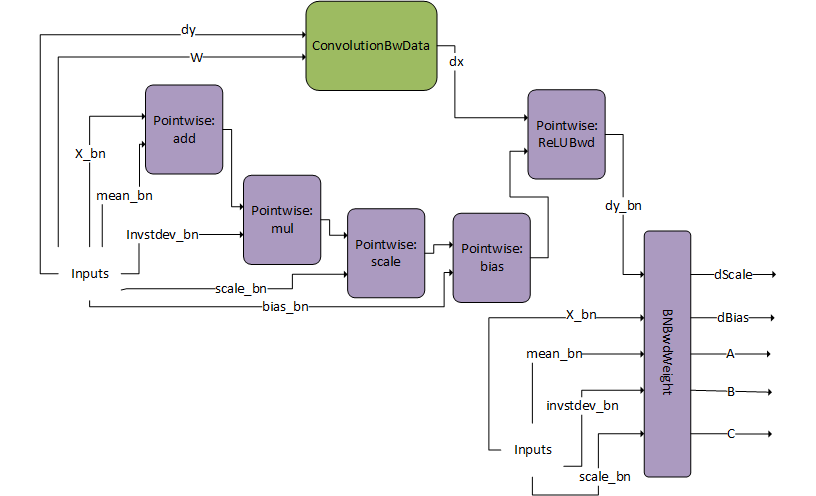
The BNBwdWeight operation takes in five inputs: X_bn, mean_bn, invstddev_bn, scale_bn, and dy_bn (that is, the output from the ReLUBwd node).
It produces five outputs: gradients of the batch norm scale and bias params, dScale, dBias, and coefficients A,B,C. Note that for illustration purposes, the inputs are duplicated. The inputs on the left and right are however exactly the same.
This pattern is typically used in the computation of the Batch Norm Backward Pass.
When computing the backward pass of batch norm, dScale, dBias, and dX_bn are needed. The DgradDreluBnBwdWeight pattern computes the former two. Using the generated A, B, and C we can use the following dBNApply pattern to compute dX, the input gradient, as follows dx_bn = A*dy_bn + B*X_bn +C.
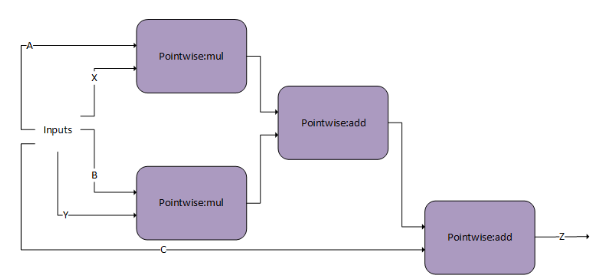
The dBNApply pattern was initially supported by a pre-compiled static engine but is now supported by the generic runtime fusion engine.
Note that the DgradDreluBNBwdWeight pattern is used in combination with the forward pass pattern ConvBNfprop. Because of performance reasons, the output of batch norm Y_bn, which was calculated in ConvBNfprop (output of scale-bias), needs to be recalculated by DgradDreluBnBwdWeight. The pointwise add node subtracts mean_bn from X_bn, hence the alpha2 parameter for that node should be set to -1.
3.3.4.6. FP8 Fused Flash Attention
Support exists for both training (forward and backward pass) and inference in FP8 format. The training forward pass is slightly different from the inference forward pass regarding whether some intermediate tensors are output or not.
Within the NVIDIA Hopper architecture, there are two new FP8 formats: E4M3 and E5M2. Currently, for forward pass, only when all the inputs and outputs are in E4M3 format is supported. For the backward pass, the support is only when some of the inputs and outputs are in E4M3 and some in E5M2. More general support for the FP8 formats will be added in future releases.
Due to the limited numerical precision of FP8 data type, for practical use cases, you must scale values computed in FP32 format before storing them in FP8 format, and descale the values stored in FP8 format before performing computations on them. For more information, refer to the Transformer Engine FP8 Primer.
- b - number of batches
- h - number of heads
- d - maximum length of sequences in a batch
- d - embedding dimension size of a word in a sequence
Scaling and Descaling
In the context of FP8, scaling refers to multiplying each element of a FP32 tensor by a quantization factor.
The quantization factor is computed as: (Max representable value in the fp8 format) / (Max absolute value seen in the tensor).
For the E4M3 format, the quantization factor is 448.f/ tensor_amax (rounded to the nearest lower power of two).
For the E5M2 format, the quantization factor is 57344.f / tensor_amax (rounded to the nearest lower power of two).
The meaning behind scaling is to spawn the full range of the FP8 format when computing on FP8 values and storing FP8 values, thereby, minimizing the precision loss. True values in FP32 format are multiplied by the quantization factor before storing them as scaled values in FP8 format. Computations on scaled values in FP8 format are descaled by multiplying with the dequantization factor to convert them back to their true values in FP32 format.
Scaling and descaling are critical for convergence with the FP8 data type, hence cuDNN only supports graph patterns for FP8 fused attention with the scaling and descaling nodes present.
Unpadded Tensors
In fused flash attention, the length of different sequences in a batch can be different. The cuDNN operation graph supports an unpadded layout where all the sequences of different lengths in a batch are tightly packed. All the word embeddings after the useful length of the sequence are pushed towards the end of all sequences in the layout.
Forward Pass
The following figure shows the cuDNN operation graph for the fused attention forward pass. The same graph supports forward pass for both training and inference. The operation graph pattern is identified as training when M and Zinv tensors are non-virtual. When M and Zinv tensors are virtual, the operation graph pattern is identified as inference.
The FP8 tensors are expected to be scaled and the matrix multiplication computation is performed on the FP8 tensors in the scaled format. All non matrix multiplication computations are performed in FP32 precision. The output of the FP8 matrix multiplication is converted to real values in FP32 by format multiplying with the descale values.
