NVIDIA DOCA HBN Service Guide
This guide provides instructions on how to use the DOCA HBN Service container on top of NVIDIA® BlueField® DPU.
For the release notes of HBN 2.1.0, please refer to "HBN Service Release Notes".
Host-based networking (HBN) is a DOCA service that enables the network architect to design a network purely on L3 protocols, enabling routing to run on the server-side of the network by using the DPU as a BGP router. The EVPN extension of BGP, supported by HBN, extends the L3 underlay network to multi-tenant environments with overlay L2 and L3 isolated networks.
The HBN solution packages a set of network functions inside a container which, itself, is packaged as a service pod to be run on the DPU. At the core of HBN is the Linux networking DPU acceleration driver. Netlink to DOCA daemon, or nl2docad, implements the DPU acceleration driver. nl2docad seamlessly accelerates Linux networking using DPU hardware programming APIs.
The driver mirrors the Linux kernel routing and bridging tables into the DPU hardware by discovering the configured Linux networking objects using the Linux Netlink API. Dynamic network flows, as learned by the Linux kernel networking stack, are also programmed by the driver into DPU hardware by listening to Linux kernel networking events.
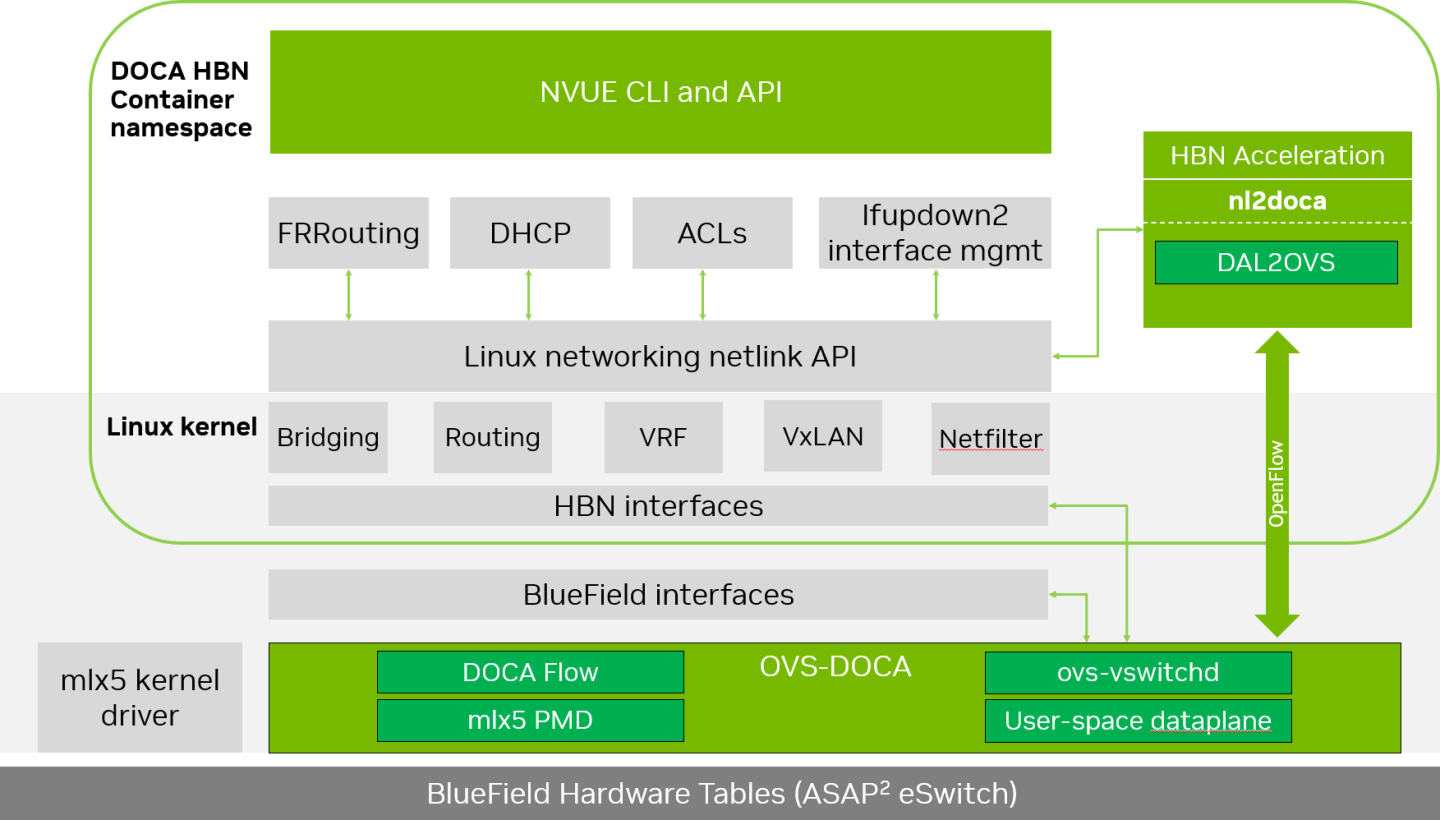
The following diagram captures an overview of HBN and the interactions between various components of HBN.
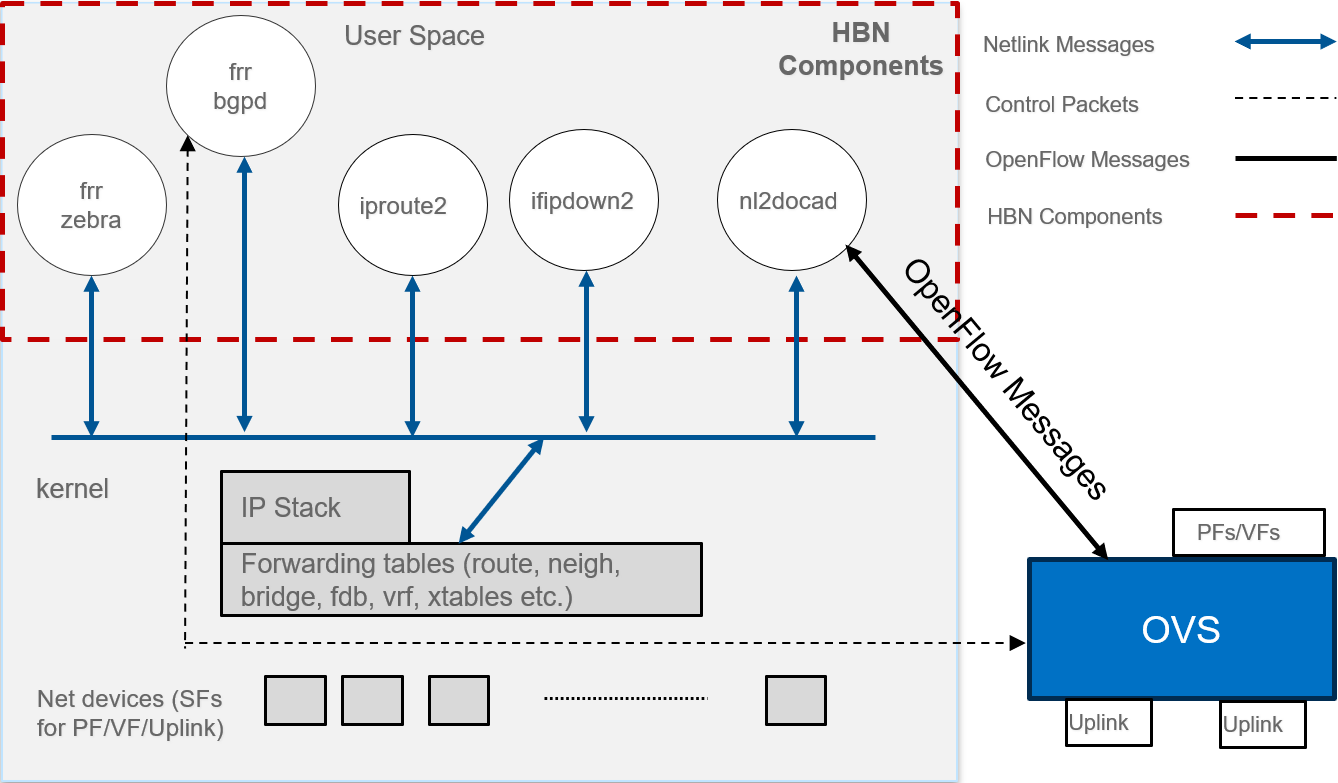
ifupdown2 is the interface manager which pushes all the interface related states to kernel
The routing stack is implemented in FRR and pushes all the control states (EVPN MACs and routes) to kernel via netlink
Kernel maintains the whole network state and relays the information using netlink. The kernel is also involved in the punt path and handling traffic that does not match any rules in the eSwitch.
nl2docad listens for the network state via netlink and invokes the DOCA interface to accelerate the flows in the DPU hardware tables. nl2docad also offloads these flows to eSwitch.
Preparing DPU for HBN Deployment
HBN requires service function chaining (SFC) to be activated on the DPU before running the HBN service container. SFC allows for additional services/containers to be chained to HBN and provides additional data manipulation capabilities.
The following subsections provide additional information about SFC and instructions on enabling it during DPU BFB installation.
Service Function Chaining
The diagram below shows the fully detailed default configuration for HBN with Service Function Chaining (SFC).
In this setup, the HBN container is configured to use sub-function ports (SFs) instead of the actual uplinks, PFs and VFs. To illustrate, for example:
Uplinks – use p0_sf instead of p0
PF – use pf0hpf_sf instead of pf0hpf
VF – use pf0vf0_sf instead of pf0vf0
The indirection layer between the SF and the actual ports is managed via a br-hbn OVS bridge automatically configured when the BFB image is installed on the DPU with HBN enabled. This indirection layer allows other services to be chained to existing SFs and provide additional functionality to transit traffic.
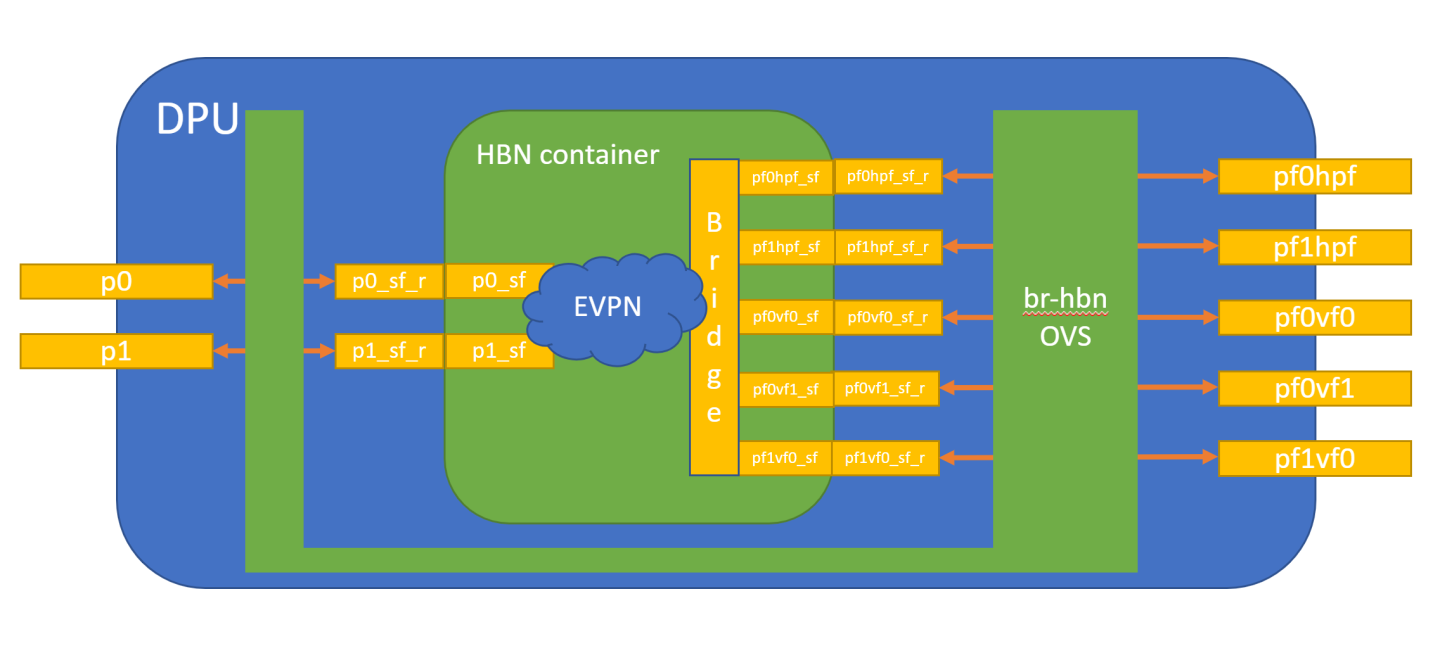
Enabling SFC for HBN Deployment
Deployment from BFB
DPU installation should follow the NVIDIA DOCA Installation Guide for Linux.
Make sure link type is set to ETH in step 5 of the "Installing Software on Host" section in the NVIDIA DOCA Installation Guide for Linux.
Add the following parameters to the bf.cfg configuration file:
ENABLE_SFC_HBN=
yesNUM_VFs_PHYS_PORT0=12# <num VFs supported by HBN on Physical Port 0> (valid range: 0-127) Default 14NUM_VFs_PHYS_PORT1=2# <num VFs supported by HBN on Physical Port 1> (valid range: 0-127) Default 0Then run:
# bfb-install -c bf.cfg -r rshim0 -b <BFB-image>
Deployment from PXE Boot
To enable HBN SFC using a PXE installation environment with BFB content, use the following configuration for PXE:
bfnet=<IFNAME>:<IPADDR>:<NETMASK> or <IFNAME>:dhcp
bfks=<URL of the kickstart script>
The kickstart script (bash) should include the following lines:
cat >> /etc/bf.cfg << EOF
ENABLE_SFC_HBN=yes
NUM_VFs_PHYS_PORT0=12 # <num VFs supported by HBN on Physical Port 0> (valid range: 0-127) Default 14
NUM_VFs_PHYS_PORT1=2 # <num VFs supported by HBN on Physical Port 1> (valid range: 0-127) Default 0
EOF
/etc/bf.cfg is sourced by the BFB install.sh script.
It is recommended to verify the accuracy of the DPU's clock post-installation. This can be done using the following command:
$ date
Please refer to the known issues listed in the "NVIDIA DOCA Release Notes" for more information.
Deploying HBN with Other Services
When the HBN container is deployed by itself, the DPU is configured with 3k huge pages. If it is deployed with other services, the actual number of huge-pages must be adjusted based on the requirements of those services. For example, SNAP or NVMesh need approximately 1k huge pages. So if HBN is running with either of these services on the same DPU, the total number of huge pages must be set to 4k (3k for HBN and 1k for SNAP or NVMesh).
