NVIDIA DOCA Allreduce Application Guide
This guide provides a DOCA Allreduce collective operation implementation on top of NVIDIA® BlueField® DPU using UCX.
Allreduce is a collective operation which allows collecting data from different processing units to combine them into a global result by a chosen operator. In turn, the result is distributed back to all processing units.
Allreduce operates in stages. Firstly, each participant scatters its vector. Secondly, each participant gathers the vectors of the other participants. Lastly, each participant performs their chosen operation between all the gathered vectors. Using a sequence of different allreduce operations with different participants, very complex computations can be spread among many computation units.
Allreduce is widely used by parallel applications in high-performance computing (HPC) related to scientific simulations and data analysis, including machine learning calculation and the training phase of neural networks in deep learning.
Due to the massive growth of deep learning models and the complexity of scientific simulation tasks that utilize a network, effective implementation of allreduce is essential for minimizing communication time.
This document describes how to implement allreduce using the UCX communication framework, which leverages NVIDIA® BlueField® DPU by providing low-latency and high-bandwidth utilization of its network engine.
This document describes the following types of allreduce:
Offloaded client – processes running on the host which only submit allreduce operation requests to a daemon running on the DPU. The daemon runs on the DPU and performs the allreduce algorithm on behalf of its on-host-clients (offloaded-client).
Non-offloaded client – processes running on the host which execute the allreduce algorithm by themselves
The application is designed to measure three metrics:
Communication time taken by offloaded and non-offloaded allreduce operations
Computation time taken by matrix multiplications which are done by clients until the allreduce operation is completed
The overlap of the two previous metrics. The percentage of the total runtime during which both the allreduce and the matrix multiplications were done in parallel.
The allreduce implementation is divided into two different types of processes: clients and daemons. Clients are responsible for allocating vectors filled with data and initiating allreduce operations by sending a request with a vector to their daemon. Daemons are responsible for gathering vectors from all connected clients and daemons, applying a chosen operator on all received buffers, and then scattering the reduced result vector back to the clients.
Offloaded mode

Non-offloaded mode

DOCA's allreduce implementation uses Unified Communication X (UCX) to support data exchange between endpoints. It utilizes UCX's sockaddr-based connection establishment and the UCX Active Messages (AM) API for communications.
Offloaded mode

Non-offloaded mode

Connections between processes are established by UCX using IP addresses and ports of peers.
Allreduce vectors are sent from clients to daemons in offloaded mode, or from clients to clients in non-offloaded mode.
Reduce operations on vectors are done using received vectors from other daemons in offloaded mode, or other clients in non-offloaded mode.
Vectors with allreduce results are received by clients from daemons in offloaded mode, or are already stored in clients after completing all exchanges in non-offloaded mode.
After completing all allreduce operations, connections between clients are destroyed.
This application leverages the UCX framework DOCA driver.
Please refer to the NVIDIA DOCA Installation Guide for Linux for details on how to install BlueField-related software.
The installation of DOCA's reference applications contains the sources of the applications, alongside the matching compilation instructions. This allows for compiling the applications "as-is" and provides the ability to modify the sources, then compile a new version of the application.
For more information about the applications as well as development and compilation tips, refer to the DOCA Applications page.
The sources of the application can be found under the application's directory: /opt/mellanox/doca/applications/allreduce/.
Compiling All Applications
All DOCA applications are defined under a single meson project. So, by default, the compilation includes all of them.
To build all the applications together, run:
cd /opt/mellanox/doca/applications/
meson /tmp/build
ninja -C /tmp/build
doca_allreduce is created under /tmp/build/allreduce/.
Compiling Only the Current Application
To build the allreduce application only:
cd /opt/mellanox/doca/applications/
meson /tmp/build -Denable_all_applications=false -Denable_allreduce=true
ninja -C /tmp/build
doca_allreduce is created under /tmp/build/allreduce/.
