NVIDIA DOCA Bench
NVIDIA DOCA Bench allows users to evaluate the performance of DOCA applications, with reasonable accuracy for real-world applications. It provides a flexible architecture to evaluate multiple features in series with multi-core scaling to provide detailed throughput and latency analysis. e. The output and intermediate buffers is sized
This tool can be used to evaluate the performance of multiple DOCA operations, gain insight into each stage in complex DOCA operations and understand how items such as buffer sizing, scaling, and GGA configuration affect throughput and latency.
DOCA Bench is designed as a unified testing tool for all BlueField accelerators. It, therefore, provides these major features:
BlueField execution, utilizing the Arm cores and GGAs "locally"
Host (x86) execution, utilizing x86 cores and the GGAs on the BlueField over PCIe
Support for following DOCA/DPU features:
DOCA AES GCM
DOCA Comch
DOCA Compress
DOCA DMA
DOCA EC
DOCA Eth
DOCA RDMA
DOCA SHA
Multi-core/multi-thread support
Schedule executions based on time, job counts, etc.
Ability to construct complex pipelines with multiple GGAs (where data moves serially through the pipeline)
Various data sources (random data, file data, groups of files, etc.)
Remote memory operations
Use data location on the host x86 platform as input to GGAs
Comprehensive output to screen or CSV
Query function to report supported software and hardware feature
Sweeping of parameters between a start and end value, using a specific increment each time
Specific attributes can be set per GGA instance, allowing fine control of GGA operation
DOCA Bench is installed and available in both DOCA-for-Host and DOCA BlueField Arm packages. It is located under the /opt/mellanox/doca/tools folder.
Prerequisites
DOCA 2.7.0 and higher.
DOCA Bench measures performance of either throughput (bandwidth) or latency.
In this mode, DOCA Bench measures the maximum performance of a given pipeline (see "Core Principles"). At the end of the execution, a short summary along with more detailed statistics is presented:
Aggregate stats
Duration: 3000049 micro seconds
Enqueued jobs: 17135128
Dequeued jobs: 17135128
Throughput: 005.712 MOperations/s
Ingress rate: 063.832 Gib/s
Egress rate: 063.832 Gib/s
Latency Measurements
Latency is the measurement of time taken to perform a particular operation. In this instance, DOCA Bench measures the time taken between submitting a job and receiving a response.
DOCA Bench provides two different types of latency measurement figures:
Bulk latency mode – attempts to submit a group of jobs in parallel to gain maximum throughput, while reporting latency as the time between the first job submitted in the group and the last job received.
Precision latency mode – used to ensure that only one job is submitted and measured before the next job is scheduled.
Bulk Latency
This latency mode effectively runs the pipelines at full rate, trying to maintain the maximum throughput of any pipeline while also recording latency figures for jobs submitted.
To record latency, while operating at the pipelines maximum throughput, users must place the latency figures inside groups or "buckets" (rather than record each individual job latency). Using this method, users can avoid the large memory and CPU overheads associated with recording millions of latency figures per second (which would otherwise significantly reduce the performance).
As each pipeline operation is different, and therefore has different latency characteristics, the user can supply the boundaries of the latency measure. DOCA Bench internally creates 100 buckets, of which the user can specify the starting value and the width or size of each bucket. The first and last bucket have significance:
The first bucket contains all jobs that executed faster than the starting period
The last bucket contains a count of jobs that took longer than the maximum time allowed
The command line option --latency-bucket-range is used to supply two values representing the starting time period of the first bucket, and the width of each sequential bucket. For example, --latency-bucket-range 10us,100us would start with the lowest bucket measuring <10μs response times, then 100 buckets which are 100μs wide, and a final bucket for results taking longer than 10010μs.
The report generated by bulk mode visualizes the latency data in two methods:
A bar graph is provided to visually show the spread of values across the range specified by the --latency-bucket-range option:
Latency report: : : : : : :: :: :: :: .::. . . .. ------------------------------------------------------------------------------------------------------
A breakdown of the number of jobs per bucket is presented. This example shortens the output to show that the majority of values lie between 27000ns and 31000ns.
[25000ns -> 25999ns]:
0[26000ns -> 26999ns]:0[27000ns -> 27999ns]:128[28000ns -> 28999ns]:2176[29000ns -> 29999ns]:1152[30000ns -> 30999ns]:128[31000ns -> 31999ns]:0[32000ns -> 32999ns]:0[33000ns -> 33999ns]:128[34000ns -> 34999ns]:0[35000ns -> 35999ns]:0
Precision Latency
This latency mode operates on a single job at a time. At the cost of greatly reduced throughput, this allows the minimum latency to be precisely recorded. As shown below, the statistics generated are precise and include various fields such as min, max, median, and percentile values.