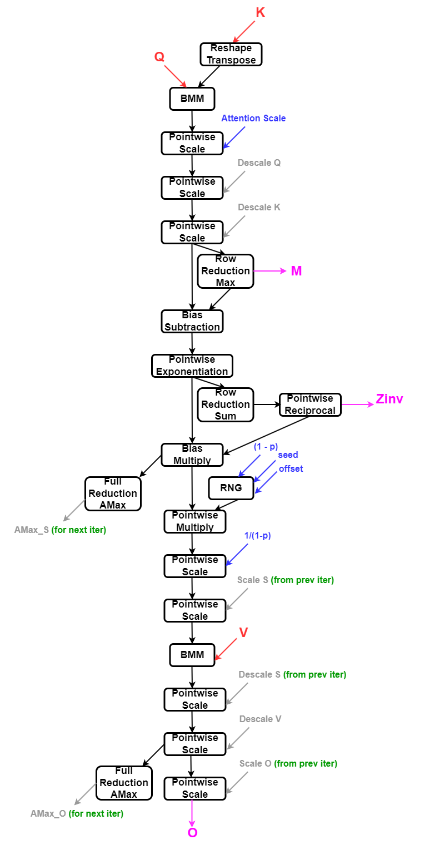
| Tensor Name | Data Type | Dimensions |
|---|---|---|
| Q | E4M3 | [b, h, s, d] |
| K | E4M3 | [b, h, s, d] |
| V | E4M3 | [b, h, s, d] |
| Attention Scale | FP32 (by value) | [1, 1, 1, 1] |
| Descale Q | FP32 | [1, 1, 1, 1] |
| Descale K | FP32 | [1, 1, 1, 1] |
| Descale V | FP32 | [1, 1, 1, 1] |
| Scale S | FP32 | [1, 1, 1, 1] |
| Descale S | FP32 | [1, 1, 1, 1] |
| Scale O | FP32 | [1, 1, 1, 1] |
| RNG Seed | INT64 | [1, 1, 1, 1] |
| RNG Offset | INT64 | [1, 1, 1, 1] |
| Dropout Probability (p) or Keep Probability (1 - p) | FP32 | [1, 1, 1, 1] |
Backward Pass
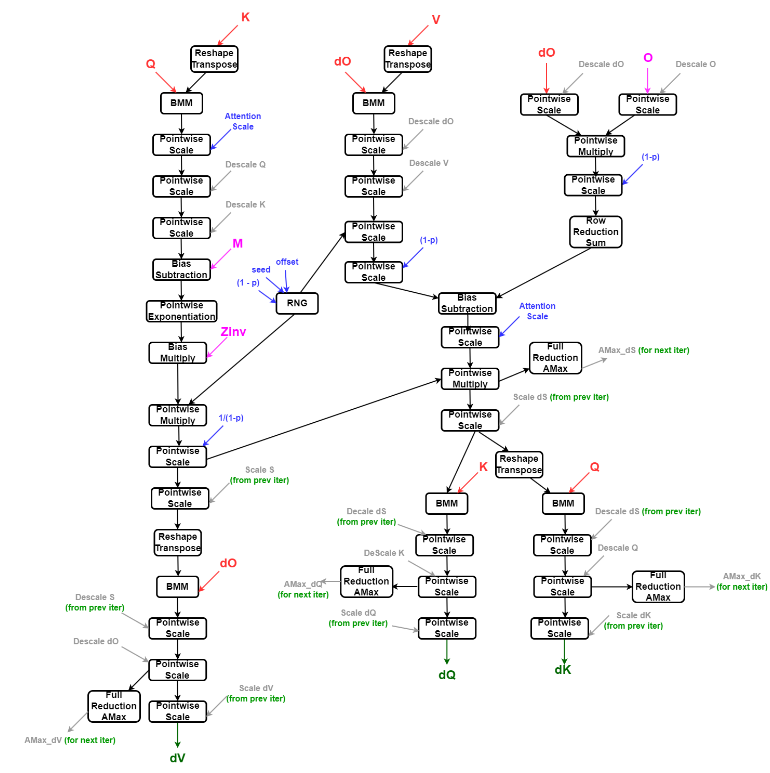
| Tensor Name | Data Type | Dimensions |
|---|---|---|
| Q | E4M3 | [b, h, s, d] |
| K | E4M3 | [b, h, s, d] |
| V | E4M3 | [b, h, s, d] |
| O | E4M3 | [b, h, s, d] |
| dO | E5M2 | [b, h, s, d] |
| M | FP32 | [b, h, s, 1] |
| Zinv | FP32 | [b, h, s, 1] |
| Attention Scale | FP32 (by value) | [1, 1, 1, 1] |
| Descale Q | FP32 | [1, 1, 1, 1] |
| Descale K | FP32 | [1, 1, 1, 1] |
| Descale V | FP32 | [1, 1, 1, 1] |
| Scale S | FP32 | [1, 1, 1, 1] |
| Descale S | FP32 | [1, 1, 1, 1] |
| Descale O | FP32 | [1, 1, 1, 1] |
| Descale dO | FP32 | [1, 1, 1, 1] |
| Scale dS | FP32 | [1, 1, 1, 1] |
| Descale dS | FP32 | [1, 1, 1, 1] |
| Scale dQ | FP32 | [1, 1, 1, 1] |
| Scale dK | FP32 | [1, 1, 1, 1] |
| Scale dV | FP32 | [1, 1, 1, 1] |
| RNG Seed | INT64 | [1, 1, 1, 1] |
| RNG Offset | INT64 | [1, 1, 1, 1] |
| Dropout Probability (p) or Keep Probability (1 - p) | FP32 | [1, 1, 1, 1] |
3.3.5. Mapping with Backend Descriptors
| Notation used in this section | Backend descriptor |
|---|---|
| Pointwise:scale | CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR with mode CUDNN_POINTWISE_MUL and with operand B broadcasting into operand X |
| Pointwise:bias | CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR with mode CUDNN_POINTWISE_ADD and with operand B broadcasting into operand X |
| Pointwise:add | CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR with mode CUDNN_POINTWISE_ADD and with operand B with same dimensions as X |
| Pointwise:mul | CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR with mode CUDNN_POINTWISE_MUL and with operand B with same dimensions as X |
| Pointwise:ReLU | CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR with mode CUDNN_POINTWISE_RELU_FWD |
| Pointwise:ReLUBwd | CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR with mode CUDNN_POINTWISE_RELU_BWD |
| Pointwise:tanh | CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR with mode CUDNN_POINTWISE_TANH_FWD |
| Pointwise:sigmoid | CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR with mode CUDNN_POINTWISE_SIGMOID_FWD |
| Pointwise:ELU | CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR with mode CUDNN_POINTWISE_ELU_FWD |
