The Making of the Riva Mandarin ASR Service
Contents
The Making of the Riva Mandarin ASR Service#
This tutorial walks you through the end-to-end process that NVIDIA engineers and data scientists employed to develop the Riva Mandarin Automatic Speech Recognition (ASR) service, from raw transcribed audio data to a ready-to-serve Riva ASR service.
Overview#
The below diagram provides a high-level overview of the end-to-end engineering workflow required to realize the Riva Mandarin ASR service. The following diagram provides a high-level overview of the end-to-end engineering workflow required to realize the Riva Mandarin ASR service.
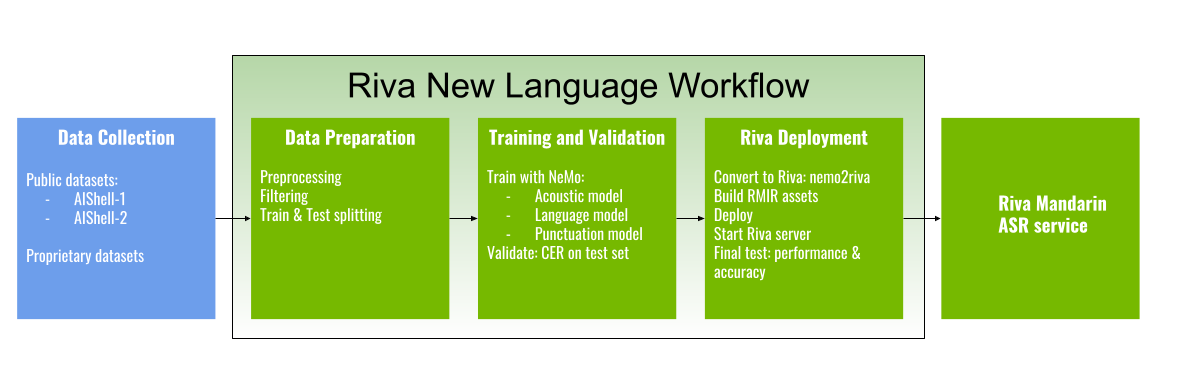
Beyond the data collection phase, the new language workflow for Riva is divided into three major stages:
Data preparation
Training and validation
Riva deployment
In the next sections, we look deeper into each of these stages.
1. Data collection#
When adapting Riva to a new language, a large amount of high-quality transcribed audio data is critical for training high-quality acoustic models.
There are several Mandarin speech corpus that we obtained from open-source and vendors:
Open-sourced corpus:
AIShell-1 178 hours, for conducting the speech recognition research and building speech recognition systems for Mandarin.
AIShell-2 1000 hours clean read-speech data from iOS.
Proprietary datasets:
4 speech datasets: 1018 hours.
3 speech datasets: 510 hours.
In total, we have 2707 hours (320GB) of Mandarin speech audio data.
2. Data preparation#
The data preparation phase carries out a series of preparation steps required to convert the diverse raw audio datasets into a uniform format that can be efficiently digested by NVIDIA NeMo.
2.1. Data preprocessing#
Audio data: Audio data acquired from various sources are inherently heterogeneous (file format, sample rate, bit depth, number of audio channels…). Therefore, as a preprocessing step, we must build a separate data ingestion pipeline for each source and convert the audio data into a common format with the following characteristics:
Wav format
Bit depth: 16 bits
Sample rate of 16 Khz
Single audio channel
Text data:
Dataset ingestion scripts are used to convert the various datasets into the standard manifest format expected by NeMo. For more information, refer to the NeMo data processing scripts.
Text normalization converts text from written form into its verbalized form. It is used as a preprocessing step for preprocessing ASR training transcripts.
2.2. Data cleaning/filtering#
Perform this step to filter out some outlying samples in the datasets.
Samples that are too long, too short or empty are filtered out.
Samples with high CER (character error rate). Use Nemo data explorer to find the proper CER for each dataset. Then, filter out samples that have a very high CER.
Keep samples which have durations in [0.1, 20] seconds.
2.3. Train and Test splitting#
This step is a staple of any deep learning and machine learning development pipeline, to ensure that the model is learning to generalize without overfitting the training data. For the dev set, we use 1% of the training datasets for validation. For the test set, we additionally curated data that isn’t from the same source as the training datasets, such as YouTube.
