Architecture Overview#
TensorRT for RTX (TensorRT-RTX) is a specialization of NVIDIA TensorRT for the RTX product line. Like TensorRT, it contains a deep learning inference optimizer and runtime for high-performance inference. Unlike TensorRT, TensorRT-RTX performs Just-In-Time (JIT) compilation on the end-user device, which simplifies deployment across a diverse set of RTX GPUs.
Performance#
TensorRT-RTX delivers significant throughput improvements over default execution providers. The following chart compares throughput across a range of models on Windows ML with TensorRT-RTX compared to default DirectML, measured on an NVIDIA RTX 5090 GPU.
How It Works#
NVIDIA RTX GeForce GPUs have an install base of more than 100 million. If you are building AI apps for desktops, laptops, or workstations on Windows or Linux, TensorRT-RTX is your library of choice. Integrate it into your apps using its native C++ or Python APIs, or use it as the default execution path through the Windows ML interface, now generally available for production use.
Two-Phase Compilation#
After you train your deep learning model in a framework of your choice, TensorRT-RTX enables you to run it with higher throughput and lower latency. Compilation proceeds in two phases:
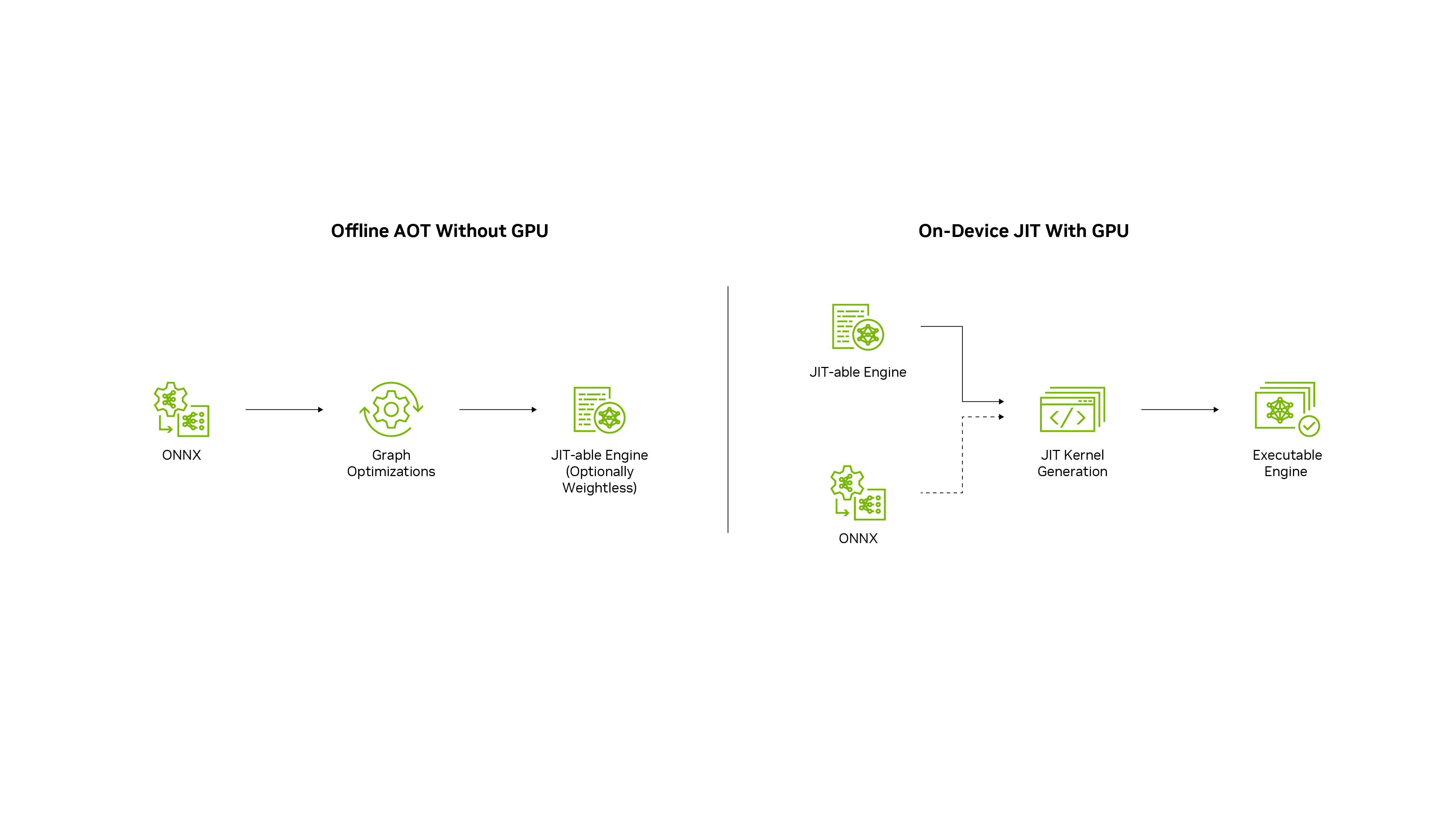
Phase 1: Ahead-of-Time (AOT) Optimization
The AOT optimizer translates the neural network into a TensorRT-RTX engine file (also known as a JIT-able engine). This step typically takes 20-30 seconds for most models, with a maximum of approximately 60 seconds for complex models. This engine is portable across multiple RTX GPU models.