| Pointwise:{ReLU,tanh,sigmoid,ELU} | CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR
with one of the following modes:
CUDNN_POINTWISE_RELU_FWD, CUDNN_POINTWISE_TANH_FWD, CUDNN_POINTWISE_SIGMOID_FWD,
CUDNN_POINTWISE_ELU_FWD |
| MatMul | CUDNN_BACKEND_OPERATION_MATMUL_DESCRIPTOR |
| ConvolutionFwd | CUDNN_BACKEND_OPERATION_CONVOLUTION_FORWARD_DESCRIPTOR |
| ConvolutionBwFilter | CUDNN_BACKEND_OPERATION_CONVOLUTION_BACKWARD_FILTER_DESCRIPTOR |
| ConvolutionBwData | CUDNN_BACKEND_OPERATION_CONVOLUTION_BACKWARD_DATA_DESCRIPTOR |
| GenStats | CUDNN_BACKEND_OPERATION_GEN_STATS_DESCRIPTOR |
| ResampleFwd | CUDNN_BACKEND_OPERATION_RESAMPLE_FWD_DESCRIPTOR |
| GenStats | CUDNN_BACKEND_OPERATION_GEN_STATS_DESCRIPTOR |
| Reduction | CUDNN_BACKEND_OPERATION_REDUCTION_DESCRIPTOR |
| BnBwdWeight | CUDNN_BACKEND_OPERATION_BN_BWD_WEIGHTS_DESCRIPTOR |
| NormForward | CUDNN_BACKEND_OPERATION_NORM_FORWARD_DESCRIPTOR |
| NormBackward | CUDNN_BACKEND_OPERATION_NORM_BACKWARD_DESCRIPTOR |
| BOOLEAN/packed-BOOLEAN |
CUDNN_DATA_BOOLEAN: As described in the NVIDIA cuDNN API Reference, this type implies that eight boolean values are packed in a single byte, with the lowest index on the right (that is, least significant bit). packed-BOOLEAN and BOOLEAN are used interchangeably, where the former is used to emphasize and remind the user about the semantics. |
| INT8 | CUDNN_DATA_INT8 |
| FP8 | CUDNN_DATA_FP8_E4M3 or CUDNN_DATA_FP8_E5M2 |
| FP16 | CUDNN_DATA_HALF |
| BF16 | CUDNN_DATA_BFLOAT16 |
| FP32 | CUDNN_DATA_FLOAT |
| TF32 | A tensor core operation mode used to accelerate floating point convolutions or matmuls. This can be used for an operation with compute type CUDNN_DATA_FLOAT, on NVIDIA Ampere architecture or later and be disabled with NVIDIA_TF32_OVERRIDE=1. |
4. Legacy API
4.1. Convolution Functions
4.1.1. Prerequisites
4.1.2. Supported Algorithms
| Supported Convolution Function | Supported Algos |
|---|---|
| cudnnConvolutionForward |
CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_PRECOMP_GEMM CUDNN_CONVOLUTION_FWD_ALGO_WINOGRAD_NONFUSED |
| cudnnConvolutionBackwardData |
CUDNN_CONVOLUTION_BWD_DATA_ALGO_1 CUDNN_CONVOLUTION_BWD_DATA_ALGO_WINOGRAD_NONFUSED |
| cudnnConvolutionBackwardFilter |
CUDNN_CONVOLUTION_BWD_FILTER_ALGO_1 CUDNN_CONVOLUTION_BWD_FILTER_ALGO_WINOGRAD_NONFUSED |
4.1.3. Data and Filter Formats
4.2. RNN Functions
4.2.1. Prerequisites
4.2.2. Supported Algorithms
4.2.3. Data and Filter Formats
For more information, refer to Features of RNN Functions.
4.2.4. Features of RNN Functions
For each of these terms, the short-form versions shown in the parenthesis are used in the tables below for brevity: CUDNN_RNN_ALGO_STANDARD (_ALGO_STANDARD), CUDNN_RNN_ALGO_PERSIST_STATIC (_ALGO_PERSIST_STATIC), CUDNN_RNN_ALGO_PERSIST_DYNAMIC (_ALGO_PERSIST_DYNAMIC), and CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION (_ALLOW_CONVERSION).
