How to pretrain a Riva ASR Language Modeling (n-gram) with TAO Toolkit
Contents
How to pretrain a Riva ASR Language Modeling (n-gram) with TAO Toolkit#
This tutorial walks you through the pretraining of Riva ASR language modeling (n-gram) with Train Adapt Optimize (TAO) Toolkit.
NVIDIA Riva Overview#
NVIDIA Riva is a GPU-accelerated SDK for building speech AI applications that are customized for your use case and deliver real-time performance.
Riva offers a rich set of speech and natural language understanding services such as:
Automated speech recognition (ASR)
Text-to-Speech synthesis (TTS)
A collection of natural language processing (NLP) services, such as named entity recognition (NER), punctuation, and intent classification.
In this tutorial, we will pretrain Riva ASR language modeling (n-gram) with TAO Toolkit.
To understand the basics of Riva ASR APIs, refer to Getting started with Riva ASR in Python.
For more information about Riva, refer to the Riva developer documentation.
TAO Toolkit#
Train Adapt Optimize (TAO) Toolkit is a simple and easy-to-use Python based AI toolkit for taking purpose-built AI models and customizing them with users’ own data. Developers, researchers, and software partners building intelligent vision AI applications and services can bring their own data to fine-tune pre-trained models instead of going through the hassle of training from scratch.
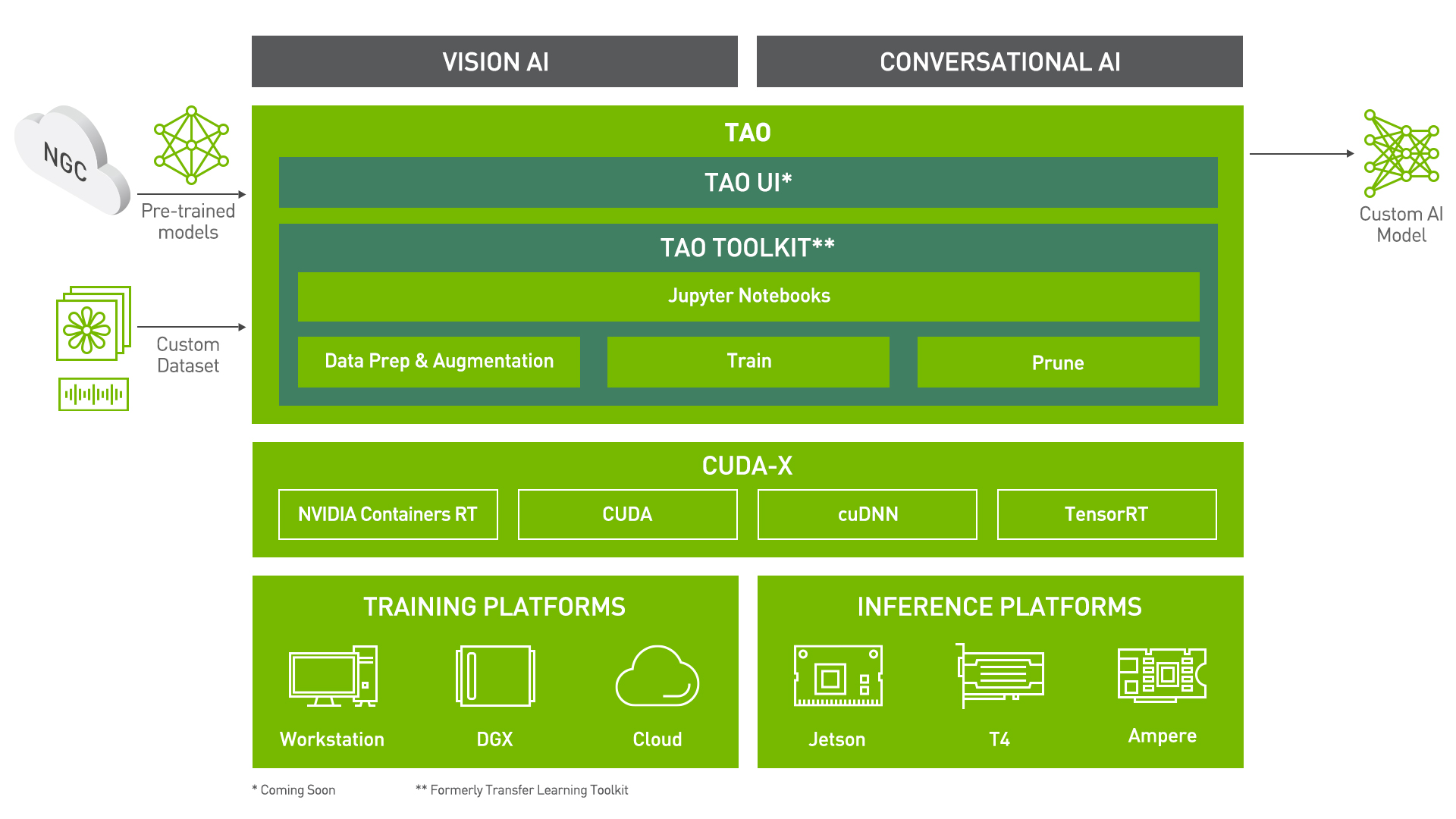
Transfer learning extracts learned features from an existing neural network into a new one. Transfer learning is often used when creating a large training dataset is not feasible. The goal of this toolkit is to reduce that 80 hour workload to an 8 hour workload, which can enable data scientists to have considerably more train-test iterations in the same time frame.
Let’s see this in action with a use case for Automatic Speech Recognition Language Modeling!
Language Modeling#
Task Description#
Language modeling returns a probability distribution over a sequence of words. Besides assigning a probability to a sequence of words, the language models also assign a probability for the likelihood of a given word (or a sequence of words) that follows a sequence of words.
The sentence: all of a sudden I notice three guys standing on the sidewalk would be scored higher than the sentence: on guys all I of notice sidewalk three a sudden standing the by the language model.