To do that, add the following parameters to the bf.cfg configuration file alongside other desired parameters.
HUGEPAGE_COUNT=4096
This should be performed only on a BlueField-3 running with 32G of memory. Doing this on 16G system may cause memory issues for various applications on DPU.
HBN Service Container Deployment
HBN service is available on NGC, NVIDIA's container catalog. Service-specific configuration steps and deployment instructions can be found under the service's container page. Make sure to follow the instructions in the NGC page to verify that the container is running properly.
For information about the deployment of DOCA containers on top of the BlueField DPU, refer to NVIDIA DOCA Container Deployment Guide.
HBN Default Deployment Configuration
The HBN service comes with four types of configurable interfaces:
Two uplinks (p0_sf, p1_sf)
Two PF port representors (pf0hpf_sf, pf1hpf_sf)
User-defined number of VFs (i.e., pf0vf0_sf, pf0vf1_sf, …, pf1vf0_sf, pf1vf1_sf, …)
Two interfaces to connect to services running on the DPU, outside of the HBN container (pf0dpu1_sf and pf0dpu3_sf)
The *_sf suffix indicates that these are sub-functions and are different from the physical uplinks (i.e., PFs, VFs). They can be viewed as virtual interfaces from a virtualized DPU.
Each of these interfaces is connected outside the HBN container to the corresponding physical interface, see section "Service Function Chaining" (SFC) for more details.
The HBN container runs as an isolated namespace and does not see any interfaces outside the container (oob_net0, real uplinks and PFs, *_sf_r representors).
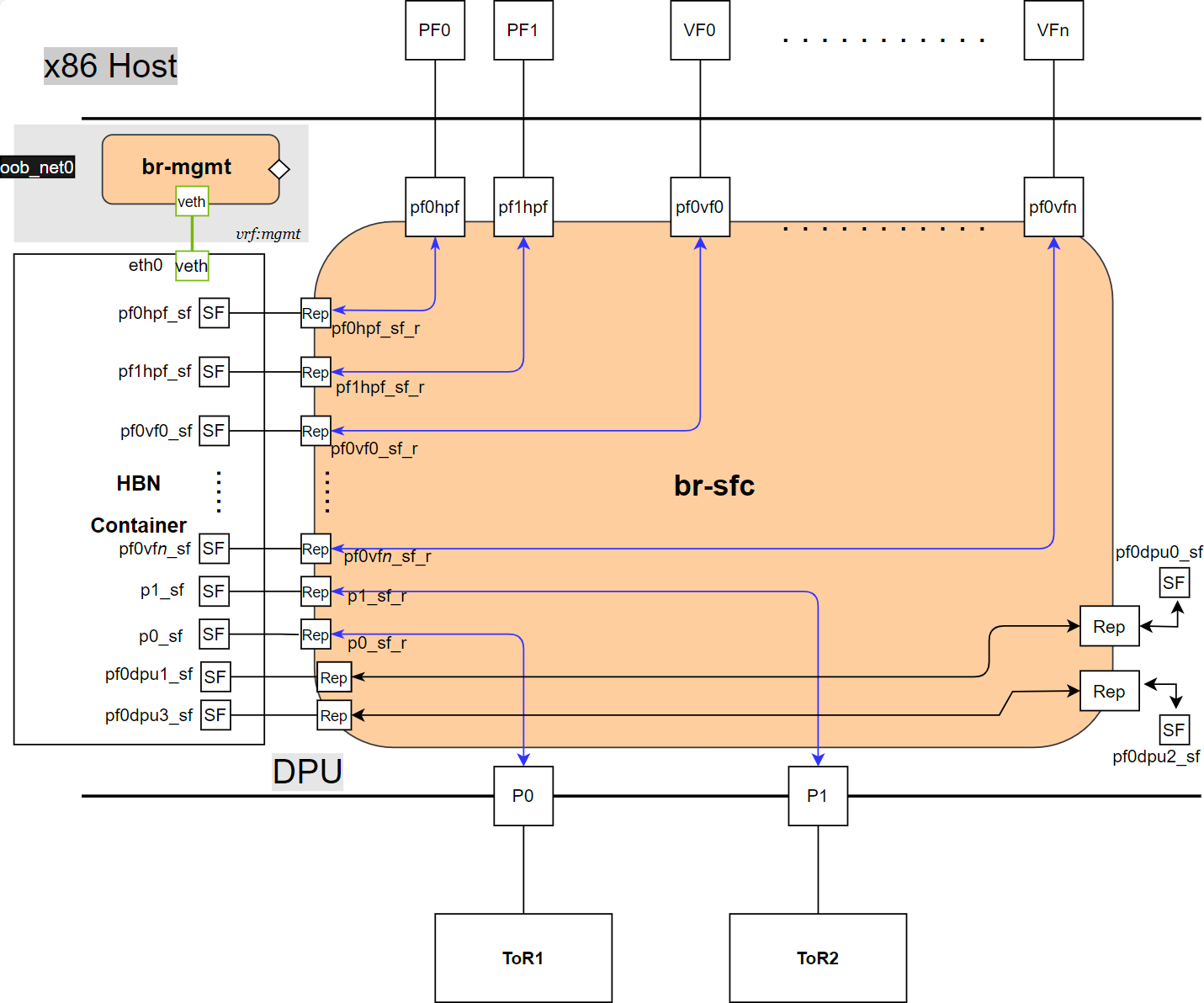
pf0dpu1_sf and pf0dpu3_sf are special interfaces for HBN to connect to services running on the DPU. Their counterparts pf0dpu0_sf and pf0dpu2_sf respectively are located outside the HBN container. See section "Connecting to Services on DPU" for deployment considerations when using the pf0dpu1_sf or pf0dpu3_sf interface in HBN.
eth0 is equivalent to the oob_net0 interface in the HBN container. It is part of the management VRF of the container. It is not configurable via NVUE and does not need any configuration from the user. See section "MGMT VRF in HBN Container" for more details on this interface and the management VRF.
HBN Deployment Considerations
SF Interface State Tracking
When HBN is deployed with SFC, the interface state of the following network devices is propagated to their corresponding SFs:
Uplinks – p0, p1
PFs – pf0hpf, pf1hpf
VFs – pf0vfX, pf1vfX where X is the VF number
For example, if the p0 uplink cable gets disconnected:
p0 transitions to DOWN state with NO-CARRIER (default behavior on Linux); and
p0 state is propagated to p0_sf whose state also becomes DOWN with NO-CARRIER
After p0 connection is reestablished:
p0 transitions to UP state; and
p0 state is propagated to p0_sf whose state becomes UP
Interface state propagation only happens in the uplink/PF/VF-to-SF direction.
A daemon called sfc-state-propagation runs on the DPU, outside of the HBN container, to sync the state. The daemon listens to netlink notifications for interfaces and transfers the state to SFs.
SF Interface MTU
In the HBN container, all the interfaces MTU are set to 9216 by default. MTU of specific interfaces can be overwritten using flat-files configuration or NVUE.
On the DPU side (i.e., outside of the HBN container), the MTU of the uplinks, PFs and VFs interfaces are also set to 9216. This can be changed by modifying /etc/systemd/network/30-hbn-mtu.network or by adding a new configuration file in the /etc/systemd/network for specific directories.
To reload this configuration, execute systemctl restart systemd-networkd.
Connecting to Services on DPU
There are various DPU ports (named pf0dpuX_sf, where X is [0..n]), which can be used to run any services on the DPU and use HBN to provide network connectivity. These ports are always created and connected in pairs of even and odd numbered ports, where even numbered ports are on the DPU side and odd numbered port are on the HBN side. For example, pf0dpu0_sf can be used by a service on DPU to connect to HBN port pf0dpu1_sf.
Traffic between the DPU and the outside world is not hardware-accelerated in the HBN container when using a native L3 connection over these ports. To get hardware-acceleration, configure the HBN side port with bridge-access over a switch virtual interface (SVI).
There are 2 DPU port pairs created by default so there can be 2 separate DPU services running at same time.
Disabling DPU Uplinks
The uplink ports must be always kept administratively up for proper operation of HBN. Otherwise, the NVIDIA® ConnectX® firmware would bring down the corresponding representor port which would cause data forwarding to stop.
Change in operational status of uplink (e.g., carrier down) would result in traffic being switched to the other uplink.
When using ECMP failover on the two uplink SFs, locally disabling one uplink does not result in traffic switching to the second uplink. Disabling local link in this case means to set one uplink admin DOWN directly on the DPU.
To test ECMP failover scenarios correctly, the uplink must be disabled from its remote counterpart (i.e., execute admin DOWN on the remote system's link which is connected to the uplink).
General Network Configuration
Flat Files Configuration
Add network interfaces and FRR configuration files to the DPU to achieve the desired configuration:
/etc/network/interfaces
NoteRefer to NVIDIA® Cumulus® Linux documentation for more information.
/etc/frr/frr.conf; /etc/frr/daemons
NoteRefer to NVIDIA® Cumulus® Linux documentation for more information.
NVUE Configuration
This section assumes familiarity with NVIDIA user experience (NVUE) Cumulus Linux documentation. The following subsections, only expand on DPU-specific aspects of NVUE.
NVUE Service
HBN installs NVUE by default and enables NVUE service at boot.
NVUE REST API
HBN enables REST API by default.
Users may run the cURL commands from the command line. Use the default HBN username nvidia and password nvidia.
To change the default password of the nvidia user or add additional users for NVUE access, refer to section "NVUE User Credentials".
REST API example:
curl -u 'nvidia:nvidia' --insecure https://<mgmt_ip>:8765/nvue_v1/vrf/default/router/bgp
{
"configured-neighbors": 2,
"established-neighbors": 2,
"router-id": "10.10.10.201"
}
For information about using the NVUE REST API, refer to the NVUE API documentation .
NVUE CLI
For information about using the NVUE CLI, refer to the NVUE CLI documentation
NVUE Startup Configuration File
When the network configuration is saved using NVUE, HBN writes the configuration to the /etc/nvue.d/startup.yaml file.
Startup configuration is applied by following the supervisor daemon at boot time. nvued-startup will appear in EXITED state after applying the startup configuration.
# supervisorctl status nvued-startup
nvued-startup EXITED Apr 17 10:04 AM
nv config apply startup applies the yaml configuration saved at /etc/nvue.d/.
nv config save saves the running configuration to /etc/nvue.d/startup.yaml.
NVUE User Credentials
The preconfigured default user credentials are as follows:
|
Username |
nvidia |
|
Password |
nvidia |
NVUE user credentials can be added post installation. This functionality is enabled by the HBN startup script by using the –-username and –-password script switches. For example:
./hbn-dpu-setup.sh -u newuser -p newpassword
After executing this script, respawn the container or start the decrypt-user-add script:
supervisorctl start decrypt-user-add
decrypt-user-add: started
The script creates a user on the HBN container:
cat /etc/passwd | grep newuser
newuser:x:1001:1001::/home/newuser:/bin/bash
NVUE Interface Classification
|
Interface |
Interface Type |
NVUE Type |
|
p0_sf |
Uplink representor |
swp |
|
p1_sf |
Uplink representor |
swp |
|
lo |
Loopback |
loopback |
|
pf0hpf_sf |
Host representor |
swp |
|
pf1hpf_sf |
Host representor |
swp |
|
pf0vfx_sf (where x is 0-255) |
VF representor |
swp |
|
pf1vfx_sf (where x is 0-255) |
VF representor |
swp |
Configuration Persistence
The following directories are mounted from the host DPU to the HBN container and are persistent across HBN restarts and DPU reboots:
|
Host DPU Mount Point |
HBN Container Mount Point |
|
Configuration Files Mount Pints |
|
|
/var/lib/hbn/etc/network/ |
/etc/network/ |
|
/var/lib/hbn/etc/frr/ |
/etc/frr/ |
|
/var/lib/hbn/etc/nvue.d/ |
/etc/nvue.d/ |
|
/var/lib/hbn/etc/supervisor/conf.d/ |
/etc/supervisor/conf.d/ |
|
/var/lib/hbn/var/lib/nvue/ |
/var/lib/nvue/ |
|
Support and Log Files Mount Points |
|
|
/var/lib/hbn/var/support/ |
/var/support/ |
|
/var/log/doca/hbn/ |
/var/log/hbn/ |
SR-IOV Support
Creating VFs on Host Server
The first step to use SR-IOV is to create VFs on the host server. VFs can be created using the following command:
echo N > /sys/class/net/<host-rep>/device/sriov_numvfs
Where:
<host-rep> is one of the two host representors (e.g., ens1f0 or ens1f1)
0≤N≤16 is the desired total number of VFs
Set N=0 to delete all the VFs on 0≤N≤16
N=16 is the maximum number of VFs supported on HBN across all representors
Automatic Creation of VF Representors on DPU
VFs created on the host must have corresponding SF representors on the DPU side. For example:
ens1f0vf0 is the first VF from the first host representor; this interface is created on the host server
pf0vf0 is the corresponding VF representor to ens1f0vf0; this interface is on the DPU and automatically created at the same time as ens1f0vf0 is created
pf0vf0_sf is the corresponding SF for pf0vf0 which is used by HBN
The creation of the SF representor for VFs is done ahead of time when installing the BFB, see section "Enabling SFC for HBN Deployment" to see how to select how many SFs to create ahead of time.
The SF representors for VFs (i.e., pfXvfY) are pre-mapped to work with the corresponding VF representors when these are created with the command from section "Creating VFs on Host Server".
Management VRF
Two management VRFs are setup for HBN with SFC:
The first management VRF is outside the HBN container on the DPU. This VRF provides separation between out-of-band (OOB) traffic (via oob_net0 or tmfifo_net0) and data-plane traffic via uplinks and PFs.
The second management VRF is inside the HBN container and provides similar separation. The OOB traffic (via eth0) is isolated from the traffic via the *_sf interfaces.
MGMT VRF on Host DPU
The management (mgmt) VRF is enabled by default when the DPU is deployed with SFC (see section "Enabling SFC for HBN Deployment"). The mgmt VRF provides separation between the OOB management network and the in-band data plane network.
The uplinks and PFs/VFs use the default routing table while the oob_net0 (OOB Ethernet port) and the tmifo_net0 netdevices use the mgmt VRF to route their packets.
When logging in either via SSH or the console, the shell is by default in mgmt VRF context. This is indicated by a mgmt added to the shell prompt:
root@bf2:mgmt:/home/ubuntu#
root@bf2:mgmt:/home/ubuntu# ip vrf identify
mgmt.
When logging into the HBN container with crictl, the HBN shell will be in the default VRF. Users must switch to MGMT VRF manually if OOB access is required. Use ip vrf exec to do so.
root@bf2:mgmt:/home/ubuntu# ip vrf exec mgmt bash
The user must run ip vrf exec mgmt to perform operations requiring OOB access (e.g., apt-get update).
