NVIDIA DOCA DPA All-to-all Application Guide
This guide explains all-to-all collective operation example when accelerated using the DPA in NVIDIA® BlueField®-3 DPU.
This reference application shows how the message passing interface (MPI) all-to-all collective can be accelerated on the Data Path Accelerator (DPA). In an MPI collective, all processes in the same job call the collective routine.
Given a communicator of n ranks, the application performs a collective operation in which all processes send and receive the same amount of data from all processes (hence all-to-all).
This document describes how to run the all-to-all example using the DOCA DPA API .
All-to-all is an MPI method. MPI is a standardized and portable message passing standard designed to function on parallel computing architectures. An MPI program is one where several processes run in parallel.
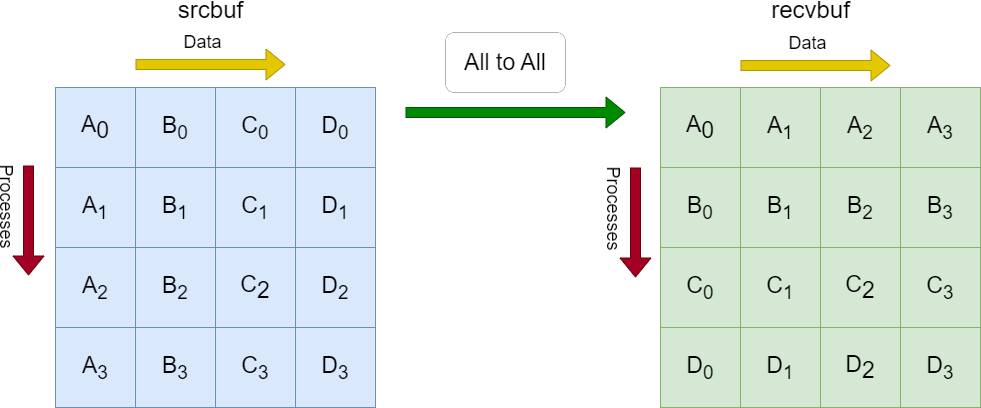
Each process in the diagram divides its local sendbuf into n blocks (4 in this example), each containing sendcount elements (4 in this example). Process i sends the k-th block of its local sendbuf to process k which places the data in the i-th block of its local recvbuf.
Implementing all-to-all method using DOCA DPA offloads the copying of the elements from the srcbuf to the recvbufs to the DPA, and leaves the CPU free to perform other computations.
The following diagram describes the differences between host-based all-to-all and DPA all-to-all.
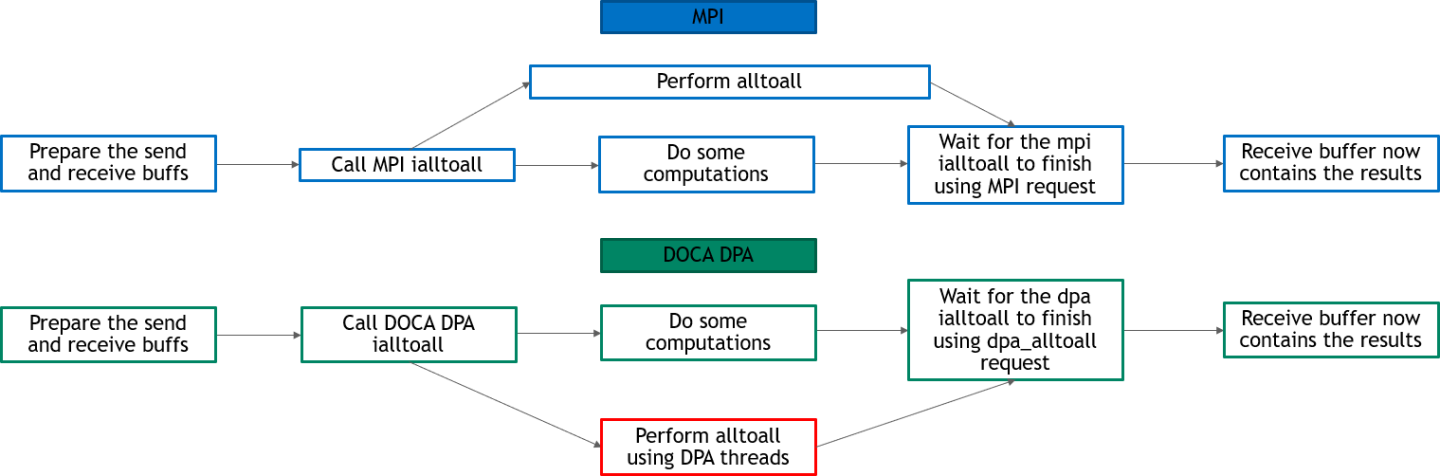
In DPA all-to-all, DPA threads perform all-to-all and the CPU is free to do other computations
In host-based all-to-all, CPU must still perform all-to-all at some point and is not completely free for other computations
This application leverages the following DOCA library:
Refer to its programming guide for more information.