Alternatively, the user can set the desired flags in the meson_options.txt file instead of providing them in the compilation command line:
Edit the following flags in /opt/mellanox/doca/applications/meson_options.txt:
Set enable_all_applications to false
Set enable_allreduce to true
Run the following compilation commands:
cd /opt/mellanox/doca/applications/ meson /tmp/build ninja -C /tmp/build
Infodoca_allreduce is created under /tmp/build/allreduce/.
Troubleshooting
Please refer to the NVIDIA DOCA Troubleshooting Guide for any issue encountered with the compilation of the application .
Application Execution
The allreduce application is provided in source form, hence a compilation is required before the application can be executed.
Application usage instructions:
Usage: doca_allreduce [DOCA Flags] [Program Flags] DOCA Flags: -h, --help Print a help synopsis -v, --version Print program version information -l, --log-level Set the (numeric) log level
forthe program <10=DISABLE,20=CRITICAL,30=ERROR,40=WARNING,50=INFO,60=DEBUG,70=TRACE> --sdk-log-level Set the SDK (numeric) log levelforthe program <10=DISABLE,20=CRITICAL,30=ERROR,40=WARNING,50=INFO,60=DEBUG,70=TRACE> -j, --json <path> Parse all command flags from an input json file Program Flags: -r, --role Run DOCA UCX allreduce process as:"client"or"daemon"-m, --mode <allreduce_mode> Set allreduce mode:"offloaded","non-offloaded"(validforclient only) -p, --port <port> Setdefaultdestination port of daemons/clients, usedforIPs without a port (see'-a'flag) -t, --listen-port <listen_port> Set listening port of daemon or client -c, --num-clients <num_clients> Set the number of clients which participate in allreduce operations (validfordaemon only) -s, --size <size> Set size of vector todoallreducefor-d, --datatype <datatype> Set datatype ("byte","int","float","double") of vector elements todoallreducefor-o, --operation <operation> Set operation ("sum","prod") todobetween allreduce vectors -b, --batch-size <batch_size> Set the number of allreduce operations submitted simultaneously (usedforhandshakes by daemons) -i, --num-batches <num_batches> Set the number of batches of allreduce operations (usedforhandshakes by daemons) -a, --address <ip_address> Set comma-separated list of destination IPv4/IPv6 addresses and ports optionally (<ip_addr>:[<port>]) of daemons or clientsInfoThis usage printout can be printed to the command line using the -h (or --help) options:
./doca_allreduce -h
InfoFor additional information, refer to section "Command Line Flags".
Configuration steps.
All daemons should be deployed before clients. Only after connecting to their peers are daemons able to handle clients.
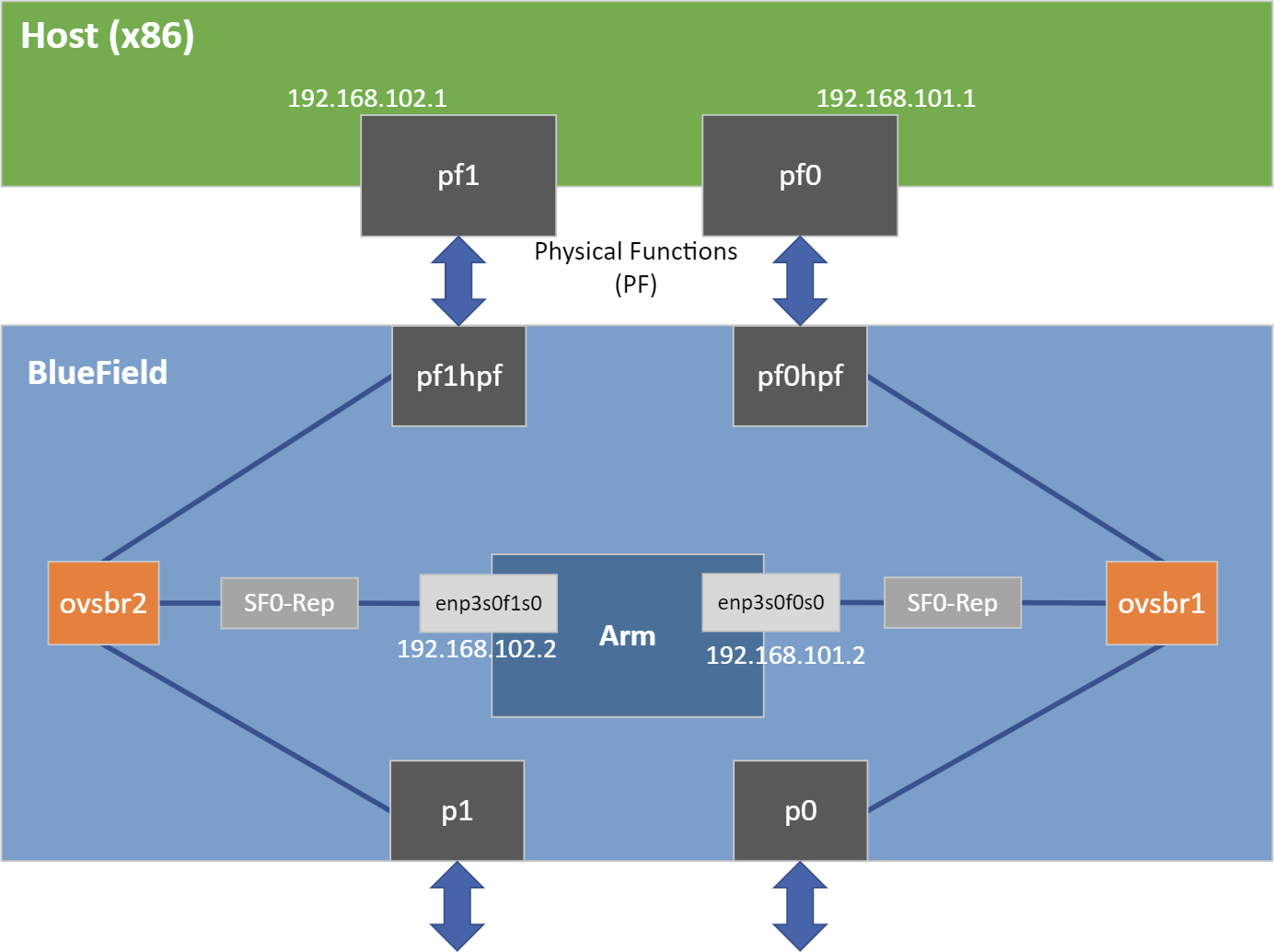
UCX probes the system for any available net/IB devices and, by default, tries to create a multi-device connection. This means that if some network devices are available but provide an unreachable path from the daemon to the peer/client, UCX may still use that path. A common case is that a daemon tries to connect to a different BlueField using tmfifo_net0 which is connected to the host only. To fix this issue, follow these steps:
Use the UCX env variable UCX_NET_DEVICES to set usable devices. For example:
export UCX_NET_DEVICES=enp3s0f0s0,enp3s0f1s0 ./doca_allreduce -r daemon -t
34001-c1-s100-o sum -dfloat-b16-i16Or:
env UCX_NET_DEVICES=enp3s0f0s0,enp3s0f1s0 ./doca_allreduce -r daemon -t
34001-c1-s100-o sum -dfloat-b16-i16Get the mlx device name and port of a SF to limit the UCX network interfaces and allow IB. For example:
BlueField> show_gids DEV PORT INDEX GID IPv4 VER DEV --- ---- ----- --- ------------ --- --- mlx5_2
10fe80:0000:0000:0000:0052:72ff:fe63:1651v2 enp3s0f0s0 mlx5_310fe80:0000:0000:0000:0032:6bff:fe13:f13a v2 enp3s0f1s0 BlueField> UCX_NET_DEVICES=enp3s0f0s0,enp3s0f1s0,mlx5_2:1,mlx5_3:1./doca_allreduce -r daemon -t34001-c1-s100-o sum -dfloat-b16-i16
CLI example for running the deamon on BlueField:
./doca_allreduce -r daemon -t
34001-c2-a10.21.211.3:35001,10.21.211.4:36001-s65535-o sum -dfloat-i16-b128Notes:
The flag -a is necessary for communicating with other daemons. In case of an offloaded client, the address must be that of the daemon which performs the allreduce operations for them. In case of a daemon or non-offloaded clients, the flag could be a single or multiple addresses of other daemons/non-offloaded clients which exchange their local allreduce results.