A language model trained on large corpus can significantly improve the accuracy of an ASR system as suggested in recent research.
N-gram Language Model#
There are primarily two types of language models:
N-gram language models: These models use frequency of n-grams to learn the probability distribution over words. Two benefits of N-gram language models are simplicity and scalability – with a larger
n, a model can store more context with a well-understood space–time tradeoff, enabling small experiments to scale up efficiently.Neural language models: These models use different kinds of neural networks to model the probability distribution over words, and have surpassed the N-gram language models in the ability to model language, but are generally slower to evaluate.
In this tutorial, we will show how to train, evaluate, and optionally fine-tune an N-gram language model leveraging TAO Toolkit.
Let’s Dig in: Riva Language Modeling using TAO#
Installing and setting up TAO#
Install TAO Toolkit inside a Python virtual environment. We recommend performing this step first and then launching the tutorial from the virtual environment.
It’s a simple pip install.
! pip install nvidia-pyindex
! pip install nvidia-tao
To view the Docker image versions and the tasks that TAO can perform, use the tao info command.
!tao info --verbose
In addition to installing the TAO Toolkit package, ensure you meet the following software requirements:
Python 3.6.9
docker-ce> 19.03.5docker-API1.40nvidia-container-toolkit> 1.3.0-1nvidia-container-runtime> 3.4.0-1nvidia-docker2> 2.5.0-1nvidia-driver>= 455.23
Check to see if the GPU device(s) is visible.
Preparing the dataset#
Downloading the dataset#
LibriSpeech LM Normalized dataset#
The training data is publicly available here and can be downloaded directly.
import os
# IMPORTANT NOTE: Set the path to a folder where you want your data and results to be saved.
# TODO
DATA_DOWNLOAD_DIR = "<YOUR_PATH_TO_DATA_DIR>"
assert os.path.exists(DATA_DOWNLOAD_DIR), "Provided DATA_DOWNLOAD_DIR does not exist."
# NOTE: Ensure that wget and unzip utilities are available. If not, install them.
!wget 'https://www.openslr.org/resources/11/librispeech-lm-norm.txt.gz' -P $DATA_DOWNLOAD_DIR
# Extract the data
!gzip -dk $DATA_DOWNLOAD_DIR/librispeech-lm-norm.txt.gz
LibriSpeech dev-clean dataset#
The evaluation data is publicly available here and can be downloaded directly. We provided a Python script to download and preprocess the dataset for you.