NVIDIA BlueField-3 platform is required
The application can be run on target BlueField or on host.
Open MPI version 4.1.5rc2 or greater (included in DOCA's installation).
Please refer to the NVIDIA DOCA Installation Guide for Linux for details on how to install BlueField-related software.
The installation of DOCA's reference applications contains the sources of the applications, alongside the matching compilation instructions. This allows for compiling the applications "as-is" and provides the ability to modify the sources, then compile a new version of the application.
For more information about the applications as well as development and compilation tips, refer to the DOCA Applications page.
The sources of the application can be found under the application's directory: /opt/mellanox/doca/applications/dpa_all_to_all/.
Compiling All Applications
All DOCA applications are defined under a single meson project. So, by default, the compilation includes all of them.
To build all applications together, run:
cd /opt/mellanox/doca/applications/
meson /tmp/build
ninja -C /tmp/build
doca_dpa_all_to_all is created under /tmp/build/dpa_all_to_all/.
Compiling DPA All-to-all Application Only
To directly build only all-to-all application:
cd /opt/mellanox/doca/applications/
meson /tmp/build -Denable_all_applications=false -Denable_dpa_all_to_all=true
ninja -C /tmp/build
doca_dpa_all_to_all is created under /tmp/build/dpa_all_to_all/.
Alternatively, one can set the desired flags in meson_options.txt file instead of providing them in the compilation command line:
Edit the following flags in /opt/mellanox/doca/applications/meson_options.txt:
Set enable_all_applications to false
Set enable_dpa_all_to_all to true
Run the following compilation commands :
cd /opt/mellanox/doca/applications/ meson /tmp/build ninja -C /tmp/build
Infodoca_dpa_all_to_all is created under /tmp/build/dpa_all_to_all/.
Troubleshooting
Please refer to the NVIDIA DOCA Troubleshooting Guide for any issue encountered with the compilation of the application .
Prerequisites
MPI is used for compilation and running of this application. Make sure that MPI is installed on your setup (openmpi is provided as part of the installation of doca-tools).
The installation also requires updating the LD_LIBRARY_PATH and PATH environment variable to include MPI. For example, if openmpi is installed under /usr/mpi/gcc/openmpi-4.1.7a1 then updating the environment variables should be like this:
export PATH=/usr/mpi/gcc/openmpi-4.1.7a1/bin:${PATH}
export LD_LIBRARY_PATH=/usr/mpi/gcc/openmpi-4.1.7a1/lib:${LD_LIBRARY_PATH}
Application Execution
DPA all-to-all application is provided in source form. Therefore, a compilation is required before application can be executed.
Application usage instructions:
Usage: doca_dpa_all_to_all [DOCA Flags] [Program Flags] DOCA Flags: -h, --help Print a help synopsis -v, --version Print program version information -l, --log-level Set the (numeric) log level
forthe program <10=DISABLE,20=CRITICAL,30=ERROR,40=WARNING,50=INFO,60=DEBUG,70=TRACE> --sdk-log-level Set the SDK (numeric) log levelforthe program <10=DISABLE,20=CRITICAL,30=ERROR,40=WARNING,50=INFO,60=DEBUG,70=TRACE> -j, --json <path> Parse all command flags from an input json file Program Flags: -m, --msgsize <Message size> The message size - the size of the sendbuf and recvbuf (in bytes). Must be in multiplies of integer size. Default is size of one integer times the number of processes. -d, --devices <IB device names> IB devices names that supports DPA, separated by comma without spaces (max of two devices). If not provided then a random IB device will be chosen.InfoThis usage printout can be printed to the command line using the -h (or --help) option:
./doca_dpa_all_to_all -h
InfoFor additional information, please refer to section "Command Line Flags".