Network devices belonging to the mgmt VRF can be listed with the vrf utility:
root@bf2:mgmt:/home/ubuntu# vrf link list
VRF: mgmt
--------------------
tmfifo_net0 UP 00:1a:ca:ff:ff:03 <BROADCAST,MULTICAST,UP,LOWER_UP>
oob_net0 UP 08:c0:eb:c0:5a:32 <BROADCAST,MULTICAST,UP,LOWER_UP>
root@bf2:mgmt:/home/ubuntu# vrf help
vrf <OPTS>
VRF domains:
vrf list
Links associated with VRF domains:
vrf link list [<vrf-name>]
Tasks and VRF domain asociation:
vrf task exec <vrf-name> <command>
vrf task list [<vrf-name>]
vrf task identify <pid>
NOTE: This command affects only AF_INET and AF_INET6 sockets opened by the
command that gets exec'ed. Specifically, it has *no* impact on netlink
sockets (e.g., ip command).
To show the routing table for the default VRF, run:
root@bf2:mgmt:/home/ubuntu# ip route show
To show the routing table for the mgmt VRF, run:
root@bf2:mgmt:/home/ubuntu# ip route show vrf mgmt
MGMT VRF in HBN Container
Inside the HBN container, a separate mgmt VRF is present. Similar commands as those listed under section "MGMT VRF on Host DPU" can be used to query management routes.
The *_sf interfaces use the default routing table while the eth0 (OOB) uses the mgmt VRF to route out-of-band packets out of the container. The OOB traffic gets NATed through the DPU oob_net0 interface, ultimately using the DPU OOB's IP address.
When logging into the HBN container via crictl, the shell enters the default VRF context by default. Switching to the mgmt VRF can be done using the command ip vrf exec mgmt <cmd>.
Existing Services in MGMT VRF on Host DPU
On the host DPU, outside the HBN container, a set of existing services run in the mgmt VRF context as they need OOB network access:
containerd
kubelet
ssh
docker
These services can be restarted and queried for their status using the command systemctl while adding @mgmt to the original service name. For example:
To restart containerd:
root
@bf2:mgmt:/home/ubuntu# systemctl restart containerd@mgmtTo query containerd status:
root
@bf2:mgmt:/home/ubuntu# systemctl status containerd@mgmt
The original version of these services (without @mgmt) are not used and must not be started.
Running New Service in MGMT VRF
If a service needs OOB access to run, it can be added to the set of services running in mgmt VRF context. Adding such a service is only possible on the host DPU (i.e., outside the HBN container).
To add a service to the set of mgmt VRF services:
Add it to /etc/vrf/systemd.conf (if it is not present already). For example, NTP is already listed in this file.
Run the following:
root@bf2:mgmt:/home/ubuntu# systemctl daemon-reload
Stop and disable to the non-VRF version of the service to be able to start the mgmt VRF one:
root@bf2:mgmt:/home/ubuntu# systemctl stop ntp root@bf2:mgmt:/home/ubuntu# systemctl disable ntp root@bf2:mgmt:/home/ubuntu# systemctl enable ntp@mgmt root@bf2:mgmt:/home/ubuntu# systemctl start ntp@mgmt
HBN Configuration Examples
HBN Default Configuration
After a fresh HBN installation, the default /etc/network/interfaces file would contain only the declaration of the two uplink SFs and a loopback interface.
source /etc/network/interfaces.d/*.intf
auto lo
iface lo inet loopback
auto p0_sf
iface p0_sf
auto p1_sf
iface p1_sf
FRR configuration files would also be present under /etc/frr/ but no configuration would be enabled.
Layer-3 Routing
Native Routing with BGP and ECMP
HBN supports unicast routing with BGP and ECMP for IPv4 and IPv6 traffic. ECMP is achieved by distributing traffic using hash calculation based on the source IP , destination IP, and protocol type of the IP header.
For TCP and UDP packets, it also includes source port and destination port.
ECMP Example
ECMP is implemented any time routes have multiple paths over uplinks or host ports. For example, 20.20.20.0/24 has 2 paths using both uplinks, so a path is selected based on a hash of the IP headers.
20.20.20.0/24 proto bgp metric 20
nexthop via 169.254.0.1 dev p0_sf weight 1 onlink <<<<< via uplink p0_sf
nexthop via 169.254.0.1 dev p1_sf weight 1 onlink <<<<< via uplink p1_sf
HBN supports up to 16 paths for ECMP.
Sample NVUE Configuration for Native Routing
nv set interface lo ip address 10.10.10.1/32
nv set interface lo ip address 2010:10:10::1/128
nv set interface vlan100 type svi
nv set interface vlan100 vlan 100
nv set interface vlan100 base-interface br_default
nv set interface vlan100 ip address 2030:30:30::1/64
nv set interface vlan100 ip address 30.30.30.1/24
nv set bridge domain br_default vlan 100
nv set interface pf0hpf_sf,pf1hpf_sf bridge domain br_default access 100
nv set vrf default router bgp router-id 10.10.10.1
nv set vrf default router bgp autonomous-system 65501
nv set vrf default router bgp path-selection multipath aspath-ignore on
nv set vrf default router bgp address-family ipv4-unicast enable on
nv set vrf default router bgp address-family ipv4-unicast redistribute connected enable on
nv set vrf default router bgp address-family ipv6-unicast enable on
nv set vrf default router bgp address-family ipv6-unicast redistribute connected enable on
nv set vrf default router bgp neighbor p0_sf remote-as external
nv set vrf default router bgp neighbor p0_sf type unnumbered
nv set vrf default router bgp neighbor p0_sf address-family ipv4-unicast enable on
nv set vrf default router bgp neighbor p0_sf address-family ipv6-unicast enable on
nv set vrf default router bgp neighbor p1_sf remote-as external
nv set vrf default router bgp neighbor p1_sf type unnumbered
nv set vrf default router bgp neighbor p1_sf address-family ipv4-unicast enable on
nv set vrf default router bgp neighbor p1_sf address-family ipv6-unicast enable on
Sample Flat Files Configuration for Native Routing
Example /etc/network/interfaces configuration:
auto lo
iface lo inet loopback
address 10.10.10.1/32
address 2010:10:10::1/128
auto p0_sf
iface p0_sf
auto p1_sf
iface p1_sf
auto pf0hpf_sf
iface pf0hpf_sf
bridge-access 100
auto pf1hpf_sf
iface pf1hpf_sf
bridge-access 100
auto vlan100
iface vlan100
address 2030:30:30::1/64
address 30.30.30.1/24
vlan-raw-device br_default
vlan-id 100
auto br_default
iface br_default
bridge-ports pf0hpf_sf pf1hpf_sf
bridge-vlan-aware yes
bridge-vids 100
bridge-pvid 1
Example /etc/frr/daemons configuration:
bgpd=yes
vtysh_enable=yes
FRR Config file @ /etc/frr/frr.conf -
!
frr version 7.5+cl5.3.0u0
frr defaults datacenter
hostname BLUEFIELD2
log syslog informational
no zebra nexthop kernel enable
!
router bgp 65501
bgp router-id 10.10.10.1
bgp bestpath as-path multipath-relax
neighbor p0_sf interface remote-as external
neighbor p0_sf advertisement-interval 0
neighbor p0_sf timers 3 9
neighbor p0_sf timers connect 10
neighbor p1_sf interface remote-as external
neighbor p1_sf advertisement-interval 0
neighbor p1_sf timers 3 9
neighbor p1_sf timers connect 10
!
address-family ipv4 unicast
redistribute connected
maximum-paths 64
maximum-paths ibgp 64
exit-address-family
!
address-family ipv6 unicast
redistribute connected
neighbor p0_sf activate
neighbor p1_sf activate
maximum-paths 64
maximum-paths ibgp 64
exit-address-family
!
line vty
!
end
BGP Peering with the Host
HBN supports the ability to establish a BGP session between the host and DPU and allow the host to announce arbitrary route prefixes through the DPU into the underlay fabric. The host can use any standard BGP protocol stack implementation to establish BGP peering with HBN.
Traffic to and from endpoints on the host gets offloaded.
Both IPv4 and IPv6 unicast AFI/SAFI are supported.
It is possible to apply route filtering for these prefixes to limit the potential security impact in this configuration.
Sample NVUE Configuration for Host BGP peering
The following code block shows configuration to peer to host at 45.3.0.4 and 2001:cafe:1ead::4. The BGP session can be established using IPv4 or IPv6 address.
Either of these sessions can support IPv4 unicast and IPv6 unicast AFI/SAFI.
NVUE configuration for peering with host:
nv set vrf default router bgp autonomous-system 63642
nv set vrf default router bgp enable on
nv set vrf default router bgp neighbor 45.3.0.4 nexthop-connected-check off
nv set vrf default router bgp neighbor 45.3.0.4 peer-group dpu_host
nv set vrf default router bgp neighbor 45.3.0.4 type numbered
nv set vrf default router bgp neighbor 2001:cafe:1ead::4 nexthop-connected-check off
nv set vrf default router bgp neighbor 2001:cafe:1ead::4 peer-group dpu_host
nv set vrf default router bgp neighbor 2001:cafe:1ead::4 type numbered
nv set vrf default router bgp peer-group dpu_host address-family ipv4-unicast enable on
nv set vrf default router bgp peer-group dpu_host address-family ipv6-unicast enable on
nv set vrf default router bgp peer-group dpu_host remote-as external
Sample Flat Files Configuration for Host BGP peering
The following block shows configuration to peer to host at 45.3.0.4 and 2001:cafe:1ead::4. The BGP session can be established using IPv4 or IPv6 address.
frr.conf file:
router bgp 63642
bgp router-id 27.0.0.4
bgp bestpath as-path multipath-relax
neighbor dpu_host peer-group
neighbor dpu_host remote-as external
neighbor dpu_host advertisement-interval 0
neighbor dpu_host timers 3 9
neighbor dpu_host timers connect 10
neighbor dpu_host disable-connected-check
neighbor fabric peer-group
neighbor fabric remote-as external
neighbor fabric advertisement-interval 0
neighbor fabric timers 3 9
neighbor fabric timers connect 10
neighbor 45.3.0.4 peer-group dpu_host
neighbor 2001:cafe:1ead::4 peer-group dpu_host
neighbor p0_sf interface peer-group fabric
neighbor p1_sf interface peer-group fabric
!
address-family ipv4 unicast
neighbor dpu_host activate
!
address-family ipv6 unicast
neighbor dpu_host activate
Sample FRR configuration on the Host
Any BGP implementation can be used on the host to peer to HBN and advertise endpoints. The following is an example using FRR BGP:
Sample FRR configuration on the host:
bf2-s12# sh run
Building configuration...
Current configuration:
!
frr version 7.2.1
frr defaults traditional
hostname bf2-s12
no ip forwarding
no ipv6 forwarding
!
router bgp 1000008
!
router bgp 1000008 vrf v_200_2000
neighbor 45.3.0.2 remote-as external
neighbor 2001:cafe:1ead::2 remote-as external
!
address-family ipv4 unicast
redistribute connected
exit-address-family
!
address-family ipv6 unicast
redistribute connected
neighbor 45.3.0.2 activate
neighbor 2001:cafe:1ead::2 activate
exit-address-family
!
line vty
!
end
Sample interfaces configuration on the host:
root@bf2-s12:/home/cumulus# ifquery -a
auto lo
iface lo inet loopback
address 27.0.0.7/32
address 2001:c000:10ff:f00d::7/128
auto v_200_2000
iface v_200_2000
address 60.1.0.1
address 60.1.0.2
address 60.1.0.3
address 2001:60:1::1
address 2001:60:1::2
address 2001:60:1::3
vrf-table auto
auto ens1f0np0
iface ens1f0np0
address 45.3.0.4/24
address 2001:cafe:1ead::4/64
gateway 45.3.0.1
gateway 2001:cafe:1ead::1
vrf v_200_2000
hwaddress 00:03:00:08:00:12
mtu 9162
VRF Route Leaking
VRFs are typically used when multiple independent routing and forwarding tables are desirable. However, users may want to reach destinations in one VRF from another VRF, as in the following cases:
To make a service, such as a firewall available to multiple VRFs
To enable routing to external networks or the Internet for multiple VRFs, where the external network itself is reachable through a specific VRF
Route leaking can be used to reach remote destinations as well as directly connected destinations in another VRF. Multiple VRFs can import routes from a single source VRF, and a VRF can import routes from multiple source VRFs. This can be used when a single VRF provides connectivity to external networks or a shared service for other VRFs. It is possible to control the routes leaked dynamically across VRFs with a route map.
When route leaking is used:
The redistribute command (not network command) must be used in BGP to leak non-BGP routes (connected or static routes)
It is not possible to leak routes between the default and non-default VRF
Local connected SVI IP address cannot be pinged from a different VRF. For example, an SVI IP in VRF RED would not be reachable from VRF BLUE.
In the following example commands, routes in the BGP routing table of VRF BLUE dynamically leak into VRF RED:
nv set vrf RED router bgp address-family ipv4-unicast route-import from-vrf list BLUE
nv config apply
The following example commands delete leaked routes from VRF BLUE to VRF RED:
nv unset vrf RED router bgp address-family ipv4-unicast route-import from-vrf list BLUE
nv config apply
To exclude certain prefixes from the import process, configure the prefixes in a route map.
The following example configures a route map to match the source protocol BGP and imports the routes from VRF BLUE to VRF RED. For the imported routes, the community is 11:11 in VRF RED.
nv set vrf RED router bgp address-family ipv4-unicast route-import from-vrf list BLUE
nv set router policy route-map BLUEtoRED rule 10 match type ipv4
nv set router policy route-map BLUEtoRED rule 10 match source-protocol bgp
nv set router policy route-map BLUEtoRED rule 10 action permit
nv set router policy route-map BLUEtoRED rule 10 set community 11:11
nv set vrf RED router bgp address-family ipv4-unicast route-import from-vrf route-map BLUEtoRED
nv config
To check the status of the VRF route leaking, run the NVUE nv show vrf <vrf-name> router bgp address-family ipv4-unicast route-import command or the vtysh show ip bgp vrf <vrf-name> ipv4|ipv6 unicast route-leak command. For example:
nv show vrf RED router bgp address-family ipv4-unicast route-import
operational applied
-------------- ------------ ---------
from-vrf
enable on
route-map BLUEtoRED
[list] BLUE BLUE
[route-target] 10.10.10.1:3
To show more detailed status information, the following NVUE commands are available:
nv show vrf <vrf-name> router bgp address-family ipv4-unicast route-import from-vrf
nv show vrf <vrf-name> router bgp address-family ipv4-unicast route-import from-vrf list
nv show vrf <vrf-name> router bgp address-family ipv4-unicast route-import from-vrf list <leak-vrf-id>
To view the BGP routing table, run the NVUE nv show vrf <vrf-name> router bgp address-family ipv4-unicast command or the vtysh show ip bgp vrf <vrf-name> ipv4|ipv6 unicast command.