| Functions | I/O layout supported | Supports variable sequence length in batch | Commonly supported |
|---|---|---|---|
| cudnnRNNForwardInference() | Only Sequence major, packed (non-padded) |
Only with _ALGO_STANDARD Require input sequences descending sorted according to length. |
Mode (cell type) supported:CUDNN_RNN_RELU, CUDNN_RNN_TANH, CUDNN_LSTM, CUDNN_GRU Algo supported1 (refer to the table for for information on these algorithms):_ALGO_STANDARD, _ALGO_PERSIST_STATIC, _ALGO_PERSIST_DYNAMIC Math mode supported: CUDNN_DEFAULT_MATH,CUDNN_TENSOR_OP_MATH (will automatically fall back if run on pre-Volta or if algo doesn’t support Tensor Cores) _ALLOW_CONVERSION (may perform down conversion to utilize Tensor Cores) Direction mode supported: CUDNN_UNIDIRECTIONAL, CUDNN_BIDIRECTIONAL RNN input mode: CUDNN_LINEAR_INPUT, CUDNN_SKIP_INPUT |
| cudnnRNNForwardTraining() | |||
| cudnnRNNBackwardData() | |||
| cudnnRNNBackwardWeights() | |||
| cudnnRNNForwardInferenceEx() |
Sequence major unpacked Batch major unpacked2 Sequence major packed3 |
Only with _ALGO_STANDARD For unpacked layout, no input sorting required. 4 For packed layout, require input sequences descending sorted according to length. |
|
| cudnnRNNForwardTrainingEx() | |||
| cudnnRNNBackwardDataEx() | |||
| cudnnRNNBackwardWeightsEx() |
| Features | _ALGO_STANDARD | _ALGO_PERSIST_STATIC | CUDNN_RNN_ALGO_PERSIST_STATIC_SMALL_H | _ALGO_PERSIST_DYNAMIC |
|---|---|---|---|---|
| Half input
Single accumulation Half output |
Supported
Half intermediate storage Single accumulation |
|||
| Single input
Single accumulation Single output |
Supported
If running on Volta, with CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION5, will down-convert and use half intermediate storage. Otherwise: Single intermediate storage Single accumulation |
|||
| Double input
Double accumulation Double output |
Supported
Double intermediate storage Double accumulation |
Not Supported | Not Supported | Supported
Double intermediate storage Double accumulation |
| LSTM recurrent projection | Supported | Not Supported | Not Supported | Not Supported |
| LSTM cell clipping | Supported | |||
| Variable sequence length in batch | Supported | Not Supported | Not Supported | Not Supported |
| Tensor Cores |
Supported For half input/output, acceleration requires setting CUDNN_TENSOR_OP_MATH6 or CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION 7 Acceleration requires inputSize and hiddenSize to be a multiple of 8 For single input/output on NVIDIA Volta, NVIDIA Xavier, and NVIDIA Turing, acceleration requires setting CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION8 Acceleration requires inputSize and hiddenSize to be a multiple of 8 For single input/output on NVIDIA Ampere architecture, acceleration requires setting CUDNN_DEFAULT_MATH, CUDNN_TENSOR_OP_MATH, or CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION9 Acceleration requires inputSize and hiddenSize to be a multiple of 4. |
Not Supported, will execute normally ignoring CUDNN_TENSOR_OP_MATH10 or _ALLOW_CONVERSION11 | ||
| Other limitations | Max problem size is limited by GPU specifications. | Requires real time compilation through NVRTC | ||
4.3. Tensor Transformations
4.3.1. Conversion Between FP32 and FP16
For Convolutions
// Set the math type to allow cuDNN to use Tensor Cores: checkCudnnErr(cudnnSetConvolutionMathType(cudnnConvDesc, CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION));
For RNNs
// Set the math type to allow cuDNN to use Tensor Cores: checkCudnnErr(cudnnSetRNNMatrixMathType(cudnnRnnDesc, CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION));
4.3.2. Padding
4.3.3. Folding
With folding or channel-folding, cuDNN can implicitly format the input tensors within an internal workspace to accelerate the overall calculation. Performing this transformation for the user often allows cuDNN to use kernels with restrictions on convolution stride to support a strided convolution problem.
4.3.4. Conversion Between NCHW And NHWC
If your input (and output) are NCHW, then expect a layout change.
Non-Tensor Op convolutions will not perform conversions between NCHW and NHWC.
In very rare and difficult-to-qualify cases that are a complex function of padding and filter sizes, it is possible that Tensor Ops is not enabled. In such cases, users can pre-pad to enable the Tensor Ops path.
4.4. Mixed Precision Numerical Accuracy
For example, when the computation is performed in FP32 and the output is in FP16, the CUDNN_CONVOLUTION_BWD_FILTER_ALGO_0 (ALGO_0) has lower accuracy compared to the CUDNN_CONVOLUTION_BWD_FILTER_ALGO_1 (ALGO_1). This is because ALGO_0 does not use extra workspace, and is forced to accumulate the intermediate results in FP16, that is, half precision float, and this reduces the accuracy. The ALGO_1, on the other hand, uses additional workspace to accumulate the intermediate values in FP32, that is, full precision float.
5. Odds and Ends
5.1. Thread Safety
When creating a per-thread cuDNN handle, it is recommended that a single synchronous call of cudnnCreate() be made first before each thread creates its own handle asynchronously.
Per cudnnCreate(), for multi-threaded applications that use the same device from different threads, the recommended programming model is to create one (or a few, as is convenient) cuDNN handles per thread and use that cuDNN handle for the entire life of the thread.
5.2. Reproducibility (Determinism)
Across different architectures, no cuDNN routines guarantee bit-wise reproducibility. For example, there is no guarantee of bit-wise reproducibility when comparing the same routine run on NVIDIA Volta™ and NVIDIA Turing™, NVIDIA Turing, and NVIDIA Ampere architecture.
5.3. Scaling Parameters
dstValue = alpha*computedValue + beta*priorDstValue
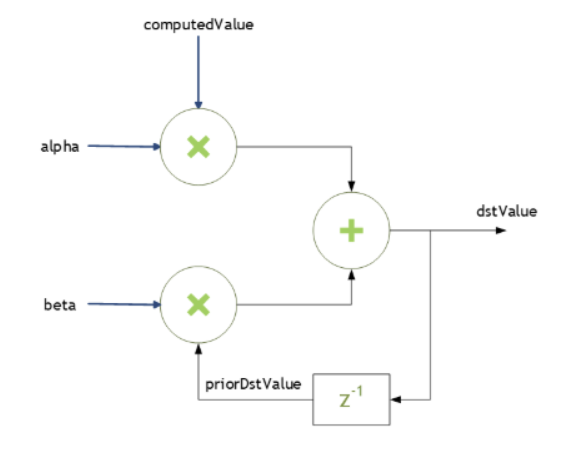
When beta is zero, the output is not read and may contain uninitialized data (including NaN).