CLI example for running the application on host:
NoteThis is an MPI program, so use mpirun to run the application (with the -np flag to specify the number of processes to run).
The following runs the DPA all-to-all application with 8 processes using the default message size (the number of processes, which is 8, times the size of 1 integer) with a random InfiniBand device:
mpirun -np
8./doca_dpa_all_to_allThe following runs DPA all-to-all application with 8 processes, with 128 bytes as message size, and with mlx5_0 and mlx5_1 as the InfiniBand devices:
mpirun-np
8./doca_dpa_all_to_all -m128-d"mlx5_0,mlx5_1"NoteThe application supports running with a maximum of 16 processes. If you try to run with more processes, an error is printed and the application exits.
The application also supports a JSON-based deployment mode, in which all command-line arguments are provided through a JSON file:
./doca_dpa_all_to_all --json [json_file]
For example:
./doca_dpa_all_to_all --json ./dpa_all_to_all_params.json
NoteBefore execution, ensure that the used JSON file contains the correct configuration parameters, especially the InfiniBand device identifiers.
Command Line Flags
|
Flag Type |
Short Flag |
Long Flag/JSON Key |
Description |
JSON Content |
|
General flags |
h |
help |
Prints a help synopsis |
N/A |
|
v |
version |
Prints program version information |
N/A |
|
|
l |
log-level |
Set the log level for the application:
|
|
|
|
N/A |
sdk-log-level |
Sets the log level for the program:
|
|
|
|
j |
json |
Parse all command flags from an input json file |
N/A |
|
|
Program flags |
m |
msgsize |
The message size. The size of the sendbuf and recvbuf (in bytes). Must be in multiples of an integer. The default is size of 1 integer times the number of processes. |
Note
The value -1 is a placeholder to use the default size, which is only known at run time (because it depends on the number of processes). |
|
d |
devices |
InfiniBand devices names that support DPA, separated by comma without spaces (max of two devices). If NOT_SET then a random InfiniBand device is chosen. |
|
Refer to DOCA Arg Parser for more information regarding the supported flags and execution modes.
Troubleshooting
Refer to the NVIDIA DOCA Troubleshooting Guide for any issue encountered with the installation or execution of the DOCA applications .
Initialize MPI.
MPI_Init(&argc, &argv);
Parse application arguments.
Initialize arg parser resources and register DOCA general parameters.
doca_argp_init();
Register the application's parameters.
register_all_to_all_params();
Parse the arguments.
doca_argp_start();
The msgsize parameter is the size of the sendbuf and recvbuf (in bytes). It must be in multiples of an integer and at least the number of processes times an integer size.
The devices_param parameter is the names of the InfiniBand devices to use (must support DPA). It can include up to two devices names.
Only let the first process (of rank 0) parse the parameters to then broadcast them to the rest of the processes.
Check and prepare the needed resources for the all_to_all call:
Check the number of processes (maximum is 16).
Check the msgsize. It must be in multiples of integer size and at least the number of processes times integer size.
Allocate the sendbuf and recvbuf according to msgsize.
Prepare the resources required to perform all-to-all method using DOCA DPA:
Initialize DOCA DPA context:
Open DOCA DPA device (DOCA device that supports DPA).
open_dpa_device(&doca_device);
Initialize DOCA DPA context using the opened device.
extern struct doca_dpa_app *dpa_all2all_app; doca_dpa_create(doca_device, &doca_dpa); doca_dpa_set_app(doca_dpa, dpa_all2all_app); doca_dpa_start(doca_dpa);
Initialize the required DOCA Sync Events for the all-to-all:
One completion event for the kernel launch where the subscriber is CPU and the publisher is DPA.
