Software#
The software stack for DGX Grace Blackwell rack scale systems is composed of software and firmware that runs on the various compute nodes, switch nodes, and the power shelves.
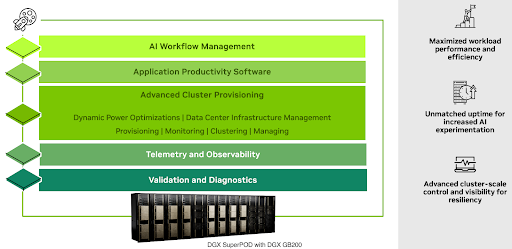
Mission Control Software#
NVIDIA Mission Control combines the workload aware intelligence with full-stack observability (this includes datacenter facilities integration) to ensure that developer jobs are executed on the right resources, intelligently orchestrated to maximize throughput and uptime so that the infrastructure as a whole is working in concert with the datacenter center facilities supporting it.
AI practitioners can seamlessly manage jobs and select power profiles based on workload type and power vs. performance goals. Topology-aware scheduling aligns the job at multiple layers ensuring the entire rack functions like one big GPU. And thanks to fast checkpointing and tiered restart, no more finding out halfway into your run that your job crashed and you just lost a week of work based on the last checkpoint.
Jobs that use Mission Control are rapidly checkpointed and when errors or faults occur the software automatically isolates those problems, and then quickly restarts the job without manual intervention. With unified, integrated telemetry the software is able to isolate the specific component that is faulty and cordons off affected infrastructure, moving workloads to healthy nodes while taking into consideration the system topology.
It’s important to remember that the infrastructure relies on the facilities that support it. This software monitors power and cooling, and can even detect leaks, to ensure the proper functioning of the facilities’ power and cooling systems, such as those supplying power to a rack or providing liquid cooling.
In conclusion, Mission Control provides end-to-end observability for the AI factory, addressing the challenge of not only deploying but also maintaining complex systems. This software offers cluster-scale control and visibility, improving infrastructure resiliency. It allows for effortless scaling and management of your cluster, simplifies the balancing of performance and power efficiency, and enables regular health checks to validate hardware and performance throughout the infrastructure lifecycle.
NVIDIA Mission Control also provides the following software benefits:
Simplified cluster setup and provisioning: New automation and standardized application programming interfaces to accelerate time to deployment with integrated inventory management, and visualizations.
Seamless workload orchestration: Simplifies Slurm and Kubernetes workflows.
Energy-optimized power profiles: Balances power requirements and tunes GPU performance for various workload types with developer-selectable controls.
Autonomous job recovery: Identifies, isolates, and recovers from inefficiencies without manual intervention to maximize developer productivity and infrastructure resiliency.
Customizable dashboards: Tracks key performance indicators with access to critical telemetry data about clusters.
On-demand health checks: Validates hardware and cluster performance throughout the infrastructure lifecycle.
Building management integration: Provides enhanced coordination with building management systems to provide more control for power and cooling events, including rapid leakage detection.
CUDA Software Platform#
NVIDIA CUDA® allows applications to use GPUs for accelerated computing and provides more than 150 libraries to create high-performance applications across programming languages and use cases. Here are some additional benefits:
CUDA provides the tools to optimize and debug your GPU accelerated application.
CUDA-enabled applications run on Grace Blackwell Superchips (such as GB200 and GB300) and leverage the NVLink network to provide distributed processing across every GPU in the DGX GB rack system.
Refer to the NVIDIA CUDA documentation for more information about CUDA.
Internode Memory Exchange Service#
The NVIDIA Internode Memory Exchange/Management (IMEX) is a secure service that facilitates the mapping of GPU memory over NVLink between the GPUs in an NVLIink domain across the OS/node boundary using memory export and import operations. The service is started on all nodes in the NVLink domain during system startup or during the launch of the CUDA job.
Here are the key features:
Facilitates memory sharing across compute nodes.
Manages the lifecycle of the shared memory.
Registers for the memory import/unimport events with the GPU driver.
Does not directly communicate with CUDA or user applications.
Communicates across nodes using the compute node’s network employing TCP/IP and gRPC connections.
Runs exclusively on compute nodes.
IMEX domain vs. IMEX channel
An IMEX domain is an OS instance or a group of securely connected OS instances that use the IMEX service daemon in a multi-node system. On single-node systems, the IMEX daemon is not required.
- An IMEX channel is a communication path exposed by the GPU driver within an IMEX domain to allow sharing memory securely in a multi-user environment.
An IMEX channel is a logical entity that is represented by a /dev node.
The IMEX channels are global resources within the IMEX domain.
When exporter and importer CUDA processes have been granted access to the same IMEX channel, they can securely share memory.