To view the FRR IP routing table, run the vtysh show ip route vrf <vrf-name> command or the net show route vrf <vrf-name> command. These commands show all routes, including routes leaked from other VRFs.
Ethernet Virtual Private Network - EVPN
HBN supports VXLAN with EVPN control plane for intra-subnet bridging (L2) services for IPv4 and IPv6 traffic in the overlay.
For the underlay, only IPv4 or BGP unnumbered configuration is supported.
Single VXLAN Device
With a single VXLAN device, a set of VXLAN network identifiers (VNIs) represents a single device model. The single VXLAN device has a set of attributes that belong to the VXLAN construct. Individual VNIs include VLAN-to-VNI mapping which allows users to specify which VLANs are associated with which VNIs. A single VXLAN device simplifies the configuration and reduces the overhead by replacing multiple traditional VXLAN devices with a single VXLAN device.
Users may configure a single VXLAN device automatically with NVUE, or manually by editing the /etc/network/interfaces file. When users configure a single VXLAN device with NVUE, NVUE creates a unique name for the device in the following format using the bridge name as the hash key: vxlan<id>.
This example configuration performs the following steps:
Creates a single VXLAN device (vxlan21).
Maps VLAN 10 to VNI 10 and VLAN 20 to VNI 20.
Adds the VXLAN device to the default bridge.
cumulus@leaf01:~$ nv set bridge domain bridge vlan 10 vni 10
cumulus@leaf01:~$ nv set bridge domain bridge vlan 20 vni 20
cumulus@leaf01:~$ nv set nve vxlan source address 10.10.10.1
cumulus@leaf01:~$ nv config apply
Alternately, users may edit the file /etc/network/interfaces as follows, then run the ifreload -a command to apply the SVD configuration.
auto lo
iface lo inet loopback
vxlan-local-tunnelip 10.10.10.1
auto vxlan21
iface vxlan21
bridge-vlan-vni-map 10=10 20=20
bridge-learning off
auto bridge
iface bridge
bridge-vlan-aware yes
bridge-ports vxlan21 pf0hpf_sf pf1hpf_sf
bridge-vids 10 20
bridge-pvid 1
Users may not use a combination of single and traditional VXLAN devices.
Sample Switch Configuration for EVPN
The following is a sample NVUE config for underlay switches (NVIDIA® Spectrum® with Cumulus Linux) to enable EVPN deployments with HBN.
It assumes that the uplinks on DPUs are connected to ports swp1-4 on the switch.
nv set evpn enable on
nv set router bgp enable on
nv set vrf default router bgp address-family ipv4-unicast enable on
nv set vrf default router bgp address-family ipv4-unicast redistribute connected enable on
nv set vrf default router bgp address-family l2vpn-evpn enable on
nv set vrf default router bgp autonomous-system 63640
nv set vrf default router bgp enable on
nv set vrf default router bgp neighbor swp1 peer-group fabric
nv set vrf default router bgp neighbor swp1 type unnumbered
nv set vrf default router bgp neighbor swp2 peer-group fabric
nv set vrf default router bgp neighbor swp2 type unnumbered
nv set vrf default router bgp neighbor swp3 peer-group fabric
nv set vrf default router bgp neighbor swp3 type unnumbered
nv set vrf default router bgp neighbor swp4 peer-group fabric
nv set vrf default router bgp neighbor swp4 type unnumbered
nv set vrf default router bgp path-selection multipath aspath-ignore on
nv set vrf default router bgp peer-group fabric address-family ipv4-unicast enable on
nv set vrf default router bgp peer-group fabric address-family ipv6-unicast enable on
nv set vrf default router bgp peer-group fabric address-family l2vpn-evpn add-path-tx off
nv set vrf default router bgp peer-group fabric address-family l2vpn-evpn enable on
nv set vrf default router bgp peer-group fabric remote-as external
nv set vrf default router bgp router-id 27.0.0.10
nv set interface lo ip address 2001:c000:10ff:f00d::10/128
nv set interface lo ip address 27.0.0.10/32
nv set interface lo type loopback
nv set interface swp1,swp2,swp3,swp4 type swp
Layer-2 EVPN
Sample NVUE Configuration for L2 EVPN
The following is a sample NVUE configuration which has L2-VNIs (2000, 2001) for EVPN bridging on DPU.
nv set bridge domain br_default encap 802.1Q
nv set bridge domain br_default type vlan-aware
nv set bridge domain br_default vlan 200 vni 2000 flooding enable auto
nv set bridge domain br_default vlan 200 vni 2000 mac-learning off
nv set bridge domain br_default vlan 201 vni 2001 flooding enable auto
nv set bridge domain br_default vlan 201 vni 2001 mac-learning off
nv set evpn enable on
nv set nve vxlan arp-nd-suppress on
nv set nve vxlan enable on
nv set nve vxlan mac-learning off
nv set nve vxlan source address 27.0.0.4
nv set router bgp enable on
nv set system global anycast-mac 44:38:39:42:42:07
nv set vrf default router bgp address-family ipv4-unicast enable on
nv set vrf default router bgp address-family ipv4-unicast redistribute connected enable on
nv set vrf default router bgp address-family l2vpn-evpn enable on
nv set vrf default router bgp autonomous-system 63642
nv set vrf default router bgp enable on
nv set vrf default router bgp neighbor p0_sf peer-group fabric
nv set vrf default router bgp neighbor p0_sf type unnumbered
nv set vrf default router bgp neighbor p1_sf peer-group fabric
nv set vrf default router bgp neighbor p1_sf type unnumbered
nv set vrf default router bgp path-selection multipath aspath-ignore on
nv set vrf default router bgp peer-group fabric address-family ipv4-unicast enable on
nv set vrf default router bgp peer-group fabric address-family ipv4-unicast policy outbound route-map MY_ORIGIN_ASPATH_ONLY
nv set vrf default router bgp peer-group fabric address-family ipv6-unicast enable on
nv set vrf default router bgp peer-group fabric address-family ipv6-unicast policy outbound route-map MY_ORIGIN_ASPATH_ONLY
nv set vrf default router bgp peer-group fabric address-family l2vpn-evpn add-path-tx off
nv set vrf default router bgp peer-group fabric address-family l2vpn-evpn enable on
nv set vrf default router bgp peer-group fabric remote-as external
nv set vrf default router bgp router-id 27.0.0.4
nv set interface lo ip address 2001:c000:10ff:f00d::4/128
nv set interface lo ip address 27.0.0.4/32
nv set interface lo type loopback
nv set interface p0_sf,p1_sf,pf0hpf_sf,pf1hpf_sf type swp
nv set interface pf0hpf_sf bridge domain br_default access 200
nv set interface pf1hpf_sf bridge domain br_default access 201
nv set interface vlan200-201 base-interface br_default
nv set interface vlan200-201 ip ipv4 forward on
nv set interface vlan200-201 ip ipv6 forward on
nv set interface vlan200-201 ip vrr enable on
nv set interface vlan200-201 ip vrr state up
nv set interface vlan200-201 link mtu 9050
nv set interface vlan200-201 type svi
nv set interface vlan200 ip address 2001:cafe:1ead::3/64
nv set interface vlan200 ip address 45.3.0.2/24
nv set interface vlan200 ip vrr address 2001:cafe:1ead::1/64
nv set interface vlan200 ip vrr address 45.3.0.1/24
nv set interface vlan200 vlan 200
nv set interface vlan201 ip address 2001:cafe:1ead:1::3/64
nv set interface vlan201 ip address 45.3.1.2/24
nv set interface vlan201 ip vrr address 2001:cafe:1ead:1::1/64
nv set interface vlan201 ip vrr address 45.3.1.1/24
nv set interface vlan201 vlan 201
Sample Flat Files Configuration for L2 EVPN
The following is a sample flat files configuration which has L2-VNIs (vx-2000, vx-2001) for EVPN bridging on DPU.
This file is located at /etc/network/interfaces:
auto lo
iface lo inet loopback
address 2001:c000:10ff:f00d::4/128
address 27.0.0.4/32
vxlan-local-tunnelip 27.0.0.4
auto p0_sf
iface p0_sf
auto p1_sf
iface p1_sf
auto pf0hpf_sf
iface pf0hpf_sf
bridge-access 200
auto pf1hpf_sf
iface pf1hpf_sf
bridge-access 201
auto vlan200
iface vlan200
address 2001:cafe:1ead::3/64
address 45.3.0.2/24
mtu 9050
address-virtual 00:00:5e:00:01:01 2001:cafe:1ead::1/64 45.3.0.1/24
vlan-raw-device br_default
vlan-id 200
auto vlan201
iface vlan201
address 2001:cafe:1ead:1::3/64
address 45.3.1.2/24
mtu 9050
address-virtual 00:00:5e:00:01:01 2001:cafe:1ead:1::1/64 45.3.1.1/24
vlan-raw-device br_default
vlan-id 201
auto vxlan48
iface vxlan48
bridge-vlan-vni-map 200=2000 201=2001
217=2017
bridge-learning off
auto br_default
iface br_default
bridge-ports pf0hpf_sf pf1hpf_sf vxlan48
bridge-vlan-aware yes
bridge-vids 200 201
bridge-pvid 1
This file tells the frr package which daemon to start and is located at /etc/frr/daemons:
bgpd=yes
ospfd=no
ospf6d=no
isisd=no
pimd=no
ldpd=no
pbrd=no
vrrpd=no
fabricd=no
nhrpd=no
eigrpd=no
babeld=no
sharpd=no
fabricd=no
ripngd=no
ripd=no
vtysh_enable=yes
zebra_options=" -M cumulus_mlag -M snmp -A 127.0.0.1 -s 90000000"
bgpd_options=" -M snmp -A 127.0.0.1"
ospfd_options=" -M snmp -A 127.0.0.1"
ospf6d_options=" -M snmp -A ::1"
ripd_options=" -A 127.0.0.1"
ripngd_options=" -A ::1"
isisd_options=" -A 127.0.0.1"
pimd_options=" -A 127.0.0.1"
ldpd_options=" -A 127.0.0.1"
nhrpd_options=" -A 127.0.0.1"
eigrpd_options=" -A 127.0.0.1"
babeld_options=" -A 127.0.0.1"
sharpd_options=" -A 127.0.0.1"
pbrd_options=" -A 127.0.0.1"
staticd_options="-A 127.0.0.1"
fabricd_options="-A 127.0.0.1"
vrrpd_options=" -A 127.0.0.1"
frr_profile="datacenter"
FRR configuration file is located at /etc/frr/frr.conf:
!---- Cumulus Defaults ----
frr defaults datacenter
log syslog informational
no zebra nexthop kernel enable
vrf default
outer bgp 63642 vrf default
bgp router-id 27.0.0.4
bgp bestpath as-path multipath-relax
timers bgp 3 9
bgp deterministic-med
! Neighbors
neighbor fabric peer-group
neighbor fabric remote-as external
neighbor fabric timers 3 9
neighbor fabric timers connect 10
neighbor fabric advertisement-interval 0
neighbor p0_sf interface peer-group fabric
neighbor p1_sf interface peer-group fabric
address-family ipv4 unicast
maximum-paths ibgp 64
maximum-paths 64
distance bgp 20 200 200
neighbor fabric activate
exit-address-family
address-family ipv6 unicast
maximum-paths ibgp 64
maximum-paths 64
distance bgp 20 200 200
neighbor fabric activate
exit-address-family
address-family l2vpn evpn
advertise-all-vni
neighbor fabric activate
exit-address-family
Layer-3 EVPN with Symmetric Routing
In distributed symmetric routing, each VXLAN endpoint (VTEP) acts as a layer-3 gateway, performing routing for its attached hosts. However, both the ingress VTEP and egress VTEP route the packets (similar to traditional routing behavior of routing to a next-hop router). In a VXLAN encapsulated packet, the inner destination MAC address is the router MAC address of the egress VTEP to indicate that the egress VTEP is the next hop and that it must also perform the routing.
All routing happens in the context of a tenant (VRF). For a packet that the ingress VTEP receives from a locally attached host, the SVI interface corresponding to the VLAN determines the VRF. For a packet that the egress VTEP receives over the VXLAN tunnel, the VNI in the packet has to specify the VRF. For symmetric routing, this is a VNI corresponding to the tenant and is different from either the source VNI or the destination VNI. This VNI is a layer-3 VNI or interconnecting VNI. The regular VNI, which maps a VLAN, is the layer-2 VNI.
For more details about this, refer to the Cumulus Linux User Manual .
HBN uses a one-to-one mapping between an L3 VNI and a tenant (VRF).
The VRF to L3 VNI mapping has to be consistent across all VTEPs.
An L3 VNI and an L2 VNI cannot have the same ID.
In an EVPN symmetric routing configuration, when the switch announces a type-2 (MAC/IP) route, in addition to containing two VNIs (L2 and L3 VNIs), the route also contains separate route targets (RTs) for L2 and L3. The L3 RT associates the route with the tenant VRF. By default, this is auto-derived using the L3 VNI instead of the L2 VNI. However, this is configurable.
For EVPN symmetric routing, users must perform the configuration listed in the following subsections. Optional configuration includes configuring a r oute distinguisher ( RD) and RTs for the tenant VRF, and advertising the locally-attached subnets.
