

Full-Stack Optimizations for Agentic Inference with Dynamo
Full-Stack Optimizations for Agentic Inference with Dynamo
Ishan Dhanani and Matej Kosec — March 2026
Coding agents are starting to write production code at scale. Stripe’s agents generate 1,300+ PRs per week. Ramp attributes 30% of merged PRs to agents. Spotify reports 650+ agent-generated PRs per month. Tools like Claude Code and Codex make hundreds of API calls per coding session, each carrying the full conversation history. Behind every one of these workflows is an inference stack under significant KV cache pressure.
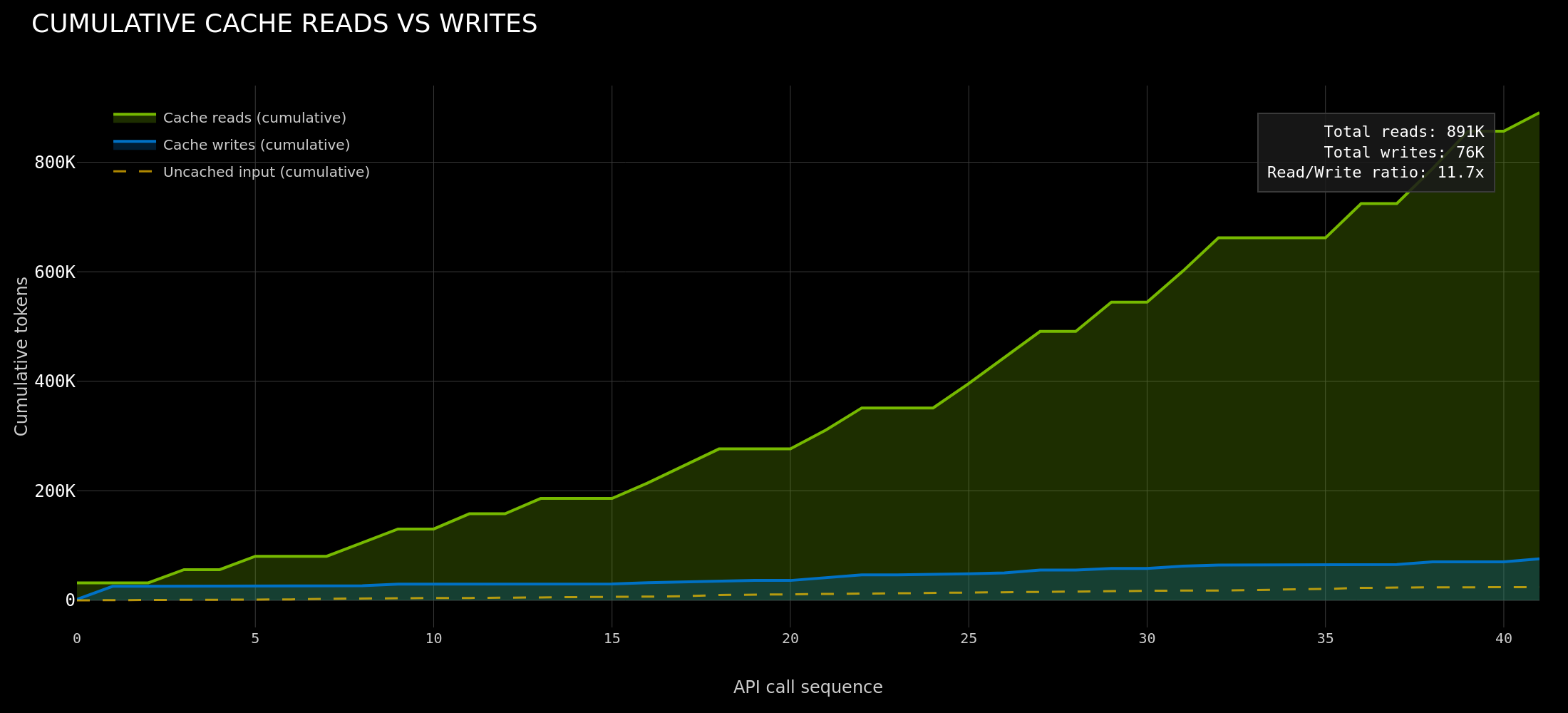
Lets take Claude Code as an example. After the first API call that writes the conversation prefix to KV cache, every subsequent call to the same worker hits 85-97% cache. Agent teams (or swarms) push this further with 97.2% aggregate cache hit rate across 4 Opus teammates. An 11.7x read/write ratio means the system reads from cache nearly 12 times for every token it writes. This is a write-once-read-many (WORM) access pattern: the system prompt and growing conversation prefix are computed once, then served from cache on every subsequent call. Maximizing cache reuse rate across all workers and keeping KV blocks warm and routable is the central optimization target for agentic inference.