- float for HALF and FLOAT tensors, and
- double for DOUBLE tensors.
Type Conversion
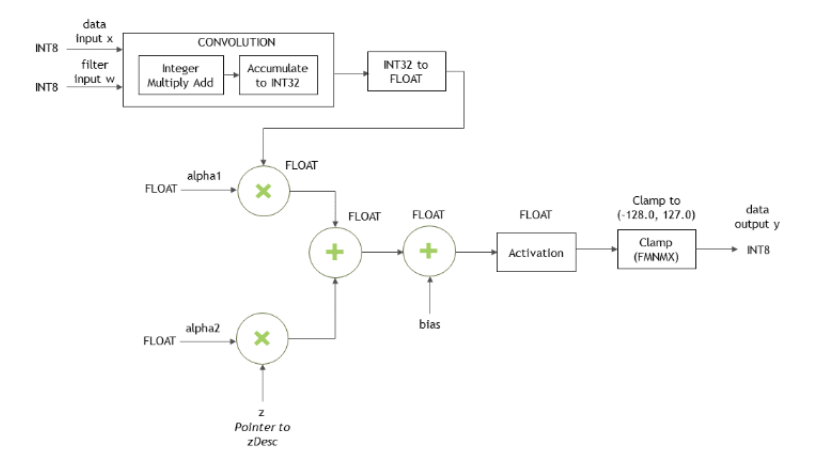
When the data input x, the filter input w and the output y are all in INT8 data type, the function cudnnConvolutionBiasActivationForward() will perform the type conversion as shown in Figure 51:
5.5. Deprecation Policy
This depreciation scheme allows us to retire the deprecated API in just one major release. Functionality that is deprecated in the current major release can be compiled without any changes.The backward compatibility ends when another major cuDNN release is introduced.
warning: ‘cudnnStatus_t cudnnSetRNNMatrixMathType(cudnnRNNDescriptor_t, cudnnMathType_t)’ is deprecated [-Wdeprecated-declarations]or
warning C4996: 'cudnnSetRNNMatrixMathType': was declared deprecated
The above warnings are disabled by default to avoid potential build breaks in software setups where compiler warnings are treated as errors.
warning: ‘EXAMPLE_VAL’ is deprecated: value not allowed [-Wdeprecated-declarations]or
warning C4996: ‘EXAMPLE_VAL’: was declared deprecated
Special Case: API Behavior Change
To help ease the transition and avoid any surprises to developers, a behavior change between two major versions of a specific API function is accommodated by suffixing the function with a _v tag followed by the current, major cuDNN version. In the next major release, the deprecated function is removed, and its name is never reused. (Brand-new API’s are first introduced without the _v tag).
Updating a function’s behavior in this way uses the API’s name to embed the cuDNN version where the API call was modified. As a result, the API changes will be easier to track and document.
- Major release 8
- The updated API is introduced as foo_v8(). The deprecated API foo() is kept unchanged to maintain backward compatibility until the next major release.
- Major release 9
- The deprecated API foo() is permanently removed and its name is not reused. The foo_v8() function supersedes the retired call foo().
5.6. GPU And Driver Requirements
5.7. Convolutions
5.7.1. Convolution Formulas
| Term | Description |
|---|---|
| Input (image) Tensor | |
| Weight Tensor | |
| Output Tensor | |
| Current Batch Size | |
| Current Input Channel | |
| Total Input Channels | |
| Input Image Height | |
| Input Image Width | |
| Current Output Channel | |
| Total Output Channels | |
| Current Output Height Position | |
| Current Output Width Position | |
| Group Count | |
| Padding Value | |
| Vertical Subsample Stride (along Height) | |
| Horizontal Subsample Stride (along Width) | |
| Vertical Dilation (along Height) | |
| Horizontal Dilation (along Width) | |
| Current Filter Height | |
| Total Filter Height | |
| Current Filter Width | |
| Total Filter Width | |
Convolution (convolution mode set to CUDNN_CROSS_CORRELATION)
Convolution with Padding
Convolution with Subsample-Striding
Convolution with Dilation
Convolution (convolution mode set to CUDNN_CONVOLUTION)
Convolution using Grouped Convolution
5.7.2. Grouped Convolutions
Basic Idea
Conceptually, in grouped convolutions, the input channels and the filter channels are split into a groupCount number of independent groups, with each group having a reduced number of channels. The convolution operation is then performed separately on these input and filter groups.
For example, consider the following: if the number of input channels is 4, and the number of filter channels of 12. For a normal, ungrouped convolution, the number of computation operations performed are 12*4.
If the groupCount is set to 2, then there are now two input channel groups of two input channels each, and two filter channel groups of six filter channels each.
As a result, each grouped convolution will now perform 2*6 computation operations, and two such grouped convolutions are performed. Hence the computation savings are 2x: (12*4)/(2*(2*6)) .
5.7.3. Best Practices for 3D Convolutions
The following guidelines are for setting the cuDNN library parameters to enhance the performance of 3D convolutions. Specifically, these guidelines are focused on settings such as filter sizes, padding and dilation settings. Additionally, an application-specific use-case, namely, medical imaging, is presented to demonstrate the performance enhancement of 3D convolutions with these recommended settings.
For more information, refer to the NVIDIA cuDNN API Reference.
5.7.3.1. Recommended Settings
| Platform |
NVIDIA Hopper architecture NVIDIA Ampere architecture NVIDIA Turing architecture NVIDIA Volta architecture |
|
| Convolution (3D or 2D) | 3D and 2D | |
| Convolution or deconvolution (fprop, dgrad, or wgrad) |
fprop dgrad wgrad |
|
| Grouped convolution size |
C_per_group == K_per_group == {1,4,8,16,32,64,128,256} Not supported for INT8 |
|
| Data layout format (NHWC/NCHW)12 | NDHWC | |
| Input/output precision (FP16, FP32, INT8, or FP64) | FP16, FP3213, INT814 | |
| Accumulator (compute) precision (FP16, FP32, INT32 or FP64) | FP32, INT32 | |
| Filter (kernel) sizes | No limitation | |
| Padding | No limitation | |
| Image sizes | 2 GB limitation for a tensor | |
| Number of channels | C |
0 mod 8 0 mod 16 (for INT8) |
| K |
0 mod 8 0 mod 16 (for INT8) |
|
| Convolution mode | Cross-correlation and convolution | |
| Strides | No limitation | |
| Dilation | No limitation | |
| Data pointer alignment | All data pointers are 16-bytes aligned. | |
5.7.3.2. Limitations
If the above is in the network, use cuDNNFind to get the best option.