Sample NVUE Configuration for L3 EVPN
If using NVUE to configure EVPN symmetric routing, the following is a sample configuration using NVUE commands:
nv set bridge domain br_default vlan 111 vni 1000111
nv set bridge domain br_default vlan 112 vni 1000112
nv set bridge domain br_default vlan 213 vni 1000213
nv set bridge domain br_default vlan 214 vni 1000214
nv set evpn enable on
nv set interface lo ip address 6.0.0.19/32
nv set interface lo type loopback
nv set interface p0_sf description 'alias p0_sf to leaf-21 swp3'
nv set interface p0_sf,p1_sf,pf0hpf_sf,pf0vf0_sf,pf1hpf_sf,pf1vf0_sf type swp
nv set interface p1_sf description 'alias p1_sf to leaf-22 swp3'
nv set interface pf0hpf_sf bridge domain br_default access 111
nv set interface pf0hpf_sf description 'alias pf0hpf_sf to host-211 ens2f0np0'
nv set interface pf0vf0_sf bridge domain br_default access 112
nv set interface pf0vf0_sf description 'alias pf0vf0_sf to host-211 ens2f0np0v0'
nv set interface pf1hpf_sf bridge domain br_default access 213
nv set interface pf1hpf_sf description 'alias pf1hpf_sf to host-211 ens2f1np1'
nv set interface pf1vf0_sf bridge domain br_default access 214
nv set interface pf1vf0_sf description 'alias pf1vf0_sf to host-211 ens2f1np0v0'
nv set interface vlan111 ip address 60.1.1.21/24
nv set interface vlan111 ip address 2060:1:1:1::21/64
nv set interface vlan111 ip vrr address 60.1.1.250/24
nv set interface vlan111 ip vrr address 2060:1:1:1::250/64
nv set interface vlan111 vlan 111
nv set interface vlan111,213 ip vrf vrf2
nv set interface vlan111-112,213-214 ip vrr enable on
nv set interface vlan111-112,213-214 ip vrr mac-address 00:00:5e:00:01:01
nv set interface vlan111-112,213-214 ip ipv4 forward on
nv set interface vlan111-112,213-214 ip ipv6 forward on
nv set interface vlan111-112,213-214 type svi
nv set interface vlan112 ip address 50.1.1.21/24
nv set interface vlan112 ip address 2050:1:1:1::21/64
nv set interface vlan112 ip vrr address 50.1.1.250/24
nv set interface vlan112 ip vrr address 2050:1:1:1::250/64
nv set interface vlan112 vlan 112
nv set interface vlan112,214 ip vrf vrf1
nv set interface vlan213 ip address 60.1.210.21/24
nv set interface vlan213 ip address 2060:1:1:210::21/64
nv set interface vlan213 ip vrr address 60.1.210.250/24
nv set interface vlan213 ip vrr address 2060:1:1:210::250/64
nv set interface vlan213 vlan 213
nv set interface vlan214 ip address 50.1.210.21/24
nv set interface vlan214 ip address 2050:1:1:210::21/64
nv set interface vlan214 ip vrr address 50.1.210.250/24
nv set interface vlan214 ip vrr address 2050:1:1:210::250/64
nv set interface vlan214 vlan 214
nv set nve vxlan arp-nd-suppress on
nv set nve vxlan enable on
nv set nve vxlan source address 6.0.0.19
nv set platform
nv set router bgp enable on
nv set router policy route-map ALLOW_LOBR rule 10 action permit
nv set router policy route-map ALLOW_LOBR rule 10 match interface lo
nv set router policy route-map ALLOW_LOBR rule 20 action permit
nv set router policy route-map ALLOW_LOBR rule 20 match interface br_default
nv set router policy route-map ALLOW_VRF1 rule 10 action permit
nv set router policy route-map ALLOW_VRF1 rule 10 match interface vrf1
nv set router policy route-map ALLOW_VRF2 rule 10 action permit
nv set router policy route-map ALLOW_VRF2 rule 10 match interface vrf2
nv set router vrr enable on
nv set system global system-mac 00:01:00:00:1e:03
nv set vrf default router bgp address-family ipv4-unicast enable on
nv set vrf default router bgp address-family ipv4-unicast multipaths ebgp 16
nv set vrf default router bgp address-family ipv4-unicast redistribute connected enable on
nv set vrf default router bgp address-family ipv4-unicast redistribute connected route-map ALLOW_LOBR
nv set vrf default router bgp address-family l2vpn-evpn enable on
nv set vrf default router bgp autonomous-system 650019
nv set vrf default router bgp enable on
nv set vrf default router bgp neighbor p0_sf address-family l2vpn-evpn add-path-tx off
nv set vrf default router bgp neighbor p0_sf address-family l2vpn-evpn enable on
nv set vrf default router bgp neighbor p0_sf peer-group TOR_LEAF_SPINE
nv set vrf default router bgp neighbor p0_sf remote-as external
nv set vrf default router bgp neighbor p0_sf type unnumbered
nv set vrf default router bgp neighbor p1_sf address-family l2vpn-evpn add-path-tx off
nv set vrf default router bgp neighbor p1_sf address-family l2vpn-evpn enable on
nv set vrf default router bgp neighbor p1_sf peer-group TOR_LEAF_SPINE
nv set vrf default router bgp neighbor p1_sf remote-as external
nv set vrf default router bgp neighbor p1_sf type unnumbered
nv set vrf default router bgp path-selection multipath aspath-ignore on
nv set vrf default router bgp path-selection routerid-compare on
nv set vrf default router bgp peer-group TOR_LEAF_SPINE address-family ipv4-unicast enable on
nv set vrf default router bgp router-id 6.0.0.19
nv set vrf vrf1 evpn enable on
nv set vrf vrf1 evpn vni 104001
nv set vrf vrf1 loopback ip address 50.1.21.21/32
nv set vrf vrf1 loopback ip address 2050:50:50:21::21/128
nv set vrf vrf1 router bgp address-family ipv4-unicast enable on
nv set vrf vrf1 router bgp address-family ipv4-unicast redistribute connected enable on
nv set vrf vrf1 router bgp address-family ipv4-unicast redistribute connected route-map ALLOW_VRF1
nv set vrf vrf1 router bgp address-family ipv4-unicast route-export to-evpn enable on
nv set vrf vrf1 router bgp address-family ipv6-unicast enable on
nv set vrf vrf1 router bgp address-family ipv6-unicast redistribute connected enable on
nv set vrf vrf1 router bgp address-family ipv6-unicast redistribute connected route-map ALLOW_VRF1
nv set vrf vrf1 router bgp address-family ipv6-unicast route-export to-evpn enable on
nv set vrf vrf1 router bgp autonomous-system 650019
nv set vrf vrf1 router bgp enable on
nv set vrf vrf1 router bgp router-id 50.1.21.21
nv set vrf vrf2 evpn enable on
nv set vrf vrf2 evpn vni 104002
nv set vrf vrf2 loopback ip address 60.1.21.21/32
nv set vrf vrf2 loopback ip address 2060:60:60:21::21/128
nv set vrf vrf2 router bgp address-family ipv4-unicast enable on
nv set vrf vrf2 router bgp address-family ipv4-unicast redistribute connected enable on
nv set vrf vrf2 router bgp address-family ipv4-unicast redistribute connected route-map ALLOW_VRF2
nv set vrf vrf2 router bgp address-family ipv4-unicast route-export to-evpn enable on
nv set vrf vrf2 router bgp address-family ipv6-unicast enable on
nv set vrf vrf2 router bgp address-family ipv6-unicast redistribute connected enable on
nv set vrf vrf2 router bgp address-family ipv6-unicast redistribute connected route-map ALLOW_VRF2
nv set vrf vrf2 router bgp address-family ipv6-unicast route-export to-evpn enable on
nv set vrf vrf2 router bgp autonomous-system 650019
nv set vrf vrf2 router bgp enable on
nv set vrf vrf2 router bgp router-id 60.1.21.21
Sample Flat Files Configuration for L3 EVPN
The following is a sample flat files configuration which has L2 VNIs and L3 VNIs for EVPN bridging and symmetric routing on DPU.
This file is located at /etc/network/interfaces:
auto lo
iface lo inet loopback
address 6.0.0.19/32
vxlan-local-tunnelip 6.0.0.19
auto vrf1
iface vrf1
address 2050:50:50:21::21/128
address 50.1.21.21/32
vrf-table auto
auto vrf2
iface vrf2
address 2060:60:60:21::21/128
address 60.1.21.21/32
vrf-table auto
auto p0_sf
iface p0_sf
alias alias p0_sf to leaf-21 swp3
auto p1_sf
iface p1_sf
alias alias p1_sf to leaf-22 swp3
auto pf0hpf_sf
iface pf0hpf_sf
alias alias pf0hpf_sf to host-211 ens2f0np0
bridge-access 111
auto pf0vf0_sf
iface pf0vf0_sf
alias alias pf0vf0_sf to host-211 ens2f0np0v0
bridge-access 112
auto pf1hpf_sf
iface pf1hpf_sf
alias alias pf1hpf_sf to host-211 ens2f1np1
bridge-access 213
auto pf1vf0_sf
iface pf1vf0_sf
alias alias pf1vf0_sf to host-211 ens2f1np0v0
bridge-access 214
auto vlan111
iface vlan111
address 2060:1:1:1::21/64
address 60.1.1.21/24
address-virtual 00:00:5e:00:01:01 2060:1:1:1::250/64 60.1.1.250/24
hwaddress 00:01:00:00:1e:03
vrf vrf2
vlan-raw-device br_default
vlan-id 111
auto vlan112
iface vlan112
address 2050:1:1:1::21/64
address 50.1.1.21/24
address-virtual 00:00:5e:00:01:01 2050:1:1:1::250/64 50.1.1.250/24
hwaddress 00:01:00:00:1e:03
vrf vrf1
vlan-raw-device br_default
vlan-id 112
auto vlan213
iface vlan213
address 2060:1:1:210::21/64
address 60.1.210.21/24
address-virtual 00:00:5e:00:01:01 2060:1:1:210::250/64 60.1.210.250/24
hwaddress 00:01:00:00:1e:03
vrf vrf2
vlan-raw-device br_default
vlan-id 213
auto vlan214
iface vlan214
address 2050:1:1:210::21/64
address 50.1.210.21/24
address-virtual 00:00:5e:00:01:01 2050:1:1:210::250/64 50.1.210.250/24
hwaddress 00:01:00:00:1e:03
vrf vrf1
vlan-raw-device br_default
vlan-id 214
auto vlan4058_l3
iface vlan4058_l3
vrf vrf1
vlan-raw-device br_default
address-virtual none
vlan-id 4058
auto vlan4059_l3
iface vlan4059_l3
vrf vrf2
vlan-raw-device br_default
address-virtual none
vlan-id 4059
auto vxlan48
iface vxlan48
bridge-vlan-vni-map 111=1000111 112=1000112 213=1000213 214=1000214 4058=104001 4059=104002
bridge-learning off
auto br_default
iface br_default
bridge-ports pf0hpf_sf pf0vf0_sf pf1hpf_sf pf1vf0_sf vxlan48
hwaddress 00:01:00:00:1e:03
bridge-vlan-aware yes
bridge-vids 111 112 213 214
bridge-pvid 1
FRR configuration is located at /etc/frr/frr.conf:
frr version 8.4.3
frr defaults datacenter
hostname doca-hbn-service-bf3-s05-1-ipmi
log syslog informational
no zebra nexthop kernel enable
service integrated-vtysh-config
!
vrf vrf1
vni 104001
exit-vrf
!
vrf vrf2
vni 104002
exit-vrf
!
router bgp 650019
bgp router-id 6.0.0.19
bgp bestpath as-path multipath-relax
bgp bestpath compare-routerid
neighbor TOR_LEAF_SPINE peer-group
neighbor TOR_LEAF_SPINE advertisement-interval 0
neighbor TOR_LEAF_SPINE timers 3 9
neighbor TOR_LEAF_SPINE timers connect 10
neighbor p0_sf interface peer-group TOR_LEAF_SPINE
neighbor p0_sf remote-as external
neighbor p0_sf advertisement-interval 0
neighbor p0_sf timers 3 9
neighbor p0_sf timers connect 10
neighbor p1_sf interface peer-group TOR_LEAF_SPINE
neighbor p1_sf remote-as external
neighbor p1_sf advertisement-interval 0
neighbor p1_sf timers 3 9
neighbor p1_sf timers connect 10
!
address-family ipv4 unicast
redistribute connected route-map ALLOW_LOBR
maximum-paths 16
maximum-paths ibgp 64
exit-address-family
!
address-family l2vpn evpn
neighbor p0_sf activate
neighbor p1_sf activate
advertise-all-vni
exit-address-family
exit
!
router bgp 650019 vrf vrf1
bgp router-id 50.1.21.21
!
address-family ipv4 unicast
redistribute connected route-map ALLOW_VRF1
maximum-paths 64
maximum-paths ibgp 64
exit-address-family
!
address-family ipv6 unicast
redistribute connected route-map ALLOW_VRF1
maximum-paths 64
maximum-paths ibgp 64
exit-address-family
!
address-family l2vpn evpn
advertise ipv4 unicast
advertise ipv6 unicast
exit-address-family
exit
!
router bgp 650019 vrf vrf2
bgp router-id 60.1.21.21
!
address-family ipv4 unicast
redistribute connected route-map ALLOW_VRF2
maximum-paths 64
maximum-paths ibgp 64
exit-address-family
!
address-family ipv6 unicast
redistribute connected route-map ALLOW_VRF2
maximum-paths 64
maximum-paths ibgp 64
exit-address-family
!
address-family l2vpn evpn
advertise ipv4 unicast
advertise ipv6 unicast
exit-address-family
exit
!
route-map ALLOW_LOBR permit 10
match interface lo
exit
!
route-map ALLOW_LOBR permit 20
match interface br_default
exit
!
route-map ALLOW_VRF1 permit 10
match interface vrf1
exit
!
route-map ALLOW_VRF2 permit 10
match interface vrf2
exit
Multihop eBGP Peering for EVPN (Route Server in Symmetric EVPN Routing)
eBGP multihop peering for EVPN support in a route server-like role in EVPN topology, allows the deployment of EVPN on any cloud that supports IP transport.
R oute servers and BF/HBN VTEPs are connected via the IP cloud. That is:
Switches in the cloud provider need not be EVPN-aware
Switches in the provider fabric provide IPv4 and IPv6 transport and do not have to support EVPN
Sample Route Server Configuration for EVPN
The following is a sample configuration of an Ubuntu server running frr 9.0 stable, configured as EVPN route server and an HBN VTEP that is peering to two spine switches for IP connectivity and 3 Route servers for EVPN overlay control.
root@sn1:/home/cumulus# uname -a
Linux sn1 5.15.0-88-generic #98-Ubuntu SMP Mon Oct 2 15:18:56 UTC 2023 x86_64 x86_64 x86_64 GNU/Linux
root@sn1:/home/cumulus# dpkg -l frr
Desired=Unknown/Install/Remove/Purge/Hold
| Status=Not/Inst/Conf-files/Unpacked/halF-conf/Half-inst/trig-aWait/Trig-pend
|/ Err?=(none)/Reinst-required (Status,Err: uppercase=bad)
||/ Name Version Architecture Description
+++-==============-=====================-============-=============================================================
ii frr 9.0.1-0~ubuntu22.04.1 amd64 FRRouting suite of internet protocols (BGP, OSPF, IS-IS, ...)
root@sn1:/home/cumulus#
FRR configuration (frr.conf):
sn1# sh run
Building configuration...