3. Training and validation#
The models in an ASR pipeline include:
An acoustic model, that maps raw audio input to probabilities over text tokens at each time step. This matrix of probabilities is fed into a decoder that converts the probabilities into a sequence of text tokens.
A language model, that is optionally used in the decoding phase of the acoustic model output.
A punctuation model, that formats the raw transcript, augmenting with punctuation.
3.1. Acoustic model#
The acoustic model is by far the most important part of an ASR service. These are the most resource intensive models, requiring a large amount of data to train on powerful GPU servers or cluster. They also have the largest impact on the overall ASR quality.
Model architecture: Citrinet is a new end-to-end convolutional Connectionist Temporal Classification (CTC) based ASR model. Citrinet is a deep residual neural model which uses 1D time-channel separable convolutions combined with sub-word encoding and squeeze-and-excitation. The resulting architecture significantly reduces the gap between non-autoregressive and sequence-to-sequence and transducer models.
We experimented with the Citrinet-1024 model for the Mandarin ASR pipeline. The final model chosen for deployment of the Riva Mandarin ASR service (ver. 22.04) was fine-tuned from STT Zh Citrinet 1024 Gamma 0.25.
Training script: We leverage NeMo training scripts.
Hyper-parameter setting: For model training, we used: 500 epochs, batch size 32, learning rate 0.005, beta parameters [0.8, 0.25], and weight decay 0.001.
Training environment: We trained the Citrinet model on a GPU cluster comprising of 64 GPUs, each taking 182 hours.
3.2. Language model#
The language model, combined with beam search in the decoding phase, can further improve the quality of the ASR pipeline. In our experiments, we typically observe WER reduction by using a simple n-gram model.
The language models supported by Riva are an n-gram model, which can be trained with the KenLM toolkit. Refer to the Riva documentation for information on how to train and deploy a custom language model.
Training data: We create a training set by combining all the transcript text in our ASR set, then normalize them.
3.3. Punctuation model#
The punctuation model consists of the pre-trained Bidirectional Encoder Representations from Transformers (BERT).
The model was trained with Google’s BERT base Chinese pretrained checkpoint on the ASR transcription and a subset of data from the Tatoeba website’s Chinese sentences.
We employed a BERT-base model for the task and leverage the NeMo script for the training part.
For more information, refer to the NeMo tutorial on the topic.
4. Riva deployment#
Now that all the models are trained, let’s deploy the Riva service.
Bring your own Mandarin models#
Given the final .nemo models that you have trained upon completing the previous training step, here are the steps that need to be done to deploy on Riva:
Download the Riva Quick Start scripts (see instructions). The scripts provide
nemo2rivaconversion tool, and scripts (riva_init.sh,riva_start.shandriva_start_client.sh) to download theservicemaker,riva-speech-serverandriva-speech-clientDocker images.Build the
.rivaassets: usingnemo2rivacommand in theservicemakercontainer.Build the
RMIRassets: use theriva-buildtool in theservicemakercontainer. See examples of build commands for different models and for offline and online ASR pipelines in the Riva build documentation page.Deploy the model in
.rmirformat withriva-deploy.Start the server with
riva-start.sh.
After the server successfully starts up, you can query the service, measuring accuracy, latency and throughput.
Riva pretrained Mandarin models on NGC#
You can use the NGC pretrained Mandarin models as starting points for your development.
Acoustic models:
STT Zh Citrinet 1024 Gamma 0.25 Citrinet-1024 model with kernel scaling factor (gamma) of 25%, which has been trained on the open source Aishell-2 Mandarin Chinese corpus.
RIVA Citrinet ASR Mandarin Citrinet-1024 model which has been trained on the ASR dataset with over 2600 hours of Mandarin (zh-CN) speech.
Language model:
Riva ASR Mandarin LM These models are simple 4-gram language models trained with Kneser-Ney smoothing using KenLM.
Conclusion#
In this tutorial, we have guided you through the steps to realize the Riva Mandarin ASR service, from raw data to a ready-to-use service.
You can follow the same process to setup a new Mandarin ASR service using your own data, or use the resources in this notebook to fine-tune parts of the pipeline with your own model and data.