Getting Started
Overview
Transformer Engine (TE) is a library for accelerating Transformer models on NVIDIA GPUs, providing better performance with lower memory utilization in both training and inference. It provides support for 8-bit floating point (FP8) precision on Hopper, Ada, as well as 8-bit and 4-bit floating point (NVFP4) precision on Blackwell GPUs, implements a collection of highly optimized building blocks for popular Transformer architectures, and exposes an automatic-mixed-precision-like API that can be used seamlessly with your JAX code. It also includes a framework-agnostic C++ API that can be integrated with other deep learning libraries to enable FP8 support for Transformers.
This guide shows how to start using Transformer Engine with JAX. Similar tutorial for pyTorch is available here. We recommend you to try understanding the basics of JAX first, using these resources:
Let’s build a Transformer decoder layer!
This is based upon the GPT decoder layer with causal masking, which prevents each position from attending to future positions.
Summary
We build a basic Transformer layer using regular Flax modules. This will be our baseline for later comparisons with Transformer Engine.
Let’s start with creating the transformer layer using plain FLAX Linen . Figure 1 shows the overall structure.
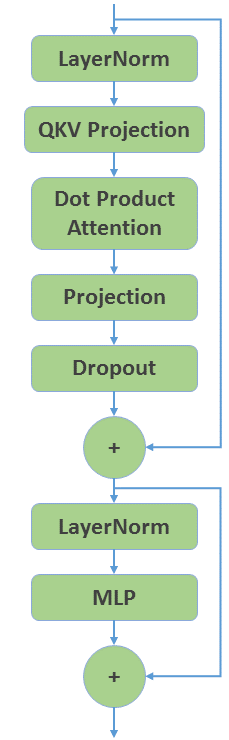
Figure 1: Structure of a GPT decoder layer.
We construct the components as follows:
LayerNorm:nn.LayerNorm(Flax)QKV Projection:nn.Dense(conceptually there are three seperateDenselayers for Q, K, and V separately, but we fuse them together into a singleDenselayer that is three times larger)DotProductAttention:nn.MuliheadDotProductAttention(Flax)Projection:nn.Dense(Flax)Dropout:nn.Dropout(Flax)MLP:FlaxMLPimplemented usingnn.Denseandnn.gelu
Over the course of this tutorial we will use a few modules and helper functions defined in quickstart_jax_utils.py. Putting it all together:
[26]:
import jax
import jax.numpy as jnp
from flax import linen as nn
import quickstart_jax_utils as utils
from typing import Optional
[27]:
class FlaxMLP(nn.Module):
"""Feed-forward network in Transformer layer
Built with plain Flax modules.
"""
hidden_size: int
ffn_hidden_size: int
@nn.compact
def __call__(self, x: jnp.ndarray) -> jnp.ndarray:
x = nn.Dense(features=self.ffn_hidden_size, use_bias=True)(x)
x = nn.gelu(x, approximate=True) # equivalent to tanh approximation
x = nn.Dense(features=self.hidden_size, use_bias=True)(x)
return x
class FlaxTransformerLayer(nn.Module):
"""Basic Transformer layer using plain Flax modules"""
hidden_size: int
ffn_hidden_size: int
num_attention_heads: int
layernorm_eps: float = 1e-5
attention_dropout: float = 0.1
def setup(self):
self.kv_channels = self.hidden_size // self.num_attention_heads
@nn.compact
def __call__(
self,
x: jnp.ndarray,
attention_mask: Optional[jnp.ndarray] = None,
deterministic: bool = False
) -> jnp.ndarray:
# Create causal mask if not provided
if attention_mask is None:
attention_mask = nn.make_causal_mask(x[..., 0], dtype=jnp.bool_)
res = x
x = nn.LayerNorm(epsilon=self.layernorm_eps)(x)
# Fused QKV projection
qkv = nn.Dense(features=3 * self.hidden_size, use_bias=True)(x)
qkv = qkv.reshape(qkv.shape[0], qkv.shape[1], self.num_attention_heads, 3 * self.kv_channels)