Aggregate stats
....
min: 1878 ns
max: 4956 ns
median: 2134 ns
mean: 2145 ns
90th %ile: 2243 ns
95th %ile: 2285 ns
99th %ile: 2465 ns
99.9th %ile: 3193 ns
99.99th %ile: 4487 ns
The following subsections elaborate on principles which are essential to understand how DOCA Bench operates.
Host or BlueField Arm Execution
Whether executing DOCA Bench on an x86 host or BlueField Arm, the behavior of DOCA Bench is identical. The performance measured is be dependent on the environment.
Only execution on x86 hosts is supported.
Pipelines
DOCA Bench is a highly flexible tool, providing the ability to configure how and what operations occur and in what order. To accomplish this, DOCA Bench uses a pipeline of operations, which are termed "steps". These steps can be a particular function (e.g., Ethernet receive, SHA hash generation, data compression). Therefore, a pipeline of steps can accomplish a number of sequential operations. DOCA Bench can measure the throughput performance or latency of these pipelines, whether running on single or multiple cores/threads.
Currently, DOCA supports running only one pipeline at a time.
Warm-up Period
To ensure correct measurement, the pipelines must be run "hot" (i.e., any initial memory, caches, and hardware subsystems must be running prior to actual performance measurements begin). This is known as the "warm-up" period and, by default, runs approximately 100 jobs through the pipeline before starting measurements.
Defaults
DOCA Bench has a large number of parameters but, to simplify execution, only a few must be supplied to commence a performance measurement. Therefore various parameters have defaults which should be sufficient for most cases. To fine tune performance, users should pay close attention to any default parameters which may affect their pipeline's operation.
When executed, DOCA Bench reports a full list of all parameters and configured values.
Optimizing Performance
To obtain maximum performance, a certain amount of tuning is required for any given environment. While outside the scope of this documentation, it is recommended for users to:
Avoid using CPU 0 as most OS processes and interrupt request (IRQ) handlers are scheduled to execute on this core
Enable CPU/IRQ isolation in the kernel boot parameters to remove kernel activities from any cores they wish to execute performance tests on
On hosts, ensure to not cross any n on-uniform memory access ( NUMA) regions when addressing the BlueField
Understand the memory allocation requirements of scenarios, to avoid over-allocating or running into near out-of-memory situations
DOCA Bench can be executed on both host and BlueField Arm environments, and can target BlueField networking platforms.
The following table shows which operations are possible using either DOCA Bench. It also provides two columns showing whether remote memory can be used as an input or output to that operation. For example, DMA operations on the BlueField Arm can access remote memory as an input to pull memory from the host into the BlueField Arm).
|
BlueField-2 Networking Platform |
BlueFIeld-3 Networking Platform |
Execute on Host Side |
Execute on BlueField Arm |
Remote Memory as Input Allowed? |
Remote Memory as Output Allowed? |
|
|
doca_compress::compress |
✓ |
✓ |
✓ |
✓ |
✓ |
|
|
doca_compress::decompress |
✓ |
✓ |
✓ |
✓ |
✓ 1 |
✓ |
|
doca_dma |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
|
doca_ec::create |
✓ |
✓ |
✓ |
✓ |
✓ |
|
|
doca_ec::recover |
✓ |
✓ |
✓ |
✓ |
✓ |
|
|
doca_ec::update |
✓ |
✓ |
✓ |
✓ |
✓ |
|
|
doca_sha |
✓ |
✓ |
✓ |
✓ |
||
|
doca_rdma::send |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
|
doca_rdma::receive |
✓ |
✓ |
✓ |
✓ |
✓ |
✓ |
|
doca_aes_gcm::encrypt |
✓ |
✓ |
✓ |
✓ |
✓ |
|
|
doca_aes_gcm::decrypt |
✓ |
✓ |
✓ |
✓ |
✓ |
|
|
doca_cc::client_producer |
✓ |
✓ |
✓ |
✓ |
||
|
doca_cc::client_consumer |
✓ |
✓ |
✓ |
✓ |
||
|
doca_eth::rx |
✓ |
✓ |
✓ |
|||
|
doca_eth::tx |
✓ |
✓ |
✓ |
A subset of BlueField operations have a remote element, whether this is an RDMA connection, Ethernet connectivity, or memory residing on an x86 host. All these operations require an agent to be present on the far side to facilitate the benchmarking of that particular feature.
In DOCA Bench, this agent is an additional standalone application called the "companion app". It provides the remote benchmarking facilities and is part of the standard DOCA Bench installation.