Current configuration:
!
frr version 9.0.1
frr defaults datacenter
hostname sn1
no ip forwarding
no ipv6 forwarding
service integrated-vtysh-config
!
router bgp 4200065507
bgp router-id 6.0.0.7
timers bgp 60 180
neighbor rclients peer-group
neighbor rclients remote-as external
neighbor rclients ebgp-multihop 10
neighbor rclients update-source lo
neighbor rclients advertisement-interval 0
neighbor rclients timers 3 9
neighbor rclients timers connect 10
neighbor rcsuper peer-group
neighbor rcsuper remote-as external
neighbor rcsuper advertisement-interval 0
neighbor rcsuper timers 3 9
neighbor rcsuper timers connect 10
neighbor swp1 interface peer-group rcsuper
bgp listen range 6.0.0.0/24 peer-group rclients
!
address-family ipv4 unicast
redistribute connected
neighbor fabric route-map pass in
neighbor fabric route-map pass out
no neighbor rclients activate
maximum-paths 64
maximum-paths ibgp 64
exit-address-family
!
address-family l2vpn evpn
neighbor rclients activate
neighbor rcsuper activate
exit-address-family
exit
!
route-map pass permit 10
set community 11:11 additive
exit
!
end
sn1#
Interfaces configuration (/etc/network/interfaces):
root@sn1:/home/cumulus# ifquery -a
auto lo
iface lo inet loopback
address 6.0.0.7/32
auto lo
iface lo inet loopback
auto swp1
iface swp1
auto eth0
iface eth0
address 192.168.0.15/24
gateway 192.168.0.2
root@sn1:/home/cumulus#
Sample HBN configuration for deployments with EVPN Route Server
root@doca-hbn-service-bf2-s12-1-ipmi:/tmp# nv config show -o commands
nv set bridge domain br_default vlan 101 vni 10101
nv set bridge domain br_default vlan 102 vni 10102
nv set bridge domain br_default vlan 201 vni 10201
nv set bridge domain br_default vlan 202 vni 10202
nv set evpn enable on
nv set evpn route-advertise svi-ip off
nv set interface ilan3200 ip vrf internet1
nv set interface ilan3200 vlan 3200
nv set interface ilan3200,slan3201,vlan101-102,201-202,3001-3002 base-interface br_default
nv set interface ilan3200,slan3201,vlan101-102,201-202,3001-3002 type svi
nv set interface lo ip address 6.0.0.13/32
nv set interface lo ip address 2001::13/128
nv set interface lo type loopback
nv set interface p0_sf,p1_sf,pf0hpf_sf,pf0vf0_sf,pf0vf1_sf,pf0vf2_sf,pf0vf3_sf,pf0vf4_sf,pf0vf5_sf,pf0vf6_sf,pf0vf7_sf,pf0vf8_sf,pf0vf9_sf,pf1hpf_sf,pf1vf0_sf,pf1vf1_sf type swp
nv set interface pf0vf0_sf bridge domain br_default access 101
nv set interface pf0vf1_sf bridge domain br_default access 102
nv set interface pf0vf2_sf bridge domain br_default access 201
nv set interface pf0vf3_sf bridge domain br_default access 202
nv set interface slan3201 ip vrf special1
nv set interface slan3201 vlan 3201
nv set interface vlan101 ip address 21.1.0.13/16
nv set interface vlan101 ip address 2020:0:1:1::13/64
nv set interface vlan101 ip vrr address 21.1.0.250/16
nv set interface vlan101 ip vrr address 2020:0:1:1::250/64
nv set interface vlan101 ip vrr mac-address 00:00:01:00:00:65
nv set interface vlan101 vlan 101
nv set interface vlan101-102,201-202 ip vrr enable on
nv set interface vlan101-102,3001 ip vrf tenant1
nv set interface vlan102 ip address 21.2.0.13/16
nv set interface vlan102 ip address 2020:0:1:2::13/64
nv set interface vlan102 ip vrr address 21.2.0.250/16
nv set interface vlan102 ip vrr address 2020:0:1:2::250/64
nv set interface vlan102 ip vrr mac-address 00:00:01:00:00:66
nv set interface vlan102 vlan 102
nv set interface vlan201 ip address 22.1.0.13/16
nv set interface vlan201 ip address 2020:0:2:1::13/64
nv set interface vlan201 ip vrr address 22.1.0.250/16
nv set interface vlan201 ip vrr address 2020:0:2:1::250/64
nv set interface vlan201 ip vrr mac-address 00:00:02:00:00:c9
nv set interface vlan201 vlan 201
nv set interface vlan201-202,3002 ip vrf tenant2
nv set interface vlan202 ip address 22.2.0.13/16
nv set interface vlan202 ip address 2020:0:2:2::13/64
nv set interface vlan202 ip vrr address 22.2.0.250/16
nv set interface vlan202 ip vrr address 2020:0:2:2::250/64
nv set interface vlan202 ip vrr mac-address 00:00:02:00:00:ca
nv set interface vlan202 vlan 202
nv set interface vlan3001 vlan 3001
nv set interface vlan3002 vlan 3002
nv set nve vxlan arp-nd-suppress on
nv set nve vxlan enable on
nv set nve vxlan source address 6.0.0.13
nv set platform
nv set router bgp autonomous-system 4200065011
nv set router bgp enable on
nv set router bgp router-id 6.0.0.13
nv set router vrr enable on
nv set system config snippet
nv set system global
nv set vrf default router bgp address-family ipv4-unicast enable on
nv set vrf default router bgp address-family ipv4-unicast redistribute connected enable on
nv set vrf default router bgp address-family ipv6-unicast enable on
nv set vrf default router bgp address-family l2vpn-evpn enable on
nv set vrf default router bgp enable on
nv set vrf default router bgp neighbor 6.0.0.7 peer-group rservers
nv set vrf default router bgp neighbor 6.0.0.7 type numbered
nv set vrf default router bgp neighbor 6.0.0.8 peer-group rservers
nv set vrf default router bgp neighbor 6.0.0.8 type numbered
nv set vrf default router bgp neighbor 6.0.0.9 peer-group rservers
nv set vrf default router bgp neighbor 6.0.0.9 type numbered
nv set vrf default router bgp neighbor p0_sf peer-group fabric
nv set vrf default router bgp neighbor p0_sf type unnumbered
nv set vrf default router bgp neighbor p1_sf peer-group fabric
nv set vrf default router bgp neighbor p1_sf type unnumbered
nv set vrf default router bgp peer-group fabric address-family ipv4-unicast enable on
nv set vrf default router bgp peer-group fabric address-family ipv6-unicast enable on
nv set vrf default router bgp peer-group fabric remote-as external
nv set vrf default router bgp peer-group rservers address-family ipv4-unicast enable off
nv set vrf default router bgp peer-group rservers address-family l2vpn-evpn add-path-tx off
nv set vrf default router bgp peer-group rservers address-family l2vpn-evpn enable on
nv set vrf default router bgp peer-group rservers multihop-ttl 3
nv set vrf default router bgp peer-group rservers remote-as external
nv set vrf default router bgp peer-group rservers update-source lo
nv set vrf internet1 evpn enable on
nv set vrf internet1 evpn vni 42000
nv set vrf internet1 loopback ip address 8.1.0.13/32
nv set vrf internet1 loopback ip address 2008:0:1::13/64
nv set vrf internet1 router bgp address-family ipv4-unicast enable on
nv set vrf internet1 router bgp address-family ipv4-unicast redistribute connected enable on
nv set vrf internet1 router bgp address-family ipv4-unicast route-export to-evpn enable on
nv set vrf internet1 router bgp enable on
nv set vrf special1 evpn enable on
nv set vrf special1 evpn vni 42001
nv set vrf special1 loopback ip address 9.1.0.13/32
nv set vrf special1 loopback ip address 2009:0:1::13/64
nv set vrf special1 router bgp address-family ipv4-unicast enable on
nv set vrf special1 router bgp address-family ipv4-unicast redistribute connected enable on
nv set vrf special1 router bgp address-family ipv4-unicast route-export to-evpn enable on
nv set vrf special1 router bgp enable on
nv set vrf tenant1 evpn enable on
nv set vrf tenant1 evpn vni 30001
nv set vrf tenant1 router bgp address-family ipv4-unicast enable on
nv set vrf tenant1 router bgp address-family ipv4-unicast redistribute connected enable on
nv set vrf tenant1 router bgp address-family ipv4-unicast route-export to-evpn enable on
nv set vrf tenant1 router bgp enable on
nv set vrf tenant1 router bgp router-id 6.0.0.13
nv set vrf tenant2 evpn enable on
nv set vrf tenant2 evpn vni 30002
nv set vrf tenant2 router bgp address-family ipv4-unicast enable on
nv set vrf tenant2 router bgp address-family ipv4-unicast redistribute connected enable on
nv set vrf tenant2 router bgp address-family ipv4-unicast route-export to-evpn enable on
nv set vrf tenant2 router bgp enable on
nv set vrf tenant2 router bgp router-id 6.0.0.13
root@doca-hbn-service-bf2-s12-1-ipmi:/tmp#
Verifying BGP sessions in HBN:
doca-hbn-service-bf2-s12-1-ipmi# sh bgp sum
IPv4 Unicast Summary (VRF default):
BGP router identifier 6.0.0.13, local AS number 4200065011 vrf-id 0
BGP table version 20
RIB entries 21, using 4032 bytes of memory
Peers 2, using 40 KiB of memory
Peer groups 2, using 128 bytes of memory
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd PfxSnt Desc
spine11(p0_sf) 4 65201 30617 30620 0 0 0 1d01h30m 9 11 N/A
spine12(p1_sf) 4 65201 30620 30623 0 0 0 1d01h30m 9 11 N/A
Total number of neighbors 2
IPv6 Unicast Summary (VRF default):
BGP router identifier 6.0.0.13, local AS number 4200065011 vrf-id 0
BGP table version 0
RIB entries 0, using 0 bytes of memory
Peers 2, using 40 KiB of memory
Peer groups 2, using 128 bytes of memory
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd PfxSnt Desc
spine11(p0_sf) 4 65201 30617 30620 0 0 0 1d01h30m 0 0 N/A
spine12(p1_sf) 4 65201 30620 30623 0 0 0 1d01h30m 0 0 N/A
Total number of neighbors 2
L2VPN EVPN Summary (VRF default):
BGP router identifier 6.0.0.13, local AS number 4200065011 vrf-id 0
BGP table version 0
RIB entries 79, using 15 KiB of memory
Peers 3, using 60 KiB of memory
Peer groups 2, using 128 bytes of memory
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd PfxSnt Desc
sn1(6.0.0.7) 4 4200065507 31410 31231 0 0 0 00:27:51 69 95 N/A
sn2(6.0.0.8) 4 4200065508 31169 31062 0 0 0 02:34:47 69 95 N/A
sn3(6.0.0.9) 4 4200065509 31285 31059 0 0 0 02:34:47 69 95 N/A
Total number of neighbors 3
doca-hbn-service-bf2-s12-1-ipmi#
The command output shows that the HBN has BGP sessions with spine switches exchanging IPv4/IPv6 unicast. BGP sessions with route servers sn1, sn2, and sn3 only exchanging L2VPN EVPN AFI/SAFI.
Access Control Lists
Access Control Lists (ACLs) are a set of rules that are used to filter network traffic. These rules are used to specify the traffic flows that must be permitted or blocked at networking device interfaces. There are two types of ACLs:
Stateless ACLs – rules that are applied to individual packets. They inspect each packet individually and permit/block the packets based on the packet header information and the match criteria specified by the rule.
Stateful ACLs – rules that are applied to traffic sessions/connections. They inspect each packet with respect to the state of the session/connection to which the packet belongs to determine whether to permit/block the packet.
Stateless ACLs
HBN supports configuration of stateless ACLs for IPv4 packets, IPv6 packets, and Ethernet (MAC) frames. The following examples depict how stateless ACLs are configured for each case, with NVUE and with flat files (cl-acltool).
NVUE Examples for Stateless ACLs
NVUE IPv4 ACLs Example
The following is an example of an ingress IPv4 ACL that permits DHCP request packets ingressing on the pf0hpf_sf port towards the DHCP server:
root@hbn01-host01:~# nv set acl acl1_ingress type ipv4
root@hbn01-host01:~# nv set acl acl1_ingress rule 100 match ip protocol udp
root@hbn01-host01:~# nv set acl acl1_ingress rule 100 match ip dest-port 67
root@hbn01-host01:~# nv set acl acl1_ingress rule 100 match ip source-port 68
root@hbn01-host01:~# nv set acl acl1_ingress rule 100 action permit
Bind the ingress IPv4 ACL to host representor port pf0hpf_sf of the DPU in the inbound direction:
root@hbn01-host01:~# nv set interface pf0hpf_sf acl acl1_ingress inbound
root@hbn01-host01:~# nv config apply
The following is an example of an egress IPv4 ACL that permits DHCP reply packets egressing out of the pf0hpf_sf port towards the DHCP client:
root@hbn01-host01:~# nv set acl acl2_egress type ipv4
root@hbn01-host01:~# nv set acl acl2_egress rule 200 match ip protocol udp
root@hbn01-host01:~# nv set acl acl2_egress rule 200 match ip dest-port 68
root@hbn01-host01:~# nv set acl acl2_egress rule 200 match ip source-port 67
root@hbn01-host01:~# nv set acl acl2_egress rule 200 action permit
Bind the egress IPv4 ACL to host representor port pf0hpf_sf of the DPU in the outbound direction:
root@hbn01-host01:~# nv set interface pf0hpf_sf acl acl2_egress outbound
root@hbn01-host01:~# nv config apply
NVUE IPv6 ACLs Example
The following is an example of an ingress IPv6 ACL that permits traffic with matching dest-ip and protocol tcp ingress on port pf0hpf_sf:
root@hbn01-host01:~# nv set acl acl5_ingress type ipv6
root@hbn01-host01:~# nv set acl acl5_ingress rule 100 match ip protocol tcp
root@hbn01-host01:~# nv set acl acl5_ingress rule 100 match ip dest-ip 48:2034::80:9
root@hbn01-host01:~# nv set acl acl5_ingress rule 100 action permit
Bind the ingress IPv6 ACL to host representor port pf0hpf_sf of the DPU in the inbound direction:
root@hbn01-host01:~# nv set interface pf0hpf_sf acl acl5_ingress inbound
root@hbn01-host01:~# nv config apply
The following is an example of an egress IPv6 ACL that permits traffic with matching source-ip and protocol tcp egressing out of port pf0hpf_sf:
root@hbn01-host01:~# nv set acl acl6_egress type ipv6
root@hbn01-host01:~# nv set acl acl6_egress rule 101 match ip protocol tcp
root@hbn01-host01:~# nv set acl acl6_egress rule 101 match ip source-ip 48:2034::80:9
root@hbn01-host01:~# nv set acl acl6_egress rule 101 action permit
Bind the egress IPv6 ACL to host representor port pf0hpf_sf of the DPU in the outbound direction:
root@hbn01-host01:~# nv set interface pf0hpf_sf acl acl6_egress outbound
root@hbn01-host01:~# nv config apply
NVUE MAC ACLs Example
The following is an example of an ingress MAC ACL that permits traffic with matching source-mac and dest-mac ingressing to port pf0hpf_sf:
root@hbn01-host01:~# nv set acl acl3_ingress type mac
root@hbn01-host01:~# nv set acl acl3_ingress rule 1 match mac source-mac 00:00:00:00:00:0a
root@hbn01-host01:~# nv set acl acl3_ingress rule 1 match mac dest-mac 00:00:00:00:00:0b
root@hbn01-host01:~# nv set interface pf0hpf_sf acl acl3_ingress inbound
Bind the ingress MAC ACL to host representor port pf0hpf_sf of the DPU in the inbound direction:
root@hbn01-host01:~# nv set interface pf0hpf_sf acl acl3_ingress inbound
root@hbn01-host01:~# nv config apply
The following is an example of an egress MAC ACL that permits traffic with matching source-mac and dest-mac egressing out of port pf0hpf_sf:
root@hbn01-host01:~# nv set acl acl4_egress type mac
root@hbn01-host01:~# nv set acl acl4_egress rule 2 match mac source-mac 00:00:00:00:00:0b
root@hbn01-host01:~# nv set acl acl4_egress rule 2 match mac dest-mac 00:00:00:00:00:0a
root@hbn01-host01:~# nv set acl acl4_egress rule 2 action permit
Bind the egress MAC ACL to host representor port pf0hpf_sf of the DPU in the outbound direction:
root@hbn01-host01:~# nv set interface pf0hpf_sf acl acl4_egress outbound
root@hbn01-host01:~# nv config apply
Flat Files (cl-acltool) Examples for Stateless ACLs
For the same examples cited above, the following are the corresponding ACL rules which must be configured under /etc/cumulus/acl/policy.d/<rule_name.rules> followed by invoking cl-acltool -i. The rules in /etc/cumulus/acl/policy.d/<rule_name.rules> are configured using Linux iptables/ip6tables/ebtables.