The flag -c must be specified for daemon processes only. It indicates how many clients submit their allreduce operations to the daemon.
The flags -s, -i, -b, and -d must be the same for all clients and daemons participating in the allreduce operation.
NoteThe daemon listens to incoming connection requests on all available IPs, but the actual communication after the initial "UCX handshake" does not necessarily use the same device used for the connection establishment.
CLI example for running the client on the host:
./doca_allreduce -r client -m non-offloaded -t
34001-a10.21.211.3:35001,10.21.211.4:36001-s65535-i16-b128-o sum -dfloat./doca_allreduce -r client -m offloaded -p34001-a192.168.100.2-s65535-i16-b128-o sum -dfloatThe application also supports a JSON-based deployment mode, in which all command-line arguments are provided through a JSON file:
./doca_allreduce --json [json_file]
For example:
./doca_allreduce --json ./allreduce_client_params.json
NoteBefore execution, ensure that the used JSON file contains the correct configuration parameters, and especially the desired PCIe and network addresses required for the deployment.
Command Line Flags
|
Flag Type |
Short Flag |
Long Flag/JSON Key |
Description |
|
General flags |
h |
help |
Print a help synopsis |
|
v |
version |
Print program version information |
|
|
l |
log-level |
Set the log level for the application:
|
|
|
N/A |
sdk-log-level |
Sets the log level for the program:
|
|
|
j |
json |
Parse all command flags from an input JSON file |
|
|
Program flags |
r |
role |
Run DOCA UCX allreduce process as either client or daemon |
|
m |
mode |
Set allreduce mode. Available types options:
|
|
|
p |
port |
Set default destination port of daemons/clients. Used for IPs without a port (see -a flag). |
|
|
c |
num-clients |
Set the number of clients which participate in allreduce operations Note: Valid for daemon only. |
|
|
s |
size |
Set size of vector to perform allreduce for |
|
|
d |
datatype |
Set datatype of vector elements to do allreduce for
|
|
|
o |
operation |
Set operation to perform between allreduce vectors |
|
|
b |
batch-size |
Set the number of allreduce operations submitted simultaneously. Used for handshakes by daemons. |
|
|
i |
num-batches |
Set the number of batches of allreduce operations. Used for handshakes by daemons. |
|
|
t |
listen-port |
Set listening port of daemon or client |
|
|
a |
address |
Set comma-separated list of destination IPv4/IPv6 address and ports optionally of daemons or clients. Format: <ip_addr>:[<port>]. |
Refer to DOCA Arg Parser for more information regarding the supported flags and execution modes.
Troubleshooting
Refer to the NVIDIA DOCA Troubleshooting Guide for any issue encountered with the installation or execution of the DOCA applications.
This section details the steps necessary to run DOCA Allreduce on NVIDIA converged accelerator.
Allreduce running on the converged accelerator has the same logic as described in previous sections except for the reducing of vectors. The reduce of incoming vectors is performed on the GPU side in batches that include the vectors from all peers or all clients. When the GPUDirect module is active, incoming vectors and outgoing vectors are received/sent directly to/from the GPU.
To make use of the GPU's capabilities, make sure to perform the following:
Refer to the NVIDIA DOCA Installation Guide for Linux for instructions on installing NVIDIA driver for CUDA and a CUDA-repo on your setup.
Create the sub-functions and configure the OVS according to NVIDIA BlueField DPU Scalable Function User Guide.
Compiling and Running Application
To build and run the application:
Setup CUDA paths:
export CPATH=/usr/local/cuda/targets/sbsa-linux/include:$CPATH export LD_LIBRARY_PATH=/usr/local/nvidia/lib:/usr/local/nvidia/lib64:$LD_LIBRARY_PATH export PATH=/usr/local/nvidia/bin:/usr/local/cuda/bin:$PATH
Reinstall UCX with CUDA support. Follow the UCX installation procedure with an additional flag, --with-cuda=/usr/local/cuda/, passed to configure-release:
dpu# ./contrib/configure-release --with-cuda=/usr/local/cuda/
To build the application with GPU support:
Set the enable_gpu_support flag to true in /opt/mellanox/doca/applications/meson_option.txt.