Kernel events, published by remote peer and subscribed to by DPA, as the number of processes.
create_dpa_a2a_events() {
// initialize completion eventdoca_sync_event_create(&comp_event); doca_sync_event_add_publisher_location_dpa(comp_event); doca_sync_event_add_subscriber_location_cpu(comp_event); doca_sync_event_start(comp_event);// initialize kernels eventsfor(i =0; i < resources->num_ranks; i++) { doca_sync_event_create(&(kernel_events[i])); doca_sync_event_add_publisher_location_remote_net(kernel_events[i]); doca_sync_event_add_subscriber_location_dpa(kernel_events[i]); doca_sync_event_start(kernel_events[i]); } }
Prepare DOCA RDMAs and set them to work on DPA:
Create DOCA RDMAs as the number of processes/ranks.
for(i =0; i < resources->num_ranks; i++) { doca_rdma_create(&rdma); rdma_as_doca_ctx = doca_rdma_as_ctx(rdma); doca_rdma_set_permissions(rdma); doca_rdma_set_grh_enabled(rdma); doca_ctx_set_datapath_on_dpa(rdma_as_doca_ctx, doca_dpa); doca_ctx_start(rdma_as_doca_ctx); }Connect local DOCA RDMAs to the remote DOCA RDMAs.
connect_dpa_a2a_rdmas();
Get DPA handles for local DOCA RDMAs (so they can be used by DPA kernel) and copy them to DPA heap memory.
for(inti =0; i < resources->num_ranks; i++) { doca_rdma_get_dpa_handle(rdmas[i], &(rdma_handles[i])); } doca_dpa_mem_alloc(&dev_ptr_rdma_handles); doca_dpa_h2d_memcpy(dev_ptr_rdma_handles, rdma_handles);
Prepare the memory required to perform all-to-all method using DOCA Mmap. This includes creating DPA memory handles for sendbuf and recvbuf, getting other processes recvbufs handles, and copying these memory handles and their remote keys and events handlers to DPA heap memory.
prepare_dpa_a2a_memory();
Launch alltoall_kernel using DOCA DPA kernel launch with all required parameters:
Every MPI rank launches a kernel of up to MAX_NUM_THREADS. This example defines MAX_NUM_THREADS as 16.
Launch alltoall_kernel using kernel_launch.
doca_dpa_kernel_launch_update_set();
Each process should perform num_ranks RDMA write operations, with local and remote buffers calculated based on the rank of the process that is performing the RDMA write operation and the rank of the remote process that is being written to. The application iterates over the rank of the remote process.i
Each process runs num_threads threads on this kernel, therefore the number of RDMA write operations (which is the number of processes) is divided by the number of threads.
Each thread should wait on its local events to make sure that the remote processes have finished RDMA write operations.
Each thread should also synchronize its RDMA DPA handles to make sure that the local RDMA operation calls has finished.
for(i = thread_rank; i < num_ranks; i += num_threads) { doca_dpa_dev_rdma_post_write(); doca_dpa_dev_rdma_signal_set(); }for(i = thread_rank; i < num_ranks; i += num_threads) { doca_dpa_dev_sync_event_wait_gt(); doca_dpa_dev_rdma_synchronize(); }Wait until alltoall_kernel has finished.
doca_sync_event_wait_gt();
NoteAdd an MPI barrier after waiting for the event to make sure that all of the processes have finished executing alltoall_kernel.
MPI_Barrier();
After alltoall_kernel is finished, the recvbuf of all processes contains the expected output of all-to-all method.
Destroy a2a_resources:
Free all DOCA DPA memories.
doca_dpa_mem_free();
Destroy all DOCA Mmaps
doca_mmap_destroy();
Destroy all DOCA RDMAs.
doca_ctx_stop(); doca_rdma_destroy();
Destroy all DOCA Sync Events.
doca_sync_event_destroy();
Destroy DOCA DPA context.
doca_dpa_destroy();
Close DOCA device.
doca_dev_close();
/opt/mellanox/doca/applications/dpa_all_to_all/
/opt/mellanox/doca/applications/dpa_all_to_all/dpa_all_to_all_params.json