Overview¶
Riva handles deployments of full pipelines, which can be composed of one or more NVIDIA TAO Toolkit models and other pre-/post-processing components. Additionally, the TAO Toolkit models have to be exported to an efficient inference engine and optimized for the target platform. Therefore, the Riva server cannot use NVIDIA NeMo or TAO models directly because they represent only a single model.
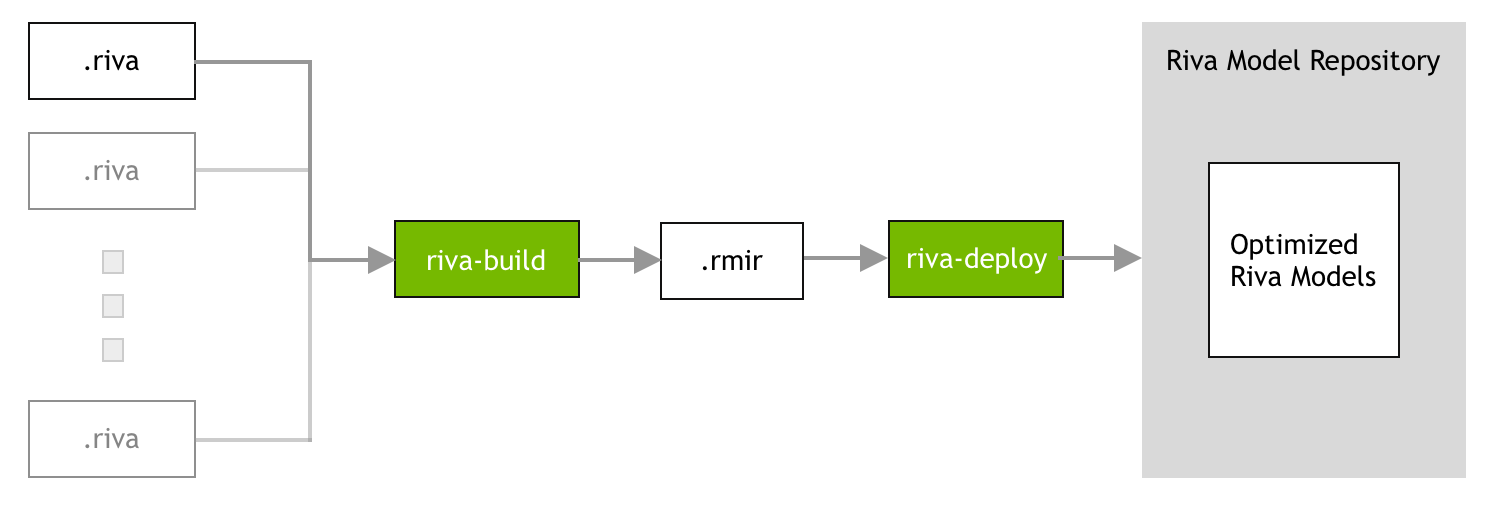
The process of gathering all the required artifacts (for example, models, files, configurations and user settings) and generating the inference engines, will be referred to as the Riva model repository generation. The Riva ServiceMaker Docker image has all the tools necessary to generate the Riva model repository and can be pulled from NGC as follows:
docker pull nvcr.io/nvidia/riva/riva-speech:1.9.0-beta-servicemaker
The Riva model repository generation is done in three phases:
Phase 1: The development phase. To create a model in Riva, the model checkpoints must be converted to .riva format. You
can further develop these .riva models using TAO Toolkit or NeMo. For more information, refer to the Model Development with TAO Toolkit
and Model Development with NeMo sections.
Phase 2: The build phase. During the build phase, all the necessary artifacts (models, files, configurations, and user settings) required to deploy a Riva service are gathered together into an intermediate file called RMIR (Riva Model Intermediate Representation). For more information, refer to the Riva Build section.
Phase 3: The deploy phase. During the deploy phase, the RMIR file is converted into the Riva model repository and the neural networks in TAO Toolkit or NeMo format are exported and optimized to run on the target platform. The deploy phase should be executed on the physical cluster on which the Riva server will be deployed. For more information, refer to the Riva Deploy section.
Model Development with TAO Toolkit¶
Models trained from NVIDIA TAO Toolkit
normally have the format .tao. To use those models in Riva, users needs to convert the model
checkpoints to .riva format for building and deploying with Riva ServiceMaker using tao_export.