Phase 2: Just-In-Time (JIT) Compilation
Run at inference time, the system JIT-compiles this engine into an executable inference plan with an optimized inference strategy for the specific GPU. This includes the concrete choice of computation kernels. This step is very fast at the time of first inference invocation (typically under 5 seconds for most models). Runtime caching can optionally speed up subsequent invocations even more.
Why This Approach Works
This two-phase approach balances portability with performance:
AOT phase: Creates a single portable engine (fast, can run on CPU)
JIT phase: Optimizes for the user’s specific GPU (happens once on the user’s machine)
Result: Simple deployment with near-optimal performance
For guidance on measuring and optimizing inference performance, refer to the Best Practices section.
Model Specification#
Models can be specified using the TensorRT-RTX C++ or Python API, or read from the ONNX neural network exchange format. Popular model training frameworks like PyTorch or TensorFlow typically offer an ONNX export option. Alternatively, the native TensorRT-RTX API defines operators for manually assembling the network structure.
ONNX (Recommended)
ONNX is a framework-agnostic option that works with models in TensorFlow, PyTorch, and more. TensorRT-RTX supports automatic conversion from ONNX files using the TensorRT-RTX API or the tensorrt_rtx executable. ONNX conversion is all-or-nothing, meaning all operations in your model must be supported by TensorRT-RTX.
Native Network Definition API
For maximum performance and customizability, you can manually construct TensorRT-RTX engines using the TensorRT-RTX network definition API. This involves building an identical network to your target model operation by operation, using only TensorRT-RTX operations. After the network is created, export the weights from your framework and load them into the TensorRT-RTX network.
Relation to Other TensorRT Ecosystem Libraries#
TensorRT-RTX optimizes CNN, Diffusion, and Speech models expressed in ONNX or native C++ APIs, for running on NVIDIA RTX GPUs. Unlike the NVIDIA TensorRT Inference library, this library does not support other NVIDIA GPU platforms like Datacenter, Edge, or Embedded.
TensorRT-RTX has a subset of APIs derived from TensorRT and shares the same namespace, so existing TensorRT applications for RTX devices can port to TensorRT-RTX by linking to the new library. For detailed porting instructions, see the Porting section. TensorRT-RTX APIs can diverge in the future.
TensorRT-RTX is the default execution provider in the Windows ML framework, which is generally available through the Microsoft Store. TensorRT-RTX is also available as an execution provider in ONNX Runtime.
TensorRT-RTX works with quantized ONNX models exported by TensorRT Model Optimizer or any other third-party quantization library. Datatype support is detailed in the Support Matrix.
TensorRT-RTX does not support native deployments of LLMs out of the box. However, when used as an execution provider with Windows ML, TensorRT-RTX optimizes inference for Ampere and later RTX GPUs. LLMs from Windows AI Foundry Local can be optimized with TensorRT-RTX execution provider. You can build LLM models specialized for ONNX Runtime GenAI and TensorRT-RTX. Further, optimize with Olive recipes like this Qwen2.5 example. On RTX Turing GPUs (20-series), support for LLMs will be enabled in future releases; on Turing GPUs, applications can use CUDA Execution Provider as the fallback path.
Note
TensorRT-RTX does not yet support framework integrations with NVIDIA TensorRT-LLM, Torch-TensorRT, TensorFlow-TensorRT, and NVIDIA Triton Inference Server.