The following diagram provides an overview of the function and communications between DOCA Bench and the companion app:
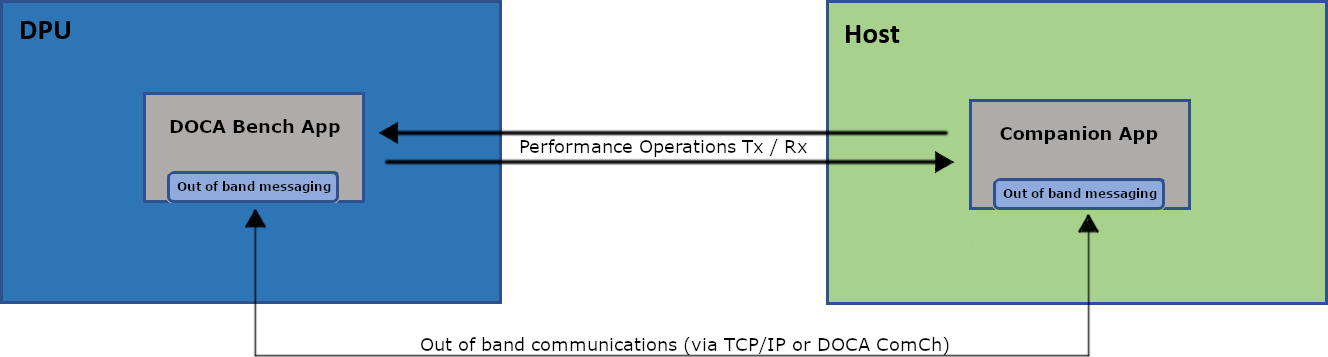
In this particular setup, the BlueField executes "DOCA Bench" while the host (x86) is executes the companion App.
DOCA Bench also acts as the controller of the tests, instructing the companion app to perform the necessary operations as required. There is an out-of-band communications channel operating between the two applications that utilizes either standard TCP/IP sockets or a DOCA Comch channel (depending on the test scenario/user preferences).
Selection of the correct CPU cores and threads has a significant impact on the performance or latency obtained. Read this section carefully.
A key requirement to scaling any application is the number of CPU cores or threads allocated to any given activity. DOCA Bench provides the ability to specify the numbers of cores, and the number of threads to be created per core, to maximize the number of jobs submitted to a given pipeline.
The following care should be given when selecting the number of CPU's or threads:
Threads that are on cores located on distant NUMA regions (i.e., not the same NUMA region the BlueField is connected to) will experience lower performance and higher latency
Core 0 is often most used by the OS and should be avoided
Standard Linux Kernel installations allow the OS to move processes on any CPU core resulting in unexpected drops in performance, or higher latency, due to process switching
The selection of CPU cores is provided through the --core-mask, --core-list, --core-count parameters, while thread selection is made via the --threads-per-core parameter.
When executing from a host (x86) environment DOCA Bench can target one or more BlueField devices within an installed environment. When executing from the BlueField Arm, the target is always the local BlueField.
The default method of targeting a given BlueField from either the host or the BlueField Arm is using the --device or -A parameters, which can be provided as:
Device PCIe address (i.e., 03:00.0);
Device IB name (mlx5_0); or
Device interface name (ens4f0)
From the BlueField Arm environment, DOCA Bench should be targeted at the local PCIe address ( i.e., --device 03:00.0 ) or the IB device name ( i.e., mlx5_0).
DOCA Bench supports different methods of supplying data to jobs and providing information on the amount of data to process per job. These are referred to as "Data Providers".
Input Data Selection
The following subsections provide the modes available to provide data for input into any operation.
File
A single file is used as input to the operation. The contents of the file are not important for certain operations (e.g., DMA, SHA, etc.) but must be valid and specific for others (e.g., decompress, etc). The data may be used multiple times and repeated if the operations required more data than the single file contains. For more information on how file data is handled in complex operations, see section "Command-line Parameters".
File Sets
File sets are a group of files that are primarily used for structured data. The data in the file set is effectively a list of files, separated by a new line that is used sequentially as input data for jobs. Each file pointed to by the file set would have its entire contents read into a single buffer. This is useful for operations that require structured data (i.e., a complete valid block of data, such as decompression or AES).
Random Data
Random data is provided when the actual data required for the given operation is not specific (e.g., DMA).
The use of random data for certain operations may reduce the maximum performance obtained. For example, compressing random data results in lower performance than compressing actual file data (due to the lack of repeating patterns in random data).
Job Sizing
Each job in DOCA Bench consists of three buffers: An original input buffer, an output, and an intermediate buffer.
The input buffer is provided by the data provider for the first step in the pipeline to use, after which the following steps use the output and intermediate buffers (can be sized by using --job-output-buffer-size) in a ping-pong fashion. This means, the pipeline can always start with the same deterministic data while allowing for each step to provide its newly generated output data to be used as input to the next step.
The input buffer is specified in one of two ways: using uniform-job-size to make every input buffer the exact same size, or using a file set to size each buffer based on the size of the selected input data file(s). Users should ensure the data generated by each step in the pipeline will fit in the provided output buffer.