q, k, v = jnp.split(qkv, 3, axis=3)
# q, k, v now have shape [batch, seq_len, num_heads, kv_channels]
# which is the correct format for dot_product_attention
# Apply dot product attention
# Note: dot_product_attention expects mask to be broadcastable to
# [batch, num_heads, q_length, kv_length], but attention_mask from
# nn.make_causal_mask has shape [batch, 1, seq_len, seq_len]
# Generate dropout RNG key when needed (not deterministic and dropout_rate > 0)
dropout_rng = None
if not deterministic and self.attention_dropout > 0:
dropout_rng = self.make_rng('dropout')
x = nn.dot_product_attention(
query=q,
key=k,
value=v,
mask=attention_mask,
dropout_rng=dropout_rng,
dropout_rate=self.attention_dropout,
deterministic=deterministic,
broadcast_dropout=True,
)
# Reshape output from [batch, seq_len, num_heads, kv_channels] to [batch, seq_len, hidden_size]
x = x.reshape(x.shape[0], x.shape[1], self.hidden_size)
x = res + x
# Second residual connection
res = x
x = nn.LayerNorm(epsilon=self.layernorm_eps)(x)
# MLP
mlp = FlaxMLP(
hidden_size=self.hidden_size,
ffn_hidden_size=self.ffn_hidden_size,
)
x = mlp(x)
return x + res
Testing Performance
Now let’s test the performance of our FlaxTransformerLayer:
[28]:
# Layer configuration
hidden_size = 4096
sequence_length = 2048
batch_size = 4
ffn_hidden_size = 16384
num_attention_heads = 32
dtype = jnp.bfloat16
# Synthetic data
key, dropout_key = jax.random.split(jax.random.PRNGKey(42))
x = jax.random.normal(key, (batch_size, sequence_length, hidden_size)).astype(dtype)
dy = jax.random.normal(key, (batch_size, sequence_length, hidden_size)).astype(dtype)
[29]:
# Initialize the FlaxTransformerLayer
flax_transformer = FlaxTransformerLayer(
hidden_size=hidden_size,
ffn_hidden_size=ffn_hidden_size,
num_attention_heads=num_attention_heads,
)
# Initialize parameters
params = flax_transformer.init(key, x, attention_mask=None, deterministic=False)
print("Pure Flax FlaxTransformerLayer initialized successfully!")
print(f"Parameter shapes: {jax.tree_util.tree_map(lambda x: x.shape, params)}")
Pure Flax FlaxTransformerLayer initialized successfully!
Parameter shapes: {'params': {'Dense_0': {'bias': (12288,), 'kernel': (4096, 12288)}, 'FlaxMLP_0': {'Dense_0': {'bias': (16384,), 'kernel': (4096, 16384)}, 'Dense_1': {'bias': (4096,), 'kernel': (16384, 4096)}}, 'LayerNorm_0': {'bias': (4096,), 'scale': (4096,)}, 'LayerNorm_1': {'bias': (4096,), 'scale': (4096,)}}}
[30]:
# Example usage of forward pass
y = flax_transformer.apply(params, x, attention_mask=None, deterministic=True)
print(f"Input shape: {x.shape}")
print(f"Output shape: {y.shape}")
print(f"Output dtype: {y.dtype}")
print("Forward pass completed successfully!")
Input shape: (4, 2048, 4096)
Output shape: (4, 2048, 4096)
Output dtype: float32
Forward pass completed successfully!
[31]:
import importlib
import quickstart_jax_utils
importlib.reload(quickstart_jax_utils)
utils.speedometer(
model_apply_fn=flax_transformer.apply,
variables=params,
input=x,
output_grad=dy,
dropout_key=dropout_key,
forward_kwargs={"attention_mask": None, "deterministic": False},
)
Mean time: 18.546080589294434 ms
Meet Transformer Engine
Summary
Now that we have a basic Transformer layer in Flax, let’s use Transformer Engine to speed up the training. The following examples show how to use TE modules.