NVIDIA Switch Tray Software#
With the fourth generation of NVSwitches, NVIDIA has implemented a unified architecture that spans across NVLink, InfiniBand, and Ethernet switches. The NVSwitch trays that implement these fourth-generation NVSwitches have an NVOS image installed on them.
NVIDIA Switch OS#
The NVLink Switch Tray comes with the NVIDIA NVSmanagerwitch™ operating system (NVOS) that enables the management and configuration of NVIDIA’s switch system platforms. NVOS provides a suite of management options, incorporates an industry-standard command line interface (CLI), and OpenAPI (Swagger) that allows system administrators to easily configure and manage the system.
NVOS includes the NVLink Subnet Manager (NVLSM), the Fabric Manager (FM), NMX services such as NMX-Controller and NMX-Telemetry, and the NVSwitch firmware.
NMX-Controller#
The NMX-Controller is a cluster application for fabric Software Defined Network (SDN) services. In DGX GB rack systems the SDN services include SM and FM.
The NVOS cluster infrastructure includes the cluster applications package file in the NVOS image. The packages are automatically installed with the NVOS image installation and upgrade process, which ensures a hassle-free setup.
Fabric Manager#
FM configures the NVSwitch memory fabrics to form a large memory fabric among the participating GPUs and monitors the NVLinks that support the fabric. At a high level, FM has the following responsibilities:
Configures routing among NVSwitch ports.
Sets up the GPU side routing/port map if applicable.
Coordinates with the GPU driver to initialize the GPUs.
Monitors the fabric for NVLink and NVSwitch errors.
NVLink Subnet Manager#
NVLink Subnet Manager (NVLSM) originated from the IB networking and added additional logic to manage the NVSwitch and NVLinks in the switch trays. At a high level, the NVLSM provides the following functionalities in NVSwitch-based systems:
Discovers the NVLink network topology.
Assigns a logical identifier (LID) to the GPU and NVSwitch NVLink ports.
Calculates and programs the switch forwarding table.
Programs the Partition Key (PKEY) for NVLink partitions.
Monitors the changes in the NVLink fabric.
NMX-Telemetry#
NMX-T is a subsystem that collects, aggregates, and transmits telemetry data from various devices, applications, and platforms. In the context of this guide, it collects and aggregates from all the NVLink switches in a NVLink domain.
DOCA Software Framework#
The DOCA framework unlocks the potential of the NVIDIA® BlueField® networking platform by enabling the rapid creation of applications and services that offload, accelerate, and isolate data center workloads. It lets developers create software-defined, cloud-native, DPU- and SuperNIC-accelerated services with zero-trust protection, which addresses the performance and security demands of modern data centers. DOCA-Host includes the host drivers and tools for BlueField and ConnectX® devices in the rack.
NVIDIA Collective Communication Library#
GPU communication libraries like NVIDIA Collective Communications Library (NCCL), NVIDIA NVSHMEM, and Unified Communication X (UCX) provide a framework for efficient and scalable inter-GPU communication. Communication performance is crucial for the overall Deep Learning (DL) performance and HPC applications that run on multi-node racks and large clusters. They support a variety of interconnect technologies including PCIe, NVLink, NVLink Network (known as NVLink Multi-node), InfiniBand, RoCE, and so on.
NCCL provides inter-GPU communication primitives that are topology-aware, removing the need for developers to optimize their applications for specific systems. NCCL implements collective communication and point-to-point send/receive primitives for intra- and inter-node data transfers. Refer to the NCCL documentation for more information.
NVSHMEM provides a partitioned global address space (PGAS) for data that spans the memory of multiple GPUs. In addition to the CPU and CUDA stream communication APIs, NVSHMEM also provides device APIs for communication. These APIs enable low latency communication between GPUs and allows applications to do fine-grained and/or fused overlap of compute and communication from the CUDA kernel. Refer to the NVIDIA NVSHMEM documentation for more information.
UCX is a framework that provides a common set of CPU-initiated tag-matching, active-messaging, and remote memory access APIs over a variety of network protocols and hardware, which enhances scalability and performance in distributed computing systems. Refer to NVIDIA UCX documentation for more information.
Data Center GPU Manager#
NVIDIA Data Center GPU Manager (DCGM) is a suite of tools that manage and monitor NVIDIA datacenter GPUs and NVSwitches in cluster environments. It includes active health monitoring, comprehensive diagnostics, system alerts, and governance policies including power and clock management. The suite can be used as a standalone option by infrastructure teams and easily integrates into cluster management tools, resource scheduling, and monitoring products from NVIDIA partners. Refer to the NVIDIA DCGM documentation for more information.
NVIDIA Firmware Tools (MFT)#
The MFT package, which is a set of network ASIC firmware management tools, is used for the following reasons:
Generating a standard or customized firmware image.
Querying for firmware information.
Flashing a firmware image.
The MFT package for DGX GB rack systems can be found in the accompanying software release.