DOCA Bench has a variety of ways to control the length of executing tests—whether based on data or time limit.
Limit to Specific Number of Seconds
Using the --run-limit-seconds or -s parameter ensures that the execution continues for a specific number of seconds.
Limited Through Total Number of Jobs
It may be desirable to measure a specific number of jobs passing through a pipeline. The --run-limit-jobs or -J parameter is used to specify the exact number of jobs submitted to the pipeline and allowed to complete before execution finishes.
As DOCA Bench supports a wide range of both GGA and software based DOCA libraries, the ability to fine tune their invocation is important. Command-line parameters are generally used for configuration options that apply to all aspects of DOCA Bench, without being specific to a particular DOCA library.
Attributes are the method of providing configuration options to a particular DOCA Library, whilst some shared attributes exist the majority of libraries have specific attributes designed to control their specific behavior.
For example, the attribute doca_ec.data_block_count allows you to set the data block count for the DOCA EC library, whilst the attribute doca_sha.algorithm controls the selection of the SHA algorithm.
For a full list of support attributes, see the "Command-line Parameters" section.
Due to batching it is possible that more than the supplied jobs are executed.
DOCA Bench allows users to specify a series of operations to be performed and then scale that workload across multiple CPU cores/threads to get an estimation of how that workload performs and some insight into which stage(s), if any, cause performance problems for them. The user can then modify various configuration properties to explore how issues can be tuned to better serve their need.
When running, DOCA Bench creates a number of execution threads with affinities to the specific CPU specified by the user. Each thread creates, uniquely for themselves, a jobs pool (with job data initialized by a data provider) and a pipeline of workload steps.
CPU Core and Thread Count Configuration
There are many factors involved when carrying out performance tests, one of these is the CPU selection:
The user should consider NUMA regions when selecting which cores to use, as using a CPU which is distant from the device under test can impact the performance achievable
The user may also wish to avoid core 0 as this is typically the default core for kernel interrupt handlers.
CPU core selection has an impact on the total memory footprint of the test. See section "Test Memory Footprint" for more details.
--core-mask
Default value: 0x02
Core mask is the simplest way to specify which cores to use but is limited in that it can only specify up to 32 CPUs (0-31). Usage example: --core-mask 0xF001 selects CPU cores 0, 12, 13, 14, and 15.
--core-list
Core list can specify any/all CPU cores in a given system as a list, range, or combination of the two. Usage example: --core-list 0,3,6-10 selects CPU cores 0, 3, 6, 7, 8, 9, and 10.
--core-count
The user can select the first N cores from a given core set (list or mask) if desired. Usage example: --core-count N.
Sweep testing is supported. See section "Sweep Tests" for more details.
--threads-per-core -t
To test the impacts of contention within a single CPU core, the user can specify this value so that instead of only one thread being created per core, N threads are created with their affinity mask set to the given core for each core selected. For example, 3 cores and 2 threads per core create 6 threads total.
Sweep testing is supported. See section "Sweep Tests" for more details.
Device Configuration
The test requires the use of at least one BlueField to execute. With remote system testing, a second device may be required.
--device -A
Specify the device to use from the perspective of the system under test. The value can be for any one of either the device PCIe address (e.g., 03:00.0), the device IB device name (e.g., mlx5_0), or the device interface name (e.g., ens4f0).
--representor -R
This option is used only when performing remote memory operations between a BlueField device and its host using DOCA Comch. This is typically automated by the companion connection string but exists for some developer debug use-cases.
This option used to be important before the companion connection string property was introduced but now is rarely used.
Input Data and Buffer Size Configuration
DOCA Bench supports multiple methods of acquiring data to use to initialize job buffers. The user can also configure the output/intermediate buffers associated with each job.
Input data and buffer size configuration has an impact on the total memory footprint of the test. See section "Test Memory Footprint" for more details.
--data-provider -I
DOCA Bench supports a number of different input data sources:
file
file-set
random-data
File Data Provider
The file data provider produces uniform/non-structured data buffers by using a single input file. The input data is stripped and or repeated to fill each data buffer as required, returning back to the start of the file each time it is exhausted to collect more data. This is desirable when the performance of the component(s) under test is meant to show different performance characteristics depending on the input data supplied.
For example, doca_dma and doca_sha would execute in constant time regardless of the input data. Whereas doca_compress would be faster with data with more duplication and slower for truly random data and would produce different output depending on the input data.