As a reminder, the FlaxTransformerLayer above used:
nn.LayerNorm: Flax LayerNormnn.Dense: Flax Dense layer for QKV projectionnn.MultiheadDotProductAttention: Flax MultiheadDotProductAttentionnn.Dense: Flax Dense layer for projectionnn.Dropout: Flax DropoutFlaxMLP: Custom MLP implemented fromnn.Dense
Below we show how to use Transformer Engine Flax modules for better performance:
[32]:
import transformer_engine.jax as te
import transformer_engine.jax.flax as te_flax
TE provides a set of Flax Linen modules that can be used to build Transformer layers. The simplest of the provided modules are the DenseGeneral and LayerNorm layers, which we can use instead of flax.linen.Dense and flax.linen.LayerNorm. Let’s modify our FlaxTransformerLayer:
[33]:
from transformer_engine.jax.flax.transformer import DotProductAttention as TEDotProductAttention
class TEUnfusedMLP(nn.Module):
hidden_size : int
ffn_hidden_size: int
@nn.compact
def __call__(self, x: jnp.ndarray, deterministic: bool) -> jnp.ndarray:
x = te_flax.DenseGeneral(features=self.ffn_hidden_size, use_bias=True) (x)
x = x.reshape(*x.shape[:-1], 1, x.shape[-1])
x = te.activation.activation(x, activation_type=('gelu',))
x = te_flax.DenseGeneral(features=self.hidden_size, use_bias=True) (x)
return x
class TEUnfusedTransformerLayer(nn.Module):
hidden_size: int
ffn_hidden_size: int
num_attention_heads: int
layernorm_eps: float = 1e-5
attention_dropout: float = 0.1
use_te_attention: bool = True # True for TE attention, False for Flax attention
def setup(self):
self.kv_channels = self.hidden_size // self.num_attention_heads
@nn.compact
def __call__(
self,
x: jnp.ndarray,
attention_mask: Optional[jnp.ndarray] = None,
deterministic: bool = False
) -> jnp.ndarray:
# Create causal mask if not provided
if attention_mask is None:
attention_mask = nn.make_causal_mask(x[..., 0], dtype=jnp.bool_)
res = x
x = te_flax.LayerNorm(epsilon=self.layernorm_eps)(x)
# Fused QKV projection
qkv = te_flax.DenseGeneral(features=3 * self.hidden_size, use_bias=True)(x)
qkv = qkv.reshape(qkv.shape[0], qkv.shape[1], self.num_attention_heads, 3 * self.kv_channels)
q, k, v = jnp.split(qkv, 3, axis=3)
# Attention - either TE or Flax implementation
if self.use_te_attention:
# Use TE's DotProductAttention
attention = TEDotProductAttention(
head_dim=self.kv_channels,
num_attention_heads=self.num_attention_heads,
num_gqa_groups=self.num_attention_heads, # No GQA
attention_dropout=self.attention_dropout,
attn_mask_type='causal',
)
x = attention(q, k, v, sequence_descriptor=None, deterministic=deterministic)
# Reshape from [batch, seq_len, num_heads, head_dim] to [batch, seq_len, hidden_size]
x = x.reshape((x.shape[0], x.shape[1], x.shape[2] * x.shape[3]))
x = te_flax.DenseGeneral(features=self.hidden_size, use_bias=True)(x)
x = nn.Dropout(rate=self.attention_dropout)(x, deterministic=deterministic)
else:
# Use Flax's MultiHeadDotProductAttention
q_reshaped = q.reshape(q.shape[0], q.shape[1], self.hidden_size)
k_reshaped = k.reshape(k.shape[0], k.shape[1], self.hidden_size)
v_reshaped = v.reshape(v.shape[0], v.shape[1], self.hidden_size)
attention = nn.MultiHeadDotProductAttention(
num_heads=self.num_attention_heads,
qkv_features=self.kv_channels,
dropout_rate=self.attention_dropout,
)
x = attention(q_reshaped, k_reshaped, v_reshaped, mask=attention_mask, deterministic=deterministic)
x = res + x
# Second residual connection
res = x
x = te_flax.LayerNorm(epsilon=self.layernorm_eps)(x)
# MLP
mlp = TEUnfusedMLP(
hidden_size=self.hidden_size,
ffn_hidden_size=self.ffn_hidden_size
)
x = mlp(x, deterministic=deterministic)
return x + res
Testing performance of the model, using DenseGeneral, LayerNorm and activation from TE, while keeping Flax’s MultiHeadDotProductAttention the same as the first simple Transformer in JAX implementation. To read more about this implementation from Flax, you can refer to this documentation: https://flax.readthedocs.io/en/latest/api_reference/flax.nnx/nn/attention.html
[34]:
te_unfused_transformer_with_flax_MHA = TEUnfusedTransformerLayer(
hidden_size,
ffn_hidden_size,
num_attention_heads,
use_te_attention=False
)
te_params = te_unfused_transformer_with_flax_MHA.init(key, x, attention_mask=None, deterministic=False)
utils.speedometer(
model_apply_fn=te_unfused_transformer_with_flax_MHA.apply,
variables=te_params, # Ensure the correct `params` is passed
input=x,
output_grad=dy,
dropout_key=dropout_key,
forward_kwargs={"attention_mask": None, "deterministic": False},
)
Mean time: 16.375374794006348 ms
Now, we move on to also replace the attention sub-layer with TE’s DotProductAttention implementation
[35]:
te_unfused_transformer = TEUnfusedTransformerLayer(
hidden_size,
ffn_hidden_size,
num_attention_heads,
)
te_params = te_unfused_transformer.init(key, x, attention_mask=None, deterministic=False)
utils.speedometer(
model_apply_fn=te_unfused_transformer.apply,
variables=te_params, # Ensure the correct `params` is passed
input=x,
output_grad=dy,
dropout_key=dropout_key,
forward_kwargs={"attention_mask": None, "deterministic": False},
)
/code/github/TransformerEngine/transformer_engine/jax/flax/transformer.py:634: UserWarning: transpose_batch_sequence defaults to False in DotProductAttention starting TransformerEngine v2.10
warnings.warn(
/code/github/TransformerEngine/transformer_engine/jax/flax/transformer.py:742: UserWarning: Fused attention is not enabled because there is no available kernel.
