How to fine-tune a Riva ASR Acoustic Model (Citrinet) with TAO Toolkit
Contents
How to fine-tune a Riva ASR Acoustic Model (Citrinet) with TAO Toolkit#
This tutorial walks you through how to fine-tune a Riva ASR acoustic model (Citrinet) with TAO Toolkit.
NVIDIA Riva Overview#
NVIDIA Riva is a GPU-accelerated SDK for building speech AI applications that are customized for your use case and deliver real-time performance.
Riva offers a rich set of speech and natural language understanding services such as:
Automated speech recognition (ASR)
Text-to-Speech synthesis (TTS)
A collection of natural language processing (NLP) services, such as named entity recognition (NER), punctuation, and intent classification.
In this tutorial, we will fine-tune a Riva ASR acoustic model (Citrinet) with TAO Toolkit.
To understand the basics of Riva ASR APIs, refer to Getting started with Riva ASR in Python.
For more information about Riva, refer to the Riva developer documentation.
Train Adapt Optimize (TAO) Toolkit#
Train Adapt Optimize (TAO) Toolkit is a Python-based AI toolkit for taking purpose-built pre-trained AI models and customizing them with your own data. Developers, researchers, and software partners building intelligent vision AI applications and services, can bring their own data to fine-tune pre-trained models instead of going through the hassle of training the models from scratch.
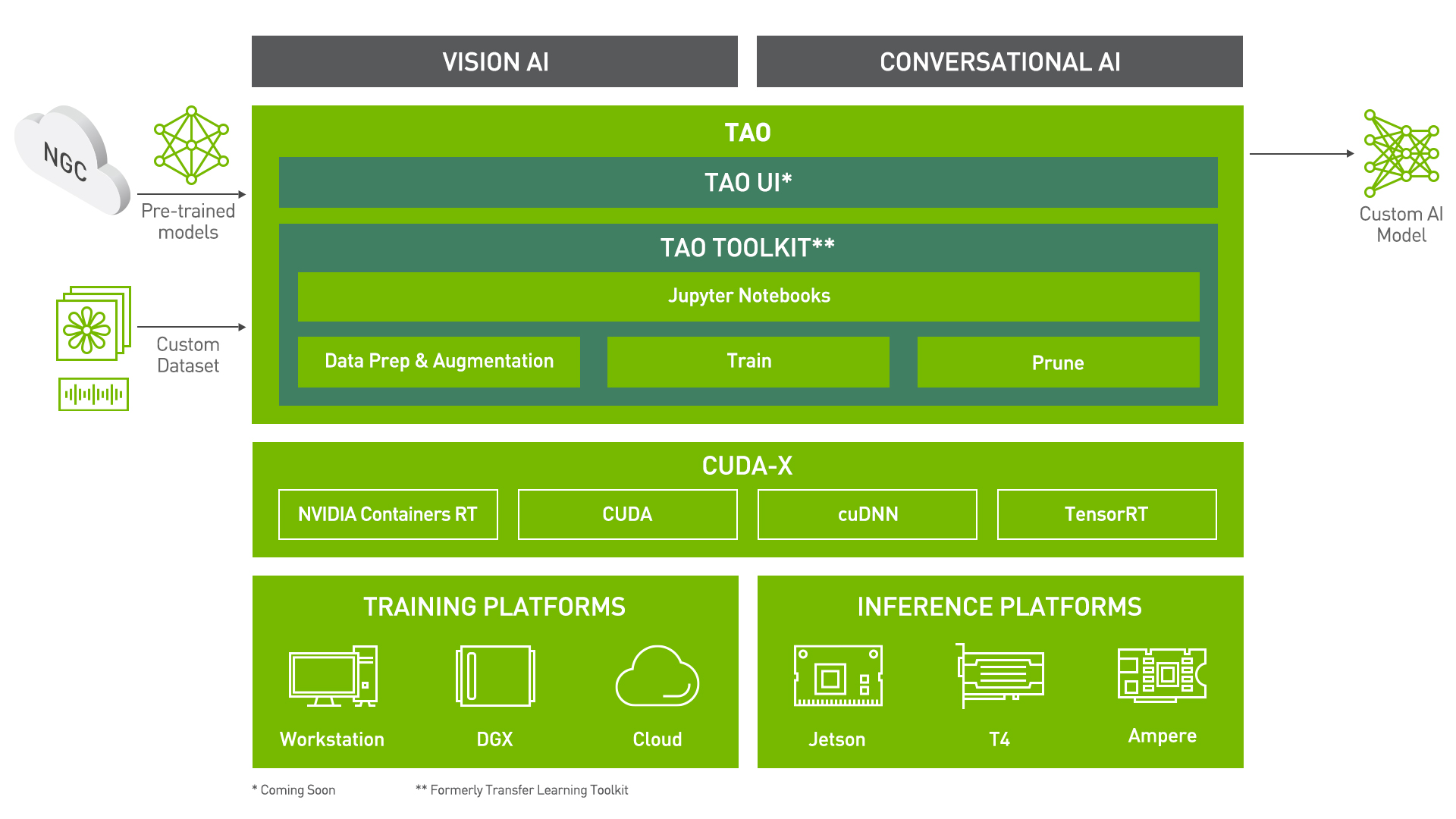
Transfer learning extracts learned features from an existing neural network into a new one. Transfer learning is often used when creating a large training dataset is not feasible. The goal of this toolkit is to reduce that 80 hour workload to an 8 hour workload, which can enable data scientists to have considerably more train-test iterations in the same time frame.