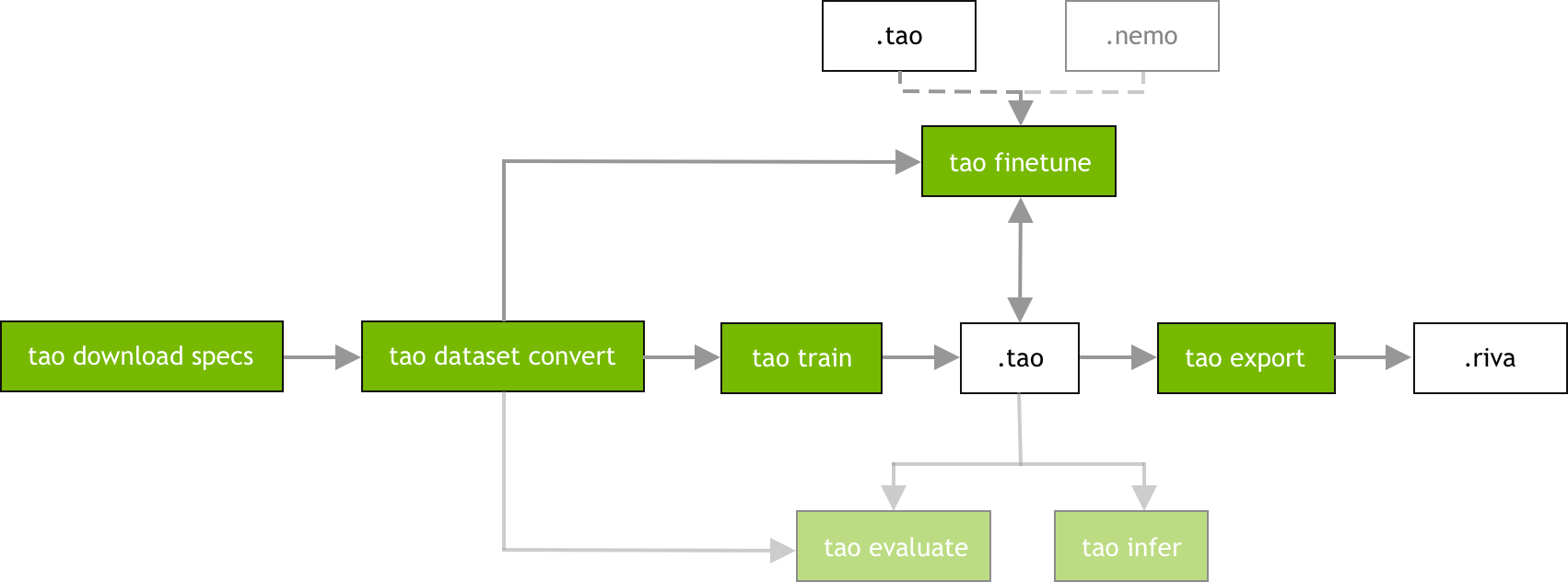
TAO Export for TAO Toolkit¶
Follow the TAO Toolkit Launcher Quick Start Guide instructions to setup.
Configure the TAO Toolkit launcher. The TAO Toolkit launcher uses Docker containers for training and export tasks. The launcher instance can be configured in the
~/.tao_mounts.jsonfile. Configuration requires mounting at least three separate directories wheredata,specification files, andresultsare stored. A sample is provided below.{ "Mounts":[ { "source": "~/tao/data", "destination": "/data" }, { "source": "~/tao/specs", "destination": "/specs" }, { "source": "~/tao/results", "destination": "/results" }, { "source": "~/.cache", "destination": "/root/.cache" } ], "DockerOptions":{ "shm_size": "16G", "ulimits": { "memlock": -1, "stack": 67108864 } } }
Convert the TAO Toolkit checkpoints to the Riva format using
tao … export. The example below demonstrates exporting a Citrinet model trained in TAO, where:-mis used to specify the Citrinet model checkpoints location-eis used to specify the path to an experiment spec file-rindicates where the experiment results (logs, output, model checkpoints, etc.) are stored
tao speech_to_text export -m /data/asr/citrinet.tao -e /specs/asr/speech_to_text/export.yaml -r /results/asr/speech_to_text/
Here is an example experiment spec file (
export.yaml):# Path and name of the input .nemo/.tao archive to be loaded/exported. restore_from: /data/asr/citrinet.tao # Name of output file (will land in the folder pointed by -r) export_to: citrinet.riva
Note that TAO Toolkit comes with default experiment spec files that can be pulled by calling:
tao speech_to_text download_specs -o /specs/asr/speech_to_text/ -r /results/asr/speech_to_text/download_specs/
Besides speech_to_text from the ASR domain, TAO Toolkit also supports several conversational AI tasks from the NLP domain:
intent_slot_classificationpunctuation_and_capitalizationquestion_answeringtext_classificationtoken_classification
More details can be found in tao --help.
Model Development with NeMo¶
NeMo is an open source PyTorch-based toolkit for research in conversational AI. While TAO Toolkit is the recommended path for typical users of Riva, some developers may prefer to use NeMo because it exposes more of the model and PyTorch internals. Riva supports the ability to import models trained in NeMo.
For more information, refer to the NeMo project page.