"""
Scripts to download and preprocess LibriSpeech dev-clean
"""
from multiprocessing import Pool
import numpy
LOG_STR = " To regenerate this file, please, remove it."
def find_transcript_files(dir):
files = []
for dirpath, _, filenames in os.walk(dir):
for filename in filenames:
if filename.endswith(".trans.txt"):
files.append(os.path.join(dirpath, filename))
return files
def transcript_to_list(file):
audio_path = os.path.dirname(file)
ret = []
with open(file, "r") as f:
for line in f:
file_id, trans = line.strip().split(" ", 1)
audio_file = os.path.abspath(os.path.join(audio_path, file_id + ".flac"))
duration = 0 # We are not using the audio
ret.append([file_id, audio_file, str(duration), trans.lower()])
return ret
if __name__ == "__main__":
name = "dev-clean"
data_path = os.path.join(DATA_DOWNLOAD_DIR, "eval_data")
text_path = os.path.join(DATA_DOWNLOAD_DIR, "text")
lists_path = os.path.join(DATA_DOWNLOAD_DIR, "lists")
os.makedirs(data_path, exist_ok=True)
os.makedirs(text_path, exist_ok=True)
os.makedirs(lists_path, exist_ok=True)
data_http = "http://www.openslr.org/resources/12/"
# Download the audio data
print("Downloading the evaluation data.", flush=True)
if not os.path.exists(os.path.join(data_path, "LibriSpeech", name)):
print("Downloading and unpacking {}...".format(name))
cmd = """wget -c {http}{name}.tar.gz -P {path};
yes n 2>/dev/null | gunzip {path}/{name}.tar.gz;
tar -C {path} -xf {path}/{name}.tar"""
os.system(cmd.format(path=data_path, http=data_http, name=name))
else:
log_str = "{} part of data exists, skip its downloading and unpacking"
print(log_str.format(name) + LOG_STR, flush=True)
# Prepare the audio data
print("Converting data into necessary format.", flush=True)
word_dict = {}
word_dict[name] = set()
src = os.path.join(data_path, "LibriSpeech", name)
assert os.path.exists(src), "Unable to find the directory - '{src}'".format(
src=src
)
dst_list = os.path.join(lists_path, name + ".lst")
if os.path.exists(dst_list):
print(
"Path {} exists, skip its generation.".format(dst_list) + LOG_STR,
flush=True,
)
print("Analyzing {src}...".format(src=src), flush=True)
transcript_files = find_transcript_files(src)
transcript_files.sort()
print("Writing to {dst}...".format(dst=dst_list), flush=True)
with Pool(processes=8) as p:
samples = list(p.imap(transcript_to_list, transcript_files))
with open(dst_list, "w") as fout:
for sp in samples:
for s in sp:
word_dict[name].update(s[-1].split(" "))
s[0] = name + "-" + s[0]
fout.write(" ".join(s) + "\n")
current_path = os.path.join(text_path, name + ".txt")
if not os.path.exists(current_path):
with open(os.path.join(lists_path, name + ".lst"), "r") as flist, open(
os.path.join(text_path, name + ".txt"), "w"
) as fout:
for line in flist:
fout.write(" ".join(line.strip().split(" ")[3:]) + "\n")
else:
print(
"Path {} exists, skip its generation.".format(current_path) + LOG_STR,
flush=True,
)
print("Done!", flush=True)
For the sake of reducing the time this demo takes, we reduce the number of lines of the training dataset. Feel free to modify the number of used lines.
# Use a random 10,000 lines for training
!shuf -n 10000 $DATA_DOWNLOAD_DIR/librispeech-lm-norm.txt > $DATA_DOWNLOAD_DIR/reduced_training.txt
TAO Toolkit workflow#
The rest of the tutorial demonstrates what a sample TAO Toolkit workflow looks like.