Let’s see this in action with a use case for the ASR acoustic model.
Automatic Speech Recognition (ASR)#
Automatic Speech Recognition (ASR) is often the first step in building a conversational AI model. An ASR model converts audible speech into text. The main metric for these models is to reduce Word Error Rate (WER) while transcribing the text. Simply put, the goal is to take an audio file and transcribe it.
In this tutorial, we are going to discuss the Citrinet model, which is an end-to-end ASR model that takes in audio and produces text.
Citrinet is a descendent of QuartzNet that features the squeeze-and-excitation (SE) block and sub-word tokenization and has a better accuracy/performance than QuartzNet.

ASR using TAO#
Installing and setting up TAO#
Install TAO inside a Python virtual environment. We recommend performing this step first and then launching the tutorial from the virtual environment.
In addition to installing the TAO Python package, ensure you meet the following software requirements:
python3.6.9docker-ce> 19.03.5docker-API1.40nvidia-container-toolkit> 1.3.0-1nvidia-container-runtime> 3.4.0-1nvidia-docker2> 2.5.0-1nvidia-driver>= 455.23
Installing TAO is a simple pip install.
! pip install nvidia-pyindex
! pip install nvidia-tao
After installing TAO, the next step is to setup the mounts for TAO. The TAO launcher uses Docker containers under the hood, and for our data and results directory to be visible to Docker, they need to be mapped. The launcher can be configured using the config file ~/.tao_mounts.json. Apart from the mounts, you can also configure additional options like the environment variables and the amount of shared memory available to the TAO launcher.
IMPORTANT NOTE: The following code creates a sample ~/.tao_mounts.json file. Here, we can map directories in which we save the data, specs, results, and cache. You should configure it for your specific use case so these directories are correctly visible to the Docker container.
# please define these paths on your local host machine
%env HOST_DATA_DIR=/path/to/your/host/data
%env HOST_SPECS_DIR=/path/to/your/host/specs
%env HOST_RESULTS_DIR=/path/to/your/host/results
! mkdir -p $HOST_DATA_DIR
! mkdir -p $HOST_SPECS_DIR
! mkdir -p $HOST_RESULTS_DIR
# Mapping up the local directories to the TAO docker.
import json
import os
mounts_file = os.path.expanduser("~/.tao_mounts.json")
tlt_configs = {
"Mounts":[
{
"source": os.environ["HOST_DATA_DIR"],
"destination": "/data"
},
{
"source": os.environ["HOST_SPECS_DIR"],
"destination": "/specs"
},
{
"source": os.environ["HOST_RESULTS_DIR"],
"destination": "/results"
},
{
"source": os.path.expanduser("~/.cache"),
"destination": "/root/.cache"
}
],
"DockerOptions": {
"shm_size": "16G",
"ulimits": {
"memlock": -1,
"stack": 67108864
}
}
}
# Writing the mounts file.
with open(mounts_file, "w") as mfile:
json.dump(tlt_configs, mfile, indent=4)
!cat ~/.tao_mounts.json
You can check the Docker image versions and the tasks that it performs. You can also check by issuing tao --help or:
! tao info --verbose
Set Relevant Paths#
# NOTE: The following paths are set from the perspective of the TAO Docker.
# The data is saved here:
DATA_DIR = "/data"
SPECS_DIR = "/specs"
RESULTS_DIR = "/results"
# Set your encryption key and use the same key for all commands.
KEY = 'tlt_encode'
The command structure for the TAO interface can be broken down as follows: tao <task name> <subcommand>
Let’s see this in further detail.
Downloading Specs#
TAO’s conversational AI toolkit works off of spec files which make it easy to edit hyperparameters on the fly. We can proceed to downloading the spec files. You may choose to modify/rewrite these specs or even individually override them through the launcher. You can download the default spec files by using the download_specs command.