Flat Files IPv4 ACLs Example
The following example configures an ingress IPv4 ACL rule matching with DHCP request under /etc/cumulus/acl/policy.d/<rule_name.rules> with the ingress interface as the host representor of the DPU followed by invoking cl-acltool -i:
[iptables]
## ACL acl1_ingress in dir inbound on interface pf0hpf_sf ##
-t filter -A FORWARD -m physdev --physdev-in pf1vf1_sf -p udp --sport 68 --dport 67 -j ACCEPT
The following example configures an egress IPv4 ACL rule matching with DHCP reply under /etc/cumulus/acl/policy.d/<rule_name.rules> with the egress interface as the host representor of the DPU followed by invoking cl-acltool -i:
[iptables]
## ACL acl2_egress in dir outbound on interface pf0hpf_sf ##
-t filter -A FORWARD -m physdev --physdev-out pf0hpf_sf -p udp --sport 67 --dport 68 -j ACCEPT
Flat File IPv6 ACLs Example
The following example configures an ingress IPv6 ACL rule matching with dest-ip and tcp protocol under /etc/cumulus/acl/policy.d/<rule_name.rules> with the ingress interface as the host representor of the DPU followed by invoking cl-acltool -i:
[ip6tables]
## ACL acl5_ingress in dir inbound on interface pf0hpf_sf ##
-t filter -A FORWARD -m physdev --physdev-in pf0hpf_sf -d 48:2034::80:9 -p tcp -j ACCEPT
The following example configures an egress IPv6 ACL rule matching with source-ip and tcp protocol under /etc/cumulus/acl/policy.d/<rule_name.rules> with the egress interface as the host representor of the DPU followed by invoking cl-acltool -i:
[ip6tables]
## ACL acl6_egress in dir outbound on interface pf0hpf_sf ##
-t filter -A FORWARD -m physdev --physdev-out pf0hpf_sf -s 48:2034::80:9 -p tcp -j ACCEPT
Flat Files MAC ACLs Example
The following example configures an ingress MAC ACL rule matching with source-mac and dest-mac under /etc/cumulus/acl/policy.d/<rule_name.rules> with the ingress interface as the host representor of the DPU followed by invoking cl-acltool -i:
[ebtables]
## ACL acl3_ingress in dir inbound on interface pf0hpf_sf ##
-t filter -A FORWARD -m physdev --physdev-in pf0hpf_sf -s 00:00:00:00:00:0a/ff:ff:ff:ff:ff:ff -d 00:00:00:00:00:0b/ff:ff:ff:ff:ff:ff -j ACCEPT
The following example configures an egress MAC ACL rule matching with source-mac and dest-mac under /etc/cumulus/acl/policy.d/<rule_name.rules> with egress interface as host representor of DPU followed by invoking cl-acltool -i:
[ebtables]
## ACL acl4_egress in dir outbound on interface pf0hpf_sf ##
-t filter -A FORWARD -m physdev --physdev-out pf0hpf_sf -s 00:00:00:00:00:0b/ff:ff:ff:ff:ff:ff -d 00:00:00:00:00:0a/ff:ff:ff:ff:ff:ff -j ACCEPT
Stateful ACLs
Stateful ACLs facilitate monitoring and tracking traffic flows to enforce per-flow traffic filtering (unlike stateless ACLs which filter traffic on a per-packet basis). HBN supports stateful ACLs using reflexive ACL mechanism. Reflexive ACL mechanism is used to allow initiation of connections from "within" the network to "outside" the network and allow only replies to the initiated connections from "outside" the network (or vice versa).
HBN supports stateful ACL configuration for IPv4 traffic.
Stateful ACLs can be applied for native routed traffic (north-south underlay routed traffic in EVPN deployments) or bridged traffic (east-west overlay bridged/L2 traffic in EVPN deployments). Stateful ACLs applied for native routed traffic are called "L3 stateful ACLs" and for EVPN bridged traffic are called "EVPN-L2 stateful ACLs".
Stateful ACLs in HBN are disabled by default. To enable stateful ACL functionality, use the following NVUE commands:
root@hbn03-host00:~# nv set system reflexive-acl enable
root@hbn03-host00:~# nv config apply
If using flat-file configuration (and not NVUE), edit the file /etc/cumulus/nl2docad.d/acl.conf and set the knob rflx.reflexive_acl_enable to TRUE. To apply this change, execute:
root@hbn03-host00:~# supervisorctl start nl2doca-reload
NVUE Example for L3 Stateful ACLs
The following is an example of allowing HTTP (TCP) connection originated by the host, where the DPU is hosted, to an HTTP server (with the IP address 11.11.11.11) on an external network. Two sets of ACLs matching with CONNTRACK state must be configured for a CONNTRACK entry to be established in the kernel which would be offloaded to hardware:
Configure an ACL rule matching TCP/HTTP connection/flow details with CONNTRACK state of NEW, ESTABLISHED and bind it to the SVI in the inbound direction.
Configure an ACL rule matching TCP/HTTP connection/flow details with CONNTRACK state of ESTABLISHED and bind it to the SVI in the outbound direction.
In this example, SVI interface is vlan101.
Configure the ingress ACL rule:
root@hbn03-host00:~# nv set acl allow_tcp_conn_from_host rule 11 action permit root@hbn03-host00:~# nv set acl allow_tcp_conn_from_host rule 11 match conntrack new root@hbn03-host00:~# nv set acl allow_tcp_conn_from_host rule 11 match conntrack established root@hbn03-host00:~# nv set acl allow_tcp_conn_from_host rule 11 match ip dest-ip 11.11.11.11/32 root@hbn03-host00:~# nv set acl allow_tcp_conn_from_host rule 11 match ip dest-port 80 root@hbn03-host00:~# nv set acl allow_tcp_conn_from_host rule 11 match ip protocol tcp root@hbn03-host00:~# nv set acl allow_tcp_conn_from_host type ipv4
Bind this ACL to the SVI interface in the inbound direction:
root@hbn03-host00:~# nv set interface vlan101 acl allow_tcp_conn_from_host inbound root@hbn03-host00:~# nv config apply
Configure the egress ACL rule:
root@hbn03-host00:~# nv set acl allow_tcp_resp_from_server rule 21 action permit root@hbn03-host00:~# nv set acl allow_tcp_resp_from_server rule 21 match conntrack established root@hbn03-host00:~# nv set acl allow_tcp_resp_from_server rule 21 match ip protocol tcp root@hbn03-host00:~# nv set acl allow_tcp_resp_from_server type ipv4 root@hbn03-host00:~# nv config apply
Bind this ACL to the SVI interface in the outbound direction:
root@hbn03-host00:~# nv set interface vlan101 acl allow_tcp_resp_from_server outbound root@hbn03-host00:~# nv config apply
NoteIf virtual router redundancy (VRR) is set, L3 stateful ACLs must be bound to all the related SVI interfaces. For example, if VRR is configured on SVI vlan101 as follows in the /etc/network/interfaces file:
auto vlan101 iface vlan101 address
45.3.1.2/24address-virtual00:00:5e:00:01:0145.3.1.1/24vlan-raw-device br_default vlan-id101With this configuration, two SVI interfaces, vlan101 and vlan101-v0 would be created in the system:
root@hbn03-host00:~# ip -br addr show | grep vlan101 vlan101@br_default UP 45.3.1.2/24 fe80::204:4bff:fe8a:f100/64 vlan101-v0@vlan101 UP 45.3.1.1/24 metric 1024 fe80::200:5eff:fe00:101/64
In this case, stateful ACLs must be bound to both SVI interfaces (vlan101 and vlan101-v0). In the stateful ACL described in the current section, the binding would be:
root@hbn03-host00:~# nv set interface vlan101,vlan101-v0 acl allow_tcp_conn_from_host inbound root@hbn03-host00:~# nv set interface vlan101,vlan101-v0 acl allow_tcp_resp_from_server outbound root@hbn03-host00:~# nv config apply
Flat Files (cl-acltool) Example for L3 Stateful ACLs
For the same NVUE example for L3 stateful ACLs cited above (HTTP server at IP address 11.11.11.11 on an external network), the following are the corresponding ACL rules which must be configured under /etc/cumulus/acl/policy.d/<rule_name.rules> followed by invoking cl-acltool -i to install the rules in DPU hardware.
Configure an ingress ACL rule matching with TCP flow details and CONNTRACK state of NEW, ESTABLISHED under /etc/cumulus/acl/policy.d/stateful_acl.rules with the ingress interface as the host representor of the DPU and the associated VLAN's SVI followed by invoking cl-acltool -i:
[iptables] ## ACL allow_tcp_conn_from_host in dir inbound on interface vlan101 ## -t filter -A FORWARD -i vlan101 -p tcp -d 11.11.11.11/32 --dport 80 -m conntrack --ctstate EST,NEW -m connmark ! --mark 7998 -j CONNMARK --set-mark 7999 -t filter -A FORWARD -i vlan101 -p tcp –d 11.11.11.11/32 --dport 80 -m conntrack --ctstate EST,NEW -j ACCEPT
NoteAs shown above, an additional rule must be configured with CONNMARK action. The CONNMARK values (-j CONNMARK --set-mark <value>) for ingress ACL rules are protocol dependent: 7999 for TCP, 7997 for UDP, and 7995 for ICMP.
Configure an egress ACL rule matching the TCP flow and CONNTRACK state of ESTABLISHED, RELATED under /etc/cumulus/acl/policy.d/stateful_acl.rules file with the egress interface as the host representor of the DPU and the associated VLAN's SVI followed by invoking cl-acltool -i:
[iptables] ## ACL allow_tcp_resp_from_server in dir outbound on interface vlan101 ## -t filter -A FORWARD -o vlan101 -p tcp -s 11.11.11.11/32 --sport 80 -m conntrack --ctstate EST -j CONNMARK --set-mark 7998 -t filter -A FORWARD -o vlan101 -p tcp -s 11.11.11.11/32 --sport 80 -m conntrack --ctstate EST -j ACCEPT
NoteAs shown above, an additional rule must be configured with CONNMARK action. The CONNMARK values (-j CONNMARK --set-mark <value>) for egress ACL rules are protocol dependent: 7998 for TCP, 7996 for UDP, and 7994 for ICMP.
NVUE Example for EVPN-L2 Stateful ACLs
The following is an example allowing HTTP (TCP) connection originated by the host, hosting the DPU, to an HTTP server (with the IP address 192.168.5.5) accessible on the EVPN bridged network ("L2 stretch"). Two sets of ACLs matching with CONNTRACK state must be configured for a CONNTRACK entry to be established in the kernel which would be offloaded to hardware:
Configure an ACL rule matching TCP/HTTP connection/flow details with a CONNTRACK state of NEW, ESTABLISHED, and bind it to the host interface in the inbound direction
Configure an ACL rule matching TCP/HTTP connection/flow details with a CONNTRACK state of ESTABLISHED, and bind it to the host interface in the outbound direction
In this example, the host interface is pf1vf7_sf.
Configure the ingress ACL rule:
root@hbn03-host00:~# nv set acl allow_tcp_conn_from_host rule 11 action permit root@hbn03-host00:~# nv set acl allow_tcp_conn_from_host rule 11 match conntrack new root@hbn03-host00:~# nv set acl allow_tcp_conn_from_host rule 11 match conntrack established root@hbn03-host00:~# nv set acl allow_tcp_conn_from_host rule 11 match ip dest-ip 192.168.5.5/32 root@hbn03-host00:~# nv set acl allow_tcp_conn_from_host rule 11 match ip dest-port 80 root@hbn03-host00:~# nv set acl allow_tcp_conn_from_host rule 11 match ip protocol tcp root@hbn03-host00:~# nv set acl allow_tcp_conn_from_host type ipv4
Bind this ACL to the host interface in the inbound direction:
root@hbn03-host00:~# nv set interface pf1vf7_sf acl allow_tcp_conn_from_host inbound root@hbn03-host00:~# nv config apply
Configure the egress ACL rule:
root@hbn03-host00:~# nv set acl allow_tcp_resp_from_server rule 21 action permit root@hbn03-host00:~# nv set acl allow_tcp_resp_from_server rule 21 match conntrack established root@hbn03-host00:~# nv set acl allow_tcp_resp_from_server rule 21 match ip protocol tcp root@hbn03-host00:~# nv set acl allow_tcp_resp_from_server type ipv4 root@hbn03-host00:~# nv config apply
Bind this ACL to the host interface in the outbound direction:
root@hbn03-host00:~# nv set interface pf1vf7_sf acl allow_tcp_resp_from_server outbound root@hbn03-host00:~# nv config apply
Flat Files (cl-acltool) Example for EVPN-L2 Stateful ACLs
For the same NVUE L2 stateful ACLs example cited above (HTTP server at IP address 192.168.5.5 accessible over bridged network), the following are the corresponding ACL rules which must be configured under /etc/cumulus/acl/policy.d/<rule_name.rules> followed by invoking cl-acltool -i.
Configure an ingress ACL rule matching with TCP flow details and CONNTRACK state of NEW, ESTABLISHED under /etc/cumulus/acl/policy.d/stateful_acl.rules with the ingress interface as the host representor of the DPU, followed by invoking cl-acltool -i:
[iptables] ## ACL allow_tcp_conn_from_host in dir inbound on interface pf1vf7_sf -t filter -A FORWARD -m physdev --physdev-in pf1vf7_sf -p tcp -d 192.168.5.5/32 --dport 80 -m conntrack --ctstate EST,NEW -m connmark ! --mark 9998 -j CONNMARK --set-mark 9999 -t filter -A FORWARD -m physdev --physdev-in pf1vf7_sf -p tcp -d 192.168.5.5/32 --dport 80 -m conntrack --ctstate EST,NEW -j ACCEPT
NoteAs shown above, an additional rule must be configured with CONNMARK action. The CONNMARK values (-j CONNMARK --set-mark <value>) for ingress ACL rules are protocol dependent: 9999 for TCP, 9997 for UDP, and 9995 for ICMP.