Setting TAO Toolkit Mounts#
Now that our dataset has been downloaded, an important step in using TAO Toolkit is to setup the directory mounts. The TAO Toolkit launcher uses Docker containers under the hood, and for our data and results directory to be visible to Docker, they need to be mapped. The launcher can be configured using the config file ~/.tao_mounts.json. Apart from the mounts, you can also configure additional options like the environment variables and the amount of shared memory available to the TAO Toolkit launcher.
IMPORTANT NOTE: The following code creates a sample ~/.tao_mounts.json file. Here, we can map directories in which we save the data, specs, results, and cache. You should configure it for your specific use case. These directories are correctly visible to the Docker container. Ensure that the source directories exist on your machine.
%%bash
tee ~/.tao_mounts.json <<'EOF'
{
"Mounts":[
{
"source": "<YOUR_PATH_TO_DATA_DIR>",
"destination": "/data"
},
{
"source": "<YOUR_PATH_TO_SPECS_DIR>",
"destination": "/specs"
},
{
"source": "<YOUR_PATH_TO_RESULTS_DIR>",
"destination": "/results"
},
{
"source": "<YOUR_PATH_TO_CACHE_DIR eg. /home/user/.cache>",
"destination": "/root/.cache"
}
]
}
EOF
# Make sure the source directories exist, if not, create them
# ! mkdir <YOUR_PATH_TO_SPECS_DIR>
# ! mkdir <YOUR_PATH_TO_RESULTS_DIR>
# ! mkdir <YOUR_PATH_TO_CACHE_DIR>
Users with basic knowledge of deep learning can get started building their own custom models using a simple specification file. It’s essentially just one command each to run data preprocessing, training, fine-tuning, evaluation, inference, and export. All configurations happen through .yaml spec files.
Configuration/Specification Files#
The essence of all commands in TAO Toolkit lies within .yaml spec files. There are sample spec files already available for you to use directly or as a reference to create your own. Through these spec files, you can tune many knobs like the model, dataset, hyperparameters, etc. Each command (like train, fine-tune, evaluate, etc.) should have a dedicated spec file with configurations pertinent to it.
Here is an example of the training spec file:
model:
intermediate: True
order: 2
pruning:
- 0
training_ds:
is_tarred: false
is_file: true
data_file: ???
vocab_file: ""
encryption_key: "tlt_encode"
...
Set Relevant Paths#
Please set these paths according to your environment.
# NOTE: The following paths are set from the perspective of the TAO Toolkit Docker.
# The data is saved here
DATA_DIR='/data'
# The configuration files are stored here
SPECS_DIR='/specs/n_gram'
# The results are saved at this path
RESULTS_DIR='/results/n_gram'
# Set your encryption key, and use the same key for all commands
KEY='tlt_encode'
Downloading Specs#
Let’s download the spec files. You may choose to modify/rewrite these specs, or even individually override them through the launcher. You can download the default spec files by using the download_specs command.
The -o argument indicates the folder where the default specification files will be downloaded. The -r argument instructs the script on where to save the logs. Ensure the -o argument points to an empty folder.
!tao n_gram download_specs \
-r $RESULTS_DIR \
-o $SPECS_DIR
Data Convert#
In preparation for training/fine-tuning, we need to preprocess the dataset. The tao n_gram dataset_convert command can be used in conjunction with the appropriate configuration in the spec file. Here is the sample dataset_convert.yaml spec file we use:
# Dataset. Available options: [assistant]
dataset_name: assistant
# Extension of the files containing in dataset
extension: ???
# Path to the folder containing the dataset source files.
source_data_dir: ???
# Path to the output folder.
target_data_file: ???
Take a look at the .yaml spec files we provide.
As we show below, you can override the source_data_dir and target_data_dir options with the appropriate paths.