NeMo2Riva Export for NeMo¶
Models trained in NVIDIA NeMo have the format .nemo. To use these models in Riva, users need to convert the model
checkpoints to .riva format for building and deploying with Riva ServiceMaker using the nemo2riva tool. The nemo2riva tool is currently packaged
and available via Riva Quickstart.
Follow the NeMo installation instructions to setup a the latest NeMo environment; version 1.1.0 or greater. From within your NeMo environment:
pip3 install nvidia-pyindex pip3 install nemo2riva-1.9.0-beta-py3-none-any.whl nemo2riva --out /NeMo/<MODEL_NAME>.riva /NeMo/<MODEL_NAME>.nemo
To export the HiFi-GAN model from NeMo to Riva format, run the following command after configuring the NeMo environment:
nemo2riva --out /NeMo/hifi.riva /NeMo/tts_hifigan.nemoFor additional information and usage, run:
nemo2riva --help
Usage:
nemo2riva [-h] [--out OUT] [--validate] [--schema SCHEMA]
[--format FORMAT] [--verbose VERBOSE] [--key KEY] source
When converting NeMo models to Riva .eff input format, passing the input .nemo as a parameter creates .riva.
If no --format is passed, the Riva-preferred format for the supplied model architecture is selected automatically.
The format is also derived from schema if the --schema argument is supplied, or if nemo2riva is able to find the schema for this NeMo model
among known models - there is a set of YAML files in the nemo2riva/validation_schemas directory, or you can add your own.
If the --key argument is passed, the model graph in the output EFF file is encrypted with that key.
- positional arguments:
source Source .nemo file
- optional arguments:
- -h, --help
Show this help message and exit
- --out OUT
Location to write resulting Riva EFF input to (default:
None)- --validate
Validate using schemas (default:
False)- --schema SCHEMA
Schema file to use for validation (default:
None)- --format FORMAT
Force specific export format:
ONNX|TS|CKPT(default:None)- --verbose VERBOSE
Verbose level for logging, numeric (default:
None)- --key KEY
Encryption key or file (default:
None)
Riva Build¶
The riva-build tool is responsible for deployment preparation. It’s only output is an
intermediate format (called a RMIR) of an end-to-end pipeline for the supported
services within Riva. This tool can take multiple different types
of models as inputs. Currently, the following pipelines are supported:
speech_recognition(for ASR)speech_synthesis(for TTS)qa(for question answering)token_classification(for token level classification, for example, Named Entity Recognition)intent_slot(for joint intent and slot classification)text_classificationpunctuation
Launch an interactive session inside the Riva ServiceMaker image.
docker run --gpus all -it --rm -v <artifact_dir>:/servicemaker-dev -v <riva_repo_dir>:/data --entrypoint="/bin/bash" nvcr.io/nvidia/riva/riva-speech:1.9.0-beta-servicemakerwhere:
<artifact_dir>is the folder or Docker volume that contains the.rivafile and other artifacts required to prepare the Riva model repository.<riva_repo_dir>is the folder or Docker volume where the Riva model repository is generated.
Run the
riva-buildcommand from within the container.riva-build <pipeline> /servicemaker-dev/<rmir_filename>:<encryption_key> /servicemaker-dev/<riva_filename>:<encryption_key> <optional_args>where:
<pipeline>must be one of the following:speech_recognitionspeech_synthesisqatoken_classificationintent_slottext_classificationpunctuation
<rmir_filename>is the name of the RMIR file that will be generated.<riva_filename>is the name of therivafile(s) to use as input.<args>are optional arguments that can be used to configure the Riva service. The following section covers the different ways the ASR, NLP, and TTS services can be configured.
<encryption_key>is optional. In the case where the.rivafile was generated without an encryption key, the input/output files can be specified with<riva_filename>instead of<riva_filename>:<encryption_key>.
By default, if a file named <rmir_filename> already exists, it will not be overwritten. To force the <rmir_filename> to be overwritten, one can use the -f or --force argument. For example, riva-build <pipeline> -f ...
Riva Deploy¶
The riva-deploy tool takes as input one or more Riva Model Intermediate
Representation (RMIR) files and a target model repository directory. It is
responsible for performing the following functions:
Function 1: Adds the NVIDIA Triton™ Inference Server custom backends for pre- and post-processing specifically for the given model.
Function 2: Generates the NVIDIA TensorRT™ engine for the input model.
Function 3: Generates the Triton Inference Server configuration files for each of the modules (pre-, post- processing and the model).
Function 4: Creates an ensemble configuration specifying the pipeline for the execution and finally writes all those assets to the output model repository directory.
The Riva model repository can be generated from the Riva .rmir file(s) with the following command:
riva-deploy /servicemaker-dev/<rmir_filename>:<encryption_key> /data/models
By default, if the destination folder (/data/models/ in the example above) already exists, it will not be overwritten. To force the destination folder to be overwritten, one can use the -f or --force parameter. For example, riva-deploy -f ...