Configure an egress ACL rule matching with TCP and CONNTRACK state of ESTABLISHED, RELATED under /etc/cumulus/acl/policy.d/stateful_acl.rules file with the egress interface as the host representor of the DPU, followed by invoking cl-acltool -i:
[iptables] ## ACL allow_tcp_resp_from_server in dir outbound on interface pf1vf7_sf ## -t filter -A FORWARD -m physdev --physdev-out pf1vf7_sf -p tcp -s 192.168.5.5/32 --sport 80 -m conntrack --ctstate EST -j CONNMARK --set-mark 9998 -t filter -A FORWARD -m physdev --physdev-out pf1vf7_sf -p tcp -s 192.168.5.5/32 --sport 80 -m conntrack --ctstate EST -j ACCEPT
NoteAs shown above, an additional rule must be configured with CONNMARK action. The CONNMARK values (-j CONNMARK --set-mark <value>) for egress ACL rules are protocol dependent: 9998 for TCP, 9996 for UDP, and 9994 for ICMP.
DHCP Relay on HBN
DHCP is a client server protocol that automatically provides IP hosts with IP addresses and other related configuration information. A DHCP relay (agent) is a host that forwards DHCP packets between clients and servers. DHCP relays forward requests and replies between clients and servers that are not on the same physical subnet.
DHCP relay can be configured using either flat file (supervisord configuration) or through NVUE.
Configuration
HBN is a non-systemd based container. Therefore, the DHCP relay must be configured as explained in the following subsections.
Flat File Configuration (Supervisord)
The HBN initialization script installs default configuration files on the DPU in /var/lib/hbn/etc/supervisor/conf.d/. The DPU directory is mounted to /etc/supervisor/conf.d which achieves configuration persistence.
By default, DHCP relay is disabled. Default configuration applies to one instance of DHCPv4 relay and DHCPv6 relay in the default VRF.
NVUE Configuration
The user can use NVUE to configure and maintain DHCPv4 and DHCPv6 relays with CLI and REST API. NVUE generates all the required configurations and maintains the relay service.
DHCPv4 Relay Configuration
NVUE Example
The following configuration starts a relay service which listens for the DHCP messages on p0_sf, p1_sf, and vlan482 and relays the requests to DHCP server 10.89.0.1 with gateway-interface as lo.
nv set service dhcp-relay default gateway-interface lo
nv set service dhcp-relay default interface p0_sf
nv set service dhcp-relay default interface p1_sf
nv set service dhcp-relay default interface vlan482 downstream
nv set service dhcp-relay default server 10.89.0.1
Flat Files Example
[program: isc-dhcp-relay-default]
command = /usr/sbin/dhcrelay --nl -d -i p0_sf -i p1_sf -id vlan482 -U lo 10.89.0.1
autostart = true
autorestart = unexpected
startsecs = 3
startretries = 3
exitcodes = 0
stopsignal = TERM
stopwaitsecs = 3
Where:
|
Option |
Description |
|
-i |
Network interface to listen on for requests and replies |
|
-iu |
Upstream network interface |
|
-id |
Downstream network interface |
|
-U [address]%%ifname |
Gateway IP address interface. Use %% for IP%%ifname. % is used as an escape character. |
|
--loglevel-debug |
Debug logging. Location: /var/log/syslog. |
|
-a |
Append an agent option field to each request before forwarding it to the server with default values for circuit-id and remote-id |
|
-r remote-id |
Set a custom remote ID string (max of 255 chars). To use this option, you must also enable the -a option. |
|
--use-pif-circuit-id |
Set the underlying physical interface which receives the packet as the circuit-id. To use this option you must also enable the -a option. |
DHCPv4 Relay Option 82
NVUE Example
The following NVUE command is used to enable option 82 insertion in DHCP packets with default values:
nv set service dhcp-relay default agent enable on
To provide a custom remote-id (e.g., host10) using NVUE:
nv set service dhcp-relay default agent remote-id host10
To use the underlying physical interface on which the request is received as circuit-id using NVUE:
nv set service dhcp-relay default agent use-pif-circuit-id enable on
Flat Files Example
[program: isc-dhcp-relay-default]
command = /usr/sbin/dhcrelay --nl -d -i p0_sf -i p1_sf -id vlan482 -U lo -a --use-pif-circuit-id -r host10 10.89.0.1
autostart = true
autorestart = unexpected
startsecs = 3
startretries = 3
exitcodes = 0
stopsignal = TERM
stopwaitsecs = 3
DHCPv6 Relay Configuration
NVUE Example
The following NVUE command starts the DHCPv6 Relay service which listens for DHCPv6 requests on vlan482 and sends relayed DHCPv6 requests towards p0_sf and p1_sf.
nv set service dhcp-relay6 default interface downstream vlan482
nv set service dhcp-relay6 default interface upstream p0_sf
nv set service dhcp-relay6 default interface upstream p1_sf
Flat Files Example
[program: isc-dhcp-relay6-default]
command = /usr/sbin/dhcrelay --nl -6 -d -l vlan482 -u p0_sf -u p1_sf
autostart = true
autorestart = unexpected
startsecs = 3
startretries = 3
exitcodes = 0
stopsignal = TERM
stopwaitsecs = 3
Where:
|
Option |
Description |
|
-l [address]%%ifname[#index] |
Downstream interface. Use %% for IP%%ifname. % is used as escape character. |
|
-u [address]%%ifname |
Upstream interface. Use %% for IP%%ifname. % is used as escape character. |
|
-6 |
IPv6 |
|
--loglevel-debug |
Debug logging located at /var/log/syslog |
DHCP Relay and VRF Considerations
DHCP relay can be spawned inside a VRF context to handle the DHCP requests in that VRF. There can only be 1 instance each of DHCPv4 relay and DHCPv6 relay per VRF. To achieve that, the user can follow these guidelines:
DHCPv4 on default VRF:
/usr/sbin/dhcrelay --nl -i <interface> -U [address]%%<interface> <server_ip>
DHCPv4 on VRF:
/usr/sbin/ip vrf exec <vrf> /usr/sbin/dhcrelay –-nl -i <interface> -U [address]%%<interface> <server_ip>
DHCPv6 on default VRF:
/usr/sbin/dhcrelay --nl -6 -l <interface> -u <interface>
DHCPv6 on VRF:
/usr/sbin/ip vrf exec <vrf> /usr/sbin/dhcrelay --nl -6 -l <interface> -u <interface>
HBN Container Stuck in init-sfs
The HBN container starts as init-sfs and should transition to doca-hbn within 2 minutes as can be seen using crictl ps. But sometimes it may remain as init-sfs.
This can happen if interface p0_sf is missing. Run the command ip -br link show dev p0_sf in the DPU and inside the container to check if p0_sf is present or not. If its missing, make sure the firmware is upgraded to the latest version. Gracefully shutdown and power cycle the host for the new firmware to take effect.
Host-side PF/VF Down After DPU Reboot
In general, the host can use any interface manager to manage host interfaces belonging to the DPU. When the host uses an interface manager other than Netplan or NetworkManager, some ports may remain down after DPU reboot.
Apply the following workaround if interfaces stay down:
Restart openibd:
systemctl restart openibd
Recreate SR-IOV interfaces if they are needed.
Replay interface config. For example:
If using ifupdown2:
ifreload -a
If using Netplan:
netplan apply
BGP Session not Establishing
One of the main causes of a BGP session not getting established is a mismatch in MTU configuration. Make sure the MTU on all interfaces is the same. For example, if BGP is failing on p0, check and verify that there is a matching MTU value for p0, p0_sf_r, p0_sf, and the remote peer of p0.
Generating Support Dump
HBN support dump can be generated using the cl-support command, inside the HBN container:
root@bf2:/tmp# cl-support
Please send /var/support/cl_support_bf2-s02-1-ipmi_20221025_180508.txz to Cumulus support
The generated dump would be available in /var/support in the HBN container and would contain any process core dump as well as log files.
The /var/support directory is also mounted on the host DPU at /var/lib/hbn/var/support.
SFC Troubleshooting
To troubleshoot flows going through SFC interfaces, the first step is to disable the nl2doca service in the HBN container:
root@bf2:/tmp# supervisorctl stop nl2doca
nl2doca: stopped
Stopping nl2doca effectively stops hardware offloading and switches to software forwarding. All packets would appear on tcpdump capture on the DPU interfaces.
tcpdump can be performed on SF interfaces as well as VLAN, VXLAN, and uplinks to determine where a packet gets dropped or which flow a packet is taking.
General nl2doca Troubleshooting
The following steps can be used to make sure the nl2doca daemon is up and running:
Make sure there are no errors in the nl2doca log file at /var/log/hbn/nl2docad.log.
To check the status of the nl2doca daemon under supervisor, run:
supervisorctl status nl2doca
Use ps to check that the actual nl2doca process is running:
ps -eaf | grep nl2doca root 18 1 0 06:31 ? 00:00:00 /bin/bash /usr/bin/nl2doca-docker-start root 1437 18 0 06:31 ? 00:05:49 /usr/sbin/nl2docad
The core file should be in /var/support/core/.
Check if the /cumulus/nl2docad/run/stats/punt is accessible. Otherwise, nl2doca may be stuck and should be restarted:
supervisorctl restart nl2doca
nl2doca Offload Troubleshooting
If a certain traffic flow does not work as expected, disable nl2doca (i.e., disable hardware offloading):
supervisorctl stop nl2doca
With hardware offloading disabled, you can confirm it is an offloading issue if the traffic starts working. If it is not an offloading issue, use tcpdump on various interfaces to see where the packet gets dropped.
Offloaded entries can be checked in following files, which contain the programming status of every IP prefix and MAC address known to system.
Bridge entries are available in the file /cumulus/nl2docad/run/software-tables/17. It includes all the MAC addresses in the system including local and remote MAC addresses.
Example format:
- flow-entry: 0xaaab0cef4190 flow-pattern: fid: 112 dst mac: 00:00:5e:00:01:01 flow-actions: SET VRF: 2 OUTPUT-PD-PORT: 20(TO_RTR_INTF) STATS: pkts: 1719 bytes: 191286
Router entries are available in the file /cumulus/nl2docad/run/software-tables/18. It includes all the IP prefixes known to the system.
Example format for Entry with ECMP:
Entry with ECMP: - flow-entry: 0xaaaada723700 flow-pattern: IPV6: LPM VRF: 0 destination-ip: ::/0 flow-actions : ECMP: 2 STATS: pkts: 0 bytes: 0 Entry without ECMP: - flow-entry: 0xaaaada7e1400 flow-pattern: IPV4: LPM VRF: 0 destination-ip: 60.1.0.93/32 flow-actions : SET FID: 200 SMAC: 00:04:4b:a7:88:00 DMAC: 00:03:00:08:00:12 OUTPUT-PD-PORT: 19(TO_BR_INTF) STATS: pkts: 0 bytes: 0
ECMP entries are available in the file /cumulus/nl2docad/run/software-tables/19. It includes all the next hops in the system.
Example format:
- ECMP: 2 ref-count: 2 num-next-hops: 2 entries: - { index: 0, fid: 4100, src mac: 'b8:ce:f6:99:49:6a', dst mac: '00:02:00:00:00:0a' } - { index: 1, fid: 4101, src mac: 'b8:ce:f6:99:49:6b', dst mac: '00:02:00:00:00:0e' }
To check counters for packets going to the kernel, run:
cat /cumulus/nl2docad/run/stats/punt
PUNT miss pkts:3154 bytes:312326
PUNT miss drop pkts:0 bytes:0
PUNT control pkts:31493 bytes:2853186
PUNT control drop pkts:0 bytes:0
ACL PUNT pkts:68 bytes:7364
ACL drop pkts:0 bytes:0
For a specific type of packet flow, programming can be referenced in block specific files. The typical flow is as follows:
For example, to check L2 EVPN ENCAP flows for remote MAC 8a:88:d0:b1:92:b1 on port pf0vf0_sf, the basic offload flow should look as follows: RxPort (pf0vf0_sf) -> BR (Overlay) -> RTR (Underlay) -> BR (Underlay) -> TxPort (one of the uplink p0_sf or p1_sf based on ECMP hash).
Step-by-step procedure:
Navigate to the interface file /cumulus/nl2docad/run/software-tables/20.
Check for the RxPort (pf0vf0_sf):
Interface: pf0vf0_sf PD PORT: 6 HW PORT: 16 NETDEV PORT: 11 Bridge-id: 61 Untagged FID: 112
FID 112 is given to the receive port.
Check the bridge table file /cumulus/nl2docad/run/software-tables/17 with destination MAC 8a:88:d0:b1:92:b1 and FID 112:
flow-pattern: fid: 112 dst mac: 8a:88:d0:b1:92:b1 flow-actions: VXLAN ENCAP: ENCAP dst ip: 6.0.0.26 ENCAP vni id: 1000112 SET VRF: 0 OUTPUT-PD-PORT: 20(TO_RTR_INTF) STATS: pkts: 100 bytes: 10200
Check the router table file /cumulus/nl2docad/run/software-tables/18 with destination IP 6.0.0.26 and VRF 0:
flow-pattern: IPV4: LPM VRF: 0 ip dst: 6.0.0.26/32 flow-actions : ECMP: 1 OUTPUT PD PORT: 2(TO_BR_INTF) STATS: pkts: 300 bytes: 44400
Check the ECMP table file /cumulus/nl2docad/run/software-tables/19 with ECMP 1:
- ECMP: 1 ref-count: 7 num-next-hops: 2 entries: - { index: 0, fid: 4100, src mac: 'b8:ce:f6:99:49:6a', dst mac: '00:02:00:00:00:2f' } - { index: 1, fid: 4115, src mac: 'b8:ce:f6:99:49:6b', dst mac: '00:02:00:00:00:33' }
The ECMP hash calculation picks one of these paths for next-hop rewrite. Check bridge table file for them (fid=4100, dst mac: 00:02:00:00:00:2f or fid=4115, dst mac: 00:02:00:00:00:33):
flow-pattern: fid: 4100 dst mac: 00:02:00:00:00:2f flow-actions: OUTPUT-PD-PORT: 36(p0_sf) STATS: pkts: 1099 bytes: 162652
This will show the packet going out on the uplink.
NVUE Troubleshooting
To check the status of the NVUE daemon, run:
supervisorctl status nvued
To restart the NVUE daemon, run:
supervisorctl restart nvued