# Preprocess training data (LibriSpeech LM Normalized)
!tao n_gram dataset_convert \
-e $SPECS_DIR/dataset_convert.yaml \
-r $RESULTS_DIR/dataset_convert \
extension=*.txt \
source_data_dir=$DATA_DIR/reduced_training.txt \
target_data_file=$DATA_DIR/preprocessed.txt
# Preprocess evaluation data (LibriSpeech dev-clean)
!tao n_gram dataset_convert \
-e $SPECS_DIR/dataset_convert.yaml \
-r $RESULTS_DIR/dataset_convert \
extension=*.txt \
source_data_dir=$DATA_DIR/text/dev-clean.txt \
target_data_file=$DATA_DIR/preprocessed_dev_clean.txt
The command preprocess the training and evaluation dataset using basic text preprocessings including converting lowercase, normalization, removing punctuation, and write the results into files named preprocessed.txt and preprocessed_dev_clean.txt for training and evaluation correspondingly. In both preprocessed.txt and preprocessed_dev_clean.txt files, each preprocessed sentence corresponds to a new line.
Training / Fine-tuning#
Training a model using TAO Toolkit is as simple as configuring your spec file and running the train command. The following code uses the train.yaml spec file available to you as reference. The spec file configurations can easily be overridden using the tao-launcher CLI. For example, below we override model.order, model.pruning and training_ds.data_file configurations to suit our needs.
For training an N-gram language model in TAO Toolkit, we use the tao n_gram train command with the following arguments:
-e: Path to the spec file-k: User specified encryption key to use while saving/loading the model-r: Path to a folder where the outputs should be written. Ensure this is mapped in thetlt_mounts.jsonfile.Any overrides to the spec file. For example,
model.order.
For more information about these arguments, refer to the TAO Toolkit Getting Started Guide.
Note: All file paths correspond to the destination mounted directory that is visible in the TAO Toolkit docker container used in backend.
!tao n_gram train \
-e $SPECS_DIR/train.yaml \
-r $RESULTS_DIR/train \
training_ds.data_file=$DATA_DIR/preprocessed.txt \
model.order=3 \
model.pruning=[0,0,1]
The train command produces three files called train_n_gram.arpa, train_n_gram.vocab and train_n_gram.kenlm_intermediate saved at $RESULTS_DIR/train/checkpoints.
Evaluation#
The evaluation spec .yaml is as simple as:
# Name of the `.arpa` or `.binary` file where the trained model will be restored from.
restore_from: ???
test_ds:
data_file: ???
!tao n_gram evaluate \
-e $SPECS_DIR/evaluate.yaml \
-r $RESULTS_DIR/evaluate \
restore_from=$RESULTS_DIR/train/checkpoints/train_n_gram.arpa \
test_ds.data_file=$DATA_DIR/preprocessed_dev_clean.txt
The output of the evaluation gives us the perplexity of the N-gram language model on the evaluation (LibriSpeech dev-clean) dataset.
Inference#
Inference using a trained .arpa or .binary model uses the tao n_gram infer command.
The infer.yaml is also very simple, and we can directly give inputs for the model to run inference.
# "Simulate" user input:
input_batch:
- 'set alarm for seven thirty am'
- 'lower volume by fifty percent'
- 'what is my schedule for tomorrow'
restore_from: ???
Try out your own inputs as an exercise.
!tao n_gram infer \
-e $SPECS_DIR/infer.yaml \
-r $RESULTS_DIR/infer \
restore_from=$RESULTS_DIR/train/checkpoints/train_n_gram.arpa
This command returns the log likelihood, perplexity, and all n-grams for each of the input sequences that users provided.
Export to Riva#
With TAO Toolkit, you can also export your model in a format that can deployed using NVIDIA Riva, a highly performant application framework for multi-modal conversational AI services using GPUs. The export command will convert the trained language model from .arpa to .binary with the option of quantizing the model binary. We will set export_format in the spec file to RIVA to create a .riva file which will contain the language model binary and its corresponding vocabulary.
!tao n_gram export \
-e $SPECS_DIR/export.yaml \
-r $RESULTS_DIR/export \
export_format=RIVA \
export_to=exported-model.riva \
restore_from=$RESULTS_DIR/train/checkpoints/train_n_gram.arpa \
binary_type=trie \
binary_q_bits=8 \
binary_b_bits=7 \
binary_a_bits=256
The model is exported as exported-model.riva which is in a format suited for deployment in Riva.
What’s Next?#
You could use TAO Toolkit to build custom models for your own applications, or you could deploy the custom model to NVIDIA Riva.