The -o argument indicates the folder where the default specification files will be downloaded. The -r argument instructs the script on where to save the logs. Ensure the -o points to an empty folder.
# delete the specs directory if it is already there to avoid errors
! tao speech_to_text_citrinet download_specs \
-r $RESULTS_DIR/speech_to_text_citrinet \
-o $SPECS_DIR/speech_to_text_citrinet
Download Data#
In this tutorial we will use the popular AN4 dataset. Let’s download it.
! wget https://dldata-public.s3.us-east-2.amazonaws.com/an4_sphere.tar.gz # for the original source, please visit http://www.speech.cs.cmu.edu/databases/an4/an4_sphere.tar.gz
After downloading, untar the dataset and move it to the correct directory.
! tar -xvf an4_sphere.tar.gz
! mv an4 $HOST_DATA_DIR
Pre-Processing#
This step converts the .mp3 files into .wav files and splits the data into training and testing sets. It also generates a “meta-data” file to be consumed by the data-loader for training and testing.
! tao speech_to_text_citrinet dataset_convert \
-e $SPECS_DIR/speech_to_text_citrinet/dataset_convert_an4.yaml \
-r $RESULTS_DIR/citrinet/dataset_convert \
source_data_dir=$DATA_DIR/an4 \
target_data_dir=$DATA_DIR/an4_converted
Let’s listen to a sample audio file.
# change path of the file here
import os
import IPython.display as ipd
path = os.environ["HOST_DATA_DIR"] + '/an4_converted/wavs/an268-mbmg-b.wav'
ipd.Audio(path)
Training commands for Citrinet is similar to those of QuartzNet.
Training#
Create Tokenizer#
Before we can do the actual training, we need to pre-process the text. This step is called subword tokenization that creates a subword vocabulary for the text. This is different from Jasper/QuartzNet because only single characters are regarded as elements in the vocabulary in their cases, while in Citrinet the subword can be one or multiple characters. We can use the create_tokenizer command to create the tokenizer that generates the subword vocabulary for us for use in training.
!tao speech_to_text_citrinet create_tokenizer \
-e $SPECS_DIR/speech_to_text_citrinet/create_tokenizer.yaml \
-r $RESULTS_DIR/citrinet/create_tokenizer \
manifests=$DATA_DIR/an4_converted/train_manifest.json \
output_root=$DATA_DIR/an4 \
vocab_size=32
The TAO interface enables you to configure the training parameters from the command-line interface.
The process of opening the training script, finding the parameters of interest (which might be spread across multiple files), and making the changes needed, is being replaced by a simple command-line interface.
For example, if the number of epochs are needed to be modified along with a change in the learning rate, you can add trainer.max_epochs=10 and optim.lr=0.02 and train the model. Sample commands are given below.
A list of some of the customizable parameters along with their default values is as follows:
trainer:
- gpus: 1
- num_nodes: 1
- max_epochs: 5
- max_steps: null
- checkpoint_callback: false
training_ds:
- sample_rate: 16000
- batch_size: 32
- trim_silence: true
- max_duration: 16.7
- shuffle: true
- is_tarred: false
- tarred_audio_filepaths: null
validation_ds:
- sample_rate: 16000
- batch_size: 32
- shuffle: false
- name: adam
- lr: 0.1
- betas: [0.9, 0.999]
- weight_decay: 0.0001
The following steps may take a considerable amount of time depending on the GPU being used. For the best experience, we recommend using an A100 GPU.
For training an ASR Citrinet model in TAO, we use the tao speech_to_text_citrinet train command with the following arguments:
- `-e`: Path to the spec file
- `-g`: Number of GPUs to use
- `-r`: Path to the results folder
- `-m`: Path to the model
- `-k`: User specified encryption key to use while saving/loading the model
- Any overrides to the spec file. For example, `trainer.max_epochs`.
Training Citrinet#
!tao speech_to_text_citrinet train \
-e $SPECS_DIR/speech_to_text_citrinet/train_citrinet_bpe.yaml \
-g 1 \
-k $KEY \
-r $RESULTS_DIR/citrinet/train \
training_ds.manifest_filepath=$DATA_DIR/an4_converted/train_manifest.json \
validation_ds.manifest_filepath=$DATA_DIR/an4_converted/test_manifest.json \
trainer.max_epochs=1 \
training_ds.num_workers=4 \
validation_ds.num_workers=4 \
model.tokenizer.dir=$DATA_DIR/an4/tokenizer_spe_unigram_v32
ASR evaluation#
Now that we have a model trained, we need to check how well it performs.