These numbers come from managed API infrastructure where the provider controls prefix matching, cache placement, and eviction. For teams running open-source models on their own GPUs, none of this exists out of the box. We have been building Dynamo to close that gap. This post walks through how we are making Dynamo agent-native at three layers: the frontend API, the router, and KV cache management.
Throughout this post, we use three terms consistently:
- Harness: the agent framework that drives the workflow (Claude Code, Codex, OpenClaw, OpenCode, etc.)
- Orchestrator: Dynamo’s routing, scheduling, and cache management layer
- Runtime: the inference engine that executes the model and owns the kv cache manager (SGLang, vLLM, TRT-LLM)
Layer 1: The Frontend
Multi-Protocol Support
Agent harnesses are increasingly adopting v1/responses and v1/messages over v1/chat/completions to cleanly handle new patterns including interleaved thinking and tool calls. The key difference in these APIs is structural. In v1/chat/completions, message content is a flat string and tool calls are bolted on as a separate field. As an example, notice how GLM and MiniMax API handle interleaved thinking differently when hosting their model behind the v1/chat/completions endpoint. The v1/responses and v1/messages APIs use typed content blocks, so a single assistant turn can contain thinking, tool calls, and text as distinct objects. This matters for inference because the orchestrator can see block boundaries, perform prompt optimizations, and apply different cache and scheduling policies per block type. Dynamo serves all three endpoints through a common internal representation, so a single deployment can act as the inference backend for any harness. Our team has been running a Dynamo deployment of GLM-5 and MiniMax2.5 internally to power our Codex and Claude Code harnesses. This lets us benchmark our backend implementations against closed-source inference, targeting parity on cache reuse performance. We will be sharing a full write-up and some optimized recipes for deploying both models in the upcoming weeks.
We have also invested in day-0 tool call and reasoning parsing support for various open-source models. If you find that a model is not supported, please open an issue or use the tool-call-parser-generator skill to generate it with your harness of choice.
Agent Hints: The Harness-Orchestrator Interface
Today, inference servers see anonymous tokenized requests. But agent harnesses have global context that the infrastructure never sees: which agents are blocked on tool calls, which just spawned, how many turns remain in a session, and whether the current call is a quick lookup or a long synthesis. When using coding agents, the user waits for a final result, not individual token streams, so the orchestrator can reorder and prioritize requests across agents without affecting the end-user experience. Sessions run for minutes to even days with long tool-call pauses. This is enough to optimize inference scheduling in ways that traditional serving cannot.

Dynamo’s new agent hints extension was designed to bridge this gap. It allows any harness to attach structured hints to a request across all three API endpoints, giving the router and runtime the context they need to make agent aware scheduling and caching decisions. This is a v1 API that we are actively co-designing with the community and would love feedback from teams building agent harnesses on what signals are most useful. Please reach out to us if you have any ideas or feedback!
The agent_hints fields:
prioritycontrols scheduling across both the router and engine. Higher values mean “more important” at the Dynamo API level; Dynamo translates that into router queue ordering and backend-specific engine priority.osl(output sequence length) is the harness’s estimate of how many tokens this request will generate. The router uses this to gauge how long a worker will be occupied, which improves load balancing. A harness can learn this over time by tracking average output lengths per tool call type.speculative_prefillsignals the orchestrator to begin caching this request’s prefix on a likely worker before the full request is ready. This is useful when the harness knows a tool call is about to return and wants to warm the cache ahead of time.
As of current Dynamo, nvext.cache_control is not a supported cache-pinning request extension. Anthropic-format requests may carry cache_control annotations for API compatibility, but Dynamo does not treat them as self-hosted TTL pinning directives. The supported public serving controls live under agent_hints; see the NVIDIA Request Extensions reference.
Layer 2: The Router
A coding agent follows a sequential pattern: long prefill, tool call, extend prefix, repeat. A multi-agent harness fans out work across parallel subagents with short, independent contexts. Default round-robin routing is blind to both patterns — it cannot account for cache locality, request priority, or session structure. Dynamo’s router closes this gap with three mechanisms: KV-aware placement, priority scheduling, and extensible routing strategies.
KV-Aware Placement
Without cache-aware routing, turn 2 of a conversation has a ~1/N chance of landing on the same worker as turn 1. Every miss is a full prefix recomputation which is a significant performance bottleneck and extremely costly for an end user. Dynamo’s router maintains a global index of which KV cache blocks exist on which workers. The Flash Indexer post covers the six iterations that got this indexer to 170M ops/s (planetary scale KV routing). On every request, the router queries the index for per-worker overlap scores and selects the worker that minimizes the combined cost of cache miss and current decode load. This cost function is tunable, and we show below how teams can build custom agent aware routing strategies on top of it.