Example 1 – Small Input File with Large Buffers
Given a small input data (i.e., smaller than the data buffer size), the file contents are repeated until the buffer is filled and then continue onto the next buffer(s). So, if the input file contained the data 012345 and the user requested two 20-byte buffers, the buffers would appear as follows:
01234501234501234501
23450123450123450123
Example 2 – Large Input File with Smaller Buffers
Given a large input data (i.e., greater than the data buffer size), the file contents are distributed across the data buffers. If the the input file contained the data 0123456789abcdef and the user requested three 12-byte buffers, the buffers would appear as follows:
0123456789ab
cdef01234567
89abcdef0123
File Set Data Provider
The file set data provider produces structured data. The file set input file itself is a file containing one or more filenames (relative to the input "command working directory (cwd)" not relative to the file set file). Each file listed inside the file set would have its entire contents used as a job buffer. This is useful for operations where the data must be a complete valid data block for the operation to succeed like decompression with doca_compress or decryption with doca_aes.
Example – File Set and Its Contents
Given a file set in the "command working directory (cwd)" referring to data_1.bin and data_2.bin (one file name per line), and data_1.bin contains 33 bytes and data_2.bin contains 69 bytes, then the data required by the buffers would be filled with these two files in a round-robin manner until the buffers are full . Unlike uniform (non-structured) data each task can have different lengths.
Random-data Data Provider
The random data data provider provides uniform (non-structured) data from a random data source. Each buffer will have unique (pseudo) random bytes of content.
--data-provider-job-count
Default value: 128
Each thread in DOCA Bench has its own allocation of job data buffers to avoid memory contention issues. Users may select how many jobs should be created per thread using this parameter.
Sweep testing is supported. See section "Sweep Tests" for more details.
--data-provider-input-file
For data providers which use an input file, the filename can be specified here. The filename is relative to the input_cwd.
Sweep testing is supported. See section "Sweep Tests" for more details.
--uniform-job-size
Specify the size of uniform input buffers (in bytes) that should be created.
Does not apply and should not be specified when using structured data input sources.
Sweep testing is supported. See section "Sweep Tests" for more details.
--job-output-buffer-size
Default value: 16384
Specify the size of output/intermediate buffers (in bytes). Each job has 3 buffers: immutable input buffer and two output/intermediate buffers. This allows for a pipeline to mutate the data an infinite number of times throughout the pipeline while allowing for it to be reset and re-used at the end, and allowing any step to use the new mutated data created by the previous step.
--input-cwd -i
To ease configuration management, the user may opt to use a separate folder for the input data for a given scenario outside of the DOCA build/install directory.
It is recommended to use relative file paths for the input files.
Example 1 – Running DOCA Bench from Current Working Directory
Considering a user executing DOCA Bench from /home/bob/doca/build, values specified in --data-provider-input-file and filenames within a file set would search relative to the shell's "command working directory (cwd)": /home/bob/doca/build. Their command might look something like:
doca_bench --data-provider file-set --data-provider-input-file my_file_set.txt
And assuming my_file_set.txt contains data_1.bin, the files that would be loaded by DOCA Bench after path resolution would be:
/home/bob/doca/build/my_file_set.txt
/home/bob/doca/build/data_1.bin
Example 2 – Running DOCA Bench from Another Directory
Considering the user executed that same test from one level up. Something like:
build/doca_bench --data-provider file-set --data-provider-input-file build/my_file_set.txt
The files to be loaded would be:
/home/bob/doca/build/my_file_set.txt
/home/bob/doca/data_1.bin
Notice how both files were loaded relative to the "command working directory (cwd)" and the data file was not loaded relative to the file set.
Example 3 – Example 2 Revisited Using input-cwd
The user can solve this easily by keeping all input files in a single directory and then referring to that directory using the parameter input-cwd. In this case, the command like may look something like:
build/doca_bench --data-provider file-set --data-provider-input-file my_file_set.txt --input-cwd build
Note that the value for --data-provider-input-file also changed to be relative to the new "command working directory (cwd)".
The files loaded this time are back to being what is expected:
/home/bob/doca/build/my_file_set.txt
/home/bob/doca/build/data_1.bin
Test Execution Control
DOCA Bench supports multiple test modes and run execution limits to allow the user to configure the test type and duration.
--mode
Default value: throughput
Select which type of test is to be performed.
Throughput Mode
Throughput mode is optimized to increase the volume of data processed in a given period with little or no regard for latency impact. Throughput mode tries to keep each component under test as busy as possible. A summary of the bandwidth and job execution rate are provided as output.
Bulk-latency Mode
Bulk latency mode strikes a balance between throughout and latency, submitting a batch of jobs and waiting for them all to complete to measure the latency of each job. This mode uses a bucketing mechanism to allow DOCA Bench to handle many millions of jobs worth of results. DOCA Bench keeps a count of the number of jobs that complete within each bucket to allow it to run for long periods of time. A summery of the distribution of results with an ASCII histogram of the results are provided as output. The latency reported is the time taken between the first job submission (for a batch of jobs) until the final job response is received (for that same batch of jobs).