Fall back to the unfused attention.
Please try to update the cuDNN and TE to the latest version.
self.dtype=<class 'jax.numpy.float32'>
qkv_layout=<QKVLayout.BSHD_BSHD_BSHD: <NVTE_QKV_Layout.NVTE_BSHD_BSHD_BSHD: 9>>
attn_bias_type=<AttnBiasType.NO_BIAS: <NVTE_Bias_Type.NVTE_NO_BIAS: 0>>
attn_mask_type=<AttnMaskType.CAUSAL_MASK: <NVTE_Mask_Type.NVTE_CAUSAL_MASK: 2>>
self.attention_dropout=0.1
self.num_attention_heads=32
self.num_gqa_groups=32
seqlen_q=2048
seqlen_kv=2048
head_dim_qk=128
head_dim_v=128
warnings.warn(
Mean time: 12.403340339660645 ms
Enabling Quantization (FP8 or FP4)
Summary
We configure a TE module to perform compute in FP8.
Enabling FP8 support is very simple in Transformer Engine. We just need to wrap the modules within an autocast context manager. See the FP8 tutorial for a detailed explanation of FP8 recipes and the supported options.
Important: FP8 Metadata Initialization
When using FP8, the model must be initialized within the ``autocast`` context. This creates a special collection called fp8_metas that contains scaling factors and other metadata required for FP8 computation. If you initialize a model outside of autocast and then try to use it with FP8, you will get a ScopeCollectionNotFound error because the fp8_metas collection was never created.
[36]:
from transformer_engine.common.recipe import Format, DelayedScaling
fp8_format = Format.HYBRID
fp8_recipe = DelayedScaling(fp8_format=fp8_format, amax_history_len=16, amax_compute_algo="max")
[37]:
with te.autocast(enabled=True, recipe=fp8_recipe):
te_unfused_params = te_unfused_transformer.init(key, x, attention_mask=None, deterministic=False)
# Example usage of forward
y = te_unfused_transformer.apply(te_unfused_params, x, attention_mask=None, deterministic=True)
utils.speedometer(
model_apply_fn=te_unfused_transformer.apply,
variables=te_unfused_params, # Ensure the correct `params` is passed
input=x,
output_grad=dy,
dropout_key=dropout_key,
forward_kwargs={"attention_mask": None, "deterministic": False},
autocast_kwargs = { "enabled": True, "recipe": fp8_recipe}
)
Mean time: 9.396424293518066 ms
Fused TE Modules
Summary
We optimize the example Transformer layer with TE modules for fused operations.
The DenseGeneral layer is enough to build any Transformer model and it enables usage of the Transformer Engine even for very custom Transformers. However, having more knowledge about the model allows for additional optimizations such as kernel fusions in mixed-precision recipes, increasing the achievable speedup.