Priority Scheduling
priority is the single user-facing scheduling knob. Higher values mean “more important” at the Dynamo API level. Dynamo uses that one hint at both layers:
- At the router, higher-priority requests are shifted earlier in the queue when
--router-queue-thresholdis enabled. - At the engine, Dynamo normalizes backend-specific polarity and forwards the request for queue ordering, preemption, and KV cache eviction.
At the router, incoming requests enter a BinaryHeap<QueueEntry> ordered by effective arrival time. A higher priority makes the request appear as if it arrived earlier, placing it ahead of lower-priority work. Requests only enter the queue when all workers exceed a configurable load threshold. Below that threshold, they bypass the queue entirely and go straight to worker selection. When capacity frees up (prefill completes or a request finishes), the queue drains highest-priority entries first.
Once dispatched, SGLang, vLLM, and TRT-LLM may interpret engine priority differently, so Dynamo normalizes the engine-facing value per backend. Engines like SGLang can also use priority-based radix cache eviction where lower-priority blocks are evicted first under memory pressure.

Agentic Workload Routing Strategies
A research agent with a 200K context window needs workers with enough free KV capacity to hold its full state. The router’s default cost function (overlap score + decode load) handles the common case, but teams with domain-specific workloads can use the router’s Python bindings to implement custom routing strategies. The core KvRouter class provides best_worker() for querying routing decisions, get_potential_loads() for per-worker load inspection, and generate() for routing + dispatch in one call. Custom routers register on the same service mesh as the default components and can override routing config per-request:
The NeMo Agent Toolkit (NAT) team used these APIs to build a custom online-learning agentic router. Their router extracts session metadata from nvext annotations and feeds it to a Thompson Sampling bandit style cost function that learns which workers perform best for which prefix patterns under load. Compared to Dynamo’s default routing, they measured 4x reduction in p50 TTFT and 1.5x increase in p50 tokens-per-second. Priority tagging of latency-sensitive requests achieved up to 63% p50 TTFT reduction under moderate memory pressure. See the NAT Dynamo integration example for implementation details. We will be making this available as a routing strategy in Dynamo soon.
Layer 3: KV Cache Management
Agentic workloads produce blocks with vastly different reuse value — system prompts reused every turn, reasoning tokens never reused again — but default LRU eviction treats all blocks identically. A 2-30 second tool call pause can age out an agent’s entire prefix, forcing full recomputation when it resumes. The cache needs to understand block value, support cross-worker sharing, and respect agent lifecycle boundaries.
The Problem with Uniform Eviction
LRU sees only recency. In a high traffic environment, a wait for the completion of a called tool (2-30 seconds while the agent waits for an external API) might cause the agent’s blocks to age out and when the agent resumes, the entire prefix must be recomputed. To solve this, we need to provide the orchestrator APIs to control which blocks should be retained, where they should live, and for how long.
KV Cache as a Shared Resource
Today, KV cache is treated as a local, ephemeral resource on each worker. An agent’s ~32K-token system prompt and tool definitions are computed independently on every worker that serves its requests. When a lead agent spawns 4 subagents, each with overlapping tool definitions, that shared prefix is recomputed 4 times if the subagents land on different workers. In our analysis of Claude Code team sessions, we measured this directly: teammates averaged 79.4% cache hit rate vs. 91.3% for the lead agent’s explore subagents (5.0x vs. 11.7x read/write ratio), with the gap driven almost entirely by cold-start writes on each teammate’s first call. The goal is to make high value KV cache blocks available to all workers in the cluster. Essentially, they are written once during cold start and then read by any worker at all times.
Solutions like SGLang’s HiCache and Dynamo’s KV Block Manager (KVBM) are building toward a 4-tier memory hierarchy:

Blocks follow a write-through path: when a worker computes KV for a prefix, the blocks flow from GPU to CPU to disk automatically. Each block is deduplicated by sequence hash in a global registry. Once a block is registered, it is immutable and addressable by any worker that can reach the storage tier.
This directly solves the subagent cold-start problem. When the lead agent computes tool definitions and system prompt, those blocks write through to shared storage. When subagent 1 spawns on a different worker, the router queries the Flash Indexer, finds the blocks in shared storage, and the worker loads them via NIXL (RDMA read) instead of recomputing from scratch. Subagent 2 does the same. Four redundant prefill computations become one compute and three loads. The same mechanism addresses cache coherence in disaggregated prefill-decode serving. In disagg mode, the prefill worker computes KV and transfers it to the decode worker via NIXL. The decode worker generates tokens, producing new KV state. On the next turn, a prefill worker needs both the original prefix and the generated tokens from turn 1, but those live only on the decode worker. With shared storage, the decode worker writes its new blocks to the common tier and any prefill worker can fetch them on the next turn.