Precision-latency Mode
Precision latency mode executes one job at a time to allow DOCA Bench to calculate the minimum possible latency of the jobs. This causes the components which can process many jobs in parallel to be vastly underutilized and so greatly reduces bandwidth. As this mode records every result individually, it should not be used to execute more than several thousand jobs. Precision latency mode requires 8 bytes of storage for each result, so be mindful of the memory overhead of the number of jobs to be executed.
A statistical analysis including minimum, maximum, mean, median and some percentiles of the latency value are provided as output.
--latency-bucket-range
Default value: 100ms,10ms
Only applicable to bulk-latency mode. Allows the user to specify the starting value of the buckets, and the width of each bucket. There are 100 buckets of the given size and an under flow and over flow bucket for results that fall outside of the central range.
For example:
--latency-bucket-range 10us,100us
This would start with the lowest bucket measuring <10μs response times, then 100 buckets which are 100μs wide, and a final bucket for results taking longer than >10010μs
Execution Limits
By default, a test runs forever. This is typically undesirable so the user can specify a limit to the test.
Precision-latency mode only supports job limited execution.
--run-limit-seconds -s
Runs the test for N seconds as specified by the user.
--run-limit-jobs -J
Runs the test until at least N jobs have been submitted, then allowing in-flight jobs to complete before exiting. More jobs than N may be executed based on batch size.
--run-limit-bytes -b
Runs the test until at least N bytes of data have been submitted, then allowing in-flight jobs to complete before exiting. More data may be processed than desired if the limit is not a multiple of the job input buffer size.
Gather/Scatter Support
Gather support involved breaking incoming input data from a single buffer into multiple buffers, which are "gathered" into a single gather list. Currently only gather is supported.
--gather-value
Default value: 1
Specifies the partitioning of input data from a single buffer into a gather list. The value can be specified in two flavors:
--gather-value 4 – splits input buffers into 4 parts as evenly as possible with odd bytes in the last segment
--gather-value 4KiB – splits buffers after each 4KB of data. See doca_bench/utility/byte_unit.hpp for the list of possible units.
Stats Output
--rt-stats-interval
By default, DOCA Bench emits the results of an iteration once it completes. The user can ask for transient snapshots of the stats as the test progresses by providing the --rt-stats-interval argument with a value representing the number of milliseconds between stat prints. The end-result of the run is still displayed as normal.
This may produce a large amount of console output.
--csv-output-file
DOCA Bench can produce an output file as part of its execution which can contain stats and the configuration values used to produce that stat. This is enabled by specifying the --csv-output-file argument with a file path as the value. Providing a value for this argument enables CSV stats output (in addition to the normal console output). When performing a sweep test, one line per iteration of the sweep test is populated.
By default, the CSV output contains every possible value. The user can tune this by applying a filter.
--csv-stats
Provide one or more filters (positive or negative) to tune which stats are displayed. The value for this argument is a comma-separated list of filter strings. Negative filters start with a minus sign ('-').
Example 1 – Emit Only Statistical Values (No Configuration Values)
--csv-stats "stats.*"
The quotes around the * prevent the shell from interpreting it as a wild card for filenames in the command.
Example 2 – Emit Statistical Values and Some Configuration Values (Remove Attribute Values)
--csv-stats "stats.*,-attribute*
--csv-append-mode
Default: false
When enabled, DOCA Bench appends to a CSV file if it exists or creates a new one. It is assumed that all invocation uses the exact same set of output values. This is not verified by DOCA Bench. The user must ensure that all tests that append to the CSV use the same set of output values.
--csv-separate-dynamic-values
A special case which creates a non-standard CSV file. All values that are not supported by sweep tests are reported only once first, then a new line of headers for values emitted during the test, then a row for each test result. This is reserved for an internal use case and should not be relied upon by anyone else.
--enable-environment-information
Instructs DOCA Bench to collect some detailed system information as part of the test startup procedure which are then made available for output in the CSV. These also gather the same details from the companion side if the companion is in use.
This collection can take a long time (up to a few minutes in some circumstances) to complete, so it is not recommended unless you know you need it.
Remote Memory Testing
Some libraries (e.g., doca_dma) support the use of remote memory. To enable this, the user can specify one or both of the remote memory flags --use-remote-input-buffers and --use-remote-output-buffers. This tells DOCA Bench to use the companion to create a remote mmap. This remote mmap is then used to create buffers that are submitted to the component under test.
These flags should be used with caution and an understanding that if the underlying components under test can support this scenario, there is no automated checking. It is user responsibility to ensure these are used appropriately.
--use-remote-input-buffers
Specifies that the memory used for the initial immutable job input buffers into a pipeline should be backed by an mmap on the remote side.
Requires the companion app to be configured.