5.8. Environment Variables
6. Troubleshooting
6.1. Error Reporting And API Logging
The log output contains variable names, data types, parameter values, device pointers, process ID, thread ID, cuDNN handle, CUDA stream ID, and metadata such as time of the function call in microseconds.
For example, when the severity level CUDNN_LOGINFO_DBG is enabled, the user will receive the API loggings, such as:
cuDNN (v8300) function cudnnSetActivationDescriptor() called:
mode: type=cudnnActivationMode_t; val=CUDNN_ACTIVATION_RELU (1);
reluNanOpt: type=cudnnNanPropagation_t; val=CUDNN_NOT_PROPAGATE_NAN (0);
coef: type=double; val=1000.000000;
Time: 2017-11-21T14:14:21.366171 (0d+0h+1m+5s since start)
Process: 21264, Thread: 21264, cudnn_handle: NULL, cudnn_stream: NULL.
cuDNN (v8300) function cudnnBackendFinalize() called:
Info: Traceback contains 5 message(s)
Error: CUDNN_STATUS_BAD_PARAM; reason: out <= 0
Error: CUDNN_STATUS_BAD_PARAM; reason: is_valid_spacial_dim(xSpatialDimA[dim], wSpatialDimA[dim], ySpatialDimA[dim], cDesc.getPadLowerA()[dim], cDesc.getPadUpperA()[dim], cDesc.getStrideA()[dim], cDesc.getDilationA()[dim])
Error: CUDNN_STATUS_BAD_PARAM; reason: is_valid_convolution(xDesc, wDesc, cDesc, yDesc)
Error: CUDNN_STATUS_BAD_PARAM; reason: convolution.init(xDesc, wDesc, cDesc, yDesc)
Error: CUDNN_STATUS_BAD_PARAM; reason: finalize_internal()
Time: 2021-10-05T17:11:07.935640 (0d+0h+0m+15s since start)
Process=87720; Thread=87720; GPU=NULL; Handle=NULL; StreamId=NULL.
There are two methods, as described below, to enable the error/warning reporting and API logging. For convenience, the log output can be handled by the built-in default callback function, which will direct the output to a log file or the standard I/O as designated by the user. The user may also write their own callback function to handle this information programmably, and use the cudnnSetCallback() to pass in the function pointer of their own callback function.
Method 1: Using Environment Variables
Refer to Table 32 for the impact on the performance of API logging using environment variables. The CUDNN_LOG{INFO,WARN,ERR}_DBG notation in the table header means the conclusion is applicable to either one of the environment variables.
| Environment variables | CUDNN_LOG{INFO,WARN,ERR}_DBG=0 | CUDNN_LOG{INFO,WARN,ERR}_DBG=1 |
|---|---|---|
| CUDNN_LOGDEST_DBG not set |
No logging output No performance loss |
No logging output No performance loss |
|
CUDNN_LOGDEST_DBG=NULL |
No logging output No performance loss |
No logging output No performance loss |
|
CUDNN_LOGDEST_DBG=stdout or stderr |
No logging output No performance loss |
Logging to stdout or stderr Some performance loss |
|
CUDNN_LOGDEST_DBG=filename.txt |
No logging output No performance loss |
Logging to filename.txt Some performance loss |
Method 2: Using the API
To use API function calls to enable API logging, refer to the API description of cudnnSetCallback() and cudnnGetCallback().
6.2. FAQs
Q: I’m not sure if I should use cuDNN for inference or training. How does it compare with TensorRT?
A: cuDNN provides the building blocks for common routines such as convolution, matmul, normalization, attention, pooling, activation and RNN/LSTMs. You can use cuDNN for both training and inference. However, where it differs from TensorRT is that the latter (TensorRT) is a programmable inference accelerator; just like a framework. TensorRT sees the whole graph and optimizes the network by fusing/combining layers and optimizing kernel selection for improved latency, throughout, power efficiency and for reducing memory requirements.
A rule of thumb you can apply is to check out TensorRT, see if it meets your inference needs, if it doesn't, then look at cuDNN for a closer, more in-depth perspective.
Q: How does heuristics in cuDNN work? How does it know what is the optimal solution for a given problem?
A: NVIDIA actively monitors the Deep Learning space for important problem specifications such as commonly used models. The heuristics are produced by sampling a portion of these problem specifications with available computational choices. Over time, more models are discovered and incorporated into the heuristics.
Q: Is cuDNN going to support running arbitrary graphs?
A: No, we don’t plan to become a framework and execute the whole graph one op at a time. At this time, we are focused on a subgraph given by the user, where we try to produce an optimized fusion kernel. We will document the rules regarding what can be fused and what cannot. The goal is to support general and flexible fusion, however, it will take time and there will be limits in what it can do in the cuDNN version 8.0.0 launch.
Q: What’s the difference between TensorRT, TensorFlow/XLA’s fusion, and cuDNN’s fusion?
A: TensorRT and TensorFlow are frameworks; they see the whole graph and can do global optimization, however, they generally only fuse pointwise ops together or pattern match to a limited set of pre-compiled fixed fusion patterns like conv-bias-relu. On the other hand, cuDNN targets a subgraph, but can fuse convolutions with pointwise ops, thus providing potentially better performance. CuDNN fusion kernels can be utilized by TensorRT and TensorFlow/XLA as part of their global graph optimization.