Transformer Engine therefore provides coarser modules that span multiple layers:
LayerNormDenseGeneralLayerNormMLPTransformerLayer
To see a complete list of all the functions TE Flax support, you can view it here: https://docs.nvidia.com/deeplearning/transformer-engine/user-guide/api/jax.html#modules
Building a third iteration of our Transformer layer with LayerNormDenseGeneral and LayerNormMLP:
[38]:
class TEFusedTransformerLayer(nn.Module):
hidden_size: int
ffn_hidden_size: int
num_attention_heads: int
layernorm_eps: float = 1e-5
attention_dropout: float = 0.1
def setup(self):
self.kv_channels = self.hidden_size // self.num_attention_heads
@nn.compact
def __call__(
self,
x: jnp.ndarray,
attention_mask: Optional[jnp.ndarray] = None,
deterministic: bool = False
) -> jnp.ndarray:
res = x
# Fused QKV projection
qkv,_ = te_flax.LayerNormDenseGeneral(features=3 * self.hidden_size,
epsilon=self.layernorm_eps,
use_bias=True,
return_layernorm_output=False)(x)
qkv = qkv.reshape(qkv.shape[0], qkv.shape[1], self.num_attention_heads, 3 * self.kv_channels)
q, k, v = jnp.split(qkv, 3, axis=3)
# Attention using TE's DotProductAttention
attention = TEDotProductAttention(
head_dim=self.kv_channels,
num_attention_heads=self.num_attention_heads,
num_gqa_groups=self.num_attention_heads,
attention_dropout=self.attention_dropout,
attn_mask_type='causal',
)
x = attention(q, k, v, sequence_descriptor=None, deterministic=deterministic)
# Reshape from [batch, seq_len, num_heads, head_dim] to [batch, seq_len, hidden_size]
x = x.reshape((x.shape[0], x.shape[1], x.shape[2] * x.shape[3]))
x = te_flax.DenseGeneral(features=self.hidden_size, use_bias=True)(x)
x = nn.Dropout(rate=self.attention_dropout)(x, deterministic=deterministic)
x = res + x
# Second residual connection
res = x
x,_ = te_flax.LayerNormMLP(intermediate_dim=self.ffn_hidden_size,
epsilon=self.layernorm_eps,
use_bias=True,
activations=('gelu',),
intermediate_dropout_rate=0.0,
return_layernorm_output=False
)(x, deterministic=deterministic)
return x + res
Similar to the unnfused model, we also compare the performance of fused model when using Flax’s MultiheadDotProductAttention implementation and TE’s.
[39]:
te_fused_transformer = TEFusedTransformerLayer(
hidden_size,
ffn_hidden_size,
num_attention_heads
)
with te.autocast(enabled=True, recipe=fp8_recipe):
te_fused_params = te_fused_transformer.init(key, x, attention_mask=None, deterministic=False)
# Example usage of forward
y = te_fused_transformer.apply(te_fused_params, x, attention_mask=None, deterministic=True)
utils.speedometer(
model_apply_fn=te_fused_transformer.apply,
variables=te_fused_params,
input=x,
output_grad=dy,
dropout_key=dropout_key,
forward_kwargs={"attention_mask": None, "deterministic": False},
autocast_kwargs = { "enabled": True, "recipe": fp8_recipe}
)
Mean time: 9.145426750183105 ms
Finally, the TransformerLayer module is convenient for creating standard Transformer architectures.
[40]:
te_transformer = te_flax.TransformerLayer(
hidden_size=hidden_size,
mlp_hidden_size=ffn_hidden_size,
num_attention_heads=num_attention_heads,
mlp_activations=("gelu",),
self_attn_mask_type='causal',
layernorm_epsilon=1e-5,
use_bias=True,
intermediate_dropout=0.0,
enable_relative_embedding=False,
self_attn_bias_type='no_bias',
hidden_dropout=0.0
)
with te.autocast(enabled=True, recipe=fp8_recipe):
te_transformer_params = te_transformer.init(key, x, deterministic=False)
y = te_transformer.apply(te_transformer_params, x, attention_mask=None, deterministic=True)
/code/github/TransformerEngine/transformer_engine/jax/flax/transformer.py:742: UserWarning: Fused attention is not enabled because there is no available kernel.
Fall back to the unfused attention.
Please try to update the cuDNN and TE to the latest version.
self.dtype=<class 'jax.numpy.float32'>
qkv_layout=<QKVLayout.BS3HD: <NVTE_QKV_Layout.NVTE_BS3HD: 5>>
attn_bias_type=<AttnBiasType.NO_BIAS: <NVTE_Bias_Type.NVTE_NO_BIAS: 0>>
attn_mask_type=<AttnMaskType.CAUSAL_MASK: <NVTE_Mask_Type.NVTE_CAUSAL_MASK: 2>>
self.attention_dropout=0.1
self.num_attention_heads=32
self.num_gqa_groups=32
seqlen_q=2048
seqlen_kv=2048
head_dim_qk=128
head_dim_v=128
warnings.warn(
[41]:
utils.speedometer(
model_apply_fn=te_transformer.apply,
model_init_fn=te_transformer.init,
variables=te_transformer_params,
input=x,
output_grad=dy,
dropout_key=dropout_key,
forward_kwargs={"attention_mask": None, "deterministic": False},
autocast_kwargs = { "enabled": True, "recipe": fp8_recipe }
)
Mean time: 9.020795822143555 ms