Compile the application sources. Run:
cd /opt/mellanox/doca/applications/ meson /tmp/build ninja -C /tmp/build
doca_allreduce_gpu is created under /tmp/build/allreduce/ alongside the regular doca_allreduce binary that is compiled without the GPU support.
To run the application with GPU support, follow the same steps as described in section "Running the Application".
Parse application argument.
Initialize arg parser resources and register DOCA general parameters.
doca_argp_init();
Register UCX allreduce application parameters.
register_allreduce_params();
Parse all registered parameters.
doca_argp_start();
UCX initialization.
Initialize hash table of connections.
allreduce_ucx_init();
Create UCP context.
ucp_init();
Create UCP worker.
ucp_worker_create();
Set AM handler for receiving connection check packets.
ucp_worker_set_am_recv_handler();
Initialization of the allreduce connectivity.
communication_init();
Initialize hash table of allreduce super requests.
Set "receive callback" for handshake messages.
If daemon or non-offloaded client:
Set AM handler for receiving allreduce requests from clients.
allreduce_ucx_am_set_recv_handler();
Initialize UCX listening function. This creates a UCP listener.
allreduce_ucx_listen();
Initialize all connections.
connections_init();
Go over all destination addresses and connect to each peer.
Repeat until a successful send occurs (to check connectivity).
ucp_am_send_nbx(); allreduce_ucx_request_wait();
Insert the connection to the hash table of connections.
allreduce_outgoing_handshake();
Scatter handshake message to peers/daemon to make sure they all have the same -s, -i, -b, and -d flags.
Daemon: Start UCX progress.
daemon_run();
Set AM handler to receive allreduce requests from clients.
allreduce_ucx_am_set_recv_handler();
Perform UCP worker progress.
while(running) allreduce_ucx_progress();Callbacks are invoked by incoming/outgoing messages by calling allreduce_ucx_progress.
Client:
client_run();
Allocate buffers to store allreduce initial data and results.
allreduce_vectors_init();
Set an AM handler for receiving allreduce results.
allreduce_ucx_am_set_recv_handler();
Perform allreduce barrier. Check that all daemons and clients are active.
allreduce_barrier();
Submit a batch of allreduce operations with 0 byte.
Wait for completions.
Reset metrics and vectors.
allreduce_metrics_init();
Submit some batches and calculate estimated network time.
Allocate matrices to multiply.
Estimate how many matrix multiplications could have been performed instead of networking (same time window).
Calculate the actual computation time of these matrix multiplications.
Reset vectors.
Submit a batch of allreduce operations to daemon/peer (depends on mode).
Perform matrix multiplications during a time period which is approximately equal to doing a single batch of allreduce operations and calculate the actual time cost.
Wait for the allreduce operation to complete and calculate time cost.
Update metrics.
Do num-batches (flag) times: allreduce_vectors_reset(); allreduce_batch_submit(); cpu_exploit(); allreduce_batch_wait(); allreduce_metrics_calculate();
Print summary of allreduce benchmarking.
allreduce_metrics_print();
Arg parser destroy.
doca_argp_destroy();
Communication destroy.
Clean up connections.
allreduce_ucx_disconnect();
Remove the connection from the hash table of the connections.
Close inner UCP endpoint.
ucp_ep_close_nbx();
Wait for the completion of the UCP endpoint closure.
Destroy connection.
Free connections array.
Destroy the hash table of the allreduce super requests.
Destroy UCX context.
Destroy the hash table of the connections.
g_hash_table_destroy();
If the UCP listener was created, destroy it.
ucp_listener_destroy();
Destroy UCP worker.
ucp_worker_destroy();
Destroy UCP context.
ucp_cleanup();
/opt/mellanox/doca/applications/allreduce/
/opt/mellanox/doca/applications/allreduce/allreduce_client_params.json
/opt/mellanox/doca/applications/allreduce/allreduce_daemon_params.json