Q: Can I write an application calling cuDNN directly?
A: Yes, you can call the C/C++ API directly. Usually, data scientists would wait for framework integration and use the Python API which is more convenient. However, if your use case requires better performance, you can target the cuDNN API directly.
Q: How does mixed precision training work?
A: Several components need to work together to make mixed precision training possible. CuDNN needs to support the layers with the required datatype config and have optimized kernels that run very fast. In addition, there is a module called automatic mixed precision (AMP) in frameworks which intelligently decides which op can run in a lower precision without affecting convergence and minimize the number of type conversions/transposes in the entire graph. These work together to give you speed up. For more information, refer to Mixed Precision Numerical Accuracy.
Q: How can I pick the fastest convolution kernels with cuDNN version 8.0.0?
A: In the API introduced in cuDNN v8, convolution kernels are grouped by similar computation and numerical properties into engines. Every engine has a queryable set of performance tuning knobs. A computation case such as a convolution operation graph can be computed using different valid combinations of engines and their knobs, known as an engine configuration. Users can query an array of engine configurations for any given computation case ordered by performance, from fastest to slowest according to cuDNN’s own heuristics. Alternately, users can generate all possible engine configurations by querying the engine count and available knobs for each engine. This generated list could be used for auto-tuning or the user could create their own heuristics.
Q: Why is cuDNN version 8.0 convolution API call much slower on the first call than subsequent calls?
A: Due to the library split, cuDNN version 8.0 API will only load the necessary kernels on the first API call that requires it. In previous versions, this load would have been observed in the first cuDNN API call that triggers CUDA context initialization, typically cudnnCreate(). In version 8.0, this is delayed until the first sub-library call that triggers CUDA context initialization. Users who desire to have CUDA context preloaded can call the new cudnnCnnInferVersionCheck() API (or its related cousins), which has the side effect of initializing a CUDA context. This will reduce the run time for all subsequent API calls.
Q: How do I build the cuDNN version 8.0.0 split library?
A: cuDNN v8.0 library is split into multiple sub-libraries. Each library contains a subset of the API. Users can link directly against the individual libraries or link with a dlopen layer which follows a plugin architecture.
To link against an individual library, users can directly specify it and its dependencies on the linker command line. For example, for infer libraries: -lcudnn_adv_infer, -lcudnn_cnn_infer, or -lcudnn_ops_infer.
For all libraries, -lcudnn_adv_train, -lcudnn_cnn_train, -lcudnn_ops_train, -lcudnn_adv_infer, -lcudnn_cnn_infer, and -lcudnn_ops_infer.
The dependency order is documented in the NVIDIA cuDNN 8.0.0 Preview Release Notes and the NVIDIA cuDNN API Reference.
Alternatively, the user can continue to link against a shim layer (-libcudnn) which can dlopen the correct library that provides the implementation of the function. When the function is called for the first time, the dynamic loading of the library takes place.
-lcudnn
Q: What are the new APIs in cuDNN version 8.0.0?
A: The new cuDNN APIs are listed in the cuDNN 8.0.0 Release Notes as well as in the API changes for cuDNN 8.0.0.
6.3. Support
We appreciate all types of feedback. Consider posting on the forums with questions, comments, and suspected bugs that are appropriate to discuss publicly. cuDNN-related posts are reviewed by the cuDNN engineering team, and internally we will file bugs where appropriate. It’s helpful if you can paste or attach an API log to help us reproduce.
- Register for the NVIDIA Developer website.
- Log in to the developer site.
- Click on your name in the upper right corner.
- Click My account > My Bugs and select Submit a New Bug.
- Fill out the bug reporting page. Be descriptive and if possible, provide the steps that you are following to help reproduce the problem. If possible, paste or attach an API log.
- Click Submit a bug.
7. Acknowledgments
7.1. University of Tennessee
Copyright (c) 2010 The University of Tennessee.
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are
met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above
copyright notice, this list of conditions and the following
disclaimer listed in this license in the documentation and/or
other materials provided with the distribution.
* Neither the name of the copyright holders nor the names of its
contributors may be used to endorse or promote products derived
from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
"AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.7.2. University of California, Berkeley
COPYRIGHT All contributions by the University of California: Copyright (c) 2014, The Regents of the University of California (Regents) All rights reserved. All other contributions: Copyright (c) 2014, the respective contributors All rights reserved. Caffe uses a shared copyright model: each contributor holds copyright over their contributions to Caffe. The project versioning records all such contribution and copyright details. If a contributor wants to further mark their specific copyright on a particular contribution, they should indicate their copyright solely in the commit message of the change when it is committed. LICENSE Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met: 1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer. 2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution. THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. CONTRIBUTION AGREEMENT By contributing to the BVLC/caffe repository through pull-request, comment, or otherwise, the contributor releases their content to the license and copyright terms herein.
7.3. Facebook AI Research, New York
Copyright (c) 2014, Facebook, Inc. All rights reserved. Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met: * Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer. * Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution. * Neither the name Facebook nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission. THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
Additional Grant of Patent Rights "Software" means fbcunn software distributed by Facebook, Inc. Facebook hereby grants you a perpetual, worldwide, royalty-free, non-exclusive, irrevocable (subject to the termination provision below) license under any rights in any patent claims owned by Facebook, to make, have made, use, sell, offer to sell, import, and otherwise transfer the Software. For avoidance of doubt, no license is granted under Facebook’s rights in any patent claims that are infringed by (i) modifications to the Software made by you or a third party, or (ii) the Software in combination with any software or other technology provided by you or a third party. The license granted hereunder will terminate, automatically and without notice, for anyone that makes any claim (including by filing any lawsuit, assertion or other action) alleging (a) direct, indirect, or contributory infringement or inducement to infringe any patent: (i) by Facebook or any of its subsidiaries or affiliates, whether or not such claim is related to the Software, (ii) by any party if such claim arises in whole or in part from any software, product or service of Facebook or any of its subsidiaries or affiliates, whether or not such claim is related to the Software, or (iii) by any party relating to the Software; or (b) that any right in any patent claim of Facebook is invalid or unenforceable.