!tao speech_to_text_citrinet evaluate \
-e $SPECS_DIR/speech_to_text_citrinet/evaluate.yaml \
-g 1 \
-k $KEY \
-m $RESULTS_DIR/citrinet/train/checkpoints/trained-model.tlt \
-r $RESULTS_DIR/citrinet/evaluate \
test_ds.manifest_filepath=$DATA_DIR/an4_converted/test_manifest.json
ASR finetuning#
After the model is trained, evaluated, and there is a need for fine-tuning, the following command can be used to fine-tune the ASR model. This step can also be used for transfer learning by making changes in the train.json and dev.json files to add new data.
The list for customizations is the same as the training parameters with the exception for parameters which affect the model architecture. Also, instead of training_ds we have finetuning_ds.
Note: If you want to proceed with a trained dataset for better inference results, you can find a .nemo model here.
Simply re-name the .nemo file to .tlt and pass it through the fine-tune pipeline.
Note: The fine-tune spec files contain specifics to fine-tune the English model we just trained to Russian. If you want to proceed with English, ensure the changes are in the spec file finetune.yaml which you can find in the SPEC_DIR folder you mapped. Ensure to delete older fine-tuning checkpoints if you choose to change the language after fine-tuning it as-is.
!tao speech_to_text_citrinet finetune \
-e $SPECS_DIR/speech_to_text_citrinet/finetune.yaml \
-g 1 \
-k $KEY \
-m $RESULTS_DIR/citrinet/train/checkpoints/trained-model.tlt \
-r $RESULTS_DIR/citrinet/finetune \
finetuning_ds.manifest_filepath=$DATA_DIR/an4_converted/train_manifest.json \
validation_ds.manifest_filepath=$DATA_DIR/an4_converted/test_manifest.json \
trainer.max_epochs=1 \
finetuning_ds.num_workers=20 \
validation_ds.num_workers=20 \
trainer.gpus=1 \
tokenizer.dir=$DATA_DIR/an4/tokenizer_spe_unigram_v32
ASR model export#
With TAO, you can also export your model in a format that can deployed using NVIDIA Riva; a highly performant application framework for multi-modal conversational AI services using GPUs. The same command for exporting to ONNX can be used here. The only small variation is the configuration for export_format in the spec file.
Export to Riva#
!tao speech_to_text_citrinet export \
-e $SPECS_DIR/speech_to_text_citrinet/export.yaml \
-g 1 \
-k $KEY \
-m $RESULTS_DIR/citrinet/train/checkpoints/trained-model.tlt \
-r $RESULTS_DIR/citrinet/riva \
export_format=RIVA \
export_to=asr-model.riva
Export to ONNX (Note: Export to ONNX is not needed for Riva)#
!tao speech_to_text_citrinet export \
-e $SPECS_DIR/speech_to_text_citrinet/export.yaml \
-g 1 \
-k $KEY \
-m $RESULTS_DIR/citrinet/train/checkpoints/trained-model.tlt \
-r $RESULTS_DIR/citrinet/export \
export_format=ONNX
ASR Inference using TLT checkpoint#
ASR Inference with TAO Toolkit#
In this section, we are going to run inference on the tlt checkpoint with TAO Toolkit. For real-time inference and best latency, we need to deploy this model on Riva - Refer to How to deploy custom Acoustic Model (Citrinet) trained with TAO Toolkit on Riva tutorial. You might have to work with the infer.yaml file to select the files you want for inference.
!tao speech_to_text_citrinet infer \
-e $SPECS_DIR/speech_to_text_citrinet/infer.yaml \
-g 1 \
-k $KEY \
-m $RESULTS_DIR/citrinet/train/checkpoints/trained-model.tlt \
-r $RESULTS_DIR/citrinet/infer \
file_paths=[$DATA_DIR/an4_converted/wavs/an268-mbmg-b.wav]
ASR Inference using ONNX#
TAO provides the capability to use the exported .eonnx model for inference. The command tao speech_to_text infer_onnx is very similar to the inference command for .tlt models. Again, the inputs in the spec file used is just for demo purposes, you may choose to try out your custom input.
!tao speech_to_text_citrinet infer_onnx \
-e $SPECS_DIR/speech_to_text_citrinet/infer_onnx_citrinet.yaml \
-g 1 \
-k $KEY \
-m $RESULTS_DIR/citrinet/export/exported-model.eonnx \
-r $RESULTS_DIR/infer_onnx \
file_paths=[$DATA_DIR/an4_converted/wavs/an268-mbmg-b.wav]
What’s Next?#
You can use TAO to build custom models for your own applications, or you could deploy the custom model to NVIDIA Riva.