Multi-tier storage solves sharing and persistence, but blocks still arrive on GPU only after the request hits the worker. The missing piece for agentic systems is prefetch: the harness can use historical timing data to predict when an agent’s tool call might return, which means it knows which blocks will be needed and when. We are building prefetch hooks so the harness can signal “bring these blocks from storage to GPU ahead of the next request.” Combined with priority metadata today and richer retention APIs in the future, this gives the harness a path toward full lifecycle control: retain high-value blocks longer, control eviction ordering, and prefetch blocks proactively before they are needed.

Selective Cache Retention
Making blocks globally available solves the sharing problem, but does not solve eviction. SGLang currently exposes priority-based radix eviction, where the harness assigns a numeric priority per request and lower-priority blocks are evicted first. TensorRT-LLM takes this further with TokenRangeRetentionConfig (designed and implemented by a Dynamo team member @jthomson04), which allows per-region control within a single request.
The general design pattern is to attach zero or more retention directives to a request or token range. Blocks without directives follow the default LRU path with zero overhead. The evictor becomes a two-structure system: an LRU free list for unprioritized blocks (O(1), unchanged) and a priority queue for annotated blocks. Dynamo’s public agent surface exposes the priority part today through nvext.agent_hints.priority; TTL or per-token-range retention directives are future API work.
Anthropic’s prompt caching lets you mark prefixes as cacheable on their infrastructure. Dynamo does not currently expose the same semantics as a self-hosted nvext.cache_control TTL pinning API. The supported production path is priority-driven: nvext.agent_hints.priority can influence router queueing and, when the backend enables it, engine scheduling and priority-aware cache eviction. SGLang can additionally tag ordinary evictable radix KV by session.
The next step is connecting richer retention directives with the distributed cache. Today, priority and session metadata are local serving signals, not a cluster-wide per-block TTL lease. Extending retention semantics across HiCache/KVBM’s shared storage tier would let the harness mark a block once and have its priority, lifetime, and placement intent travel with it through the write-through path. Combined with the prefetch hooks described above, this gives the harness end-to-end lifecycle control across the full memory hierarchy.
Agent Lifecycle Awareness
Consider a typical Claude Code session. The lead agent runs for 20+ turns, accumulating a growing conversation prefix. Along the way it spawns explore subagents that each run 1-3 turns and terminate. It might spawn a team of 4 specialists that work in parallel on different subtasks and then terminate. Midway through, the agent hits a context limit and summarizes its history, compressing ~175K tokens down to ~40K. Each of these events produces ephemeral KV: blocks that will never be referenced again. Subagent termination, context summarization, and closed reasoning loops all generate ephemeral KV that occupies the same memory as high-value blocks like the system prompt. Reasoning models amplify this: <think>...</think> blocks account for ~40% of generated tokens but become ephemeral the moment the reasoning loop closes. Without lifecycle awareness, the cache treats all of these blocks identically.

The retention primitives above give us the building blocks: priority today, and TTL or token-range directives as future extensions. What is missing is the ability to associate them with sessions. If the harness can tag a subagent’s requests as belonging to a session and mark that session’s KV as ephemeral, the evictor can target those blocks first and skip writing them to shared storage entirely. When the subagent terminates, its session’s blocks are the first to reclaim. The same mechanism applies to thinking tokens: the engine can detect <think> boundaries during generation and tag those blocks as ephemeral at insertion time, so they skip L2 write-back and evict before normal blocks without any external signal. The design space here is wide: harness-driven session tagging, engine-native semantic detection, hybrid approaches that combine both. We are actively exploring multiple directions and expect the right answer will vary by workload and framework.
Closing the Gap
The biggest optimization surface in agentic inference is the gap between what the harness knows and what the infrastructure can see. Which agents are blocked, which are about to resume, which KV is worth keeping, which can be thrown away — all of this context exists at the harness layer but never crosses the API boundary. nvext.agent_hints is our first cut at closing that gap: a small set of structured signals that let the orchestrator make informed routing, scheduling, and cache management decisions instead of treating every request as anonymous tokens. This is a v1 API and we are actively evolving it. If you are building agent harnesses, running open-source models for agentic workloads, or thinking about cache-aware inference, we want to hear what signals matter most for your use case. Reach out on GitHub or tag us on X: @0xishand, @KranenKyle, @flowpow123.