--use-remote-output-buffers
Specifies that all output and translation buffers in use are backed by an mmap on the remote side.
Requires the companion app to be configured.
--mtu-size
For use with doca_rdma. Value is an enum: 256B 512B 1KB 2KB 4KB or raw_eth.
--receive-queue-size
For use with doca_rdma. Configure the RDMA RQ size independently of the SQ size.
--send-queue-size
For use with doca_rdma. Configure the RDMA SQ size independently of the RQ size.
DOCA Lib Configuration Options
--task-pool-size
Default value: 1024
Configure the maximum task pool size used when libraries initialize task pools.
Pipeline Configuration
DOCA Bench is based on a pipeline of operations, This allow for complex test scenarios where multiple components are tested in parallel. Currently only a single chain of operations in a pipeline is supported (but scaled across multiple cores or threads), future versions will allow for varied pipeline's per CPU core.
A pipeline is described as a series of steps. All steps have a few general characteristics:
Step type: doca_dma, doca_sha, doca_compress, etc.
An operation category – transformative or non-transformative
An input data category – structured or non structured
Individual step types may also have some additional metadata information or configuration as defined on a per step basis.
Metadata examples:
doca_compress requires an operation type: compress or decompress
doca_aes requires an operation type: encrypt or decrypt
doca_ec requires an operation type: create , recover or update
doca_rdma requires a direction: send , receive or bidir
Configuration examples:
--pipeline-steps doca_dma
--pipeline-steps doca_compress::compress,doca_compress::decompress
--pipeline-steps
Define the step(s) (comma-separated list) to be executed by each thread of the test.
The following is the list of supported steps:
doca_compress::compress
doca_compress::decompress
doca_dma
doca_ec::create
doca_ec::recover
doca_ec::update
doca_sha
doca_rdma::send
doca_rdma::receive
doca_rdma::bidir
doca_aes_gcm::encrypt
doca_aes_gcm::decrypt
doca_cc::client_producer
doca_cc::client_consumer
doca_eth::rx
doca_eth::tx
Some modules may be unavailable if they were not compiled as part of DOCA when DOCA Bench was compiled.
--attribute
Some of the options are very niche or specific to a single step/mmo type, so they are defined simply as attributes instead of a unique command-line argument.
The following is the list of supported options:
doption.mmp.log_qp_depth
doption.mmo.log.num_qps
doption.companion_app.path
doca_compress.algorithm
doca_ec.matrix_count
doca_ec.data_block_count
doca_ec.redundancy_block_count
doca_sha.algorithm
doca_rdma.gid-index
doca_eth.max_burst_size
doca_eth.l3_chksum_offload
doca_eth.l4_chksum_offload
--warm-up-jobs
Default value: 100
Warm-up serves two purposes:
Firstly, it runs N tasks in a round robin fashion to get the data path code, tasks memory, and tasks data buffers memory into the CPU caches before the measurement of the test begins
Secondly, it uses doca_task_try_submit instead of doca_task_submit to validate the jobs. This validation is not desirable during the proper hot path as it costs time revalidating the task each execution.
The user should ensure their warmup count equals or exceeds the number of tasks being used per thread (see --data-provider-job-count).
Companion Configuration
Some tests require a remote system to function. For this purpose, DOCA Bench comes bundled with a companion application (this application is installed as part of the DOCA-for-Host or BlueField packages). The companion is responsible for providing services to DOCA Bench such as creating a doca_mmap on the remote side and exporting it for use with remote operations like doca_dma/doca_sha, or other doca_libs that support remote memory input buffers. DOCA Bench can also provide remote worker processes for libraries that require them such as doca_rdma and doca_cc. The companion is enabled by providing the --companion-connection-string argument. Companion remote workers are enabled by providing either of the arguments --companion-core-list or --companion-core-mask.
DOCA Bench requires that an SSH key is configured to allow the user specified to SSH without a password to the remote system using the supplied address (to launch the companion). Refer to your OS's documentation for information on how to achieve this.
The companion connection may also specify the no-launch option.
This is reserved for expert developer use.
The user may also specify a path to a specific companion binary to allow them to test companion binaries not in the default install path using the following command:
--attribute doption.companion_app.path=/tmp/my_doca_build/tools/bench/doca_bench_companion
This is reserved for expert developer use.
--companion-connection-string
Specifies the details required to establish a connection to and execute the companion process.
Example of running DOCA Bench from the host side using the BlueField for the remote side using doca_comch as the communications method:
--companion-connection-string
"proto=dcc,mode=DPU,user=bob,addr=172.17.0.1,dev=03:00.0,rep=d8:00.0"Example of running DOCA Bench from the BlueField side using the host for the remote side using doca_comch as the communications method:
--companion-connection-string
"proto=dcc,mode=host,user=bob,addr=172.17.0.1,dev=d8:00.0"Example of running DOCA Bench on one host with the companion on another host using TCP as the communications method:
--companion-connection-string
"proto=tcp,user=bob,addr=172.17.0.1,port=12345,dev=d8:00.0"NoteFor doca_rdma only.