Notices
Notice
This document is provided for information purposes only and shall not be regarded as a warranty of a certain functionality, condition, or quality of a product. NVIDIA Corporation (“NVIDIA”) makes no representations or warranties, expressed or implied, as to the accuracy or completeness of the information contained in this document and assumes no responsibility for any errors contained herein. NVIDIA shall have no liability for the consequences or use of such information or for any infringement of patents or other rights of third parties that may result from its use. This document is not a commitment to develop, release, or deliver any Material (defined below), code, or functionality.
NVIDIA reserves the right to make corrections, modifications, enhancements, improvements, and any other changes to this document, at any time without notice.
Customer should obtain the latest relevant information before placing orders and should verify that such information is current and complete.
NVIDIA products are sold subject to the NVIDIA standard terms and conditions of sale supplied at the time of order acknowledgement, unless otherwise agreed in an individual sales agreement signed by authorized representatives of NVIDIA and customer (“Terms of Sale”). NVIDIA hereby expressly objects to applying any customer general terms and conditions with regards to the purchase of the NVIDIA product referenced in this document. No contractual obligations are formed either directly or indirectly by this document.
NVIDIA products are not designed, authorized, or warranted to be suitable for use in medical, military, aircraft, space, or life support equipment, nor in applications where failure or malfunction of the NVIDIA product can reasonably be expected to result in personal injury, death, or property or environmental damage. NVIDIA accepts no liability for inclusion and/or use of NVIDIA products in such equipment or applications and therefore such inclusion and/or use is at customer’s own risk.
NVIDIA makes no representation or warranty that products based on this document will be suitable for any specified use. Testing of all parameters of each product is not necessarily performed by NVIDIA. It is customer’s sole responsibility to evaluate and determine the applicability of any information contained in this document, ensure the product is suitable and fit for the application planned by customer, and perform the necessary testing for the application in order to avoid a default of the application or the product. Weaknesses in customer’s product designs may affect the quality and reliability of the NVIDIA product and may result in additional or different conditions and/or requirements beyond those contained in this document. NVIDIA accepts no liability related to any default, damage, costs, or problem which may be based on or attributable to: (i) the use of the NVIDIA product in any manner that is contrary to this document or (ii) customer product designs.
No license, either expressed or implied, is granted under any NVIDIA patent right, copyright, or other NVIDIA intellectual property right under this document. Information published by NVIDIA regarding third-party products or services does not constitute a license from NVIDIA to use such products or services or a warranty or endorsement thereof. Use of such information may require a license from a third party under the patents or other intellectual property rights of the third party, or a license from NVIDIA under the patents or other intellectual property rights of NVIDIA.
Reproduction of information in this document is permissible only if approved in advance by NVIDIA in writing, reproduced without alteration and in full compliance with all applicable export laws and regulations, and accompanied by all associated conditions, limitations, and notices.
THIS DOCUMENT AND ALL NVIDIA DESIGN SPECIFICATIONS, REFERENCE BOARDS, FILES, DRAWINGS, DIAGNOSTICS, LISTS, AND OTHER DOCUMENTS (TOGETHER AND SEPARATELY, “MATERIALS”) ARE BEING PROVIDED “AS IS.” NVIDIA MAKES NO WARRANTIES, EXPRESSED, IMPLIED, STATUTORY, OR OTHERWISE WITH RESPECT TO THE MATERIALS, AND EXPRESSLY DISCLAIMS ALL IMPLIED WARRANTIES OF NONINFRINGEMENT, MERCHANTABILITY, AND FITNESS FOR A PARTICULAR PURPOSE. TO THE EXTENT NOT PROHIBITED BY LAW, IN NO EVENT WILL NVIDIA BE LIABLE FOR ANY DAMAGES, INCLUDING WITHOUT LIMITATION ANY DIRECT, INDIRECT, SPECIAL, INCIDENTAL, PUNITIVE, OR CONSEQUENTIAL DAMAGES, HOWEVER CAUSED AND REGARDLESS OF THE THEORY OF LIABILITY, ARISING OUT OF ANY USE OF THIS DOCUMENT, EVEN IF NVIDIA HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. Notwithstanding any damages that customer might incur for any reason whatsoever, NVIDIA’s aggregate and cumulative liability towards customer for the products described herein shall be limited in accordance with the Terms of Sale for the product.
Arm
Arm, AMBA and Arm Powered are registered trademarks of Arm Limited. Cortex, MPCore and Mali are trademarks of Arm Limited. "Arm" is used to represent Arm Holdings plc; its operating company Arm Limited; and the regional subsidiaries Arm Inc.; Arm KK; Arm Korea Limited.; Arm Taiwan Limited; Arm France SAS; Arm Consulting (Shanghai) Co. Ltd.; Arm Germany GmbH; Arm Embedded Technologies Pvt. Ltd.; Arm Norway, AS and Arm Sweden AB.
HDMI
HDMI, the HDMI logo, and High-Definition Multimedia Interface are trademarks or registered trademarks of HDMI Licensing LLC.
Blackberry/QNX
Copyright © 2020 BlackBerry Limited. All rights reserved.
Trademarks, including but not limited to BLACKBERRY, EMBLEM Design, QNX, AVIAGE, MOMENTICS, NEUTRINO and QNX CAR are the trademarks or registered trademarks of BlackBerry Limited, used under license, and the exclusive rights to such trademarks are expressly reserved.
Trademarks
NVIDIA, the NVIDIA logo, and BlueField, CUDA, DALI, DRIVE, Hopper, JetPack, Jetson AGX Xavier, Jetson Nano, Maxwell, NGC, Nsight, Orin, Pascal, Quadro, Tegra, TensorRT, Triton, Turing and Volta are trademarks and/or registered trademarks of NVIDIA Corporation in the United States and other countries. Other company and product names may be trademarks of the respective companies with which they are associated.