How to Customize a Riva ASR Acoustic Model (Conformer-CTC) with Adapters
Contents
How to Customize a Riva ASR Acoustic Model (Conformer-CTC) with Adapters#
This tutorial walks you through how to customize a Riva ASR acoustic model (Conformer-CTC) with Adapter modules, using NVIDIA NeMo.
NVIDIA Riva Overview#
NVIDIA Riva is a GPU-accelerated SDK for building speech AI applications that are customized for your use case and deliver real-time performance.
Riva offers a rich set of speech and natural language understanding (NLU) services such as:
Automated speech recognition (ASR)
Text-to-Speech synthesis (TTS)
A collection of natural language processing (NLP) services, such as named entity recognition (NER), punctuation, and intent classification.
In this tutorial, we will customize a Riva ASR acoustic model (Conformer) with Adapter modules, using NeMo.
To understand the basics of Riva ASR APIs, refer to Getting started with Riva ASR in Python.
For more information about Riva, refer to the Riva developer documentation.
Neural Module (NeMo)#
NVIDIA Neural Module (NeMo) Toolkit is an open-source framework for building, training, and fine-tuning GPU-accelerated speech AI and NLU models with a simple Python interface. Developers, researchers, and software partners building intelligent conversational AI applications and services, can bring their own data to fine-tune pre-trained models instead of going through the hassle of training the models from scratch.
ASR with Adapters#
The following tutorial heavily references the NeMo tutorial on ASR Domain Adaptation with Adapters.
We advise to keep both tutorials open side-by-side to refer to the contents effectively by using the Table of Contents.
What are Adapters?#
Adapters are trainable neural network modules that are attached to pretrained models, such that we freeze the weights of the original model and only train the adapter parameters. This reduces the amount of data required to customize a model substantially, while imposing the limitation that the model’s vocabulary cannot be changed.
In short,
Adapter modules form a residual bridge over the output of each layer they adapt, such that the model’s original performance is not lost.
The original parameters of the model are frozen in their entirety, so that we can recover the original model by disabling all adapters.
We train only the new adapter parameters (an insignificant fraction of the total number of parameters). This allows fast experimentation with very little data and compute.
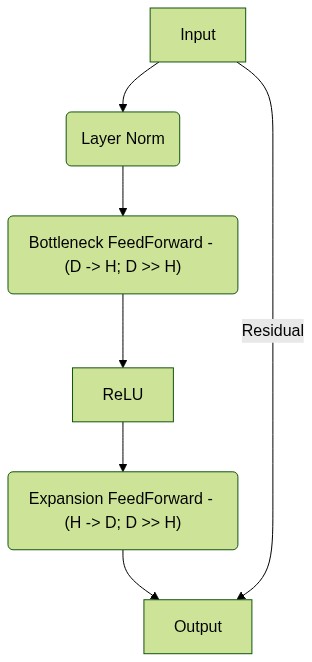
Adapters are a straightforward concept, as shown in the following diagram. At their simplest, they are residual Feedforward layers that compress the input dimension (\(D\)) to a small bottleneck dimension (\(H\)), such that \(R^D \text{->} R^H\), compute an activation (such as ReLU), finally mapping \(R^H \text{->} R^D\) with another Feedforward layer. This output is then added to the input through a residual connection.
Advantages and Limitations of Adapter Training#
Adapters can be used with limited amounts of training data and compute budget, however, they impose the restriction that the model’s original vocabulary must be used. Therefore, a new character set vocabulary/tokenizer cannot be used.
Refer to the Advantages of Adapters and Limitations of Adapters sections in the NeMo tutorial for further details.
Preparing the Acoustic Encoder for Adapter Training#
Pre-trained models do not automatically support Adapter modules, so we must prepare the acoustic encoder prior to creating the model. The steps for this procedure are detailed in the Prepare the “base” model section of the NeMo tutorial.
Preparing the Model and Dataset for Adaptation#
There are very few differences between fine-tuning and adapter training with respect to the preparation of the model, data loaders, or optimization method.
One significant difference is that there is no need to change the vocabulary of the pre-trained network, therefore, there is no need to construct a new tokenizer or update the character vocabulary. If your customization dataset contains tokens that requires such changes (for example tokens that don’t exist in the model), then you will need to either preprocess the text to remove such tokens, or instead perform fine-tuning (which may require substantially more data).
Another minor difference is the use of spectrogram augmentation (SpecAugment). During fine-tuning, the amount of data is very little compared to when the model was pre-trained with thousands of hours of speech, so SpecAugment may have been used to prevent overfitting. For adapters, we recommend first disabling spec augmentation and trying to see if results are good enough, then adding it back slowly, as needed, to see if any improvements can be obtained.
Refer to the Setup training and evaluation of the model section, and particularly the Setup Spectrogram Augmentation section of the NeMo tutorial for further details.
Creating and Training an Adapter#
The Adapters: Creation and Preparation section of the NeMo tutorial details how to create an config object for a LinearAdapter, add it to the pretrained model, then freeze the original parameters of the model to train just the new parameters.
All of this is a few lines of code, which will initialize your model so that it is prepared to train the adapter on new speech data.
Evaluating the Model#
Since adapters contain new parameters and are dynamic in nature, they can be enabled/disabled prior to evaluation. The Evaluate the adapted model section in the NeMo tutorial showcases how you can load the model, enable or disable an adapter in the model, save the model and then evaluate it with some data.
Adapters are trained such that if one disables all adapters, the model will revert back to the pretrained model, which allows you to select whether you want to do well on general speech (with original pretrained model) or do better on your adaptation domain (with an adapter enabled).
Export the Model to Riva#
The nemo2riva command-line tool provides the capability to export your .nemo model in a format that can be deployed using NVIDIA Riva, a highly performant application framework for multi-modal conversational AI services using GPUs. A Python .whl file for nemo2riva is included in the Riva Skills Quick Start resource folder. You can also install nemo2riva with pip, as shown in the Conformer-CTC fine-tuning tutorial.
Using nemo2riva, you can export your trained NeMo model for use in Riva by following the instructions in the Riva documentation.
What’s Next?#
You can use NeMo to build custom models for your own applications, or you could deploy the custom model to NVIDIA Riva.