--companion-core-list
Works the same way as --core-list but defines the cores to be used on the companion side.
Must be at least as large as the --core-list.
--companion-core-mask
Works the same way as --core-mask but defines the cores to be used on the companion side.
Must be at least as large as the --core-mask.
Sweep Tests
--sweep
DOCA Bench supports executing a set of tests based on a number of value ranges. For example, to understand the performance of multi-threading, the user may wish to run the same test for various CPU core counts. They may also wish to vary more than one aspect of the test. Providing one or more --sweep parameters activates sweep test mode where every combination of values is tested with a single invocation of DOCA Bench.
The following is a list of the supported sweep test options:
core-count
data-provider-input-file
data-provider-job-count
gather-value
mtu-size
receive-queue-size
send-queue-size
threads-per-core
task-pool-size
uniform-job-size
doption.mmo.log_qp_depth
doption.mmo.log_num_qps
doca_rdma.transport-type
doca_rdma.gid-index
Sweep test argument values take one of three forms:
--sweep param,start_value,end_value,+N
--sweep param,start_value,end_value,*N
--sweep param,value1,...,valueN
Sweep core count and input file example:
--sweep core-count,1,8,*2 –sweep data-provider-input-file,file1.bin,file2.bin
This would sweep cores 1-8, inclusive, multiplying the value each time as 1,2,4,8 and two different input files resulting in a cumulative 8 test cases:
|
Iteration Number |
Core Count |
Input File |
|
1 |
1 |
file1.bin |
|
2 |
2 |
file1.bin |
|
3 |
4 |
file1.bin |
|
4 |
8 |
file1.bin |
|
5 |
1 |
file2.bin |
|
6 |
2 |
file2.bin |
|
7 |
4 |
file2.bin |
|
8 |
8 |
file2.bin |
Queries
Device Capabilities
DOCA Bench allows the querying of a device to report which step types are available as well as information of valid configuration options for each step. A device must be specified:
tools/bench/doca_bench --device 03:00.0 --query device-capabilities
For each supported library, this would report:
Capable – if that library is enabled in DOCA Bench at compile time (if not capable, installing the library would not make it become available to bench)
Installed – if the library is installed on the machine executing the query (if not installed, installing it would make it available to bench)
Library wide attributes
A list of supported task types (~= step name)
If the task type is supported
Task specific attributes/capabilities
doca_compress:
Capable: yes
Installed: yes
Tasks:
compress::deflate:
Supported: no
compress::lz4:
Supported: no
compress::lz4_stream:
Supported: no
decompress::deflate:
Supported: yes
Max buffer length: 134217728
decompress::lz4:
Supported: yes
Max buffer length: 134217728
decompress::lz4_stream:
Supported: yes
Max buffer length: 134217728
Supported Sweep Attributes
Shows the possible parameters that can be used with the sweep test parameter
tools/bench/doca_bench --query sweep-properties
Example output:
Supported query properties: [
core-count
threads-per-core
uniform-job-size
task-pool-size
data-provider-job-count
gather-value
mtu-size
send-queue-size
receive-queue-size
doption.mmo.log_qp_depth
doption.mmo.log_num_qps
doca_rdma.transport-type
doca_rdma.gid-index
]
DOCA Bench allocates memory for all the tasks required by the test based on the input buffer size, output/intermediate buffer size, number of cores, number of threads, and number of jobs in use. All jobs contain an input buffer, an output buffer, and an intermediate buffer. The input buffer is immutable and sized based on the data provider in use. The output and intermediate buffers are sized based on the users specification or automatically calculated at the users request. For a library which produces the same amount of output as it consumes (e.g., doca_dma), typically the user should set the buffers all to the same size to make things as efficient as possible.
The memory footprint for job buffers can be calculated as: (number-of-tasks) * (number-of-cores) * (number-of-threads-per-core) * (input-buffer-size + (output/intermediate-buffer-size * 2)). For a 1KB job with the default of 32 jobs, 1 core, and 1 core per thread, the memory footprint would be 96KB.
For sweep testing and structured data input, it can be difficult to pick a suitable output buffer size so the user may choose to specify 0 and have DOCA Bench try all the tasks once to calculate the required output buffer sizes. This only has a cost in terms of time taken to perform the calculation. After this, there is no difference between auto-sizing and manually sizing the jobs output buffers.
When running DOCA Bench on the BlueField and on some host OSs, it may be necessary to increase the limit of how much memory the process can acquire. Consult your OS's documentation for details of how to do this.